
深度伪造生成与检测研究综述
2022-12-06 10:27唐玉敏曲金帅
计算机工程与应用 2022年23期
唐玉敏,范 菁,曲金帅
1.云南民族大学 电气信息工程学院,昆明 650500
2.云南省高校通信与信息安全灾备重点实验室,昆明 650500
过去,文本伪造检测的过程仅限于打样、验证和查询,数字数据在此过程中并没有起到很大重用。但随着数字数据在互联网上的快速增长以及其在日常生活中的相关性,如数字营销、法律取证图像、医学图像、敏感卫星图像处理和许多其他的应用,使得伪造问题慢慢成为人们所关注的点。此外,不同应用程序中的数据的发展,也在助长网络犯罪率的增加。在这种情况下,有趋势表明目前数据内容传播存在严重的漏洞,数字数据的可信度也在大大下降[1]。深度伪造与网络信息息息相关,与之有关的一些网络安全问题也随之出现,很多学者对此也提出了相应的学术担忧以及看法[2-3]。
为了防止深度伪造生成技术被不法分子恶意利用,越来越多的学者就深度伪造生成技术研究提出了一系列检测方法,实现在网络、现实生活中更好地帮助人们辨别获取到的视频、音频、图像所传递的信息真伪。
本文将从深度伪造生成技术、深度伪造检测技术这两个方面进行分析总结,并对深度伪造生成与检测未来进行总结与展望。
1 深度伪造生成技术
现有的深度伪造技术主要是基于音频、视频以及图像的伪造生成方法。自深度伪造技术盛行以来,已有大量学者对其进行研究[4-9]。首先深度音频伪造技术,又称语音技术,是对语音信号的一种伪造生成。其次深度视频伪造技术,是对视频序列中的对象或者字幕内容进行替换。最后深度图像伪造,大部分都是基于人的图像伪造,对图像中的人物进行替换或者是对人物对事件做出的表情进行替换的技术。以下小节将对现有深度音频伪造技术、深度视频伪造技术以及深度图像伪造技术进行总结。如图1所示,为深度伪造生成大致思路框图。通过该思路设计深度伪造生成算法,可实现深度音频、视频、图像伪造,例如光照、姿态、身份、眼嘴部动作等其余特征的伪造[10-12]。
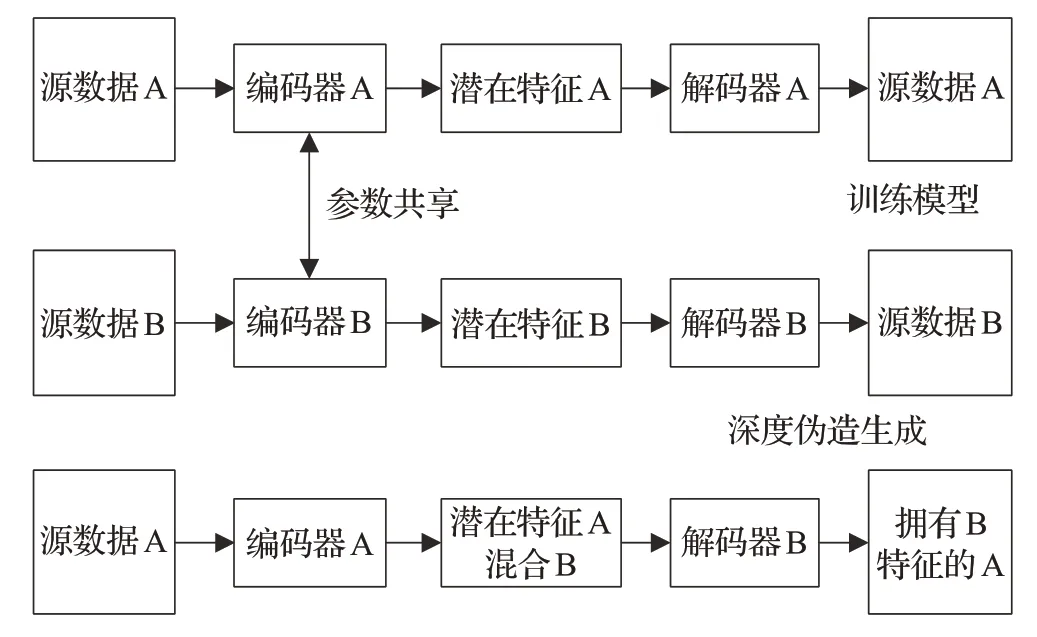
图1 深度伪造生成框架Fig.1 Deepfake generation framework
1.1 深度伪造生成相关技术
1.1.1 深度音频伪造技术
音频伪造技术,通常是从文本到语音或者是由语音转换成合成语音两种方式[13]。文本到语音的方式,主要是通过计算机技术将指定的文本内容转换成语音信号(语音合成),这种方法对社会几乎不造成太大的负面影响;而语音转换成合成语音则是计算机将一段语音转换成为指定音色的语音信号的过程(语音转换)[14-15],语音转换通常包含频谱和韵律两个方面的转换,需要大量的语音数据进行训练,训练完成之后生成的合成语音与目标声音相差无几,具有极大的欺瞒性[16]。通过上述方法,不法分子可以将一段语音进行相应操作,并将之插入到另一段与之无关的语音中,造成整段语音的语义发生变化,对社会造成无法想象的恶性后果。
Zhang等人[17]提出,在生物识别时对话人的身份验证很重要;但随着深度音频伪造技术的迅猛发展,自动说话人验证系统(ASV)越发地容易受到计算机伪造的攻击和欺骗。通过分析声纹认证系统中特征向量——梅尔倒谱,将改进的双向长短时记忆网络加之全局方差一致性滤波,实现了对声纹认证系统的欺骗攻击[18]。Qureshi等人[19]指出,假新闻对社会和政治等方面都有很大的影响。音频伪造技术可以实现对于特定的新闻背景下记者报道的语音内容进行合成,恶意用户则将假新闻发布到社交媒体上,以误导和欺骗群众。Song等人[20]提出TACR-Net,用于解决合成语音内容的编辑系统中说话人与内容在嘴型上不一致的问题。
目前深度音频伪造在电话诈骗、名人争议录音合成均有了典型违法案例[21]。因此更好地检测出音频真伪,是现实的需求,是维护人民权益、网络内容安全以及政治内容安全的保障。
1.1.2 深度视频伪造技术
视频伪造技术,通常是将特定的视频,使用机器学习、深度学习的算法将特定视频中的人与人或人与物或物与物进行交换的过程,如表1,即为目前可实现视频伪造的一些经典工具。视频是一连串连续的视频帧的组合,对于目前视频的伪造,最重要的是实现伪造视频内容的连续性。故目前存在最多的视频伪造:一是视频中的语音以及内容伪造;二是视频中角色伪造。视频中的语音及内容伪造,主要是针对视频中的角色对待一件事件或者事物做出的反应和回应进行篡改,使得视频原先表达的内容发生了改变;而视频中的角色伪造,指的是将某个视频的主角换成目标对象,使得该目标对象成为该视频的主角,目前的视频角色伪造技术越来越成熟,其危害性也在慢慢地增加。
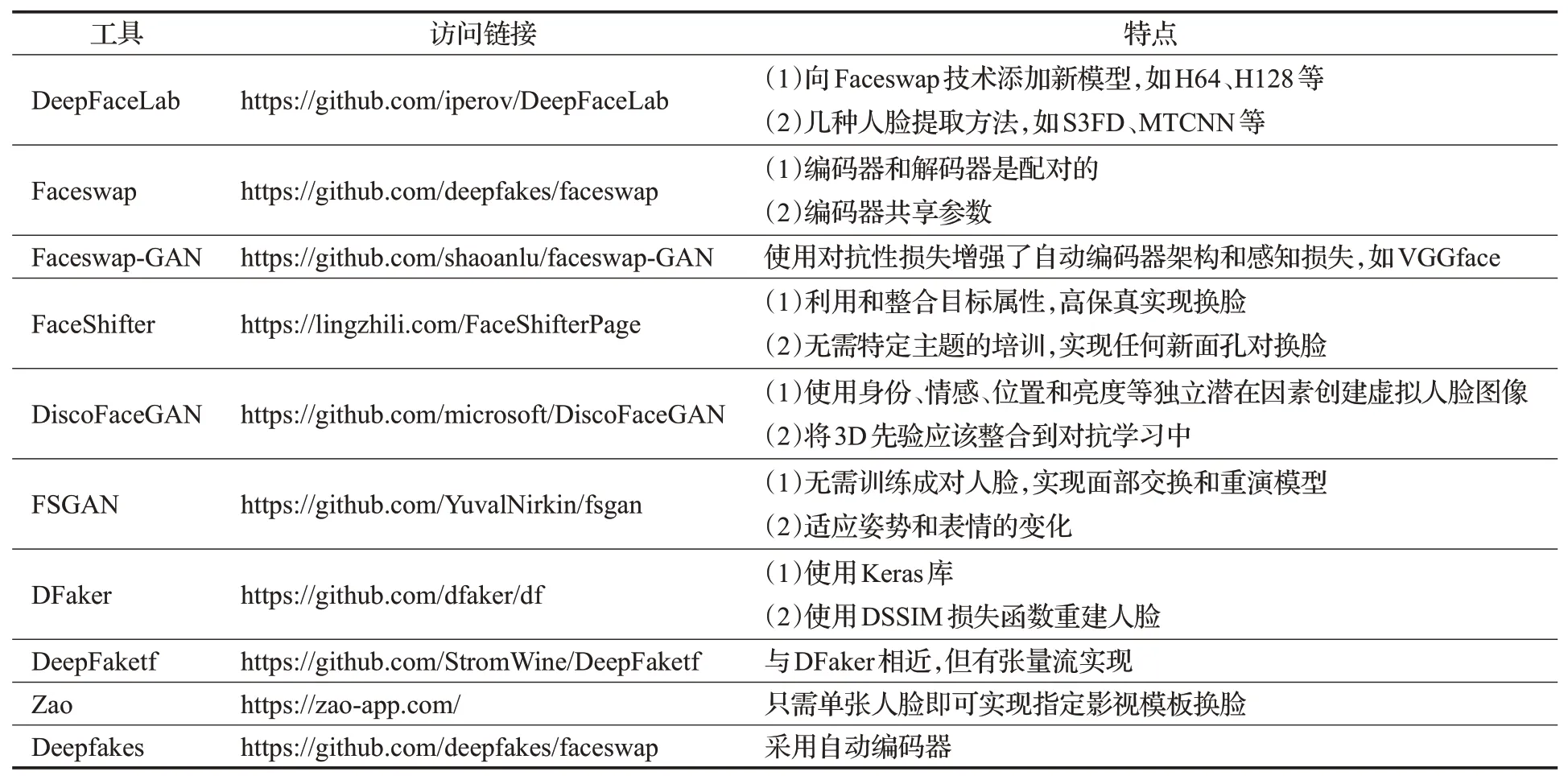
表1 视频伪造经典工具Table 1 Video forgery classic tool
Zakharov等人[22]提出一种对抗性元学习生成模型框架,实现使用少量图像样本建立一个伪造视频,且视频呈现的效果高度逼真。此外,Samuel[23]指出近期有一个深度视频伪造app,在未经本人许可的情况下,可将一个人变成某色情视频的主角,并以几乎全裸的形象呈现在色情视频中。Thies等人[24]针对生成的伪造视频与原始视频光度不一致的问题,提出了一种单目目标视频序列的实时面部重演方法,实现了生成的伪造视频与现实生活中的光照无缝连接,伪造视频的生成效果逼真清晰。
2017年,第一个假视频发布,内容为非色情名人参演色情视频。2020年,深度视频伪造技术被用来制作国际领导人的假演讲视频,引来各国的关注[25]。深度视频伪造技术正成为全球安全威胁,也随之成为了世界各学者、各国家机构广泛关注的热点。
1.1.3 深度图像伪造技术
目前大部分的深度图像伪造技术都是利用深度学习技术,且大多集中在关于人的操作。从目前最新深度图像伪造成果来看,深度图像伪造技术在操作的方式以及程度上可以分为四类:完整的面部合成、身份替换、属性操作以及面部重演[26]。其中完整的面部合成是指对面部进行操作或编辑的过程,一般生成的是并未在现实生活中存在的人的面部。其次身份替换即是将特定图像目标中的人脸替换成为源目标中的其他人脸。此外,属性操作是指修改目标图像的特定面部区域,例如:头发颜色、表情、性别等。面部重演作为新兴的深度图像伪造技术,可以更好地作为面部表情迁移的条件面部合成任务;它可以实现转化目标图像的表情、面部姿态以及眼球运动等等,使得伪造的图像更加逼真。
在面部合成方面,Lin等人[27]针对计算机在合成面部图像时的计算限制(交互内容有限),提出了条件坐标生成对抗网络(COCO-GAN),实现了生成样本大于训练样本的过程(越界生成),并且生成图像质量为当时最先进的质量。Karras等人[28]针对StyleGAN生成图像质量问题进行了修复(代码优化、惰性正则化、权重解调等),提出了StyleGAN2,实现在面部图像合成质量上、训练表现上的提升。
在身份替换方面,Gandhi等人[29]提出通过使用对抗性扰动(对图像进行修改)来增强深度伪造,使得伪造的人脸图像与原始图像在视觉上难以察觉,实现了深度图像伪造的检测准确率从95%下降到了27%。
在属性操作方面,Geng等人[30]则通过3D引导的细粒度人脸操作方法,实现了注释者无法区分真实图像与计算机生成的伪造人脸图像。Huang等人[31]针对属性操作容易出现边界的伪影的问题,提出FakePolisher方法,实现更好的欺骗假图像检测分类器。
在面部重演方面,Zhang等人[32]提出了一种一次性方法来生成仅使用单个源图像的重演面部,且与一组目标图像的方法相比取得了具有竞争力的结果。
数字图像的生命周期由图像采集、图像编码和图像处理三个步骤。第一步图像采集,使用外部设备获取图像;第二步图像编码,涉及存储或保存数字图像;第三步图像编辑,涉及图像的后处理,以增强或修改图像的实际内容[33]。
如今,互联网上很容易获取大量图像,尤其是在不同的社交媒体平台上,这些图像可用于生成虚假信息。数字图像处理目前可分为三类:数字水印、数字签字和图像伪造。数字水印是在图像进行处理后对图像标记所有权的方式;而数字签字则是确保数字图像的真实性,通过图像伪造的方法使得图像呈现出真实情况;图像伪造则是通过对图像进行操作,以改变其所描绘的事实,而这种技术鲜有人去关注其可能造成的社会危害,而仅仅只是关注其伪造结果的逼真性。
目前深度伪造生成图像在伪造图像逼真性上做到了越来越多的突破,传统的检测方法已经很难检测出伪造图像的真伪。因此研究更好的深度伪造图像检测方法,是目前学者们可接续研究的研究热点。
1.2 深度伪造生成数据集
深度伪造生成技术主要由深度音频、视频、图像伪造技术组成。数据集相应地分为深度音频伪造数据集、深度视频伪造数据集、深度图像伪造数据集三类。
本节将对深度音频、视频、图像伪造数据集进行一一的说明和总结。
1.2.1 深度音频伪造数据集
据目前研究而言,并未存在高质量的深度音频伪造数据集(具有对其良好的音频通道,并且人类无法立即感知到错误)。现有的方法将拥有音频通道的伪造视频进行语音转录,并应用TTS、VC算法或基于卷积神经网络的方法转换成伪造语音数据集[13]。
FF[34]:FaceForensics++是拥有5 000个包含音频通道视频序列的基准深度伪造数据集,其中音频通道由Deepfakes、Face2Face、FaceSwap以及NeuralTexture操作,且大部分音频数据是非英语内容组成。
VoxCeleb[35]:VoxCeleb数据集是基于计算机视觉技术的全自动流水线创建的开源媒体数据集。其中VoxCeleb包含从上传到YouTube的视频中提取的1 251名名人的100 000多个话语,如表2所示,为VoxCeleb数据集的分布情况说明。

表2 VoxCeleb数据集分布Table 2 VoxCeleb dataset distribution
VoxCeleb2[36]:VoxCeleb2是一个从开源媒体收集的超大规模视听说话人识别数据集。使用完全自动化的管道。其中包含来自6 000多名发言者的超过一百万条话语,这比任何公开可用的说话人识别数据集都要大几倍。
VCTK[37]:VCTK(The Voice Cloning Toolkit)数据集是在爱丁堡大学的半消音室内,由109名英语母语者使用不同口音读取由贪婪算法选择出的文本而采集到的音频数据集。且VCTK数据库拥有几种变体,例如语音增强数据库、混响语音数据库、Microsoft可伸缩噪声语音数据库等等。
LibriSpeech[38]:LibriSpeech数据集起源于LibriVox项目的有声读物,包含以16 kHz采样的1 000 h的音频数据。该数据集通过(文本错误率)WER将音频数据分为clean和other两部分,再通过进一步的细分将数据集分 为dev-clean、test-clean、dev-other、test-other、trainclean-100、train-clean-360、train-other-500七个部分。
VCC 2018[39]:VCC 2018(The Voice Conversion Challenge 2018)是VCC的第二个版本,是一项大规模语音转换挑战赛。VCC 2018数据集是从DAPS(The Device and Production Speech)数据集[40]中筛选的一部分说话人形成的数据集,该部分数据是由专业美语人士在干净无噪声的环境中录制形成的。其中包括2 572个评估集,每个评估集合有44个话语组。
1.2.2 深度视频伪造数据集
IJB-C[41]:IJB-C(IARPA Janus Benchmark-C)数据集包含3 531个受试者的人脸图像和视频,边界框和源数据标签均使用的是AMT(Amazon Mechanical Turk)。IJB-C包括11 779个全动态视频提取出的117 542帧,平均每33帧为一个主题,每三个主题为一个完整视频。
FaceForensics++[34]:FaceForensics++数据集是Face-Forensics数据集的扩展[42]。收集了现实场景下的视频(尤其是YouTube),并使用四个最先进的自动面部处理方法对视频进行剪辑和筛选后获得的大规模视频序列数据集。
CelebV[43]:该数据集是从YouTube上收集的五位名人视频,分别为唐纳德-特朗普、伊曼纽尔-马克龙、特蕾莎-梅、马云以及凯瑟琳;视频平均时长为30 min,且每个名人都具有自身独有的面部特征,具有很好的稳健性;此外200 000张人脸均使用半自动方法进行注释和额外的手动校正。
VidTIMIT[44]:VidTIMIT数据集是由43个受试者在受控环境下拍摄(面对指定摄像机、背诵预定的短语)形成的。每个受试者的视频分别用一个编号序列的JPEG图像存储起来,分辨率为512×384。
LRS2[45]:LRS2(The Lip Reading Sentences 2)数据集是目前公开的最大可用唇读句子数据集。该数据集由BBC的一些新闻和脱口秀节目中的短段组成而来(最长6.2 s)且包含200多万个单词和140 000多个话语,具体组成如表3所示。
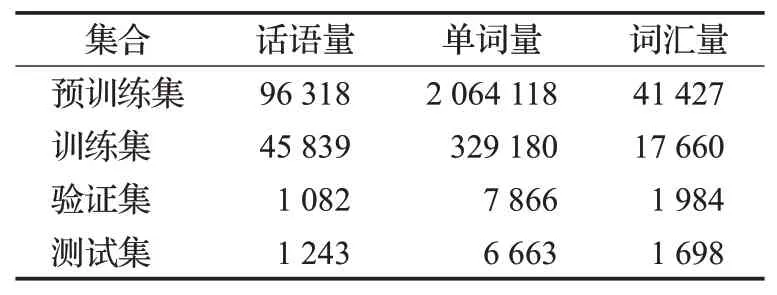
表3 LRS2数据集分布Table 3 LRS2 dataset distribution
TCD TIMIT[46]:TCD-TIMIT数据集是由62位说话者和6 000多个语音朗读示例组成,语音长度通常为4~5 s,均来自语音平衡和自然的句子。该视频数据是在实验室的两个固定角度录制形成的,分辨率为1 080p。
1.2.3 深度图像伪造数据集
FFHQ[47]:FFHQ(FlickrFaces-HQ)数据集包含70 000张分辨率为1 024×1 024的高质量人脸面部图像,且该数据集在年龄、种族和图像背景拥有多种的变化,在眼镜、太阳镜、帽子等配饰的覆盖率也更好,如图2所示,即为该数据集的部分示例图。

图2 FFHQ数据集示例图Fig.2 Example graph of FFHQ dataset
RAF-DB[48]:RAF-DB(现实世界下的人脸情感数据库)是可用于面部表情识别的数据集;包含29 672张人脸面部图像,通过40个独立的标记工具标注出基础情感数据集(15 339张)以及复合情感数据集(厌恶情绪去除,14 333张)。
VGGFace2[49]:VGGFace2是由9 131个主题、331万张图像组成(每一个主题包含了362.6张图像);该数据集是通过谷歌图像搜索引擎下载获取,具有身份数量多、涵盖姿势、年龄和种族范围大、标签噪声小的特点,比较适合现实场景中的实验研究,数据集示例如图3所示。

图3 VGGFace2数据集示例图Fig.3 Example graph of VGGFace2 dataset
Yale Face Database B[50]:Yale Face Database B是由耶鲁大学计算机视觉与控制中心建立的人脸数据库。该数据集中,每个受试者在特定环境中做出9个姿势,在每个姿势下给予64种不同的光照,以此方式重复实验获取总的人脸图像数据集。该数据集包含10个受试者的5 760张单光源图像,数据集图像大小为640×480。
Helen[51]:Helen数据集包含2 330幅高分辨率全注释的现实场景下的人脸图像数据。其中训练集图像2 000张,测试集图像330张。该数据集使用了AMT对图像进行精准的手工注释,如眼睛、鼻子、嘴巴等等,此外每幅图标注有194个特征,具有较高的鲁棒性。
2 深度伪造检测技术
深度伪造技术的快速发展,是对隐私、社会安全以及互联网的完整性的一种重大威胁。为了抑制、避免深度伪造技术影响到人类的正常生活,深度伪造检测技术成为了一个很重要的工具。近几年,有很多的深度伪造检测技术提出并被用于对抗深度伪造技术[52-57]。
最初目标检测技术多是用于模式识别等任务。如今已经扩展成为使用机器学习、深度学习、人工智能技术实现对音频、视频、图像数据的真伪检测。
2.1 深度伪造检测相关技术
2.1.1 深度音频伪造检测技术
当前,可以使用多样的软硬件技术创建深度伪造音频数据。音频伪造技术旨在音频数据中删除某些内容或者增加某些特定内容而形成特定的音频数据。因此,对音频数据的真伪鉴定是十分必要的[58]。
现有的深度音频伪造检测技术可分为主动检测和被动检测技术。主动检测技术是使用某种方法在原始音频数据中生成数据水印,另一方在使用过程中会重新生成水印,检测时将重构后的水印与接收的水印进行比对,一致则为原始不一致则为伪造。与主动不同的是,被动检测技术更受学者们的欢迎,因为它不需要任何的先验知识(水印),而是利用伪造音频在创建过程中留下的痕迹进行检测。首先利用深度音频伪造检测算法将可疑语音分为有声段、无声段两个部分;再利用特定的具有鲁棒性的后处理操作方法从片段中提取特征,并将特征进行相似性分析,从而检测出伪造的音频片段。
Chettri等人[59]为了实现更好的伪造音频检测鲁棒性,提出了通过逻辑回归将深度神经网络(CNN、CRNN、ID-CNN、Wave-U-Net)和传统的机器学习模型(GMM、SVM)组合成一个深度伪造音频检测集成模型。Moussa等人[60]针对目前刑事检察人员获取到的伪造音频多是具有未知特征无限制来源的数据,用传统的方法很难检测出真伪的问题;提出一种无约束的伪造音频检测技术——Transformerseq2seq网络,实验证明该技术优于目前有竞争性的网络和CNN基线网络,同时具有参数量最小的优势。Ustubioglu等人[58]针对目前音频检测多是手工提取特征的方法,提出了第一种将梅尔谱图与深度学习应用到一起的深度音频伪造检测方法。实验证明该方法与其他研究相比具有较高的有效性、鲁棒性和精确性。
目前基于传统的手工提取特征的深度音频伪造检测技术已经很难精确地鉴别出音频数据的真伪。而使用深度学习网络检测音频数据的技术目前已经有些学者进行了尝试并获取了一些可观有效的结果。未来音频检测技术可以接续往深度学习方向进行研究,以实现进一步的技术突破。
2.1.2 深度视频伪造检测技术
由于智能手机和数据设备的普及,视频录制功能越发得强大,使得目前的视频存在成本低、易于捕获以及易于在社交媒体共享的特点。然而视频编辑工具和技术的发展迅猛,也使得视频的伪造变得越发容易。很多不法分子通过视频伪造用于宣传不良言论、获取非法利益,使得目前的视频的真实性不断地受到公众的质疑。其中深度视频伪造检测技术可分为主动检测和被动检测两类[61]。主动检测可以进一步分为数字水印和数字签字两类,这两类均是通过在视频数据中加入不可见的信息,如若视频被篡改不可见信息便会自动发生改变,但因该方法过于依赖算法和硬件的实现以及先验信息的获取,故学者们更加偏向于研究被动检测的技术。被动检测技术则是利用由于视频伪造而在视频帧中留下的肉眼无法识别的痕迹进行视频伪造检测。这种痕迹多是统计数据的变化,如噪声、纹理、光流差异等等,学者们则是通过将视频帧中实现帧的差异检测从而实现视频伪造的真伪检测。
Yang等人[62]针对当时的深度视频伪造多是通过拼接合成人脸创建到原始视频中这一缺陷,引入3D头部姿势(头部方向和位置)的方法来训练SVM分类器用于区分原始视频数据和深度伪造视频数据。考虑到伪造视频在媒体中传播之快,JPEG委员会发起了JPEG Fake Media探索,目的是产生一个可以促进对媒体资产创建和修改进行安全可靠注释的标准,该标准可支持多种应用场景[63]。Demir等人[64]针对计算机伪造视频不具备人类的生物信号的特点,提出了基于眼睛和凝视特征构建的深度视频伪造检测器,并将视觉、几何度量和光谱集成在其中,实现在CelebDF数据集上88.35%的检测准确率。Zhou等人[13]针对生成的伪造视频在视听上不同步的问题,提出一种视觉/听觉深度伪造联合检测技术,并表明视听内在同步有利于深度视频伪造检测,并产生了出色的泛化能力。
现有的被动深度视频伪造检测技术分为空间和时间两个部分。虽然目前学者们利用这两部分获得了不少成果,但由于手工制作深度伪造视频是一项相当耗时的工作,导致目前学术环境中仍然缺乏大型的深度伪造视频标准化数据集,使得研究人员的研究很难获得大的突破。其次,由于目前篡改技术的不断增多,视频伪造篡改不再仅限于一种类型的篡改,视频伪造检测的难度也在不断地提升。未来视频伪造数据集的建立以及多类型视频伪造检测是学者们可以接续研究的热点以及难点。
2.1.3 深度图像伪造检测技术
数字图像目前在报纸、数字取证、科学研究、医学等领域都发挥着重要作用。考虑到通过WhatsApp、Instagram、Telegram和Reddit等各种社交媒体平台过度使用图像共享的功能,区分深度伪造图像的真伪将是一项十分具有挑战性的任务[65]。深度伪造图像检测的方法目前可分为主动和被动两种方法。主动方法即和深度图像和视频伪造的主动方法类似,利用数字签字和水印实现。而被动检测又可分为独立和非独立两种方式:独立检测侧重于检测图像重采样和压缩伪造;非独立检测则侧重于图像拼接、复制和移动伪造。
Jeong等人[66]针对传统深度图像伪造检测方法严重依赖训练设置,会导致测试性能的下降的问题,提出双边高通滤波器(BiHPF),它通过放大在合成图像中发现的频率水平伪影的效果,实现稳健地检测出各类深度伪造图像。Liu等人[67]针对目前伪造检测技术在遇到一些常见转换(如模糊、调整大小)时出现泛化能力不足的问题,提出了一种新颖的块混洗学习并结合对抗损失算法克服混洗引入的噪声带来的过拟合问题,实现深度图像伪造检测的先进泛化能力。Guarnera等人[68]使用期望最大化(EM)算法提取局部特征,然后训练分类器(K-NN、SVM、LDA)来分辨真实图像和由当时最新的五种架构生成的图像的真伪,结果表明,这个检测方案具有可解释性、对法医调查也很有价值。Hooda等人[69]针对基于DNN的深度伪造检测对于对抗性深度伪造生成的图像检测效果不好的问题,提出了正交梯度以减弱深度伪造技术的对抗性,以实现深度伪造检测器的鲁棒性。裘昊轩等人[70]针对伪造图像问题,提出改进的对抗生成算法APGD,通过使用生成对抗样本进行扰动,使得深度伪造模型出现失真,实现更快地检测出伪造图像,然而该方法只适合白盒攻击的场景。耿鹏志等人[71]提出了遮挡式增强方法以及光学变换的数据增强的伪造检测方法,实现了高鲁棒性的图像伪造检测,但存在泛化性不强的问题。
深度图像伪造检测是一个需要重点关注的问题、需要不断地根据深度图像伪造生成技术的更新进行对应的检测技术的升级换代。未来,深度图像伪造检测技术可以扩展到多种类型深度伪造图像检测以及多数据集的图像伪造检测实验,以提升深度图像伪造检测技术的精确性和泛化性能。
2.2 深度伪造检测数据集
深度伪造技术生成的一些成熟的伪造成果,被应用于深度伪造检测技术当中,使得有针对性地提升对应方面深度伪造检测检测器的鉴别真伪的能力。
根据深度伪造生成内容的差异,深度伪造检测数据集也对应分为了深度音频伪造检测、视频伪造检测、图像伪造检测数据集三类。本节将对这三类数据集进行对应的说明和总结。
2.2.1 深度音频伪造检测数据集
ASVspoof2019[72]:ASVspoof2019数据集是基于VCTK2标准的多说话人语音合成数据库,从107位演讲者(46名男性、61名女性)中收集的真实语音,该语音没有明显的通道或背景噪音影响,再通过深度伪造算法将真实语音数据进行深度音频伪造;该数据集完整地分为三个部分,第一部分用于训练,第二部分用于开发,第三部分用于评估。
DFDC[73]:DFDC(深度伪造检测挑战)数据集是现今最大的伪造视频数据集,包含100 000个视频和音频(英文)序列。
2.2.2 深度视频伪造检测数据集
Celeb-DF[74]:Celeb-DF数据集是一个大规模的深度伪造视频数据集,拥有5 639个高质量的深度伪造视频,200万帧数据对应于59位名人公开的YouTube视频片段,包括不同的性别、年龄和种族的合成过程;视频伪影、拼接边界、颜色不匹配、分辨率低等情况非常少。
UADFV[75]:UADFV数据集是一组深度伪造视频及其对应的真实视频,49个真实视频通过深度伪造技术生成对应的49个深度伪造视频,视频平均时长为11.14 s。
DF[76]:DF(Deep Fakes Dataset)是一组在真实世界下采集的肖像视频数据集,数据集中的视频的生成模型、分辨率、压缩、照明、纵横比、帧速率等等内容具有多样性,视频来源包括媒体来源、新闻文章和研究报告。总共有142个视频、时长32 min、内存占用30 GB。
DFor[77]:DFor(DeeperForensics-1.0)数据集由60 000个视频(50 000个真实视频、10 000个伪造视频)组成,1 760万帧的数据;DFor数据集中所有源视频都是在可控条件下获取到,伪造视频通过10种图像处理算法外推至10 000个视频,数据集示例如图4所示。

图4 DFor数据集伪造视频帧示例Fig.4 Example of fake video frame in DFor dataset
2.2.3 深度图像伪造检测数据集
由于深度图像伪造检测数据集中数据多是使用源数据集经过伪造方法生成的深度伪造图像,故本文列出一些最近学者们经常用于深度伪造生成图像的数据集。
FFHQ[47]:FFHQ(Flickr Faces-HQ)数据集,由分辨率为1 024×1 024的70 000张高质量图像组成,该数据集的图像是从Flickr上获得许可后抓取并进行自动对齐与裁剪后形成。
LSUN[78]:LSUN数据集中10个场景类别和20个对象类别中的每个都有大约100万个标记图像,其中场景类别包含了卧室、客厅、教室等场景图像;每个类别的图像以LMDB格式存储。
MS COCO[79]:(Microsoft Common Objects in Content)MS COCO数据集包含91个常见对象类型,其中82个对象有超过5 000个标记实例,总计328 000个图像250万个实例;与别的数据集相比,COCO数据集的类别更少,但每个类别的实例更多,这样可以帮助计算机进行详细的学习并精确定位。
CelebA[80]:CelebA数据集包含10 000个身份,每个身份拥有20张图像,总计200 000张人脸图像;其中CelebA数据集被分为三部分,前8 000个身份图像用于预训练以及微调,另外1 000个身份用于训练支持向量机(SVM),剩下的1 000个身份图像用于测试。
3 总结与展望
3.1 技术风险
深度伪造生成技术的发展虽然给学术实验上提供了便利,但同时也对人类的生活带来了很多的负面影响。目前深度伪造生成技术带来的技术风险如下所示。
(1)经济风险:如假新闻的制作,发送到社交媒体上,导致股市的波动、市场的混乱。
(2)伦理风险:如色情视频的制作,涉及到明星名人或者普通人,影响到公民的正常生活。
(3)社会风险:如伪造图像、视频的制作,涉及到案件取证照片、人脸识别系统中人脸数据库、案件参与视频中的人脸等等,这些内容在以后的科技发展中,深度伪造生成都可能涉及,能够帮助到犯罪违法分子作案,影响到社会、民众安全。
(4)政治风险:如国家领导人的假言论制作,并将视频传到国内外网站,造成国家间民众、民族、领导人的误解,造成政治上的威胁。
3.2 研究难点
虽然目前深度伪造检测技术,在很多方面都实现了卓越的成果,但随着深度伪造技术的对抗提升,检测的难度系数也在不断提升。目前深度伪造检测技术的研究难点如下。
(1)针对对抗性扰动处理(如调整大小、模糊等),深度伪造检测鲁棒性不好。
(2)泛化能力较弱,针对单一数据集的检测效果好,切换其余特定数据集的检测可能会检测效果下降。
(3)生物信号的伪造效果提升,例如嘴部动作细节、眼球变化幅度随着深度伪造生成技术的不断突破,深度伪造检测的难度也在不断地提升。
(4)随着社交媒体使用量的爆发性增长,合成视频、图像、音频的数量也在大幅度地增加,针对互联网海量的数据资源,目前普通的深度伪造检测技术都难以做到个个精准检测。
(5)网络的全球范围的覆盖使得深度伪造生成的成果可以大范围跨国地传输,深度伪造生成技术成果覆盖率的提升将给深度伪造检测带来很大的困难。
(6)目前的深度伪造检测多是很多公众人物的检测,因其数据量充足;针对普通大众的检测效果并不如意。
3.3 未来研究方向
针对目前的社会发展,深度伪造生成技术可以进行如下接续研究。
(1)研究具有权限性的深度伪造生成技术:由于深度伪造生成技术的研究越发地趋向成熟,且研究的权限设置不够严谨,使得很多不法分子很容易就能获取相关技术进行有目的深度伪造生成,生成了许多对社会有害的伪造成果。未来,深度伪造生成技术可以添加一些权限认定功能,例如身份认证、用处认证、地址认证等等,以防止深度伪造生成技术被不法分子用于危害社会、侵犯公众合法权益等等。
(2)研究生成更加趋近于真实的伪造成果的深度伪造生成技术:目前在深度伪造生成技术方面虽然已经获得了不少的成果,但在生成效果上看,还是有些差强人意,例如在音频伪造生成中存在噪音、视频伪造生成中存在变化僵硬(不连续)、图像伪造生成的图像存在纹理上的缺失等等。未来的工作可以就提升深度伪造生成成果的效果进行进一步的研究。
(3)研究更加多元化的深度伪造生成数据集:深度伪造生成技术总归来说多是利用深度学习相关的技术进行实现,数据作为模型能够更好训练的依据,数据质量的提升也是必须要完成的。不仅仅是数据的量要大,且数据集的数据标注的正确率也必须对应得到提升;包含的内容也不能仅限于性别、种族、年龄的差异,而应该扩充一下光照程度、嘴部眼部等姿态变化等等差异数据集。
针对目前深度伪造生成技术的发展,对应深度伪造检测技术可以如下接续研究。
(1)研究计算机目前无法学习的生物信号的检测算法:已有的检测方法,很大部分是针对眼球变化、嘴唇变化与伪造人脸视频帧不对应的问题进行检测研究。未来,人们可以研究针对心跳、血压等等生理信号进行检测的研究,以实现检测准确率的提升。
(2)研究泛化能力强的检测算法:目前深度伪造生成的方法层出不穷,生成出来的伪造音频、视频、图像数据集越来越多,生成能够检测更多数据集的检测技术是目前可以研究的方向。
(3)研究鲁棒性强的检测算法:目前的检测算法均在处理很好的数据集上进行检测,故一遇到对抗性信号、噪声等问题就会出现检测率降低的情况。故目前可以研究对复杂数据的检测问题,以实现检测的强鲁棒性。
(4)研究和大数据相关的检测算法:目前的检测算法大多针对固定的数据或数据集进行检测,针对海量的社交媒体数据的研究很少。故目前可以结合一些盛行的区块链、云计算等大数据相关的技术一起研究伪造检测问题,以应对海量的数据。
(5)研究多国协同的检测算法:目前的检测技术,都是国家内部的研究,而针对现在网络的跨国覆盖,网络内容安全是国与国之间良好关系的保障。故目前针对深度伪造跨境性问题,可以通过多国之间在网络内容上的合作交流,实现深度伪造检测多国深度交流合作进行解决。
(6)研究更加普适的检测算法:目前的检测技术,都是基于一些公众知名人物的检测。而针对普通大众的检测少之又少,这和数据量的缺乏有很大的关系。故目前的研究,可以多针对普通大众进行,以实现所有公民的权力都不受伪造生成的侵害,也可以进一步地提升模型的泛化能力。
4 结束语
随着深度伪造生成技术的快速发展,深度伪造检测技术也在对应着对抗发展。未来深度伪造生成与检测技术研究,应多关注研究现存的深度伪造生成与检测的相关技术问题,并进行相应的改进和创新。本文对深度伪造生成与检测进行分析和总结,并对其存在的技术风险、研究难点也进行了分析与总结。最后对未来研究方向进行了一定的展望,旨在为推动深度伪造生成与检测领域的进一步应用和发展提供指导和参考。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
家庭影院技术(2021年1期)2021-03-19
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
福建基础教育研究(2019年6期)2019-05-28
家庭影院技术(2018年11期)2019-01-21
小说界(2018年5期)2018-11-26
电子制作(2018年19期)2018-11-14
