
基于多级语义信息融合编码的序列标注方法*
2022-12-22 11:31蔡雨岐郭卫斌
计算机工程与科学 2022年12期
蔡雨岐,郭卫斌
(华东理工大学信息科学与工程学院,上海 200237)
1 引言
序列标注是自然语言处理领域的一个基本任务,目的是通过给文本序列中的每个词进行标注得到对应的标签序列,包括命名实体识别NER(Named Entity Recognition)、词性标注POS(Part Of Speech)及词汇组块(Chunking)等子任务。序列标注在自然语言处理中发挥着重要作用,其性能对于机器翻译和智能问答等下游应用有着重要影响。
目前,主流的序列标注方法多使用循环神经网络RNN(Recurrent Neural Network)或其变体来直接提取序列中的上下文信息,即按照序列的输入顺序,利用网络生成的所有历史信息来递归地对每一个单词进行编码,有效提取序列中单词之间的连续依赖关系。但是,这种方法捕获离散依赖关系的能力不强,同时也忽略了词与标签之间的联系。在序列标注任务中,序列中每一个词的最终标注结果都受其他所有词的影响,这种影响与距离无关,句子中的末尾词可能对句首词的最终标注结果产生很大影响。以命名实体识别为例,在“Amazon is one of the largest online e-commerce companies”这一句子中,将“Amazon”标注为“机构”主要依赖于“companies”。由此可见,序列中词之间的离散依赖关系也十分重要。其次,词与标签之间也存在一定关联,若上下文编码过程中学习到正确的标签知识[1,2],能够提升模型的性能。
为了更好地捕获序列中的离散依赖关系,同时增强词与标签的联系,本文提出了一种基于多级语义信息融合编码的序列标注方法。首先,采用双向长短期记忆网络BiLSTM(Bidirectional Long Short-Term Memory)[3]提取序列上下文语义信息;然后,利用注意力机制将标签语义信息添加到上下文语义信息中,得到融合标签信息的上下文语义信息;接着,引入自注意力机制捕捉序列中的离散依赖关系,得到含有离散依赖关系的上下文语义信息;再使用融合机制对3种语义信息进行融合,得到一种全新的语义信息;最后,使用条件随机场CRF(Conditional Random Fields)[4]对全新的语义信息进行建模,得到对应的标签序列。通过对比实验发现,融合标签信息的上下文语义信息和含有离散依赖关系的上下文语义信息,在单独使用的情况下,相比于基准模型性能有提升,但提升幅度要小于使用多级语义信息融合编码的模型,验证了基于多级语义信息融合编码的序列标注方法的合理性与有效性。
2 相关技术
传统的序列标注方法主要是基于经典的机器学习模型,如隐马尔可夫模型HMM(Hidden Markov Model)[5]、条件随机场CRF[5]和支持向量机SVM(Support Vector Machine)[6]等。传统的序列标注方法取得了成功,但是其所使用的特征需要手工制作,使得系统的设计成本过高,且泛化能力较弱,在新的数据集上很难达到好的效果。近年来,随着深度神经网络的不断发展,其在训练过程中自动提取特征的能力引起了研究人员的关注。
Collobert等人[7]率先使用固定大小窗口的简单前馈神经网络提取上下文语义信息,并通过CRF层生成最终的标记序列,取得了不错的实验结果。然而,通过窗口对序列进行编码只能提取到邻近词的信息,忽略了序列中的长距离连续依赖关系。双向长短期记忆网络BiLSTM因为具有良好的序列信息保存能力,被广泛应用于各种序列建模任务当中。Huang等人[8]首先利用BiLSTM对序列进行编码,得到序列的上下文语义表示后,利用CRF层解码生成最终的序列标记。在此基础上,Lample等人[9]和Ma等人[10]分别使用BiLSTM和卷积神经网络CNN(Convolutional Neural Network)对序列字符级别的特征进行编码;Liu等人[11]在使用BiLSTM提取字符特征的基础上加入了语言模型进行联合训练;Yamada等人[12]和Jiang等人[13]使用了新的词嵌入模型,通过引入外部知识来提升模型的性能。上述模型在序列标注任务中都取得了很好的成绩,但都没有有效捕捉词之间的离散依赖关系。
自注意力机制(Self-Attention)[14]能够无视距离建模序列中任意2个词依赖关系的能力引起了研究人员的关注,如何利用自注意力机制提高自然语言处理任务的性能,成为了当前研究的热点。目前,通过引入自注意力机制,阅读理解[15]、情感分析[16]和机器翻译[14]等自然语言处理任务的性能都得到了提升。同时有大量研究表明,在原有的语义信息上加入标签语义信息[17-20],增强序列与标签之间的依赖关系能够得到更好的实验结果。
本文受以上研究启发,提出了一种新的语义信息编码方法。首先,利用注意力机制生成包含序列离散依赖关系的语义信息,以及包含序列与标签依赖关系的语义信息;然后,设计了一种新的语义信息融合机制,将不同的语义信息融合在一起。在新的语义信息中既包含了序列的离散依赖关系,又包含了序列与标签之间的依赖关系。实验结果表明,本文提出的多级语义信息融合编码方式与基准模型相比性能有明显提升。
3 基于多级语义信息融合编码的序列标注
序列标注任务可以看成一个分类任务,目的是给序列中的每一个单词选择一个最佳标记。即给定序列X=(X1,X2,…,Xn),求出对应的标记序列(y1,y2,…,yn)。本文提出了一种基于多级语义信息融合编码的序列标注方法,具体标注过程如图1所示。
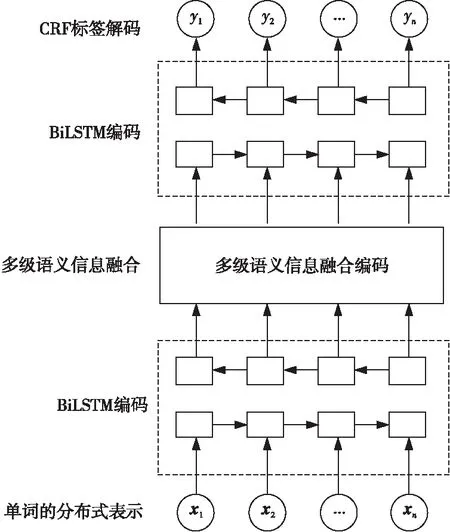
Figure 1 Process of sequence labeling based on multi-level semantic information fusion coding
首先,使用第1层BiLSTM提取原始序列的上下文语义信息,并将其输入多级语义信息融合层;在多级语义信息融合层中,利用注意力机制生成包含序列离散依赖关系的语义信息和包含序列与标签依赖关系的语义信息,然后将3种语义信息进行融合得到新的语义信息;第2层BiLSTM对新的语义信息进行建模,进一步从新的语义信息中提取特征;最后,将这些特征输入CRF层中,利用CRF预测出最终的标签序列。
3.1 单词的分布式表示
给定文本序列(X1,X2,…,Xn),其中Xi表示序列中的第i个单词。首先使用BiLSTM对序列进行字符编码,提取序列字符级别的特征,得到单词字符级别的向量表示,如式(1)所示:
(1)
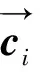
将ci与预先训练好的词向量ei进行拼接得到单词的分布式表示。对于给定单词Xi,其单词的分布式表示xi如式(2)所示:
xi=[ci;ei]
(2)
3.2 基于BiLSTM的上下文特征表示
本文使用BiLSTM来学习序列的上下文特征表示,共有2个BiLSTM编码层。

(3)
H={h1,h2,…,hn}
(4)
第2个BiLSTM层的输入为融合后的语义信息,通过对新的语义信息进行建模,进一步从新的语义信息中提取上下文特征。
3.3 多级语义信息融合编码
BiLSTM按照顺序处理输入的文本序列,以递归的方式将每个单词的前向隐藏状态和后向隐藏状态拼接起来,作为每个单词的上下文信息表示。在此基础上,为了更好地捕捉序列中的离散依赖关系以及充分利用标签信息,本文提出了一种多级语义信息融合编码方式。
(1)使用多头自注意力机制对序列的上下文语义信息H进行建模,增强序列中任意2个单词之间的依赖关系,进而得到含有离散依赖关系的上下文语义信息Hs。对于输入序列H,定义Q=K=V=H,其中Q,K和V分别表示查询向量序列、键向量序列和值向量序列。多头自注意力机制计算如式(5)~式(7)所示:
(5)
(6)
Hs=concat(head1,…,headm)Ws
(7)


再利用多头注意力机制将标签语义信息添加到序列的上下文语义信息H中,得到融合标签语义信息的上下文语义信息Hl。输入序列为H,定义Q=H,K=V=Le,Le为标签的分布式表示。具体计算同式(5)~式(7),最后得到输出Hl。
(3)由(1)可知,Hs和Hl中包含了一部分H的信息,因此需要通过遗忘机制增强Hs和Hl中的特殊语义信息。首先通过线性变换和非线性激活函数tanh、sigmoid生成对应的遗忘因子λ,如式(8)和式(9)所示:
(8)
(9)
接着使用融合门自适应地分别将Hs和Hl中的语义信息与H中的语义信息结合起来,得到zs和zl,如式(10)和式(11)所示:
zs=(1-λs)⊙H+λs⊙Hs
(10)
zl=(1-λl)⊙H+λl⊙Hl
(11)
最后将3种语义信息进行拼接,得到融合多级语义信息的Hf,如式(12)所示:
Hf=concat(H,zs,zl)
(12)
3.4 CRF标签预测
不同于普通的分类任务,序列标注任务中的标签之间具备一定的相关性,序列中元素的标签正确与否往往取决于邻近元素的标签。因此,在对元素进行标签预测时,还需要考虑相邻标签之间的相关性,从而得到最优的标注序列。

(13)
(14)
其中,Wyi-1,yi和byi-1,yi分别表示标签对(yi-1,yi)的状态转移矩阵和偏置矩阵中的相应值,这些参数在训练过程中被不断优化,从而让条件概率达到最大值。最后,选取极大似然函数L为目标函数,如式(15)所示:
(15)
其中,Y为所有可能的序列标注的集合。
4 实验与结果分析
4.1 实验数据集
本文针对命名实体识别NER、词性标注POS和词性组块Chunking等序列标注子任务进行实验,从而综合评估本文方法的性能,所使用的数据集分别为CoNLL03 NER、WSJ和CoNLL00 chunking等公开数据集,表1是3个数据集的具体统计情况。
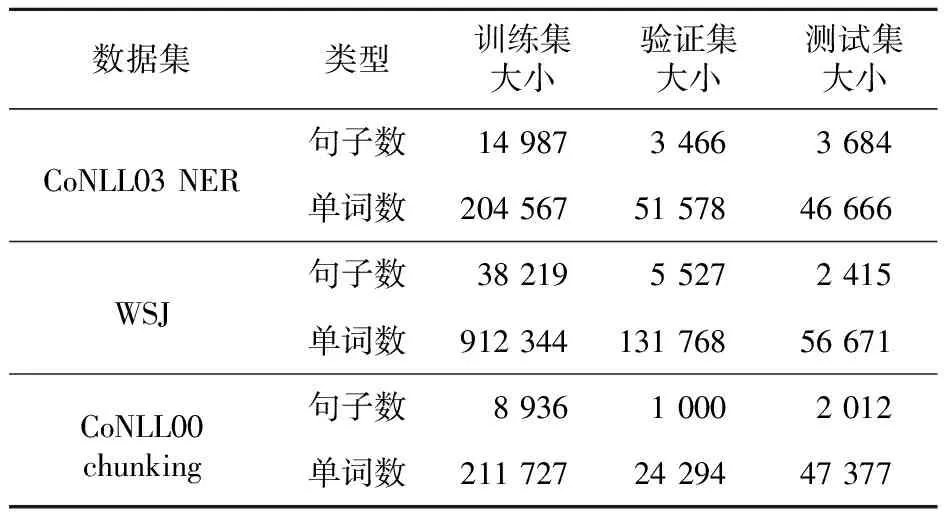
Table 1 Information of three datasets
4.2 实验参数设置
在单词的分布式表示过程中,使用隐藏状态大小为25维的BiLSTM学习单词字符级别的表示,得到维度大小为50的字符嵌入,然后与预训练好的100维度的glove词嵌入[21]进行拼接,得到150维度的单词分布式表示。上下文编码过程中BiLSTM的隐藏状态维度设置为256,层数为1,在多级语义信息融合编码阶段,设置多头注意力机制中的h=8。为了防止过拟合,在词嵌入与神经网络之后添加了dropout层,dropout参数分别设置为0.1和0.3。
在模型训练过程中,使用随机梯度下降优化函数训练模型参数,初始学习率η0=0.02,学习率更新方式为ηt=0.9ηt-1,batch_size=32,max_epoch=100。
4.3 评估指标
POS实验采用精确度Accuracy来评估实验结果,NER和Chunking实验采用综合评价指标F1值来评估实验结果,具体计算如式(16)~式(18)所示:
(16)
(17)
(18)
其中,TP表示正例样本中被预测为正例样本的数目,FP表示反例样本中被预测为正例样本的数目,FN表示正例样本中被预测为反例样本的数目。
为了综合评估模型的性能,定义深度学习模型将所有输入数据完整运行一次的时间为模型的训练时间,所有输入数据完整运行一次的过程称为一个epoch。本文记录模型的训练时间以及模型达到收敛所需的epoch数量,用于评估模型的效率。
4.4 结果分析
本文所提出的基于多级语义信息融合编码的序列标注方法对BiLSTM-CRF基准模型做出了改进,为了验证本文方法的有效性与合理性,本文自主设计了4种对比实验,每种对比实验重复实验5次,取平均值做为最终结果。同时,为了综合评估改进模型的性能,在经典的NER任务中,本文选取了BiLSTM-CRF基准模型和几个在其基础上改进的经典模型进行对比。4种自主设计的对比实验如下所示:
(1)BiLSTM-CRF:经典的BiLSTM-CRF模型,基于Huang等人[8]提出的序列标注模型,在单词层级上使用3.1节的单词分布式表示方法。
(2)BiLSTM-CRF+SA:在BiLSTM-CRF的基础上,添加自注意力机制捕获序列中的离散依赖关系。
(3)BiLSTM-CRF+LA:在BiLSTM-CRF的基础上,使用标签嵌入生成标签语义关系,然后利用多头注意力机制将标签语义关系添加到原始语义关系中,增强序列元素与标签之间的联系。
(4)BiLSTM-CRF+FA:在BiLSTM-CRF的基础上,通过(2)和(3)得到包含序列离散依赖关系的语义信息以及包含序列与标签依赖关系的语义信息,然后将这2种语义信息与原始语义信息融合得到新的语义信息。
4.4.1 NER实验结果
上述算法在NER任务上的实验结果如表2所示。其中,Lample等人[9]和Ma等人[10]分别使用BiLSTM和CNN对序列字符级别的特征进行编码,Liu等人[11]在使用BiLSTM提取字符特征的基础上加入了语言模型进行联合训练。
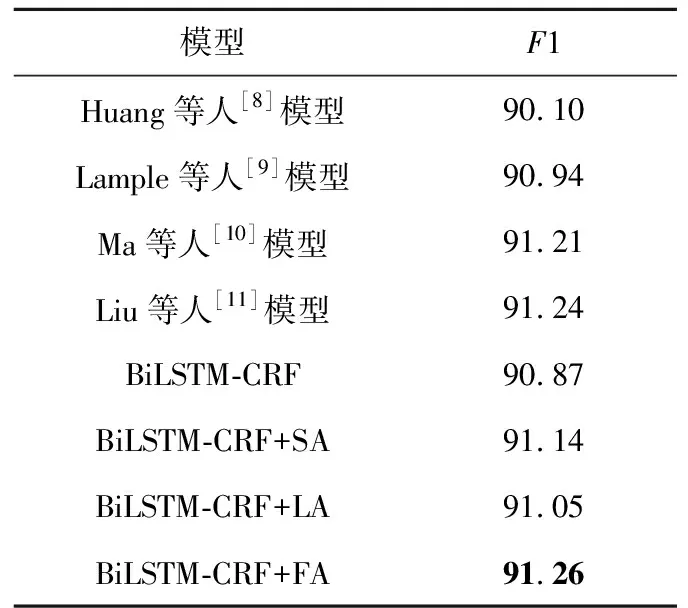
Table 2 Comparison of experimental results of different models on NER
从表2可以看出,相比于经典的BiLSTM-CRF模型,加入使用自注意力机制的语义信息后,F1分数提高了0.27%;加入融合标签嵌入信息的语义信息后,F1分数提高了0.18%;加入融合多级语义信息的新型语义信息后,F1分数提高了0.39%。相比于Huang等人实现的基准模型,本文改进的BiLSTM-CRF+SA模型的F1分数提高了1.04%;BiLSTM-CRF+LA模型的F1分数提高了0.95%;BiLSTM-CRF+FA模型的F1分数提高了1.16%。
总之,对比算法所取得的实验效果均不如本文所提方法对基准模型改进后的效果。
4.4.2 POS实验结果
上述算法在POS任务上的实验结果如表3所示。
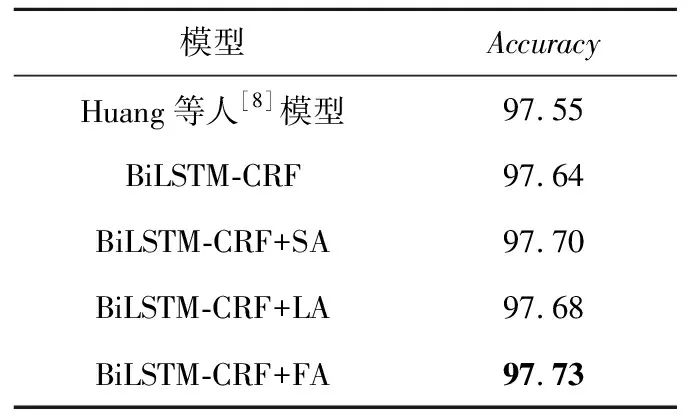
Table 3 Comparison of experimental results of different models on POS
从表3可以看出,相比于经典的BiLSTM-CRF模型,加入使用自注意力机制的语义信息后,准确率提高了0.06%;加入融合标签嵌入信息的语义信息后,准确率提高了0.04%;加入融合多级语义信息的新型语义信息后,准确率提高了0.09%。相比于Huang等人[8]实现的基准模型,BiLSTM-CRF+SA模型的准确率提高了0.15%;BiLSTM-CRF+LA模型的准确率提高了0.13%;BiLSTM-CRF+FA模型的准确率提高了0.18%。
4.4.3 Chunking实验结果
上述算法在Chunking任务上的实验结果如表4所示。从表4可以看出,相比于经典的BiLSTM-CRF模型,加入使用自注意力机制的语义信息后,F1分数提高了0.22%;加入融合标签嵌入信息的语义信息后,F1分数提高了0.09%;加入融合多级语义信息的新型语义信息后,F1分数提高了0.38%。相比于Huang等人[8]实现的基准模型,本文所实现的BiLSTM-CRF+SA模型的F1分数提高了0.41%;BiLSTM-CRF+LA模型的F1分数提高了0.28%;BiLSTM-CRF+FA模型的F1分数提高了0.57%。

Table 4 Comparison of experimental results of different models on Chunking
4.4.4 模型训练时间结果对比与分析
本文所提方法改进的模型在不同数据集上的训练时间如表5所示。从表5可以看出,在3个数据集上,模型训练时间满足如下关系:BiLSTM-CRF+FA > BiLSTM-CRF+SA > BiLSTM-CRF+LA > BiLSTM-CRF。
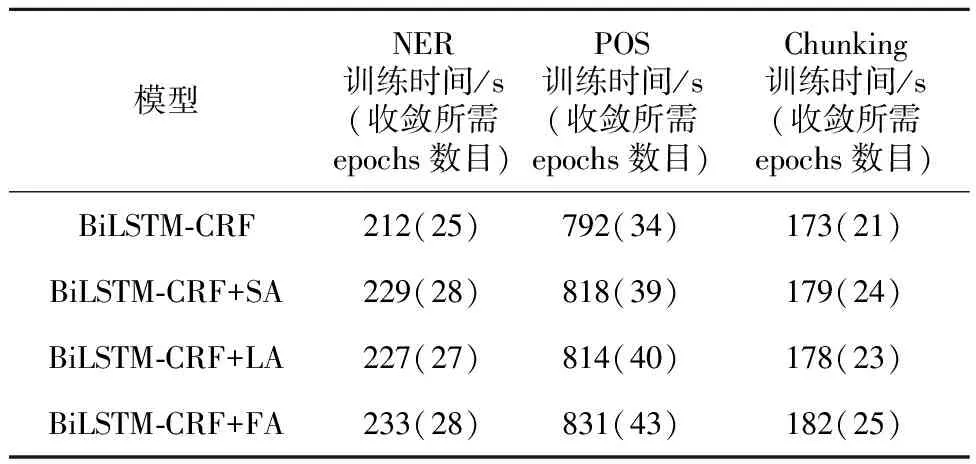
Table 5 Comparison of the training time of models on different data sets and the number of epochs required for training
从模型结构上来看,前3种模型相比于基准模型多了一个BiLSTM层,因此训练时间增加较为明显;3种模型的线性变换结构不同,训练时间虽然有差异,但差距较小;BiLSTM-CRF+FA模型结构最复杂,所以训练时间最长。
在NER任务和Chunking任务上,BiLSTM-CRF+FA模型的F1分数相比于基准模型提升较大,训练所需时间提升较小;在POS任务上,BiLSTM-CRF+FA模型的准确率相比于基准模型提升较小,但是训练所需时间提升较大。因此,在解决NER问题和Chunking问题时,BiLSTM-CRF+FA模型是最好的选择;在解决POS问题时,如果要选择最高的准确率,也应该选择BiLSTM-CRF+FA模型。
从表5还可以看出,在NER任务上,模型达到收敛所需的训练时间较短,不同的模型所需时间相差不大,均为1~2 h;在POS任务上,BiLSTM-CRF+FA模型达到收敛所需的训练时间最长,需要将近10 h,经典的BiLSTM-CRF模型所需时间最短,需要7 h;在Chunking任务上,模型达到收敛所需的训练时间大约为1 h。
4.4.5 实验结果分析
通过对比实验可以看出:
(1)在基准模型上加入使用自注意力机制的语义信息后,模型性能在3个任务上都有提升。这说明利用自注意力机制能捕获序列中的离散依赖关系,且使用包含序列离散依赖关系的语义信息能提高模型的性能。
(2)在基准模型上加入融合标签嵌入信息的语义信息后,模型性能在3个任务上都有提升。这说明在训练过程中优化标签嵌入向量的参数能够使标签具备语义信息,且利用注意力机制可以建立序列元素与标签之间的依赖关系,合理利用这种依赖关系能提高模型的性能。
(3)BiLSTM-CRF+SA模型的整体性能优于BiLSTM-CRF+LA的。这说明在本文提出的模型中,序列间离散依赖关系对最终序列标注结果的影响大于序列元素与标签之间的依赖关系的。
(4)BiLSTM-CRF+FA模型的性能在3个任务上都取得了最好的结果。这说明本文提出的融合机制能有效地将3种语义信息融合成为1种新的多级语义信息,使新的语义信息同时包含了序列中的离散依赖关系与序列元素与标签之间的依赖关系,且在后续的神经网络中使用融合后的多级语义信息提升了模型性能。
5 结束语
本文提出了一种基于多级语义信息融合编码的序列标注方法。针对BiLSTM-CRF基准模型无法有效捕获序列中离散依赖关系的缺点,引入自注意力机制生成包含离散依赖关系的语义信息;在此基础上,将标签语义信息加入原始语义信息中,建立序列与标签之间的联系;最后通过融合机制生成一种新的多级语义信息。通过多组对比实验发现,本文提出的方法改进的模型相比于基准模型在性能上有显著提升,验证了本文所提方法的合理性与有效性。从实验结果可以看出,序列间的离散依赖关系是影响序列标注最终结果的一个重要因素,因此设计出相应方法以更高效地捕捉序列间离散依赖关系是未来的一个重要研究方向。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
开放教育研究(2020年2期)2020-03-31
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
