
一种HEVC帧内预测算法的动态自重构实现方法*
2022-12-22 11:31崔馨月胡传瞻
计算机工程与科学 2022年12期
崔馨月,蒋 林,杨 坤,惠 超,胡传瞻,赵 静
(1.西安邮电大学电子工程学院,陕西 西安 710121;2.西安科技大学集成电路实验室,陕西 西安 710054;3.西安邮电大学计算机学院,陕西 西安 710121)
1 引言
高效视频编码HEVC(High Efficiency Video Coding)是当前互联网技术飞速发展背景下的产物。编解码算法具有数据量大、复杂度高的特点,有着良好的应用前景。
可重构阵列处理器在兼顾通用处理器的灵活性和专用硬件高性能特性的同时,又具有较好的能量效率和面积效率,因而受到了广泛关注[1]。HEVC在专用硬件上的实现远没有在可重构阵列处理器上实现的灵活性高。
以帧内预测算法为例,利用相邻预测单元PU(Prediction Unit)中已编码的像素来预测新的编码单元CU(Coding Unit)中的像素,去除空间冗余信息。使用专用硬件实现帧内预测算法主要是针对固定编码块大小或者1种固定模式,无法根据不同应用场景的需求实现不同算法的切换。文献[2]采用了近似角度预测的帧内预测技术,并且设计了近似角度预测的硬件架构,减小了硬件面积,但是编码时间较长且效率不高。文献[3]为HEVC帧内预测提供了一种绝对误差和SAD(Sum of Absolute Difference)单元硬件体系结构,但此结构会降低预测计算的精确度和编码效率。文献[4]提出了一种基于梯度的帧内预测硬件加速算法,省去了预测模式和划分深度的选择,减小了计算量,节省了编码时间。但是,仅支持CU大小为16×16的算法实现,并且只选择1种预测模式计算,固定块大小的预测方式降低了编码效率,单一的运算模式降低了帧内预测算法的准确性。文献[5]提出了像素相似性的计算方法,减少了帧内预测算法执行的计算量和硬件的能量消耗。使用5个并行的数据路径来分别计算1个8×8的CU块和4个4×4的CU块的预测方程,每条路径都需要进行35种预测模式的计算,硬件结构固定且计算周期长。文献[6]采用新的预测单元处理顺序,基于16点的硬件复用结构,4种预测模式并行处理,预测准确性不高。
为了充分提高资源利用率,减小帧内预测算法在硬件实现上的资源消耗,本文提出一种帧内预测算法在可重构阵列处理器上的动态自重构实现方法,对处理单元PE(Processing Element)的执行状态进行监测,实现帧内预测算法在不同应用场景间的动态自重构。
2 帧内预测算法动态自重构实现的需求分析
帧内预测算法的模式重构指的是根据不同应用场景,灵活切换所需的预测模式。在高清视频传输应用场景下,对编码质量与编码速度有较高要求,为了得到较高的编码质量需要全部遍历帧内预测的35种预测模式,若对此35种预测模式在硬件上串行实现,则计算时间长且编码速度低,因此,需要提出一种可并行计算方案;在移动视频传输的应用场景下,需要降低硬件资源消耗及功率消耗,就要求在保证编码质量的前提下减少硬件资源的使用,但是,35种预测模式并行计算会造成很大的资源消耗。如果满足单一的应用场景需求,在专用硬件上实现帧内预测算法是有效的,但是当应用场景切换时,专用硬件无法同时满足其需求,因此需要一种帧内预测算法的动态自重构的硬件实现方法,可以在应用场景切换时实现算法不同模式间的动态自重构。
通过分析帧内预测每种模式的计算过程可知,平面模式(Planar)和直流模式(DC)计算过程单一,33种角度模式占总预测模式的很大部分。虽然预测模式较多,但是其计算过程相对固定,确定每种模式的偏移量offset以后,就可以确定参考像素矩阵Ref的位置,之后所进行的操作完全相同。因此,可以通过重新配置offset值实现35种预测模式的重构计算。从硬件实现角度分析,整个可重构处理器结构通过PE执行状态监测器对PE当前执行状态进行监测,再由H-tree型传输网络实现对PE阵列上任意PE配置信息的下发。所以,通过下发不同预测模式映射方案的配置信息,可以实现同一块大小不同预测模式在阵列上的动态重构。此外,随着CU块大小(N值)改变,只是参考像素矩阵Ref的大小和数值随之变化,处理过程不变。因此,在实现不同预测模式的灵活切换时,同时也支持不同预测块大小的像素计算在硬件上的实现。
阵列结构的分布是规则的,但是帧内预测算法在阵列中的映射方案是非规则的,这导致部分PE未被分配执行任务而处于空闲状态,同时又有部分PE执行完分配的任务后处于等待状态,造成阵列计算资源在时间上的浪费。为了有效提升整个阵列的资源利用率,在执行帧内预测算法映射任务时需要对阵列的执行状态做出判断。因此,本文在每个PE中加入了执行状态监测器,建立了一种基于状态监测机制的帧内预测算法在可重构阵列上的动态自重构。
3 帧内预测算法的并行化实现
3.1 基于状态监测的可重构阵列结构
本文采用基于状态监测的可重构视频阵列处理器[7],如图1所示。此处理器由可重构视频阵列结构、输入存储器DIM(Data Input Memory)和输出存储器DOM(Data Output Memory)组成,可重构视频阵列结构中包含主机接口、全局控制器和处理单元PE阵列。
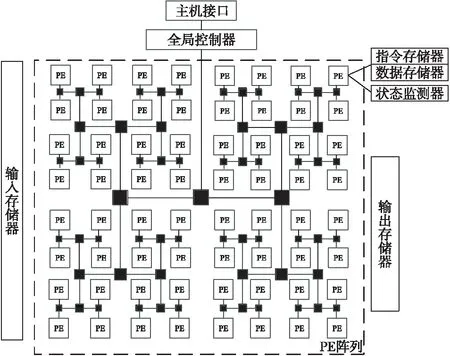
Figure 1 Reconfigurable video array structure
全局控制器用于控制与管理阵列计算资源,是可重构机制的关键部分。PE阵列是整个系统的核心计算部分。图1所示的PE阵列包括4个处理单元簇PEG(Processing Element Group),它们通过路由器进行通信,每个PEG中包含4×4个PE,每个PE中又包含指令存储器、数据存储器及执行状态监测器。
含有执行状态监测器的PE结构如图2所示。PE执行状态监测器实时监测可重构阵列中每个PE的执行状态,并把状态信息反馈给上层控制器,这是可重构阵列实现实时自重构调度的基础。整个PE采用取指、译码、执行和回写四级流水线架构。PE通过对指令的译码产生不同的控制信号,控制执行级完成相应的操作。因此,状态监测主要是通过PE内的标志信号busy_flag来判断执行单元实际是否工作,busy_flag为1,说明当前PE处于工作状态;busy_flag为0,说明当前PE处于空闲状态。全局控制器下发一条状态收集指令peg_state,获取一个PEG中各个PE的工作状态,根据状态收集命令发送的顺序,形成一个16位的PE阵列状态寄存器,用来存储16个PE的执行状态,最低位代表PE00,最高位代表PE33。通过对该寄存器中0的个数与位置的统计,可以清晰地判断出当前时刻哪些PE处于空闲,哪些PE正在工作。
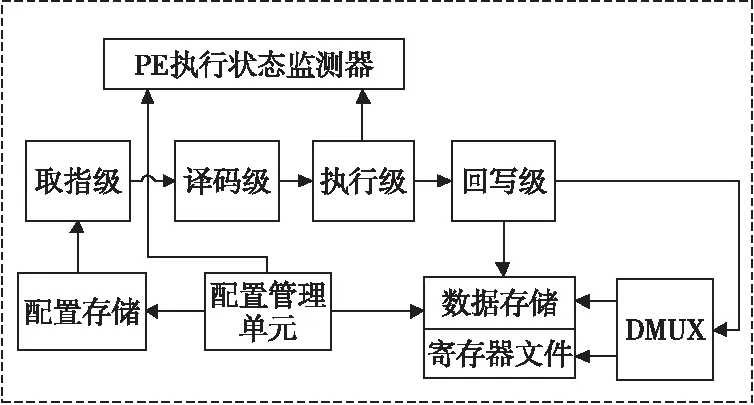
Figure 2 PE structure based on state monitoring
根据此状态寄存器中的数值,全局控制器通过H-Tree型层次化配置网络,将配置指令下发到下层PE阵列的每一个空闲PE中去,让PE在有效的执行周期内一直处于工作状态,从而实现算法在可重构阵列处理器上的灵活切换。配置指令用于实现多种模式的灵活切换和对阵列计算资源的控制与管理,从而达到合理分配资源的目的。
3.2 帧内预测算法的并行化设计
在帧内预测算法计算过程中,每种模式预测像素的计算过程相互独立、互不影响,因此可以实现算法在硬件上的并行映射。以8×8的CU为例,在4×4的PE阵列结构下,结合角度模式的计算特点以及阵列结构的特征进行预测值P(x,y)的映射,其中每个PE可以完成4个预测像素P(x,y)计算的所有操作,并且x方向与y方向同时并行处理,由于像素值的计算本身不存在数据依赖关系,因此可以在PE中同时计算。每个PE中可以执行4个像素点的所有预测模式的计算,因此本文选择4路并行计算,既保证了计算速度适中,也不会造成过多的硬件资源消耗。
图3和图4分别为高清应用场景下帧内预测水平类和垂直类角度模式计算在可重构阵列处理器上的并行映射图。其中,帧内预测在PEG00中映射,PE0000与DIM通信,用来接收原始像素值,在PEG00中计算结束后由PEG00的PE0033将残差像素值传给PEG01的PE0130,以进行后续离散余弦变换DCT(Discrete Cosine Transform)。

Figure 3 Parallel mapping of horizontal class angle pattern
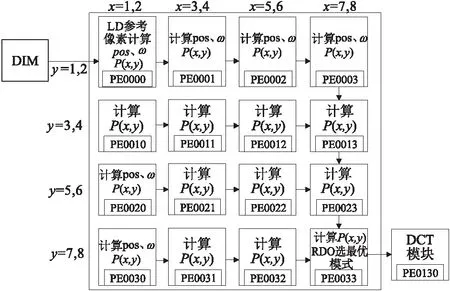
Figure 4 Parallel mapping of vertical class angle pattern
对于水平类预测模式,每行所计算的预测像素值对应的pos(参考像素在Ref中的位置)和ω(当前像素对应参考像素的加权因子)是相同的,只在每行的起始PE计算(垂直类模式同理,每列所需的pos与ω相同),每个PE中计算4个像素点的所有角度预测模式,最大化地利用PE的资源。在HM16.7软件中对大量测试序列的CU块划分并进行统计,结果显示将1帧图像划分为8×8的CU块出现的概率最高[8],因此,本文主要以8×8的CU块进行像素预测计算。首先,在PE00中从DIM内每次取出一个8×8的CU作为原始块,和其左侧、上方共33个参考像素存入PE00的数据存储器中,整个PEG共享此存储,其他PE计算时均从PE00的数据存储器中读取数据,分别计算出64个像素点在不同模式下的预测值;最后根据率失真优化算法选择一种最优的预测模式,并将此最优模式计算出来的预测像素与原始像素作差,得到8×8的残差矩阵传入DCT模块做后续处理。
4 帧内预测算法动态自重构实现
3.2节中,在4×4的可重构阵列上实现了帧内预测算法的4路并行设计。但由于多个PE在访问同一地址中的数据时有先后顺序,并非所有PE同时结束任务,导致有些PE先完成计算后处于空闲状态,造成PE资源的浪费。因此,需要一种帧内预测算法的自重构实现方法,在部分PE空闲时及时下发新的任务,实现对可重构阵列资源的充分利用。
4.1 单一应用场景下帧内预测算法实现过程
在高清视频传输应用场景下,要求编码质量高,编码计算过程精确,因此使用的是3.2节中帧内预测算法的并行化设计映射方案。使用阵列规模为4×4的PE,将8×8大小的CU遍历35种预测模式,从中选择最优预测模式,记为方案1。首先将参考像素的选取指令初始化到阵列处理器外部存储的0~47号地址中,将35种预测模式的计算指令存到外部存储的48~466号地址中,每个PE计算1个CU块4个原始像素点的预测像素。
在移动视频传输应用场景下,要求减小硬件资源的消耗,为了保证编码速度,降低了对编码质量的要求,因此使用阵列规模为1×4的PE,将8×8大小的CU遍历5种预测模式,从中选择最优预测模式,记为映射方案2。经过HM16.7官方软件分别对测试序列Cactus_1920×1080、ChinaSpeed_1024×768和RaceHorses_832×480进行预测统计,图5~图7所示为测试出现频率最高的7种预测模式统计结果,其中横坐标为模式种类,纵坐标为使用该模式预测的CU块数。同时,在3个序列的测试过程中,Planar、DC、角度模式Angular26、Angular10和Angular18出现的频率最高,平均出现概率为92.23%。因此,本文选用该5种预测模式作为最优预测模式的备选。
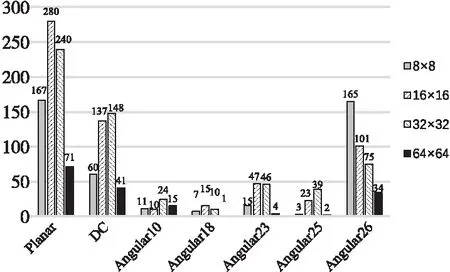
Figure 5 Seven prediction models with the highest occurrence probability of Cactus
如图8所示的映射方案2中,每个PE计算8×8 CU块的2列共16个像素点在5种预测模式下的预测像素。其本质上与映射方案1的每行处理过程一样,不同的是映射方案2的y值要从1遍历到8。映射方案2中读取数据时采用的是共享存储,在阵列上的映射不受PE位置的影响,所以可以使用阵列上任意位置的4个PE完成该映射方案的执行。

Figure 6 Prediction models with the highest occurrence probability of ChinaSpeed
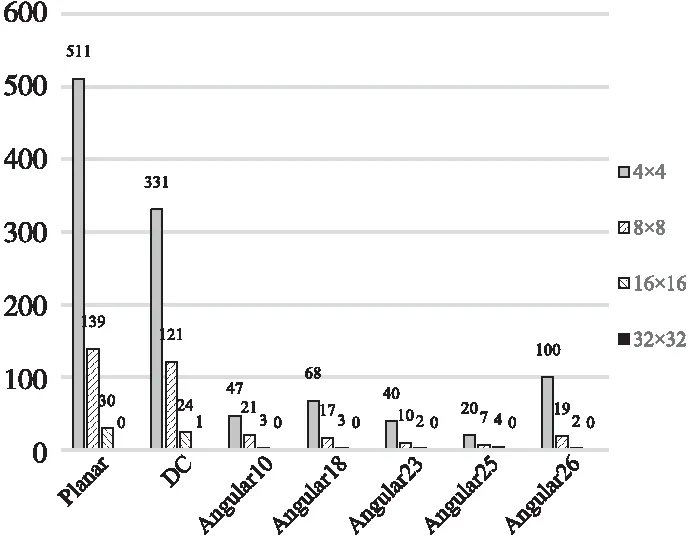
Figure 7 Prediction models with the highest occurrence probability of RaceHorses

Figure 8 Intra prediction mapping under mobile application scenarios
4.2 1帧图像内的2种方案动态自重构实现
为了实现2种映射方案在可重构阵列上的灵活切换,首先针对1帧图像实现2种映射方案的自重构。首先将图像分割成若干个64×64的编码树单元CTU(Coding Tree Unit)进行处理,以1个CTU划分成16个8×8的CU为例,将第1个CU配置成为方案1,即从35种预测模式中选取最优的预测模式;后续的15个CU重构成方案2,即从5种预测模式中选取最优的预测模式。计算下一个CTU时,再将第1个CU重构成方案1,以此类推,直到1帧图像预测结束。
图9所示为1帧图像基于状态监测机制的帧内预测自重构流程图。PE阵列启动时,每个PE内的状态监测器同步开始工作,此时所有PE处于空闲状态。全局控制器通过H-tree型指令传输网络下发一条状态收集指令收集当前PE的执行状态并反馈给上层控制器,此时状态寄存器中会显示16位全为0。计算第1个CTU时,全局控制器首先下发方案1的配置信息,阵列中PE接收到配置信息后开始工作,进行第1个CU块预测像素的计算。此时,PE执行状态监测器不断地监测PE是否处于空闲状态,由于多个PE在访问同一地址中的数据时有先后顺序,因此,并非所有PE同时结束任务。全局控制器下发状态收集指令,接收到反馈信号后,若状态寄存器中出现4个0,说明有4个PE处于空闲状态,则对这4个PE下发映射方案2的配置信息,以计算第2个CU块的预测像素;继续监测PE的执行状态,再次出现4个空闲PE时,再对这4个空闲PE下发映射方案2的配置信息,计算第3个CU块的预测像素。第1个CTU计算结束后,等待全部PE空闲,再次下发方案1来计算第2个CTU第1个CU的预测像素,以此类推,直到1帧图像所有CTU遍历结束后停止。
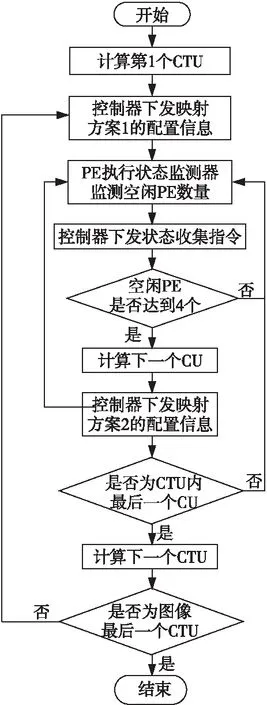
Figure 9 Flow chart of intra prediction self-reconstruction
全局控制器下发不同的配置信息实现了2种映射方案的灵活切换,当监测到空闲PE达到4个时,能够及时下发下一CU块所要执行的映射方案,让PE在有效的执行周期内一直处于工作状态,从而缩短重构时间,提升重构性能。在基于状态监测的可重构阵列处理器上映射帧内预测算法,能够合理利用每一个空闲PE,及时下发新的配置指令,不仅节省了计算时间,而且不会造成资源浪费。
5 实验结果及性能分析
为了验证帧内预测算法动态自重构实现方法的可行性,本文将帧内预测模块的自重构方案与帧内环路的其它模块联调,在可重构阵列处理器中进行测试。通过ModelSim仿真验证,在XILINX公司的ISE14.7基于Virtex 6开发环境对设计进行综合,结果如表1所示。
表1列举了1帧图像分别在高清场景(下文用方案1表示)、移动场景(下文用方案2表示)以及2种方案切换(自重构方案)下的各项性能指标对比,3种方案分别在4.1节和4.2节有说明。将1帧图像分割为8×8的CU块执行映射方案1的模式计算,花费的时钟周期数为7 692,电路规模为32 738 Flip-flops,硬件资源的消耗高于方案2的,但是预测模式较全面。将1帧图像分割为8×8 CU执行映射方案2的计算,所花费的时钟周期数为5 787,相比方案1降低了24.8%,电路规模为9 084 Flip-flops,硬件资源的消耗低于方案1的。基于状态监测机制下的自重构方案,平均每个CU块执行的时钟周期数为4 849,相比方案1的减少了36.9%,相比方案2减少了10.6%,硬件资源的消耗与方案1的相同。
使用多种测试序列加载到可重构阵列处理器进行帧内编码,将编码前后的像素值导入Matlab端计算其峰值信噪比PSNR,与HM16.7软件下的测试结果相比较并计算ΔPSNR[9],结果如表1所示。由表1可知,3种方案相比,方案1的PSNR值最高,方案2的PSNR值低于方案1的,编码质量较低,但仍能满足图像质量要求。执行自重构方案得出的PSNR值在与方案1的几近相同的情况下,即达到几乎相同的编码质量条件下,执行时间减少了36.9%。
同样地,使用本文的自重构方案重复上述步骤,将不同测试序列的PSNR值、结构相似度SSIM与HM16.7标准测试下(QP值为32)的结果相比。比较结果如表2所示,使用本文的自重构方案得出的平均PSNR值高于HM16.7软件的0.043 dB,平均ΔPSNR值高于文献[9]的0.106 dB,满足图像质量要求。
通过全局控制器下发不同应用场景的配置信息,实现本文提出的自重构方案,将帧内预测算法在可重构阵列处理器上进行映射,使用stefan_cif测试序列在BEEcube公司的BEE4系列开发板上进行FPGA测试,验证自重构方案的正确性。将该测试序列的第1帧原始像素存入DIM中,按照4.2节提出的自重构方案,将1帧图像以CTU为单位处理,CTU内是方案1切换至方案2,CTU间是方案2切换为方案1。将帧内预测计算后的预测像素值进行帧内环路联调,导入Matlab恢复后的测试结果如图10所示,可以看出测试结果具有良好的可视效果。

Table 1 Performance comparison of different schemes
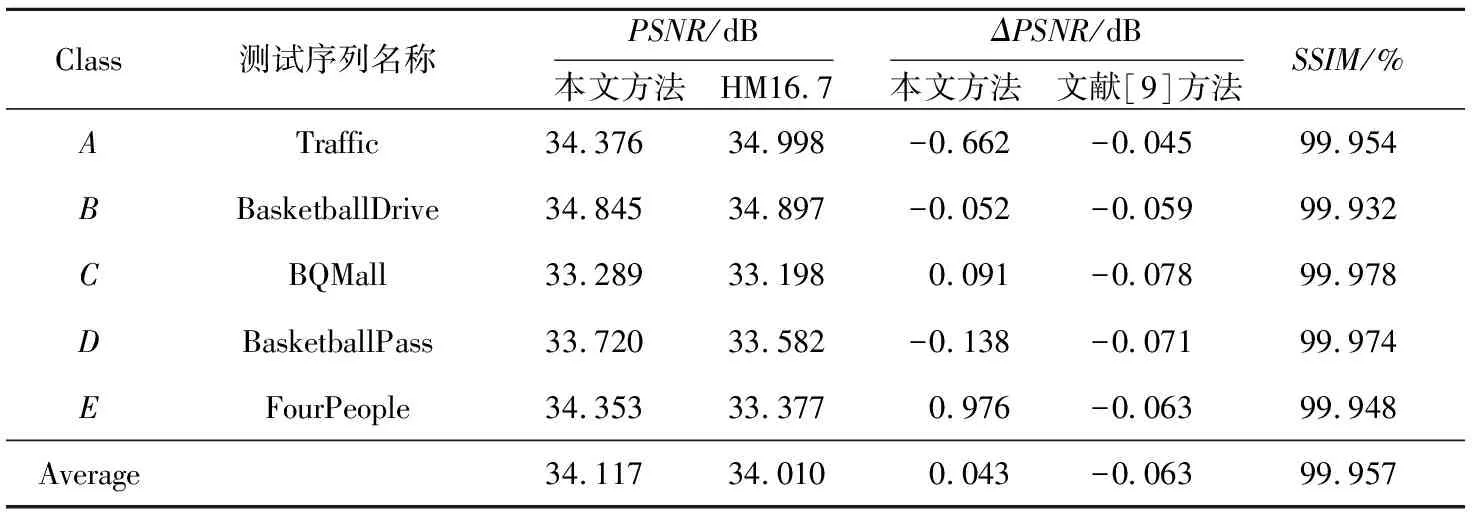
Table 2 Performance indices of different test sequences

Figure 10 Test results of stefan_cif FPGA
将1帧图像的自重构思路扩展至一个分辨率为1920×1080的视频测试序列,第1个I帧采用方案1预测,后7个I帧采用方案2预测,以图像为单位进行2种方案的自重构,模拟高清、移动场景的切换。测试结果表明,平均1帧图像的编码时间为3.56×10-2s,满足1 080 p@30的编码要求。
在ISE14.7基于Virtex 6开发环境下对设计进行综合后和不同文献的硬件参数的对比结果如表3所示。由表3可知,在相同的硬件工艺下,文献[6]方法消耗了5 787个时钟周期,最高主频为196 MHz,本文使用的时钟周期数为4 849,相比之下时钟周期数降低了16.2%,虽然最高主频低了20%,但是本文方法的硬件资源比其减少了33.6%,并且可以灵活切换所有的预测模式。文献[10,11]方法的时钟周期和频率都优于本文方法的,且文献[11]方法的吞吐量在高清视频下达到每秒110帧,但是其硬件资源是本文方法的3倍以上,产生的成本过大,并且只是对帧内预测算法的固定映射。文献[12]方法的吞吐量与本文的相近,但是最高主频比本文方法的低了31%,这会导致编码效率不高,并且其硬件资源的消耗比本文方法的高26%。文献[13]方法支持4 K的视频传输,硬件资源的消耗也较少,但是文献[13]方法仅支持CU块大小为4×4的2种预测模式的计算,通过牺牲模式种类的选择,减少CU块尺寸,来增加视频编码的精准性,计算复杂,频率是本文方法的1/3。
6 结束语
本文基于状态监测机制的可重构阵列处理器结构,针对HEVC帧内预测算法在专用硬件上实现难以达到算法灵活切换以及资源消耗过多的问题,提出了一种帧内预测算法自重构的硬件实现方法。该方法通过PE的工作状态监测器监测PE的执行状态,监测到空闲PE则及时下发新的配置信息,实现对阵列资源的充分利用,提高了计算效率,减少了硬件资源的使用。实验结果表明:对于帧内预测算法的动态自重构实现方法,与文献[6]方法在专用处理器上的实现方法相比,达到了对算法灵活切换的同时,硬件资源消耗减少了33.6%,算法执行的时钟周期数减少了16.2%。本文提出的帧内预测算法的动态自重构实现方法在对配置信息的调度方式上仍有待完善,如何结合算法本身以及阵列结构的特点,在指令流与数据流混合驱动的PE阵列实现帧内预测算法在时间与空间上的自适应重构将是下一步的研究方向。
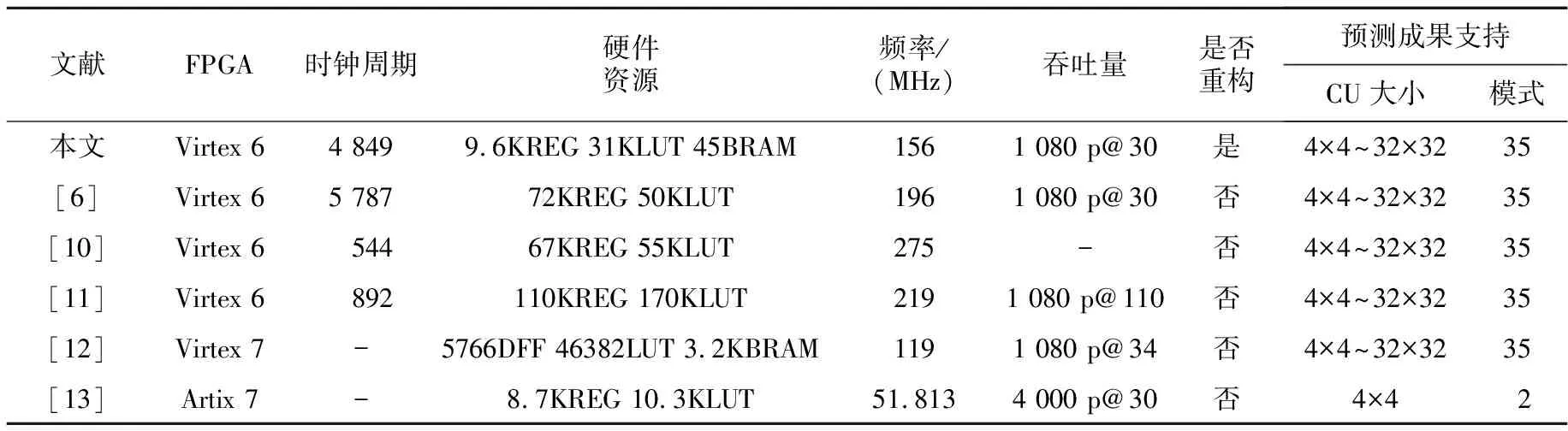
Table 3 Comparison of hardware parameters and other performance indices
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
红领巾·萌芽(2019年8期)2019-08-27
知识经济·中国直销(2018年12期)2018-12-29
中国与非洲(法文版)(2017年10期)2017-11-23
商周刊(2017年6期)2017-08-22
CHIP新电脑(2016年3期)2016-03-10
汽车零部件(2014年1期)2014-09-21
微型计算机(2009年17期)2009-05-19
