
结合BERT与多尺度CNN的民事纠纷问句意图分类
2022-12-06 10:34邢义男张娜娜
计算机工程与应用 2022年23期
邢义男,张娜娜
1.上海海洋大学 信息学院,上海 201306
2.上海建桥学院 信息技术学院,上海 201306
随着互联网和社会经济的迅速发展,人们面临的法律问题越来越多样化、复杂化,因此法律顾问业务的开展对社会的发展而言,有着至关重要的作用。然而,现阶段法律顾问业务开展过程中还是存在各种各样的问题,比如:聘请率低下,发展速度过慢,常年法律顾问业务创收较低,常年法律顾问律师业务水平不足等诸多问题[1]。因此,借助大数据和深度学习的方法,建立高效、方便的自动问答系统能够有效解决上述问题。问句意图分类作为问答系统的初始环节,其能否正确地对问句意图进行分类会直接影响到后续的答案抽取环节[2]。民事纠纷问句意图分类就是借助自然语言的相关技术理解问句的意图,为民事纠纷问句确定一个意图类别,从而快速确定问题答案的类别,缩小答案的搜索范围,提升问答系统的准确率。目前,民事纠纷问句中存在着长短不一、特征分散、种类繁多的问题,使得机器难以理解问题的意图类别。针对上述问句的特点,本文选择使用预训练模型BERT(bidirectional encoder representations from transformers)[3],来缓解问句长度短时造成的语义稀疏的问题;对于问题信息的提取设计了多尺度卷积模块Text Inception来获得问题不同层次的信息,相较于循环神经网络比如:长短期记忆网络(long short-term model,LSTM)和门控循环单元(gated recurrent unit,GRU),Text Inception速度更快,而且效果更好;此外普通的卷积神经网络(convolutional neural network,CNN)会因为网络变深而出现性能饱和的问题。接着,采用最大池化来获取句子中的关键语义特征从而排除一些歧义特征,最后通过Softmax对问句进行分类。通过设计民事纠纷问句意图分类模型,本文的贡献有:(1)自建了一个民事纠纷问句数据集,为后续的相关研究提供了参考;(2)针对该数据集,本文基于BERT模型,引入多尺度CNN,设计了一个准确率高,实时性好的民事纠纷问句意图分类模型,并与其他模型进行了对比分析,侧面印证了本文模型的有效性;(3)本文设计了一种新型的多尺度卷积模块Text Inception,通过实验证明该模块特征提取能力更强,分类效果更好。
1 相关工作
问句意图分类是属于文本分类的问题范畴,一直都是自然语言中的经典任务。国内外对于文本分类的研究主要包括两大类方法:机器学习方法和深度学习方法。
基于传统的机器学习方法,主要是先提取文本的特征向量,然后使用带标签的文本数据建立分类器,最后利用分类器标注类别。文献[4]结合词汇特征并使用支持向量机(support vector machine,SVM)在分类预测、估计法律判决日期上取得了不错的结果。文献[5]基于TF-IDF(term frequency-inverse document frequency)和TF-IGM(term frequency-inverse gravity moment)词权重加权的方法,结合改进的朴素贝叶斯(native Bayesian,NB)应用到泰国民事裁决书分类上。文献[6]从问题中提取语法和语义信息结合最大熵模型(maximum entropy,ME)较好地提升了问句分类的准确率。文献[7]利用K近邻算法(K-nearest neighbor,KNN)丰富了原始数据的特征空间,应用于多标签分类。上述方法,没有应用到深度学习方法,具有较大的局限性。
基于深度学习的方法,是基于神经网络实现的一种机器学习方法。神经网络模型由一系列基本的神经元相互连接而成,是通过对人类大脑的神经结构模拟构建的一种人工系统[8]。近几年,神经网络在自然语言领域取得了极大的进展。文献[9]将问题用预训练好的词向量Word2vec[10]进行编码,在简单的CNN上取得了很好的效果。文献[11]融合双向长短期记忆网络(bidirectional long short-term memory,Bi-LSTM)和CNN结构并加入注意力机制,进行提取问句特征进行分类。文献[12]利用深度长短期记忆网络的特征映射来捕获高阶非线性特征表示,对问句进行分类。文献[13]利用自注意力机制学习句子中重要局部特征,并结合LSTM,应用在句子的情感分类上。文献[14]提出一种融合CNN、Bi-LSTM、Attention的混合模型,该模型同时考虑不同层次的局部和全局结构信息,在多个文本分类数据集上取得了不错的效果。
上述文献为民事纠纷问句意图的分类提供了一定的参考和研究思路,但是存在以下问题:(1)对于问句或者文本的建模大多使用Word2vec、Glove[15]等传统的词向量,然而这些词向量忽视了同一词语不同语境下的多义性,对文本的表征依然存在局限性;(2)虽然上述神经网络模型通用性强,但是面对特定领域的民事纠纷问句时却不能准确地获得文本中的特征,主要原因有民事纠纷问句长短不一,口语化严重,难以捕捉到关键有效的信息;(3)目前CNN、LSTM等神经网络模型获取文本的特征有限,相对于利用大量无监督数据学习的BERT等预训练模型仍有差距。
2 模型构建
本文提出了结合BERT与多尺度CNN的民事纠纷问句意图分类模型(intent classification of questions in civil disputes combining BERT and multi-scale CNN model,BCNN),应用于中文民事纠纷问句意图分类。该模型主要包括BERT语义编码层、多尺度卷积层和分类层。
民事纠纷问句意图的分类,就是对给定的问句进行语义理解,从而判定其所属意图。例如对于问句“我朋友要离婚了,怎么认定夫妻共同债务?”,首先对其进行预处理操作,去除其中的特殊符号等操作。然后,将该问句输入到BERT语义编码层进行语义编码、语义补充,来缓解问句短、语义稀疏的问题;接着利用多尺度卷积层中多种尺度的卷积核得到不同尺度的语义特征,比如:“离婚”“夫妻”“共同债务”等多尺度特征;最后,在分类层对上一层的特征进行最大池化来获取最优特征,使用BatchNorm和ReLU来减少模型的训练难度,通过Softmax进行分类得到该问句的具体意图。
模型整体架构图如图1所示:其中X1,X2,…,Xn-1,Xn表示问句输入向量;接着为BERT语义编码层,由Transformer编码器(Trm)组成,T1,T2,…,Tn表示问句输入向量经过BERT的输出向量;多尺度卷积层是由1×768和3×768、5×768三种尺度的卷积核(Conv)组成,并在中间两卷积通道上使用了两层卷积以及批量归一化处理BatchNorm和ReLU激活函数;分类层由最大池化(Maxpool)、BatchNorm和ReLU激活函数、Softmax组成。
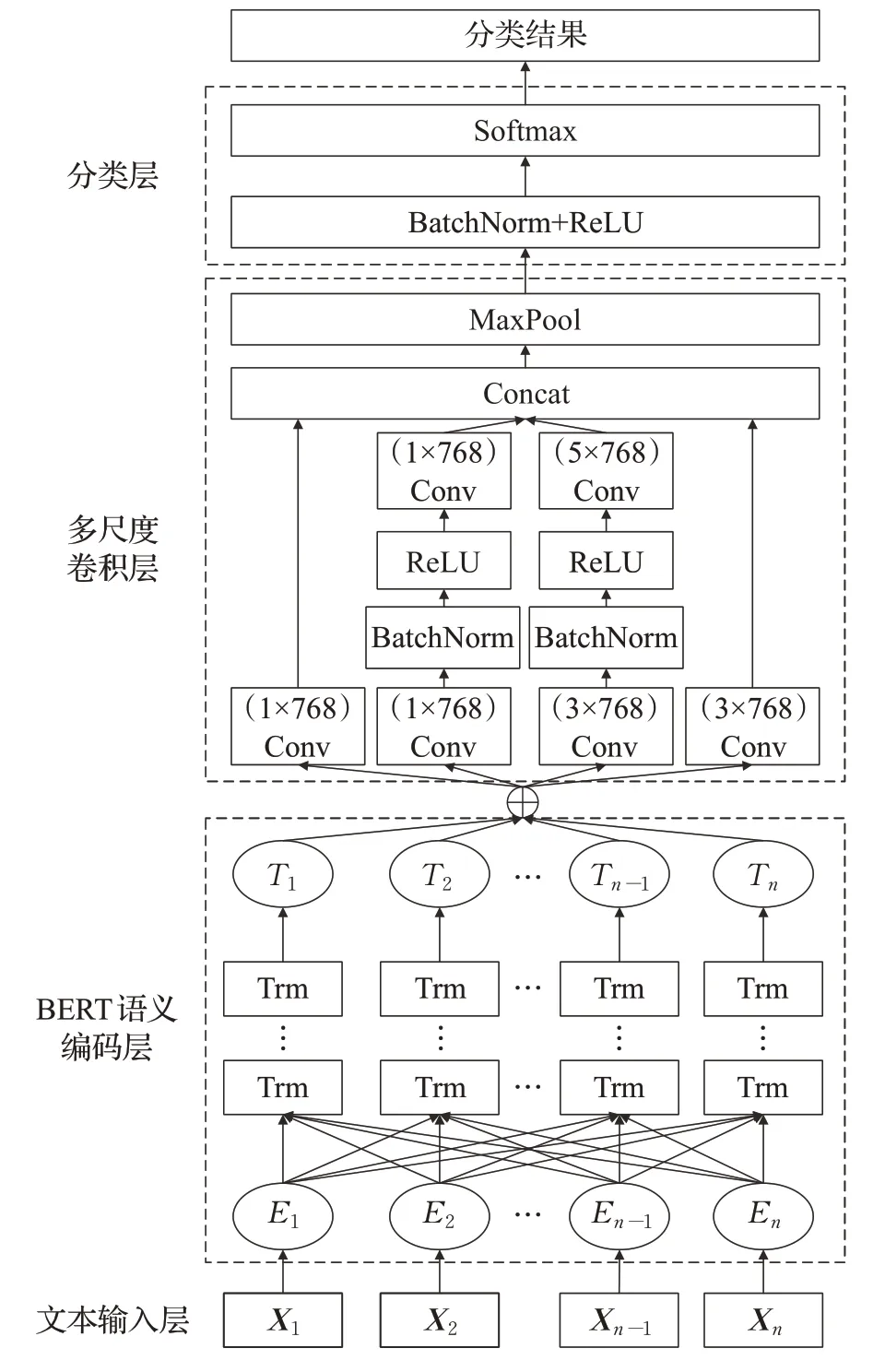
图1 BCNN模型框架Fig.1 BCNN model framework
2.1 BERT语义编码层
BCNN的语义编码层采用BERT对输入长度为n的问句进行编码,可得到n×768的向量。BERT模型采用了两个预训练任务:双向语言模型和预测下一段文本,这两个任务均属于无监督学习。因此,相比于传统的词向量Word2Vec、Glove等,BERT充分考虑了文本的上下文关系,具有良好的语义多样性。其结构如图2所示,其中E1,E2,…,En表示模型的输入向量,T1,T2,…,Tn表示模型的输出向量。
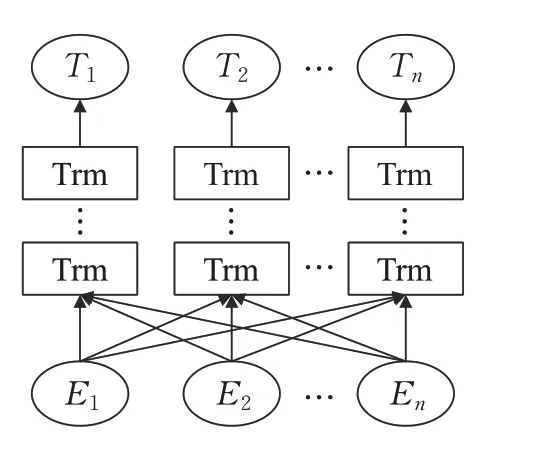
图2 BERT模型Fig.2 BERT model
BERT是一个双向语言模型,它首先采用了双向Transformer编码器,可以同时接收两个方向的文本的输入,而不是简单的双向编码拼接。其次,BERT使用了掩码(Masking)机制:随机掩盖其中15%的词,其中被打上[MASK]标记的词有80%的概率直接替换为[MASK]标签,10%的概率替换为任意单词,10%的概率保留原始Token,让模型预测被掩盖的单词含义。此外,BERT从训练文本中挑选语句对,其中包括连续的语句对和非连续的语句对,让模型来判断两个语句对是否具有上下文的语义关系。
BERT的输入一般是给定两段文本A、B,主要作用是判断两段文本之间是否具有上下文关系。该输入由Token Embeddings、Segment Embeddings和Position Embeddings三部分叠加起来表示,其结构如图3所示。其中,Token Embeddings表示单词嵌入,起始单词嵌入为E[CLS],分隔符为E[SEP],结尾单词嵌入为E[SEP],且两段文本总的最大长度为512;Segment Embeddings表示分段嵌入,用来区分A、B两段文本,即给两段文本中的单词分配不同的编码;Position Embeddings表示位置嵌入,是人为设定的序列位置向量。
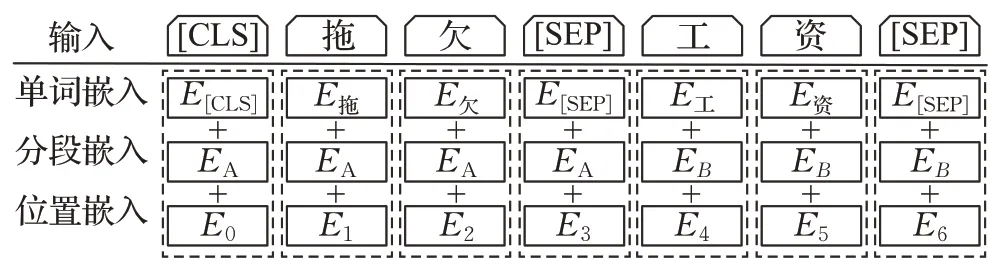
图3 BERT的输入表示Fig.3 Input representation of BERT
BERT采用了双向Transformer编码器[16]作为特征提取器,其结构如图4所示。Transformer Encoder完全是以多头注意力机制作为基础结构,并且具有并行计算的优点,见公式(1)~(3):
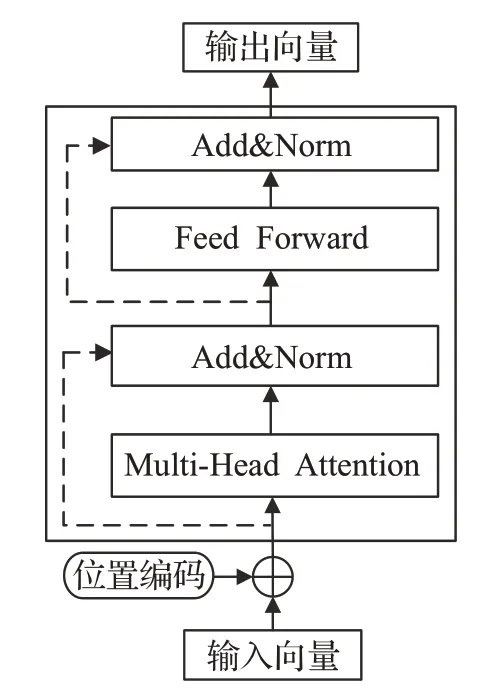
图4 Transformer编码器Fig.4 Transformer encoder
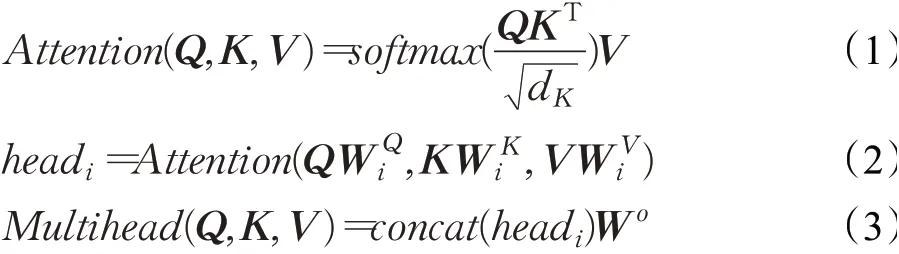
其中,Q表示Query向量,K表示Key向量,V表示Value向量,它们分别为输入向量的映射矩阵,d表示输入向量的维度,除以可以使得梯度训练更加稳定;分别表示Q、K、V的线性变换矩阵;i表示注意力头的数量;Wo表示多头注意力的映射矩阵。
Transformer Encoder采用位置编码原理对输入的序列进行表示,其原理见公式(4)、(5):
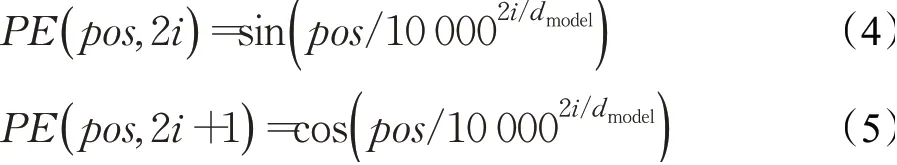
其中,pos表示文本序列中词语的位置;i表示位置向量中值的索引;dmodel表示位置向量的维度。
Transformer Encoder利用残差连接(图4虚线)和层归一化(Norm[17])来加速模型的收敛,计算见公式(6):

其中,LayerNorm表示层归一化函数,X表示输入序列,M表示X经过多头注意力处理后特征。
2.2 多尺度卷积层
卷积神经网络(CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元[18]。CNN具有权值共享、局部连接、下采样三个重要特点,在计算机视觉和自然语言领域有着重要的应用[19]。
CNN的结构通常是由卷积层、池化层和全连接层组成。卷积层是由多种卷积核组成,它的主要功能是对图片或者文本输入的特征图进行局部特征提取。池化层是由相应的池化函数构成,常见的池化有平均池化和最大池化,它的主要功能是将卷积之后特征图中的局部特征替换为相邻区域的特征,既可以提取主要特征,也可以减少特征图的大小来降低网络的复杂度。全连接层的功能是对提取的特征进行非线性组合。
CNN为了提取高维度特征,主要是进行更深层卷积,但是随之带来网络变深、性能饱和的问题。因此,谷歌提出的Inception V1[20]卷积模块使网络变宽,减少参数个数,提取高维特征。本文针对民事纠纷问句的特征,参考Inception V1卷积模块的思想,设计了如图5的TextInception卷积模块。该结构通过不同尺度的卷积核学习问句中不同尺度的信息,将这些多尺度特征进行拼接来获得关键的问句语义特征。
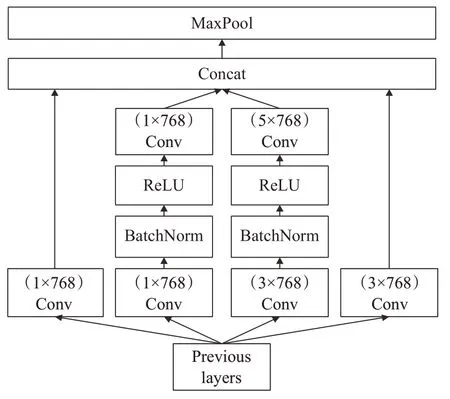
图5 Text InceptionFig.5 Text Inception
Text Inception有4个卷积通道,3种卷积核,分别为1×768、3×768、5×768。使用这些卷积核的主要目的如下:(1)方便特征对齐,从而得到相同大小的特征图,可以顺利进行Concat。(2)卷积核不同,意味着感受野的大小不同,可以得到不同尺度的特征。(3)采用比较大的卷积核即5×768,因为有些问句过长时相关性可能隔得比较远,采用大的卷积核能够学到较远的相关特征。其中,第一个卷积通道和最后一个卷积通道只有一层卷积,目的是减少深层卷积之后信息的流失;第二和第三个卷积通道是两层卷积,目的是得到深层的多尺度高维特征;在第二和第三个通道之间使用了BatchNorm[21]和ReLU[22]的作用是加速神经网络的训练速度。
Text Inception模块中所有卷积核的步长均为1;第一通道的卷积核的尺寸为1×768,数量为256,padding为0;第二通道中第一层卷积核的尺寸为1×768,数量为256,padding为0,第二层卷积核的尺寸为3×768,数量为256,padding为1;第三通道中第一层卷积核的尺寸为3×768,数量为256,padding为1,第二层卷积核的尺寸为5×768,数量为256,padding为2;第四通道的卷积核的尺寸为3×768,数量为256,padding为1。将4个通道的特征拼接在一起可得到一个256×4=1 024维的问句向量。
2.3 分类层
本文在分类层使用Softmax作为特征分类器,来实现问句的意图分类。通过Softmax计算上一层的隐层特征,将该特征转换为不同意图类别的概率,见公式(7):
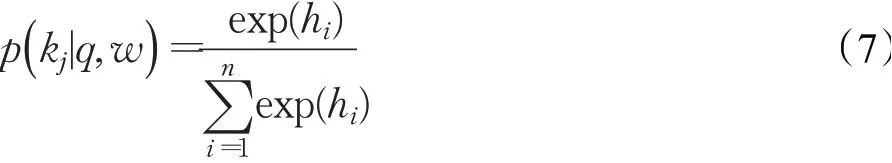
其中,j表示问句分类的标签,本实验使用了10种类别的问句;q表示问句,w表示模型的训练参数;h表示模型的隐藏层特征;n表示隐藏层特征的数量。
模型通过反向传播进行迭代训练,利用自适应时刻估计梯度优化算法(adaptive moment estimation,Adam)[23]进行学习率的调整。Adam与其他自适应学习率算法相比,收敛速度更快,学习效果更为有效。模型采用交叉熵损失函数进行模型的优化。其中损失函数见公式(8):

其中,D表示训练集大小,N表示问句分类的标签数量,ŷ表示真实问句意图标签,y表示模型预测的问句意图标签。
3 实验与结果分析
3.1 实验数据集
本文采用Scrapy爬虫框架在法律咨询网站(http://www.110.com/ask/)上爬取了常见的民事纠纷问句,并对该数据集进行清洗、筛选、标注等预处理操作,共得到47 781条数据集,每种类别的问句数量、问句意图类别、类别样例,见表1。

表1 实验数据集分布Table 1 Experimental data set distribution
3.2 实验参数与超参数
BERT的预训练模型常用的有两种版本分别为BERT-Base和BERT-Large。本实验使用BERT-Base的中文预训练模型进行实验,此模型有12层,隐藏层的维度为768,12个注意力头,包含110×106个参数。训练过程的超参数如表2所示。
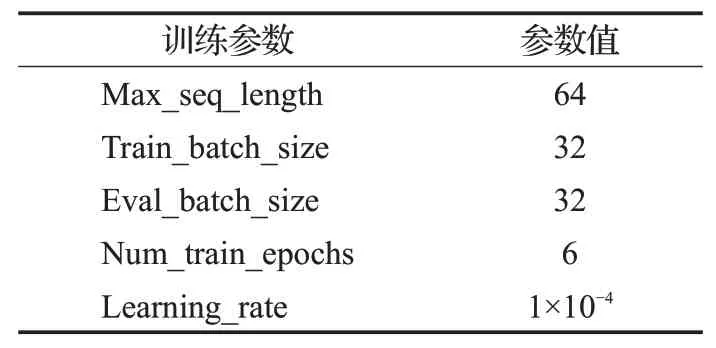
表2 BERT中的超参数Table 2 Hyper parameters in BERT
表2中,Max_seq_length表示输入到BERT的最大问句长度;Train_batch_size表示训练集训练迭代数据的数量;Eval_batch_size表示验证集训练迭代数据的数量;Num_train_epochs表示模型训练迭代的次数,Learning_rate表示模型的学习率。
3.3 实验环境
所有实验均采用同一个实验环境,实验环境参数如表3所示。

表3 实验环境Table 3 Experimental environment
3.4 评价标准
本实验的评价标准采用的是精确率P(precision)和召回率R(recall)以及F1值,其计算如公式(9)~(11)所示。其中,精确率P表示所有预测正确的样本占数据中真正例与错误预测正例的样本中比例;召回率R表示所有预测正例的样本占所有真实正确样例的比例;为了综合评价模型的指标往往采用两者的调和平均值F1值。
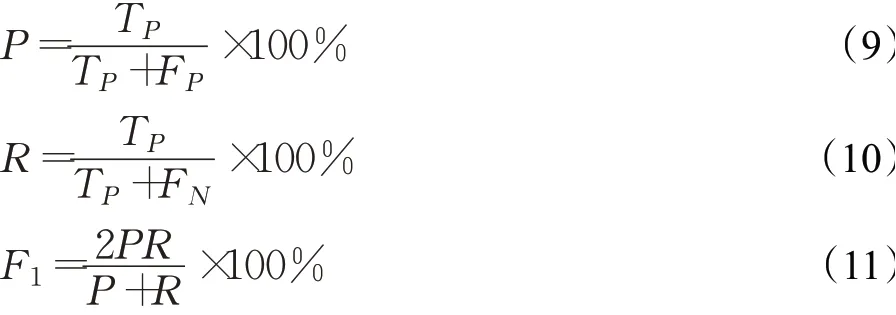
其中,TP、FP、TN、FN的含义如表4中混淆矩阵所示。

表4 混淆矩阵Table 4 Confusion matrix
3.5 对比实验
实验选取90%的数据作为训练集,10%的数据作为测试集。为了验证本文提出的BCNN问句意图分类模型的有效性。本文在同一实验环境下,选择了以下模型进行对比实验:
(1)SVM:经典的机器学习方法,本文采用高斯核来作为核函数进行实验;
(2)KNN:传统的机器学习方法,采用聚类的方法找出特征空间中最相邻的样本;
(3)NB:利用贝叶斯公式根据某一问句的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该问句所属的类;
(4)Text_CNN:经典的文本卷积分类算法,模型采用Word2Vec作为词向量表示问句,采用尺寸为(2,3,4)的卷积核进行局部特征提取,然后进行最大池化,最后全连接后进行分类;
(5)Text_RCNN[24]:该网络将Text_CNN网络中的卷积层换成了双向循环神经网络(bidirectional recurrent neural network,Bi-RNN),即模型采用Word2Vec作为词向量表示问句,用Bi-RNN双向提取问句的特征,再使用最大池化筛选出最优特征进行分类;
(6)Text_RNN[25]:模型首先利用Word2Vec作为词向量表示问句,接着采用Bi-RNN捕捉民事纠纷问句中的语义依赖关系,确保信息的完整性,以此来提高模型的效果;
(7)BERT:经典的预训练模型采用大规模无监督语料进行训练,在多个自然语言任务上都取得了较好的效果;
(8)BERT+Bi-RNN:模型利用BERT获得丰富问句的语义特征,在BERT后面加上Bi-RNN进行双向提取问句信息;
(9)BERT+CNN:模型采用BERT对问句进行语义编码,然后使用尺寸为(2,3,4)的卷积核进行局部特征提取,将提取到的向量进行Softmax分类。
3.6 消融实验
为了评估BCNN模型中不同参数的影响程度,本文进行了消融实验。通过控制变量的思想分别改变学习率,Text Inception卷积模块的层数,Text Inception卷积模块的通道数,Text Inception卷积模块中不同卷积核的大小,Transformer Encoder的注意力头数量来找出模型的最优参数。
(1)学习率对BCNN的影响
学习率是控制模型的收敛速度的主要参数,对模型的实验结果有着很大的影响。因此,在民事纠纷问句分类任务中,学习率按乘以1/10的衰减系数来分别选取0.000 1,0.000 01,0.000 001进行实验,选择0.000 2作为学习率上升时的一个参照,实验结果见表5。
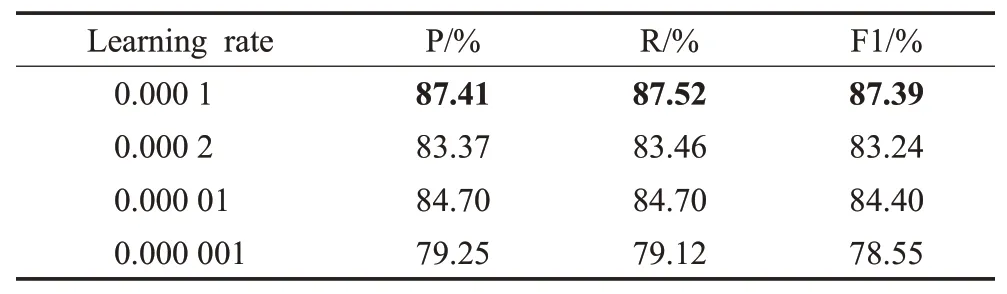
表5 不同学习率实验对比Table 5 Experimental comparison of different learning rates
由表5可知,Learning rate的取值为0.000 1时,模型的效果最好。当Learning rate上升到0.000 2的时候,模型在P、R、F1值三个指标上分别下降4.04、4.06和4.15个百分点,这是因为模型的学习率增加使得训练时无法收敛,导致模型无法找到最优解。当Learning rate下降到0.000 001的时候,模型在P、R、F1值三个指标上分别下降8.16、8.4和8.84个百分点,出现了较大幅度的下降,主要原因在于模型的学习率下降时,不仅会导致模型的训练时间增长同时会使模型陷入局部最优点。
(2)Text Inception模块数量对BCNN的影响
深度学习模型在一定层数下会随着模型的深度的加深而增强,但超过特定层数时,会因为特征的流失而出现模型效果下降的现象。因此,本文针对多尺度卷积层,通过设置Text Inception模块数量为1、2、3、4进行实验,实验结果见表6。
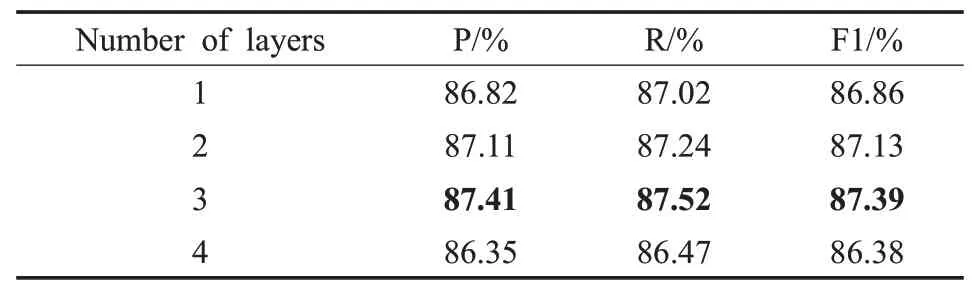
表6 不同模块数量实验对比Table 6 Experimental comparison of different module numbers
由表6可知,Text Inception卷积模块的数量为3时,模型的效果最好。当模块的数量减少到1时,模型在P、R、F1值三个指标上分别下降0.59、0.5和0.53个百分点,这是因为模型层数较小时尚未拟合,没有学习到最优的特征。当模块的数量增加到4个时,模型在P、R、F1值三个指标上分别下降1.06、1.05和1.01个百分点,这是因为模型层数较深时,特征出现流失,而使得模型的效果下降。
(3)Text Inception卷积通道数对BCNN的影响
Text Inception模块卷积通道的数量越多,不同通道卷积之后得到的多尺度特征也就会越多,因此,本文选取了2,3,4,5个卷积通道来进行对比实验,实验结果见表7。
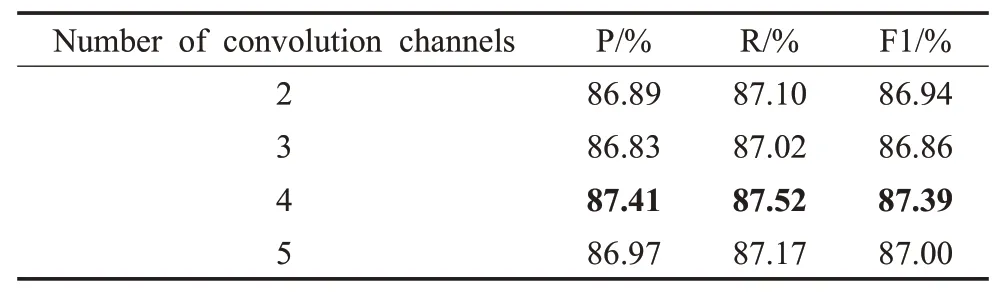
表7 模块不同通道数量实验对比Table 7 Experimental comparison of different channel number of modules
由表7可知,Text Inception模块的卷积通道数为4个时,模型的效果最好。当通道数为2的时候,模型在P、R、F1值三个指标上分别下降了0.52、0.42和0.45个百分点,这是因为卷积通道的数量少的时候,通过多尺度卷积层之后,只能得到2种尺度的特征,从而使得模型的效果出现下降。当通道数为5的时候,模型在P、R、F1值三个指标上分别下降0.44、0.35和0.39个百分点,这是因为多尺度特征的增加会引入其他的干扰特征使得模型的性能下降。
(4)不同卷积核大小对BCNN的影响
Text Inception模块中卷积核大小的不同会造成感受野的不同,从而影响模型对问句不同尺度特征的提取。因此,本文在Text Inception模块中第一个通道选取了大小为1的卷积核,第2、3、4通道分别选取(2,3,4)、(1,3,5)、(3,4,5)3种大小的卷积核进行实验,实验结果见表8。
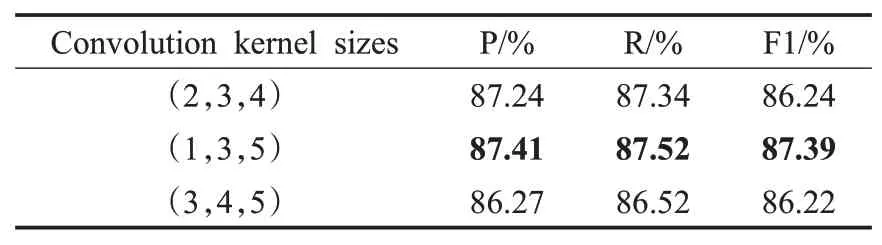
表8 不同卷积核大小实验对比Table 8 Experimental comparison of different convolution kernel sizes
由表8可知,卷积核取(1,3,5)时,模型性能最好。当卷积核的大小为(2,3,4)、(3,4,5)时,模型的效果出现了不同程度的下降,原因在于尽管卷积核已经提取到了大部分特征,但是却忽略了较小和较大的特征,从而导致模型性能的下降。
(5)不同注意力头数对BCNN的影响
Transformer Encoder中采用了Multi-Head Attention机制可以从不同角度学习问句中的语义信息,注意力头数的不同会很大程度影响模型的学习效果。因此,本文针对Transformer Encoder的多头注意力数量,分别选取了6、8、12、16个注意头数来进行对比,实验结果见表9。
由表9可知,注意力头数为12时模型的效果最好。当注意力头的数量为6时,模型的效果最差,主要原因在于注意力头数较少时,模型忽略了问句中不同部分的语义信息。当注意力头的数量增加到16的时候,模型在P、R、F1值三个指标上分别下降1.08、0.92和1.02个百分点,这是因为模型注意力头数过多会使头与头捕捉的信息产生冗余从而干扰模型的性能。
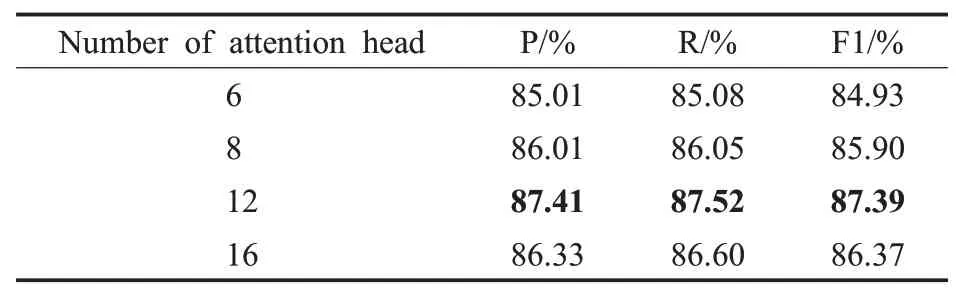
表9 不同注意力头数实验对比Table 9 Experimental comparison of different number of attention head
3.7 实验结果与分析
在民事纠纷数据集上选择了SVM、KNN、NB、Text_CNN、Text_RCNN、Text_RNN、BERT、BERT+Bi-RNN、BERT+CNN多种机器学习与深度学习模型进行对比实验,实验结果见表10。其中选取经典的机器学习方法SVM以及深度学习方法Text_CNN与BERT作为基线模型。F1值更能反映出模型的效果,因此,表11为不同模型在不同问句意图类别的F1值。
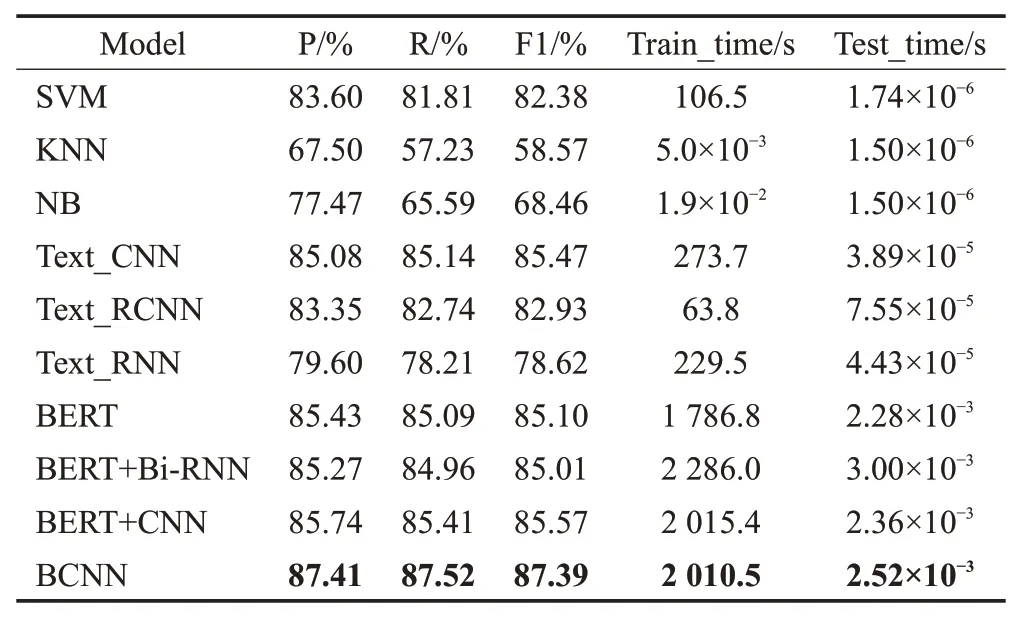
表10 不同模型实验结果Table 10 Experimental results of different models
由表10、表11可以看出,本文提出的结合BERT与多尺度CNN的民事纠纷问句意图分类模型BCNN在民事纠纷数据集上取得了较好的效果。此外,与传统的机器学习方法相比,深度学习方法整体上在问句类别上表现优异。但是机器学习方法在训练时间和测试时间上要优于深度学习方法。
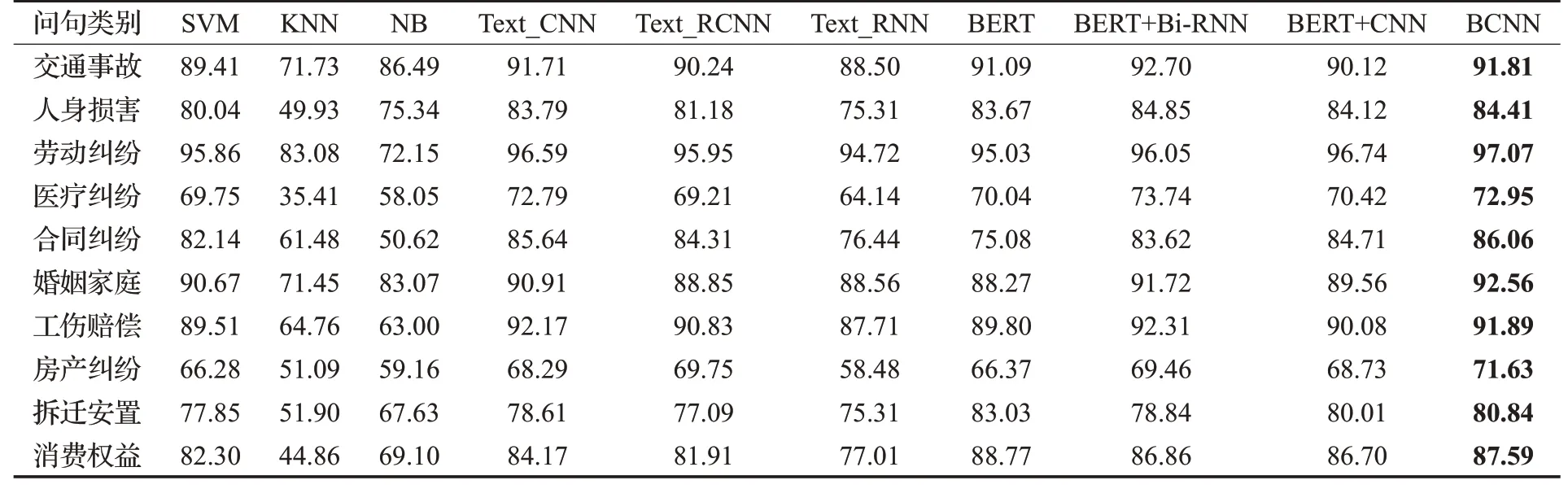
表11 不同方法在各个意图类别中的F1值比较Table 11 Comparison of F1 values in different intention classification in different methods 单位:%
在机器学习中SVM的效果要明显优于KNN与NB,在P、R、F1值三个指标上分别达到了83.60%、81.81%、82.38%的效果。这表明SVM采用最大化分类边界的思想更加适用于小样本数据集。其中SVM的训练时间要长于KNN、NB,主要原因在于问句种类较多,SVM的核函数很难找到收敛的超平面,而SVM的分类效果是三者中最好的,测试时间也不错。
深度学习方法中,Text_CNN和Text_RNN相比,Text_CNN要明显好于Text_RNN,在P、R、F1值三个指标上分别高出5.48、6.93和6.85个百分点,这表明CNN的局部抽取特性更有助于模型学习到较好的类别特征,从而提升模型的性能。而Text_CNN的训练时间相对于Text_RNN较长主要原因在于Text_CNN采用3种卷积核进行卷积相对于Text_RNN参数量更大,因此训练时间较长。Text_RCNN与Text_RNN模型相比,Text_RCNN的性能明显要好于Text_RNN,原因在于Text_RCNN使用Bi-RNN提取信息之后采用了最大池化来进行选取较好的类别特征。因此,选用能够提取局部重要特征的CNN或者最大池化能够有效提升模型的性能。Text_RCNN相比于Text_RNN、Text_CNN的训练时间最短,主要原因在于Text_RCNN的结构为单层RNN和一层最大池化,结构最简单,因此训练时间最短。此外,BERT在精确率上比Text_CNN、Text_RNN、Text_RCNN分别高出0.35、2.08、5.83个百分点。这表明了BERT对于表征问句的语义有着较好的效果,但是BERT的结构复杂层数较多参数量大训练时间较长。对比BERT+CNN与Text_CNN、BERT+Bi-RNN,BERT+CNN在P、R、F1值三个指标上都要优于两者,原因在于民事纠纷问句长度不会过长,无用的信息相对较少,采用BERT进行语义编码可以对问句进行语义补充,CNN的局部信息提取特性更加适用于短句。尽管BERT、BERT+CNN、BERT+Bi-RNN,BCNN的训练时间较长,但是它们的效果较好,测试时间是毫秒级的,实时性也不错。由表11可知在房产纠纷和拆迁安置等类上BERT+CNN的提升效果并不明显,而BCNN明显要优于BERT+CNN的效果,主要原因在于BCNN采用了Text Inception进行多尺度卷积,卷积层数更深,Text Inception采用了4个通道和3种类型的卷积核进行卷积,相比于单层CNN能够获得更多尺度的特征。
通过对比各个模型在同一数据集上的实验效果可以看出本文提出的BCNN模型效果最好。针对民事纠纷问句长短不一、特征分散、种类繁多的特点,采用BCNN能够有效地提取问句特征信息,主要原因在于BERT能够丰富问句语义信息弥补问句特征分散的不足,Text Inception多尺度、多通道的卷积特性能够有效提取不同尺度问句的特征,从而提升了模型的整体性能。
BCNN结合了BERT、多尺度CNN的优点在P、R、F1值三个指标上分别取得了87.41%、87.52%、87.39%的效果,都要优于目前主流的机器学习和深度学习模型,在测试时间上也表现优秀,能够为后续的问答系统提供有效的支持。
4 结束语
本文通过分析民事纠纷问句中存在的长短不一、特征分散、种类繁多的特点,提出了一种用于问句意图分类的模型BCNN。该模型,首先用BERT进行语义补充和语义编码,缓解了民事纠纷问句特征分散的问题;接着采用Text Inception卷积模块进行多尺度卷积,通过组合不同尺度的问句特征得到更加丰富的语义特征信息,进而提升民事纠纷问句分类的效果。实验结果表明,该模型与传统的机器学习方法、经典的深度学习方法相比效果提升显著,为民事纠纷问句分类提供了参考。在下一步的研究工作中,考虑引入知识图谱来扩充问句的语义,提升民事纠纷问句分类的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
