
基于车联网大数据的行驶工况构建
2022-12-17 12:32崔海龙王书庆车兆伟
小型内燃机与车辆技术 2022年5期
崔海龙 王书庆 车兆伟
(北汽福田汽车股份有限公司 北京 102206)
引言
行驶工况最早由欧盟、美国和日本等汽车工业发达国家提出并应用。行驶工况可以作为车辆排放试验和燃油经济性试验方法和限值标准的基础。中国早期引入欧盟WTVC 工况,通过调整加速度和减速度,演变成C-WTVC 工况,作为中国重型商用车法规测试的标准工况[1],2019 年颁布的《中国汽车行驶工况》[2]第2 部分,重型商用汽车引入了基于中国道路和中国车辆开发的6 种重型商用车中国工况。
中国汽车行驶工况具有法规性质,是车企产品指标定义、产品认证和技术交流的重要依据。中国幅员辽阔,地势从西到东分成3 级阶梯递降,南北气候差异大,道路按行政等级可分为国家公路、省公路、县公路和乡公路以及专用公路五个等级。重型商用车客户行业各有不同,直接造成使用工况千差万别。
按照人、车、货和场若干要素构建的应用场景,根据不完全统计,中国重型商用车应用场景有200多个。企业开发产品最终面对的是细分化市场,没有可以适应所有细分化市场的万能产品,也不可能开发无限多样化的产品去对应每一细分化市场。
企业选取的典型工况以能够覆盖全部工况为主要目的,兼顾主销区域和企业战略要求,在安装车载终端T-Box 的车辆范围内寻找典型用户。为了保证取样样本具有代表性,同时考虑采集过程中可能发生个别典型用户数据丢失,必须保证典型工况的典型用户满足一定的数量要求。基于用户大数据构建用户真实的行驶工况,优化传动系统配置,通过Cruise 仿真分析和整车转毂测试,验证方案的有效性,从而在推出的下一代产品提升客户动力性和燃油经济性体验。基于多个应用场景的用户行驶工况数据库建设,合并同类项,明确定义各类应用场景适用的产品群集,企业销售符合应用场景定义的产品,实现企业和用户双赢。
1 应用场景定义
按照人、车、货、场四个要素,定义应用场景,以某物流车为例。行驶工况构建首先确定用户(人)的范围,组织客户和个人客户都具有一定的代表性,因此进行混编放入同一应用场景,为了保证样本具有一定代表性,通常选择不少于20 辆车,车辆配置相同。通过用户访谈,了解研究对象车辆载重量、货物类型、运输路线、运输类型等确定车、货、场等要素,确保与工作策划内容相符。采用自主驾驶法,即用户自主定义运行时间和运行路线,不进行干预。通过T-box 采集CAN 总线数据包括时间、车速、转速、负荷、里程、经度和纬度等信息,数据采集频率1 Hz。T-Box 将数据传输到平台,平台下载数据用于分析,如图1 所示。

图1 数据采集示意图
2 载荷分析和行驶轨迹分析
2.1 载荷分析
一个月的大数据采集完成后,基于Matlab[3-5]开发的数据处理软件进行基于时间、里程维度的大数据分析,提炼工程工况信息,如车速分布图和转速分布图等,如图2 所示。

图2 车速分布图
从图2 车速分布图看,车速分布特点与里程强相关。从里程分布看,车辆60~90 km/h 占比54.05%,为常用车速,常用车速平均值为75 km/h,另外还可以得到25%分位数、50%分位数,75%分位数,平均车速等;从时间占比看,怠速占比29.63%最大,高车速范围占比与里程占比分布趋势相近。
2.2 行驶轨迹分析
用户车辆行驶轨迹也是重要关注对象,本文以某物流车用户工况为例,基于市场调研,该应用场景“主要围绕一二级批发市场转运,主要运输绿色通道产品,高速为主,单边运距500 km 以内。用户车辆中途、短途运输皆有,分布较广,基本满足应用场景定义。
3 行驶工况构建
T-Box 采集的车速数据如实记录了用户每天车辆启动、配货、送货和返回等全过程车速的变化情况。车速为零但发动机转速不为零的怠速停车工况,包含了车辆停车配货,路口等待的工作场景分布特点。用户行驶工况是对归类为同一应用场景的用户数据经过数学处理后生成的速度-时间曲线。
对于某物流车辆,将工况时长定义为1 800 s,即方便了与相关法规工况比较,
也便于在整车转毂实验室组织测试。一个月的用户数据超过1×107行(1 行表示1s 采集到的时间、车速、转速等数据),采用如下的方式,找到最适合的片段来构建用户行驶工况。通常按照如下流程进行工况构建。
3.1 工况定义
首先参照国际和国内法规及文献[6-11],确定行驶工况分为以下四类工况:加速工况、减速工况、匀速工况和怠速工况,对这四类工况划定准则如下:
1)加速工况
车辆行驶过程中的加速度a≥0.15 m/s2的工况;
2)减速工况
车辆行驶过程中的加速度a≤-0.15 m/s2的工况;
3)匀速工况
车辆行驶过程中的加速度|a|≤0.15 m/s2,且车辆行驶速度v≥1 km/h 的工况;
4)怠速工况
车辆行驶过程中的加速度a 的绝对值小于0.15 m/s2,且车辆行驶速度v <1 km/h 的工况。
3.2 片段分割
编写行驶工况构建程序,大数据先存入数据矩阵。对数据有效性进行确认后,逐车将大数据切割成片段。
在实际采集过程中,会有数据丢失造成的空白行,数据丢失超过30 s 的作为片段的始点,如果数据丢失小于30 s,插值后也作为片段的始点。片段长度大于300 s 需要再次进行分割,最终分割好的片段时间长度介于150 s 到300 s 之间。计算分割后片段的车速加速度分布矩阵(VAD)分布并保存,如图3所示。

图3 车速加速度分布矩阵
车辆加速度为

式中:ai是i 秒加速度,单位m/s2;vi+1是i+1 秒车速,单位km/h;vi-1是i-1 秒车速,单位km/h。
计算分割后片段的特征值,有基于时间的特征值,也有基于车速的特征值,包括平均车速,基于加、减速度和时间占比的特征值等等,并保存。
3.3 片段分组
片段分组一般分成城市、郊区和高速三种区间,基于海量大数据定义各区间参考值,如表1 所示。

表1 区间车速参考值
不同应用场景的实际车速区间不同,按照自主驾驶法采集的数据无法和交通流数据对应。按照具体应用场景车速分布,对车速区间进行修正,各区间修正值都取整为5 的倍数。
高速区间取常用车速平均值、75%分位数车速和高速参考值的中位值,修正为最靠近一个取整值,如表2 所示。

表2 高速区间车速 km/h
郊区区间取郊区参考值、平均车速和50%分位数的中位值,修正为最靠近一个取整值,如表3 所示。
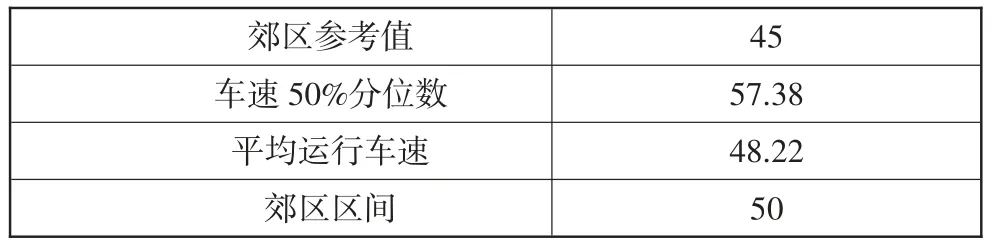
表3 郊区区间车速 km/h
依次类推获得城市区间车速,如表4 所示。

表4 城区区间车速 km/h
3.4 主成分分析和片段评价值计算
3.4.1 大数据主成分分析
车辆大数据部分片段和特征参数见表5。可以将特征参数作为原始变量进行主成分分析,获得主成分及其对应的贡献率和特征值,以及每一个特征参数对应每一个主成分的成分值。将主成分按照从大到小贡献率排序,并从大到小依次累积计算贡献率和,将贡献率和大于或等于预设贡献率的主成分确定为特征参数对应的主成分。
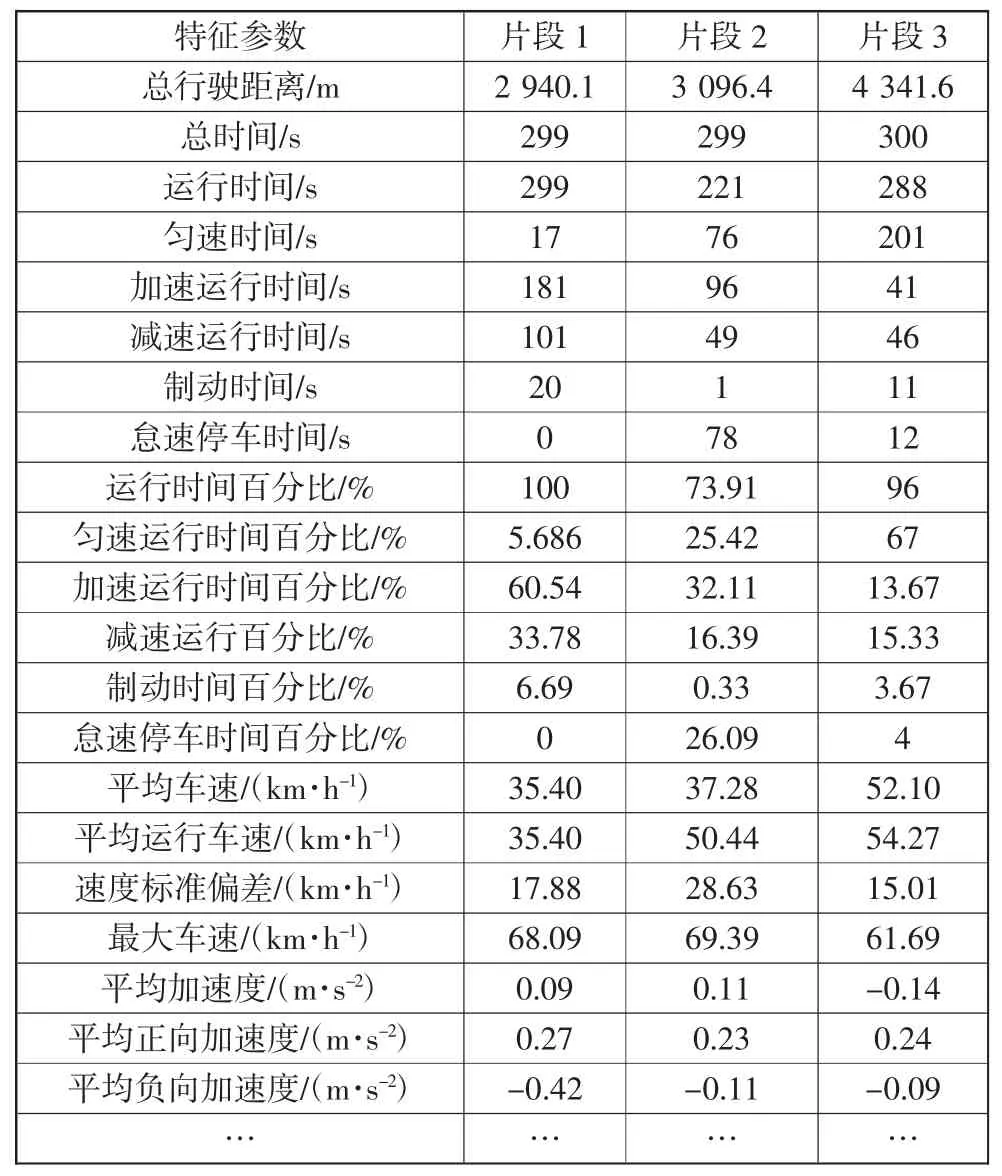
表5 片段特征参数表
图4 是碎石图,得主成分1、2、3、4 和5 等分别对应的主成分特征值。

图4 碎石图
如图5 所示,主成分1、2、3、4、5 和6 的贡献率已经达到88%,在预设贡献率为90%的情况下,认为主成分1、2、3、4、5 和6 中包括的特征参数的信息量可以近似代表特征参数的总信息量,从而将主成分1、2、3、4、5 和6 作为特征参数对应的主成分。
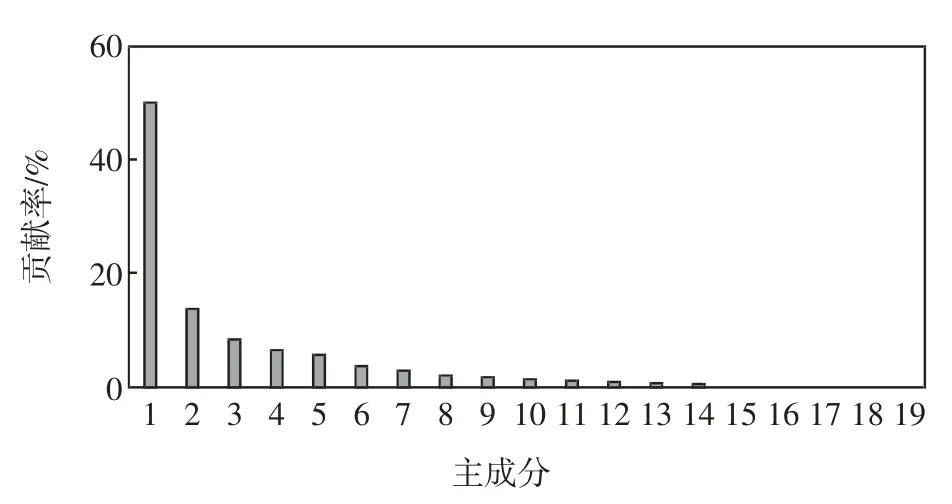
图5 主成分分析贡献率
以特征参数在主成分分析贡献率作为每一种特征参数的权重,通过归一化处理后,从而获得每一种特征参数对应的权重系数。
3.4.2 片段评价值计算
计算城市、郊区和高速区间各片段的特征参数平均值,特征参数平均值可以通过公式(1)计算得到,如下所示:

式中:Ai是第i 个特征参数的平均值,是该区间片段总数,Di是第i 个特征参数值。
片段的评价值,可以通过特征参数值、特征参数平均值、权重系数等计算工况片段对应的评价值:
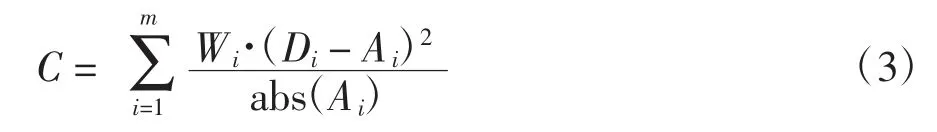
式中:C 为评价标准;m为特征参数编号;Wi为权重系数;Di为片段第i 个特征参数值;Ai为片段第i 个特征参数平均值。
将特征参数平均值作为实际工况的期望值,则通过上述公式(2)计算得到的评价值越小,则各工况片段特征参数越接近实际工况的期望值,工况片段越接近实际工况。
3.5 用户行驶工况合成
按照城区、城郊、高速的顺序,先后挑选各区间与评价标准靠近的片段,逐步构建用户行驶工况,即合成1 800 s 速度-时间曲线,如图6 所示。

图6 用户行驶工况
4 用户行驶工况校验
4.1 用户行驶工况校验
对实施构建的用户行驶工况进行特征参数的获取,并比较了用户行驶工况的特征参数与实际工况(车联网大数据)的特征参数。多数特征参数误差<5%,少数参数误差介于5%~10%之间,个别超过10%,如表6 所示。

表6 用户行驶工况与实际工况比较
行驶工况的车速分布与实际工况车速分布也进行了比较,一般车速区间误差都在5%以内,个别车速区间误差介于5%~10%,基本符合实际工况,如图7 所示。

图7 车速分布比较
4.2 试验验证
在整车转鼓台架,输入生成的用户行驶工况1 800 s 时间-速度曲线,验证内容包括工况曲线的可操作性以及工况对能耗的影响。
跟随性试验测试原则和判定方法参考GB/T 27840-2011 中关于试验公差的要求,即其速度偏差不应超过±3 km/h,每次超过速度偏差的时间不应超过2 s,累计不应超过10 s,试验结果如表7 所示。

表7 跟随性试验结果
当试验车辆不能达到试验循环的加速度或试验车速时,司机会将加速踏板完全踩到底;当试验车辆不能达到试验循环规定的减速度时,应完全作用制动踏板直至车辆运行状态再次回到试验循环规定的偏差范围内。
由上可知,错误数和错误时间都满足验证要求,即某物流车用户行驶工况车辆的可行性和跟随性方面是良好的。
4.3 仿真分析与转鼓试验对比
获取实际用户使用车型配置信息,将数据输入Cruise 软件进行模拟仿真计算,见图8。在软件计算任务界面导入需要仿真的工况(时间-车速曲线)、转鼓驾驶员实际操作参数(换挡转速、换挡操作时间等),使仿真更贴近实际。
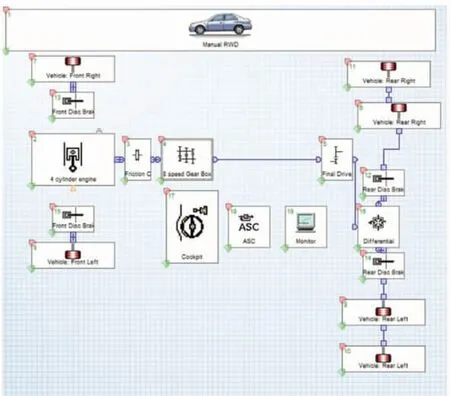
图8 仿真分析模型
仿真计算完成后需要进行校核,导出结果中工况运作的时间-车速曲线,使用Excel 进行绘图与导入工况进行对比。如图9 所示,与试验验证测试原则和判定方法要求相同,如果有区间不满足要求,则需根据实际情况调整模型车辆最大制动力或者进行部分区间降挡加速。

图9 仿真工况与试验工况比较
对比表8 仿真和试验结果,差异在可接受范围内。分析结果差异性原因可以从以下几方面入手:

表8 仿真与试验结果比较
1)对比仿真导出时间-车速曲线与试验导出时间-车速曲线,分析主观驾驶造成的影响;2)依据时间-挡位变化,对比两者差异,分析影响;3)发动机数据、传动系统各部分效率、附件功率等客观因素差异分析;4)试验仪器、燃油消耗测量方法等系统误差分析。
5 结论
本文完成了基于车联网大数据,构建用户行驶工况及应用的开发工作,得到如下结论。
1)对真实用户使用工况进行深入研究,定义了基于人、车、货、场四个要素的应用场景,并进行了分类。按照某物流应用场景的定义,定义用户车辆清单并采集大数据。
2)对车联网大数据分析,获取实际工况车速分布特征,同时分析行驶轨迹确认用户定义的符合性。
3)开发构建了用户行驶工况流程和方法,完成用户行驶工况构建。
4)对比了用户行驶工况和实际工况(用户大数据)特征值和车速区间,基于里程分布大部分特征值误差<5%,少数介于5%~10%,个别超过10%,两者基本一致;对比了安排在企业的转鼓台架进行行驶工况试验,跟随性试验结果满足GB 27840 试验要求。
5)对比了仿真分析结果和转鼓试验结果,偏差在±5%范围之内,具有较好的一致性。
基于车联网大数据构建的用户行驶工况,满足了对细分市场和特定应用场景研究的需求,可以便利地进行各种工况比较,指导经济性和排放测试工作,将大大缩短产品研发工作周期和费用。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
中国外汇(2019年13期)2019-10-10
装备制造技术(2018年8期)2018-10-17
汽车维护与修理(2018年1期)2018-04-04
制造技术与机床(2017年11期)2017-12-18
作文周刊·小学一年级版(2017年27期)2017-08-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电测与仪表(2015年7期)2015-04-09
