
非独立同分布文本情感表示学习方法
2022-12-22 11:46郭红钰郑扬飞刘玉龙李山海吴艳雄
计算机工程与应用 2022年24期
李 倩,郭红钰,郑扬飞,刘玉龙,李山海,吴艳雄
1.中国电子科技集团有限公司 第十五研究所,北京 100083
2.中华全国工商业联合会 信息中心,北京 100035
洞察文本中的情感极性(例如,正面情感、负面情感、中立情感等)并嵌入到文本的向量化表示中是情感分析的一项关键任务[1]。研究表明,有监督的机器学习方法可以有效捕获文本中的情感特征[2]。相比于人工提取的文本情感特征,基于深度表示学习构建的文本特征可以显著提高情感分析的准确性[3]。
然而,面向情感分析的文本表示学习方法普遍忽视了文本中的非独立同分布特点,进而不能对含有非独立同分布特点的文本进行有效的表示。通常,文本中的词与词之间、句子与句子之间存在着相互耦合的关系(非独立特点),相同词或者句子在不同的语境下也可能有着不同的含义(非同分布特点)。文本的非独立特点和非同分布特点共同构成了文本的非独立同分布特点。图1展示了一段文本中的非独立同分布特点及其带来的挑战。在词层面,单个词语与其近邻的词语之间存在着耦合关系。例如,单词“not”和“sure”是相互耦合的。这种耦合关系构成了句子中最基本的情感单元。句子中的情感单元再进一步直接耦合(例如,“not sure”和“why this”)或间接耦合(例如,“best parts”和“bread and the rice”)决定了一个句子的情感极性。此外,一个词语可能在不同的语境和位置具有不同的含义。例如“dark”一词在图1的示例中具有负面的情感,但如果其用于描绘颜色则具有中性的情感。在句子层面,具有与词层面类似的非独立同分布特点。一个句子和它近邻的句子相互作用(例如,图1示例中的第一句和第二句),这些相互作用的句子又进一步耦合在一起(例如,图1示例中的间接耦合关系)决定了文本的情感极性。除此之外,一个句子在不同的位置也可能具有不同的情感极性。例如,图1示例中的最后一句话,当考虑第一句和第二句话时,其具有负面的情感;但仅考虑这句话本身时,其展现出正面的情感。对于非独立同分布文本而言,非独立同分布特点可能层次化的存在于词层面、句子层面、段落层面,深度影响着文本的情感极性,并且难以被有效表示。
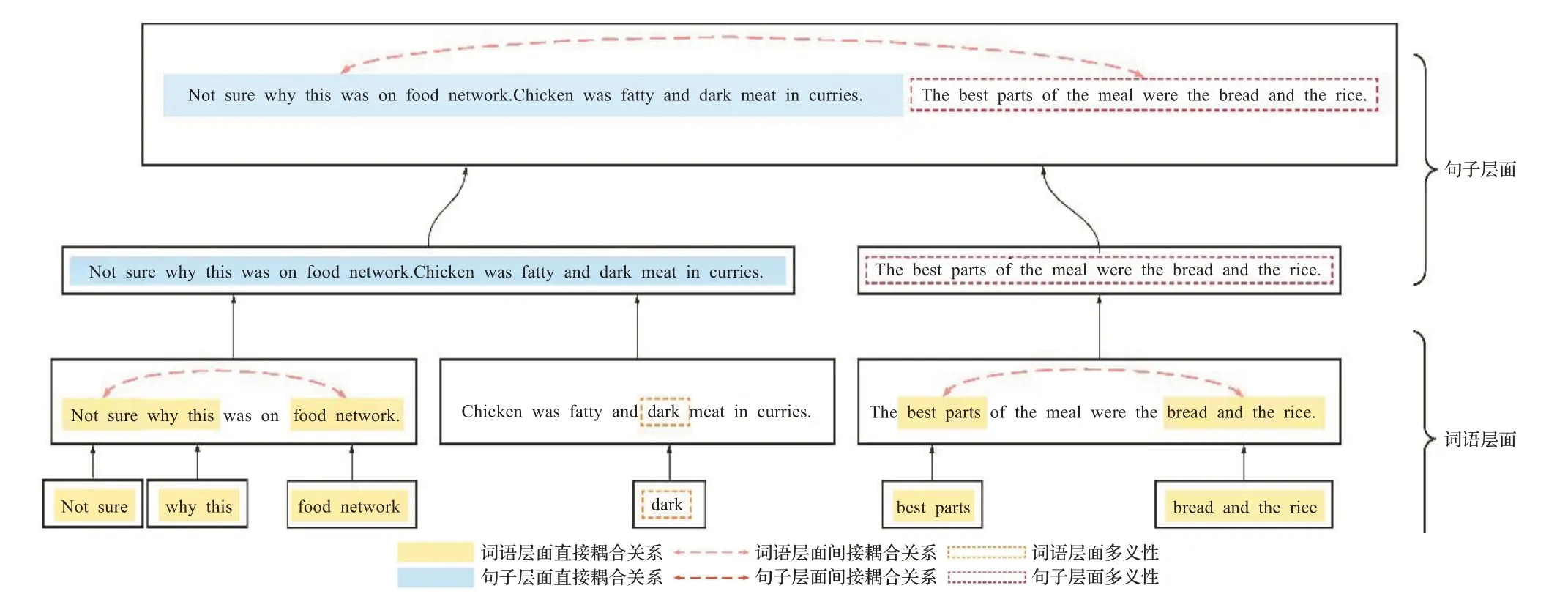
图1 文本中非独立同分布特点示意图Fig.1 Example of Non-IID characteristics in paragraph
当前仅有少量针对非独立同分布文本的表示方法。这些方法考虑了近邻词语之间的耦合关系[4],词语之间的序关系[5],词和句子层次化的多义性[6],显著地提升了情感分析的性能。然而,上述方法并未有效捕获文本中完整的非独立同分布特点。例如,大多数方法将“I feel the restaurant is good”和“I don’t feel the restau‐rant is good”判别为相同的情感极性。一个可能的原因是这些方法都只关注于情感词“good”而忽略了词语“don’t”和“good”的耦合关系。同样,由于忽略了词语“deal”在不同语境中具有不同的含义,又将“The taste is great”和“Cost a great deal of time”两句中反应的情感视为一致。
完整地捕获非独立同分布文本中的非独立同分布特点是具有挑战的工作,既需要构建复杂的模型,又需要防止模型过于复杂从而带来数据过拟合的问题。为应对这一挑战,本文提出了一种全新的非独立同分布文本表示学习框架。该框架系统地捕获文本中层次化分布的非独立同分布特点并将其嵌入到向量空间中,构成对文本的隐式特征表示。进一步,通过情感先验知识构造现实情感特征,在文本向量表示中,融入更多的情感信息,并以此防止复杂模型可能出现的数据过拟合问题。
本文亦提出一种带有注意力机制的层次化的、多尺度深度神经网络来实现非独立同分布文本表示学习框架。具体而言,该神经网络采用多尺度卷积递归神经网络的结构来捕获层次化和异构的耦合关系,采用注意力机制解决词或句子的多义性问题。除此之外,该神经网络根据语义匹配层次化地融合了隐式和显式的文本特征表示。
本文的主要贡献包括:
(1)提出了一种面向情感分析的非独立同分布文本表示学习框架。该框架综合考虑了决定文本情感极性的文本非独立特点和非同分布特点,是首个全面考虑文本非独立同分布特点的表示学习框架。
(2)提出了一种可对非独立同分布文本进行建模的深度神经网络结构。该神经网络结构采用了带有注意力机制的层次化多尺度卷积递归模块,以建模层次化的耦合关系和多义性,从而揭示文本的情感极性。
(3)提出了一种融合显式特征表示和隐式特征表示的方法避免复杂模型数据过拟合。其中,隐式特征表示捕获了非独立同分布文本的情感极性,显式特征表示减小了隐式特征表示在学习构建过程中的过拟合风险并提供了额外的情感信息。
本文在7个数据集上进行了充分实验以验证所提出方法的性能。实验结果表明:(1)本文所提方法可以有效学习非独立同分布特性,并带来了显著的情感分析性能提升;(2)融合显式和隐式的特征表示可以有效提高非独立同分布文本表示的质量。
1 相关工作
1.1 非独立同分布文本表示学习方法
现有的非独立同分布文本表示学习方法主要关注于捕获文本的以下几个方面的特性:上下文关联关系,序列关联关系以及词或句子的多义性。
(1)上下文关联关系:通过考虑词语/句子与其近邻的词语/句子的关联关系来反映情感极性。例如,在词向量的基础上使用卷积神经网络来捕获多个近邻词语的关系[7];在修辞结构理论上引入循环神经网络以捕获文本中直接的耦合关系[8];选取对上下文极度敏感的词,求这类词的词向量之和,以捕获文本中间接的耦合关系[9-10];采用层次化网络结构建模词/句之间复杂的上下文关系[3]。
(2)序列关联关系:通过词语/句子之间的序列关系反映情感极性。此类方法往往采用层次化的循环神经网络捕获文本中序列的关联关系[5]。但是,在循环网络训练过程中常面临梯度消失的问题。为了解决这类梯度消失的问题,后续工作在每一层循环神经网络都加入了批归一化操作[11]。尽管如此,以上方法还是忽略了词/句在不同语言环境下可能出现的多义性现象。
(3)词或句子的多义性:通过分析词/句在不同语言环境下的不同语义判定情感极性。这类方法可以分为两类,一类利用概率图模型分析不同语言环境下的词或句子所在的主题。例如,通过主题模型分析词/句的多义性[12]。另一类方法通过词/句上下文的分析体现多义性。例如,在层次化的网络结构中引入注意力机制[6,13],以及采用双向循环神经网络以此捕获词语/句字相关的更多信息[14]。
以上方法都从非独立同分布特点的某一方面挖掘情感极性,本文则致力于全面地捕获和分析非独立同分布特性,从而支持更为精准的文本情感分析。
1.2 面向情感分析的文本特征提取
从文本中提取情感有关特征是一种构建面向情感分析的文本表示的直接有效的方法。与通过表示学习构造文本向量表示不同,传统的文本特征提取是基于对文本语义和情感的理解,人工构造特征指标,所提取特征一般具有很强的情感指示能力。典型特征包括词频[15]、词性标注[16]等。此外,文献[17]基于特定词或词组的存在性构建特征,以反映段落情感。还有一些研究通过提取稀有词,即一些几乎不会出现在语料库中,但具有明显情感倾向的特殊词(比如“Gooooood”)构建段落特征[18]。另外一些工作[19]认为情感词是影响文本情感极性的最主要因素,因此直接将情感词作为特征进行情感极性的判断。
近年来,越来越多的研究者将人工提取的情感特征融入表示学习构造的文本向量之中[20-21],从而利用情感特征中包含的领域知识来增强文本向量表示对于情感极性的判别性,进一步提升了基于文本向量表示的情感分类效果。然而,大多数现有的方法未考虑人工提取的情感特征与表示学习构建的文本向量表示在语义层面的层次化对应关系[22-23],使其融合效果受限。
2 非独立同分布文本表示学习方法
2.1 非独立同分布文本表示学习目标函数
给定一段包含ns个句子{si|i=1,2,…,ns}的文本P∈ℙ,其中第i个句子位包含nwi个词的词序列{wi,j|j=1,2,…,nwi},文本表示学习模型可以形式化定义为E(·):P→该模型将一段文本P转化为一个nf维的向量p∈此处,P表示一个文本空间,ℝ表示一个实数空间。
将文本P中第i句中的第j个词的情感极性表示为oi,j,则第i句的情感极性可以表示为Oi=∮nwi1oi,jdwi,j。此处,∮nwi
1dwi,j表示从wi,1到wi,nwi的一种序列化运算。在此基础上,文本P的情感极性O∈O可以表示为O=Oidsi。此处表示从s1到sns的一种序列化运算。一段文本的情感极性由从词到句层次的∮和∮运算决定,即:Ons×nwi→O。此处,O表示情感极性空间。
面向情感分析的文本表示学习目标是构建一个模型E(·),使得该模型对于一个情感分类器C(·):ℝnf→O可以提供有效的包含情感信息的文本向量表示。在形式上,若定义一组文本P的分布为,面向情感分析的文本表示学习目标函数可由如下公式表示:
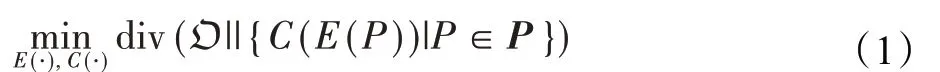
其中,div(·||·)表示两个分布间的散度度量。为了适应于不同任务种的不同数据特点,div(·||·)可以采用不同的散度测量方法或者转换后的散度函数,例如KL散度、交叉熵、海灵格距离等。利用上述目标函数,可以在文本的表示空间中保留文本的情感分布特性。换而言之,利用情感分类器C(·)可以从文本的表示空间中恢复出文本的情感信息。
在实际运用目标函数(1)的过程中,可能会出现两个问题:较高的泛化误差和较低的模型适应度。此处,泛化误差是指文本真实情感分布和由情感分类器从文本表示中学到的情感分布之间的差异。较高的泛化误差通常由缺少训练数据所导致。虽然实际运用中会有成千上万的文本可供训练,但对于完全覆盖文本的情感特性而言还是不足的。模型的适应度是指表示模型E(·)捕获情感相关信息的能力。较低的模型适应度往往是由于在设计模型E(·)时忽略了情感相关的复杂数据特性导致的。
为了有效降低泛化误差,一种可行的策略是对表示学习的目标函数增加约束项,使得在文本的表示空间E:ℝnf中尽可能地保留住文本在原始空间P中的分布特性。若将文本原始空间P中的分布表示为,将文本表示空间E中的分布表示为,文本表示学习的目标函数可调整为:
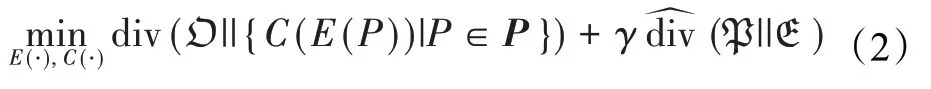
为了有效增强模型的适应度,一种有效策略是对决定文本极性的数据特点进行建模。本文假设词与词、句子与句子之间的交互关系决定了一段文本的情感极性,这些交互关系包含在序列化运算∮和之中。在此,定义词表示函数为Ew(·):W→句子表示函数为Es(·):ℝnwi×new→,段 落 表 示 函 数 为Ep(·):→其中W表示词空间,new表示词表示空间的维度,nes表示句子表示空间的维度。为了对交互关系进行建模,文本表示模型需要能够分解为由词表示函数、句子表示函数、段落表示函数顺序运算的形式。由此,文本表示学习的目标函数可以重构为:
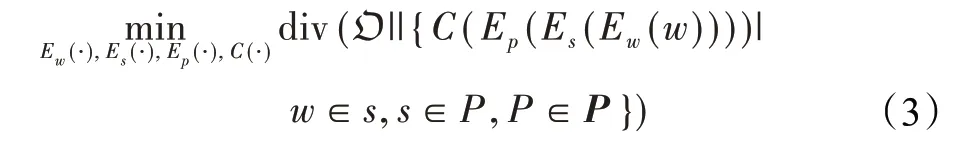
本文同时考虑保留文本的分布信息以及非独立同分布文本的数据特性来实现对于情感分析更加精准的文本表示。结合公式(2)和公式(3),非独立同分布文本表示学习目标函数定义如下:
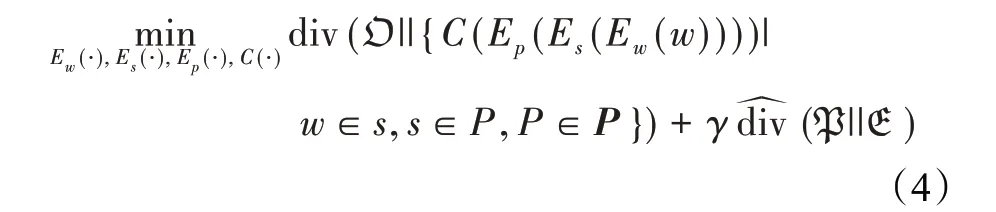
2.2 非独立同分布文本表示学习框架设计
依据非独立同分布文本表示学习目标函数,本节提出面向情感分析的非独立同分布文本表示学习框架,如图2所示。非独立同分布文本表示学习框架由具有层次化的结构的深度神经网络构成。该框架按照从词语到句子再到段落的层次化结构,顺序使用目标函数词表示函数Ew(·)、句子表示函数Es(·)、段落表示函数Ep(·)来生成文本表示。

图2 非独立同分布文本表示学习框架示意图Fig.2 Non-IID document representation framework
具体而言,词表示函数Ew(·)由隐式词嵌入层、显式词特征层、全连接层构成。隐式词嵌入层捕获词的上下文信息,并将其嵌入到向量空间之中构成词的隐式特征。显式词特征层通过预先构建的词情感信息提取函数提取词语的特征,包含着专家对于文本情感的先验知识。全连接层融合隐式词嵌入层和显式词特征层提取的词特征向量,最终形成词的向量表示。句子表示函数Es(·)由非独立同分布特征学习模块构成。非独立同分布特征学习模块捕获词语之间的耦合关系及词语本身在不同环境下的不同语义,而后将它们嵌入到句子的向量表示之中。本文将在3.3节对非独立同分布学习模块进行详细介绍。最后,段落表示函数Ep(·)由非独立同分布特征学习模块、显式段落特征层、全连接层构成。此处,非独立同分布特征学习模块与句子表示函数中的非独立同分布特征学习模块具有相同的结构。不同的是,此处的非独立同分布特征学习模块通过捕获句子间而不是词语间的耦合关系及不同语义来生成段落的隐式特征表示。显式段落特征层通过预先构建的段落情感特征提取函数来构造段落的特征。最终,全连接层融合显式的段落表示和隐式的段落表示来构成非独立同分布段落的向量表示。
非独立同分布文本表示框架通过最小化文本原始情感分布与基于文本表示向量预测的情感分布的差异来实现目标函数中的第一部分;通过层次化地融入先验知识驱动的显式特征来保留文本原始分布特征,以实现目标函数中的第二部分。通过这种方式,非独立同分布文本表示学习框架不仅可以捕获复杂的非独立同分布文本特征,同时可以防止过度拟合的问题发生。
非独立同分布文本学习框架可以很容易地通过设计非独立同分布特征学习模块和选择合适的先验特征来实现。本文在2.3节给出了非独立同分布文本表示学习框架的一种实现方法。
2.3 非独立同分布文本表示学习方法实现
本节提出了一种带有注意力机制的多尺度层次化深度神经网络框架来实现非独立同分布文本表示学习。具体地,利用带注意力机制的多尺度卷积循环神经网络来实现非独立同分布特征学习模块,并使用了三种类型的情感相关文本特征作为显式的词和段落特征。
2.3.1 带注意力机制的多尺度卷积循环神经网络
带注意力机制的多尺度卷积循环神经网络如图3所示。在非独立同分布文本表示学习方法中,该神经网络实现了非独立同分布特征学习模块。在句子表示函数中,该神经网络的输入是一组词向量;在段落表示函数中,该神经网络的输入是一组句向量。该神经网络首先采用注意力机制将输入的向量进行转化,通过输入向量中的上下文信息为该向量赋予注意力权重。通过这种方式,可以利用相同文本的不同上下文内容有效解决文本多义性的问题。然后,该神经网络使用带有多尺度过滤器的卷积神经网络层来从转化后的词或句子向量中提取卷积特征。在卷积特征的基础上,进一步引入带有门控循环单元的双向循环神经网络层来生成对应于卷积特征的循环神经网络特征。最后,该神经网络使用全连接层聚合各循环神经网路特征,从而构造出句子或段落的表示向量。
多尺度卷积循环神经网络结构能够捕获文本中的耦合关系。一方面,该神经网络可以利用卷积神经网络层捕获词或句子之间的直接的耦合关系。卷积神经网络层通过不同尺度的过滤器(例如,图3中1到K号卷积神经网络过滤器)来对词或句子之间具有不同范围和大小的直接耦合关系进行建模。与传统n-gram特征不同,此处生成的卷积特征更加关注于与情感直接关联的文本间耦合关系,而n-gram特征对于所有的词或句的组合赋予相同权重、一视同仁。另一方面,多尺度的卷积循环结构可以通过双向循环神经网络层捕获词或句子之间的间接耦合关系。同时,双向循环神经网络还可以揭示出句子或段落中的情感变化过程。综上,由全连接层融合直接和间接耦合关系后的向量表示可以完整反映文本中的耦合关系。
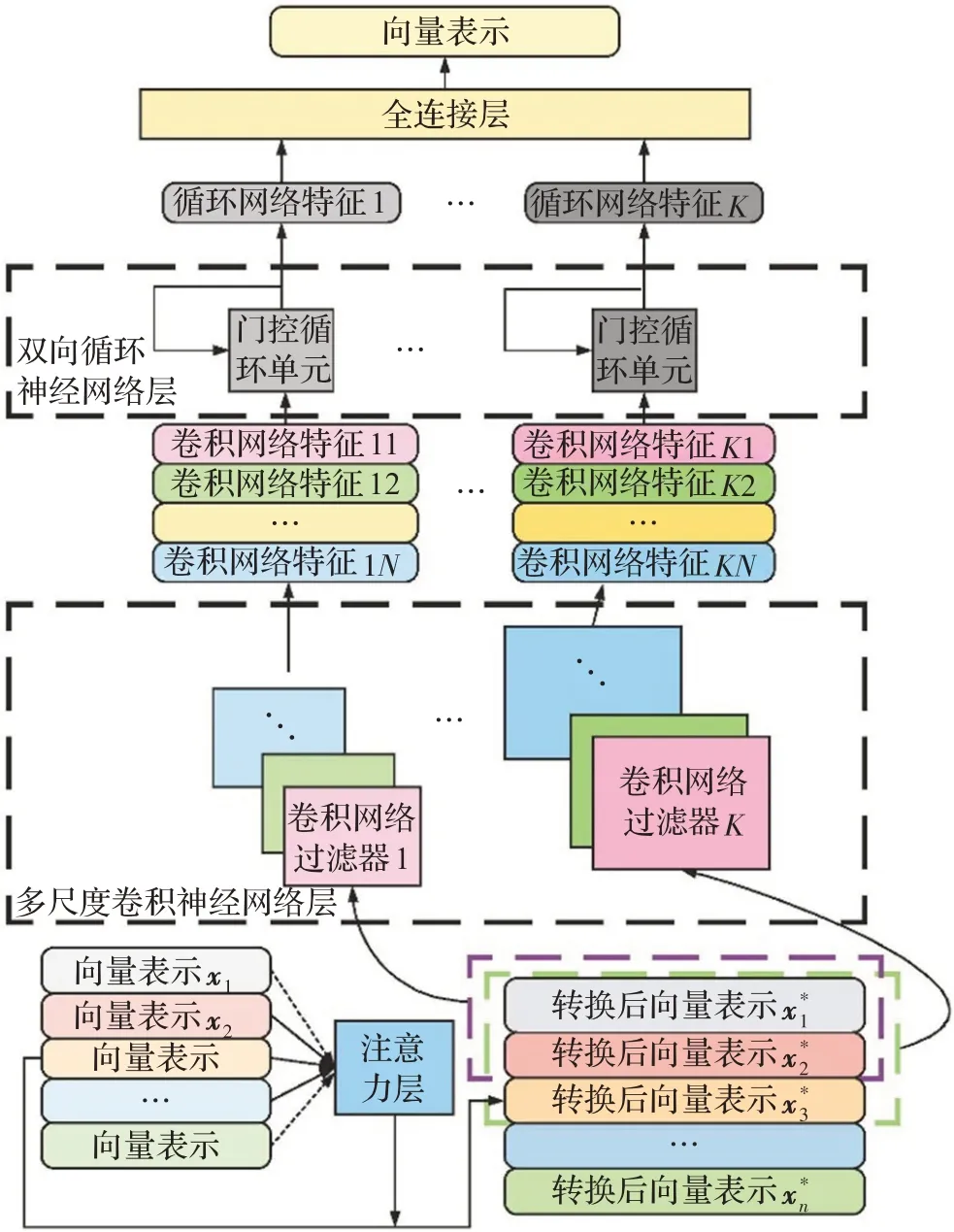
图3 非独立同分布特征学习模块Fig.3 Non-IID-characteristic-learning module
注意力机制用以捕获词或句子的异构性,即词或句在不同语境中的多义性问题。注意力机制根据上下文的信息对词或句子的表示进行调整,以此消除词或句子的多义性对数据表示带来的影响。对于一个表示向量xi,注意力机制首先用一个非线性层将其映射为hi=tanh(Wxi+b),其中W和b分别表示非线性层的权重于与偏置值。然后,注意力机制基于向量的上下文计算表示向量的调整系数αi,计算公式如下:
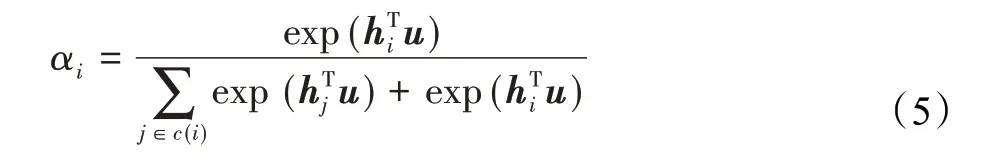
其中,{xj|j∈c(i)}是向量xi的上下文集合,u是需要学习的上下文信息的全局记忆量。根据调整系数αi,注意力机制将向量xi调整为:

调整后的向量表示将进一步输入到多尺度卷积循环结构中对文本的耦合关系进行学习。
本文采用带注意力机制的多尺度卷积循环神经网络来实现句子表示函数Es(·)和段落表示函数Ep(·)中的非独立同分布特征学习模块,其原因在于非独立同分布特征在词和句子层面具有相同的结构和层次。此外,具有相同结构的神经网络可以有效捕获不同层次的相同结构特征,例如GoogLeNet层次化地叠加Inception模块在提取图像不同层次特征时取得了巨大的成功[24]。
2.3.2 显式情感特征层次化构建
为了避免模型的过度拟合,非独立同分布文本表示框架使用层次化的情感显式特征来约束模型的学习过程。本文所提出方法在词层次和段落层次均引入了显式特征对模型进行约束。
在词层次上,本文引入的显式特征包括:(1)情感词典特征[25];(2)词性特征[16]。情感词典特征包含着每个词的情感极性概率值。词性特征则显式地指出了哪些词需要在情感分析中得到更多的重视。为了生成情感词典特征,本文提出的方法将每个词编码为一个二维向量,向量的两个维度分别是每个词正、负情感极性的概率值。为了生成词性特征,本文提出的方法将每个词进行热独编码,编码的每一位对应于一种词性,若该词拥有某词性则对应位编码为1,其余位编码为0。
在段落层次上,本文引入稀有词频率特征[18]来构造段落的显式特征表示。研究表明,稀有词对于文本极性可能有决定性的影响[17]。例如,单词“Goooood”可能仅在语料库中出现1到2次,但其清晰地指明了文本具有积极的情感极性。为有效构造稀有词频率特征,本文所提方法首先对语料库中的词频进行统计,并选取出现频率最低的10%的词构成稀有词集合。而后,利用该稀有词集合对段落进行热独编码,编码的每一位对应于一个稀有词,若段落包含该稀有词则对应位编码为1,若不包含则对应位编码为0。
3 实验验证
3.1 实验设置
3.1.1 对比方法
本文将所提出的方法与4种基于人工情感特征的方法以及7种深度表示学习方法的共11个变种进行对比,以检验所提出方法的性能。
基于人工情感特征的方法包括词袋模型特征(bagof-words,BOW)、带有词频-逆文本频率的词袋模型特征(bag-of-words with term frequency-inverse docu‐ment frequency,BOW-TFIDF)、n元语法特征(ngram),以及带有词频-逆文本频率的n元语法特征(n-gram-TFIDF)。
基于深度表示学习的方法包括:GateRNN的变种GateRNN-CNN[5]、GateRNN-LSTM[5];HNATT的 变 种HNATT-ATT[31]、HNATT-AVG[31]、HNATT-MAX[31];EL‐MO[14];BERT[3];SentiLARE[20];MF的 变 种MF_CNN[23]、MF_RNN[23];SKEP[21]。
3.1.2 数据集
本文在实验中使用了5个带有情感标签的大型文本数据集,包括IMDB电影评论数据集[26],Amazon产品数据集[27],Yelp情感分析挑战中的Yelp13、Yelp14、Yelp15数据集。同时,在实验中还用了两个较小的数据集Twitter短文情感分析数据集(Twitter)以及Twitter航程评论数据集(Twitter-Air)。对于IMDB、Yelp13、Yelp14、Yelp15、Twitter数据集而言,训练集和测试集已经划分,本实验依据其划分好的训练集训练模型,并在其划分好的测试集上进行测试。对于Amazon和Twitter-Air数据集,本实验随机划分90%的数据作为训练集,剩余10%作为测试集。
上述7个数据集来自于不同的领域和应用,例如Twitter和Twitter-Air来自于社交平台,IMDB来自于电影平台,Yelp13、Yelp14、Yelp15来自于推荐平台,Amazon来自于电子商务平台。因此,数据集在结构特点上有着非常大的差异性。具体而言,上述7个数据集中包含的文本数量从5 697到5 255 009不等,每个文本包含的平均句子数量为3到14,每个文本包含的平均词数为22到325.6,数据集中包含的单词总数从16 389到3 652 038不等。
3.1.3 数据预处理
在数据预处理阶段,本文提出的方法首先将文本分割成若干句子,并使用斯坦福大学的CoreNLP工具[28]对句子中的词进行标记和标准化处理。然后,使用skip-gram模型[29]对各个词语进行隐式向量表示的预训练。接着,本文方法使用斯坦福大学的CoreNLP工具生成词性特征,并使用SentiWordNet[25]生成情感字典特征。
3.1.4 神经网络参数
在实验中,本文模型的神经网路参数设置如下:隐式词向量的特征维度设置为100;多尺度卷积神经网络层的过滤器尺寸设置为2×100和3×100两种尺度;在句子表示函数中,每一个卷积神经网络层中的过滤器个数设置为32,门控循环单元的个数设置为64,全连接层中的节点个数设置为64;在段落表示函数中,每一个卷积神经网络层中的过滤器个数设置为64,门控循环单元的个数设置为128,全连接层中的节点个数设置为128;全连接层的层数设置为2。在训练阶段,本文提出方法使用在每一层后使用批归一化(batch-normalization),并在全连接层后使用保持概率为0.5的dropout策略。训练采用Adam算法[30]以64个样本的批量训练大小来优化表示学习目标函数。采用上述神经网络参数设置的主要考虑如下:(1)保持在同一语义层次中每层神经网络输出向量维度数目不变,避免维度减少可能导致的信息损失以及维度增加可能导致的模型过拟合;(2)在段落表示上采用高于句子表示的向量维度,从而使得段落表示向量拥有大于句子表示向量的信息容量;(3)采用批归一化和dropout策略,缓解模型训练中可能导致的过拟合问题。本实验中的参数配置仅代表本文提出方法的一种具体实践,用于展示所提出方法的性能优势,不代表本文方法的最佳实践。
实验中的对比方法采用其推荐的参数配置,其中ELMO和BERT两个模型采用其在Tensorflow Hub平台上预训练得到的参数配置。对于所有对比方法,实验将其得到的向量表示输入到输出层带有softmax激活函数的单隐层前馈神经网络中来构造情感分类器。
3.2 文本情感分析性能验证
3.2.1 验证方法
本实验验证所提出的方法捕获的非独立同分布文本特征是否能够增强情感分析性能。本实验用两种指标来度量情感分析的性能:准确率(accuracy)和均方根误差(rooted-mean-square error,RMSE)。准确率用于衡量表示学习使能的情感分类器可将文本的情感分类为其原本情感的能力。
在传统的分类问题中,通常面对的是离散的类别型标签。然而,在情感分析任务中,分类器面对的是有着序关系的类别型标签。例如,情感程度4更接近于情感程度5而不是情感程度1。因此,更精准的情感分类器应该可以预测出更接近于文本真实情感程度的文本情感值,然而这并不能被准确率指标所反映。为了弥补准确率指标的不足,本实验进一步使用了均方根误差指标,预测结果与真实情感值之间具有越小的均方根误差表示所用模型的情感分析性能越好。
3.2.2 验证结果
实验结果如表1所示,其中本文提出的方法相较于对比的大多数方法提升了情感分类的准确率。此处的准确率提升主要受益于捕获到的非独立同分布数据特点以及融合了显式和隐式的文本情感特征(将在4.3节予以验证)。对于Twitter和Twitter-Air数据集,本文所提出方法与BERT、SentiLARE和SKEP模型相比性能略低,但是仍然取得了高于其余对比模型的结果。此处的关键原因在于这两个数据集所包含的结构和耦合关系都较为简单(体现在其中文本仅包含少量语句),不具有显著的非独立同分布特性;并且文本量很少(分别为5 695和13 176),难以训练好本文提出的复杂模型。在此情况下,本文提出的方法性能略低于已经在大量数据上进行过预训练的模型。
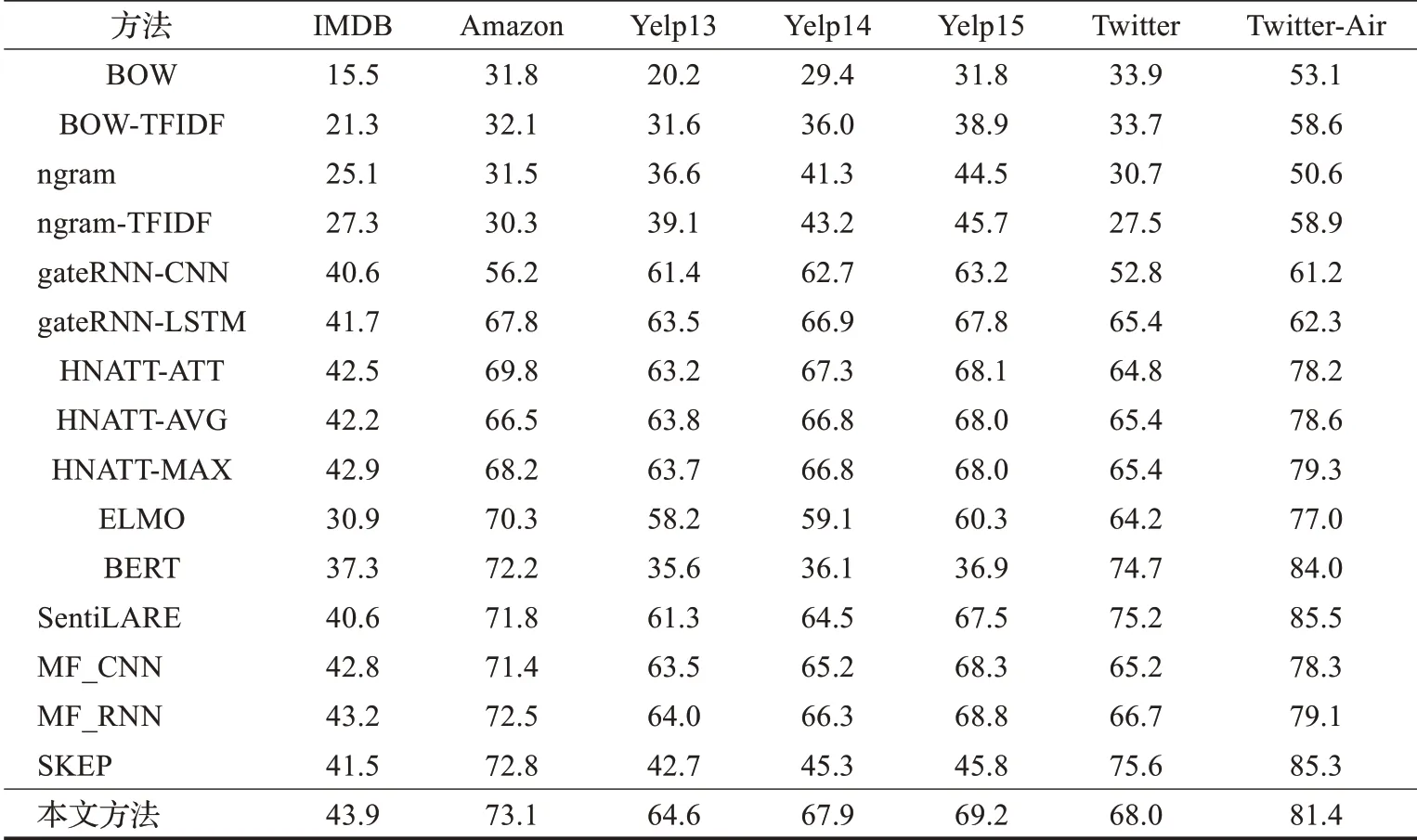
表1 不同方法的情感分类准确率Table 1 Sentiment classification accuracy of different methods 单位:%
如表2所示,在均方根误差指标的评价标准下,本文提出方法可以使得情感分析的性能得到显著提升。从表2中可以看出,现有方法中性能最佳的是MF_RNN方法。该方法与本文方法一样采用了层次化模型和并且融合了显式和隐式的文本特征。对于非独立同分布文本,本文提出的方法在情感分类问题上优势更为明显。
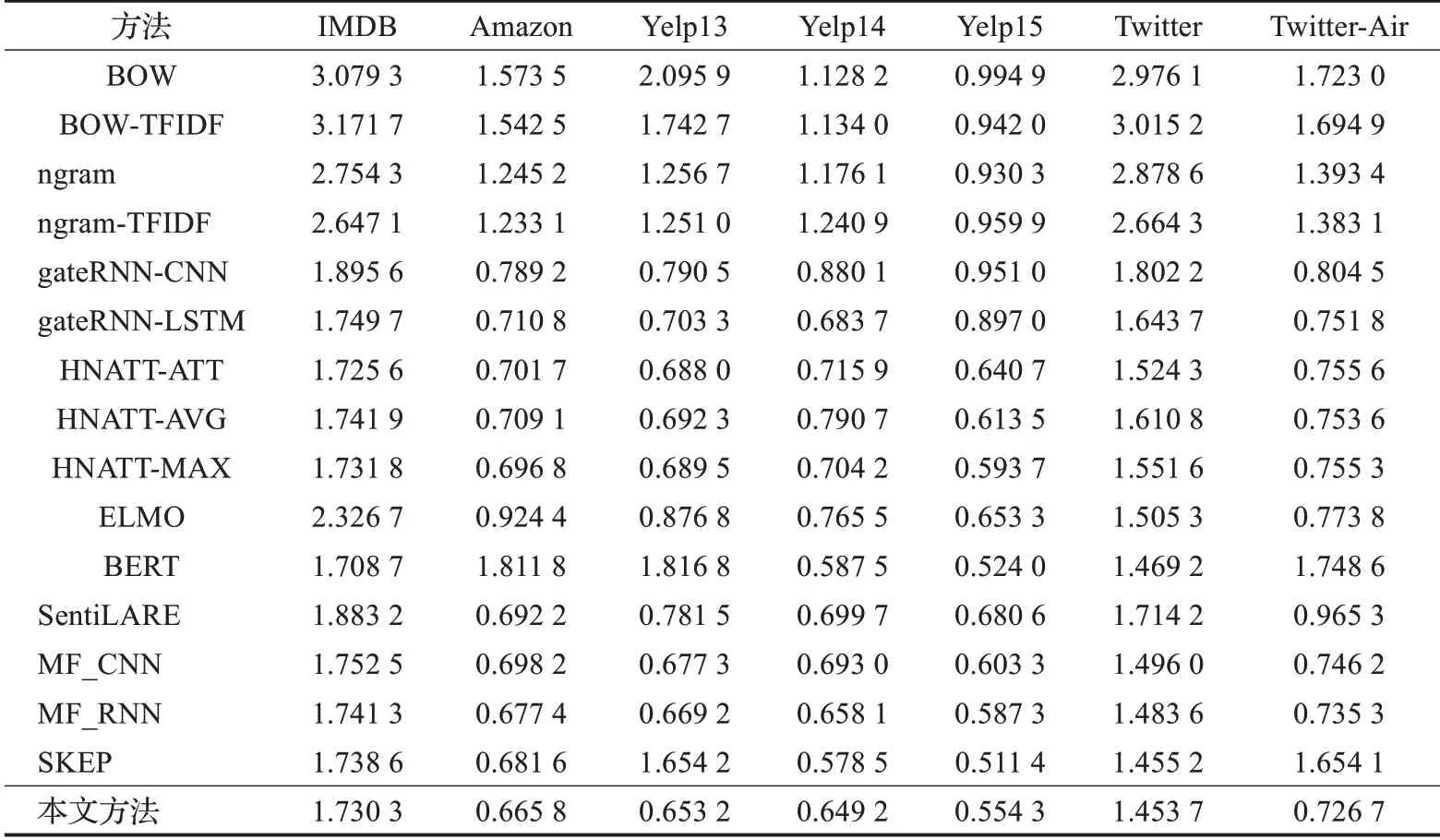
表2 不同方法的情感预测均方根误差Table 2 Sentiment prediction rooted-mean-square error of different methods
3.3 层次化显式隐式特征融合性能验证
3.3.1 验证方法
实验通过对比所提方法的两个变种来验证层次化结合显式特征和隐式特征的重要性。变种一仅采用了非独立同分布特征学习模块。变种二仅在词层面融入了词性特征这一种显式文本情感特征。为了更为全面地进行验证,实验采用了分类准确率和均方根误差两种验证指标。
3.3.2 验证结果
实验结果如表3所示,可以得出如下结论:(1)融合显式特征增加了情感分类的性能;(2)层次化的融合显式特征进一步提升了情感分类的精度。其根本原因是融合显式特征后引入了更多的情感相关信息,这些信息使得原始空间中的文本情感分布在其表示空间得以保留。
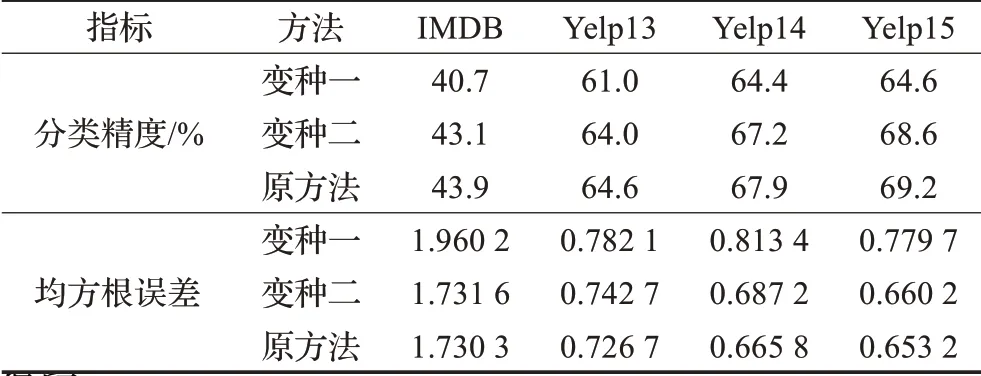
表3 本文方法与其变种方法情感分析对比结果Table 3 Sentiment analysis performance based on proposed method and its variants
4 结束语
面向情感分析的非独立同分布文本表示学习方法将文本中复杂的层次化非独立同分布特点嵌入到文本的向量表示之中,以更为精准地刻画文本情感。本文提出了一种非独立同分布文本学习框架,并通过带有注意力机制的多尺度层次化深度神经网络予以实现。充分的实验结果验证了所提出方法可以显著增强情感分析的性能。
在未来工作中,可以从如下三个方面对本文工作进行拓展延续:
(1)针对特定领域的文本特性,研究非独立同分布文本表示学习框架的其他实现方法。
(2)针对中文文本,研究非独立同分布文本表示学习框架的具体实现方法。
(3)针对情感分析应用的可解释性需求,研究可解释的非独立同分布文本表示学习方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学阅读指南·低年级版(2022年5期)2022-05-09
吉林大学学报(信息科学版)(2022年1期)2022-01-14
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
时代英语·高一(2019年5期)2019-09-03
天然产物研究与开发(2018年9期)2018-10-08
散文诗(2017年17期)2018-01-31
中国舰船研究(2015年2期)2015-02-10
航天返回与遥感(2014年5期)2014-07-31
