
基于流计算的锅炉高温管壁金属寿命指标管理方法研究
2022-12-12 12:14:58周宇阳陈东娃
化工自动化及仪表 2022年6期
刘 阳 徐 凯 周宇阳 何 成 李 伟 陈东娃 廖 杰 叶 凌
(1.国网新疆电力有限公司电力科学研究院;2.新疆新能集团有限责任公司乌鲁木齐电力建设调试所;3.上海朴宜实业有限公司;4.新华控制工程有限公司)
化工热力车间与电站的锅炉设备由于燃烧调节不当、过热器、再热器等受热面热流控制欠妥,以及壁温监测不到位等因素, 部分受热面长期在超温状态下运行,造成高温管路超温,进而出现锅炉爆管的事故,严重影响锅炉的安全运行[1,2]。据国产大型机组非计划停运次数统计,由于高过(高再) 爆管造成的非停次数占总非停次数的40%~50%。
有条件的企业在锅炉基建的时候设计了更多的壁温测点,以全方位检测高温管壁受热部件的温度变化。 部分在役锅炉也利用大修期增设了壁温测点,其原则是在不改变锅炉原测点的基础上,在容易超温的部位增加壁温测量密度,例如某2 000 t级锅炉针对整体设计及运行状况的分析判断,结合高温受热面在炉膛宽度方向管壁温度分析后增加了壁温测点,原测点与增加的壁温测点对比如下:
末级过热器 原76测点,增设后460测点
分隔屏 原36测点,增设后250测点
末级再热器 原45测点,增设后200测点
增加测量密度会增加较多的建设和维护成本,其获取的信息收益并不可观。 对于没有条件增加测点的锅炉,更需要寻找到低成本高收益的金属寿命管理方法,赖儒杰和范启富在引入寿命预测机器学习算法时注意到了与传统信号处理渠道相结合的优势[3],裴峻峰等基于寿命数据进行可靠性分析时充分利用了数据统计的特征值[4],陈东升及李卓漫等在各自寿命导向的研究中均重 视 了 数 据 挖 掘[5,6],即 便 采 用 不 同 的 检 测 手段[7],数据的有机融合也是其中突出的要点[8,9]。
因此, 基于DCS充分利用已有测点的实时与历史信息是一个现实的选择[10,11]。 对于DCS的分散处理单元DPU而言, 基于时间断面进行逻辑分析计算的特征不能处理金属寿命这种具有历史信息的参数,需要进行功能拓展,笔者探索了一种挖掘现有测点的时空内在联系的方法, 在DPU上建立流计算能力,通过流计算对壁温测点进行多方位的信息分析,为高参数、大容量锅炉高温管壁寿命指标管理提供一种新的方法。
1 通过流数据拓展测点信息
高参数、大容量锅炉的特点之一是同屏管子数目较多,因为锅炉容量增大时,锅炉的宽度并不成比例地增大,根据数据统计,锅炉的宽度大致与容量的0.7次方成正比,其必然导致过热器再热器的同屏管子数目增多。 例如超临界锅炉的末级过热器同屏管子有20根,屏式过热器的同屏管子多达28根。 同屏管子数目增多使同屏各管的热偏差增大,外圈管较长而蒸汽流量小,辐射吸热量却比内圈管大,双重的影响会使外圈管的温升比内圈管大得多,从而造成超温。
锅炉高温管壁金属寿命指标管理中的壁温指标考核系统是常见的工程手段, 具有简明、易行的特点,不过弊端也很明显,这是因为指标考核是一种异常或故障产生后的被动警示机制,它能够提示运行人员的运行失当并且执行相关惩罚措施,而不能起到预示作用;另外,指标考核是一种固化的判别模式,对于超温等失当行为不能根据实际的持续伤害给出判定,也不能直观地给出实际损失的大小;同时指标考核办法只着眼于当前的损伤,不计及当前损伤对象的累积损伤情况,使得炉管不同生命周期受到相同伤害时得到的是相同的防护提示。
究其原因,锅炉壁温指标考核是基于运行参数实时数值集合而建设的管理体系,在进行壁温超限的伤害评估时,缺少以下视角:其一,从寿命消耗分数来讲, 不同工况下的寿命消耗是不同的;其二,从寿命的不同周期而言,同一个消耗量所带来的实际损害是不同的;其三,对于同一次寿命消耗行为,不同的延续时间所带来的实际损害也是不同的。
显然孤立地看待现有测点集的实测值,所能提取的信息确实有限,但是每个测点从时间和空间的维度上来说却具有丰富的信息:从时间维度而言,每个壁温的实时值都处于不断演变的过程中,其变化趋势、幅度、加速度等可以充分展现流动与传热等因素的不同影响作用;从空间维度而言,每个测点与相邻测点之间具有一定的协同性和一致性,可以体现壁温的区域特性,达到以点概全的效果,也能够在测点缺失或者故障时帮助进行甄别和替换,起到查缺补漏的作用。 因此,充分利用好现有测点在时间和空间上的内在联系,更大地发挥其作用是一个切实的需求。
为了使得锅炉高温管壁寿命指标管理能够以在线、闭环的方式进行,应在成熟并且应用丰富的DPU上拓展流数据的处理和计算能力, 一方面,锅炉高温受热面寿命计算与分析可以充分利用DPU的优势;另一方面,运行效率与设备寿命竞争的应用与自动控制相结合,成为融合的、在线的智能应用,例如在材料老化条件下针对锅炉运行效率和锅炉设备寿命竞争的控制优化策略,则是流计算和逻辑计算的综合应用,具备流计算能力的DPU既能实施流计算分析, 也能实施竞争性的控制优化。
DPU在处理数据采集、标度变换、报警限值检查、操作记录与顺序事件记录、逻辑控制等方面能力较强, 但是普遍缺少流数据的计算能力,即对宽载的、具有流特征的数据缺少处理和分析能力,而只能对单载的即时时间断面上的数据进行处理,所实施的计算大部分限于逻辑计算,即DPU逻辑组态的模块之间只能批量传递单个模拟量或开关量,不能读写、传递、计算流数据。
建立基于流计算的锅炉高温管壁寿命指标管理方法,首先为需要监测的壁温测点给出专用标识,拥有该特征字段的测点自动归类为一个数据流;其次针对每个流数据设置流特征值,包括压力与温度边界条件、持续寿命消耗情况、流最大值、平均值、均方差值、概率密度值等,还包括机组检修情况简报,例如金相检测内容、氧化皮探测厚度等,流数据中容纳了这两类信息,就对该测点所代表的管段的历史检验情况和历史运行情况(包括累积情况)有了基本了解,进而对超温发生时的实际损害有了更透彻的认识。
2 基于DPU建立流计算
在逻辑计算能力的基础上拓展流计算能力,DPU需要从标识、存储、取值与传输等方面进行功能扩充,使得DPU兼容流数据的处理能力。具备流数据处理能力的DPU可为流计算单独使用而不含逻辑计算的功能,从原理上讲与兼容流计算和逻辑计算能力的DPU在硬件结构上是一样的, 在软件功能上具有兼容性。
2.1 寿命分析数据的流数据化
流数据的长度是指流数据在时间维度上的度量,流数据具有的时间标戳作为分割流数据长度的唯一标记,唯一而非连续。 唯一是指时间标戳的墙上时刻是唯一的;非连续是指流数据的时间标戳并非按照严格的墙上时间间隔,而是根据流计算等实际应用的特征进行筛选。
流数据的宽度是指流数据在空间维度上的度量,流数据具有的空间标戳作为分割流数据宽度的唯一标记,唯一且连续。 连续是指流数据的空间标戳根据实际应用对象的定义而依序排列,并且其空间上的相邻数据也被严格标戳,具有唯一性。
流数据化需要依照长度和宽度两个维度对测量数据进行标识、存储、取值与传输,即在DPU中对流数据进行特征字段标注, 将流数据从DPU的输出通道存放到本地或者网络的内存或者磁盘文件中,反之则读入DPU输入通道,在全局数据库中进行流数据的页间传递、网间传递、并行传递等。 为了实现上述目的,需要实施以下技术步骤:
a. 为需要纳入流数据的测点给出专用标识。标识为DPU通用点表的一个特征字段, 在所有的DPU及其网络中通用,具有标识的唯一性,即拥有该特征字段的测点自动归类为一个数据流。 DPU的通用点表一般能够实时修改实时生效,否则需要离线修改完成后重启DPU及其网络。
b. 为流数据设置特征值算法以及特征值判断依据。 特征值为流数据宽度方向的数值特征统计值,为实现实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分。利用流数据特征值进行流数据价值判断的依据时,当流数据特征值满足判据,为具有存储的价值,并且可被实时或者后续调取,构建流计算。
c. 为流数据创建存储空间并且写入。 首先根据所定义的流数据分别建立头文件,头文件中包含了对应流数据的全部索引; 根据头文件的索引,满足特征值判据的流数据被实时、批量写入存储空间,写入的数据具有时标和空间标记。 当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上受限于磁盘空间的无限长。
d. 取值并且传输流数据。流数据取值的批次和大小受限于实时数据库中预设的空间大小,按照一定的长度读入。
DPU定义如通用点表、KKS编码、Tag名(测点名)、特征字段、全局数据库等均采用DPU现有架构, 并且对DPU已经具备的逻辑计算能力不做修改,流数据的二维处理方法对逻辑计算能力没有影响,基于流数据开展的流计算兼容原有的逻辑计算。
建立流计算时不区分单个独立的DPU或者多个并行的DPU,也不区分本地应用或者网络应用,不过如果寿命分析数据的流数据应用于并行环境或者网络应用,需要在网络广播包中为流数据类型定义流数据缓冲,方法与公认的网络广播包的定义并无不同。
DPU具备了流数据支持, 进而能够具有基于流计算的建模和在线校验能力,使得金属寿命分析这种具有历史追溯的计算可以基于DPU布署并且展开。
2.2 金属寿命流数据的处理流程
流数据的标识包括流数据长度和宽度维度上的标识, 流数据宽度维度上的标识是指DPU全局数据库中归属于特定流数据的测点的特定标识。 特定流数据是指被纳入分析的一组测点,例如材料老化条件下跟锅炉某个区段寿命相关的一组测点,特定标识是指给这一组测点的每个测点定义特征字段。 特征字段是指全局数据库中每个测点都具备的特定字段, 在所有的DPU及其网络中通用,拥有该特征字段的测点自动归类为一个数据流。
特征字段通常以XYZ的样式表达, 以前例说明,其中X为某锅炉设备代号,以设备英文首字母表达,Y为某区段代号,以英文字母依序表达,从A到Z代表26个区段,Z为流数据复用标志, 可以为0~9、A~Z中任意一个,当Z为0时,该测点不复用,否则可复用。例如SD0特征字段代表过热器第D段所有的管壁温度并且不被复用;若该流数据中的某个管壁温度的特征字段被标识为SD1, 它同样归属于过热器第D段所有的管壁温度这个流数据,但是也可以被其他流数据复用,归属于一个新的流数据,这个新的流数据的典型特征是所有测点特征字段的末尾均为数字1。
更明确地,DPU以两种形式归纳流数据,一种方式依据XYw,以XY为标识而无论w,这是主要的归纳方式;另一种方式依据wwZ,以Z为标识而无论ww,这是辅助的归纳方式。 标识方法使得测点具有复用性,这种复用性使得本研究在归纳流数据时具有更大的灵活性。 例如前例中主要以过热器受热面为对象进行流数据归纳,在某些特殊区域,如折焰角处等,还需要以折焰角的整个覆盖面为对象进行流数据归纳。
流计算的流程(图1)具体如下:

图1 金属寿命流数据的处理流程
a. 头文件检查。不同的流数据具有不同的头文件,每一个头文件和该流数据所有的数据文件在单独的内存空间或者磁盘目录里面。
b. 流数据文件检查。当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上受限于磁盘空间的无限长度。
c. 流数据宽度检查。 对流数据在空间维度上的度量变化进行检查,当流数据宽度发生改变时进行头文件的尾添工作,即增加的测点信息被添置在头文件流索引的最后。
d. 数据的获取。 从DPU实时数据网络中,通过广播包的侦听,以流数据所包含的测点为单位获取实时数据。 由于测点复用的存在,流数据的获取存在同一个测点多次被获取的情形。
e. 流数据的特征值计算。特征值为流数据数值特征的统计值, 是以流数据宽度为维度的,亦即流数据空间上的数值特征的统计值,特征值计算为统计值的计算方法,为实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分,当流数据不需要进入存储环节时特征值自动抛弃。
f. 流数据的特征值判据判断。 利用流数据特征值进行流数据价值判断的依据,当流数据特征值满足判据时, 流数据被认为具有存储的价值,并且可被实时或者后续调取,构建流计算。 如果不满足,则继续获取流数据,当后续流计算需要补充这些数据时从历史记录中读取。 从历史记录中的读取需要进行流数据的格式转换。
g. 流数据的写入。当存储空间为内存空间时则写入内存,为磁盘空间时则写入磁盘文件。 当加密密钥不为0时, 根据预设进行流数据的加密操作,写入的流数据为加密后的数据。 每写入一个流数据,宽度计数自动增1,一个宽度的流数据写完后宽度计数自动清零。
h. 流数据宽度末位检测。 检查流数据写入的宽度计数是否达到流数据的宽度上限,若未达到则继续写入。 流数据的宽度上限为流数据时标个数+流数据内数据的个数+预留空间+特征值的个数,预留空间既为可能添加的流数据内数据所预留,也便于保持流数据的宽度基本一致。 通常流数据的宽度为128。
i. 流数据特征值的写入。 完成流数据特征值写入后,长度计数自动增1。
j. 流数据长度末位检测。 检查流数据写入的长度计数是否达到流数据长度上限,若未达到则继续检查流数据宽度是否改变,若达到则新建一个数据文件。 流数据长度上限计算式为数据文件预设大小÷流数据宽度÷浮点数字节数,数据文件预设大小为系统预设数值,一般为256 MB,最大不超过1 024 MB,浮点数字节数一般为4Byte。
2.3 金属寿命流数据的实时重建
应用流数据时,如锅炉壁温指标考核,首先定位流序号以及所需流数据的始末时间,当流序号与实际发生冲突时进行容错处理,冲突包括流序号未定义或者多重定义的情形。 当始末时间与实际发生冲突时进行容错处理,冲突包括始末时间与内存空间或者磁盘文件的早于最早开始时间或者晚于最晚结束时间的情形。 其次利用存储时设置的头文件从信息头获取流序号进行比对,确认后从信息头获取流宽度、流特征宽度、起始时间、终止时间、存储计数及加密密钥等,从特征头获取均值、大值均值、小值均值、调和均值、几何均值、最大值、最小值及均方差值等,从流索引获取KKS编码、Tag名、流内序号、左邻测点KKS编码、右邻测点KKS编码、上邻测点KKS编码及下邻测点KKS编码等。
接续根据流数据的KKS编码以及左邻、右邻、上邻、下邻测点KKS编码,完整重建出流数据在宽度维度上的排列,并与流内序号进行比对,当出现不匹配时进行容错操作。 不匹配包括测点删除、测点新增等情形。
根据重建并且容错的流数据排列以及所需始末时间,以流数据时标作为分割而非墙上时钟来读取流数据。 当加密密钥不为0时,取值的流数据为解密后的数据,再根据逻辑设定,在DPU的全局数据库中进行页间传递、网间传递及并行传递等。 以锅炉壁温指标考核系统为例,在每个计算周期内根据流数据重建出指定测点在时间和空间上的信息,纳入逻辑判断并给出壁温安全的提示和处理措施。
3 基于流计算的高温管壁寿命指标管理
某超临界锅炉全炉膛受热面壁温指标考核系统的主要功能如下:
a. 每分钟显示和记录1次炉内壁温和寿命损耗。 监测的管屏为末级过热器、屏式过热器、高温再热器、低温再热器及水冷壁等共3 340根管子的代表性壁温数据。
b. 如发生超温,则对记录的数据进行自动统计,显示和记录各点炉内壁温和寿命损耗,以备检修和技术改造时查询。
c. 显示锅炉中间点温度及其变化速率,可为燃烧调整提供依据。
d. 历史数据查询及自动生成各种分析报表等。
e. 其他,如预防发生煤水比失控、受热面严重结渣等故障报警, 受热面积灰和结渣的分析、报警等。
f. 在壁温计算的基础上即可对运行情况进行考核,在DCS上根据不同材料从低到高设置3个超温限值,表示超温情况从一般到严重。 同时针对设备的区间特性在不同超温区间内进行持续时间统计,按超温程度设置一般异常、异常、严重异常、二类障碍,每类障碍按照超温幅度和时长进行当值考核(表1)。
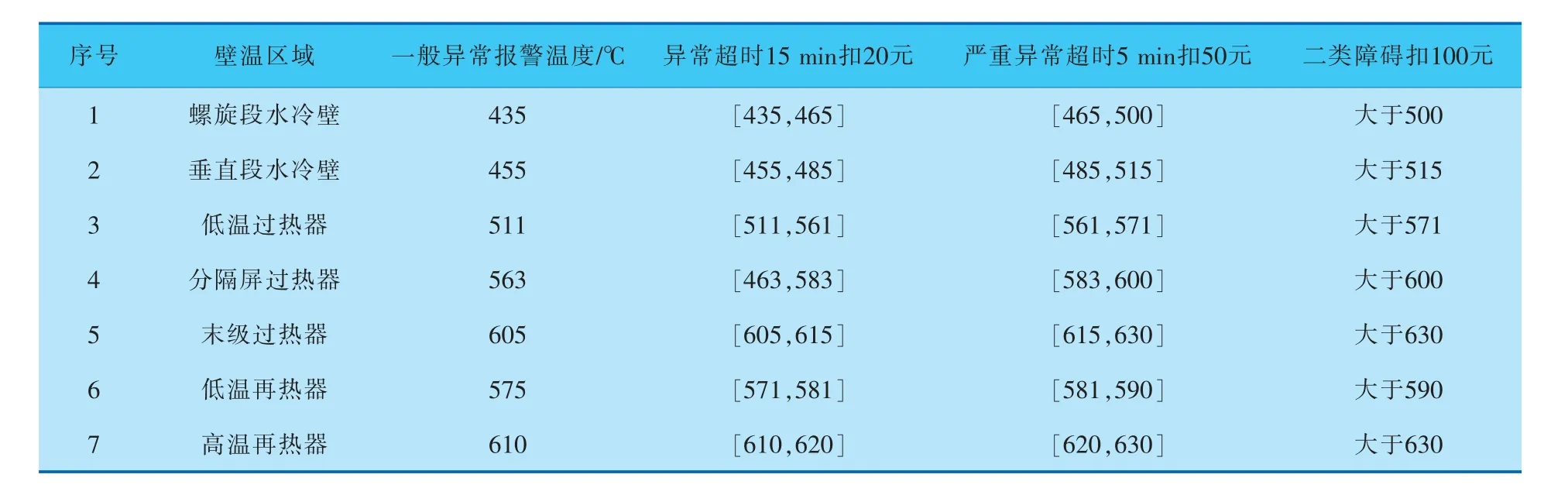
表1 壁温常规考核汇总
利用本研究方法建立基于流数据的金属寿命分析体系,考察数据库容量以及处理器运算能力以后,将所有壁温测点纳入监测范畴,根据前述分类方法进行归类,同时将故障多发管段标识为重点区域,给予更长和更宽的时空长度。
针对每个壁温测点的流数据设置流特征值,例如压力与温度边界条件、 持续寿命消耗情况、流最大值、流平均值、流均方差值及流概率密度值等。 另外,将机组检修情况的特征数据以预定的格式读入流数据中,DPU进入流计算模式,捕捉到的金属安全信息较改造前更为深入、细致。
例如,某锅炉在583.2 MW运行工况下,高温过热器末段发生持续性超温3次, 各次最高值/持续时间分别为610.0 ℃/8 min、619.2 ℃/2 min、606.6 ℃/14 min。根据常规考核标准,该项考核为0;而根据流计算,这3次超温折合“异常”行为1.5次,应予考核20元;再考虑到该段寿命消耗分数为0.59, 剩余寿命分数约为40%, 叠加考核折合“异常”行为0.5次,则累计折合“异常”行为2次,合计40元。
DPU流计算模式中还加入了班值的轮值信息以及具体班值中的易超温数值统计,以帮助理解班值的运行特征,防止习惯性的持久损害。 同上例,考虑到该班值过去30天内同一区段考核已经执行了5次以上,叠加考核折合“异常”行为1次,则累计折合“异常”行为2.5次,合计50元。
从工程实践来看,每个管壁流数据的大小约为1~2 KB数据量的存储空间,以现场典型控制器硬件配置(Intel Atom芯片,2~4 GB内存)而言,处理整个锅炉高温受热面的管壁温度约3~4 s,因此将相关的控制逻辑扫描周期设置为10 s左右,对于锅炉高温管壁金属寿命管理而言处理速度已经足够。
在每个扫描计算周期内,具备流计算功能的DPU完成流数据的维护, 同时利用流数据计算获得寿命偏差的历史趋势和未来预测,从而体现基于流数据的金属壁温精细化管理。 系统实时捕捉超温信息,并通过流计算实时对超温信息进行评价和考核,实现按值统计、计及历史的超温的精细化管理模式,督促运行人员有针对性地实施调整运行策略,从寿命的历史性角度出发降低超温频次,并且形成空间性联防联控,避免传统考核方式浮于表面的弊病。
4 结论与展望
锅炉高温管壁金属寿命的管理是金属安全的常规工作,尽管厂级监控系统通过实时数据库的广泛应用,为锅炉壁温指标考核系统提供了丰富的手段, 但从金属安全的管控一体化角度来看,为了有效落实“控”,仍然离不开单元机组控制这个层级,尤其在锅炉运行效率与锅炉设备寿命互为矛盾的前提下, 为了达到综合优化目标,实现两者之间在竞争机制下的控制优化策略,需要DPU具有金属寿命相关数据的处理能力。
本研究通过DPU流计算能力的拓展, 使得DPU处理金属寿命相关数据时, 不再局限于时间断面上的孤立数值,而是通过流数据将时空数据链接起来,形成丰富的表达能力,以常见的锅炉壁温指标考核系统为例,其对运行过程中超标越限的侦测能力大为增强,同时得力于流数据中纳入轮值信息,进一步指出班组的运行特征,把管控落实到班组操作行为上来。
由于流数据表征数据特性具有更宽阔的视野, 其特征值的选取与设计可以更加多元化,从而丰富金属寿命管理的工程应用,例如通过调节级温度的流数据监测保护汽轮机部件寿命等。 此外,DPU的流计算是一个通用思路,除了锅炉金属安全这个命题之外,还可以有更多的工程应用场合,例如通过中间点温度的流数据监测提高超临界变工况稳定性、速率等。
猜你喜欢
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
山东工业技术(2019年2期)2019-02-09 05:28:40
中国科技博览(2018年32期)2018-09-10 09:07:56
山东工业技术(2017年18期)2017-09-12 20:16:10
少儿科学周刊·少年版(2017年1期)2017-03-29 17:50:36
东北电力大学学报(2015年1期)2015-11-13 05:20:25
医学研究杂志(2015年5期)2015-06-10 06:43:26
人生十六七(2015年5期)2015-02-28 13:08:24
四川轻化工大学学报(自然科学版)(2014年3期)2014-04-16 03:56:42
