
道路环境下动态特征视觉里程计研究
2022-12-06 10:33杨斌超续欣莹
计算机工程与应用 2022年23期
杨斌超,续欣莹,2,程 兰,冯 洲
1.太原理工大学 电气与动力工程学院,太原 030024
2.先进控制与装备智能化山西省重点实验室,太原 030024
随着自动驾驶技术的研究取得卓越进展,未来自动驾驶将可以在更加复杂的环境中应用,这对视觉里程计的精度和鲁棒性提出了更高的要求。视觉里程计是通过分析相关的摄像机图像来确定车辆的位置和方向的过程,被广泛应用于无人驾驶、机器人、虚拟现实、增强现实等[1],是一种性价比及可靠性较高的新兴导航技术[2]。
传统的视觉里程计[1,3]依赖人工设计的特征、不准确的建模、环境动力约束复杂等不足导致其在动态目标、光度变化等的环境条件下依然存在较多挑战。
与利用物理模型或几何理论创建人工设计的算法不同,基于深度学习的视觉里程计在预测位姿和深度等信息取得了积极进展[4-5]。相对基于雷达、双目相机的视觉里程计,现有的基于单目相机的视觉里程计鲁棒性较差,但在低成本和普适性上有着无法替代的优势。
近年来,使用深度学习解决帧间位姿估计和回环检测问题取得不错的进展[6-7]。与经典的帧间估计提取特征点进行匹配后计算位姿运动不同,基于深度学习的帧间估计提取的特征点更加稠密[8],并且无需利用图像的几何结构、进行特征搜索和匹配等复杂的操作。Li等人[9]在立体图像上基于空间与时间一致性,利用视图合成建立自监督信号,估计位姿和深度信息。由于自监督的训练方式相对有监督的训练方式不需要任何的人工标记、更具泛化能力[10],本文采用自监督的方式设计模型。
自监督建立在光度一致性假设上,即只有当场景几何和相机姿态的中间预测与物理地面相一致时,几何视图合成系统才能始终如一地运行良好[11]。在实际道路环境中,动态物体会对光度一致性假设造成破坏,从而导致深度和位姿的不准确估计。为了解决这个问题,GeoNet[12]通过强化几何一致性损失,构建刚性结构重构器和非刚性运动定位器来估计静态场景结构和运动动力学。Ricco等人[13]使用遮罩去除不稳定像素点。但上述方法并不能很好地解决移动物体所带来的光度投影扭曲。
语义信息可以帮助自监督的光度误差损失去除不确定的像素点,而不是简单的遮罩。目前,视觉里程计与语义信息的融合通常是将语义信息作为单独的任务或在建图中引入语义映射,而未利用语义信息辅助构建深度、位姿等几何信息。
针对这类移动物体对光度一致性假设的破坏,本文提出一种基于道路环境动态语义特征的单目视觉里程计,简称为DS-VO(visual odometry with dynamic semantic),主要内容如下:
(1)在语义分割网络的基础上,对道路环境下车辆的前景图像处理得到动态语义概率先验图;设计语义概率解析网络,将得到的动态语义概率先验图作为先验信息,以空间仿射变换的形式影响深度估计网络的中间特征层,使网络学习到当前环境下的动态信息,提高深度估计与位姿估计的鲁棒性。在测试中,只需一次前向传播就可以得到动态语义特征图、深度图和位姿向量。
(2)设计两个独立的全连接层,分别估计位姿向量中的旋转向量和平移向量。降低大旋转带来的连续帧间交叠区域少而导致旋转向量的预测误差,同时避免相同的全连接层网络对旋转向量和平移向量拟合能力的差异问题。在损失函数上,采用结构相似度指标(SSIM)和鲁棒性较强的L1光度绝对误差作为光度误差的损失函数,与二阶梯度平滑损失一起构成网络的损失函数。
1 网络设计
本文的DS-VO由位姿估计网络和深度估计网络构成,并在网络中加入语义概率解析网络,网络结构如图1所示。输入网络的图像为相邻的多张连续彩色图像序列,图像分辨率为416×128,每3张连续帧为一个集合。每个集合以通道数为轴叠加为9通道的张量输入位姿估计网络中,集合的中间帧输入深度估计网络中,分别产生相邻帧的6维位姿向量和深度。
1.1 深度估计网络
编码解码器网络结构作为神经网络的一种类型,其结构可以保留图像像素的空间信息。考虑到深度图具有一定分辨率、边缘信息复杂的特点,本文的深度估计网络基于编码解码结构,以恢复原图像的完整深度信息。如图1所示,通过输入一张当前车辆的前景图像产生对应四个尺度的稠密深度图(灰色矩形)。其具体网络结构主要由7组卷积和反卷积组成,反卷积由Zeiler等人提出[14],与卷积一样都是通过网络的反向传播进行参数优化。
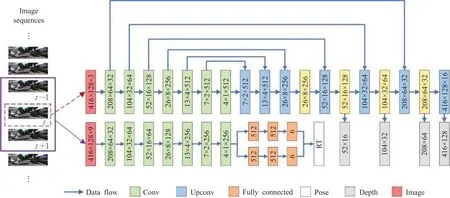
图1 DS-VO网络设计Fig.1 Network structure of DS-VO
在道路环境下,存在大量动态物体、不稳定实例,这会对光度一致性假设条件构成破坏,有研究使用掩码或遮罩来对光度不稳定的像素进行弱化处理[15],也有研究直接处理光度误差损失过大的像素点[11]。通过实验,发现在像素层面的简单弱化不稳定像素点光度或者简单强化稳定像素点光度并不会达成很好的效果。本文借鉴Wang等人[16]的方法,提出语义概率解析网络。在深度估计网络的编码解码结构中加入概率解析网络(图1黄色矩形),并融合上下文信息,其具体细节结构如图2所示,其中Semantics为语义概率先验,由Deeplab[17]产生,Conv feature和Upconv feature分别为编码和解码结构的特征层,Osem为语义概率解析网络输出特征层,即动态语义概率先验信息:
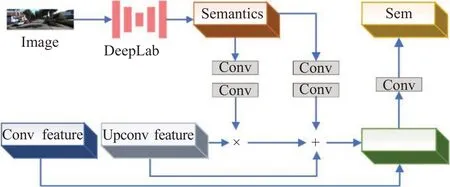
图2 语义概率解析网络Fig.2 Semantic probability analysis network
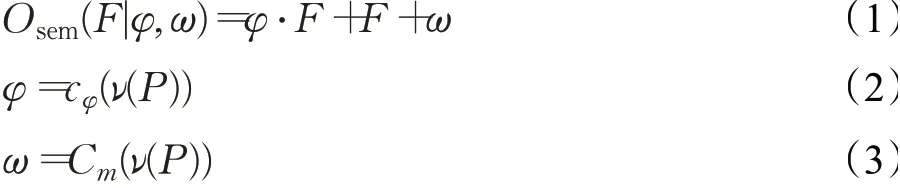
式中,·为点乘计算,P为语义概率先验,ν为语义概率解析网络,其输入的通道数为语义类别数,输出的通道数和上下文连接通道的特征图通道数一致,φ,ω为输入的特征图F通过语义概率解析网络产生的参数对。
1.2 位姿估计网络
位姿估计可以连续跟踪车辆的运动并产生相对位姿,通过在已有的初始化条件下整合相对位姿重建车辆的全局运动轨迹。现有的位姿估计网络存在两个主要问题:第一,由于在道路环境下大旋转会导致连续帧之间交叠区域过小,对光度一致性造成一定程度的破坏;并且旋转向量的表示与平移向量表示相比,具有更高的非线性,相对训练难度较大。第二,位姿预测并非传统意义上的图像预测,而是一种运动估计,如何通过简单有效的网络预测位姿向量达到较好的精度成为一个具有挑战性的问题。本文提出使用2个不同的全连接网络(图1的橙色矩形)分别处理位姿向量中的旋转向量和平移向量,以避免相同的全连接层对旋转向量和平移向量拟合能力的不同导致出现预测误差,进一步利用简单的网络结构提升位姿估计的能力,保证了位姿估计中不同类型向量估计的准确性。
位姿估计网络包含:7层卷积层和2组3层全连接层,每个卷积层后皆有批归一化层,避免梯度消失,每个全连接层后为ReLU(rectified linear unit)非线性激活函数和Dropout层。Dropout层防止网络过拟合,而ReLU函数可以有效进行梯度下降的反向传播,减少参数量,避免梯度问题。
2 单目图像的损失函数
为了能使网络进行自监督训练,本文利用光度几何一致性构建损失函数,通过损失函数的反向传播进行训练。光度几何一致性表示几何投影两个连续的单目图像中对应像素点之间的约束,通过最小化光度误差,使网络以端到端的方式学习6维位姿向量和深度地图。
一张图像帧I输入深度预测网络产生相应的深度图D,相邻的3个图像帧序列输入位姿预测网络产生2个相邻帧间的位姿变换[R|t],其中,R为旋转向量,t为平移向量,两者共同构成位姿向量[R|t]。以相邻的两张图像帧为例,光度误差的损失来自于两张相邻的单目图像,图3展示了单个像素计算光度误差的方式。这里,假设第一张图像帧I1的一个像素点为p1,p1所对应的在第二张图像帧I2的一个像素点为p2,I1和I2之间的位姿向量为送入深度预测网络得出的深度图为D2,p2所对应的深度为D2(p2),则可以通过p2估计出p1,公式如下:
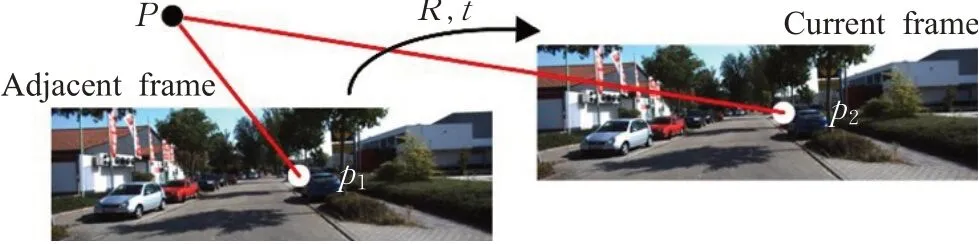
图3 光度误差Fig.3 Photometric error
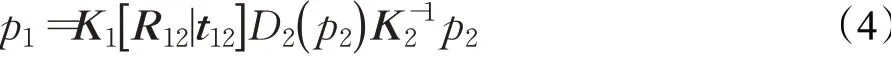
式中,K1和K2分别是图像帧I1和I2对应两幅图像的本征矩阵。通过估计得到的深度和位姿对每个像素点使用同样的计算过程和相应的空间转移[18],可以通过图像I2得到I1的投影图像,将I1的投影图像与I1作光度误差比较,两者越相似则表示估计得到的深度与位姿越准确。
早期研究中,单目自监督的深度估计主要依赖基于光度一致性计算光度误差[15],然而直接计算光度误差作为损失函数会导致深度估计网络鲁棒性较低。本文使用结构相似性指标(SSIM)作为损失函数的一部分[19],与L1光度绝对误差一起作为单目光度误差损失函数,用来评估目标图像和投影生成图像的相似度。SSIM在超分辨[20]、图像去模糊[21]等都有应用,SSIM越大,表明投影图像与原图像之间的差距越小,当两图像完全相同时,SSIM为1。L1损失函数为最小绝对值误差,较L2损失函数相比鲁棒性更强。可以得到基于无监督的单目光度误差损失为:
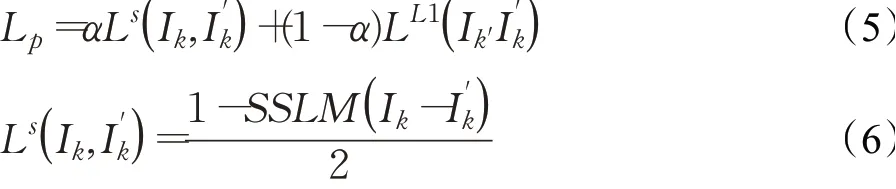

式中,α是平衡系数[22],Ik为图像序列中的一张图像帧,为图像帧Ik通过计算投影和双线性插值后生成的图像。
由于深度不连续性经常出现在图像的像素梯度中,为了去除不准确的预测、解决深度和位姿估计中的梯度局部性问题和消除低纹理区域学习深度的不连续性,本文在损失公式中引入深度平滑项[15]。深度平滑项对相邻像素进行梯度进行计算,与光度误差损失一起构成网络的损失函数。由于一阶梯度平滑项会导致深度图梯度趋于零,而深度图具有连续性,其梯度期望为常值,所以本文采用二阶梯度平滑项,深度平滑项为预测深度图的二阶梯度的L1范数,其公式如下:
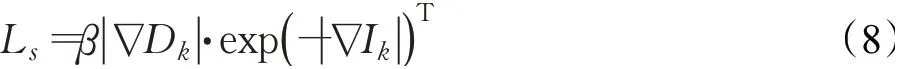
式中,||为绝对值,β为深度平滑损失的权重,Dk是Ik所估计的深度图,∇为向量的微分计算,T为转置。
在训练过程中,将单目图像序列同时输入深度估计网络和位姿估计网络,利用卷积神经网络强大的建模能力预测位姿向量和深度图,结合输入的原始图像、深度图以及位姿向量,根据光度误差计算,重建出下一帧图像,并将重建的下一帧图像与真实的下一帧图像进行对比,计算出损失。通过损失函数反向传播到神经网络,调整网络参数,改进生成的结果,不断重复该过程,直到重建误差降到最小,神经网络趋于拟合。本文的网络具体流程如图4所示。
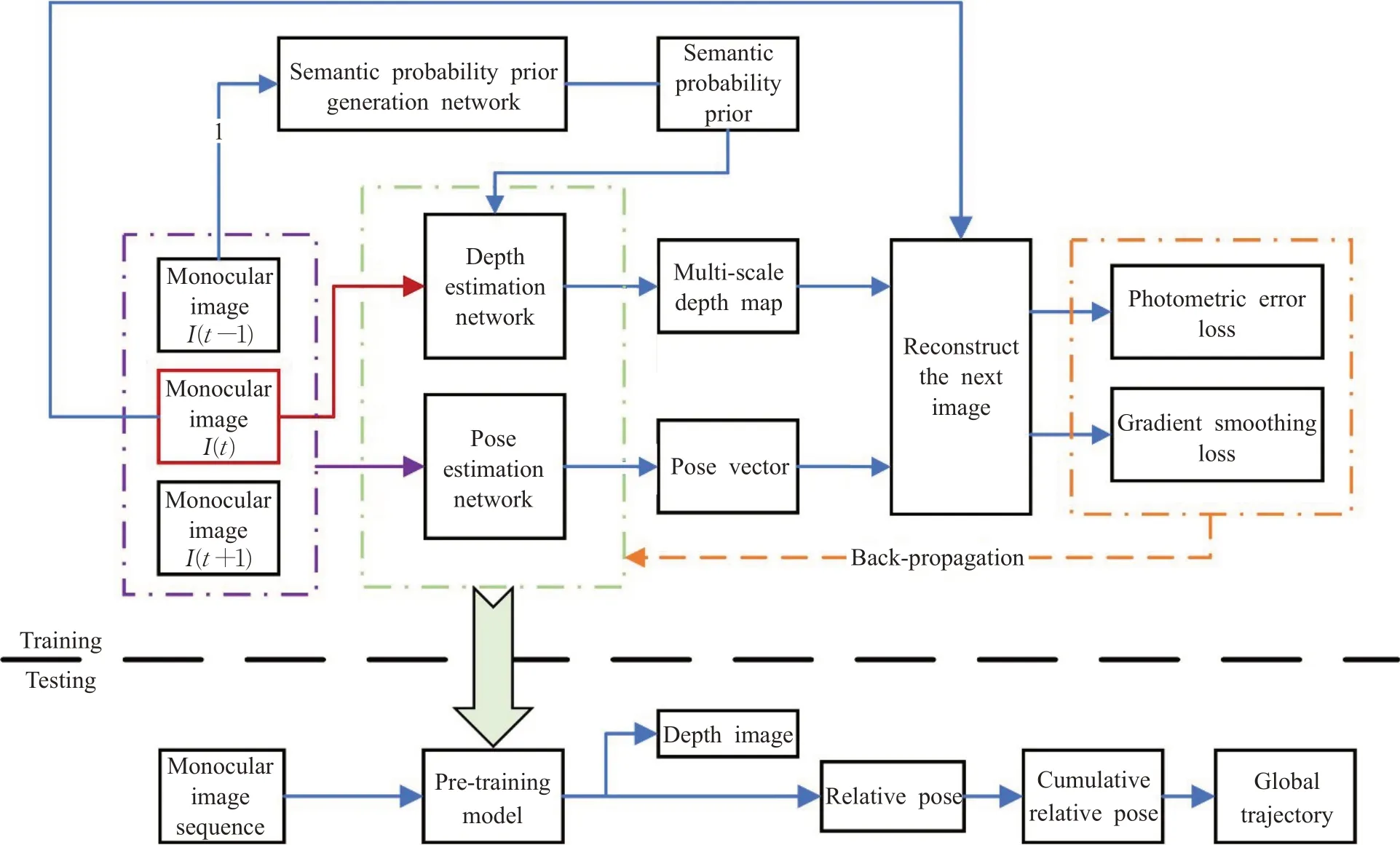
图4 网络流程图Fig.4 Flow chart of network
3 实验结果与分析
3.1 实验数据
实验使用KITTI数据集[23]、Cityscapes数据集[24]和PASCAL VOC 2012数据集[25],其中使用KITTI数据集的视频图像用于训练、深度预测的评估,KITTI Odometry数据集用于位姿预测的评估,Cityscapes、PASCAL VOC数据集用于语义先验产生网络的训练。
KITTI数据集是目前国际上最大的自动驾驶场景下的视觉算法评测数据集,包含市区、乡村和高速公路等场景采集的真实图像数据,包括原始的输入原图像、雷达三维点云数据和相机运动轨迹。Cityscapes数据集包含了5 000张精细标注的图像,其中包含50个城市的不同背景,以及30类涵盖地面、建筑、交通标志、自然、人和车辆等的物体标注。PASCAL VOC数据集主要是针对视觉任务中监督学习提供标签数据,主要类别为人、动物、交通车辆等。
诸多的相关工作中都采用了Eigen划分的单目深度估计数据集[26],这个测试数据由28个场景、697张图片构成,不包括训练图片,为了方便与其他方法比较,本文也采用了这个数据集来评估深度预测效果。
系统工作站采用Nvidia Titan Xp GPU进行训练,实验使用PyTorch深度学习框架。初始化Adam[27]优化器参数β1=0.9,β2=0.999。最初按照经验值设置学习率为0.001,此时模型难以收敛;改进学习率为0.000 1,训练曲线振荡较大,无法达到最优值。经过多次调整。最终选择合适的学习率为0.000 2,批尺寸设置为4。训练迭代次数为20万次时,模型趋于拟合。所有训练数据为单目图像,没有任何数据标签下自监督训练。将训练的图像大小调整为128×416,并进行随机缩放与裁剪以扩充数据集。
3.2 消融实验
通过对引入的语义概率解析网络在不同网络结构上的训练结果对比验证网络设计的合理性。为了直观地评估消融实验的结果,给出了上述11个深度估计评价指标对4个网络的深度估计结果,以及绝对轨迹误差(ATE)和相对轨迹误差(RE)指标[23]对4个网络的位姿估计结果,如图5所示。Base即位姿估计和深度估计网络中未引入语义概率解析网络;Sem-en为在深度估计网络中的编码部分引入语义概率解析网络;Sem-de为在深度估计网络中的解码部分引入语义概率解析网络;Sem-all为在深度估计网络中的编码及解码部分引入语义概率解析网络。可以发现,在深度估计中,语义先验加入到深度估计网络的解码结构带来了较好的效果,同样在位姿估计中,相较不引入语义先验,在网络中引入语义先验提升了位姿估计的精度。深度估计定量分析的评价指标如下:

图5 消融实验Fig.5 Ablation experiment
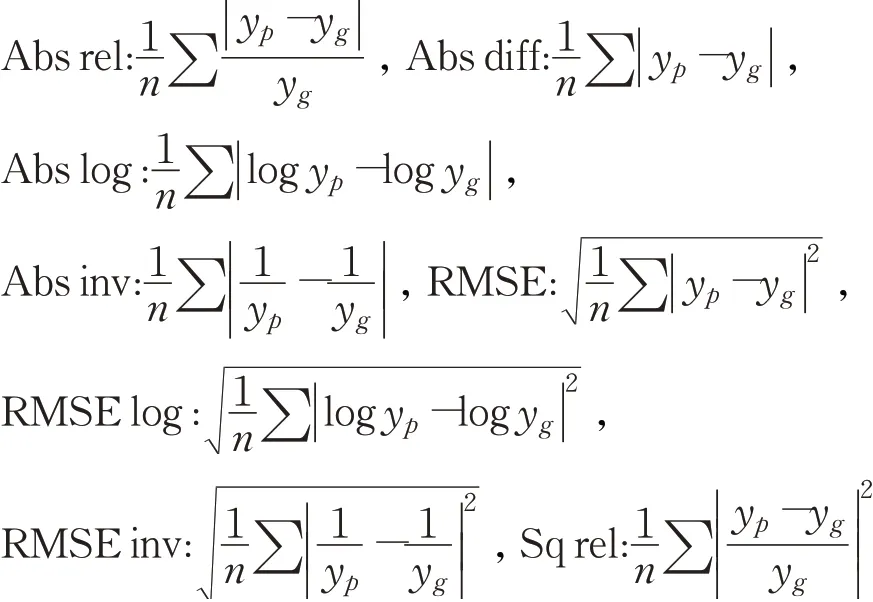
图5中a1、a2、a3分别代表深度估计预测精度ζ,三个不同的阈值(1.25,1.252,1.253)。它统计像素的百分比预测的深度值与真实值之比小于阈值。预测的深度值与真实值之比小于阈值。越接近1,预测结果越好,评价指标公式如下:
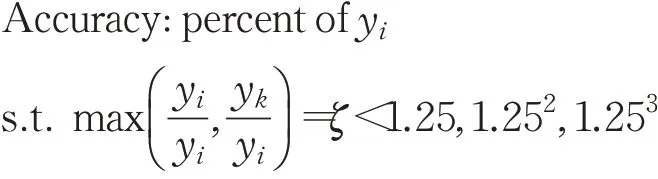
3.3 语义估计
对于语义概率先验的产生网络,使用文献[17]提出的语义分割网络,在PASCAL VOC数据集预训练后在Cityscapes数据集上精调,语义概率先验的产生网络产生8个动态物体类别概率,输出的语义概率先验作为语义概率解析网络的输入,语义概率解析网络输出为动态语义概率先验信息。如图6所示,本文对语义先验产生网络所产生的语义先验进行了可视化,可以清晰地看到语义概率对于动态物体的理解能力。

图6 动态语义概率先验可视化Fig.6 Dynamic semantic probability prior visualization
3.4 深度估计
本文从测试场景中排除所有平均光流值小于1像素的静态序列帧进行训练。使用的数据一共有30 945个序列,其中23 982个序列用于训练,6 963个序列用于验证。首先进行定量对比实验,将本文方法与现有方法比较,深度估计的阈值精度如图7所示,仍使用同图5相同的深度估计预测精度ζ,深度估计对比结果如表1所示。
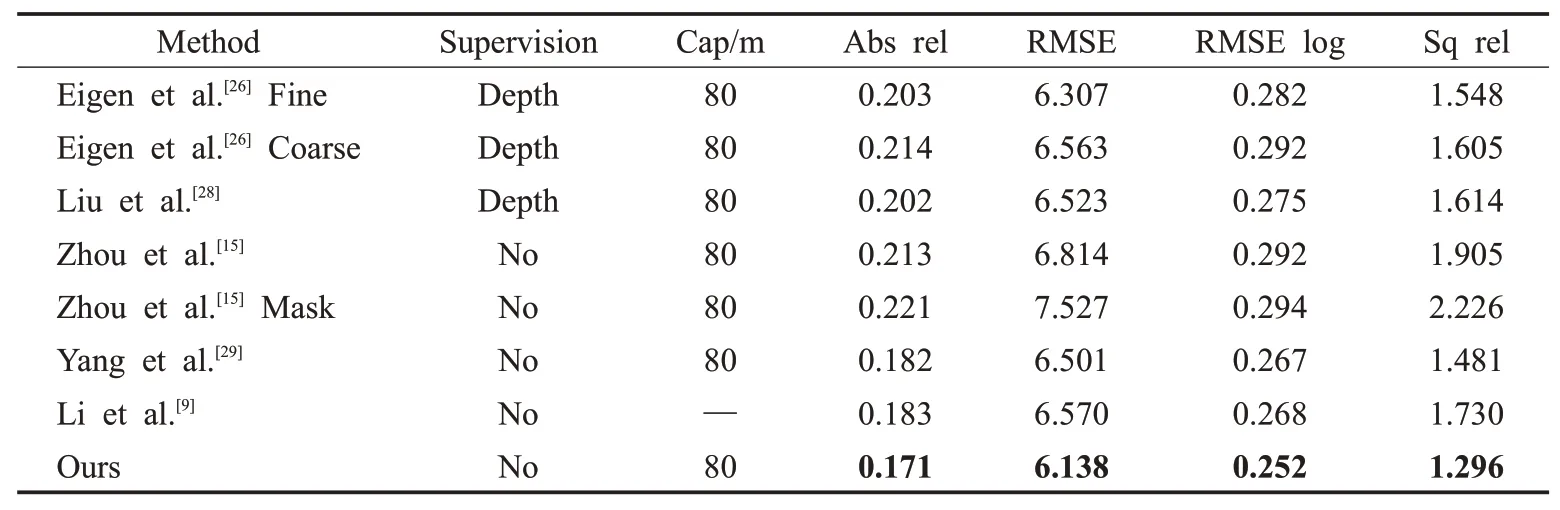
表1 深度估计量化结果对比Table 1 Comparison of depth estimation quantitative results
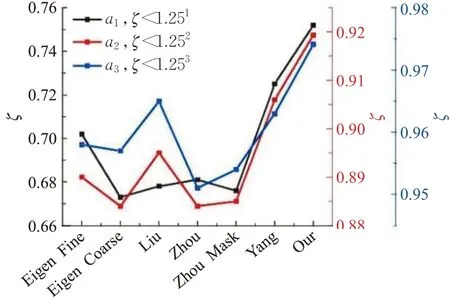
图7 阈值精度评价指标对比Fig.7 Comparison of threshold accuracy evaluation indicators
分析上述实验结果,与现有的有监督方法[26,28]和无监督方法[9,15,29]相比,本文方法在无深监督信号的情况下,取得了更好的深度估计效果。为了直观评估深度估计的结果,本文与文献[15]的方法进行对比,分别可视化本文引入和不引入语义先验的网络的深度估计结果,并可视化深度真值,如图8所示。可以发现,相较于其他方法对于深度估计存在深度图模糊、边缘不清、深度不连续、不完整的现象,本文方法引入动态物体语义先验后,深度估计可以准确估计深度图,有效改善深度图不连续、模糊、空洞等现象,并且深度图边缘更加清晰。

图8 深度估计结果对比Fig.8 Comparison of depth estimation results
3.5 位姿估计
为了量化评估位姿估计网络,使用KITTI odometry 09和10序列进行测试,并与一些已经提出的方法进行比较,对比结果如表2所示,其中,第四行数据为数据集的里程计真值的平均值。与ORB-SLAM2等在长期具有滑动窗口优化相比,由于本文所设计的视觉里程计是在短期的图像序列片段进行训练和测试,本文方法在短期评估上,即相对位姿的评估更具优势。与文献[15]方法相比,本文方法在序列09上的绝对轨迹误差指标均值降低1%,标准差降低1.2%;与人工设计特征点的传统算法[30]相比,本文方法也取得了相似或更优的结果,因此本文方法有着更好的表现。
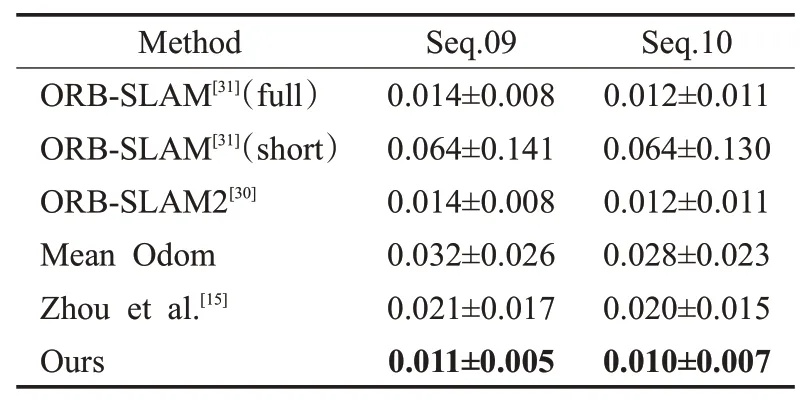
表2 绝对轨迹误差(ATE)Table 2 Absolute trajectory error(ATE)
4 结束语
本文提出一种基于道路环境动态语义特征的视觉里程计(DS-VO),通过神经网络模型直接将输入原始数据和输出目标连接起来,不再需要人工设计特征;分析了在视觉里程计中基于光度一致性的自监督网络存在的局限性,提出语义概率解析网络为深度估计网络提供动态物体先验,以增强自监督网络的鲁棒性;针对平移和旋转向量的网络训练难度不一致,提出使用两个独立的全连接层分别估计平移和旋转向量。实验结果表明,本文算法可以显著提升深度估计与位姿估计的精度。
猜你喜欢
电子测试(2022年16期)2022-10-17
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
现代信息科技(2020年22期)2020-06-24
矿山测量(2020年2期)2020-05-17
山东工业技术(2019年16期)2019-07-19
电子技术与软件工程(2019年6期)2019-04-26
汽车电器(2019年1期)2019-03-21
花火A(2018年9期)2018-11-26
科技与创新(2018年12期)2018-06-22
