
结合时间特征的协同过滤深度推荐算法
2022-12-06 10:27魏紫钰朱小栋
计算机工程与应用 2022年23期
魏紫钰,朱小栋,徐 怡
上海理工大学 管理学院,上海 200093
在大数据时代,信息种类越来越多,体量越来越大,并且用户在新闻阅读、电子商务、视频娱乐等平台偏好于从平台推荐来获取信息[1]。如果能将这些信息精准地推荐给用户,那么就会有巨大的商业价值,因此推荐算法已经越来越成为学者研究的方向。
推荐算法模型主要分为基于内容的推荐、基于协同过滤的推荐,以及其他推荐算法[2],其中应用范围最广的是协同过滤推荐算法[3],基本思想是利用所有用户的协作行为来预测目标用户的行为[4]。协同过滤算法中的核心主要是基于矩阵分解(MF)的推荐算法,矩阵分解技术根据用户和项目的特征构建了一个评分矩阵,通过内积的方式去重构矩阵。但是仅仅依靠用户和项目的基本特征是无法挖掘出更深层次的关联性,因而无法更加准确地作出推荐[5]。
基于协同过滤的推荐算法还存在一些问题。当需要推荐新的用户或者新的项目时,没有相关的历史数据,无法针对其进行推荐,遇到冷启动问题。并且,不是所有的用户和项目都有交互数据,导致评分数据稀疏,遇到数据稀疏性问题[6-7]。同时,如何能够提取用户和物品中的特征,也是需要考虑的问题。
对于冷启动问题,Dureddy等人[8]创新提出了一种利用冷启动用户来生成用户嵌入的方法,主要是通过让冷启动用户回答几个问题,再将问题和答案传递到推荐模型中,在一定程度上能解决冷启动问题。对于数据稀疏性问题,Wang等人[9]提出了名为协作深度学习的分层贝叶斯模型,通过结合内容信息深度表示和评分矩阵的协同过滤方法,能够有效地缓解辅助信息的稀疏问题。Lei等人[10]提出了DeepCoNN模型,该模型通过两个并列的神经网络,分别学习用户和项目的特征信息,最后通过一个共享层将两个神经网络学习的结果融合起来,最后得到预测评级。在对于特征提取方面,李同欢等人[11]提出的多交互混合推荐模型,将输入信息通过多层交互的非线性深度学习网络融合了多种辅助信息,从而能获得不同层次的特征表示结果,在一定程度上缓解了数据稀疏性的问题。刘振鹏等人[12]将用户和项目的隐藏特征学习出来,再结合用户的评分提出了一种新的混合推荐模型。冯楚滢等人[13]提出了一种协同深度学习算法,利用深度学习训练大量数据,融入协同过滤进行推荐。陈彬等人[14]提出一种基于深度神经网络和深度交叉网络以及因子分解剂的混合推荐模型,充分挖掘属性特征间的隐性关联关系。Alfarhood等人[15]提出DeepHCF是目前理论和实验效果都比较出色的融合模型。该模型使用深层神经网络挖掘用户和项目的隐表示,将用户和项目隐表示输入因子分解机预测评分。
周传华等人[16]在DeepHCF的基础上进行了改进,针对个性化推荐中用户评分矩阵数据集稀疏的问题,充分利用用户和项目描述信息,提出了DeepRec算法。这些研究都能够一定程度上解决冷启动问题,同时有效缓解了数据稀疏性。但时间因素也会对于推荐结果产生重要影响。
针对时间因素,Wu等人[17]提出用一个深度循环神经网络来追踪用户如何浏览网页,通过构建隐藏层模拟用户访问的网页组合和顺序,同时利用GRU更好地提升了效果。Wu等人[18]提出一种基于LSTM(long shortterm memory)的循环推荐网络(RRN)以适应用户和项目随时间的动态性。Sun等人[19]提出一种基于注意力的循环网络社交推荐方法(ARSE),通过融合用户之间的社交影响来模拟用户随时间变化的偏好。同时,卷积神经网络对于推荐系统的性能提高也是一个有利的工具。蔡念等人[20]提出一种改进矩阵分解与跨通道卷积神经网络结合的推荐模型,将用户对项目的评价文本信息特征提取,提高预测模型的准确度。
综上所述,如果能充分利用用户在时间维度上的信息来挖掘用户的隐藏偏好,这样就能够提高推荐的准确度。因此,本文的主要贡献是:首先模型使用二进制的表示法表示用户与项目的ID编号,有效地缓解了one-hot编码带来的数据稀疏性问题。其次提出了两种结合时间特征的协同过滤深度推荐算法,提取出了用户和项目特征之间的隐藏特征,结合时间戳信息,通过深度神经网络进行学习和推荐。其中,C-DRAWT算法利用卷积神经网络的特点,能够有效提取用户近期的偏好;M-DRAWT算法利用多层感知机的特点,能够挖掘用户的历史偏好,以提高推荐的效率与准确度。在MovieLens数据集上的实验结果表明,本文提出的C-DRAWT和M-DRAWT算法有优于前人模型的效果。
1 相关工作
1.1 隐藏特征提取
本文提出的基于卷积神经网络的隐藏特征时间异构推荐算法主要思路流程如图1所示,通过对原User和Item的数据进行处理,将数据全部数值化。

图1 隐藏特征提取算法结构Fig.1 Structure of hidden feature extraction
定义1对于User方面,用户集的定义为:

定义2则对于所有User的用户集表示为:

定义3对于Item方面,用户集的定义为:

定义4则对于所有Item的用户集表示为:

将Uinf与Iinf分别输入至两个嵌入层中,将其各自设置确定的维度,得到对应维度的特征表示。并将两方数据分别放入两个全连接层,得到更深层次的特征表示,同时也为了更新维度。全连接层表示为:

另外在Item一侧,因为文本信息往往包含更多的隐藏特征,因此将包含文本的原始数据单独放入图2所示的TextCNN模型中,得到从文本中提取的特征信息后,再与其他Item特征从全连接层得到的特征表示融合在一起,进一步放入一个新的全连接层,得到最终提取到的Item隐藏特征。
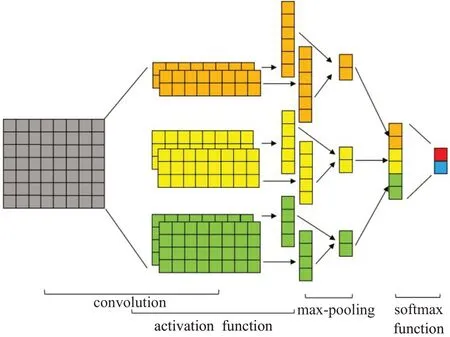
图2 TextCNN结构Fig.2 Structure of TextCNN
同时为了统一维度,用户数据也一同放入200维的全连接层,得到最终提取的基于User的隐藏特征User Feature与基于Item的隐藏特征Item Feature。中间层得到需要的隐藏特征之后,需要进行输出训练优化以得到最好的结果。所以将User Feature与Movie Feature一同放入全连接层以输出预测的用户对电影的评分,与实际第三个数据集中真实的评分相拟合,利用MSE以降低误差进行训练优化,以得到最优的User Feature与Item Feature/Movie Feature。
当得到用户特征与项目特征,接下来根据时间戳来构建想要的数据。时间戳的结构为,用户第t(t∈[1,3])时刻选择过的项目的ID和特征,以及用户对于该项目的评分。本文采用二进制编码的形式,对UserID和ItemID进行编码,就会极其有效地降低了one-hot编码导致的内存的消耗与数据稀疏问题。

数据按照时间戳的顺序进行排列,完整整合之后是864维的数据格式,并且与之相对的y值是在第四时刻用户购买或者想看的项目ID,同样也是利用二进制表示方法,结构如图3所示。
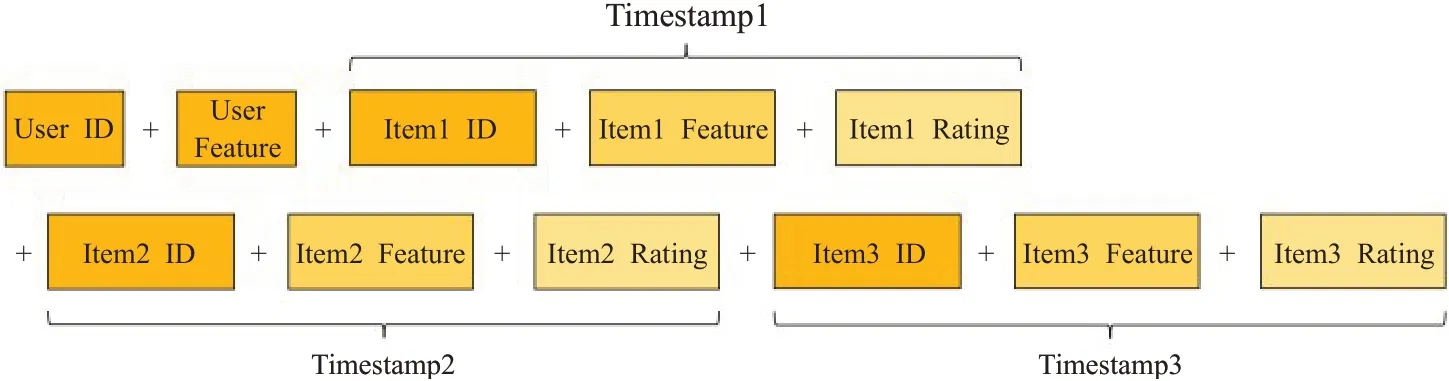
图3 时间戳特征拼接Fig.3 Timestamp concat
1.2 C-DRAWT
本文提出的第一个模型是基于卷积神经网络而设计的协同过滤深度推荐模型C-DRAWT。
本文所设计的卷积神经网络结构如图4所示。输入的数据是隐藏特征提取部分提取出来的隐藏特征向量。首先是第一层一维卷积形成特征图mi,卷积核大小设置为600×1,以便融合后续第二时刻和第三时刻的Item信息,公式如下。其中,F表示卷积核,*表示卷积运算,bi表示偏置项,f()·表示一个非线性激活函数,本模型中使用Relu函数。

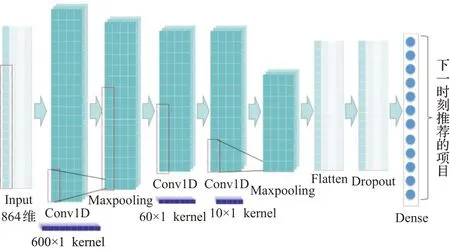
图4 C-DRAWT中的卷积神经网络结构Fig.4 Structure of CNN in C-DRAWT
接下来连接池化层,本文采用的池化方法为最大池化法(Max-pooling),目的是通过消除非极大值来降低需要运算的参数量,从而降低运算复杂度,在一定程度上也控制了过拟合。其中,池化窗口大小设置为3。其中,p表示池化结果,max(·)表示最大池化操作。

随后再连接两个卷积层,其中两个卷积核的大小分别为60×1和10×1。随后连接一个池化层,同样为最大池化,池化窗口大小为3,池化结果连接了一个Flatten层和一个Dropout层,以平坦数据维度和增加泛化能力。

最后,输出层输出维度为12的结果,也就是本文所要预测的时间戳t=4时的项目ID,即下一时刻用户最想看到的项目。
1.3 M-DRAWT
本文提出的第二个模型是结合MLP所提出的基于MLP的时间异质深度推荐模型M-DRAWT(MLP-deep recommend model with time),此模型所利用的多层感知机结构如图5所示。
本文采用的多层感知机是包括输出层在内的一共5层的网络结构,将特征集合D输入到4层MLP中,输出维度为12维,也就是本文要的第四时刻项目的ID,即下一时刻用户最想观看或购买的项目的是哪一个,并且在每一层全连接层中间都会有Dropout层进行神经元的丢弃,丢弃概率都设置为0.5,以减少模型参数,增加模型的泛化能力,避免过拟合,完整的M-DRAWT结构如图5所示。
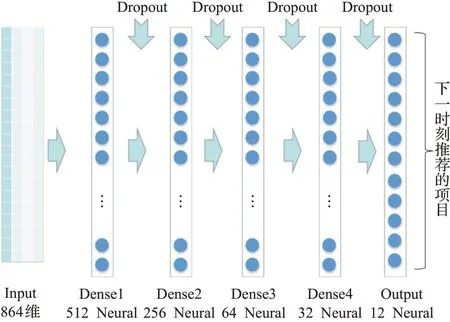
图5 M-DRAWT中的多层感知机结构Fig.5 Structure of MLP in M-DRAWT
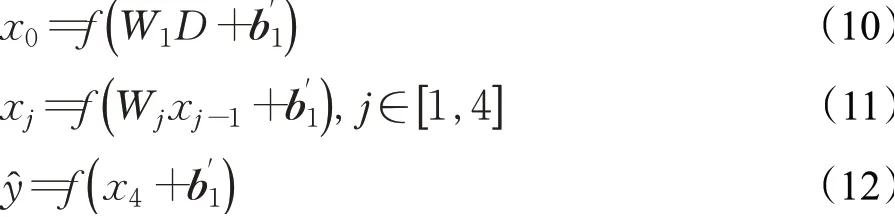
其中,x0为第一层输出值,xj为后三层输出值,W1和Wj表示权重,f(·)表示激活函数,b"1表示偏置向量。
2 基于MovieLens的实验
2.1 实验数据
本次实验用到的是MovieLens-1M的数据集,是在经过预处理后,将其划分为互不相交的训练集和测试集,其中训练集占80%,测试集占20%。数据集的信息如表1所示。

表1 实验数据集信息表Table 1 Dataset of expriments
2.2 评价指标
本文运用均方根误差(RMSE)作为损失函数,精确度(Precision)、召回率(Recall)和F1-Score值来评价指标来检验模型效果。
均方根误差(RMSE)作为损失函数能反映出预测值与真实值之间的偏差,偏差值越小说明预测效果越好,公式如下所示:
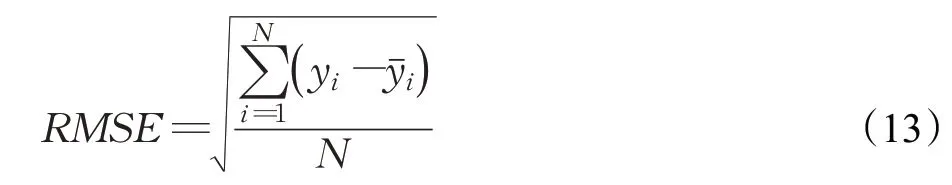
精确度(Precision)也称查准率,指的是分类器预测为正类的部分数据在实际数据的比例。精确度越高,分类器假正类错误率越低,公式如下所示:
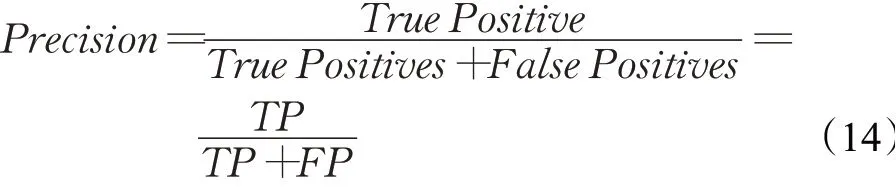
召回率(Recall)也称查全率,指的是被分类器正确预测的正样本的比例。具有高召回率的分类器很少将正样本分为负样本,公式如下所示:
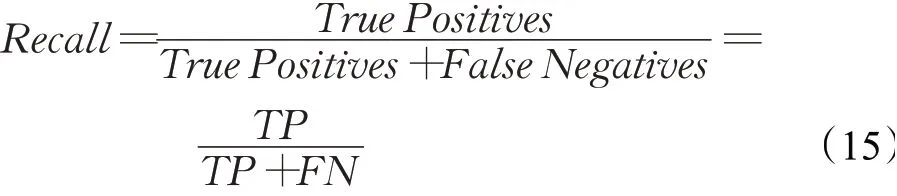
F1-Scoure值可以同时最大化精确率与召回率,使得精确度与召回率共存,是精确率和召回率的调和平均数,公式如下所示:
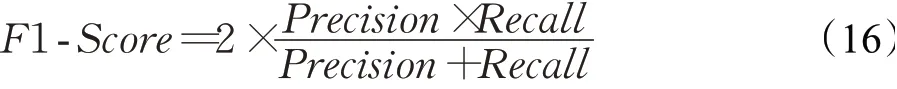
2.3 对比实验
本文通过与以下几种先进的模型进行对比实验,来验证本文所提模型的推荐性能。
(1)PMF[21]:概率矩阵分解模型,通过用户和项目的评分交互矩阵进行协同过滤推荐。
(2)DeepCoNN[11]:使用推荐评论对用户和项目进行联合深度建模模型,通过卷积神经网络将用户评论集和项目评论集结合起来对用户和项目进行建模
(2)ConvMF[22]:卷积矩阵分解模型,将卷积神经网络与矩阵分解模型进行推荐。
(3)DeepHCF[15]:结合CNN和MLP分别从评分和项目评论中挖掘用户和项目的潜在特征,并使用因子分解方法预测评分。
(4)DeepRec[16]:融合评分矩阵和评论文本的深度神经网络推荐模型,它是一种由多层感知机和卷积神经网络组成的推荐方法,该模型将两种不同的数据类型作为输入。
2.4 实验结果与分析
2.4.1 模型性能分析
实验的F1-Score值结果和RMSE实验结果如图6和图7所示。
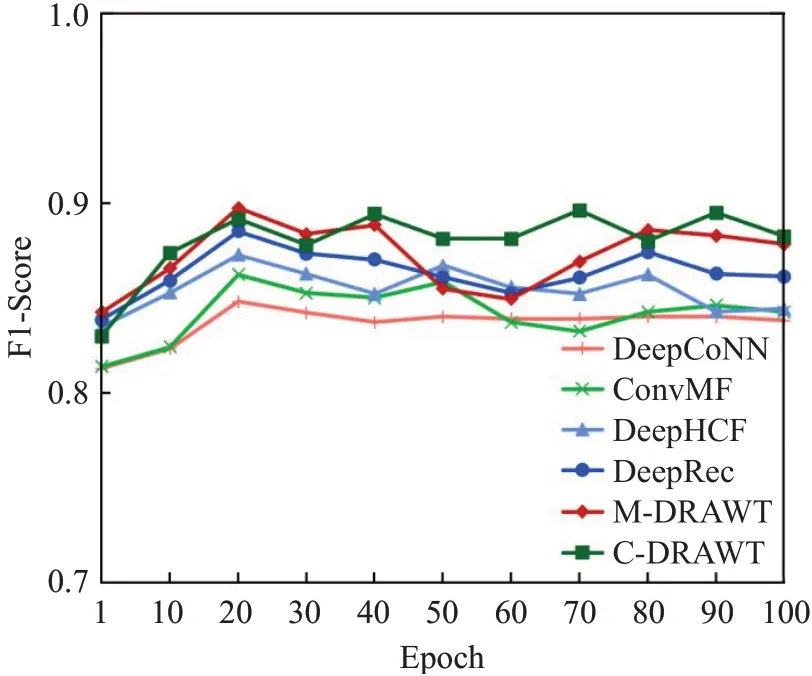
图6 F1-Score值对比图Fig.6 Comparison of F1-Score values
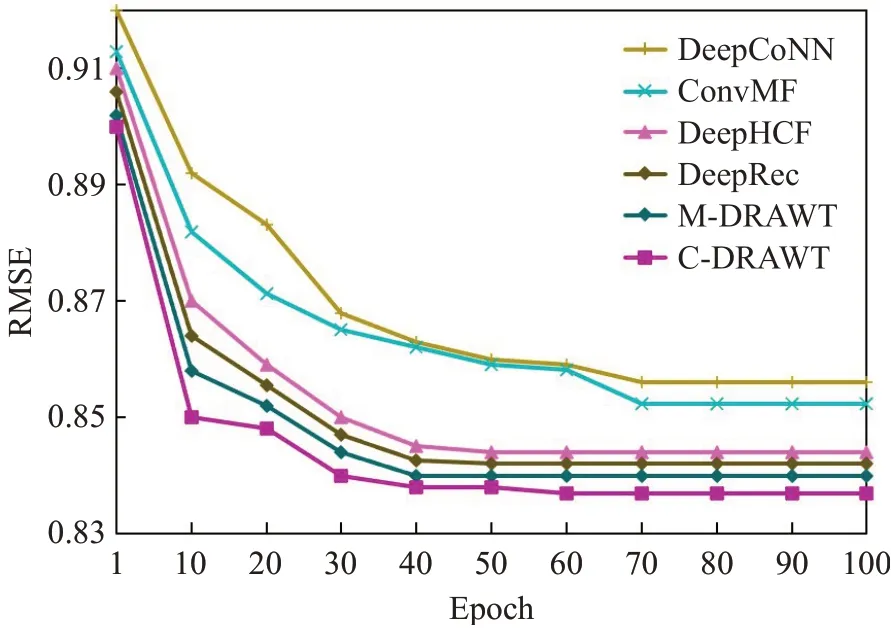
图7 RMSE损失函数对比图Fig.7 Comparison of RMSE loss function
F1-Score值随着训练epoch数的增加而趋于稳定,效果最好的是C-DRAWT,其次是M-DRAWT。二者的结果均优于DeepCoNN、ConvMF和DeepHCF。RMSE损失函数值随着epoch数的增加而下降并收敛,效果最好的仍是C-DRAWT和M-DRAWT,并且优于DeepCoNN、ConvMF和DeepHCF。模型的综合对比结果如表2所示。
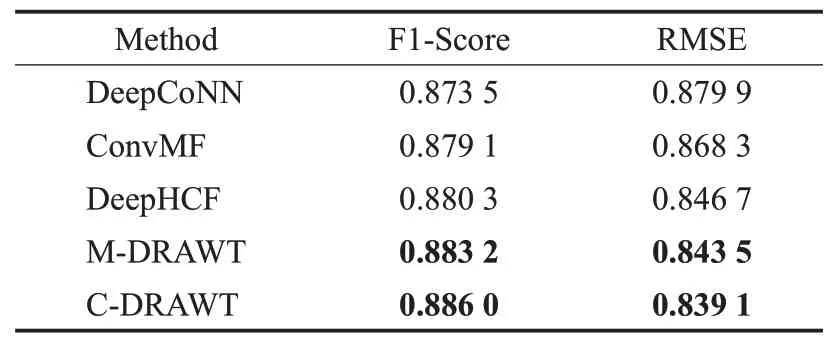
表2 对比实验结果Table 2 Comparison of experimental results
从表2中可知,C-DRAWT和M-DRAWT在F1-Score值和RMSE上都有所提高。相比较于DeepCoNN,M-DRAWT的F1-Score提升了1.11%,RMSE提升了4.1%,C-DRAWT的F1-Score提升了1.43%,RMSE提升了4.6%;相比较于ConvMF,M-DRAWT的F1-Score提升了0.46%,RMSE提升了2.85%,C-DRAWT的F1-Score提升了0.78%,RMSE提升了3.36%;相比较于DeepHCF,M-DRAWT的F1-Score提升了0.3%,RMSE提升了0.37%,C-DRAWT的F1-Score提升了0.65%,RMSE提升了0.9%。综合上述结果可以看出,综合了时间信息的C-DRAWT和M-DRAWT在各个评价指标上优于其他对比算法,有着较好的推荐性能。
图8为模型运行时间的对比。可以看出,基于矩阵分解的模型在训练大量的矩阵数据中需要消耗大量的时间,而本文所设计的基于神经网络的模型采用one-hot编码降低了数据稀疏性,并且本文采用的CNN模型中的池化操作降低了数据维度,从而降低了复杂度。
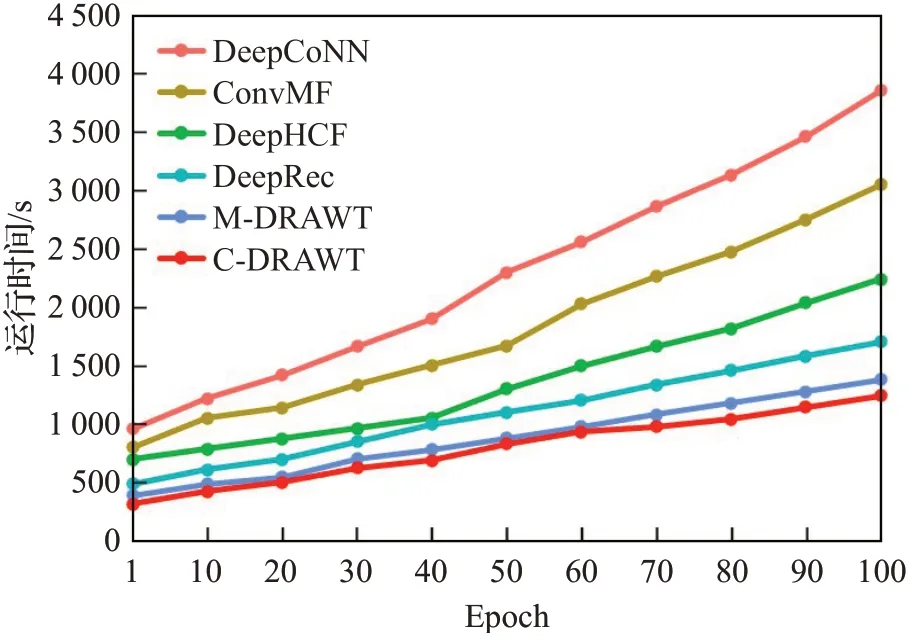
图8 模型运行时间对比Fig.8 Comparison of model running time
2.4.2 编码分析
为了能够更好地表示拥护和项目的信息,缓解数据稀疏性问题,本文采用了二进制编码来代替one-hot编码。为了验证二进制编码的优异性,本文通过同一个模型采用两种编码方法,选取MovieLens-10M数据集上进行对比实验。同时还对比了模型在训练集不同比例下的结果,如图9和图10所示。结果表明,二进制编码的方法更能表示用户和项目的大量隐信息,并且当训练集比例越高模型效果也好,这表明模型是用了更多的辅助信息进行训练后能产生更高的预测效果。
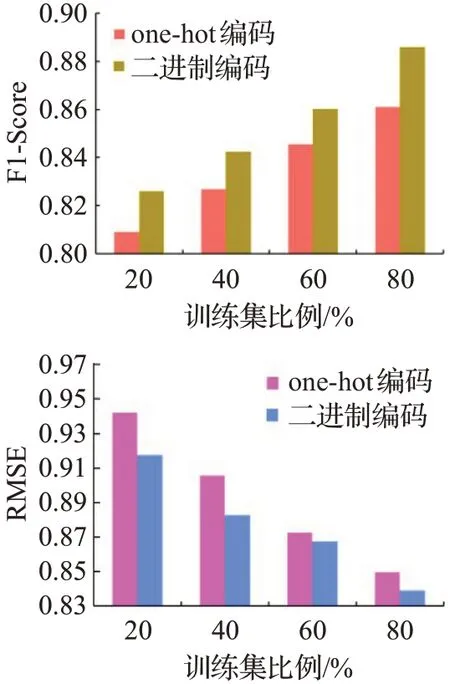
图9 基于C-DRAWT的one-hot编码与二进制编码对比分析Fig.9 Comparison of one-hot encoding and binary encoding based on C-DRAWT
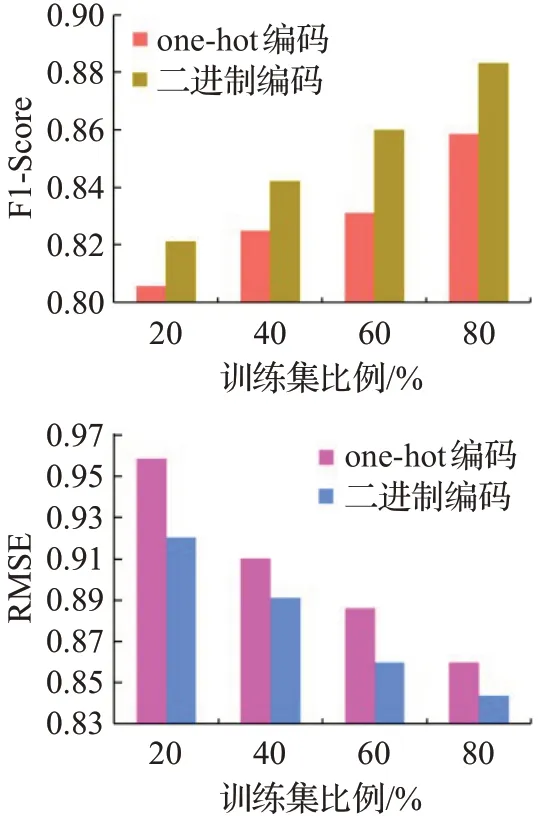
图10 基于M-DRAWT的one-hot编码与二进制编码对比分析Fig.10 Comparison of one-hot encoding and binary encoding based on M-DRAWT
2.4.3 Dropout比率分析
在C-DRAWT和M-DRAWT模型中,均加入了Dropout技术,这是因为Dropout技术可以有效地防止模型过拟合,得到更好的泛化性。两个模型中具体的Dropout比率都设置为了0.5,这样设置是因为经过实验表明,当Dropout=0.5时,其RMSE最小即模型表现最好,结果如图11所示。
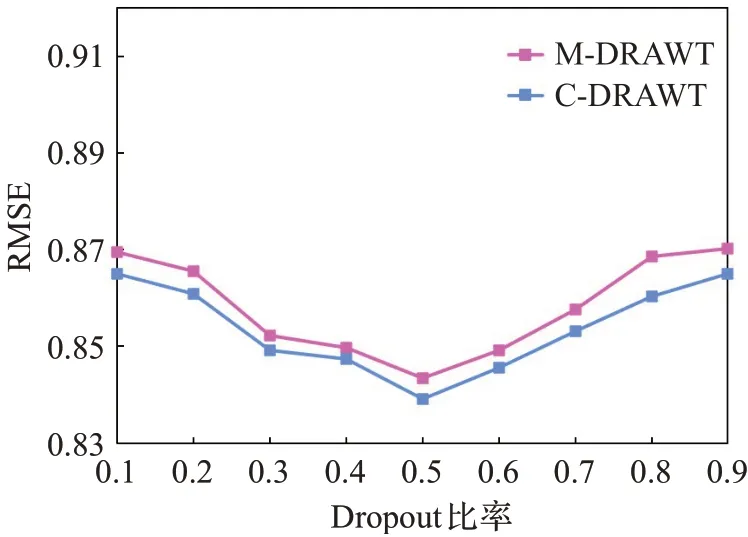
图11 Dropout比率对模型效果的影响Fig.11 Impact of dropout ratio on model performance
3 结束语
本文提出了基于卷积神经网络的结合时间特征的协同过滤深度推荐算法(C-DRAWT)与基于多层感知机的结合时间特征的协同过滤深度推荐算法(M-DRAWT),主要贡献是将推荐任务转化为用户下一时刻最希望看到的项目,在特征提取前用二进制表示法取代one-hot编码,极大地减少了数据维度。随后对提取出的用户和项目隐藏特征加入时间戳信息,再利用改进后的卷积神经网络和多层感知机进行预测推荐,C-DRAWT和M-DRAWT更能够实时了解用户的兴趣点,有效地解决了数据稀疏性,缓解了冷启动问题。进一步的工作会继续优化算法,减少计算资源的消耗,提升计算速度和效果。
猜你喜欢
现代电力(2022年2期)2022-05-23
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
疯狂英语·新读写(2018年3期)2018-11-29
