
基于LDA的眉毛识别方法研究
2022-12-07 01:09李颜瑞
微型电脑应用 2022年11期
李颜瑞
(山西机电职业技术学院,信息工程系,山西,长治 046011)
0 引言
在如今飞速发展的社会里,能够准确地识别出每个人的身份已经变的越来越重要了,目前,在识别中常用的识别方法有物品识别和标识识别,这两种识别方法自古就有,所以我们统称为传统的识别方法,例如会员卡、身份证、钥匙、口令和密码等。但是这些识别方法都存在着很大的安全隐患,例如钥匙、身份证、会员卡容易丢失或者损坏,口令和密码也容易被泄露或者被不法分子攻破。所以,为了进一步提高安全性和可靠性,生物特征识别技术悄然兴起,为信息安全的发展奠定了新的基础,能提高社会的稳定因素。生物特征识别技术是将人的生物特征和信息特征相结合起来,以人的生物特征为物质条件的识别技术。到目前为止,已经研究的生物技术有指纹[1]、虹膜[2]、人脸[3]、掌纹[4]等,其中人脸识别和指纹识别已经得到了广泛的应用,虹膜识别和掌纹识别也在一些关键领域得到了应用。眉毛识别的研究也已经开始,已经完成了使用PCA、小波、HMM和2DPCA[5]等方法进行眉毛识别,但是总体上还处于研究的初级阶段,还有具有很大的研究空间。本文利用线性判别分析方法(LDA方法)提取特征向量,该方法是在主成分分析方法(PCA方法)提取特征的基础上,再进行两次投影得到最终的特征向量。解决了PCA中忽略高阶统计量信息的缺点。最后利用最近邻方法进行识别。
1 LDA理论
LDA[6]也称为线性判别分析方法,还可称为Fisher脸法,英文形式为Linear Discriminant Analysis(FLDA),在1936年,Fisher(费舍)提出了该方法,该方法是依据测量或者观察得到的一系列的值,并对该一系列的值进行研究分析决定如何分类的方法。
线性判别分析方法是在训练集的样本空间上进行分组,然后对分组的样本空间中的样本进行计算,生成特征向量,研究计算生成的特征向量和分组的样本之间的关系,通过研究得到的关系,来进一步确定出能决定分组的函数。将生成的函数用于识别或者分类待识别的样本空间中的样本,在整个函数中训练样本的分组情况定义为因变量,待识别的样本被称为自变量。
假设存在一个样本集合Z,且Z={x1,x2,x3,…,xn}。其中,将样本分成ij类,第i类是{xi1,i2,…,zi}其元素数量用zi表示,根据样本中的数据可以求出每个类样本的平均值μi和整个样本集合的平均值μ。那么μi和μ的公式为
(1)
(2)
那么样本中的类间离散度Sb和类内离散度Sw这2个矩阵为
(3)
(4)

那么最后生成的投影矩阵为,其该矩阵为最优矩阵。
(5)
然后继续将训练的眉毛图像直接在Wopt矩阵上进行投影计算,就能得到最佳的特征向量,具体计算为
Sbwi=λiSwwi
(6)
其中,λi为特征值,且i的取值为1,2,…,n-1 。
2 基于LDA的眉毛识别方法
2.1 眉毛图像数据信息预处理[7]
为了完成研究,第一步必须建立自己的眉毛数据库进行实验。考虑到采集设备有一定的要求,所以继续采用北工大李玉鑑教授提供的眉毛数据库进行实验。
通常我们采集到的眉毛图像是包含头发和一部分脸部信息的人脸图像。这样的图像是不能直接用于识别的,必须将眉毛区域图像从人脸的图像上分离出来,这一过程我们称之为图像分割[7]。因为图像分割的目的是排除一切影响识别的干扰信息、提高识别,所以本文采用了简单、方便的手工圈取眉毛图像分割方法进行预处理,得到眉毛图像区域部分如图1(a)、图1(b)。
然后进行彩色图像的灰度化,根据心理学的知识,人对红色和绿色最敏感,所以,交通信号灯就选择了这两种颜色,那么这个公式为
g=0.3R+0.59G+0.11B
(7)
生成纯眉毛图像的灰度图,见图1(c)。
最后进行归一化处理,通过实验发现,用双线性插值算法进行归一化处理,效果最好,并且将图像归一化为40×200 px时,无论是在识别率还是在特征量的大小上,都有一个比较好的效果。所以文本采用双线性插值算法进行纯眉毛图像的尺度归一化处理,且纯眉毛图像归一化为40×200 px见图1(d)。

(a) 原始眉毛
2.2 眉毛特征提取
用于特征提取的纯眉毛图像必须是经过预处理得。其中输入的纯眉毛图像的格式为:灰度图,且图片为BMP或者jpg格式。特征提取后的输出结果为一个矩阵,且矩阵中的每一行或者每一列为一张眉毛图像的特征向量。具体方法如下。
(1) 先将训练中的纯眉毛图像按照人的类别进行分组,然后计算训练中每个人的训练眉毛的平均值μi和所有纯眉毛的平均值μ。
(2) 将每个人的训练眉毛都减去自己的均值μi,即x′=xi,j-μi,眉毛记为Ei,j。

(4) 将Ei,j表示的眉毛图像先按照行优先顺序形成一个列向量。然后按照眉毛的先后顺序,将产生的列向量依次放到同一个矩阵中,组建成一个新矩阵记为Mij。
下面求解Sw矩阵,要求是非奇异矩阵,但是实际情况是奇异矩阵,为了求解简化,所以本文借助PCA方法求解。
(5) 利用PCA求解投影空间


(c) 求解协方差矩阵CM,即CM=BBT。解的一组特征值λ0,λ1,…,λm-1和特征值所对应的向量β0,β1,β2,…,βm-1。
(d) 利用特征值进行从大到小排序,取出前K个特征值λ0,λ1,…,λm-1和其所对应的向量β0,β1,β2,…,βm-1,分别组成两个矩阵。即特征值矩阵λ和向量矩阵β。其中λ矩阵为对角矩阵,β矩阵就为投影矩阵。



(8)
(9) 求解SbV=λSwV矩阵,得到其特征向量及特征值。
(10) 将特征值从大到小排序,选取前n-1个特征值所对应的特征向量并组成矩阵。记为F矩阵。
(11) 将纯眉毛图像先在β矩阵上投影,然后再在F矩阵上投影,得到的结果就为最终提取到的特征向量。
(12) 按此方法提取出训练集合中的眉毛图像的特征向量,并保存到一个数组中,那么该数组就为训练集合眉毛特征库。
2.3 眉毛识别
近邻法则[8]是一种采用比较的方法进行识别的,主要的思想是通过比较待识别的样本的特征与训练样本所形成的特征数据库中,哪个特征向量最近,就确定待识别样本就是该最近的类别。
利用距离的大小,作为识别决策的重要依据的方法叫作最近邻方法。假设有一个样本类,样本类中有N个类,其中每个类的样本用xi,i表示是第几个类别,i∈[1,N],j表示是第几个样本,那么xi表示是第i个样本类中的第j个样本。则识别函数为
(9)
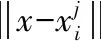

识别方法如下。
(1) 将待识别集合中的眉毛图像,按照预处理方法进行操作并生成40×200 px的灰度图像。
(2) 使用LDA算法提取待测试集合中的纯眉毛图像的特征向量。
(3) 计算待识别眉毛特征与训练集合的眉毛特征向量数据库中特征向量的之间的距离,记为di,其中di为测试眉毛特征向量与训练集合的眉毛特征向量数据库中第i个特征向量的欧式距离。
(4) 判断公式min(di)≤dmax,如果判断为假,执行步骤(5);如果判断为真,则执行步骤(6)。
(5) 当min(di)>dmax时,可以确定待识别眉毛不是已知眉毛数据库中的眉毛。
(6) 当min(di)≤dmax,可以确定待识别的眉毛为已知眉毛数据库中的眉毛,并且与训练集合的眉毛特征向量数据库中第i个特征向量是同一个人的眉毛。
3 实验结果与分析
实验中所使用的眉毛数据库是由北京工业大学的李钰鑑教授提供的,在109人的眉毛库上进行实验。每个人都分为睁眼和闭眼两种情况,其中睁眼用于训练,闭眼用于识别。通过实验,进一步证明眉毛识别用于个人身份识别的可能性和有效性。
3.1 使用多种眉毛识别方法其实验结果比较
该实验是为了证明基于LDA眉毛识别方法的正确性,并且同时验证了该方法优于其它的眉毛识别方法。实验结果如表1所示。

表1 多种识别方法的比较
通过表1可以看出,利用LDA方法做特征提取,用最近邻方法做识别,其识别率高于HMM、PCA和小波变换等方法。分析原因是LAD在做训练时,每个人选用了3张进行训练,加大了训练样本中每类的数量。并且PCA特征提取算法是提取的眉毛图像的像素点的灰度值的二阶统计量,对于高阶统计量直接给忽略掉。而LDA特征提取方法很好的克服这些缺陷。最近邻方法识别是利用的距离方法,该方法简单实用。
3.2 在不同数量的眉毛训练集对识别的影响
下面的实验是为了证明在训练样本中,每类样本选取不同的数量对实验的影响。实验结果如表2所示。

表2 不同量眉毛库数据库的实验结果
通过表2可以看出,基于距离的识别方法,训练样本中每类样本选取数量逐渐增多时,识别率也相应的提高,但是消耗的时间也会增加。这是因为每类样本选取数量增加,其最后得到的该类的特征向量越优化,识别率也就提高了。但是,特征向量的优化程度在特定的提取方法上也是有极限的,不能无限制提高,除非进行算法改进,所以出现了选用3张和选用4张的识别率相同。
所以利用LDA方法提取眉毛特征向量,采用最近邻方法,在109人的眉毛库上做识别具有较高的识别率,且识别率高达94.5%。进一步证明使用LDA提取的特征质量好,识别率高。
4 总结
在近二十年里,涌现出了很多的生物识别方法,但是眉毛识别是近十年左右才开始研究的。本文采用基于LDA的眉毛识别方法在109人的眉毛库上取得了较好的识别效果,进一步证明了眉毛识别的可行性。后续工作要集中在眉毛的自动提取以及眉毛的基本形状信息的识别方法,比如眉毛轮廓的识别方法,这样才更有利于眉毛识别技术的应用推广。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
科学大众(2021年9期)2021-12-31
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
许昌学院学报(2018年4期)2018-05-02
作文大王·低年级(2017年9期)2017-09-18
小学生作文(低年级适用)(2017年5期)2017-07-07
中华建设(2017年1期)2017-06-07
