
基于融合深度兴趣进化单元的DeepFM边缘主动缓存模型研究
2022-12-12 12:14刘伦珲吴丽萍
化工自动化及仪表 2022年6期
刘伦珲 吴丽萍
(昆明理工大学信息工程与自动化学院)
5G时代是数据流量爆发式增长的时代,用户需求不断增加,用户通信业务体验要求也不断提高,移动应用的数量和种类不断增加,使得通信网络线路中数据和链路负载相对于前4G时代有了质的变化。而边缘缓存技术是应对当前5G网络大数据高负载问题的有效解决途径之一,受到许多学者的关注。 边缘缓存技术即在边缘网络节点基站上增加缓存空间, 缓存流行度较高的内容,可以缓解用户发起内容请求时从远端服务器到用户之间的高通信代价问题,以及由于内容过多导致的用户请求延时过高问题。 然而,因为有限的缓存空间和有限的计算资源不能缓存受大众欢迎的全部内容,因此在有限的缓存空间上研究更高效的缓存策略及算法模型是有意义和有价值的。
如今边缘主动缓存技术所面临的挑战主要有以下几个方面:
a. 在性能方面, 用户请求数量迅速增加,用户体验需求不断增高, 请求内容也更加复杂多样,现有缓存策略很难取得很好的性能表现;
b. 受到有限缓存空间和计算资源的约束;
c. 用户的移动性和地区差异性也为边缘主动缓存技术带来挑战。
为优化当用户请求内容不在缓存空间时所造成的通信高负载问题,同时使缓存更贴合用户偏好,笔者提出基于深度学习方法的分层缓存模型, 该方法将深度兴趣进化网络 (Deep Interest Evolution Network,DIEN) 中的兴趣进化单元与DeepFM模型相结合,利用兴趣进化单元中的兴趣抽取层分析用户兴趣时间序列,提取用户隐藏兴趣状态,再通过兴趣进化层对用户兴趣隐藏状态变化过程建模,得到最终的用户兴趣状态。 最后利用DeepFM模型对用户最终兴趣状态和用户信息、 目标内容信息和内容特征信息进行分析,以得到最终结果。
该策略的优势在于考虑了用户兴趣状态随时间和外部环境变化而变化的情况,使推荐缓存内容更加符合用户兴趣偏好,能够更好地应对用户兴趣大范围转变的情况,同时具有较强的泛化能力和学习能力,也能够更好地应对用户的移动性和地区间的差异性。
1 相关工作
1.1 传统边缘主动缓存技术
MÜLLER S等提出一种基于文本感知算法的主动缓存策略,通过分析关联用户的相关请求内容,学习特定的上下文信息,得出网络中流行度较高的内容,并进行主动缓存[1]。 ZEYDAN E等提出基于大数据框架的体系结构,利用协同过滤方法,对大量数据进行内容流行度预测,将预测内容缓存至基站,以此来达到更好的用户体验和更低的回程负载[2]。ZHOU S等则更加注重数据交付过程中的能量消耗,为了用更低的能量满足更高的用户体验需求, 提出新的绿色交付框架[3]。CHANG Z等利用大数据分析,从数据中获得用户流行内容偏好,设计边缘主动缓存策略,使边缘缓存性能提高[4]。BASTUG E等认为利用用户终端的存储空间和资源也是一个十分有效的方法,利用社交网络采用终端数据共享, 即终端到终端(Device-to-Device,D2D) 通信技术让缓存内容能在用户间共享,减少了基站缓存空间和计算资源消耗,同时利用上下文信息丰富了模型对内容特征的提取,进而制定了一个新的边缘缓存策略[5]。
1.2 基于深度学习的主动缓存技术
目前,深度学习方法在很多领域都取得了不俗的成绩,其较强的学习能力能更好地应对复杂的网络结构以及大量多样的数据。 GASTUG E等提出一种基于强化学习的多时间维度框架,该方法能使边缘节点基站更有效地利用有限的缓存空间资源,缓存用户更加偏好的内容,使用户使用体验度得到提升。
ALE L等提出将卷积层和双向RNN(BRNN)相结合的方法来提高预测内容的准确度,预测用户时间序列下一时刻可能的请求内容,并更新缓存在边缘节点上[6]。 DOAN K N等则利用卷积神经网络提取输入层特征,训练预测流行内容并缓存,以获得更高的用户体验度得分和更低的回程负载[7]。
综上所述,目前的边缘缓存技术虽然考虑了用户的行为时间序列,但并未考虑用户行为序列中并非每一个行为都对最终预测产生影响的情况,同时也不能很好地应对用户兴趣大范围转移的情况,且采用的深度学习模型虽具有很强的学习能力,但其泛化能力不足。
DeepFM模型既具有深度学习模型的强学习能力, 也整合了机器学习的泛化能力, 若利用DeepFM模型进行预测并加入对用户兴趣变化的考虑, 则有可能获得更符合大众喜好的缓存内容。
2 融合兴趣进化单元的DeepFM主动缓存模型
通信网络中用户的兴趣具有多样性,用户兴趣是驱使用户行为的关键因素,若能获取用户行为背后的潜在兴趣状态,则能为用户提供更感兴趣的内容。 但用户兴趣总是随着很多因素的改变而动态变化。 在融合了深度兴趣进化单元的DeepFM模型中,利用兴趣提取层获取用户的潜在兴趣并引入辅助损失值,来监督兴趣提取过程中的每一步潜在状态。 在兴趣进化层中利用加入注意力机制的GRU来获取用户与内容间的兴趣进化过程, 改变不同时间点用户的兴趣影响权重,并将该值与目标内容和用户信息记录输入至DeepFM。 根据最终结果判断该内容是否会被用户在未来时刻请求。
2.1 深度兴趣进化网络
兴趣进化单元源自阿里公司于2019年提出的深度兴趣进化网络, 在深度兴趣进化网络中,研究人员设计了兴趣提取层获取用户历史行为中的兴趣偏好。 用户兴趣具有多样性,因此研究人员又在DIEN中加入兴趣进化层,用来对用户兴趣演变进行建模、提取用户兴趣变化特征,并在其中嵌入注意力机制加强了相关兴趣对预测的影响,同时也削弱了不相关用户兴趣对结果的负面影响[8]。
深度兴趣网络首先通过嵌入层转化所有类别特征,将用户信息和内容信息映射到向量空间中表示。 接下来对用户兴趣进化过程进行建模:首先通过兴趣提取层对用户历史行为记录进行兴趣特征提取; 再通过兴趣进化层模型提取用户对目标内容相关的兴趣进化过程特征; 最后将得出的最终兴趣嵌入表示向量与用户信息特征和内容信息特征进行拼接, 并将该向量输入至MLP中进行最终结果的预测,其模型如图1所示,其中b(1)表示用户行为序列中的第1个用户行为。
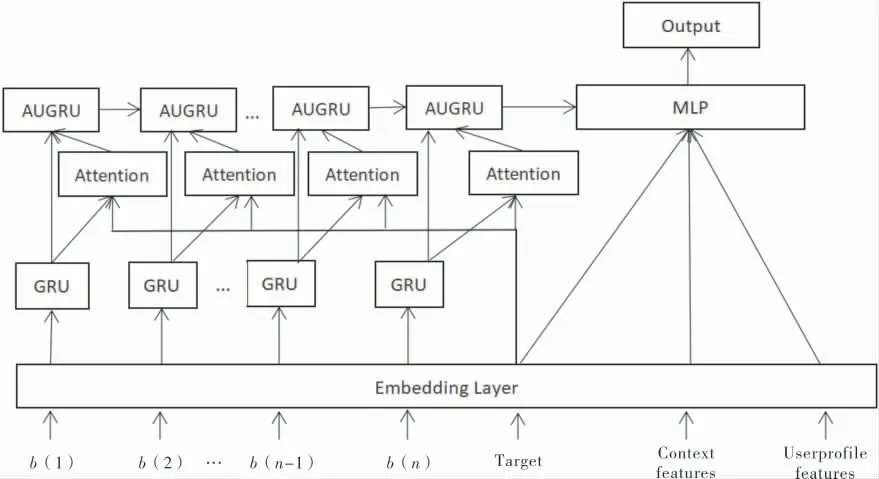
图1 深度兴趣进化网络结构
兴趣进化单元包含兴趣抽取层和兴趣进化层,在兴趣提取层中,主要通过对用户历史行为的分析,提取出用户一系列的兴趣状态。 利用门循环单元(Gate Recurrent Unit,GRU)对行为间的依赖关系进行建模,将有序行为序列输入GRU中得到隐藏的兴趣状态。 GRU克服了循环神经网络RNN的梯度消失问题,并且相较于LSTM而言有更快的运算速度,因此更加符合5G大数据时代高运算速度的要求。
GRU的公式如下:
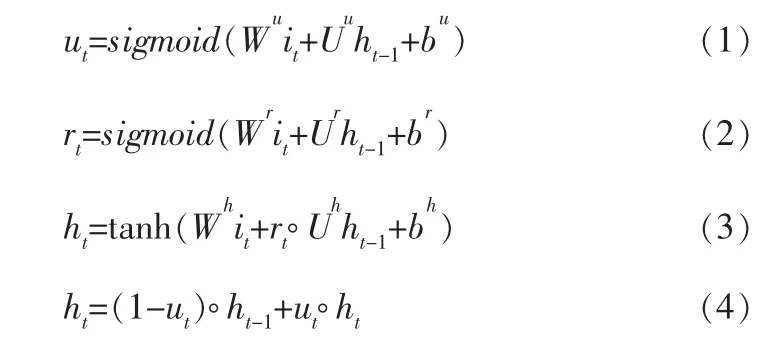
其中,ut为加入注意力机制的得分;Uu为原始更新门;bu为更新门的偏置参数;Wu、Wr及Wh分别为更新门、 重置门以及输出最终状态的权重参数,Wu、Wr、Wh∈RnH×nI(nH是隐藏向量大小,nI是输入向量大小);rt为重置门最终得分;Ur为原始重置门;br、bh为偏置值;◦代表矩阵中对应元素相乘;it是GRU的输入向量,代表用户行为序列中的第i次行为向量;ht是第t次的隐藏状态。
然而仅获取用户行为之间依赖关系的隐藏状态并不能有效表示用户兴趣,因此研究人员提出利用辅助损失值来监督对于兴趣状态的学习。利用用户b+1次来监督b次兴趣状态是否准确,同时根据误差值对隐藏兴趣状态进行更新和改变。在辅助损失值的帮助下每个隐藏状态都足以表示用户采取行为后的兴趣状态。 有序的T个用户历史行为对应着所有T个兴趣状态的序列,即[h1,h2,h3,…,hT],可以利用该兴趣序列模拟兴趣进化过程。
而在兴趣进化层中,通过对兴趣抽取层中获得的用户对请求内容的兴趣偏好序列进行分析,在注意力机制局部激活后,利用门循环单元分析兴趣进化过程,提取用户行为背后的最终兴趣状态。 在兴趣进化层中同样用it和ht表示输入向量和隐藏状态。 其中,下一个GRU的输入对应的是上一个兴趣提取层中的兴趣状态,即it=ht-1,并且最终的hT表示最终的兴趣状态。 在兴趣抽取层中使用的注意力机制表示为:
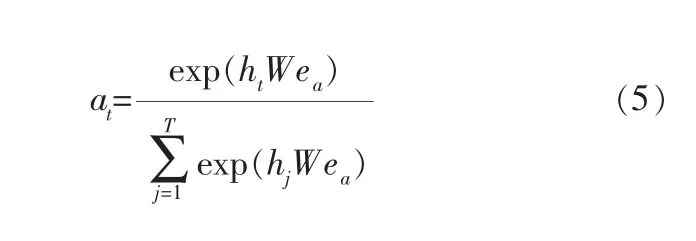
其中,at表示注意得分;ea是候选目标内容的拼接向量;W∈RnH×nA,nH是隐藏向量的维度,nA是目标内容的嵌入向量维度。
注意力得分可以反映该兴趣状态与目标内容间的关系,若用户的某个隐藏兴趣状态对目标内容影响较大,则在兴趣进化层中能获得更高的注 意 力 得 分。 因 此, 使 用AUGRU(Attention Update Gate Recurrent Unit)对用户兴趣变化过程进行建模,其公式如下:
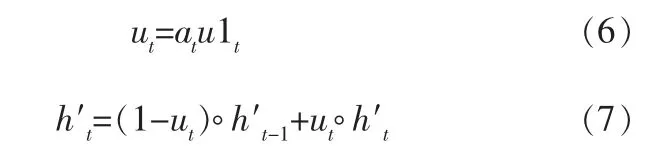
其中,u1t表示原本门循环单元中更新门的结果。
AUGRU的结构如图2所示,其中r是一个循环单元。
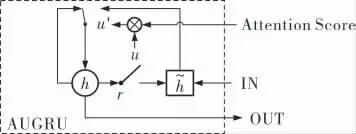
图2 AUGRU结构
在AUGRU中保留了原始维度信息,因此考虑了每一个维度大小的重要性。 在差异化信息的基础上利用注意力机制对GRU更新门中的所有向量维度进行增大或减小,带来的影响就是兴趣状态越小对隐藏状态影响越小,兴趣状态越大对隐藏状态影响越大。AUGRU有效缓解了用户兴趣大范围变化的影响,并且合适准确地对用户兴趣发展进行建模,为后续模型得到最终缓存结果提供基础。
2.2 DeepFM模型
DeepFM模型由GUO H F于2017年首次提出,DeepFM 可以看成是因子分解机(Factorization Machines,FM) 的衍生, 该方法将深度神经网络(DNN)与FM相结合,利用FM挖掘低阶组合特征的同时, 利用深度神经网络学习高阶特征信息,通过并行方式将二者组合。 模型框架如图3所示。
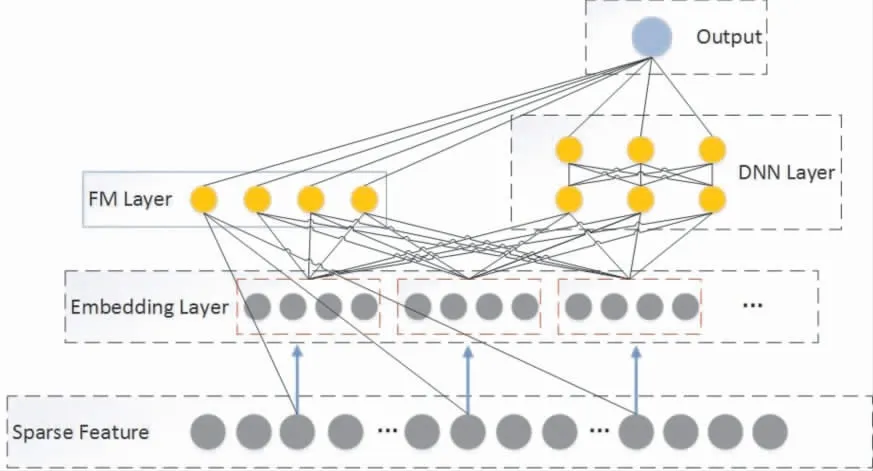
图3 DeepFM框架
由图3可以看出,DeepFM由FM和DNN两部分构成,模型的最终输出也由这两部分构成,具体为:
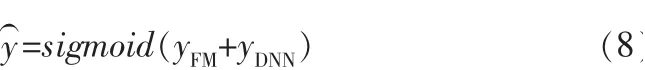
因子分解机是由Rendle提出的一种和支持向量机(SVM)类似的预测器,但因子分解机能更好地应对数据稀疏的情况,即使在数据高稀疏的情况下也能估计得到可靠的参数,并且FM具有线性复杂度,在学习了低阶特征的同时,能考虑到特征之间的相互关系及特征组合的影响情况。 普通的线性模型为:

线性模型独立地考虑了每个特征的影响,但对于特征组合的情况并未考虑,因此因子分解机针对这一问题进行了改进,考虑了二阶及以上的交叉情况:

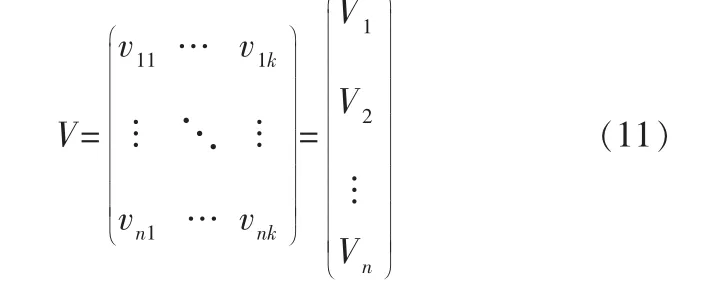
其中,n表示输入数据经过嵌入层嵌入后的数据维度;xi表示第i个特征;wij是特征组合情况的参数, 为了能更好地得到特征参数wij,FM对于每一个特征xi引入了辅助向量Vi=(vi1,vi2,vi3,…,vik),然后利用向量之间的内积得到特征组合参数w,辅助向量V的计算式为:
引用辅助向量使求解的参数数量减少,从本来的n×(n-1)/2个参数变成了n×k个参数,并且削弱了高阶参数间的数据独立性;k值越大向量对特征的表现能力越强, 而较小的k值能使模型具有更好的泛化能力。
在DNN部分,DNN的作用就是构造和学习高维的特征,其输入是和FM层一样经嵌入层处理后的输入数据,经过FM层对不同特征域的嵌入数据进行两两交叉后,将FM和DNN的输出一同输入到最后的输出层与最后的目标进行拟合。
在Google公司提出了Wide&Deep模型之后,很多模型都采用了双模型组合的结构,DeepFM也是其中之一, 但相较于Wide&Deep模型而言,DeepFM方法用FM部分替换了Wide部分, 加强了浅层网络部分特征组合的能力, 并且不需要像Wide&Deep模型在特征输入前需要进行人工特征标注处理。 因此,融合了LDA主题模型的DeepFM方法在第1层缓存上对大部分用户可能喜欢的内容进行预测和筛选。
2.3 基于融合兴趣进化单元的DeepFM模型
利用兴趣进化单元中的兴趣抽取层提取用户兴趣状态,利用兴趣进化层对用户兴趣动态变化进行建模,来获得最终用户未来兴趣状态。 将该兴趣状态与用户信息向量以及目标内容向量拼接后输入至DeepFM模型中, 利用DeepFM模型的泛化能力和学习能力提取兴趣状态与用户信息特征以及目标内容信息特征之间的相互关系获得最终缓存结果。融合兴趣进化单元的DeepFM模型结构如图4所示。
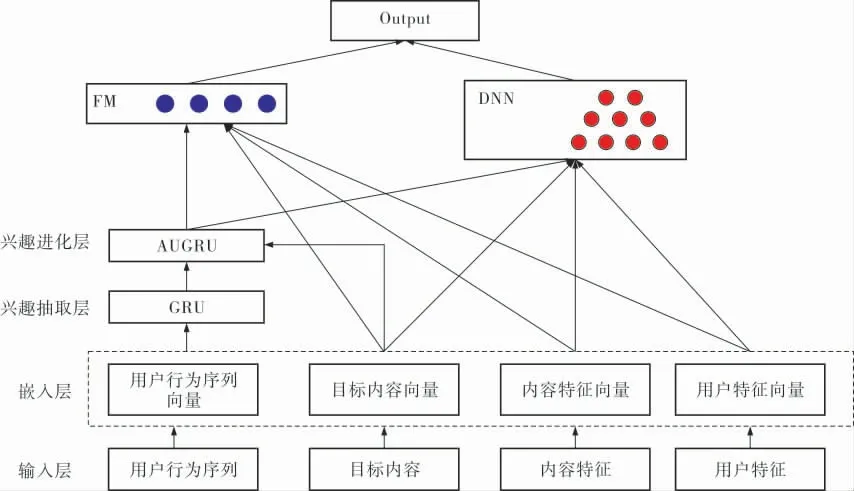
图4 融合兴趣进化单元的DeepFM模型结构
输入层。 首先通过数据预处理后提取出每一个用户的行为序列(如用户在两周内的内容请求记录)、个人信息特征(如性别、年龄、职业等)和内容特征信息(如内容分类、请求记录量等),将用户行为序列、目标内容、目标内容特征和用户特征作为输入输入模型中。
嵌入层。 将输入层输入的数据向量化,将向量化后的用户行为序列向量输入到兴趣抽取层中,将目标内容向量、内容特征向量和用户特征向量输入到DeepFM模型中的FM层和DNN部分,同时将目标内容向量输入到兴趣进化层中。
兴趣抽取层。 将用户行为向量输入到GRU中, 通过GRU挖掘用户行为记录间的依赖性,提取用户兴趣点。 最终得到用户行为序列中每一个行为对应的隐藏兴趣状态,将隐藏的兴趣状态输入到兴趣进化层中。
兴趣进化层。 将兴趣抽取层中提取出的用户隐藏兴趣状态输入到AUGRU结构中,描述用户兴趣动态变化过程,利用注意力得分监督隐藏兴趣状态的更新,保留原始GRU结构中更新门中所有向量维度, 与目标内容拟合, 将注意力机制与GRU结构结合,获得最终的兴趣状态,并输入到DeepFM模型中的FM部分和DNN部分进行后续模型分析。
FM层。 FM层主要利用因子分解机来考虑特征间的交叉情况。 相对于线性回归模型,FM模块结合了SVM与分解模型的优点,对所有变量间的联系使用分解参量建模。 其优势在于,首先因子分解机能够很好地应对数据稀疏情况,其次FM的复杂度是线性的,具有很好的优化效果。 将兴趣进化层中提取出的用户最终兴趣状态向量、目标内容向量、用户信息向量和内容特征向量输入到DeepFM中的FM部分,提取其中的交叉影响情况,为最终预测提供支撑,将最终输出的结果与DNN模块得到的最终结果进行Sigmoid激活,获得最终的输出结果。
DNN层。 在DeepFM中DNN部分与FM部分是并发进行的,同样是将兴趣进化层中提取出的用户最终兴趣状态向量、目标内容向量、目标内容特征向量和用户信息特征向量拼接后输入到DNN层。 DNN部分和Google公司提出的Wide&Deep模型中的Deep部分类似,都是简单的全连接神经网络结构。 利用DNN部分的强学习能力,进一步挖掘输入特征之间的依赖关系,以及输入特征中隐藏的有用信息。
输出层。输出联合FM部分和DNN部分的最终预测值。
3 实验与结果分析
3.1 数据集
实验选用的MovieLens100K数据集中包含了943个用户对1 682部电影的评分记录, 总计10万条。 为了能更好地模拟5G通信的情景,对数据集进行预处理:数据集中的每一条记录包含用户信息、评论时间、电影标签及用户评分等特征,一条记录对应着一个用户对该部电影的评分行为。 在5G通信场景中,不论评分高低都代表该用户请求这部电影内容的行为,即数据集中所有记录都为用户请求过的历史内容记录。 所以还需要对每个用户未请求的内容部分进行添加和完善,首先为数据集中的每一条记录添加一个Tag标签(1表示用户已请求,0代表用户未请求); 其次给定每个用户对电影的请求数目K, 用户已经请求的电影数目为M, 需在用户未曾请求的数据集中随机选择K-M个电影和用户信息拼接,并且加上是否请求标签0,重复上述操作完成数据集的填充工作。
所有实验均在一台8 GB RAM 3.6 Hz Intel(R)Core(TM)CPU的机器上运行。
本次实验主要验证以下几个方面:
a. 深度学习方法在5G推荐缓存的任务上能取得相对于机器学习方法更高的用户体验满意度和更低的回程负载;
b. 双层缓存结构相较于单层边缘缓存的网络结构,在有更好的性能表现的同时,也能降低回程负载和通信成本;
c. 在第1层缓存上利用DeepFM模型,能取得相较于CNN和其他深度学习模型更好的用户体验度和更低的回程负载;
d. 通过LDA主题模型对全部内容进行建模,挖掘其中的隐藏主题信息并作为特征输入DeepFM模型中的方法能够提高模型性能的上限。
3.2 评价指标
为了评估模型在5G通信过程中的性能,采用两个评分标准进行评估,分别为用户体验度得分(QOE_Score)和回程负载(TrafficLoad):
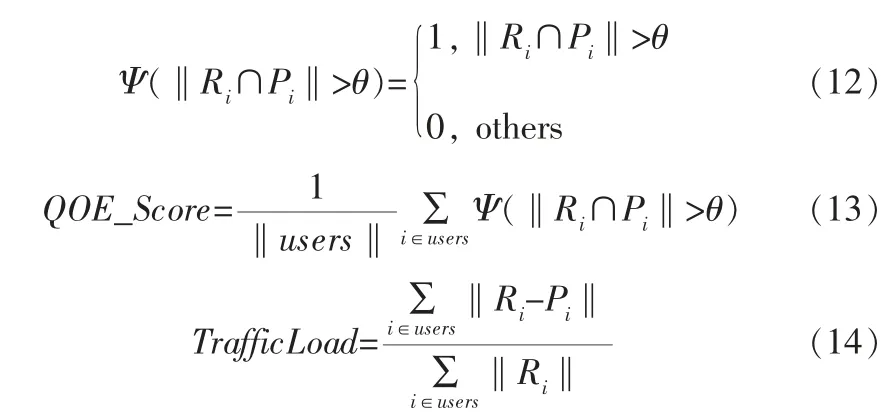
其中,Ri代表用户i真实请求的内容集合;Pi代表模型预测的用户i请求内容的集合;users代表在当前网络中所有用户集合;Ri∩Pi则表示模型所预测的用户请求内容在实际用户请求内容集合中的数量,若大于平均请求个数θ则为1分,因此QOE_Score指标用于评估模型对用户预测内容的准确度和与用户期待的体验相符合的程度。‖Ri-Pi‖表示模型未预测到的用户请求内容情况,若模型没有预测到用户真实请求的内容则需要到远端服务器提取出相应内容,因此增加了线路负载和成本, 所以TrafficLoad是为了描述模型在5G通信网络中所造成的线路负载情况和成本。
3.3 融合兴趣进化单元的DeepFM与边缘主动缓存模型实验对比
该实验主要验证在同样缓存空间下,基于融合深度兴趣进化单元的DeepFM 模型(DIEN DeepFM) 与基于深度进化网络 (DIEN), 基于DeepFM,基于物品的协同过滤算法(ItemCF),以及基于用户的协同过滤算法的边缘主动缓存模型(UserCF)在用户体验度得分和回程负载的表现情况。
深度兴趣进化网络。 深度兴趣进化网络是深度兴趣网络的改进版本,强调用户兴趣的多样性,利用注意力模型获取用户对目标内容的兴趣。 同时深度兴趣网络关注兴趣的变化过程, 并利用新的结构对用户兴趣动态变化过程进行建模。
DeepFM模型。 DeepFM模型的优势在于共享FM模块和DNN部分的参数,能够学习到高阶的组合特征影响,同时也不再需要提前人工进行专业的特征工程, 相对于Wide&Deep模型来说具有训练更加快速且预测结果更精确的优势。
基于物品的协同过滤算法。 基于物品的协同过滤方法的原理为利用矩阵分解的方法缓存用户过去请求过的内容, 它适用于有较多用户、较少缓存内容且有明确用户喜好的场景,主要描述用户和内容间的交互关系,其优势在于有一定的预测能力、能够应对新用户且具有可解释性。 但在5G大数据的通信场景中,基于物品的协同过滤算法有着很高的计算成本,当有新内容加入到网络中后无法处理,同时该方法也没有考虑用户请求内容的顺序特性。
基于用户的协同过滤算法。 基于用户的协同过滤算法是根据用户历史请求内容的行为,为用户寻找兴趣相近的用户,然后缓存用户未请求且与用户兴趣相近的内容。 该方法用于用户较少、有较多内容且用户具有隐藏兴趣偏好的情况。 基于用户的协同过滤算法主要考虑了用户与内容交互的情况,具有足够的内容预测能力,当有新的内容加入时可以有效应对。 但算法的可解释性不足, 并且和基于物品的协同过滤算法一样,数据量很大时需要很高的计算成本,并且该方法也无法处理新用户,也没有考虑内容的属性特征。
实验结果如图5、6所示。
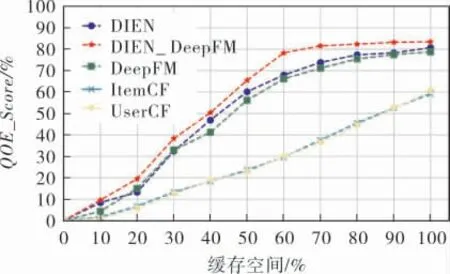
图5 用户体验度得分对比结果

图6 回程负载的对比结果
基于深度学习方法的边缘主动缓存模型相较于机器学习方法(如基于物品和基于用户的协同过滤方法)能取得更高的用户体验度得分和更低的回程负载。当缓存为100%时,基于DeepFM模型的边缘主动缓存模型取得了79.1%的用户体验度得分, 而基于用户的协同过滤算法则取得了60.2%的用户体验度得分, 较前者低了约18.9%。在回程负载方面,基于DeepFM的边缘主动缓存模型为48.6%, 而基于用户的协同过滤方法则为72.3%,较前者高了23.7%。由此可以看出,基于深度学习方法的边缘主动缓存模型相较于基于机器学习方法的边缘主动缓存模型能取得更高的用户体验度得分以及更低的回程负载消耗。
基于融合深度兴趣进化单元的DeepFM的边缘主动缓存模型,能在基于原DeepFM模型以及基于深度兴趣网络的边缘主动缓存模型的基础上,提高用户体验度得分并降低回程负载消耗。 当缓存空间为100%时,基于融合深度兴趣进化单元的DeepFM模型能取得83.4%的用户体验度得分和21.3%的回程负载,DeepFM以及深度进化网络分别取得了79.1%和81.5%的用户体验度得分以及48.6%和38.3%的回程负载消耗。 由此可以看出,在DeepFM模型的基础上融合深度兴趣进化单元,能够有效提高模型性能。当缓存空间从100%减少至60%时,基于融合深度兴趣进化单元的DeepFM模型用户体验度得分仅下降5.3%, 而基于DeepFM模型和基于深度兴趣进化网络的用户体验度得分在缓存空间从100%下降至60%的过程中分别下降了11.3%和12.4%,由此可知,基于融合深度兴趣进化单元的DeepFM 模型相较于DeepFM和深度进化网络来说具有更好的抗衰减性能。
4 结束语
为了高效利用边缘基站上有限的缓存空间和计算资源,需要合适的缓存结构和更优的筛选方法。 考虑到实际应用中用户兴趣总是随着时间动态变化的情况,利用兴趣进化单元对其进行建模,获得最终的用户兴趣状态,通过DeepFM模型挖掘交叉特征以及高阶特征,并最终得到符合用户偏好的缓存内容。 经实验证明,该模型不仅取得了更高的用户体验度得分,也在相同条件下降低了网络中的回程负载。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
小学生作文(低年级适用)(2019年5期)2019-07-26
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
高中生学习·高三版(2016年9期)2016-05-14
山东青年(2016年3期)2016-02-28
