
基于指令Cache和寄存器压力的循环展开优化*
2022-12-22 11:31王翠霞刘浩浩
计算机工程与科学 2022年12期
王翠霞,韩 林,刘浩浩
(中原工学院前沿信息技术研究院,河南 郑州 450007)
1 引言
循环是影响程序性能的核心,通常也是编译器优化的理想目标[1]。循环展开是关键的循环优化技术之一,主流编译器如GCC(GNU Compiler Collection)、LLVM和ICC等都实现了该优化技术。循环展开通过多次复制原始循环体,并调整循环退出代码来减少计算循环索引和测试循环分支条件带来的开销[2]。循环展开能为其他优化增加机会,如公共子表达式消除、归纳变量优化和软件流水等[3],它也是向量化、数据预取[4,5]等优化的重要组成部分。
但是,循环展开并不总是有收益的,过度的循环展开会导致循环的指令数量激增,如果目标平台的指令Cache过小,将会造成指令Cache溢出,从而降低指令Cache的命中率。同时,循环展开会增加额外的中间变量,展开之后的循环体对寄存器的需求增大,容易导致寄存器溢出,从而降低程序的运行性能[6]。然而,循环展开次数过少,则浪费了潜在的优化机会,不能充分改善程序运行时的性能。因此,决定循环展开性能的关键因素是确定合适的展开因子。
针对这一问题的研究可以分为2个方向:一个是使用机器学习预测展开因子;另一个是编译器普遍采用启发式方法自动计算展开因子。文献[7]使用有监督的机器学习来优化循环展开,通过使用2种不同的机器学习算法NN(Near Neighbor)和SVM(Support Vector Machine)来预测循环展开因子。文献[8]基于优化遍之间的交互关系对循环展开的影响,提出了一种介于传统编译器和迭代编译器的轻量型编译器。文献[9]将传统的随机森林模型进行加权和非平衡数据集处理,使用改进后的模型来预测展开因子。文献[10]在TIRAMISU多面体编译器上利用深度神经网络DNN(Deep Neural Network)学习循环展开因子模型,用来自动计算循环展开因子。但是,使用机器学习预测展开因子的开销大于启发式方法的,因为模型的准确性不仅依赖于提取特征的完备性,而且还需要大量样本用于训练,所以编译器普遍采用启发式方法计算展开因子。
文献[11]基于软件流水中的资源限制提出了基于程序特性的展开因子算法,并考虑循环展开对数据预取的影响,同时提出了基于展开的数据预取优化技术,并在ORC(Open Research Compiler)编译器上实现了该算法。文献[12]基于开源编译器Open64-5.0,针对向量程序的向量寄存器压力和代码膨胀等因素,提出了一种自动计算展开因子的算法CUFVL(Compute Unroll Factor for Vectorized Loop),通过结合CUFVL算法和完全展开策略,选取合适的展开因子进行展开优化。文献[13]基于GCC-5.3.0编译器,提出了一种将循环展开优化技术与寄存器压力相结合的方法,用于估算合适的展开因子。文献[14]针对编译时和运行时都无法确定迭代计数的循环(不可计数循环),提出了一种通过快速路径展开不可计数循环的方法,并在Java虚拟机GraalVM上实现了该方法。
影响展开因子的因素众多,有控制流、指令数量、寄存器数量和指令Cache大小等,其中最为重要的2个因素是指令Cache和寄存器资源[6,12]。基于GCC-7.1.0开源编译器,以循环展开问题开展深入的分析与研究,针对指令Cache和寄存器资源对循环展开的影响,本文提出了一种基于指令Cache和寄存器压力的循环展开因子计算方法,旨在计算出更加适合目标架构的循环展开因子。在申威和海光平台上的实验结果表明了该方法的有效性。本文的主要贡献如下:
(1)深入分析了GCC-7.1.0编译器中寄存器传输语言RTL(Register Transfer Language)阶段的循环展开优化技术,着重剖析了计算循环展开因子的代价模型,指出了其不足之处。
(2)针对指令Cache容量和寄存器资源对循环展开的影响,提出了一种更加完善的循环展开因子计算方法,并在GCC-7.1.0编译器中实现了该方法。
2 RTL循环展开
2.1 GCC编译流程

Figure 1 Compilation process of GCC
GCC是GNU项目中应用最广泛的软件之一,它支持多种语言前端和目标平台[15]。GCC将源代码编译成目标平台汇编代码时,通常被划分为高级语言前端、中间代码优化和后端代码生成3个阶段,分别采用不同的中间表示形式:抽象语法树AST(Abstract Syntax Tree)、GIMPLE中间表示和寄存器传输语言RTL。转换流程如图1所示,首先,源程序代码通过词法/语法分析转化为与前端语言相关的抽象语法树AST;然后,通过Gimplify转化为GIMPLE三地址中间表示形式,GIMPLE层的优化是基于SSA(Static Single Assignment)的,目的是实现与前端语言和目标机器无关的优化;接着,Expand过程将GIMPLE表示转化为RTL表示形式,进行一些与目标机器相关的优化;最后根据机器描述文件生成汇编代码。
GCC中的编译过程是由多个优化遍(Pass)组成的,各个遍之间相对独立,完成各自的功能。循环展开优化在GCC-7.1.0编译优化中有2种实现方式:GIMPLE阶段的循环完全展开优化;RTL阶段的循环展开优化。本文主要对RTL阶段的循环展开进行分析与优化。
2.2 循环展开流程
RTL阶段的循环展开是根据循环类型进行展开的。循环展开将循环分为3种类型:编译时可计数循环,迭代次数能在编译时确定的循环;运行时可计数循环,迭代次数能在运行时确定的循环;不可计数循环,迭代次数不可以在编译时和运行时确定的循环[14]。循环展开优化遍的信息如表1所示。优化遍pass_rtl_unroll_loops在loop-init.c中定义,入口函数为unroll_loops(intflags),在loop-unroll.c中实现。要开启循环展开优化,需要使用编译优化选项-funroll-loops或-funroll-all-loops。

Table 1 Information of loop unrolling pass
循环展开优化从内到外遍历循环嵌套,选择满足条件的循环进行展开,其流程如图2所示,主要分为3个阶段:合法性分析、计算循环展开因子和生成循环展开代码。
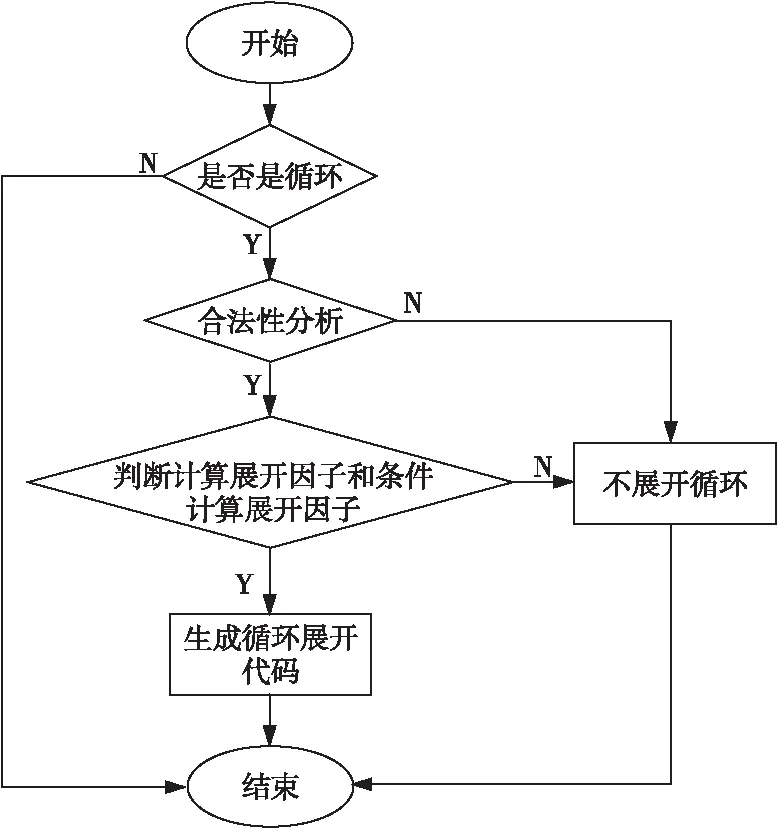
Figure 2 Flow chart of loop unrolling
合法性分析主要是对循环进行检查,判断循环是否满足循环展开的条件,不满足条件则不会进行循环展开。其包括3种类型的检查:(1)检查是否优化了目标代码体积,因为循环展开优化增大了目标代码体积,如果用户要求优化目标代码体积,则不会考虑循环展开;(2)检查循环体是否能进行复制,不能复制的循环体无法进行展开;(3)检查循环是否为最内层循环,非最内层循环不予展开。
在进行展开因子计算之前,首先计算出当前循环的指令数用于估算循环展开因子的上界,然后再根据循环类型分别计算出最佳展开因子。循环的指令数ninsns由函数num_loop_insns()计算得出,此时不考虑循环中的分支情况。对于存在分支的循环,由函数average_num_loop_insns()计算出循环的平均指令数av_ninsns。不同的循环类型需要与之相应的展开因子计算方式。利用decide_unroll_constant_iterations()计算编译时可计数循环的展开因子时,需要开启编译选项-funroll-loops。利用decide_unroll_runtime_iterations()计算运行时可计数循环的展开因子时,需要开启编译选项-funroll-loops。当循环的迭代次数不能在编译时和运行时确定,且循环中的分支数小于或等于1时,调用decide_unroll_stupid()计算不可计数循环的展开因子,需要开启编译选项-funroll-all-loops。当不满足计算展开因子条件(如未开启循环展开编译选项或展开因子上界小于或等于1)时,无法计算出展开因子,则不进行循环展开。
在代码生成阶段,从内到外遍历循环嵌套,根据展开类型和最佳展开因子生成循环展开代码。若循环类型为LPT_UNROLL_CONSTANT,由函数unroll_loop_constant_iterations()生成编译时可计数循环的展开代码。在进行展开代码生成时,如果展开因子能被循环迭代次数整除,就根据展开因子去复制循环体。如果展开因子不能被循环迭代次数整除,就会产生剩余循环,需要将剩余循环完全展开。若展开类型为LPT_UNROLL_RUNTIME,由函数unroll_loop_runtime_iterations()生成运行时可计数循环的展开代码。在生成展开代码时,需要将剩余循环进行剥离,剥离完之后调整循环信息,然后根据展开因子去复制循环体。若展开类型为LPT_UNROLL_STUPID,由函数unroll_loop_stupid()生成不可计数循环的展开代码。代码变换完成后,更新循环信息,调整循环结构和基本块的支配信息。
2.3 代价模型
展开因子的计算是循环展开优化的核心问题,结合循环展开流程对计算展开因子的代价模型进行分析。循环展开的代价模型主要分为2部分:(1)计算展开因子上界nunroll;(2)计算最佳展开因子best_nunroll。
(1)计算展开因子上界。展开因子的上界nunroll通过循环的指令数和编译器中给定的指令数上限进行估算,并且不能超过编译器中给定的展开因子上限,首先由编译器中给定的指令数上限(pmui,pmaui)除以循环本身的指令数(ninsns,av_ninsns)计算出结果,并从中选取最小值作为展开因子上界的初始值nun_pre。然后比较nun_pre和编译器中给定的展开因子上限pmut,选取较小值为展开因子上界nunroll。计算公式如式(1)~式(4)所示:
nun=pmui/ninsns
(1)
nun_av=pmaui/av_ninsns
(2)
nun_pre=nun>nun_av?nun_av:nun
(3)
nunroll=nun_pre>pmut?pmut:nun_pre
(4)
其中,pmui代表GCC编译器中给定的指令数上限PARAM_MAX_UNROLLED_INSNS,默认值为200;pmaui代表GCC编译器中给定的平均指令数上限PARAM_MAX_AVERAGE_UNROLLED_INSNS,默认值为80;pmut代表GCC编译器中给定的最大展开因子上限PARAM_MAX_UNROLL_TIMES,默认值为8。
(2)计算最佳展开因子。编译时可计数循环计算最佳展开因子时,需要对剩余循环完全展开,则循环展开因子是循环体的复制次数加剩余循环迭代次数。从第1步计算的展开因子上界所在的[nunroll-1,2*nunroll+2]内选取最小值做为最佳展开因子best_nunroll。运行时可计数循环和不可计数循环计算最佳展开因子时,调整上一步计算出的展开因子上界nunroll为2的整数次幂,并将其做为最佳展开因子best_nunroll,使展开后的循环满足指令 Cache对齐[8]。
2.4 存在的问题
通过上述分析可以发现,代价模型中展开因子上界nunroll的计算只考虑到了循环指令数的影响,而忽略了寄存器资源等其他限制因素,模型的准确性仍有较大的改进空间。模型参数pmui和pmaui为编译器给定的经验值,参数的调整依赖于编译器开发人员的经验知识,缺乏理论依据,需要结合目标架构进行定制。
3 循环展开优化方法
为了解决2.4节中提到的问题,本节介绍基于指令Cache和寄存器压力的循环展开因子计算方法。针对循环展开代价模型的不足之处,首先根据指令Cache容量对编译器中的指令数上限进行调整;然后考虑寄存器压力对循环展开的限制,对展开因子的上界进行预估;最后确定展开因子上界和最佳的展开因子。
3.1 基于指令Cache容量的架构参数调优
循环展开的有效性取决于可调参数:循环展开最大指令数pmui和平均指令数pmaui,它们是编译器给定的经验值,与循环自身的指令数一起用于估算展开因子上界(式(1)~式(3))。根据机器描述中的指令Cache容量,实现pmui和pmaui的自动调整,以适应目标平台。
现在处理器架构的指令Cache容量一般为32 KB,假定指令字长为4 B,由式(5):

(5)
可知其最多能容纳8 192条指令。而编译器中给定的循环展开指令数pmui和平均指令数pmaui上限值太小,默认为200和80,不适用于现在的处理器架构[8]。由于循环展开次数过少浪费了潜在的优化机会,因此针对目标平台的指令Cache容量和指令字长对循环展开指令数上限进行调整,需要满足以下条件:
pmui=(L1_ICache*50%)/word_size
(6)
pmaui=(L1_ICache*50%)/word_size
(7)
其中,L1_ICache代表目标实验平台的一级指令Cache容量(32 KB,32*1024 B),word_size代表目标实验平台的指令字长(定长32 b,4 B)。
单纯考虑指令Cache对循环展开的影响,可能会导致过度的循环展开,展开之后的循环体对寄存器的需求增大,容易导致寄存器溢出,从而降低程序性能。为避免这一情况,通过考虑寄存器压力对展开因子上界进行预估。
3.2 基于寄存器压力的展开因子上界预估
程序某一点的寄存器压力是指在这一点处活跃的虚拟寄存器数量,这些活跃的虚拟寄存器会被分配到不同的物理寄存器中[16]。虚拟寄存器用于存储程序中的变量或编译器产生的临时变量。
编译器在对程序进行循环展开优化时,会增加额外的临时变量,增大寄存器压力,寄存器压力大于可用的物理寄存器会导致寄存器溢出,就需要将溢出寄存器中的变量值写回到内存中,在需要的时候通过内存加载指令加载到寄存器中,这些额外的访存开销会降低程序性能[17]。因此,针对上述问题,在进行循环展开优化时对循环中的寄存器压力进行评估,并计算出展开因子估计值。
在RTL阶段的循环展开优化中,代码中的寄存器为虚拟寄存器和物理寄存器(处理器要求某些操作数存储在特定的CPU寄存器中),每个寄存器都有特定的数据类型[16]。首先对函数中的寄存器进行活跃分析,计算出每个基本块出口处和入口处的活跃寄存器集(即算法1第1行),根据基本块中指令的def集和use集计算不同类型的最大寄存器压力(即算法1第2行),与该类型可用的物理寄存器数量进行对比,如果寄存器压力大于可用物理寄存器数量,则认为寄存器压力过大。否则,通过寄存器压力和可用物理寄存器数量去计算展开因子估计值(即算法1第3~5行)。评估循环寄存器压力和展开因子估计值的算法伪代码如算法1所示。
算法1计算寄存器压力和展开因子估计值
输入:函数function。
输出:展开因子loop->reg_nunroll。
1.init_anaylise();
2.calculate_bb_reg_pressure(function);
3.foreachloopstarting at innermostdo
4.loop->reg_nunroll←check_register_pressure(loop);
5.endfor
6.returnloop->reg_nunroll
首先由算法1中的init_anaylise()函数进行寄存器活跃分析,计算函数中每个基本块出口处和入口处的活跃寄存器集。活跃分析由式(8)和式(9)所示的后向数据流公式描述[18]:
in[B]=(out[B]-def[B])∪use[B]
(8)
(9)
其中,in[B]表示基本块B入口处的活跃寄存器集;out[B]表示基本块B出口处的活跃寄存器集;def[B]表示基本块B中存在的寄存器集:寄存器中的变量在引用之前已明确地对该变量进行了赋值;use[B]表示基本块B存在的寄存器集:寄存器中的变量在定义之前可能会被引用;S是基本块B的后继基本块。
遍历函数中的基本块,计算出每个基本块的def[B]和use[B]集合;然后再后向遍历函数中的基本块,根据式(8)和式(9)计算出每个in[B]和out[B]集合,其中初始值in[EXIT]=∅,EXIT为函数的退出块。
计算函数中每个基本块的最大寄存器压力,由算法1中的calculate_bb_reg_pressure(function)函数完成。寄存器压力是根据指令def集和use集计算的,指令的def集是指令定义(产生)的寄存器集,而use集是指令使用(消耗)的寄存器集[16]。由curr_live保存在基本块bb出口处的活跃寄存器集out[bb](即算法2第3行),根据不同的寄存器类reg_classes对基本块bb中的最大寄存器压力值curr_regs_pressure[reg_classes]进行初始化(即算法2第4~6行),获取分配curr_live时所需的不同类别的物理寄存器数量,作为当前基本块的最大寄存器压力(即算法2第7~9行)。然后通过对基本块bb中的指令insn进行反向遍历,根据指令的def和use信息计算在各指令处的活跃寄存器集,并更改相应的寄存器压力(即算法2第10~22行)。计算函数基本块最大寄存器压力的伪代码如算法2所示。
算法2计算函数中基本块的最大寄存器压力
输入:函数function。
输出:每个基本块的最大寄存器压力。
1.curr_live←∅;
2.foreachbboffunctiondo
3.curr_live←df_get_live_out(bb);
4.foreachreg_classesdo
5.curr_regs_pressure[reg_classes]← 0;
6.endfor
7.foreachiofcurr_livedo
8.change_pressure(i,true);
9.endfor
10.foreachinsnofbbin backward orderdo
11.foreachdefofinsndo
12.ifcleari(register number ofdef)fromcurr_liveis truethen
13.change_pressure(i,false);
14.endif
15.endfor//def
16.foreachuseofinsndo
17.ifaddi(register number ofuse)intocurr_liveis truethen
18.change_pressure(i,false);
19.endif
20.endfor//use
21.endfor//insn
22.endfor//bb
最后从内到外遍历循环,通过算法1中的check_register_pressure(loop)函数估算循环中的寄存器压力,并用寄存器压力计算展开因子估计值。遍历循环中所有的基本块,根据不同的寄存器类reg_classes,比较在同一基本块中不同寄存器类下的最大寄存器压力curr_regs_pressure[reg_classes]和可用的物理寄存器数量hard_regs_num[reg_classes],以评估寄存器压力是否过大,当满足寄存器压力小于可用物理寄存器数量时,通过寄存器压力和可用物理寄存器数量去计算展开因子估计值集合unroll_list,如式(10)所示:
(10)
从中选取最小值赋给loop->reg_nunroll作为寄存器压力相关的展开因子估计值。计算展开因子估计值的伪代码如算法3所示。
算法3计算展开因子估计值
输入:循环loop。
输出:展开因子reg_nunroll。
1.body←get_loop_body(loop);
2. auto_vec(int,10)unroll_list;
3.fori← 0 toloop->num_nodesdo
4.curr_bb←body[i];
5.ifcurr_bbis NULLthen
6. continue;
7.endif
8.foreachreg_classesdo
9.unroll← 0;
10.ifcurr_regs_pressure[reg_classes]ofcurr_bbis 0then
11. continue;
12.endif
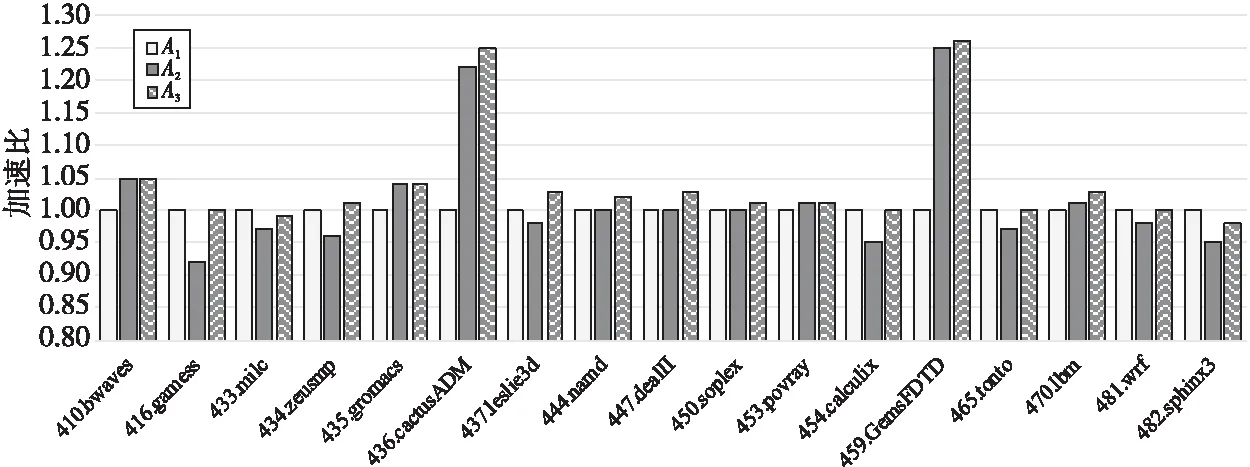
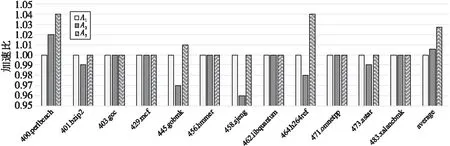
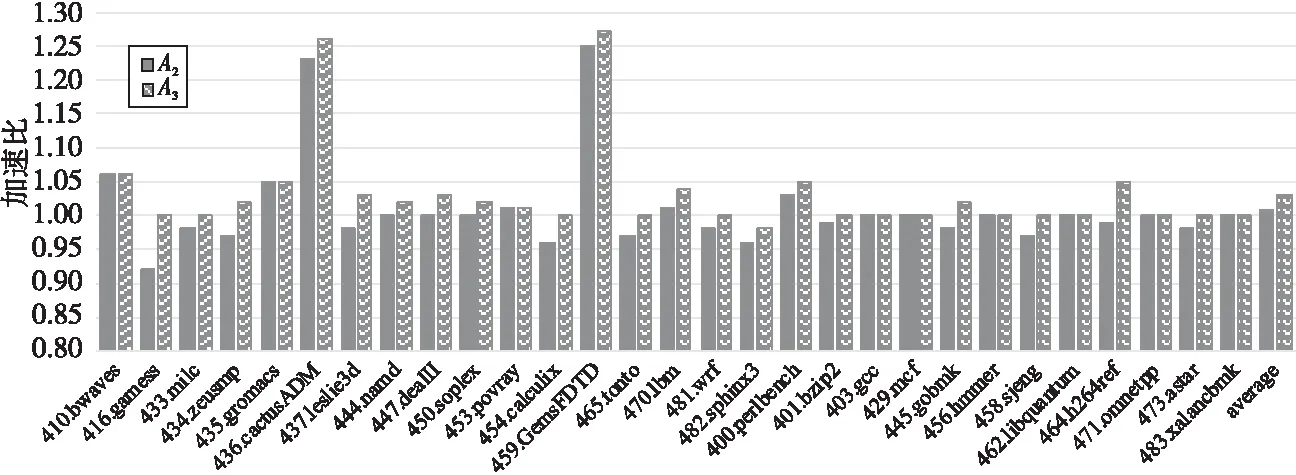
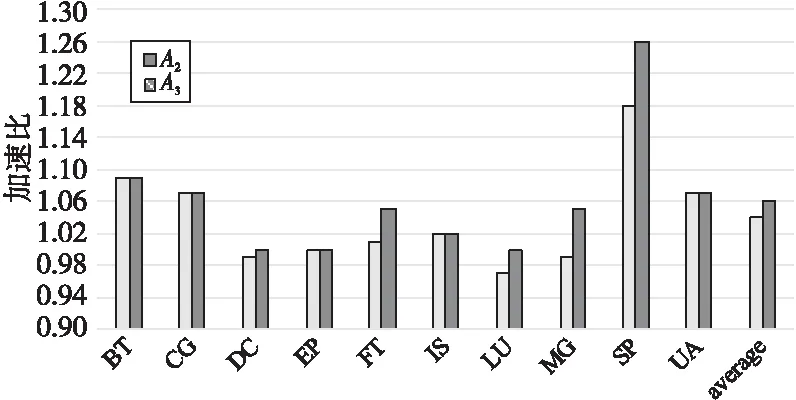
13.ifcurr_regs_pressure[reg_classes]ofcurr_bb 15.unroll_list.safe_push(unroll); 16.endif 17.endfor 18.endfor 19. Select the minimum ofunroll_listand assign it toloop->reg_nunroll; 20.returnloop->reg_nunroll 因为循环展开最大指令数pmui和平均指令数pmaui的限制,导致循环不能展开或展开因子过小,浪费了潜在的优化机会,根据指令Cache容量对循环展开指令数进行调整,会增大展开因子,增加额外的中间变量,导致寄存器压力增大,所以结合指令Cache和寄存器压力这2个因素来共同确定最佳的展开因子,具体要求步骤如下所示: (1)根据指令Cache容量(式(6)和式(7))调整pmui和pmaui,由代价模型中的式(1)~式(4)计算出展开因子上界nunroll。 (2)利用算法1计算当前循环中与寄存器压力有关的展开因子估计值loop->reg_nunroll。 (3)在根据循环类型计算展开因子时,如果loop->reg_nunroll为空,则说明寄存器压力过大,就不进行循环展开;否则比较loop->reg_nunroll与展开因子上界nunroll,选取较小值作为展开因子上界,如式(11)所示: n=n>lr?lr:n (11) 其中,n代表nunroll,lr代表loop->reg_nunroll。 (4)根据展开因子上界nunroll计算最佳展开因子best_nunroll。最佳展开因子best_nunroll需满足式(12): best_nunroll×ninsns≤pmui (12) 在GCC-7.1.0编译器中实现了本文所提出的方法,并分别在申威(Sunway)1621多核处理器和海光(Hygon)C86 7165处理器上对优化前后的编译器进行了实验,表2为实验平台信息。 测试集采用SPEC CPU 2006和NPB-3.3.1标准测试集,SPEC使用ref规模输入,NPB使用B规模输入。编译选项:-O3-static-funroll-loops-funroll-all-loops-fprefetch-loop-arrays。 Table 2 Information of experimental platforms Figure 3 Results of SPEC CPU 2006 FP test sets on Sunway platform Figure 4 Results of SPEC CPU 2006 INT test sets on Sunway platform 为了验证本文优化方法的有效性,使用SPEC和NPB测试集,分别在2种实验平台上进行3组不同版本的测试:基础的循环展开版本A1;基于指令Cache优化的循环展开版本A2;结合指令Cache和寄存器压力的循环展开版本A3。若经过优化后的循环展开未对测试集的运行结果带来不良影响,则表明了该优化方法的正确性。以版本A1下的程序运行时间为基准,计算不同优化版本下的程序加速比,评估优化后的程序性能。某优化版本v下的课题加速比计算公式如式(13)所示: (13) 其中,timev为优化版本v下课题的运行时间,timeA1为基础循环展开版本A1下课题的运行时间。测试集上的平均性能加速比(average)为测试集上所有课题加速比的算术平均值。 SPEC测试结果如图3和图4所示,NPB测试结果如图5所示。实验结果显示,通过综合寄存器压力和指令Cache对循环展开的影响,优化版本A3在所有测试用例上都可以获得不次于版本A2的加速效果;对于绝大多数课题,版本A3可以获得不次于基础优化版本A1的加速效果;部分课题取得了显著的性能提升,个别课题出现了少许性能下降。整体上看,版本A3优化在SPEC和NPB上的平均性能分别提升了2.7%和5.4%。接下来对有性能提升和出现性能下降的课题进行分析。 对SPEC中性能提升效果较好的课题459.GemsFDTD和436.cactusADM的热点循环进行分析。在进行原始循环展开优化时,由于编译器给定的指令数的限制太小,2个循环的展开因子均为0,未进行循环展开。通过指令Cache调整指令数限制,计算出展开因子均为8(达到编译器给定的最大展开因子限制)。循环展开不但降低了循环开销,同时也暴露了相邻2次迭代间的冗余访存,为后续的冗余消除提供了机会。版本A2优化后的459.GemsFDTD和436.cactusADM程序性能与版本A1优化后的相比,分别提升了25%和22%。考虑展开次数过多,增加了额外的临时变量,会导致寄存器压力过大的情况,结合指令Cache和寄存器压力完善展开因子计算(版本A3),此时展开因子为4和2,性能较版本A1的提升了26%和25%。优化版本A2和A3在SP上也分别有17%和25%的性能提升。 Figure 5 Results of NPB-3.3.1 test sets on Sunway platform 使用版本A3时其他课题如410.bwaves、435.gromacs、437.leslie3d、447.dealII、470.lbm、400.perlbench、464.h264ref、BT、CG、FT、MG和UA等,分别相比使用版本A1时有3%~8%的加速效果。 Figure 6 Results of SPEC CPU 2006 test sets on Hygon platform 但是,本文方法并非对所有程序都有正面效果,如482.sphinx3的热点循环为2层嵌套for循环,耗时比重占整个课题的36%,使用版本A1优化时的展开因子为4,使用版本A2优化时的展开因子为8。由于循环体含有较多的中间变量,展开因子增大后,出现了较多的寄存器溢出,程序性能下降了5%。考虑寄存器压力因素(版本A3)进行优化,代价模型认为寄存器压力过大而拒绝展开,丢失了程序潜在的优化机会,程序性能下降了2%,但性能下降幅度较小。从SPEC和NPB测试集上的测试结果来看,结合指令Cache和寄存器压力的循环展开方法能够有效提升程序性能。 海光平台上的SPEC和NPB测试结果分别如图6和图7所示。版本A3优化下的平均性能分别比版本A1优化的提升3.1%和6.1%。 Figure 7 Results of NPB-3.3.1 test sets on Hygon platform 由于编译器给定了指令数限制,导致选取的展开因子较小或不能进行循环展开。针对这种情况,通过指令Cache调整循环展开指令数限制(版本A2优化),增加循环的优化机会,其中性能提升较好的课题有459.GemsFDTD、436.cactusADM和SP,其展开因子由原本的0,0和2,均增加到了8,较原始循环展开优化分别提升了 25%,23%和18%。考虑寄存器压力对循环展开的影响,结合指令Cache和寄存器压力对展开因子计算进行完善(版本A3优化),展开因子分别为4,2和4,性能较版本A2的进一步提升了2%,3%和8%。 在版本A3优化下的其他课题如410.bwaves、435.gromacs、437.leslie3d、447.dealII、470.lbm、400.perlbench、464.h264ref、BT、CG、FT、MG和UA等,较原始循环展开优化有3%~9%的性能提升。 综合Sunway平台和Hygon平台上的测试结果来看,结合指令Cache和寄存器压力的循环展开优化方法能够针对目标架构自动计算出合适的展开因子,提升了程序性能,但仍有需要改进之处。在当前的实现中,代价模型对寄存器溢出是零容忍的,即只要存在寄存器溢出就拒绝展开。这种对寄存器压力的评估和使用方式是过于简单和严苛的,可能使程序丢失潜在的优化机会,导致性能下降,需要结合优化之间的相互作用,做出改进。 本文在对GCC中RTL阶段的循环展开优化技术进行深入分析后,指出了现有代价模型的不足之处。结合处理器架构的指令Cache容量和寄存器资源对循环展开的影响,提出了一种基于指令Cache和寄存器压力的循环展开因子计算方法,并在GCC-7.1.0编译器中实现了该方法。申威和海光平台上的实验结果显示,相较于目前GCC中存在的其它展开因子计算方法,该方法能够自动计算出适合目标架构的循环展开因子,提升程序性能。2种平台上在SPEC CPU 2006测试集上平均性能分别提升了2.7%和3.1%,在NPB-3.3.1测试集上的平均性能分别提升了5.4%和6.1%。 由于各个优化遍之间的交互也会对程序性能造成影响,因此下一步的工作是考虑其他优化遍对循环展开的影响,完善循环展开优化。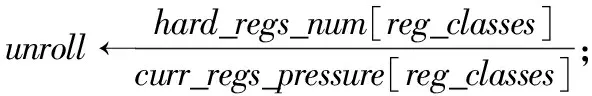
3.3 确定最佳展开因子
4 实验测试与分析
4.1 实验环境

4.2 实验方法
4.3 Sunway平台测试

4.4 Hygon平台测试
4.5 总结
5 结束语
猜你喜欢
有色金属设计(2022年4期)2022-02-04
计算机应用(2020年5期)2020-06-07
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
电子技术与软件工程(2018年1期)2018-03-22
科技传播(2015年20期)2015-03-25
信息安全研究(2015年3期)2015-02-28
西安航空学院学报(2014年5期)2014-07-13
汽车零部件(2014年2期)2014-03-11
组合机床与自动化加工技术(2014年10期)2014-03-01
