
GPU环境下加速移动对象可视化更新的方法研究
2022-12-06 10:37冒艳纯许建秋
计算机工程与应用 2022年23期
冒艳纯,许建秋
南京航空航天大学 计算机科学与技术学院,南京 211106
随着移动通信、智能交通、现代物流等技术的不断发展,与时间和空间相关的移动对象数据[1]的数量和种类越来越多。这些数据具有规模大、更新快等特点。移动对象是用于描述位置随时间连续变化的空间对象。在数据库中按照时间顺序存储其位置记录,构成移动对象时空运动轨迹。在移动对象数据库系统中,索引和查询处理[2]是数据库的主要技术。但是在数据库系统中的移动对象可视化[3]也同样重要,数据可视化可以将查询结果以直观的、便于可读的视觉形式呈现给用户,方便用户理解和分析数据。
现有的移动对象可视化工具[4-7]应用广泛,但是忽略了移动对象数据规模大和更新频繁造成的可视化效率问题。GPU(graphic processing unit)[8]作为一种擅长处理大规模和并行数据计算的设备[9],相较于CPU,有强大的计算能力和高性能的内存使用率。移动对象可视化的时间瓶颈主要在查询处理上,且GPU的并行可视化主要应用在体绘制技术的并行[10-11],所以需要应用GPU来加速数据的查询处理能力,提高移动对象可视化效率。R-Tree、KD-Tree是常见的存储移动对象数据的索引,针对GPU并行架构,研究人员提出了一些并行RTree构造和查询处理算法[12-15],但都存在局限性。传统的R-Tree索引结构并不适用于GPU,简单的线性数据结构才能更容易地在CPU主内存和GPU设备内存之间传输。同时,由于移动对象查询结果集的不确定性,查询输出所需的内存空间可能相差很大。但是在GPU上没有真正的动态内存分配,必须静态分配缓冲区,因此造成内存的额外开销。
本文主要研究移动对象可视化查询的效率提升,提高绘制查询窗口内移动对象轨迹的速度。可应用在移动对象的时间范围查询、最近邻的连续时间查询等移动对象可视化查询。可视化查询的时间瓶颈主要在:
(1)移动对象查询:移动对象更新实际上是移动对象的索引查询,由于移动对象数据规模大、查询复杂,因此代价较高。
(2)同一时间片移动对象的重复查询和绘制:现有方法在每次时间片更新时,是将整个查询时间窗口内的移动对象重新查询和绘制,这会造成同一时间片重复查询和绘制,存在不必要的时间消耗。
针对问题(1),本文提出了GPU环境下移动对象更新方法,使用一维数组存储移动对象数据,并且将移动对象串行查询改为基于CPU/GPU的异构并行查询方法,通过GPU内部大量独立的计算单元,实现移动对象查询加速,从而提高查询效率。该方法简单有效,更加适合GPU内存,减少了查询结果集的不确定性,带来的额外内存开销。针对问题(2),本文提出了移动对象更新函数的优化方法,通过比较当前可视化查询的时间区间与上一次可视化查询的时间区间,找出需要更新的时间片,避免整个时间区间的更新。
1 相关工作
移动对象的可视化是研究移动对象的重要方向之一。国内外许多研究人员已经开发了各种移动对象的可视化系统,得到广泛的应用。Ortal等人[4]提出了使用谷歌地图实时展示移动对象的web应用程序,该系统可以为移动领域的研究人员提供可视化支持,以分析运动物体的轨迹,评估预测模型。Wang等人[5]提出了一个交互式的可视化分析系统,来分析大规模道路网络中的交通拥堵。该系统将行驶轨迹映射到道路网络,并计算道路速度。在估计各路段的自由流速度后,基于相对低速的检测,自动检测道路上的交通堵塞事件。Güting等人[6-7]提出的开源数据库SECONDO中实现了多种基于Java-GUI图形用户界面的可视化工具,用于可视化移动对象的运动轨迹、查询结果和数据结构等。这些移动对象可视化工具[4-7]虽然应用广泛,但是忽略了移动对象数据规模大和更新频繁造成的可视化效率问题。
GPU[8]作为一种擅长处理大规模数据和并行数据计算的设备[9],相较于CPU,有强大的计算能力和高性能的内存使用率。现有的GPU并行可视化技术,主要应用于体绘制技术的并行实现[10],体绘制是由三维数据场产生屏幕上二维图像的技术,应用于医学影像、气象气候学[11]等复杂三维图像绘制领域。本文研究的移动对象可视化,主要是绘制简单的点和线段,所以GPU的并行可视化不适用于本文研究的移动对象可视化,并且移动对象可视化更新的时间瓶颈主要在查询处理上。因此要提高移动对象可视化效率,需要将GPU运用到移动对象的数据查询处理。
现有的移动对象查询和索引[12-15]都可以在GPU上实现。Gowanlock等人[12]提出了适用于GPU的友好索引方法,将其应用于相似轨迹查询,该方法与CPU版本相比,速度提高了15.2倍。文献[13]提出了用于并发构建R-Tree和在GPU上查询移动对象的算法。但是该方法为每个R-Tree节点分配了固定数量的内存,从而造成了设备全局内存的浪费和相应的性能损失。文献[14-15]都提出了基于GPU使用简单线性阵列构建R-Tree的批量加载方法,并对大型地理空间数据进行并行空间查询。简单的线性数据结构可以很容易地在CPU主内存和GPU设备内存之间传输,并且不需要序列化。但是在GPU上基于R-Tree的查询还是会有局限性,即查询输出所需的内存空间可能相差很大,由于GPU资源的有限性,无法在最坏的情况下进行内存预分配。并且GPU上没有真正的动态内存分配,因此必须静态分配缓冲区,从而造成内存的额外开销。本文提出的方法,相比较于上述方法,简单有效且更加适合GPU内存,并减少了查询结果集不确定性,而带来额外的内存开销。
2 基本概念
2.1 移动对象
移动对象在二维平面上移动的轨迹实际上是一条有向曲线,利用定位设备对其进行采样可以得到一系列的采样点,如图1所示,依照时间顺序将采样点连接起来,就组成了移动对象的时空运动轨迹。
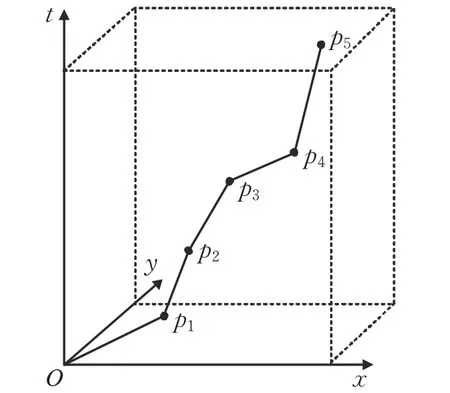
图1 移动对象轨迹示意图Fig.1 Moving objects trajectory schematic diagram
定义1(移动对象轨迹)
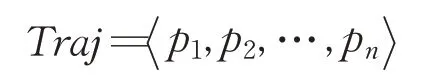
其中,p表示采样点,且p=(lng,lat,t),其中t表示采样点的时间信息,lng表示采样点的经度,lat表示采样点的纬度。两个连续采样点之间的位置,通过线性差分的方法获取。
定义2(时间区间)
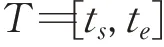
其中,ts表示时间区间T的开始时刻,te表示时间区间T的结束时刻,且满足ts<te。
表1列出了本文中使用的符号含义。

表1 符号表示Table 1 Symbol table
2.2 GPU
GPU是一种众核架构处理器,主要用于高度并行计算,所以其运算单元占比很大。GPU的控制和缓存单元主要是负责数据合并和转发,因此GPU不擅长复杂的逻辑运算,但面对海量且单一的运算时,GPU的速度比CPU快很多。如图2所示,GPU包含多个流式多处理器(streaming multiprocessors,SM)。每个SM包含多个流处理器(streaming processors,SP)、共享内存等部件。线程束是SM中执行的基本线程单元。一个线程束由32个连续的线程组成,线程束内的线程之间必定是并行执行的,并在同一时间执行相同的指令。
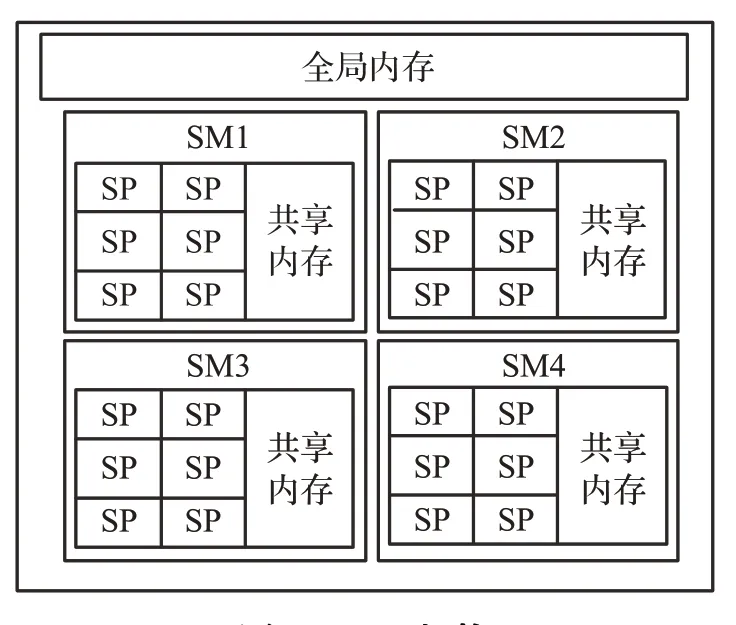
图2 GPU架构Fig.2 GPU architecture
3 关键技术
本章首先介绍现有的移动对象更新方法,然后介绍了GPU环境下的移动对象更新方法,并提出了基于GPU的移动对象并行查询算法。最后,介绍了移动对象更新函数的优化方法。
3.1 现有更新函数
本文主要研究移动对象查询可视化的效率提升,提高绘制查询窗口内移动对象轨迹的速度。例如在基于时间范围的可视化查询时,用户改变查询的时间范围,系统就需要更新对应的可视化内容。开源数据库SECONDO[6-7]中的移动对象更新函数如算法1所示。

算法1首先判断移动对象轨迹是否在可视化查询时间区间内(行2)。然后,对于在可视化查询时间区间内的移动对象,按秒数递增,for循环查询时间区间内T的时间点t,调用getCTIndex()函数用二分法查找对应时间点t的移动对象索引(行7)。然后,通过索引定位到该时间点t移动对象对应的坐标(行6)。算法1的时间瓶颈主要在同一时间片移动对象的重复查询和绘制(行3)和移动对象查询的时间消耗(行4)。
3.2 GPU环境下的移动对象更新方法
在GPU基础上发展起来的计算统一设备架构[16](compute unified device architecture,CUDA),支持C、C++等多种编程语言。CUDA的高性能计算能力,是通过CPU与GPU的异步执行来实现的。在CUDA模型中,通常将CPU称作主机端,GPU称作设备端。数据初始化、内存分配、数据拷贝和启动核函数等串行任务在主机端进行,设备端负责处理高度线程化的并行任务,又称为核函数。
由算法1可知移动对象可视化更新的时间消耗主要在移动对象的串行索引查询,因此为了提高移动对象可视化效率,提出了GPU环境下的移动对象更新方法,将移动对象更新函数中的串行索引查询方法改为基于GPU的并行查询方法,流程图如图3所示。
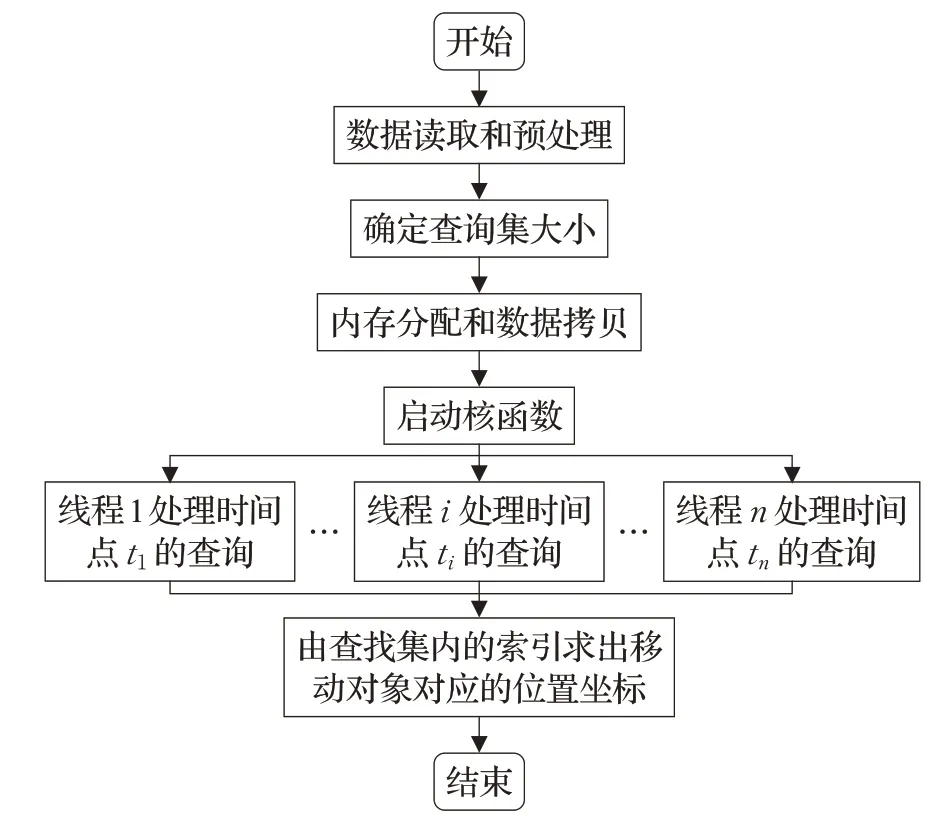
图3 基于GPU的移动对象更新流程图Fig.3 Moving objects updating flow chart based on CUDA
由2.1节可知,移动对象轨迹数据由一组采样点构成,每个采样点包括时间和空间信息。数据预处理是将移动对象数据的时间信息提取出来,存放在一维数组中,如图4所示,时间数据和拥有该时间数据的采样点具有相同的索引(数组下标),数据传输时,仅把时间数据从CPU拷贝到GPU。即将数据变成简单的一维数组,使得数据更容易在CPU内存和GPU内存之间传输。
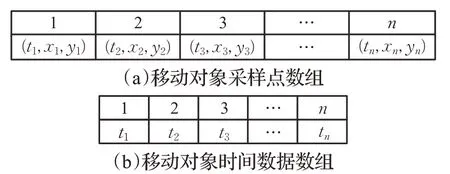
图4 移动对象数据Fig.4 Moving objects data
并行查询区间的大小决定了查询集的大小。每个移动对象有不同的时间区间Ttraj,查询时间区间为T,则并行查询的时间区间TP=Ttraj∩T,对应的时间点为{t1,t2,…,tn}(TP.ts≤t1<ti<tn≤TP.te),每个时间点ti间隔1 s。按时间点ti分割成N个查询任务,一个查询任务返回一个移动对象的索引,则查询集大小为N。
内存分配和数据拷贝完成后,主机端启动核函数,将需要执行的N个查询任务交给设备端处理。当核函数映射到GPU后,会被分配到网格上,网格中有多个线程块,每个线程块由多个线程构成,并在同一个多处理器上运行。单个线程处理一个独立的时间点查询任务,N个查询任务并行执行结束后,设备端返回查询集。再根据查找集内的索引,得到移动对象对应的位置坐标,将所有坐标点连接构成查询范围内的移动对象轨迹。移动对象并行索引查询如算法2所示。
算法2基于GPU的移动对象并行查询算法

算法2中,首先获取对应的线程索引(行1),并且一个线程索引对应一个时间点t的查询任务。然后,运用二分法查找算法,查找对应时间点t的移动对象索引(行2~行17)。最后,将查找到的索引存放在索引数组中(行18)。
3.3 优化更新函数
在移动对象可视化查询时,移动对象的更新函数是将查找的整个时间区间内的移动对象轨迹全部更新,这会造成同一时间片的重复更新。所以,提出了优化更新函数的方法。
首先,判断需要更新的时间片。如图5所示,当上一次可视化查询的时间区间T1与当前可视化查询的时间区间T2相交时,比较T1和T2的重叠区间,以此分情况讨论。然后,根据找出的需要更新的时间区间,对移动对象进行相应的可视化更新操作。
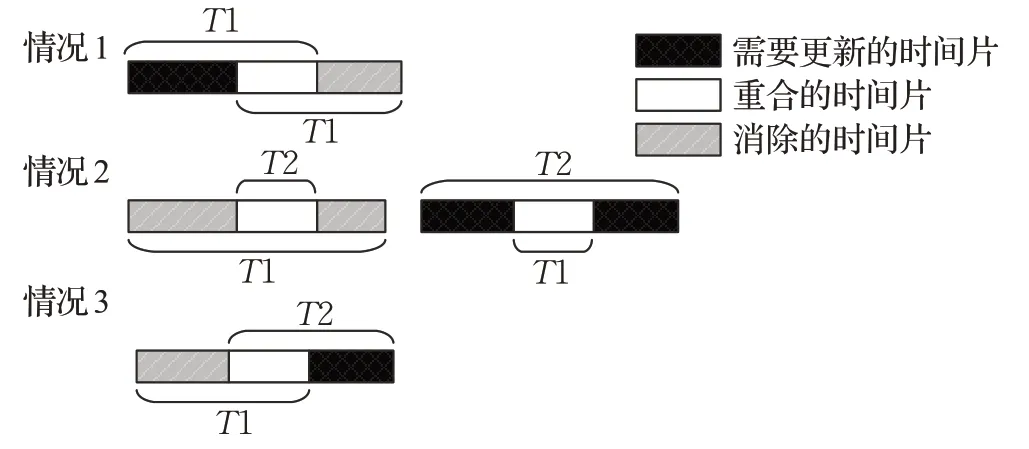
图5 更新函数优化方法Fig.5 Optimization method of update function
情况1当T2.ts<T1.ts且T2.te<T1.te时,需要更新的时间区间为[T2.ts,T1.ts]。
情况2分两种情况。(1)当T2.ts>T1.ts且T2.te<T1.te时,T2的整个时间区间都在T1的时间区间内,所以没有需要更新的时间片。(2)当T2.ts<T1.ts且T2.te>T1.te时,需要更新时间区间为[T2.ts,T1.ts]和[T1.te,T2.te]。
情况3当T2.ts>T1.ts且T2.te>T1.te时,则需更新的时间区间为[T1.te,T2.te]。
算法1第3行的for循环查找的时间区间T,替换为上述情况讨论的需要更新的时间区间。
引理更新函数优化后的时间复杂度为O(n×cm)(c∈(0,1])。
证明给定移动对象数据的大小为n,可视化查询时间区间的大小为m,临近的两次可视化查询时间区间的重叠率为w,c=1-w,w∈[0,1),c∈(0,1]。对于原有的移动对象更新函数,首先遍历移动对象数据集,判断移动对象轨迹是否在可视化查询时间区间内,该操作时间复杂度为O(n)。然后,对于在时间区间内的移动对象,查找其在查询时间区间内的索引,该操作的时间复杂度为O(m)。所以,移动对象更新函数的时间复杂度为O(n×m)。优化后的更新函数,缩小了移动对象更新的时间区间,查询的时间区间由临近的两次可视化查询时间区间的重叠范围决定。当临近的两次可视化查询时间区间重叠率为w,则需要更新的时间区间大小为cm(c=1-w)。因此优化后的更新函数时间复杂度为O(n×cm)(c∈(0,1])。
4 实验评估
本文实验CPU采用Intel®Core™i7-5500@2.4 GHz,内 存8 GB,4核;GPU采用NVIDIA公司的GeForce GTX 1660 Ti,支持CUDA 10.0的驱动版本,显存容量为6 GB;操作系统为Ubuntu 14.04;实验代码使用CUDA C编写。
4.1 实验数据
实验使用合成数据集和真实出租车轨迹数据集,数据集信息如表2所示。其中Cabs_Data为旧金山真实出租车数据集[17],{D1,D2,D3,D4,D5,D6,D7}为Brinkhoff[18]轨迹生成器生成的不同规模的合成数据集。
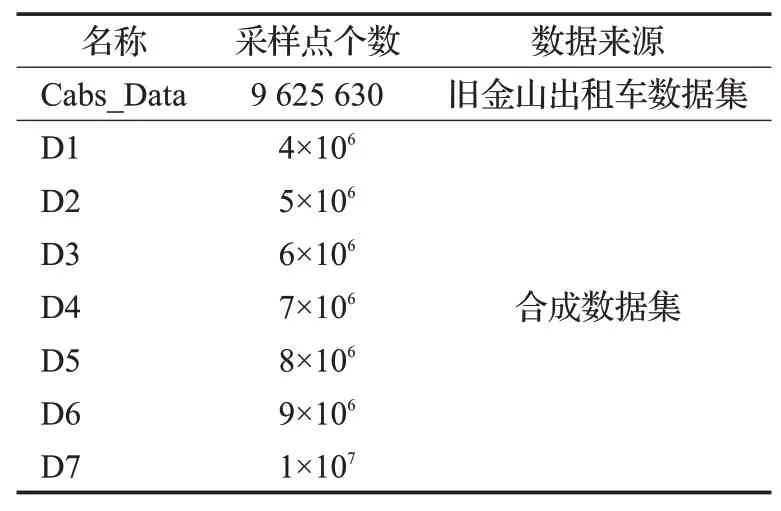
表2 数据集Table 2 Dataset
4.2 实验结果
4.2.1 查询性能对比
R-Tree是最常见的存储移动对象数据的索引,有较好的查询性能。移动对象更新时间消耗主要在是移动对象的索引查询,因此本小节实验对比了3种查询方法:(1)CPU上的R-Tree查询;(2)GPU上的R-Tree查询;(3)CPU上更新函数中的串行索引查询。将这3种查询方法分别记作CPU_R-Tree、GPU_R-Tree、CPU_Serial。本文提出的方法记作GPU_Parallel,是将移动对象更新函数中的串行索引查询方法改为基于GPU的并行查询方法。
实验数据使用不同规模的合成数据集,对不同大小的数据集和时间范围分别使用CPU_R-Tree、GPU_RTree、CPU_Serial、GPU_Parallel这4种方法运行测试,数据大小从400万条递增到1 000万条,查询时间范围从3小时递增到16小时。为了减少实验误差,每种规格的数据均运行10次,再取平均值。
在处理数据规模为1 000万条时,比较GPU_Parallel查询方法和其他3种查询方法在不同时间范围上的查询性能,如图6所示。
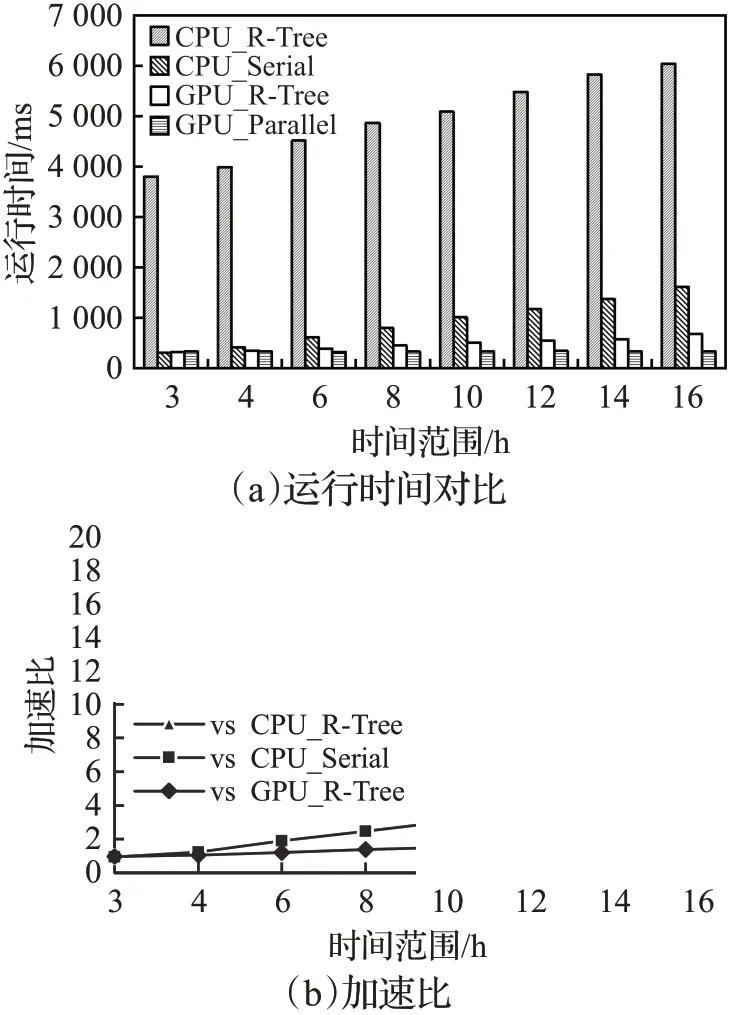
图6 时间范围对查询性能的影响Fig.6 Effect of time ranges on query performance
主机和设备的数据传输消耗的时间会影响整个程序的效率,经测试本实验使用的GPU设备的数据传输时间大约占整个GPU运行时间的23%。所以只有当计算数据足够大时,才能显示出GPU的并行计算的优势。因此在图6(a)中,当可视化查询时间区间只有3个小时,数据传输时间大约为76 ms,使得GPU_Parallel运行时间大于CPU_Serial的运行时间,加速比为0.94。
为了使实验效果明显,在不同规模的数据集上的比较测试,查询时间范围设置为16小时,比较GPU_Parallel查询方法和其他3种查询方法在不同数据规模上的查询性能,如图7所示。
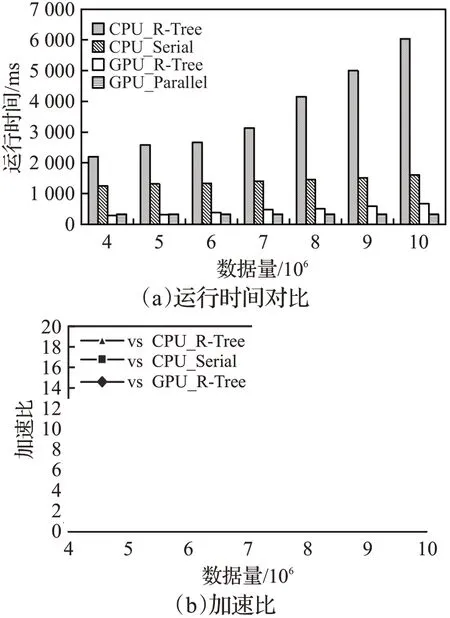
图7 数据规模对查询性能的影响Fig.7 Effect of data sizes on query performance
从图6和图7中的结果可以看出,随着查询的数据规模和时间范围的递增,CPU_R-Tree和CPU_Serial方法的运行时间快速增长,而GPU_R-Tree和GPU_Parallel方法的运行时间变化不大。虽然GPU_R-Tree方法与GPU_Parallel方法在不同时间范围和数据规模上运行时间相差不大,但是GPU_R-Tree方法还有构建R-Tree的时间消耗,且其查询集不确定,必须静态分配缓冲区,这会造成内存的额外开销。因此GPU_Parallel方法更优,与其他查询方法相比,加速比最高可达18.48。
4.2.2 优化更新函数
本小节实验数据使用Cabs_Data数据集,用加速效率作为衡量算法性能提升的指标,加速效率越大表明实验效果越好,加速效率S的定义如公式(1)所示:

其中,TO表示现有更新函数可视化查询时间,TN表示优化后的更新函数可视化查询时间。
实验测试发现,如图8所示,加速效率与邻近的两次可视化查询时间片段的重叠范围有关。
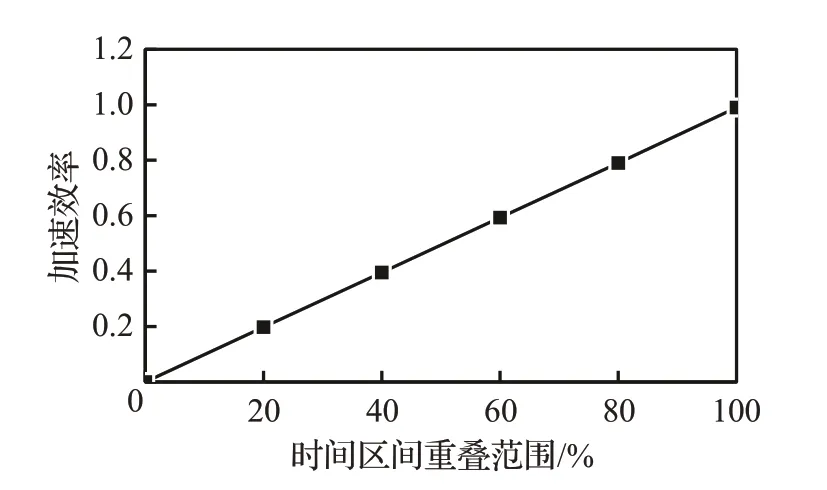
图8 加速效率Fig.8 Acceleration efficiency
如果重叠范围是100%,例如上一次时间区间是[7:00,8:00],当前查询时间范围是[7:00,7:30],那么查询时间为2 ms,可忽略不计。如果两次时间范围有交叉,例如上一次的查询时间范围是[7:00,7:30],当前的查询时间范围是[7:00,7:50],重叠范围为60%。只需要更新[7:30,7:50]这20 min内的移动对象,时间消耗就从1 000 ms变成418 ms,速度提升了2.5倍。但是如果两次查询时间没有交叉,则没有显著效果。因此,两次查询时间,重叠范围越大,查询时间消耗就越小,加速效率就越高。当临近的两次可视化查询时间区间完全重叠时,加速效率接近100%。
5 结束语
针对大规模移动对象数据可视化效率问题,本文提出了GPU环境下的移动对象更新方法和优化移动对象的更新函数。通过GPU加速移动对象查询,以及比较临近的两次可视化查询时间区间的重叠范围,避免相同时间片的重复更新,来提高可视化效率。实验表明,与CPU上的R-Tree查询、GPU上的R-Tree查询和CPU上更新函数中的串行索引查询方法相比,本文所提方法具有较好的查询性能,加速比最高可达18.48。更新函数优化后,当临近的两次可视化查询时间区间重叠范围越大,加速效果越明显,当临近的两次可视化查询时间区间完全重叠时,加速效率接近100%。下一步的工作考虑优化GPU的数据传输,采用异步流来缩短数据传输时间,以获得更高的加速比。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
师道·教研(2022年1期)2022-03-12
延安大学学报(自然科学版)(2021年4期)2022-01-11
北京测绘(2021年7期)2021-07-28
中国外汇(2019年13期)2019-10-10
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电脑爱好者(2015年21期)2015-09-10
