
基于嵌入式平台的安全帽实时检测方法
2022-12-12 03:05李发伯景晓琦
沈阳理工大学学报 2022年6期
李发伯,刘 猛,景晓琦
(沈阳理工大学信息科学与工程学院,沈阳 110159)
建筑工地施工人员佩戴安全帽能有效减轻高处坠落物造成的头部伤害以及一些机械性的损伤,对建筑工地的工作人员佩戴安全帽情况进行检测具有保障安全施工的作用。 现阶段,该检测主要还是使用人工巡检的方式,但由于施工场地范围大、人员分散,靠人工随时监察安全帽的佩戴情况不仅耗费大量的时间和人工成本,还容易出现漏检情况,效率非常低。
近些年来,一些学者对目标检测算法不断进行改进,并应用到安全帽检测中。 基于视频智能监控的安全帽佩戴检测的研究也取得了一定的进展。 文献[1 -3]通过改进YOLO[4]、SSD 等算法对安全帽进行检测与识别,提高了目标检测的速度;文献[5 -6]改进了Faster R-CNN[7]算法,实现了安全帽的检测与识别,提高了目标检测的识别精度。
目前,主流目标检测算法大都基于带有图形处理器实验平台开发,未考虑采用嵌入式平台。少量基于嵌入式平台的检测算法虽然可以实现实时检测,但精度不够,特别是针对小区域目标的检测。 在嵌入式平台上进行安全帽佩戴检测具有低成本、低延时、可扩展性强等优势,可满足施工人员安全帽佩戴实时检测的任务需求。 鉴于此,本文在嵌入式平台上将模型小、检测速度较快的深度学习模型YOLOv4-Tiny 引入安全帽检测领域,并对其进行改进,融合多尺度特征信息,引入空间金字塔池化结构[8],改进初始化锚框并引入有效边界框损失(EIOU)方法。 改进后的算法不仅保证了对安全帽进行实时检测时的速度,同时提高了检测的准确率。
1 YOLOv4-Tiny 轻量级网络模型
YOLOv4-Tiny 模型包括主干特征提取网络(CSPDarknet53_tiny)、加强特征提取网络创建的特征金字塔结构(FPN)[9]以及YOLO 目标检测层三部分。 主干特征提取网络主要由三个跨阶段部分网络(CSPNet)[10]、两个CBL(Conv BN Leaky ReLU)下采样模块以及三次最大池化组成。
CSPNet 将原来的残差块堆栈分为左右两部分,主体部分不断叠加原来的残差块,另一部分像一个大的残差边,在最后直接与主体部分相连。使用CSPNet 可以提高卷积神经网络的学习能力,并能在轻量化的同时保持准确性,减少计算瓶颈和内存成本。
CBL 下采样模块由一个卷积层、批标准化(Batch Normalization,BN)层以及激活函数Leaky ReLU 构成,BN 层减少了不同样本之间取值范围的差异,避免了梯度消失和梯度爆炸问题,降低了参数或其初始值的尺度依赖性,提高了网络归一化能力[11]。
Leaky ReLU 为所有负值分配了一个非零梯度以避免神经元失活,该模块相当于网络的基本组成元件。 池化使用的是最大池化(Maxpool),改变输入特征图的尺寸。 利用主干网络可以获得CSPdarknet53_tiny 最后两个尺度的有效特征层,随后将两个有效特征层传入加强特征提取网络当中进行FPN 的构建。
FPN 解决物体检测时多个尺度融合的问题,通过在简单的网络上构建特征金字塔,在基本不增加YOLOv4-Tiny 模型复杂度的情况下显著提升小目标检测的性能。
YOLOv4-Tiny 的网络结构如图1所示。
由图1可见,采用FPN 完成第一步获得的两个有效特征层的特征融合。 FPN 会将最后一个尺度的有效特征层卷积后进行上采样,然后与上一个尺度的有效特征层进行堆叠并卷积,从而使下一个尺度的有效特征层获得更多的特征信息,提高检测效果。 在目标检测部分,YOLOv4-Tiny 提取了两个尺度为(38,38,128)、(19,19,512)的特征层,最后输出尺度为38 ×38、19 ×19 的特征图用于边界框回归和目标分类。
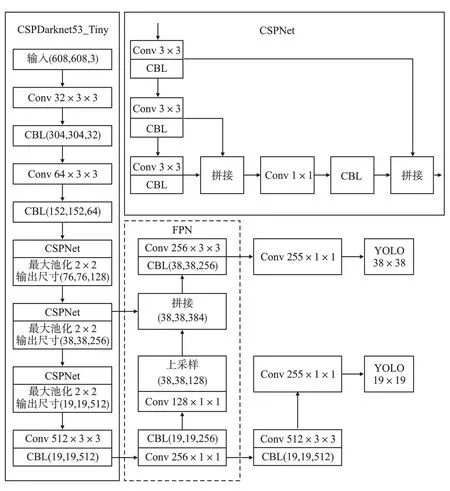
图1 YOLOv4-Tiny 网络结构
2 YOLOv4-Tiny 轻量级网络的改进
YOLOv4-Tiny 网络模型小,检测安全帽速度快,适合应用于嵌入式平台,但其检测的准确率不足, 无法满足安全帽的实时检测, 因此对YOLOv4-Tiny 网络做出如下改进。
(1)优化网络结构,增加检测尺度,进行多个尺度融合,丰富特征信息,并加入空间金字塔池化(Spatial Pyramid Pooling,SPP)网络结构,增强卷积神经网络的学习能力,提高检测精度;
(2)引入EIOU 损失方法构建回归损失函数;
(3)采用聚类算法K-means ++改进初始化锚框。
2.1 优化网络结构
施工场地环境复杂,场景中的安全帽尺度小、数量密集,还可能存在目标被遮挡的问题。 在这些条件下使用原网络YOLOv4-Tiny 检测会出现漏检的情况。 鉴于此,在原网络基础上再增加一个检测层(76 ×76),通过FPN 网络结构融合前两个尺度的特征信息,提高对小目标的检测能力。
由于原算法主干特征提取网络的卷积层CBL(19,19,512)计算量消耗了25.55 亿次浮点运算,消耗的资源较其他卷积层多出近2 倍,为提高嵌入式设备的检测速度,将其从网络中移除。
为进一步精简网络,将第一个上采样前面卷积层的核数由128 降为64;尺度为19 ×19 的检测层最后两个CBL 模块中的卷积层核数由256 和512 降为128 和256;尺度为38 ×38 的检测层最后一个CBL 模块的卷积层核数由256 降为128。
在施工现场,由于施工人员比较分散,获取的安全帽图像因距离的不同而导致输入图像的尺度不同,不能满足输入所需的尺寸。 通常的解决方案是对图像进行裁剪和拉伸,但这会改变图像的纵横比从而导致原始图像发生扭曲。 为了解决这一问题,引入SPP。 对于不同尺寸的图像输入,SPP 可以产生固定大小的输出,并且通过最大池化操作将输入的图像特征映射到维度不同的空间上进行融合,进一步丰富了特征图的多尺度信息。SPP 结构如图2所示。

图2 空间金字塔池化结构
由图2可见,将尺寸为19 ×19、通道数为512的安全帽特征图输入到空间金字塔池化层后,在5×5、9 ×9、13 ×13三个大中小不同尺寸、通道数均为1 的池化层上进行最大池化操作,生成三个尺寸均为19 ×19、通道数均为512 的局部特征图,最后将生成的三个局部特征图与原始输入的特征图利用通道融合在一起,得到尺寸为19 ×19、通道数为2048 的特征图,丰富了安全帽特征图的多尺度信息。 引入SPP 结构可对图片中不同尺度的安全帽进行特征融合,解决输入图像尺度不一致问题,提高检测准确率。
将改进后的模型命名为TS-YOLO,其结构如图3所示。
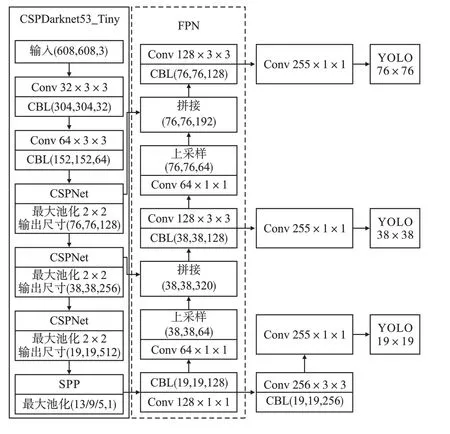
图3 TS-YOLO 算法的网络结构
2.2 引入边界框损失函数EIOU
边界框损失函数IOU 是目标检测中的一个重要指标,通过计算预测框和真实框之间的交集与并集的比值衡量边界框的优劣,计算公式为

式中:A表示目标的真实框;B表示目标的预测框。
YOLOv4-Tiny 采用边界框完全损失函数CIOU,计算公式为


式中:bgt、b分别为真实框和预测框的中心点;ρ为真实框和预测框两个中心点之间的欧式距离;c为能够同时包含真实框和预测框的最小外接矩形的对角线距离;wgt、w分别为真实框和预测框的宽度;hgt、h分别为真实框和预测框的高度;ν为衡量真实框和检测框的长宽比相似性的参数;α为权重参数。
CIOU 损失函数虽然考虑了边界框回归的重叠面积、中心点距离、纵横比,但其反映的是纵横比的差异,而不是宽高分别与其置信度的真实差异,有时会阻碍模型有效的优化相似性。
为弥补CIOU 损失函数存在的不足,本文采用有效边界框损失函数EIOU,计算公式为
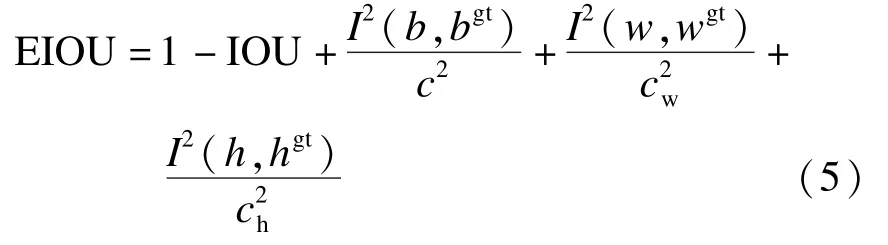
式中:I为真实框与预测框宽度或者高度的差值;c2w、c2h为能够同时包含真实框和预测框的最小外接矩形的宽度与高度。
该损失函数是在CIOU 基础上将纵横比的影响因子拆开,分别计算真实框和预测框的长和宽。 EIOU 损失函数包含重叠损失、中心距离损失和宽高损失三个部分,前两部分延续CIOU 中的方法,但宽高损失直接使真实框与预测框的宽度和高度之差最小,使得模型的收敛速度更快。
2.3 改进初始化锚框
YOLOv4-Tiny 算法中的每个输出尺度使用三个不同的先验框进行预测,先验框的大小因数据集而异,需要通过聚类获得。 原始YOLOv4-Tiny算法中的先验框大小是基于公共数据集进行聚类获得。 由于公共数据集的类别太多,大小不同,聚类得到的先验框形状不同。 YOLOv4-Tiny 算法仅有两个检测层,聚类得到的先验框只有6 个;本文改进后的算法(简称TS-YOLO),因为优化了网络结构,变成三个尺度的检测层,先验框有9 个。 因此,需要对安全帽数据集重新聚类,并选择具有代表性的先验框。
原始的YOLOv4-Tiny 算法采用K-means 算法选取锚框,但由于K-means 算法随机初始化质心,导致算法收敛速度慢。 本文采用K-means ++算法,对初始化质心进行了优化,并据聚类中心选取9 个先验框,使用回归函数对不同尺度上的每个先验框进行置信度回归,得到预测框,然后根据置信度选出最合适的类别。 本文使用聚类算法K-means ++对所使用的数据集进行聚类分析。设定簇的值为9,经聚类算法迭代后选取的对应先验框的宽高分别为(8,18)、(12,25)、(19,35)、(29,49)、(42,72)、(64,106)、(91,164)、(144,237)、(272,376),将其面积按从小到大排列均分到76 ×76、38 ×38、19 ×19 三个不同尺度的特征图上。
3 实验
3.1 实验数据集
本文所使用的数据集是开源安全帽数据集SHWD。 该数据集共有7581 张图像,包含9044个佩戴安全帽的正类,以及111514 个未佩戴安全帽的负类。 根据实际场景,本文对未佩戴安全帽和佩戴安全帽进行检测,在7581 张图片中,取其中6139 张作为训练集、683 张作为验证集、759 张作为测试集。 配戴安全帽标签为hat,未佩戴安全帽标签为person。
3.2 实验平台及配置
目标检测算法的数据训练对硬件环境要求较高,需要带有GPU 的服务器进行训练,表1为本实验训练数据的服务器硬件环境配置。 将通过服务器训练得到的模型移植到GPU 型号为128-coreNVIDIA MaxwellTM 并采用CUDA10. 2、CUDNN8.0 加速的嵌入式平台NVIDIA Jetson Nano进行部署。

表1 服务器硬件环境配置
3.3 网络训练
实验基于深度学习框架Darknet 进行,鉴于服务器显存足够大,训练时批量处理大小设置为64,分组设置为1,冲量设置为0.9,初始学习率为0.00261。 通过这些参数的设置加快模型的收敛速度;设置权重衰减为0.0005,防止出现过拟合的现象。 使用改进后的算法对数据集进行训练的损失值变化如图4所示。
由图4可见,网络训练过程中,前5000 次迭代的损失值较大,但损失值减小较快,并随着迭代次数的增加,损失值不断减小。 当训练的迭代次数达到30000 次后损失值基本稳定在1.8 左右,表示模型收敛。

图4 训练过程损失曲线
3.4 模型评价指标
本实验采用召回率(Recall)、F1 值以及均值平均精度(mAP)作为衡量模型精度的指标定量评价实验结果。
采用模型体积、浮点运算量(BFLOPs)和每秒传输帧数(FPS)分别衡量模型运行时所占内存大小、计算量及运行速度。
3.5 对比试验
实验选择YOLOv3、YOLOv3-Tiny、YOLOv4、YOLOv4-Tiny、TS-YOLO 等算法进行对比,其中YOLOv3-Tiny、YOLOv4-Tiny 以及TS-YOLO 都是轻量级网络,YOLOv3、YOLOv4 是单阶段检测算法。 其中YOLOv4-Tiny 是本文算法未改进前的原网络,TS-YOLO 为本文算法。 输入图片大小均为608 ×608,对比结果如表2所示。

表2 不同算法在SHWD 上的对比
由表2可见,TS-YOLO 较原算法YOLOv4-Tiny 在均值平均精度、召回率以及F1 值上分别提高了12.91%、31.91%和19%,检测精度接近YOLOv3、YOLOv4 高精度目标检测算法。 此外,提出的TS-YOLO 算法在模型体积上均小于其余四种算法,较原算法YOLOv4-Tiny 模型体积缩小了两倍多,浮点运算量仅比YOLOv3-Tiny 大不到两个百分点,比其余算法的浮点运算量都小,有利于缓解嵌入式设备的计算压力,释放存储空间。
实验结果表明,相较于YOLOv4-Tiny,改进后的算法TS-YOLO 在减少计算量和模型体积的同时,有效提高了安全帽检测精度。 具体检测结果对比如图5所示。

图5 YOLOv4-Tiny 与TS-YOLO 检测效果对比图
图5是运用两种算法分别在高空小目标、部分遮挡目标以及目标密集的场景下进行检测的效果对比,其中左右两侧分别为YOLOv4-Tiny、TSYOLO 检测的效果图。 从图5可看出,YOLOv4-Tiny 在检测小目标、部分遮挡目标、密集目标出现漏检,而本文算法TS-YOLO 在保持其轻量化的同时,不仅提高了检测精度,在目标小、存在遮挡以及目标密集的场景下仍具有较高的识别率,原算法YOLOv4-Tiny 出现的漏检,在本文算法中并未出现。
3.6 嵌入式平台实验
为检验提出的模型在嵌入式平台上的检测速度,先在嵌入式平台NVIDIA Jetson Nano 上配置加速引擎TensorRT 和Opencv 库,嵌入式平台如图6所示。

图6 嵌入式平台
将服务器上训练得到的模型加载到嵌入式平台的TensorRT 进行加速推理,测试模型检测速度,并与其他模型的检测速度相比较,输入图片尺寸均为608 ×608。 速度检测结果如表3所示。

表3 不同算法在Jetson Nano 的检测速度
由表3可知,嵌入式平台计算能力有限,在图片输入尺度为608 ×608 的条件下,检测精度较高的YOLOv3 与YOLOv4 在Jetson Nano 上的检测速度(FPS)最高分别只有1.63、1.82,无法实现实时检测。 而TS-YOLO 在相同输入尺寸下实现了每秒20.16 帧的检测速度,可满足在嵌入式平台上对安全帽进行实时检测的需求。
实验结果表明,本文提出的TS-YOLO 在嵌入式平台满足实时检测的情况下,检测精度较原网络YOLOv4-Tiny 有较大幅度的提升,更适合在嵌入式平台上进行安全帽检测。
4 结论
提出一种改进YOLOv4-tiny 的安全帽检测方法TS-YOLO,旨在解决现存安全帽检测方法中检测精度低以及难以在嵌入式平台有效运行的问题。 TS-YOLO 通过优化YOLOv4-tiny 的网络架构,加入SPP 结构,并融合多尺度特征信息提高小目标的安全帽检测能力,其次引入EIOU 提高模型收敛速度以及检测精度,最后通过K-means ++算法重聚类,得到适合的锚框。 通过实验结果的验证与分析可知,TS-YOLOv4 模型所需内存大小仅为 YOLOv4-tiny 的41. 7%, mAP 提升了12.91%,检测速度仍能保持与原算法一个水平,该方法在模型大小、检测精度的表现均优于YOLOv4-tiny,在嵌入式平台上的检测速度亦能满足安全帽实时检测的需求。
TS-YOLO 算法并未加入注意力机制,下一步将引入注意力机制,在保持其检测速度的同时,进一步提高检测能力。
猜你喜欢
机电安全(2022年4期)2022-08-27
家庭影院技术(2021年7期)2021-08-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
课外生活·趣知识(2019年4期)2019-09-10
电子制作(2019年7期)2019-04-25
电子制作(2018年16期)2018-09-26
电子制作(2017年8期)2017-06-05
今古传奇·故事版(2017年5期)2017-04-08
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
