
改进Stacking集成学习的指纹识别算法*
2022-12-22 11:31罗海波
计算机工程与科学 2022年12期
苏 赋,罗海波
(西南石油大学电气信息学院,四川 成都 610500)
1 引言
当今社会中,生物识别技术在人们日常生活中应用日益广泛,而指纹识别在生物识别市场中所占份额依然最多[1]。指纹是手指表面脊线和谷线的纹理特征,能增加手指与物体接触的摩擦力,从而更容易抓取物件,特征点是指纹最重要的特征,包括端点和交叉点。手指指纹面积较小,指纹采集设备仅需采集手指表面的一部分就可以获得所需信息,所以指纹采集设备大多小巧便携。指纹特征还具有普遍性、唯一性及不变性等生物识别所必需的特性,以上优点使指纹识别作为一种重要的身份认证技术得到了广泛的应用。常见的指纹识别系统有门禁系统、考勤系统及智能手机的指纹识别系统等。随着指纹识别系统越来越多地运用于各种场合,提升指纹识别算法精度仍具有重要意义。
传统的指纹识别方法通过算法提取出特征点,再比对特征点。若相似度高于阈值,则指纹匹配成功。早期的指纹特征提取方法有Maio等[2]提出的追踪指纹原始灰度图中的脊线的方法,Jiang等[3,4]提出的自适应步长法和局部图像分类法等。尺度不变特征变换SIFT(Scale Invariant Feature Transform)是一种基于尺度空间的特征描述算子,它对图像缩放、旋转及仿射变换都有保持不变的特性,因此也有学者[5]尝试提取指纹SIFT特征进行指纹识别。如Park等[6]通过提取指纹的SIFT特征点,利用SIFT算子对特征点周围的纹理信息进行指纹匹配。Awad等[7]评估了一种利用SIFT特征缩短指纹识别时间的算法匹配分数矩阵MSM(Matching Score Matrix)。Zhong等[8]提出了一种基于SIFT和LSH局部敏感哈希(Locality Sensitive Hashing)算法的快速指纹分类检索与识别方法。Aravindan等[9]提出了一种基于小波分解图像的SIFT指纹识别方法。
除传统方法外,有学者尝试将机器学习运用到指纹识别中。Chen等[10]提出了一种基于改进支持向量机的区域信息融合方法并用于指纹识别。Hsieh等[11]将多目标优化的思想融入支持向量机中,提出了一种新的指纹识别算法。Noor等[12]尝试使用不同分类器对指纹进行分类,包括决策树、线性判别分析、中高斯支持向量机MG-SVM(Medium Gaussian Support Vector Machine)、k近邻k-NN(k-Nearest Neighbor)、袋装树集成分类器,其中中高斯支持向量机验证率在所有分类器中最高。
近年来,深度学习在图像分类任务上取得了良好的效果,越来越多的学者开始将深度学习应用到指纹识别中。张永泉等[13]建立了一个轻量级的深度神经网络,并分别利用二值化特征模式和三元组损失(Triplet Loss)优化模型,进行指纹匹配。Yuan等[14]设计了一种学习率自适应的卷积神经网络,并且采用图像尺度均衡的方法检测指纹活性。Zeng等[15]采用残差网络ResNet(Residual Networks)[16]及交叉熵函数和对比度函数来训练网络,同时还采用了权值衰减的正则化方法和k均值算法来识别指纹。上述方法将不同的卷积神经网络应用到了指纹识别中来,相比传统方法,取得了更好的表现。这些方法大多只使用了某一种卷积神经网络,改变其中某些参数,或者引入其他方法到网络中,可以提升网络的性能。但是,单一网络受本身结构的制约,尽管改变了参数,但其性能仍难以突破自身上限。
针对这一问题,本文提出了一种改进Stacking的集成学习[17]算法,该算法通过Stacking集成学习,将DenseNet网络[18]与改进的AlexNet网络[19]进行融合,以获得比单一网络模型更优的网络性能。首先,针对AlexNet网络特征传播能力不足的问题,引入深度可分离卷积(Depthwise Separable Convolution)[20];针对AlexNet网络获取全局信息的能力不高的问题,引入空间金字塔池化(Spatial Pyramid Pooling)[21];针对AlexNet网络泛化能力不高的问题,引入全局平均池化(Global Average Pooling)[22],替代前2个全连接层;采用批归一化(Batch Normalization)[23]取代局部响应归一化(Local Response Normalization),解决AlexNet网络中间层数据分布改变的问题。改进后的AlexNet网络识别准确率有了大幅提高,将改进后的AlexNet网络称为GS-AlexNet。DenseNet网络能够缓解梯度消失,加强特征传播,鼓励特征重用,增强了指纹特征提取能力。使用Stacking集成学习,将DenseNet网络与GS-AlexNet网络结合起来,充分利用上述2种网络的优点,获得了比单一网络模型更优的性能。对同一基学习器训练得到的不同模型,根据模型的识别准确率对测试集预测结果赋权,改进了Stacking集成学习算法。采用随机梯度下降分类器(Stochastic Gradient Descent Classifier)[24]作为元分类器,对加权预测结果进行分类,最终输出整个模型对指纹的预测结果。
2 卷积神经网络模型
卷积神经网络具有强大的特征表达和图像分析处理能力,因此本文选择DenseNet和改进的AlexNet 2种卷积神经网络来提取图像特征,获取预测结果。下面对AlexNet及其改进版本与DenseNet网络进行详细的介绍。
2.1 AlexNet网络
1989年,卷积神经网络问世,但在此后很长一段时间内,卷积神经网络只在手写数字识别等小规模图像识别问题上取得了较好的成绩,在大规模图像的识别问题上则效果不佳,其中原因包括算法有待提升,以及硬件对计算能力的限制。直到2012年,AlexNet的出现改变了这一切。AlexNet采用了许多方法来提升网络性能,在ImageNet数据集上取得的效果超越了当时其它所有网络。
AlexNet网络模型结构如图1所示,它包括5个卷积层、2个池化层及3个全连接层,总体结构较为简单,训练所花费的时间相对残差网络等结构复杂的网络要短。

Figure 1 Structure of AlexNet
2.2 GS-AlexNet
GS-AlexNet以AlexNet网络为基础网络结构,通过添加深度可分离卷积、空间金字塔池化等结构来提升网络性能,其网络结构如图2所示。

Figure 2 Structure of GS-AlexNet
(1)在第3个3×3卷积层之后加入2个3×3深度可分离卷积层,后跟1个最大池化层,然后再与旁路第3个3×3卷积层之后的1×1卷积层的结果相加。深度可分离卷积相比传统卷积参数量更少,计算速度更快。采用如图2所示的结构,能够使特征传播得到加强,有助于提高识别准确率。
(2)增加空间金字塔池化层。空间金字塔池化最初被应用于目标检测中,通过搜索算法产生的候选区域可能具有不同的尺寸,直接剪裁或者更改图像尺寸会使图像扭曲变形或失去部分重要信息,使目标检测的精度受到限制。而空间金字塔池化对任意尺寸的特征图都能输出固定长度的向量,使得卷积神经网络不再需要严格要求输入图像的尺寸。同时,空间金字塔池化通过将特征层划分为不同的区域,各区域分别进行平均池化,使不同区域的上下文信息聚合,提高了获取全局信息的能力。
(3)将1个全局平均池化层添加到空间金字塔池化层后,以替代前2个全连接层。对于分类任务来说,最后一个卷积层通常连接到全连接层中,然后再连接到Softmax逻辑回归层。这种方式能够将卷积结构与传统的神经网络分类器连接起来,即用卷积层提取特征,并以传统方式对特征分类。然而,使用全连接层容易发生过拟合,降低网络的泛化能力。因此,本文采用全局平均池化替代传统的全连接层。全局平均池化层对最后一个卷积层的每个对应类别都生成一个特征图,然后取每个特征图的平均值,通过强制特征映射和类别之间的对应,全局平均池化更适合卷积结构,使网络的泛化能力得到了提高。
(4)去除前2个最大池化层之前的局部响应归一化,改为在每个卷积层以及深度可分离卷积之后添加一个批归一化层。批归一化不仅能够加快模型的收敛速度,还可以起到正则化的作用,提高模型的训练精度。虽然通常输入数据都被进行过归一化处理,但经过网络训练及迭代后,数据分布会被改变。批归一化处理能够在网络中任意一层进行,可以有效地解决训练过程中,中间层数据分布改变的情况,使数据分布由始至终控制在一个较小的范围内。
2.3 DenseNet网络
AlexNet之后出现的许多网络都尝试通过加深网络来提升网络性能,Simonyan等[25]通过对3×3卷积核和2×2池化层的堆叠,构建了16~19层的卷积神经网络,多于AlexNet的8层,但若再加深网络则可能面临梯度消失和梯度爆炸的问题。Highway Networks[26]是首个网络深度达到100层的卷积神经网络,而且利用门单元形成的旁路,研究人员可以很轻松地构建超过100层的网络,且网络性能依然十分优秀。ResNet网络与Highway Network有相似之处,二者都采用了旁路连接的方式使特征传播得到加强。但是,Highway Network中的门单元可能会关闭,而ResNet中的连接不会关闭,残差模块产生的特征始终会向前传递。
DenseNet虽然借鉴了ResNet的旁路连接方式,但其主要研究目的不是通过加深网络来提高网络的性能,而是探索特征重用对网络的影响,以获得训练速度快且参数对输入图像拟合程度高的网络。对于卷积神经网络而言,输入与输出临近的层间如果包含更短的连接,会使网络更深、参数对输入图像拟合程度更高,并能提高训练效率。基于这种思想,DenseNet的设计人员采用了将每一层与其他所有层以前馈方式连接起来的结构,通过特征复用加强了特征的传播,同时缓解了梯度消失,网络性能由此得到提升,图3展示了一个Dense模块的结构。

Figure 3 A 4-layer dense block with a growth rate of 4
Dense模块使每一层与后面所有层相连,增强了信息流动性。换言之,第n层能够得到前面所有层的特征图,将x0,…,xn-1作为输入,则:
xn=Hn([x0,x1,…,xn-1])
(1)
其中,[x0,…,xn-1]表示从0到n-1层的特征图的连接,其使特征图组合起来的方式是连接而不是如ResNet中的加法,这种方式能够使计算量减少,可大大提升效率。Hn(·)是一个混合函数,其包括正则化操作、线性整流和1个3×3的卷积。
3 Stacking集成学习算法
要将2个以上的卷积神经网络模型结合起来,需要使用一种模型融合算法,把不同的卷积神经网络置于同一系统之中。本文采用Stacking这种2层堆叠的模型融合算法,并通过对预测结果赋权改进算法。
3.1 Stacking集成学习模型
Stacking集成学习的主要思想是将不同模型结合起来,充分利用它们各自不同的优点,以获得最好的效果。首先将原始数据集划分为若干子数据集,此过程运用了K折交叉验证的思想,避免模型过拟合;然后将子数据集输入不同的基学习器,基学习器输出预测结果;再将各基学习器输出的预测结果结合起来输入元学习器;最后输出整个模型的预测结果。Stacking集成学习基本结构如图4所示。

Figure 4 Structure of stacking ensemble learning
原始数据的划分可以分为2步,首先将原始数据集划分为训练集和测试集,再运用K折交叉验证算法将训练集中的数据划分为训练数据和测试数据。如当K=6时,将训练集中的数据分为6份,其中1份作为测试数据,剩余5份作为训练数据来训练基学习器,之后再挑选另1份数据作为测试数据,其余数据作为训练数据。重复6次后,得到6个对测试数据的预测结果,将其结合起来作为元学习器的训练数据。如果有2个以上的基学习器,则其余基学习器也按照如上步骤来训练,再将所有基学习器的预测结果结合起来作为元学习器的训练数据。
基学习器模型经过训练集的训练数据和测试数据训练后得到训练好的模型,用该模型预测测试集中的数据,将得到的预测结果结合起来作为元学习器的测试数据,最终由元学习器输出整个模型的预测结果。
3.2 CW-Stacking
为了进一步提升Stacking集成学习算法的性能,本文采用DenseNet网络和GS-AlexNet网络2种卷积神经网络作为Stacking集成学习的基学习器,同时将基学习器预测测试集的结果赋权相加,得到的结果再输入元学习器。
在指纹数据集上的实验显示,DenseNet网络和GS-AlexNet均能取得较高的识别准确率。但是,同一网络训练得到的K个模型的效果不尽相同,对预测结果取均值无法得到更好的结果。对测试集预测结果赋权相加,为效果好的模型赋大的权值,为效果不好的模型赋较小的权值,能使性能好的模型对之后的训练影响更大,性能差的模型对后续训练的影响变小,从而改善模型整体的性能。本文中元学习器均采用随机梯度下降分类器,将本文使用的Stacking算法称为CW-Stacking,其流程如图5所示。训练集中的训练数据用来训练DenseNet和GS-AlexNet模型,训练集中的测试数据输入训练好的模型输出预测结果。预测结果连接起来作为训练数据,输入随机梯度下降分类器中。
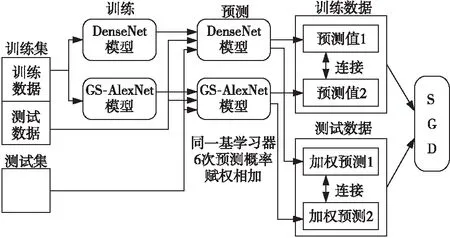
Figure 5 CW-Stacking algorithm
赋权的第1步要将测试集数据输入训练好的模型,输出的是模型正确预测测试集输入数据的概率a。如测试集数据总共可分为C类,则卷积神经网络可以针对每幅图像或其他类型数据输出C个概率值,代表该数据为某一类的概率,C个概率值之和为1。从C个概率值中取出1个正确表示该数据类型的概率,就得到所需要的概率值a了。一幅图像输入卷积神经网络后,获取概率值a的大致流程如图6所示。
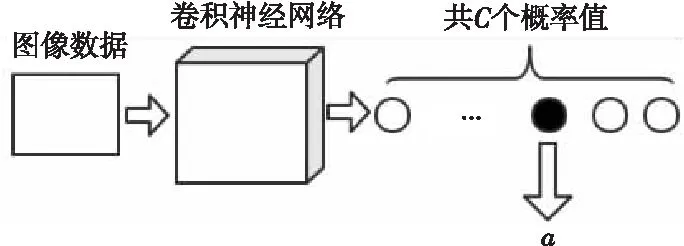
Figure 6 Process of obtaining probability value a
如果有N个异质基学习器,每个基学习器经K次训练共得到N×K个模型,也得到N×K组概率值。一个基学习器输出的概率除以同一同质基学习器训练得到的K个模型输出的概率值之和,可以得到权重w。第n(1≤n≤k)个同质基学习器权重计算公式如式(2)所示:
wn=an/(a1+…+aK)
(2)
再以按权重分配的方式,将同一基学习器得到的K组预测结果结合起来,如式(3)所示:
P=w1p1+w2p2+…+wKpK
(3)
其中,p1,p2,…,pK为某一基学习器输出的整组预测结果。然后将DenseNet和GS-AlexNet网络输出的2组加权预测结果连接起来作为测试数据输入随机梯度下降分类器中,最终得到整个模型的预测结果。
4 实验及结果分析
4.1 数据集介绍
本文所采用的数据集来自山东大学公开的指纹数据集——多传感器指纹数据库(Multi-Sensor Fingerprint Database),指纹图像如图7所示。

Figure 7 Fingerprint images collected by five kinds of sensors
本数据集包括5种不同传感器采集的指纹,这5种传感器分别为AES2501刷卡指纹扫描仪、FPR620光学指纹扫描仪、FT-2BU电容式指纹扫描仪、URU4000光学指纹扫描仪和ZY202-B光学指纹扫描仪。采集指纹时,使用上述5种传感器分别采集左手和右手的食指、中指、无名指共6个手指的指纹,每个手指的指纹采集8次,共采集106人的指纹。所以,该数据集中共有6×5×8×106=25440幅指纹图像。5种不同的采集设备导致多传感器指纹数据库中指纹图像具有不同的尺寸,表1中展示了各指纹采集设备采集到的指纹的指标。
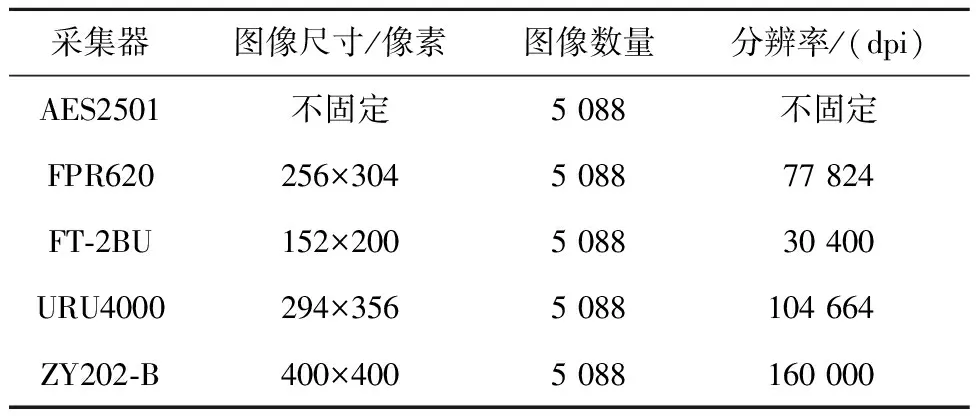
Table 1 Indexes of fingerprint collected by each sensor
由于不同的指纹采集设备采集到的指纹图像尺寸各不相同,实验中将所有的指纹图像尺寸统一转化为224×224,得到25 440幅224×224的指纹图像。本文将其中3/4的指纹图像划分为训练集,用作基学习器模型的训练,得到的预测结果作为元学习器的训练数据;剩余1/4划分为测试集,用基学习器训练后得到的模型来预测测试集指纹图像,得到的预测结果作为元学习器的测试数据。指纹数据集划分如表2所示。

Table 2 Fingerprint data set partition
由于传感器本身对指纹的提取能力有限,再加上被采集的手指上可能有污渍或者存在脱皮的现象,导致指纹图像中存在一些干扰信息,会对后续指纹识别造成影响,所以有必要进行指纹图像预处理。本文主要处理步骤如下:
(1)指纹图像归一化;
(2)指纹纹路增强;
(3)去除空洞和毛刺;
(4)图像细化。
通常指纹采集设备采集到的指纹都具有较大的灰度值差距,导致强烈的明暗效果,进行归一化处理之后,指纹图像灰度均值和灰度方差均相同,图像间灰度场强显著减少。将指纹图像增强,通过计算得到指纹的脊线方向,并对图像进行二值化,进一步降低噪声的影响。去除指纹中的空洞和毛刺,消除指纹粘连及断裂的影响。指纹的粗细对识别也有干扰,所以最后一步进行图像细化,去除指纹粗细对指纹识别的影响。经过上述步骤处理后得到的指纹图像如图8所示。

Figure 8 Processed fingerprint image
4.2 实验结果分析
本文实验涉及卷积神经网络的训练和测试,还包括运用Stacking集成学习算法结合不同的卷积神经网络模型的实验,以及对测试集预测结果赋权的实验。实验的硬件环境为笔记本电脑和服务器,其中服务器配置为英特尔第八代i5 CPU,频率为2.80 GHz,内存为16 GB,显卡为NVIDIA GeForce RTX 2080Ti。实验的软件平台为PyCharm,编程语言为Python 3.6,深度学习框架为TensorFlow和Keras。将卷积神经网络各类参数尽量设置得一致,损失函数选择Softmax Loss,优化器选择Adam。Batch设置为64,即每次训练从样本中取64幅图像。网络进行200次迭代,准确率取最后5次均值。使用ReduceLROnPlateau函数,根据损失值自适应调整学习率。
第1组实验是为了验证改进AlexNet的性能提升程度。对指纹数据集预处理之后,按训练数据与测试数据3∶1来划分,实验得到的准确率曲线如图9所示,损失值曲线如图10所示。其中图9和图10的横坐标表示迭代步数,图9的纵坐标表示指纹识别准确率,图10的纵坐标表示损失值。此外,表3展示了网络准确率曲线和损失值曲线收敛之后各网络的损失值及准确率。

Figure 9 Accuracy curves

Figure 10 Loss curves
本文选择了AlexNet、DenseNet和Im-AlexNet[27]作为改进AlexNet(也就是GS-AlexNet)的对比模型。从图9和图10可以看出,GS-AlexNet的收敛相对较慢,约迭代75步左右收敛,而Im-AlexNet与DenseNet则收敛得稍快一些。但是,GS-AlexNet最终获得的识别准确率是最高的,损失值是最低的,说明通过在AlexNet中加入深度可分离卷积、金字塔池化、全局平均池化及批归一化的改进是十分有效的。从图中还可以看出,得益于ReduceLROnPlateau的使用,4种卷积神经网络的识别准确率和损失值最终都收敛到了一个较小的范围内,十分稳定,并且均在迭代约100步以内就能收敛。
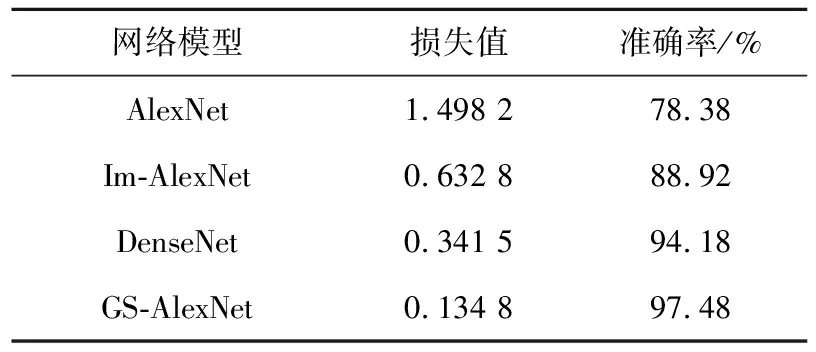
Table 3 Experimental results of different convolutional neural networks
第2组实验引入Stacking集成学习算法,分别尝试将DenseNet与AlexNet、Im-AlexNet、GS-AlexNet结合以研究性能不同的基学习器算法对Stacking集成学习算法最终准确率的影响。实验内容是将实验数据中的训练集采用K折交叉验证方法划分为6份,将其中1份作为测试数据,其余5份作为训练数据,选择DenseNet卷积神经网络来进行训练。然后选择另1份数据作为测试数据,重复上述步骤共6次,得到6个训练数据的预测结果,置于同一数组中。再将训练好的模型用来预测测试集数据得到6个预测结果,并将预测结果取均值。然后再选用AlexNet、Im-AlexNet与GS-AlexNet中一种卷积神经网络作为另一个基学习器,重复上述步骤,将2种卷积神经网络的预测结果结合输入元学习器随机梯度下降分类器中,得到整个模型的预测结果。本实验的实验结果如表4所示,从实验结果可以看出,3种不同的卷积神经网络与DenseNet结合后,原本识别准确率最高的GS-AlexNet的识别准确率依然最高,即97.64%,原本识别准确率最低的AlexNet的识别准确率还是最低,即94.73%,并且3组实验采用Stacking后准确率都高于任一一卷积神经网络。这说明在实验采用的数据集上,采用Stacking方法融合后均能利用2种卷积神经网络各自的优点,取得更高的准确率,而本身性能较优的网络,融合后会取得更好的效果。因此,之前对AlexNet的改进是具有重要意义的。

Table 4 Experimental results of combining different convolutional neural networks
第3组实验将3种不同的卷积神经网络分别与DenseNet结合,并在使用训练好的模型预测测试集数据时,将预测结果以赋权的方式相加,以验证改进的Stacking集成学习算法的优越性,最终得到的实验结果如表5所示。从表5可以看出,在所采用的数据集上,对3种不同的卷积神经网络组合,改进的Stacking集成学习算法都能够取得更好的效果。其中,DenseNet与GS-AlexNet结合的最终准确率达到了98.43%,与单独使用任一卷积神经网络模型相比至少提升了0.95%,与将测试集预测结果取均值时相比提升了0.79%。表明对同一基学习器训练所得各模型预测结果按对指纹正确预测的概率赋权,能够提升好的模型对后续分类的影响,降低差的模型的影响,从而得到比单纯取均值时更好的效果。
Xception是He等[21]提出的一种卷积神经网络,它是完全基于深度可分离卷积的网络结构。Xception网络结构中包含36个卷积层,前2个为普通卷积层,其余为深度可分离卷积。36个卷积层构成14个模块,除第一个和最后一个模块,其余模块周围均使用了残差连接方法,以加强特征传播。NASNet[28]是谷歌AutoML项目产出的模型,该项目致力于让计算机设计出性能可与人类专家设计的神经网络相媲美的神经网络。通过在CIFAR-10数据集上寻找最佳的模块堆叠组合方式,最终获得NASNet。将其应用于ImageNet上,得到的Top-1准确率比人类发明的最好的神经网络高1.2%。在多传感器指纹数据库上,Xception算法相对本文算法准确率降低5.82%,NASNet相对本文算法准确率降低5.19%,说明本文算法相对单一卷积神经网络方法具有较大优势。PCA-Stacking算法[29]对基学习器输出的预测结果进行PCA降维后再输入元学习器中,该算法能够利用样本的统计特性,提升分类精度。使用DenseNet与GS-AlexNet作为基学习器,本文CW-Stacking算法与PCA-Stacking相比准确率提升了0.71%,充分说明了本文算法的优越性。
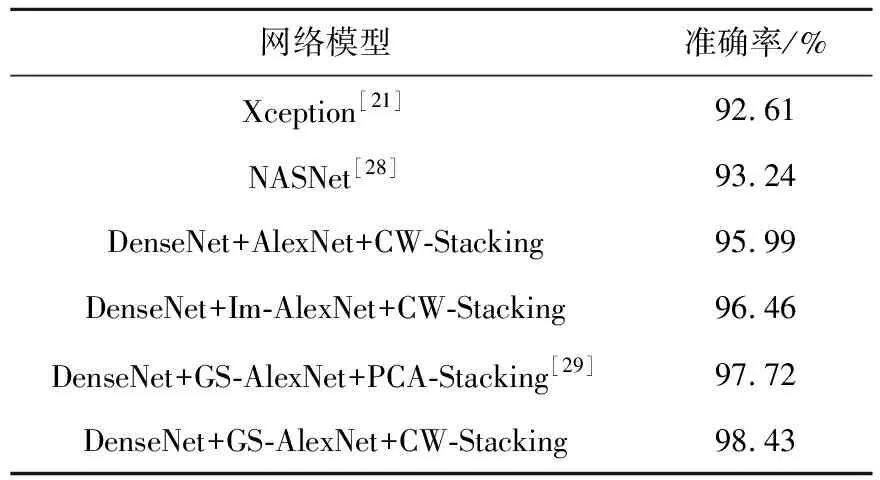
Table 5 Experimental results of improved Stacking ensemble learning algorithm
实验结果表明,本文通过指纹图像预处理、改进AlexNet卷积神经网络,融合本文中性能最优的2种卷积神经网络模型,以及将测试集预测结果赋权,获得了较高的指纹识别准确率,相比传统的单一卷积神经网络有较大提升。
5 结束语
本文针对传统的单一卷积神经网络指纹识别算法性能无法突破网络本身结构限制的问题,提出了一种改进Stacking集成学习的指纹识别算法。首先对指纹图像进行预处理,提高指纹图像质量,并且采用深度可分离卷积、金字塔池化、全局平均池化及批归一化对AlexNet进行改进。然后采用Stacking集成学习将模型融合进行指纹识别,并将改进的AlexNet卷积神经网络引入Stacking模型中,把DenseNet和GS-AlexNet 2种卷积神经网络作为Stacking模型的基学习器,另尝试进一步改进Stacking集成学习算法,将测试集预测结果赋权相加,最后采用随机梯度下降分类器对所有基学习器输出预测结果分类。该算法在山东大学公开的指纹数据集——多传感器指纹数据库上进行实验,获得了98.43%的识别准确率。实验结果表明,本文对AlexNet的改进使其性能得到了显著提高,采用Stacking集成学习算法将不同的卷积神经网络结合起来能够得到比单一卷积神经网络更好的识别结果,对Stacking集成学习算法进行改进,对测试集预测结果赋权,可以使识别效果再次提升。本文采用的是随机梯度下降分类器作为元学习器,进一步的研究方向是对元学习器进行改进。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
信息安全研究(2016年4期)2016-12-01
发明与创新·大科技(2016年5期)2016-05-17
自动化学报(2016年8期)2016-04-16
