
适用于点云数据的注意力机制研究
2022-12-06 10:36孙一珺李子钥吴少奕
计算机工程与应用 2022年23期
孙一珺,胡 辉,李子钥,陈 阳,吴少奕
华东交通大学 信息工程学院,南昌 330013
近年来,深度学习在图像处理领域取得了显著的成果,其中卷积神经网络(convolutional neural network,CNN)对于规整的图像数据[1]具有优异的效果。随着无人驾驶需求的日益增加,激光雷达点云数据和图像数据一样,逐渐变成了一种深度学习的基本数据。然而,由于点云数据固有的非结构性与无序性特点[2],使得一些传统的图像领域的深度学习方法无法直接应用于点云领域。
为了将卷积的优势发挥在点云处理领域,先前的研究者使用多视图思想对三维数据的每一个角度单独使用CNN并融合这些多角度信息实现数据处理[3],或是将三维CNN直接使用在点云领域[4]。但是这些方法均要求大量的计算资源且处理速度较慢,并不是点云处理领域的最优方法,如何直接使用三维点云数据作为网络输入因而成为了研究的热点。PointNet[5]网络作为直接使用点云数据的先驱者,有效地解决了点云特征获取和无序性的问题。这为之后的研究者提供了方向指引,如PAT[6]、LightPointNet[7]、PointWeb[8]。然而不同于CNN,多层感知器(multilayer perceptron,MLP)具有不能包含邻域信息,不能使用空洞卷积[9]等技巧的缺点,导致网络特征提取能力仍具有较大的优化空间。PointNet++[10]和DGCNN[11](dynamic graph CNN)分别通过模仿多层CNN的层次特点和K近邻算法构建邻域使网络具有了邻域信息,RS-CNN[12](relation shape CNN)和Moment[13]则通过丰富网络输入从而使网络性能提升。除了以上的方法,注意力机制的重要性在以往的文献中已经被广泛地研究,能够帮助网络明白应该关注哪些位置,提升网络表达能力。不同于WDGCNN[14](weighted dynamic graph CNN)需要手动设计一种权重,注意力机制可以帮助网络自适应地学习权重,使网络自动关注重要的特征,抑制非必要的特征。然而由于点云数据的特点,以往的注意力机制同样不能直接应用于点云领域。
针对这些问题,本文首先提出了一个简单有效的直接应用于点云数据的注意力机制,通过对点云数据进行并行的最大池化与平均池化,采用共享权重的多层感知器训练自适应注意力权重,并与输入特征相乘以增强网络特征表示能力,从而提升网络性能,可以广泛地应用于PointNet类网络的特征提取阶段,以提高网络的表征能力;其次对本文所提出注意机制的最优设计和使用方案进行研究分析;最后嵌入设计的注意力机制,验证了在不明显提高网络运算成本的前提下,多种三维点云处理任务(分类、分割、检测)的性能相比于原始网络有了很大提高。
1 相关研究工作
1.1 点云学习网络
由于CNN无法直接应用于点云领域,先前的研究者大多考虑使用间接法进行三维特征学习。MVCNN[3]的研究思路是通过多视图法处理三维数据,使用CNN获取某一角度的多视图特征,最后使用最大池化对多角度特征进行特征融合。VoxNet[4]通过三维网格将点云进行体素转换,并用三维CNN进行特征的学习。然而,受限于点云数据的稀疏性、计算成本以及间接转化导致的信息损失,通过间接法研究三维数据受到了较大的阻碍。Qi等人是直接使用原始点云作为网络输入的先驱者,提出了PoinNet网络,其网络直接使用点云作为输入而不需要任何间接变换,借助MLP获取非结构的点云特征,采用对称函数处理点云的无序性问题,使用变换网络(transformer network,T-Net)来实现点的对齐,从而处理点云图像的旋转不变性问题,然而这种网络缺少局部特征的构建能力。Qi等人之后提出的PointNet++网络通过不断使用基于最远点采样(farthest point sampling,FPS)的方法并逐层次地使用PointNet网络,从而获取了一定的点云局部特征。DGCNN通过K近邻算法为每个点构建了一个邻域图,提出了边缘卷积(edge convolution,EdgeConv)的概念,成功地为每个点构建了邻域特征,但采用的仍是MLP进行每一条边的特征学习。Point-GNN[15]明确地将图卷积的概念引入点云特征学习领域,在网络输入前对点云进行建图,之后采用图卷积神经网络(graph neural network,GCN)进行特征学习以进行物体检测,网络可以对一张点云同时进行多物体检测。RandLA-Net[16]设计了一种轻量高效的可处理大规模场景点云的网络,通过简单高效的随机采样替换常用的FPS以极大地降低计算成本并通过设计有效的局部特征模块增加网络的感受野,在大场景点云语义分割问题上获得了优异的成绩。
1.2 注意力机制
Google团队使用多头注意力和缩放点积注意力的自注意力(self attention)机制进行学习[17],代替了传统的编解码模型必须结合CNN或者RNN(recurrent neural network)的固有模式,在不降低可靠性的前提下减少了计算成本,提高了有效性。Sun等人[18]提出了堆叠注意力网络(stacked attention networks,SANs)来进行视觉问答任务(visual question answering,VQA),并通过实验说明三个或更多注意力层并不一定提高性能。Luong等人[19]提出了两种叫作局部和全局的注意力机制(local and global attention),全局注意力类似于传统的软注意力(soft attention)[20],局部注意力提供了网络在计算效率和可微性之间的参数权衡。CBAM[21]采用多角度池化的方法生成自适应的注意力权重以产生通道与空间注意力,并通过串行的方式融合通道与空间注意力,从而提高网络性能。与此不同,BAM[22]使用了空洞卷积的思想产生空间注意力权重,并与并行计算后的通道注意力相加激活后作为最终的注意力权重,最后与原始输入相加得到细化后的特征图。Chaudhari等人[23]总结出注意力的核心思想是对输入特征引入注意力权重,这些工作为本文设计适用于点云的注意力机制研究提供了指导思路。
2 点云注意力机制设计
现有的增强点云网络性能的方法一是设计新的网络结构,二是在现有结构上丰富网络输入。不需要像WDGCNN一样人为设计一种权重,注意力机制可以通过网络自适应地生成优化网络特征的权重,帮助网络学习需要对哪些信息进行强调或抑制,从而帮助特征在网络中的生成。本文设计了一种即插即用的适用于点云的轻量级注意力机制,可以随意嵌入到PointNet类网络的特征提取阶段,在不明显增加计算成本的情况下提升网络性能。嵌入有点云注意力机制的网络结构如图1所示。
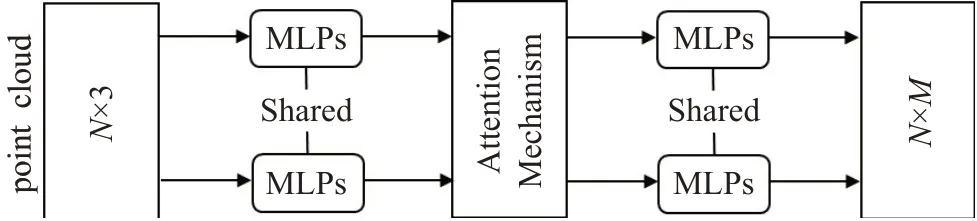
图1 注意力机制嵌入图Fig.1 Attention mechanism embedding map
2.1 应用于图像的通道与空间注意力
在图像处理领域,通道与空间注意力可以帮助网络在通道和空间两个分支上学习要注意“什么”和“哪里”,共用这两种注意力机制可以有效地提升网络性能。
对于图像数据,其特征在神经网络中可以表示为F∈ℝB×H×W×C,其中B、H、W、C分别表示Batch Size、图像的长、宽、特征通道数。融合的通道与空间注意力可以表示为:

其中,Mc∈ℝB×1×1×C表示一维的通道注意力,Ms∈ℝB×H×W×1表示二维的空间注意力,⊗代表矩阵叉乘,F""表示最终的输出特征。
对于通道注意力图Mc的计算过程为:
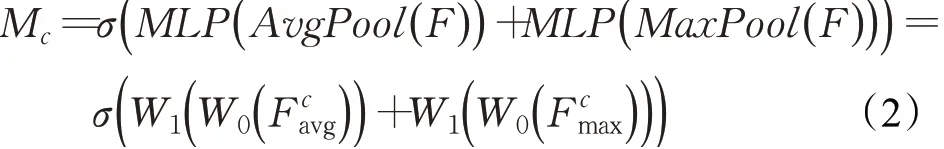
其中,σ表示激活函数,W0和W1表示MLP的权重,表示沿着特征通道数C维度对特征F进行平均池化和最大池化。
对于空间注意力图Ms的计算过程为:
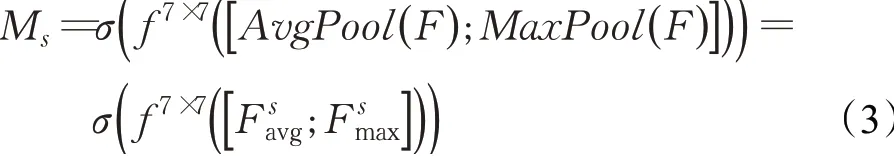
其中,σ表示激活函数,f7×7表示核为7×7的卷积运算,表示沿着图像的长、宽维度对特征F进行平均池化和最大池化。
2.2 设计适用于点云的注意力机制
不同于图像数据,点云数据具有非结构性与无序性的特点,其特征在神经网络中可以表示为F∈ℝB×N×1×C,其中B、N、C分别表示Batch Size、点云数目、特征通道数。
受到图像领域通道与空间注意力机制的启发,本文同样设计了两种注意力机制,分别沿着特征通道数C维度和点云数目N维度进行池化,可以表示为:

其中,Mc∈ℝB×N×1×C表示点云特征注意力机制,Fc表示点云特征注意力的输出特征,Mn∈ℝB×1×1×C表示点云通道注意力机制,Fn表示点云通道注意力的输出特征,⊗代表矩阵叉乘。
为了生成点云特征注意力机制Mc,借助CBAM的经验,采用不同的池化方法意味着通过不同的角度收集特征的信息,能够有效地提高网络表达性能。首先沿着特征通道数C维度,使用并行的平均池化和最大池化对点云输入特征F进行特征聚合,从而生成不同角度的特征表述符不同于图像数据的空间注意力,受限于点云数据的非结构性,本文未使用卷积操作进行权重训练,仍使用共享参数的单隐藏层MLP对聚合特征的特征通道数维度进行训练,用来生成注意力权重,最后使用激活函数σ激活权重。点云特征注意力机制Mc可以表示为:
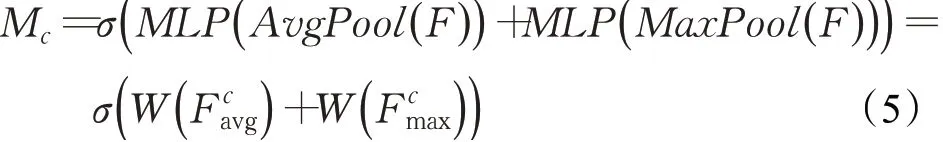
其中,σ表示sigmoid激活函数,W表示MLP的权重,表示沿着特征通道数C维度对特征F进行平均池化和最大池化。计算过程如图2(a)所示。
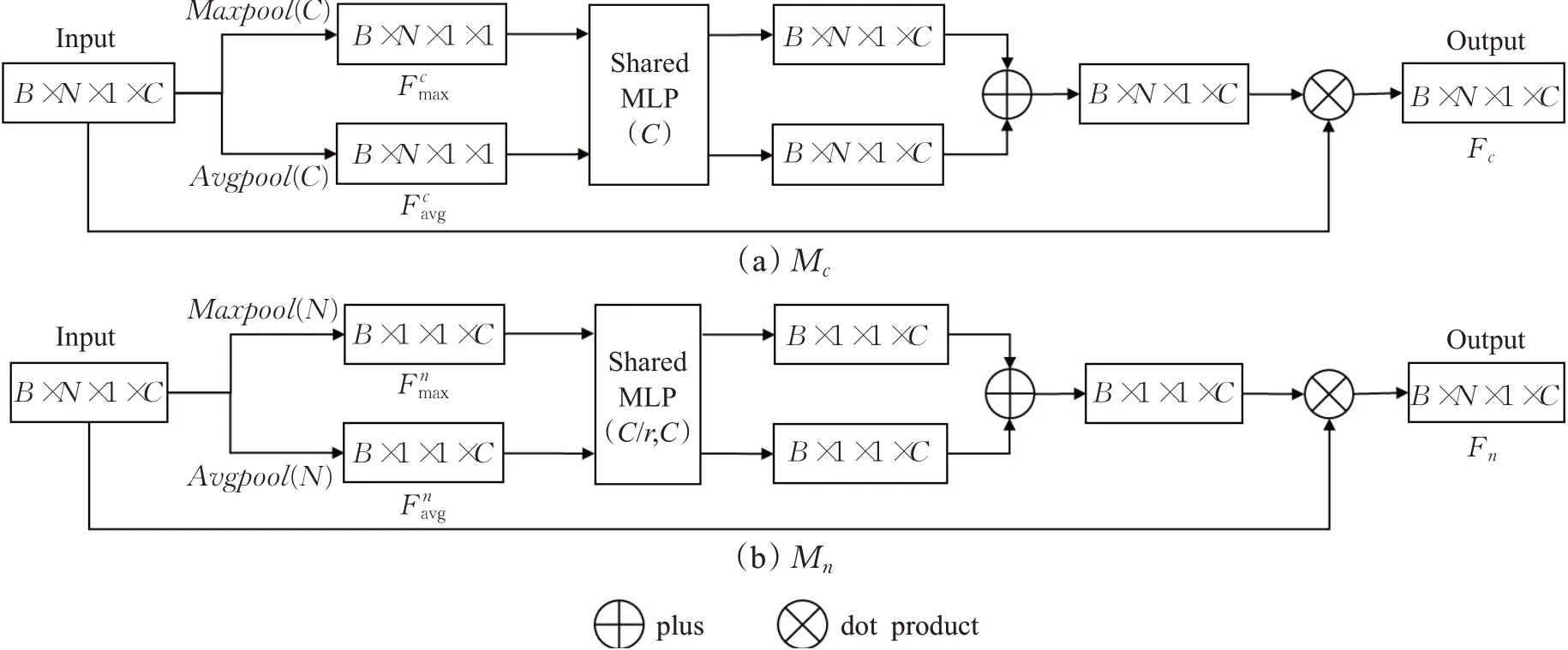
图2 注意力机制计算过程图Fig.2 Attention mechanism computation process map
为了生成点云通道注意力机制Mn,沿着特征通道数N维度,同样使用平均池化和最大池化对点云输入特征F进行特征聚合,生成不同角度的特征表述符Fnavg和Fnmax。由于在点云领域无法直接使用CNN,本文仍采用MLP对点云特征进行精炼,使用共享参数的双隐藏层MLP对聚合特征进行训练,对点云特征通道C先缩减再恢复,缩减系数为r,用来生成注意力权重,最后使用激活函数σ激活权重。点云通道注意力机制Mn可以表示为:
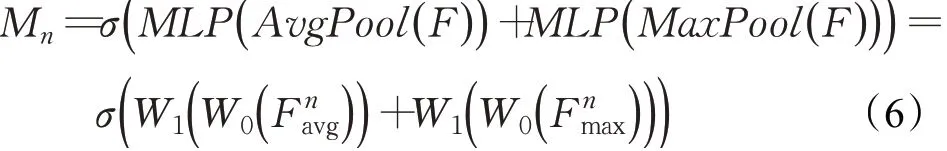
其中,σ表示sigmoid激活函数,W0和W1表示MLP的权重,表示沿着点云数目N维度对特征F进行平均池化和最大池化。计算过程如图2(b)所示。
3 实验与结果分析
3.1 实验配置
实验的硬件环境为Intel Core i7-6700 CPU、32 GB内存,GeForce GTX 1080ti显卡、11 GB显存。软件环境为Ubuntu 16.04 x64操作系统、Anaconda 1.7.2、Cuda10.1、Cudnn 7.6.5、TensorFlow 1.14、Python 3.6.1。
3.2 注意力机制设计分析
本节通过对嵌入有适用于点云注意力机制的Point-Net网络在ModelNet40[24]分类数据集上的分类效果研究,对不同的注意力机制设计进行了分析。ModelNet40点云分类数据集共有40种物体种类,12 311个点云模型,其中训练集9 842个,测试集2 468个。
为研究多角度的池化特征融合顺序对网络性能的影响,本文设计了先融合后训练的注意力机制Mc"、Mn",设计方案如图3(a)、(b)所示。此外,受到CBAM的启发,本文同样对两种注意力机制的融合效果进行了研究,根据特征和通道注意力机制的使用顺序,分别设计了Mcn、Mnc两种融合方案,设计方案如图3(c)、(d)所示。
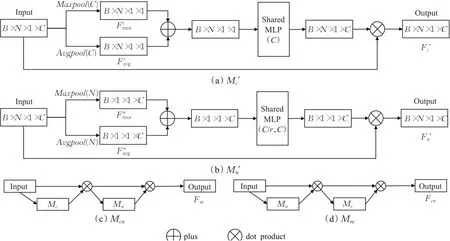
图3 其他注意力机制设计方案图Fig.3 Other attention mechanism design plans
在表1中给出了不同注意力设计方案在ModelNet40上的分类准确率(overall accuracy,OA)结果。PointNet(vanllia)相比于PointNet网络减少了T-Net,—表示不使用注意力机制的原始网络框架,PointNet(vanllia)和PointNet的Batch Size分别设置为64、32,其余设置遵循原网络设置。
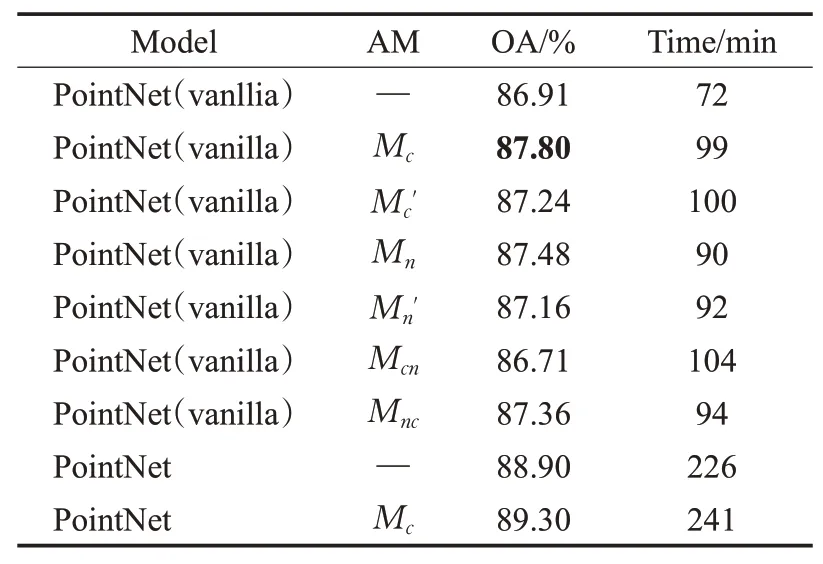
表1 注意力机制设计方案Table 1 Design of attention mechanism
点云特征注意力机制Mc和点云通道注意力机制Mn将OA提升至87.80%和87.48%,相比于原始的PointNet(vanllia)网络分别提升了0.89和0.57个百分点,实验结果表明本文设计的两种注意力机制对点云数据的特征提取均发挥了积极的作用,验证了机制设计的合理性。同时,相比于点云通道注意力机制Mn,点云特征注意力机制Mc具有更优的效果。当注意力机制Mc对点云特征沿着特征通道数维度进行池化,并通过MLP学习特征与注意力加权,可以在基础网络上进一步丰富点云特征信息,网络性能提升更明显。这表明仅具有(x,y,z)坐标信息的非结构点云数据,其特征信息单一仍是点云特征学习必须着重考虑的问题。
先融合后训练的注意力机制Mc"和Mn"的OA分别为87.24%和87.16%,实验结果虽然相比于原始网络仍有提升,但提升效果均不如先训练后融合的注意力机制Mc和Mn。平均池化和最大池化代表着不同角度的特征,实验结果表明“先融合,后训练”的策略导致多角度特征在融合过程中会产生一定的信息损失,因而对经过网络训练后的池化特征进行融合效果更优。对于两种注意力机制的融合方案Mcn和Mnc,OA分别为86.71%和87.36%,不同于图像注意力领域CBAM的经验,串行融合使用本文设计的注意力机制并未对网络特征提取性能做进一步提升。
最后,将Mc注意力机制应用于PointNet网络,OA相比于原始网络的88.90%提升至89.30%,同样提升了网络分类效果。同时,可以观察到相比于原始网络,注意力机制Mc分别仅使PointNet(vanllia)和PointNet的运行时间增加了27 min和15 min,并未明显提高网络计算成本,表明了本文设计注意力机制Mc的轻量级特点。下文中的实验如无特殊说明,均用注意力机制Mc。
本实验旨在研究所设计的注意力机制Mc在MLP网络中的使用位置方案,实验结果如表2所示,I、Ⅱ、Ⅲ、Ⅳ、V、Ⅵ分别表示在网络特征维度为3、64、64、64、128、1 024时,在之后嵌入使用注意力机制,—表示不使用注意力机制的原始网络框架。
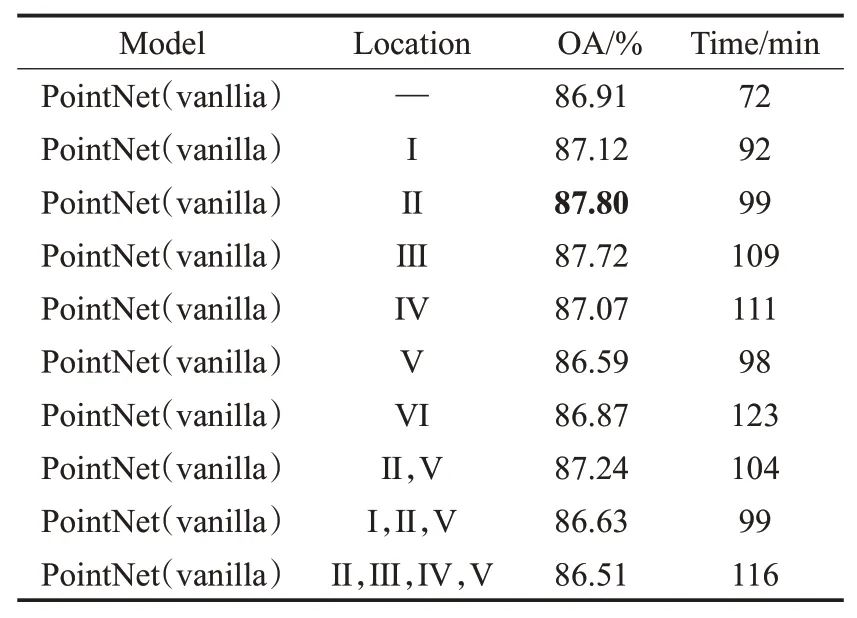
表2 注意力机制使用方案Table 2 Usage of attention mechanism
本文设计了两种注意力机制使用方案:仅使用单个注意力机制和使用多个注意力机制。当在原始点云后I直接使用注意力机制时,OA为87.12%,相比于原始网络有一定提升;当在第一层Ⅱ和第二层Ⅲ的MLP后使用注意力机制时,OA分别为87.80%和87.72%,相比于原始网络有了较大提升;当继续在更深层网络Ⅳ、V、Ⅵ后使用注意力机制时,OA均提升较少甚至有所下降。当在两层Ⅱ、V的MLP网络后使用注意力机制时,OA为87.24%,结果并未优于仅使用单个注意力机制的情况;更进一步,当在三层I、Ⅱ、V或者四层Ⅱ、Ⅲ、Ⅳ、V的MLP网络后使用注意力机制,OA甚至相较于不适用注意力机制的原始网络有所下降。
实验结果表明,和PointNet网络只使用了少量TNet网络且只在浅层使用T-Net网络的情况类似,本文设计的适用于点云的注意力机制更适合嵌入在网络的浅层而非深层,且使用单次注意力机制的效果优于使用多次注意力机制,具有轻量级的优点。
本文中的实验如无特殊说明,均仅使用单次注意力机制,并将注意力机制嵌入到第一层网络提取的特征之后。
3.3 零件分割有效性分析
为验证本文设计注意力机制的普适性,本节进行了对嵌入有点云注意力机制的PointNet零件分割网络在ShapeNet[25]零件分割数据集上的效果研究。ShapeNet零件分割数据集共有16种物体类别,每个类别有2至5个零件,总计50种零件类别、2 874个物体、16 881个零件。
在图4中给出了零件分割的可视化结果,左、中、右三列分别表示算法预测结果、真实标准、区别点。零件分割实验结果如表3所示,—表示不使用注意力机制的原始网络框架,网络的Batch Size设置为16,其余设置遵循原网络设置。可以看到,通过对PointNet零件分割网络嵌入本文设计的注意力机制Mc,网络的平均交并比(mean intersection over union,mIoU)由81.76%提升至83.14%,提升了1.38个百分点。此外,注意力机制Mc帮助16种物体类别中大多数类别交并比(intersection over union,IoU)的得分超过原始网络。对于car、ear phone、rocket类别的IoU提升超过5个百分点,对于cap、motor、skate board类别的IoU提升超过10个百分点。可以看出,本文设计的注意力机制在零件分割领域有优秀的实验结果,验证了设计注意力机制的普适性。

图4 零件分割可视化结果Fig.4 Visualization results for part segmentation

表3 基于注意力机制的零件分割结果Table 3 Results of part segmentation based on attention mechanism 单位:%
3.4 基于视锥体法的融合检测有效性分析
本文同样对PointNet延伸网络进行了注意力机制嵌入实验,以进一步验证设计注意力机制的普适性。Frustum-Pointnet[26]是PointNet网络在点云三维检测任务的延伸,是一种融合了图片与点云数据的多源融合目标检测网络,其网络可分为三个部分:使用图片检测结果生成视椎体点云候选区域,在候选区域使用PointNet分割网络滤除非目标噪点,对去噪后的点云使用PointNet预测网络生成三维目标边框。
数据使用KITTI[27]数据集,分别将点云注意机制Mc应用于Seg分割网络、Est预测网络、Seg&Est分割和预测网络。KITTI目标检测结果如图5所示,其中图5(a)为2D目标检测结果,图5(b)为与其对应的3D目标检测结果,该图仅包含预测边框与方向,不包含类别与真值。平均精度(average precision,AP)结果如表4所示,—表示不使用注意力机制的原始网络框架,Easy为目标全部可见,Mod.为目标被部分遮挡,Hard为目标被严重遮挡,网络的Batch Size设置为32,其余设置遵循原网络设置。

表4 基于注意力机制的多源融合检测结果Table 4 Results of multisource fusion detection based on attention mechanism
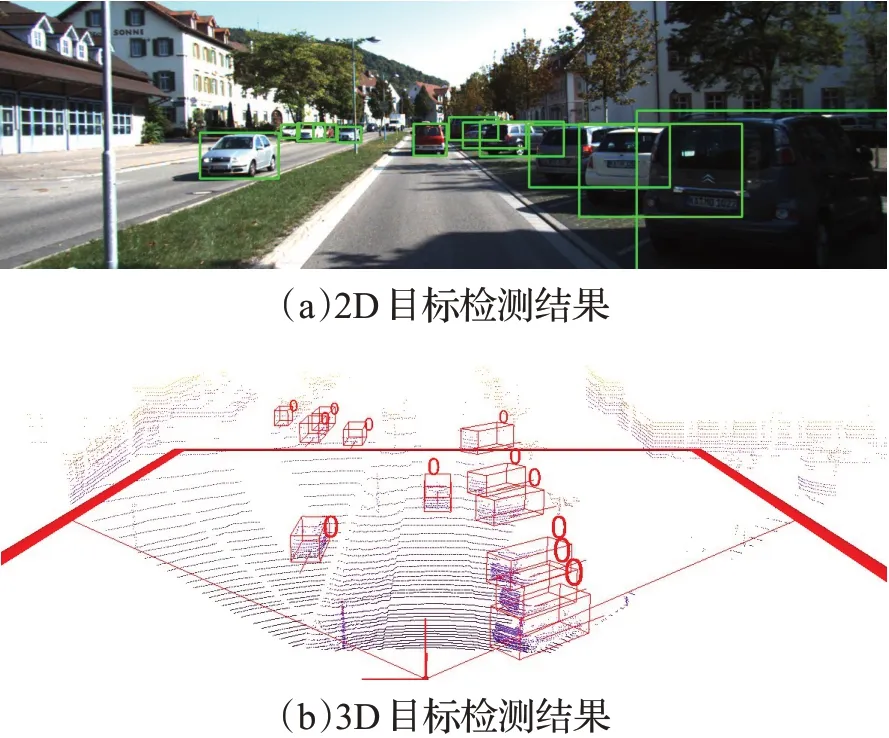
图5 KITTI目标检测结果Fig.5 Results for kitti target detection
可以看到,无论是将注意力机制单独使用在分割网络还是预测网络,AP值在大多情况下相比于原始网络有一定提升;在预测网络使用注意力机制时,汽车这一类别的AP值取得了最优的结果;在分割和预测网络均使用注意力机制时,汽车这一类大物体的AP值无明显改变,但是对于行人和骑行者这种小物体,AP值有了明显提升。实验结果进一步证明了设计注意力机制的普适性,同时网络运行时间仅增加了51 min,增加幅度不足5%,说明了所设计注意力机制的轻量级特性。
4 结束语
针对现有的点云特征提取网络性能有待提高,传统的注意力机制无法直接应用于点云数据的现状,本文提出了适用于点云的注意力机制,通过注意力机制对网络训练特征生成自适应权重。以PointNet类网络作为基础网络,对所设计的注意力机制学习过程进行了详尽说明,并进行了广泛的测试与实验。实验结果表明,所设计的注意力机制具有普适性和轻量级的特点,能够提升多种三维点云处理任务的性能。但是,本文对于如何在网络的多个层次中发挥注意力机制的优势以及如何根据传统注意力机制进一步优化点云注意力机制仍有不足,这是进一步研究的方向。
猜你喜欢
计算机应用(2022年9期)2022-09-25
心理学报(2022年5期)2022-05-16
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
当代陕西(2020年17期)2020-10-28
甘肃教育(2020年22期)2020-04-13
计算机技术与发展(2019年1期)2019-01-21
人大建设(2018年5期)2018-08-16
智能计算机与应用(2018年2期)2018-05-23
证券市场红周刊(2018年3期)2018-05-14
