
基于BG-DATT-CNN网络的方面级别情感分析
2022-12-22 11:46余本功王惠灵朱晓洁
计算机工程与应用 2022年24期
余本功,王惠灵,朱晓洁
1.合肥工业大学 管理学院,合肥 230009
2.合肥工业大学 过程优化与智能决策教育部重点实验室,合肥 230009
情感分析(sentiment analysis,SA)是自然语言处理(natural language processing,NLP)的一个子领域,在现实生活中有着非常广泛的应用场景。例如企业可以对淘宝商品评价、饿了么外卖评价等进行情感分析,判断其中蕴含的情感倾向,从而更好地洞悉用户需求,推动产品更新迭代。
传统的情感分析只关注评论表现出来的整体情感,对其中信息的挖掘往往不够深入。方面级别情感分析(aspect-level sentiment analysis,ALSA)是一种细粒度的情感分析任务,旨在分析文本针对不同方面的情感极性。如图1所示,在“Staffs are not that friendly,but the taste covers all.”这句评论中,对于方面词“service”,句子表现出消极的情感极性。而对于方面词“food”,句子表现出积极的情感极性。其中,“service”和“food”都是预定义的方面类别。通过方面级别情感分析,可以挖掘产品在各个维度的优劣,进一步明确如何改进产品。

图1 方面级别情感分类的例子Fig.1 Example of ALSA
早期,人们主要使用机器学习方法来处理ALSA任务,如支持向量机(SVM)[1]。近年来,深度学习的方法渐渐成为主流,如LSTM[2]、记忆网络[3]等。与传统的情感分析任务不同的是,ALSA任务不仅需要考虑句子上下文的信息,如何将方面词的信息融合到模型结构中也是需要研究的重点。
注意力机制[4]最初被用于图像处理领域中,现在已经成为神经网络中的一个重要概念。通过对输入的各个部分赋予不同权重,注意力机制可以使模型高度关注重要信息。目前,结合注意力机制的神经网络主要包括基于注意力机制的卷积神经网络(CNN)和基于注意力机制的循环神经网络(RNN)。RNN及其衍生网络(如LSTM、GRU等)适合处理序列信息,具有很强的上下文依赖能力。而CNN类模型利用滤波器抽取特征,能够有效地提取局部信息。基于此,本文提出了基于双重注意力机制的BG-DATT-CNN模型。该模型结合了CNN和RNN各自的优势,能够同时提取方面词和上下文相关信息,实现对文本信息的深层次挖掘。
1 相关工作
方面级别情感分析本质上属于NLP领域的分类问题。传统的方法首先会定义情感词典[5]、语法规则等一系列特征,然后采用SVM、朴素贝叶斯[6]等分类器进行分类。这种方法虽然在特定领域有良好的表现,但是往往需要耗费大量的人工成本。
近年来,随着深度学习的发展,越来越多的神经网络模型[7-9]被应用到ALSA领域中。起初这些模型都没有考虑到方面词的信息,导致分类的准确率不高。有学者[10]指出40%的分类错误是忽略方面词信息导致的。
后来人们开始尝试将方面词信息融入到模型中。根据方面词的不同类别可将ALSA任务分为两个子任务。一类基于目标词(aspect-target),另一类基于方面类别(aspect-category),即本文的研究重点。两种任务最大的区别是基于目标词的任务的方面词就在句子中,而基于方面类别的任务的方面词是预定义的具有高度概括性的词汇。换句话说,基于方面类别的ALSA任务不关心句子中各个具体的实体对应的情感极性,而是关心句子在几个特定维度上表现出来的情感。例如在“The hamburger is delicious but expensive”这句话中,“hamburger”是一个目标词,而“food”为方面类别,是一个具有概括性的词汇。
RNN类序列模型适合处理文本信息,在ALSA领域应用十分广泛。Tang等[11]提出了TD-LSTM和TC-LSTM。TD-LSTM将句子分成左右两个部分,分别对目标词的上下文用LSTM建模,最后将隐藏向量连接起来输入到softmax函数中进行分类。TC-LSTM是在TD-LSTM基础上的改进,通过将目标词向量和上下文词向量连接起来输入到前后两个LSTM中,从而实现方面词和文本的交互。Tang等[3]还引入了记忆网络[12]解决ALSA问题,捕捉不同的上下文单词对于特定方面词的重要性,改善了RNN、LSTM等网络记忆能力较差的问题。以上模型主要是为了解决基于目标词的ALSA任务。
目前,注意力机制在情感分析、关系抽取[13]、阅读理解[14]等NLP任务中应用十分广泛。在针对方面类别的ALSA任务上,ATAE-LSTM[15]首次将注意力机制应用到模型中,先将方面词向量和上下文词向量组合作为LSTM的输入,再通过注意力机制给上下文单词赋予不同的权重,极大地改善了模型表现。Tay等[16]认为简单的拼接会增加模型的参数成本和训练难度,因此提出在LSTM层后接入方面词-文本融合层,首先对方面词和上下文之间的关系进行建模,然后使注意力层专注于学习经过融合后的上下文的相对重要性。使用单层注意力机制可能不足以提取长文本中的重要特征。IAN[17]、AOA[18]、MGAN[19]都是针对基于目标词任务设计的交互式注意力模型,首先通过对目标词和文本分别建模,然后利用交互注意力机制获取两者的交互信息。孙小婉等[20]提出了结合多头注意力机制的双注意力网络模型,使得模型能够更全面地理解句中单词之间的依赖关系。
CNN能有效提取句子局部特征,具有训练速度快和权值共享等优点。Xue等[21]提出了一种基于CNN和门控机制的方面级别情感分析模型,设计了GTRU门控单元有选择地提取相关信息。梁斌等[22]结合位置、词性、目标词三种注意力机制来构造多注意力机制卷积神经网络模型,能有效识别不同目标词的情感极性,证明了注意力机制和CNN结合的有效性。
综上,现有的基于RNN的模型忽略了局部特征的重要性,而基于CNN的模型不能捕捉长距离依赖的信息。基于此,本文提出了基于双重注意力机制的BG-DATTCNN模型,将RNN和CNN的优势相结合,并设计了一种基于综合权重的双重注意力机制同时获取方面词和上下文相关信息。该模型首先采用BERT[23]对句子和方面词分别编码获得文本的深层特征表示,再利用Bi-GRU提取全局特征,然后通过双重注意力机制强化特征,给重要程度不同的单词赋予不同的权重,最后利用CNN分两阶段提取重要特征,从而实现对文本信息更深层次的抽取。
2 BG-DATT-CNN模型
本文的任务是基于方面类别的ALSA任务。以下提到的方面词均为方面类别。
对于长度为n的句子和m个预定义的方面词v={a1,a2,…,am}。本文的目标是针对不同的方面词分析句子的情感极性。例如句子“The price is reason‐able although the appetizers is poor.”,对于给定的方面词“price”,模型输出的是积极的情感极性,而对于给定的方面词“food”,模型输出的是消极的情感极性。本文利用BERT[23]将每一个单词映射成低维空间的连续词向量,得到上下文词向量矩阵E=[x1;x2;…;xn]∈Rn×dw和方面词向量V∈R1×dw,其中dw为词向量维度。
2.1 双重注意力机制
注意力机制的作用是在训练过程中,通过计算权重的方式让模型了解输入数据中哪一部分信息是重要的。本文通过双重注意力机制计算两类权重。外部注意力机制根据方面词和上下文的相关程度计算权重,内部注意力机制根据单词对上下文语义重要程度计算权重。
(1)外部注意力机制
对于ALSA任务而言,外部注意力机制的作用是获取文本和方面词的依赖关系,强化文本的方面词相关特征。通过计算方面词和句子中各个单词的注意力得分,给和方面词相关度不同的单词赋予不同的权重。例如在“Staffs are friendly,but the taste is bad.”这句话中,“friendly”是用来形容“service”的,而“ok”是用来形容“food”的。因而在该句中,单词“friendly”相比“bad”与方面词“service”相关程度更高,因此应该被赋予更大的权重。假设句子的向量表示为h,方面词的向量表示为V,外部注意力计算公式如下:

首先采用缩放点积注意力计算h和V之间的相似度,然后通过softmax函数归一化得到注意力权重α1。其中d为词向量维度。
(2)内部注意力机制
内部自注意力机制即自注意力机制,是注意力机制的一种特殊形式。通过计算句子中每一个单词的注意力得分,给重要程度不同的赋予不同的权重。比如在“The place is so cool.”这句话中,相比其他单词,“cool”这个词直接体现了情感倾向,对句子语义的影响更大,应该被赋予较大的权重。
根据文献[24]提出的计算文本中注意力的方式,本文首先将句子的向量表示h输入到一个单层的感知机中得到u作为h的隐层表示。为了衡量每个单词的重要性,本文用u和一个随机初始化的上下文向量uw的相似度来表示,然后经过softmax操作获得了归一化的注意力权重α2。公式表示如下:

其中,tanh为非线性激活函数,w、uw为参数矩阵,b为偏置。
2.2 基于BG-DATT-CNN网络的层次特征提取
BG-DATT-CNN模型的整体结构如图2所示。模型共由6个子模块组成,分别为词嵌入层、Bi-GRU层、双重注意力层、K-Max池化层、CNN层和输出层。首先将上下文词向量矩阵E输入到Bi-GRU中获取句子的全局特征,然后通过双重注意力机制强化句子的上下文相关特征和方面词相关特征,再利用K-Max池化和TextCNN分两步提取特征,增强模型的特征提取能力。最后将得到的特征输入到全连接层中得到结果。
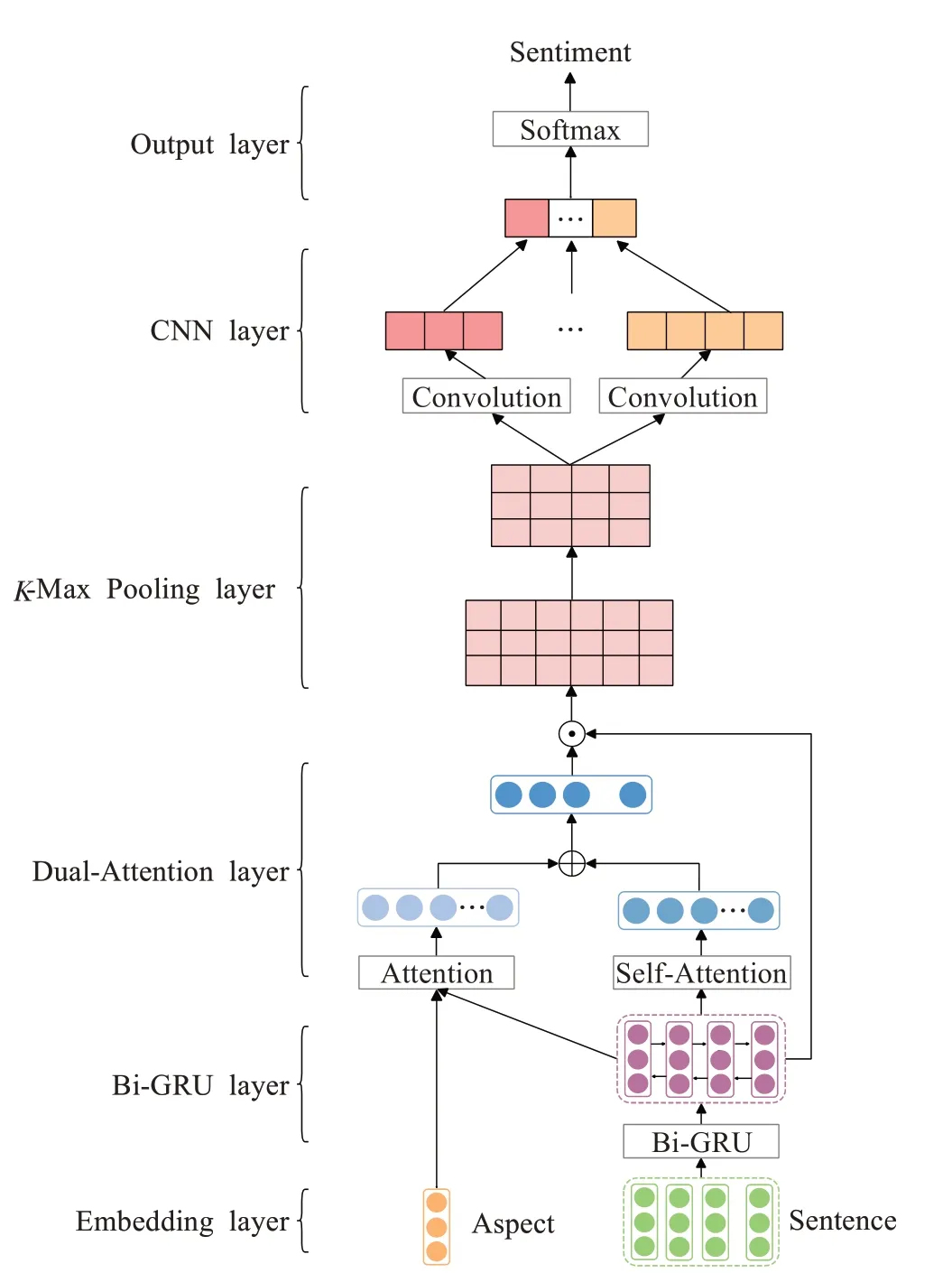
图2 BG-DATT-CNN模型结构图Fig.2 Architecture of BG-DATT-CNN
(1)Bi-GRU提取全局特征
GRU是一种序列模型,可用于文本建模,双向的GRU可以从前后两个方向对句子建模,同时考虑到上下文的信息。因此,本文将上下文词向量矩阵E输入到Bi-GRU中提取句子的全局特征。前向的GRU产生一个隐藏向量h1∈Rn×dh,后向的GRU产生一个隐藏向量h2∈Rn×dh,最终的输出hs由h1和h2连接起来得到。公式表示如下:
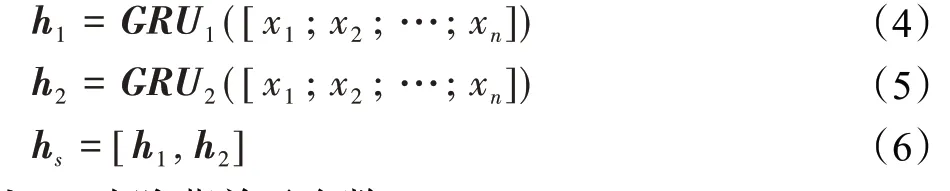
其中,dh为隐藏单元个数。
(2)双重注意力机制强化重要特征
根据上文提出的计算文本中双重注意力的方式,本文首先对Bi-GRU层输出的隐藏向量hs计算内部注意力得到注意力权重αin,再对hs和V计算外部注意力注意力权重αout。然后将两者相加得到综合权重α。最后将hs和α相乘得到加权后的句子表示s。公式表示如下:

(3)K-Max池化提取前K个重要特征
在NLP领域,池化层主要用来提取特征。最大池化为比较常见的池化操作,做法是保留其中最重要的特征,但这样会不可避免地丢失部分重要特征。K-Max池化可以取所有特征值中得分在Top-K的值,并保留这些特征值原始的先后顺序,即通过保留更多有价值的信息供后续阶段使用。本文对注意力层输出的向量s表示采用K-Max池化,保留前K个注意力分值较大的向量,得到前K个词的组合特征向量γ。
(4)CNN提取局部特征
本文采用类似于TextCNN模型[25]的结构进一步提取局部特征。该网络第一层为输入层,将K-Max池化层提取的前K个向量γ作为输入;第二层为卷积层,使用多个大小不同的滤波器对输入的向量进行卷积运算;第三层为池化层,执行最大池化操作,提取最重要的特征,重新构建一个特征向量r。
最后将r输入到全连接网络,通过softmax函数分类,得到每个文本所属类别的概率分布值p,最大值的类别即为预测类别。公式表示如下:

其中,w'为参数矩阵,b'为偏置。C为情感类别数。
2.3 模型训练
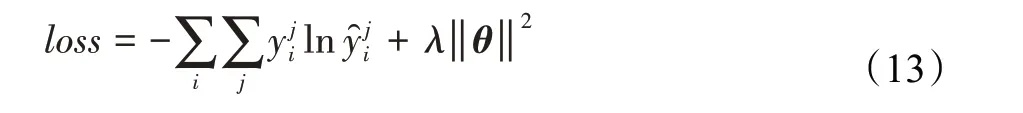
其中,i为文本序号,j为类别序号。λ‖θ‖2为交叉熵正则项。
3 实验分析
3.1 数据集
本文采用国际语义评测大赛SemEval 2014的Res‐taurant数据集(https://alt.qcri.org/semeval2014/)来验证模型的有效性。该数据集一共包含3 518条评论,每条评论包含若干个方面词和对应情感类别。其中方面词包含“Food”“Aspect”“Service”“Ambience”和“Anecdotes”,情感类别分为“Positive”“Negative”和“Neutral”。实验的任务是根据输入评论文本和给定的方面词,输出对应的情感类别。表1给出了本文实验使用数据统计。
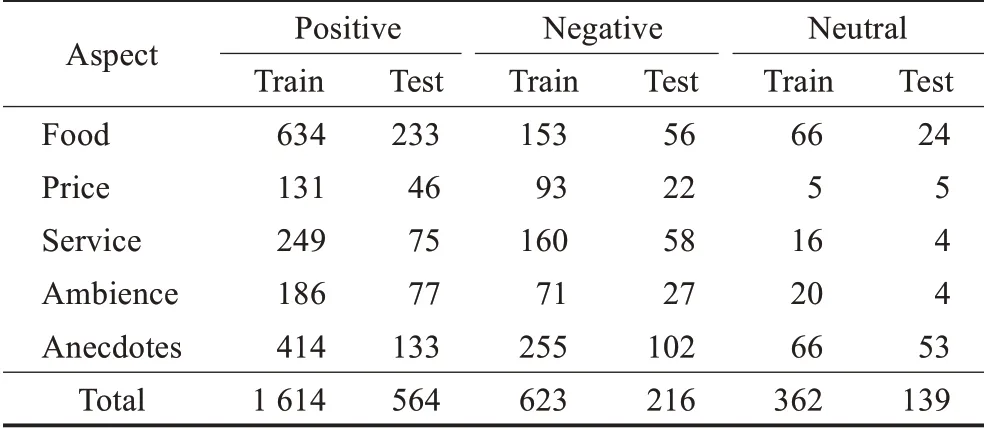
表1 实验使用数据统计Table 1 Statistic of datasets
3.2 参数设置
本文实验中的词向量有两种,分别为斯坦福开源的Glove词向量(https://nlp.stanford.edu/projects/glove/)和BERT预训练得到的词向量,其中Glove每个词向量维度为300维,词典大小为1.9 MB。BERT预训练词向量为768维。其他参数如表2所示。

表2 模型参数设置Table 2 Parameter settings
3.3 对比实验与分析
本文选取了基于方面类别任务的5种基准模型在相同的数据集上进行对比实验。
(1)Bi-LSTM:即双向循环神经网络,不考虑方面词信息,直接将前后两个隐藏向量拼接后作为句子表示,输入到softmax分类器中。
(2)Bi-GRU:将Bi-LSTM中的LSTM单元换成了GRU。
(3)AT-LSTM:由Wang等[15]提出,首先通过LSTM对文本上下文建模,然后将隐藏向量和方面词向量连接后输入到注意力网络中,再由注意力向量输入到softmax中进行分类。
(4)ATAE-LSTM[15]:在AT-LSTM基础之上将方面词向量和上下文词向量拼接后作为模型的输入,进一步加强方面词和上下文的交互。
(5)AF-LSTM[16]:相对于ATAE-LSTM模型,最大的不同就是增加了一个word-aspect融合层,代替了原来的直接拼接的操作。
(6)BG-DATT-CNN:本文模型。
本文采用准确率(Accuracy)作为模型分类性能的评估标准,对比实验结果如表3所示。
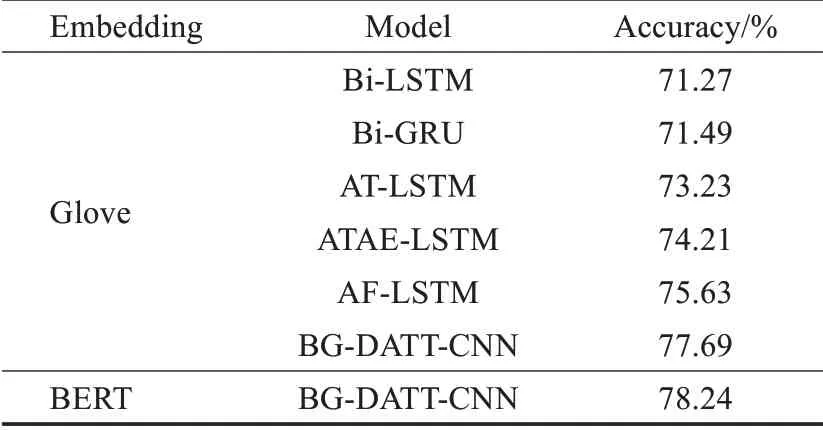
表3 不同模型准确率对比Table 3 Accuracy of different models
由表3可知,本文提出的BG-DATT-CNN模型在和几个基准模型的对比实验中取得了最好的分类效果,基于Glove词向量的BG-DATT-CNN分类准确率达到了77.69%,相比AF-LSTM提升了2.50个百分点,从而验证了模型的有效性。而基于BERT预训练词向量的BGDATT-CNN准确率达到了78.24%,比基于Glove词向量的BG-DATT-CNN准确率提升了0.55个百分点。这说明了BERT预训练词向量比Glove词向量质量更高,包含了更多的语义信息。
将Bi-LSTM和Bi-GRU对比可知,Bi-GRU的效果略优于Bi-LSTM。并且前者的结构更简单,训练速度更快。这也是本文模型选择Bi-GRU提取全局特征的原因。
Bi-LSTM和Bi-GRU由于没有考虑到方面词信息,仅仅对上下文建模,因此效果相对较差。AT-LSTM改进了这一点,将LSTM的隐藏向量和方面词向量连接后再利用注意力机制对重要程度不同的单词赋予不同的权重,使得准确率有了较大的提升。这也说明了注意力机制的重要作用,即能使模型在训练过程中高度关注部分信息,忽略不相关的信息。
ATAE-LSTM在AT-LSTM基础上进一步融合了方面信息,将方面词向量和上下文向量连接后作为模型的输入,使得效果更优。然而简单拼接并不是一种很好的融合方式,ATAE-LSTM不能使注意力机制专注于对上下文单词之间的关系或方面词和上下文的关系进行建模,并且增加了参数成本。AF-LSTM摒弃了直接拼接的方式,设计了方面词-上下文融合层,改进了融合方式,使得准确率提高了1.74个百分点。
以上基于注意力机制的模型都只采用了一种注意力机制,BG-DATT-CNN采用了双重注意力机制,能够提取到更加丰富的特征,并且结合了Bi-GRU和CNN各自的优势,因此取得了最高的分类准确率。
3.4 BG-DATT-CNN模型分析
3.4.1 不同注意力机制作用分析
BG-DATT-CNN模型采用了内外两种注意力机制对上下文和方面词建模,为了更深入地探究不同注意力机制对模型的影响,本文设计了多组对比实验进行分析。实验模型如下:
(1)BG-CNN。不使用任何注意力机制,将Bi-GRU层得到的隐藏向量直接输入到CNN层进行特征提取。
(2)BG-IATT-CNN。仅使用内部注意力机制,其他部分与BG-DATT-CNN相同。
(3)BG-EATT-CNN。仅使用外部注意力机制,其他部分与BG-DATT-CNN相同。
(4)BG-DATT-CNN。本文模型。
表4为上述4种模型在SemEval 2014的Restaurant数据集上的实验结果,词向量均使用Glove。

表4 不同模型准确率对比Table 4 Accuracy of different models
由表4可得,在不使用注意力机制的情况下,BG-CNN的准确率仅为74.21%。BG-IATT-CNN在BG-CNN的基础上加上了内部注意力,能够使模型训练时更加专注于上下文重要信息,使得准确率提升了0.81个百分点。BGEATT-CNN在BG-CNN的基础上加上了外部注意力,能够使模型训练时更加专注于与方面词相关信息,使得准确率提升2.07个百分点。BG-DATT-CNN将两种注意力结合,取得了最好的效果。
将BG-IATT-CNN和BG-EATT-CNN对比可以发现,外部注意力机制的效果明显好于内部注意力机制。这说明了在ALSA任务中,方面词信息对于最终分类结果有着更加重要的作用。
3.4.2 K值分析
本文模型在CNN层采用了两阶段特征提取的方式,先利用K-Max池化层将前K个权重较大的向量提取出来,再输入到TextCNN中进行下一步处理。因此K的取值尤为重要。为了得到最佳K值,本文进行了多次实验,绘制了准确率随着K值变化的曲线,如图3所示。
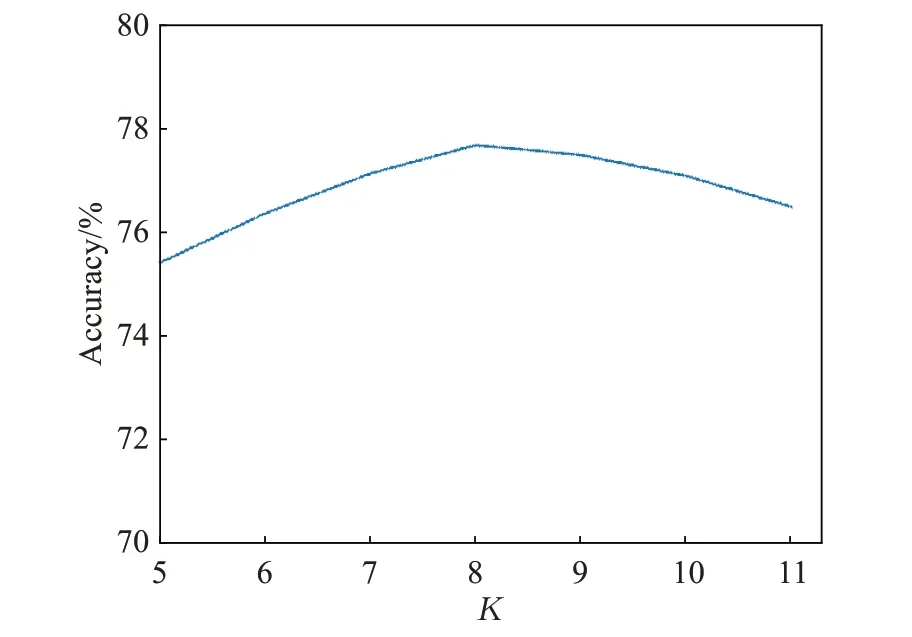
图3 准确率随着K值的变化曲线Fig.3 Curve of accuracy with K changing
从整体上看,模型分类准确率随着K值的增加而上升,说明了K-Max池化层起到了一定的作用。当K=8时,准确率达到最高,之后呈缓慢下降的趋势。因此本文KMax池化层的K值设为8。
3.4.3 分类结果分析
为了分析方面词对分类结果的影响,本文统计了不同方面的分类准确率,如图4所示。
由图4可知,除了“Anecdotes”这一方面外,其他方
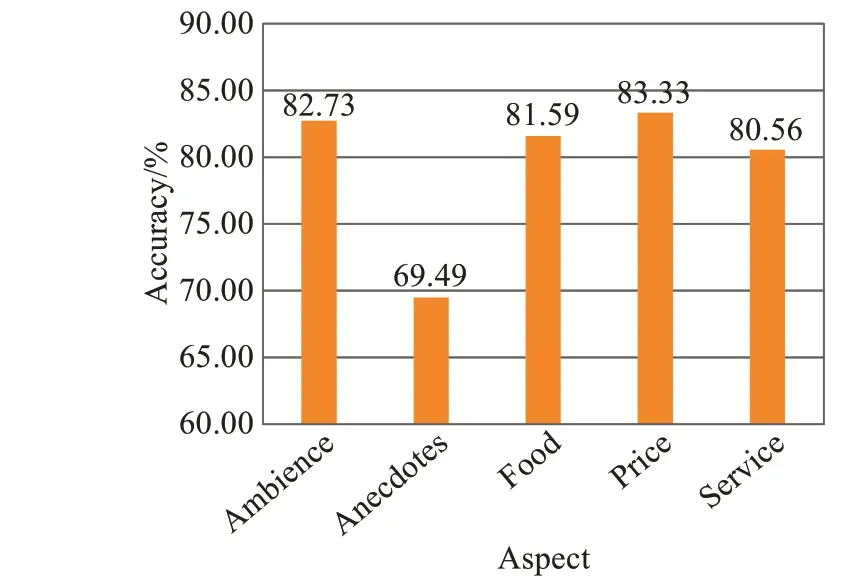
图4 不同方面的分类准确率Fig.4 Classification accuracy of different aspects
面的分类准确率均在80%以上。其中,“Price”方面的准确率最高,达到了83.33%。并且虽然各个方面的数据总量不一,但对分类结果并无明显影响。至于“Anecdotes”方面的分类准确率远远低于其他方面,一个最主要的原因即为方面词的概括性较差。例如“The food was just ok but I would never go back”这句评论,对于“Food”,句子表现为正面的情感;对于“Anecdotes”,句子表现为负面的情感。显然,“I would never go back”这种表述方式不够直接,“Anecdotes”并不能很好地概括这一方面,因此容易导致模型分类错误。同时,这也印证了方面词信息的重要性。方面词与句子的相关性越高,概括性越好,越有利于模型融入重要的信息,从而做出正确的判断。
为了分析模型对于不同情感倾向的句子的分类效果,本文绘制了模型在“positive”“neutral”“negative”三种情感倾向下的分类准确率,如图5所示。
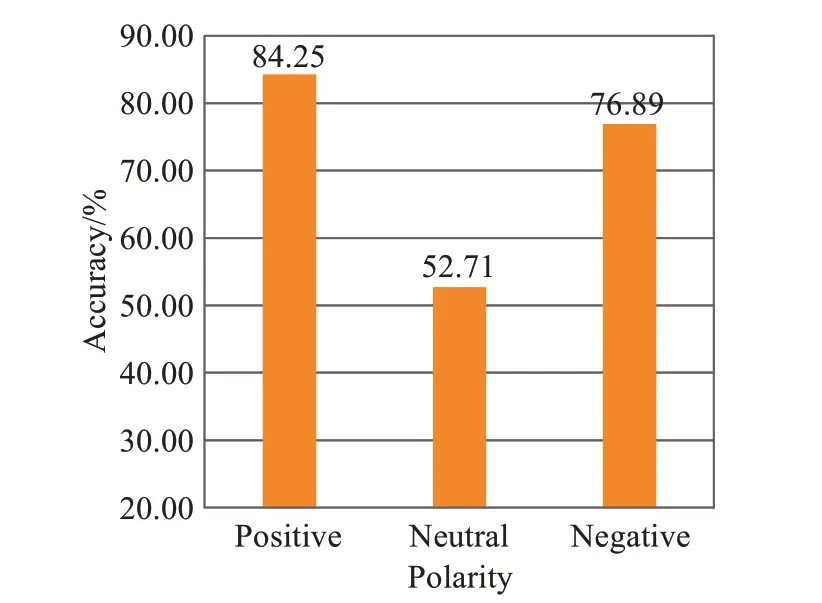
图5 模型在三种情感倾向下的分类准确率Fig.5 Classification accuracy of model towards three sentiment polarities
由图5可知,模型在正向评论数据上准确率最高,为84.26%,负面评论数据上准确率次之,中立评论数据上准确率最低,只有52.71%。这一方面与数据量大小有一定关系,因为正向评论数据量远远高于其他两类。另一方面,正向和负向情感的评论一般都有明确的情感词,而中立评论的情感倾向表现得较为模棱两可,给模型判断增加了很大的难度。这也是后续工作需要解决的一个问题。
4 结束语
本文根据方面级情感分析任务的特点,设计了一种新的模型。首先本文采用了基于Transformer结构的BERT模型获得句子和方面词的向量表示。为了更加充分地提取上下文特征和方面词相关特征,本文采用了基于综合权重的双重注意力机制,并设计了BG-DATTCNN混合网络提取特征。实验表明,模型具有良好的分类性能。然而,由于公开的数据集较小易造成过拟合,且存在个别方面词概括性较差的情况,导致分类准确率依然不高。在后续的工作中本文将考虑通过引入语言学知识等方式进一步提升模型效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
中国交通信息化(2018年5期)2018-08-21
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
