
深度融合辅助信息的跨域推荐算法
2022-12-22 11:46陆永倩生佳根
计算机工程与应用 2022年24期
陆永倩,生佳根
江苏科技大学 计算机学院,江苏 镇江 212100
近年来,随着信息数据量的不断增加,用户渴望采用一种有效的方式来处理信息过载问题。推荐系统[1]作为解决这一问题的有效方法之一,它在为用户推荐可能感兴趣的项目方面起着不可或缺的作用。现有推荐方法大致可分为两类:基于内容的方法和基于协同过滤的方法[2]。基于内容的方法利用用户个人资料和项目内容信息进行推荐,基于协同过滤的方法根据其他具有相似兴趣的用户偏好信息进行推荐。然而,推荐系统通常面临两个主要问题:冷启动和数据稀疏性[3]。当历史数据稀疏时,使用这些方法难以达到令人满意的性能。另一方面,在获得用户的历史评分之前,很难对用户进行推荐。
为了解决这些问题,一种解决方案是将辅助信息和协同过滤相集成,以获取更多的有效特征[4]。除了评分信息可以直观显示用户的喜好外,大多数辅助信息中隐含着用户的个性偏好,如用户和项目的基本描述性信息中蕴含着更丰富的语义信息。此外,如购买历史,浏览信息等隐式反馈信息[5]更能够反映出用户对某些项目的偏好。一些基于协同过滤的混合方法[6-7]将辅助信息集成到矩阵分解中以学习有效潜在特征。然而,这些方法将辅助信息用作正则化,尤其是当评分矩阵和辅助信息比较稀疏时,学习到的潜在特征通常无效。因此,从这些稀疏数据中实现有效潜在特征学习是非常必要的。深度学习[8]作为一种学习特征的强大方法在处理稀疏数据方面表现出了出色的能力。将辅助信息融入到深度协同过滤中所涉及到的一个重要问题是捕捉辅助信息与评分矩阵之间的隐藏关系。基于自动编码器的深度学习模型由于能够将特征表示学习到低维空间中,从而使特征表示更加紧凑且有效,应用十分广泛[9]。
跨域推荐[10]则是利用迁移学习来改善推荐性能的另一种解决方案。跨域推荐通过将知识从相关领域(称为源域)迁移到当前领域(称为目标域),以提高目标域的推荐性能。在实际应用中,可以获得同一用户在几个不同推荐系统中的参与情况,以获取用户在不同领域中的各种有效信息。然而,现有的大多数跨域推荐算法相关的工作仅仅使用评分信息,仅基于这些信息做知识的迁移存在很大的局限性,难以充分迁移源域中的知识[11]。
综上所述,无论是传统的协同过滤方法还是跨域推荐方法,将辅助信息引入推荐系统都可以极大地提高推荐的准确性,降低为新用户推荐项目的错误率。尽管如此,大多数现有的跨域推荐在进行知识迁移时并没有充分考虑各种有价值的辅助信息,忽略了隐式反馈信息对目标域知识刻画的有益影响。为此,本文将隐式反馈信息视为重要的可用辅助信息,并将其引入跨域推荐模型,提出了一种深度融合辅助信息的跨域推荐算法,即CICDR。该算法一方面通过扩展标准的堆叠降噪自动编码器(stacked denoising autoencoder,SDAE)[12]模型,以提取用户和项目描述性信息中的用户和项目潜在特征。另一方面,则将隐式反馈信息与矩阵分解[13]集成,以减少用户不喜欢项目的推荐。在此基础上,采用非完备正交非负矩阵三分解[14]方法建立源域和目标域之间的关联,以更有效地实现源域知识向目标域迁移。
本文的主要贡献总结如下:
(1)在两个域中集成了Semi-SDAE以深度融合的方式处理评分矩阵和两种辅助信息,学习到的用户和项目特征包含了更多的语义信息。
(2)采用非完备正交非负矩阵三分解方法从源域中提取评分模式。该方法松弛了对源域评分矩阵的全评分限制,并使评分模式矩阵与目标矩阵更加近似相关。
(3)在三个真实数据集上与几种算法进行比较,证明了CICDR算法的可行性和有效性,能够为冷启动用户做出更令人满意的推荐。
1 相关工作
1.1 Semi-SDAE
Semi-SDAE[15]包括三个部分:输入层集成辅助信息,隐藏层学习潜在表示,输出层进行信息重构。Semi-SDAE允许输入和输出具有不同维度的情况,即当更多的辅助信息被模型使用(输入的维度增加)时,输出层不受影响。当模型需要处理更多的辅助信息源时,这一重要特征使得模型更容易扩展。此外,它具有更高的推荐准确度,减少信息的丢失。给定评分矩阵R,用户和项目的辅助信息集分别表示为X和Y。可以将处理用户信息的Semi-SDAE公式化如下:
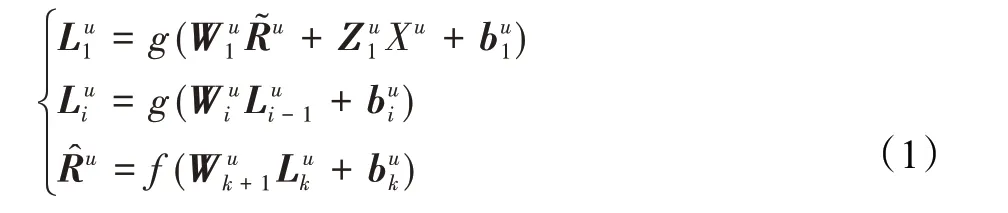
其中W1,W2,…,Wk+1和Z1是权重矩阵,g(·)和f(·)表示激活函数表示加入噪声的用户评分向量,bui表示第i个隐藏层的用户偏置向量,Lui表示第i个隐藏层用户隐藏潜在特征表示,则表示输出层的重构评分。Semi-SDAE通过最小化损失函数(2)来训练:
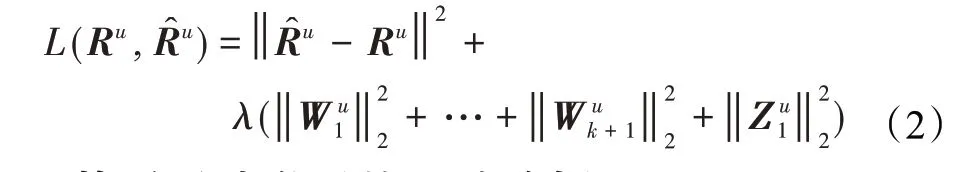
1.2 基于迁移学习的矩阵分解
通过集体矩阵分解[16]使用多个分解矩阵可以实现知识的跨域迁移。在迁移学习中,一些共同的潜在因子被作为连接源域和目标域的桥梁。以往基于矩阵分解的迁移学习者通常通过优化预定义的目标函数来挖掘这些潜在因素,包括最大化经验似然[17],或保持固有的几何结构[18]。它的三因子分解变体最近被广泛研究用于迁移学习。在正交非负矩阵三分解(orthogonal nonnegative matrix tri-factorization,ONMTF)[19]中,一个数据矩阵RM×N会被分解为三个非负因式部分U∈RM×K,H∈RK×L,V∈RL×N,满 足R≈UHVT,而 对 于数据矩阵不断逼近是通过公式(3)优化矩阵来实现的:
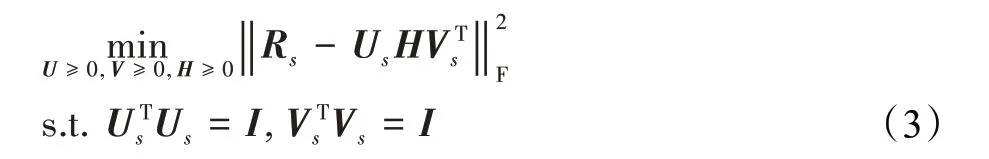
其中,Rs表示源域评分矩阵,I为单位矩阵,表示Frobenius范数,Us是用户聚类索引矩阵,Vs是项目聚类索引矩阵,H是一个K×L维的评分模式矩阵,代表K个用户聚类对L个商品分类的评分模式。
其中U和V是非负正交的,通过对用户和项目同时进行聚类,正交非负矩阵三分解模型利用用户和项目间的交互信息,从而会产生比其他聚类方法更加优化的结果。ONMTF方法的优化求解过程等同于同时对矩阵R的行和列进行K维和L维的协同K-means聚类。而非完备正交非负矩阵三分解(incomplete orthogonal non-nega‐tive matrix tri-factorization,IONMTF)在ONMTF的基础上松弛了对源域评分矩阵的完备性评分限制,使评分模式与目标矩阵更加近似相关。
2 CICDR算法
2.1 CICDR算法框架
为了缓解跨域推荐中的单个特征向量预测精度低的问题,本文提出了一种融合辅助信息的深度协同跨域推荐方法。同时融入描述信息和隐式反馈信息,以提取出包含更丰富语义信息的用户和项目潜在特征,进而改善目标域的推荐精度并减少用户反感项目的出现。如图1所示,本文提出的CICDR算法的基本框架包括潜在特征提取和目标域评分矩阵重构两个部分。为了同时利用评分信息以及两种辅助信息,即用户和项目的基本描述性信息与用户的隐式反馈信息,首先将Semi-SDAE和矩阵分解(matrix factorization,MF)相集成,以更为全面地提取用户和项目的潜在特征,进一步丰富源域的预测评分矩阵。
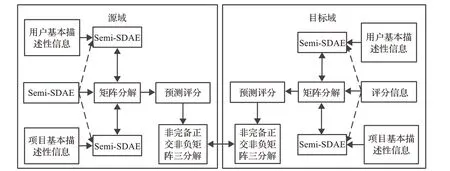
图1 CICDR框架Fig.1 CICDR framework
接着在源域和目标域中采用非完备正交非负矩阵三分解(IONMTF)生成可以链接两个域的附加关联矩阵,将源域中通过IONMTF提取到的评分模式迁移到目标域中,能够有效提高标域的推荐准确性。为了方便起见,表1总结了CICDR算法使用的主要符号。

表1 主要符号概要Table 1 Summary of primary notations
2.2 潜在特征提取
在本节中,详细介绍了基于Semi-SDAE的混合协同过滤模型的潜在特征提取,如图2所示。使用Rs表示源域评分矩阵,Rt表示目标域评分矩阵,Rij表示用户i对项目j的评分。为了便于描述,将域的索引表示为d∈{s,t}。对于两个域中给定评分矩阵Rd,矩阵的每一列作为各项目的评分向量,每一行则表示每个用户的评分向量。将辅助信息,即用户基本描述性信息和项目基本描述性信息分别用X和Y表示。辅助信息被视为一个整体,和评分信息一起直接作为Semi-SDAE的输入。
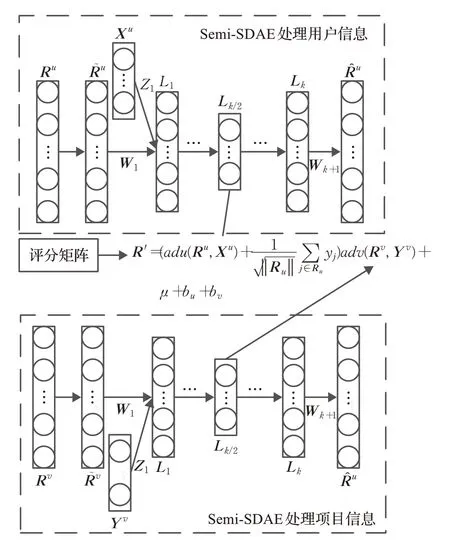
图2 基于Semi-SDAE提取潜在特征Fig.2 Extracting latent features based on Semi-SDAE
在两个域中,通过同时训练两种不同类型的Semi-SDAE,来分别提取用户潜在向量Ud和项目潜在向量Vd,中间层的输出被视为所要提取的用户和项目潜在因子。公式(1)表示的是Semi-SDAE从输入信息中提取用户潜在特征,类似地,可以将公式(1)中的u替换为v,将X替换为Y,提取项目潜在特征。通过这种方式,学习到的项目潜在因子不仅能反映项目的固有特征(从评分信息中提取),而且还反映了用户的偏好特征(从辅助信息中提取)。
本文提出的模型是一种混合模型,如图2所示。CICDR同时利用评分信息和其他辅助信息,并在源域和目标域中将Semi-SDAE和MF算法相结合以提取潜在特征。通常两个Semi-SDAE的中间层作为评分信息和其他信息之间连接的桥梁,这两个中间层是使混合模型同时学习有效潜在因子并捕获用户和项目之间相似性和关系的关键。因此,通过Semi-SDAE的中间层与矩阵分解进行结合。通过在两个域中获得的用户和项目潜在特征向量的乘积来近似得到更加稠密的预测评分矩阵。此外,在用户潜在特征向量中还新增一个隐式反馈特征向量,这部分表示用户u浏览过的项目之和。因此,在两个域中Semi-SDAE和MF相结合可以获得的预测评分矩阵R'd如公式(4)所示:
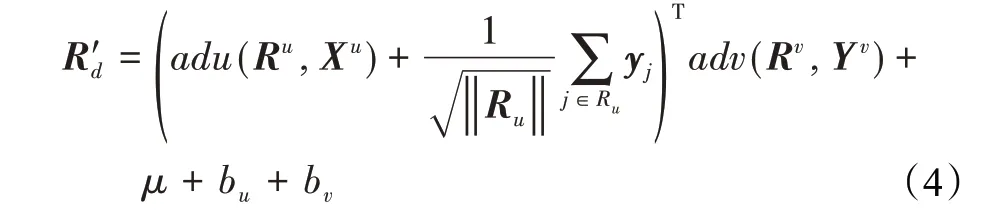
其中,μ表示整体平均评分,bu和bv分别表示观察到的用户u和项目v的平均偏置值,Ru是用户u所评分的所有项目集,yj表示隐式反馈向量,并且表示隐式反馈观点,adu(Ru,Xu)和adv(Rv,Yv)分别表示用户u和项目v的特征转换函数,Ru和Rv分别表示用户u和项目v的评分信息,Xu和Yv分别表示用户和项目所对应的辅助信息。从公式(4)可以看出,所提出的CICDR模型同时使用了评分信息、描述信息和隐式反馈信息,有助于更加充分地挖掘各种信息中所隐含的潜在特征加以有效利用。
然而,Semi-SDAE提取的特征不能直接与评分矩阵相集成,因为Semi-SDAE的特征空间与MF不一致,并且在编码器提取特征的过程中,对所有用户采用相同的权重,因此不同用户的特征之间会相互影响。为了将Semi-SDAE提取的特征集成到评分中,通过转换函数adu(·)和adv(·),将编码器的特征空间转换到矩阵分解特征空间,使两者所提取的特征能够深度融合,特征转换函数adu(·)和adv(·)的表达式如公式(5)所示:
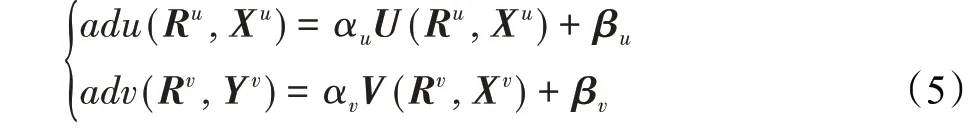
其中,αu和αv表示缩放系数,分别对Semi-SDAE提取的用户特征和项目特征进行缩放,对其进行随机初始化,更新规则如公式(14)所示,βu和βv分别表示用户的偏置向量和项目的偏置向量。
为了防止过拟合,通过λfreg实现正则化,目标函数可以表示为:
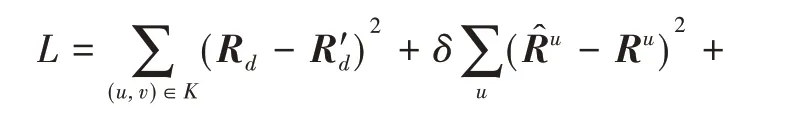

上述目标函数包含四个部分,第一部分表示预测评分的损失,采用平方损失函数,其中K为所有已知评分的项目集。第二部分和第三部分表示Semi-SDAE的损失,其中δ和ρ是两个权衡参数,主要用于控制编码器的特征学习。最后一部分是正则项,其目的是防止发生过拟合,其中λ表示正则项系数,freg的具体表达式如公式(7)所示:
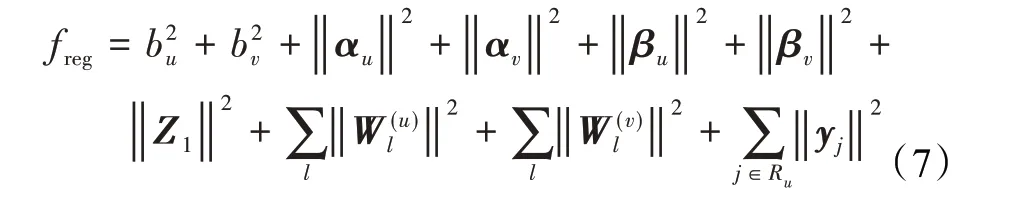
2.3 知识迁移和目标评分预测
在两个域中分别提取用户和项目潜在特征并得到更加密集的评分矩阵R'd后,使用非完备正交非负矩阵三分解(IONMTF)对两个域的评分矩阵进行分解,用户-项目评分矩阵可以分解为三个因子的乘积R'd≈UdHVTd,其中Ud是用户的聚类指标,Vd是项目的聚类指标,H是集群级别的用户项目评分模式。近似可以通过以下矩阵范数优化来实现:
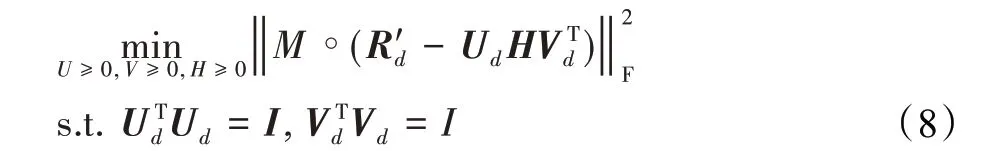
其中,Ud和Vd都是非负正交的,表示用户和项目的集群值。此外,添加矩阵M作为指示矩阵,当R'd≠0时Mij=1,否则Mij=0。操作符∘表示指标矩阵M和后面损失公式的哈达玛积操作,其有助于在求解优化公式时避免R'd中没有评分项目的影响。
从源域中提取评分模式后,可以将评分模式进行聚类得到密码本[18],目标域适配通过复制密码本中的行和列来学习目标评分矩阵中缺失的评分项目,然后通过Ut、B和VTt的乘积来得到近似结果。最后重建目标域评分矩阵,缺失值均由以下公式计算填充:
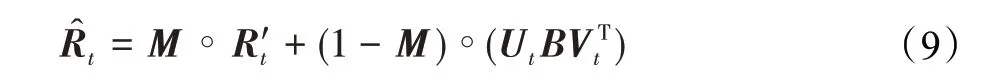
其中,M表示指示矩阵,∘表示哈达玛积操作,Ut和Vt分别表示目标域中用户和项目的聚类指示矩阵,B表示通过对源域稠密评分矩阵进行聚类得到的密码本。为了使预测值尽可能接近真实值,应该尽可能缩小用户的预测评分与原始评分值之间的平方误差,来为用户做出更准确的推荐。
2.4 CICDR模型算法优化
CICDR模型通过最小化公式(4)来学习参数。为了学习算法中的参数,需要设计合适的优化函数,但考虑算法中所有的变量,目标函数难以直接优化。而如果通过固定神经网络的权重,只优化矩阵分解中的参数,则目标函数更易于优化,因此本文采用随机梯度下降(SGD)作为一种优化选择,SGD通过以下方式来计算特征提取预测误差εuv:

同时,使用Q来表示转换后的特征之和,基于隐式反馈的角度在以下更新规则中使用:
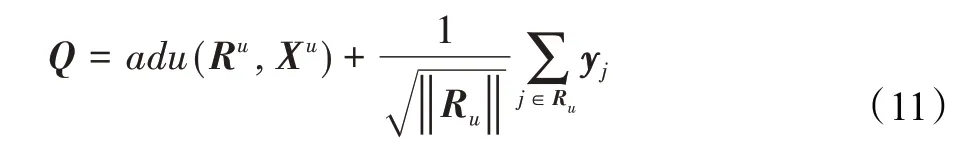
然后通过循环已知的评分信息来更新模型中的参数,更新规则如下:
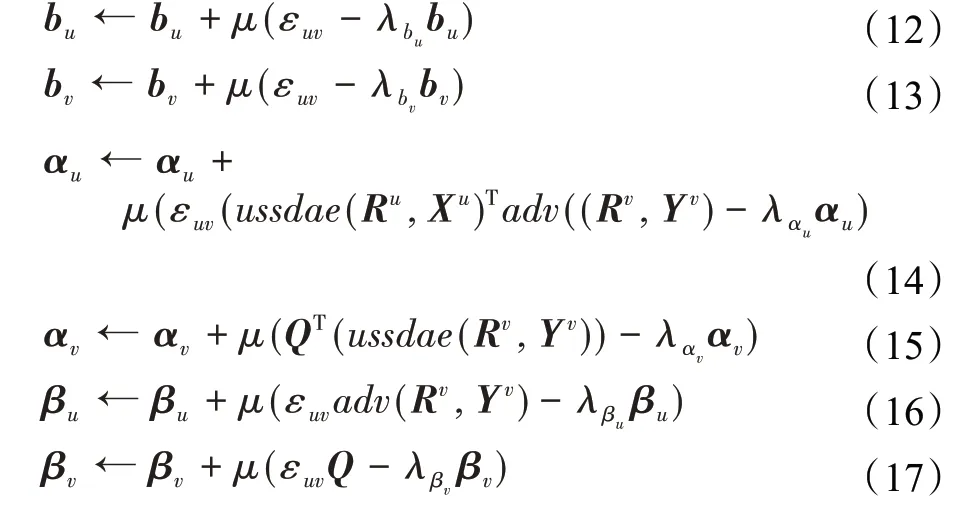
隐式反馈向量更新公式如下:
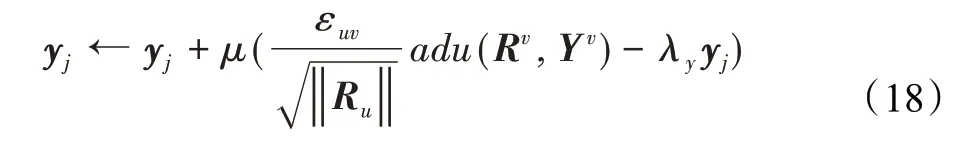
其中,μ是学习率,λi是学习参数i的超参数。
3 实验结果及分析
3.1 数据集
本文评估CICDR模型在电影和书籍推荐上的性能,实验在三个公共数据集上进行:MovieLens-100K、MovieLens-1M和BookCrossing。MovieLens-100K数据集由943个用户和1 682部电影的100K评分组成,而MovieLens-1M数据集由6 040个用户和3 706部电影的100万个评分组成,每个评分是1到5范围内的一个整数。它们的评分非常稀疏,其中没有评分的数据在MovieLens-100K数据集中占93.7%,在MovieLens-1M数据集中占95.8%。用户的辅助信息包含用户的年龄、性别、职业和邮政编码等,而项目的辅助信息包含电影类型和发布日期的类别等。BookCrossing数据集包含来自278 858个用户的1 149 780本书,其中每个评分都是0到10的整数,没有评分的数据占99.9%,其中还包含书籍和用户的一些属性信息,并将其作为辅助信息。
为了在电影推荐中合并辅助信息,辅助信息被编码成长度为139(对于用户)和28(对于两个域中的项目)的二进制向量。同样,对于书籍推荐,辅助信息被编码成长度为62(对于用户)和1 003(对于项目)的二进制向量。将三个数据集分为两对MLK(s)与MLM(t),BC(s)与MLM(t),其中一个充当源域,另一个充当目标域,使用随机选择的不同训练数据进行迭代训练并评测平均性能。
3.2 评估指标
CICDR将用户和项目辅助信息以及隐式反馈信息融入模型中,主要目的是提高目标域的推荐准确度。因此采用均方根误差(RMSE)、平均绝对误差(MAE)作为评估指标,分别定义为:
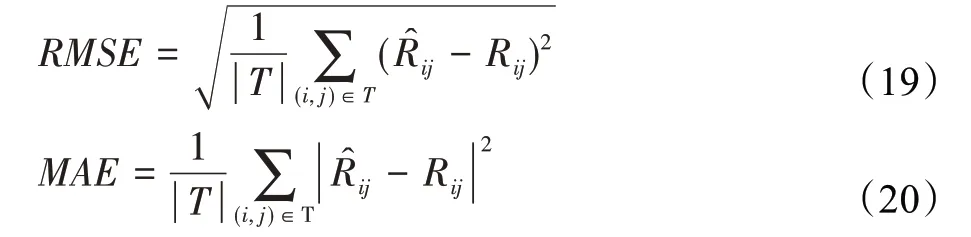
其中,Rij是目标域用户i在项目j上的真实评分,Rij表示相应的预测评分,T是测试集。
本文使用召回率Recall@K作为另一个评估指标,因为很多辅助信息是以隐式反馈的形式出现的。具体来说,另一个常见的指标即准确度不适合用于评测隐式反馈的推荐,因为用户-项目评分矩阵中没有评分的项目可能是由于用户对项目不感兴趣,或者用户不知道它。为了评估本文的深度协同跨域模型,通过对每个用户的所有项目的预测评分进行排序,然后向每个用户推荐前K个项目。每个用户的Recall@K定义如下:
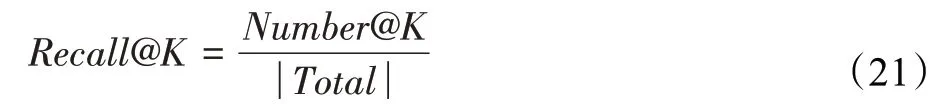
其中,Number@K表示前K个推荐项目中用户喜欢的项目数,Total表示用户喜欢的项目总数。最终的度量结果是所有用户的平均召回率。
3.3 基准算法
为了评估CICDR算法的性能,本文在实验中考虑了以下各种方法。
CDL[20]:协同深度学习是一种分层深度贝叶斯模型,用于实现项目信息的深度表示学习和用户-项目矩阵的协同过滤。
aSDAE[21]:附加堆叠降噪自动编码器是一个单域推荐模型,其中辅助信息和原始评分信息通过自动编码器进行融合。
RC-DFM[22]:深度混合模型首先采用堆叠降噪自动编码器来学习潜在因子,然后利用MLP网络将用户潜在因子从辅助域映射到目标域。
DTCF[23]:深度迁移协同过滤是集集体矩阵分解和深度迁移学习于一体的推荐模型。
对于上述模型,实验以不同的评分百分比(60%、80%、95%)训练这些模型。从上述数据集中随机选取数据作为训练集,其余数据作为测试集。本文对上述模型的性能进行了五次评估,并使用平均RMSE和MAE作为结果。对于CICDR模型参数作出如下设置:δ=ρ=0.5,λbu=λbv=0.001,λαu=λαv=0.5,λβu=λβv=0.02,λy=0.05并且学习率设置为0.001。对于Semi-SDAE,输入输出维度设置为1 000,隐藏层维度设置为64,此外,使用噪声级别为0.2的高斯噪声对初始输入数据加噪。
3.4 实验比较和分析
表2和表3分别显示了在两对数据集上CDL、aSDAE、RC-DFM、DTCF和CIDCR模型的平均RMSE和MAE,其中每个数据集的最低值以粗体突出显示。
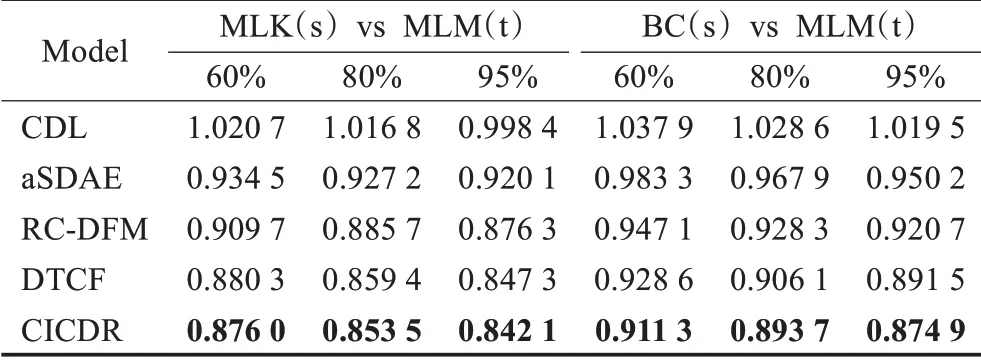
表2 在RMSE方面的性能比较Table 2 Performance comparison in terms of RMSE
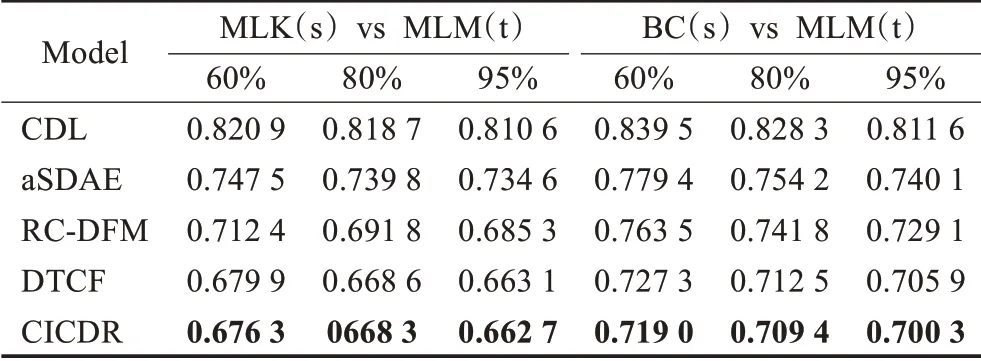
表3 在MAE方面的性能比较Table 3 Performance comparison in terms of MAE
本文分别评估几种模型在不同的评分百分比下的RMAE和MAE性能。从表2和表3中可以得出结论,aSDAE、RC-DFM、DTCF和CICDR模型的性能优于CDL,这表明深度融合各种辅助信息的有效性。与CDL和aSDAE相比,其他三种跨域算法在一定程度上提供了较好的结果,这是因为跨域推荐试图为目标域中没有反馈的冷启动用户做出更准确的推荐,而CDL和aSDAE是一种单域推荐算法,其性能取决于用户历史信息的丰富程度,且辅助信息较为稀疏未能充分挖掘其中的潜在特征。此外,还可以观察到,DTCF和CICDR结果较为相近,两者都采用集体矩阵分解与深度迁移学习相融合,而CICDR略优于DTCF表明跨域推荐中融合隐式反馈信息可以提高推荐的准确性,且使用IONMTF进行矩阵分解实现知识迁移略优于ONMTF。从表中还可以看出,MLK(s)vs MLM(t)的性能优于BC(s)vs MLM(t)数据对的性能,因为BookCrossing和MovieLens-1M数据集之间相差较大,而跨域迁移学习能从更相近的域中传输更多的信息。
通过表2和表3可以看出,本文提出的CICDR模型在不同评分百分比情况下,RMSE和MAE的值均优于其他几种算法。这意味着融合包括隐式反馈信息在内的多种辅助信息的跨域推荐算法可以较好地为用户提供个性化推荐,从而为缓解目标域冷启动用户问题提供了一个可行的方法。
图3显示了MovieLens-100K数据集上的Recall@K结果,其中在RMSE方面将四个优越的基线与CICDR模型进行比较。如图3所示,只考虑了在60%和80%训练数据下的情况,因为在95%训练数据的情况下,这些模型的表现大约接近1,所表明的信息有限。此外,观察到DTCF和CICDR有很大的重叠,表明它们在Recall@K方面属于一类,发生重叠是因为模型的影响小于数据结构的影响。尽管如此,即无论K在10到50的范围内发生什么变化,本文模型都优于基线模型。
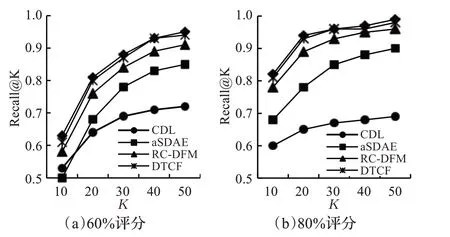
图3 Recall@K方面的性能比较Fig.3 Performance comparison in terms of Recall@K
3.5 时间复杂度分析
图4 显示了在lbt规模下的CPU时间比较。与单域推荐算法CDL和aSDAE相比,跨域推荐算法RC-DFM,DTCF和CICDR的高效训练实现了时间复杂度的显著降低。同时,与RC-DFM模型相比,融合隐式反馈信息的CICDR不会降低训练效率。而与DTCF模型相比,因为CICDR模型融入了更多的辅助信息,且DTCF未使用矩阵分解融合隐式反馈信息,因此CICDR时间复杂度相对较高。
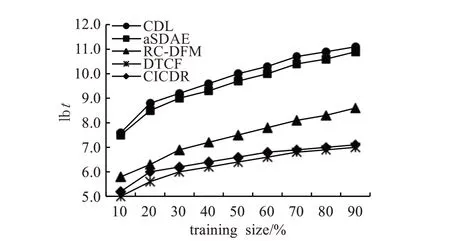
图4 Movielens-100K上一个epoch的训练时间比较Fig.4 Comparison of training time of one epoch on Movielens-100K
接下来为了验证本文特征转换函数的有效性,通过将特征转换函数从模型中移除并在单个数据集上进行实验对比,其他超参数如正则项和学习率等如上文所示,对比实验结果如表4所示。

表4 加入特征变换函数前后对比Table 4 Comparison before and after adding feature transform function
从表4可以看出,当从模型中加入特征转换函数之后,推荐算法的性能会提高很多,在三个数据集上都实现了更好的结果。由此可见,Semi-SDAE学习的特征和矩阵分解学习的隐式反馈信息是两个不同的任务,并不能直接将Semi-SDAE提取的特征用于评分预测任务。
4 结束语
在本文中,提出了一种深度协同跨域推荐模型,称为CICDR。它桥接了深度学习模型Semi-SDAE和矩阵分解,并实现了跨域推荐。CICDR模型结合了协同过滤和迁移学习的评分模式,以逼近目标域并预测缺失值。特别是,通过考虑负迁移的影响,自动学习从源域到目标域信息的权重,获得了稳健的推荐。综上所述,CICDR模型更容易扩展到更大的数据集,而不会损害推荐性能和计算成本。作为未来工作的一部分,将研究其他深度学习模型来替代Semi-SDAE以进一步提高性能,例如循环神经网络和卷积神经网络。其次,将利用文本、视觉信息等丰富的项目内容信息,通过神经网络获得更丰富的特征表示。同时,可以通过结合时间动态和社交网络信息来进一步改进所提出的模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
哈尔滨工业大学学报(2022年5期)2022-04-19
河北理科教学研究(2021年3期)2022-01-18
发明与创新(2021年39期)2021-11-05
科学家(2021年24期)2021-04-25
计算机技术与发展(2020年11期)2020-12-04
中国交通信息化(2019年10期)2019-11-16
青年文学家(2015年29期)2016-05-09
汽车文摘(2015年11期)2015-12-02
