
基于预训练语言模型特征扩展的科研论文推荐
2022-12-29 06:37章小卫耿宜帅
扬州大学学报(自然科学版) 2022年6期
章小卫, 耿宜帅, 李 斌
(扬州大学信息工程学院, 江苏 扬州 225127)
在互联网时代,信息数据呈指数型增长, 推荐系统可从海量数据中为用户推荐可能感兴趣的信息, 提高用户获取信息的效率,帮助用户快速做出决策[1], 已广泛应用于各种互联网服务[2].近年来, 随着大量科研成果的发表和知识体系的更新迭代, 科研论文的长尾效应愈加明显,即少部分热度较高的论文所受关注较多,而剩余的大量论文鲜为关注.此外,受自然语言表达复杂性的影响,研究者难以找到所需科研论文,给后续科研工作的开展带来困难.因此,科研论文推荐系统成为了学术领域不可或缺的工具,通过计算和排序已发表论文记录,缓解信息过载问题,为研究者推荐相关论文[3].
传统的论文推荐方法主要为矩阵分解法, 通过将评分矩阵分解为基于用户和项目的特定矩阵,以缓解数据稀疏和泛化能力差的问题,但由于隐私安全限制,难以获取有关用户属性的附加信息.深度学习中的自编码机具有收敛速度快,且无需标签数据的特性,也受到广泛关注[4],但训练模型合并项目和边信息时,要求输入层和输出层的维数相等,大大限制了网络的可扩展性和灵活性[5].针对以上问题,本文拟提出一种基于预训练语言模型特征扩展的科研论文推荐方法,仅利用论文的摘要信息辅助特征扩展,挖掘研究者兴趣,准确推荐论文,以期提升科研工作效率,助推科研工作发展.
1 研究方法
本文提出的预训练语言模型特征扩展方法具体结构如图1所示.该方法主要包括两部分: 一是辅助信息的特征表示学习, 利用预训练语言模型学习论文摘要的特征向量表示, 通过自编码机模型降维,提取高维特征表示; 二是将用户-论文的标签矩阵与辅助信息的扩展特征融合到半自编码机中.
1.1 辅助信息的特征表示学习
预训练语言模型(pre-training language models, PLMs)微调的方法已成功应用于各种数据挖掘和人工智能任务, 如文本分类[6]和词汇简化等.本文利用预训练语言模型学习论文摘要的特征向量表示, 并通过自编码机模型降维,提取高维特征表示.谷歌公司提出的基于转换器的双向编码表征模型(bidirectional encoder representations from transformers, BERT)是应用最广泛的预训练语言模型之一, 能够根据不同的上下文信息进行动态编码[7].因此, 本文使用BERT模型对论文摘要进行编码{w1,w2,…,wn}=B(w),{ay,1,ay,2,…,ay,n}=B(ay), 其中B(w)为摘要中每个单词的向量表示,B(ay)为第y个摘要的向量表示.
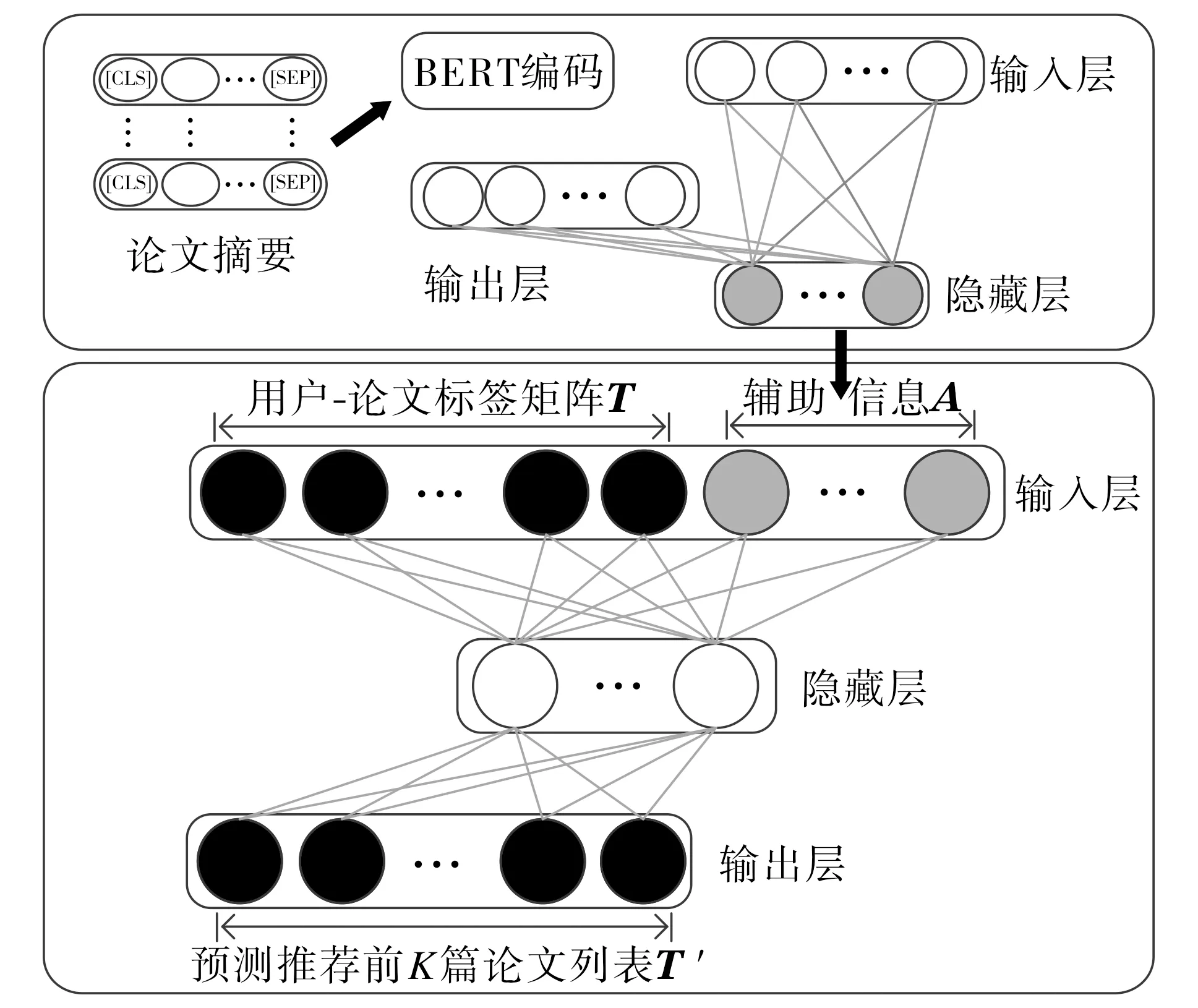
图1 预训练语言模型特征扩展方法结构示意图Fig.1 Structure diagram of feature expansion method for pre-training language model
1.2 半自编码机的共嵌入
获得论文摘要的特征表示后, 引入一个半自编码机模型结构, 合并用户-论文标签矩阵和论文摘要辅助信息, 学习到更多的推荐特征.半自编码机的输入定义为论文的标签矩阵T和论文摘要的特征表示矩阵A的拼接con(T,A), 其中con(T,A)∈Rn×(m+k),T∈Rn×m,A=B(ay)∈Rn×k,m,n分别为用户数量和论文数量,k为论文摘要特征表示维度.压缩重构后, 编码层表示为ξ=f(con(T,Α)·W+b), 其中W,b分别为编码层的权重矩阵和偏置向量,W∈R(m+k)×h,b∈Rh;h为隐层特征维度;f为sigmoid激活函数.解码层表示为T′=g(ξ·W′+b′), 其中W′,b′分别为解码层的权重矩阵和偏置向量,W′∈Rh×m,b′∈Rm;g为identity激活函数.此外, 使用随机梯度下降(stochastic gradient descent, SGD)方法对半自编码机进行模型优化.
由于半自编码机包含优化特征表示的辅助信息, 因此在重构输入时, 输出仅重构输入的一部分, 即输出T′, 不是con(T,A), 而是T的重构.目标函数表示为J=min{‖(T′-T)‖2}, 通过计算得到的T′进行推荐预测.
2 实验结果与分析
2.1 数据集
选取CiteULike网站中两个真实的科学论文数据集CiteULike-a和CiteULike-t进行实验, 采用精确度P、召回率R和F1分数F1三种评价指标测试本文所提方法的论文推荐效果[8], 计算公式分别为P=|AT∩AK|/|AT|,R=|AT∩AK|/K,F1=2PR/(P+R), 其中AT为测试集论文总数,AK为前K篇推荐论文.三个指标的值越大, 说明论文推荐效果越好.实验数据集包括标题、摘要、引文和标签等用于训练自动编码器的辅助信息, 其中用户设置的书签为用户-论文交互数据, CiteULike-a和CiteULike-t数据集中书签数量为1~5的论文比率如图2所示.由图2可知, CiteULike-a和CiteULike-t数据集中书签数量不超过5的论文占比分别为15%和77%, 表明数据集CiteULike-t比CiteULike-a的用户-论文交互数据更为稀疏.
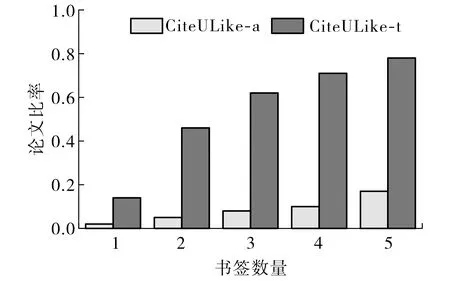
图2 数据集中书签数量为1~5的论文比率Fig.2 Ratio of articles with 1~5 bookmarks in the dataset
对数据集中每篇论文的文本信息进行预处理, 删除标记数量较少的论文[9], 处理后CiteULike-a和CiteULike-t数据集中交互数据的稀疏度分别为99.87%和99.93%, 具体数据统计结果如表1所示.每篇论文的标签信息不同, 相应的标签矩阵可表示所有项目的标签信息,每个矩阵条目Tij为一个二进制值, 若Tij=1表示用户i对论文j进行了标记, 否则Tij=0.

表1 CiteULike数据集处理后的数据统计
2.2 实验结果
选取广义矩阵分解[10](generalized matrix factorization, GMF)、协作深度学习[11](collaborative deep learning, CDL)、协作变分自编码机[12](collaborative variational autoencoder, CVAE)三种方法与本文所提的预训练语言模型特征扩展方法进行对比实验, 设定K=5,10,20,50,100, 测试CiteULike-a和CiteULike-t科研论文数据集推荐列表前K篇论文top-K的推荐效果, 结果如图3和图4所示.由图3~4可知, 本文方法对两个数据集中的论文推荐效果均优于其他方法. 此外, 由于本文方法引入辅助信息并整合上下文数据, 故可缓解推荐系统数据稀疏问题.
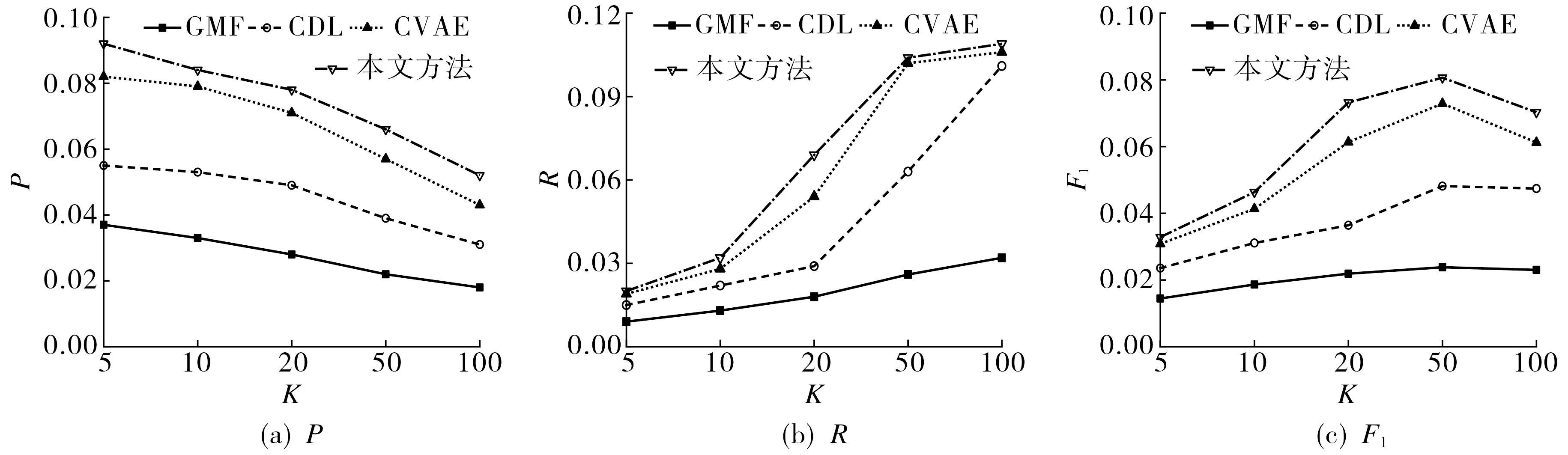
图3 CiteULike-a数据集top-K的推荐效果Fig.3 The top-K recommendation performance using CiteULike-a dataset

图4 CiteULike-t数据集top-K的推荐效果Fig.4 The top-K recommendation performance using CiteULike-t dataset
设置训练率为0.5,K=50, 将CiteULike-a数据集中摘要辅助信息进行BERT编码, 通过自编码机降至100维, 其他参数保持不变,选用F1分数作为性能评价指标,研究本文方法在不同半自编码机隐藏层神经元数量下的论文推荐效果. 当隐藏层神经元数量为500,1 000,1 500,2 000,2 500时,F1分别为0.075 5,0.079 6,0.071 4,0.067 2,0.061 1. 由此可见: 当隐藏神经元数量为1 000时, 模型的性能最佳; 随着半自编码机隐藏神经元数量的增加,模型推荐效果下降,这可能是由于隐藏层维度增加,半自编码机特征表示能力降低,导致无法较好地完成特征重构.
3 结论
本文提出了一种基于预训练语言模型特征扩展的科研论文推荐方法, 利用BERT模型学习论文摘要的特征表示,将其作为辅助信息, 通过半自编码机压缩特征, 缓解论文推荐中数据稀疏的问题.通过对经典科研论文数据集CiteULike的实验分析, 验证了本文所提方法的有效性.今后将扩展论文辅助信息, 进一步优化神经网络结构, 以实现更精准的论文推荐效果.
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
发明与创新(2021年39期)2021-11-05
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
读与写·教育教学版(2017年10期)2017-11-10
中学数学杂志(初中版)(2017年4期)2017-08-28
汽车文摘(2015年11期)2015-12-02
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
