
采用支路辅助学习的人脸表情识别
2022-12-06 10:30赵家琦周颖玥王欣宇
计算机工程与应用 2022年23期
赵家琦,周颖玥,王欣宇,李 驰
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.西南科技大学 特殊环境机器人技术四川省重点实验室,四川 绵阳 621010
面部表情是人类情绪变化的直接载体,也是一种在社会交流中不可或缺的非语言信号,随着机器视觉研究的迅速发展,如何通过面部图像来获取人类的情绪信息成了备受关注的研究方向。研究人员Ekman[1]提出了六种人类情感的概念:生气、厌恶、害怕、高兴、悲伤和惊讶。不同面部表情之间的差异性主要集中在嘴部和眼部等局部区域,因此人脸表情识别属于一种细粒度分类问题。
传统的人脸表情特征提取方法有很多,较为经典的有:提取表情纹理特征的局部二值模式(local binary pattern,LBP)方法[2]、提取表情边缘特征的方向梯度直方图(histograms of oriented gradient,HOG)方法[3]、具有抗角度旋转和尺度变化的尺度不变特征转换(scale invariant feature transform,SIFT)算法[4]等。由于通过截取得到的人脸图像尺寸较小,且各类表情之间类内差异大,类间差异小,这使得人工设计的特征提取算法在实际运用中十分容易受到背景、噪声、角度等因素的干扰,模型识别性能有限、泛化能力相对不足。
近些年来,卷积神经网络(convolutional neural network,CNN)模型在计算机视觉各个领域中发挥了至关重要的作用。CNN无需人工设计特征,而是将端到端的数据投入训练,使得参数不断迭代更新,从而获得具有较好特征提取能力的网络模型。通过众多学者的不断研究,CNN的网络结构得以不断改进和优化。2014年Simonyan等[5]提出了VGG模型,该网络首次使用逐级通道数递增的小卷积核代替大卷积核参与运算,在有效减少参数量的同时使得网络层数更深,有效提升了网络的特征提取能力。2015年,ResNet[6]的提出,有效解决了深度卷积网络出现模型退化的问题。随后,Inception[7]模型被提出,通过嵌入空间聚合模块,有效提升网络特征提取能力并且进一步加深网络深度。2018年,轻量化网络MobileNet[8]提出了深度可分离卷积方法,将传统卷积核从通道数量和卷积核尺寸两个参数上进行拆分,极大减少了网络参数量。2019年,关于注意力机制的研究从自然语言处理方向转移到了机器视觉方向,Hu等[9]提出了压缩-激励(squeeze-and-excitation,SE)模块,通过在模型训练中不断修正不同深度特征图通道的权重,达到特征校准的目的。同年,Woo等[10]提出了完整的基于卷积神经网络的卷积注意力模块(convolution block attention module,CBAM),该模块由空间注意力模块和通道注意力模块前后堆叠而成,既关注了模型中通道间的相互关系,也关注了局部信息与全局信息在空间位置上的相互关系,进一步提升了网络性能。2020年,基于计算机视觉的Transformer模块[11]被广泛运用在计算机视觉任务中,它使用自注意力提取特征的方式成为了该领域新的研究方向。
在人脸表情识别问题中,许多研究学者也在传统神经网络模型的基础上提出了相关的创新方法。例如:Al-Shabi等[12]通过将面部表情中提取出的SIFT特征与CNN训练得到的特征进行合并,建立了一个适用于小样本数据集的混合CNN-SIFT分类器,最终在公开人脸表情数据集CK+上达到了99.4%的识别率,但该模型参数较多,运算复杂度较大。Gu等[13]使用VGG和ResNet同时学习,以双通道输入的方式训练网络,再将两个网络上提取的高维特征进行级联,得到了较单一网络更好的分类结果。柳璇等[14]在CNN模型中添加了跨连接通道加权模块,同时在输入端将由人工提取得到的特征伴随原图共同输入网络,有效提升了网络的泛化能力,但忽略了面部表情中不同关键区域特征的关联性。高红霞等[15]通过Transformer模块提取面部表情关键点属性,再融入多种注意力机制,在多个数据集上都得到了不错的识别率。
对于表情识别任务,模型需要同时聚焦于浅层初级特征与深层高级特征。传统的多尺度特征融合通过拼接的方式将多尺度特征在通道维度上直接堆叠,这种方法在细粒度识别场景下会造成大量信息冗余,并且模型会丢失不同尺度特征对背景信息的抑制能力。针对这一缺陷,本文提出一种基于支路辅助学习的人脸表情识别方法:在基础网络之外引入一条用于提取全局特征的支路辅助网络,使用特征映射方法,将支路得到的初级特征作为掩膜传递到主路,有效提升模型对细粒度特征的表征能力,极大降低非表情区域特征对分类结果的影响。该方法由以下三个部分组成:
(1)支路辅助学习网络:该网络由多个金字塔卷积块堆叠形成,和基础网络共享输入、输出层。金字塔卷积块由空洞卷积和非线性过滤层组合形成,能够获取感受野更大的多尺度特征,更加注重全局信息提取,从而实现抑制背景干扰的目的。金字塔卷积块得到的输出会经由特征映射模块单向传递给基础网络以实现高效信息交互。
(2)特征映射模块(feature-mapping module,FM):该模块能够将特征图转化为单通道的权重图,其中每一个点的取值表示该像素位置对目标分类结果影响的大小。特征映射模块会将支路网络得到的初级特征转化为空间上的权重掩膜覆盖在基础网络上,通过不断迭代,优化自身参数,以提升基础网络对细粒度特征的学习能力及泛化能力。
(3)双路权重分配单元(double-channels weight assignment,DCWA):由于得到统一空间信息加权的特征图在通道维度呈高度离散化,为了重构通道映射关系,提出一种双路权重分配单元。对得到特征映射的特征空间采用两路不规则卷积配合池化的方法计算通道权重,从而实现通道归一化。
为验证所提出的支路辅助学习方法的有效性,本文将几类主流网络选作基础网络,对其添加支路辅助学习模块,并在公开人脸表情数据集上进行实验。实验结果表明,支路辅助学习模块可以有效提升基础网络的特征提取性能。
1 基于支路辅助学习的识别模型
本文提出的识别模型由基础网络、支路辅助学习网络、特征映射模块和双路权重分配单元四个部分组成。其中,基础网络可以备选各类主流卷积神经网络,例如:VGG、Inception、ResNet等。本文统一将基础网络分为三部分:前处理块,指不受支路辅助学习网络影响的特征提取块;计算块,指得到支路特征映射的特征提取块;后处理块,是对即将输出的特征进行全连接计算或者特征降维的部分。完整的模型框架见图1所示,其中输出端使用全连接层(fully connected,FC)计算类别概率。
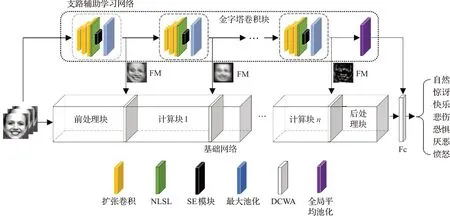
图1 本文算法模型框架图Fig.1 Overview of proposed framework
1.1 金字塔卷积块
金字塔卷积块是一个具有多尺度感受野的特征提取器,能够得到精度粗略、局部信息关联度高的初级特征,参考结构重参数化[16]的思想,金字塔卷积块使用3×3的多尺度扩张卷积配合一种非线性过滤层(non-linear sift layer,NLSL)。扩张卷积能够有效增加感受野,使得输出特征包含更多的上下文关系。NLSL层是一种提取全局纹理信息的方法,通过对局部特征信息解耦,有效减少了背景干扰,使得模型在不断迭代的过程中能够利用输入图片的全局特征去抑制非表情区域特征。将NLSL输出的结果和扩张卷积得到的特征图在通道维度串联,得到特征提取部分的输出。具体结构如图2所示。
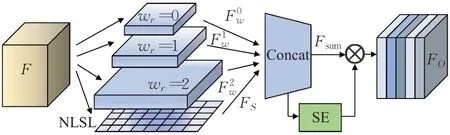
图2 金字塔卷积块Fig.2 Pyramid convolution block
将输入特征F,F∈RH×W×D(H×W×D表示特征的空间尺度为H×W、通道数为D),分别馈送至wr=0、wr=1和wr=2的三个扩张卷积通路,其中r=0,1,2表示三种不同扩张比例。然后对卷积后的结果进行激活,得到输出,计算公式如式(1)所示:

其中,δ表示Sigmoid激活函数。
NLSL层由一组可训练的参数矩阵构成,该组矩阵的尺寸与输入特征的尺寸完全相同,它能够建立点到点的独立映射,有效利用全局感受野。用λ表示NLSL的参数矩阵组(默认包含偏置值),用λd表示其中的一个通道,Fd表示输入特征中的一个通道,其中0<d<D,d∈ℝ*。将NLSL的计算方法定义为fS,则输入特征F经NLSL处理后的输出特征图FS可表示为式(2)和(3)所示:
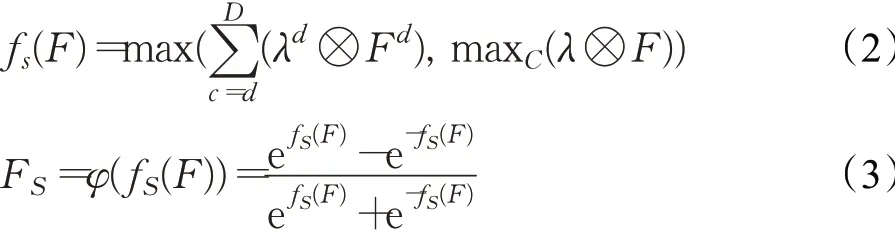
其中,φ表示tanh激活函数,⊗表示矩阵内积运算,maxC表示计算通道维度上的最大值。使用tanh作为激活函数是为了对输出结果进行归一化的同时保留输入的符号。由于减小了邻域信息对有效特征的干扰,NLSL能够保留输入特征中最原始的纹理信息,但同时也会造成部分细节信息丢失,这使得支路辅助学习网络仅能够获得感受野更大、全局信息更多、细节信息更少的初级浅层特征。
将Fs与在通道维度上拼接得到输出特征图Fsum。为了对Fsum进行信息整合,在特征拼接后添加了SE模块,得到金字塔卷积块的输出FO。SE模块能够增强特征通道间的相互关联性,进一步提升了金字塔卷积块的特征表征能力。与原始SE模块不同的是,将激活函数Sigmoid替换为线性整流函数(rectified linear unit,ReLU),这样可以有效避免梯度消失的问题。
1.2 支路辅助学习网络
通过串联数个金字塔卷积块,得到了支路辅助学习网络,其具体框架如图3所示。其中k表示支路网络的深度。在训练过程中,支路得到的特征会不断反馈到基础网络,对基础网络的分类决策进行修正;在输出端,支路网络会使用全局平均池化(global average pooling,GAP)压缩信息,在最后一个全连接层通过向量拼接的方式与基础网络进行特征融合,并且共同参与Softmax激活,计算出输入表情样本属于各类表情的概率。
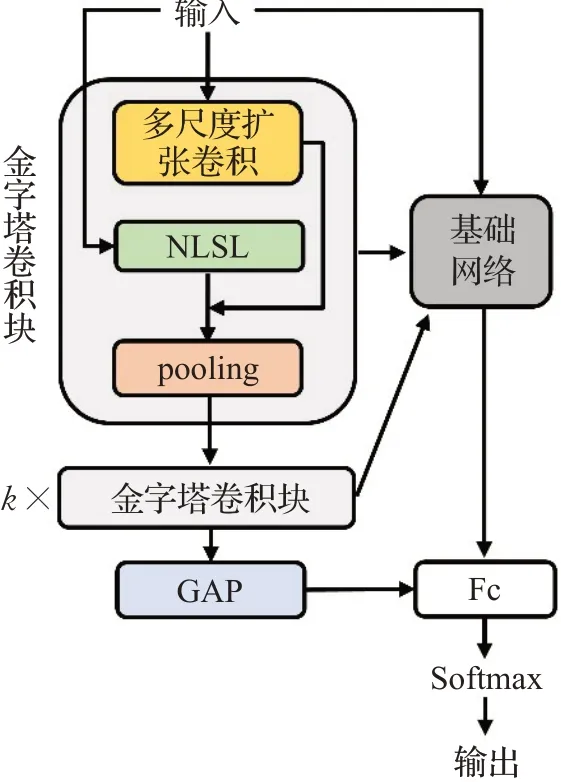
图3 支路辅助学习网络Fig.3 Branch-assisted learning network
所构建的支路辅助学习网络旨在获取感受野更大、全局信息利用率更高的特征。在网络的浅层,这些信息能够为基础网络的特征提取提供增益,去除背景干扰,提升收敛速度;在网络的深层,它们能够传导原始纹理信息,为基础网络的特征提取提供补偿,使其更有效地响应模型输出。
1.3 特征映射模块
为了高效率、低冗余地将支路信息传递至主路,本文提出一种特征映射方法,该模块能够将支路得到的初级特征转化为单通道权重掩膜覆盖在基础网络上,合理地利用了多尺度下的特征信息。该模块的具体框架如图4所示。
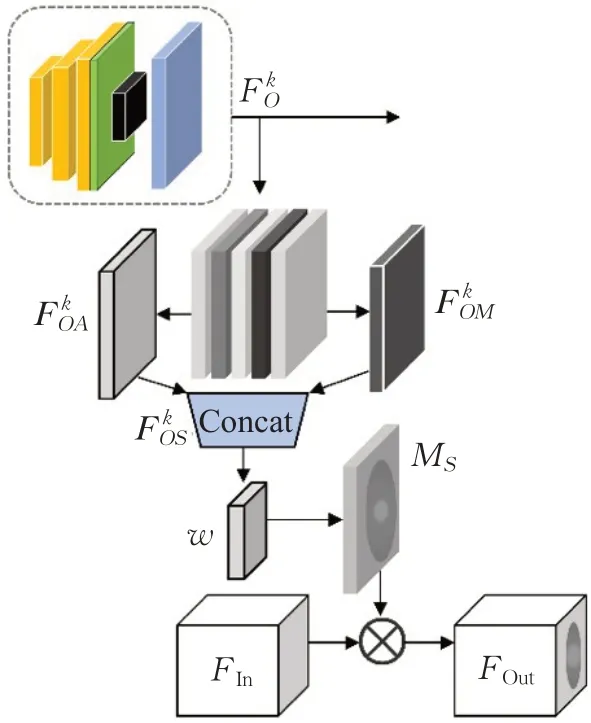
图4 特征映射模块Fig.4 Feature-mapping module
将第k层金字塔模块的输出作为特征映射模块的输入。首先,对在通道维度上并行使用平均池化和最大池化,分别得到特征向量;然后,沿通道轴合并得到;其次,为了整合信息、改变通道数,使用3×3卷积作用于合并后的特征,得到空间特征算子MS;最后,MS与基础网络计算块中的输入特征信息FIn相乘,得到模块输出FOut,即:

特征映射模块实现了由支路到主路的特征递进,将支路信息作为先验知识传递至主路。因为仅有一个单通道卷积核参与计算,且输出特征图的维度与输入一致,所以该模块并不会对模型学习造成负担。通过不断迭代运算,模型能够快速聚焦在对分类结果高度敏感的像素块部分,从而抑制低敏感信息特征的提取,有效提升模型对面部表情特征的学习能力。同时,由于该模块中信息传导方式为单向传导,并且添加了NLSL方法的金字塔卷积块学习能力始终“有限”。所以在训练初期,支路辅助学习网络能够有效提供空间注意力信息,而在训练后期,支路辅助学习网络提供的权重掩膜也能防止基础网络陷入过拟合,所以该模块对模型的泛化能力也有一定提升。
1.4 双路权重分配单元
由于特征算子MS中包含具有高度空间敏感性的信息,得到统一映射的特征空间很容易丧失通道间的相互依赖性。因此,为了在训练过程中对其重建逻辑关系,本文提出一种双路权重分配单元,添加在特征映射模块的输出端。
由于人脸特征在水平与垂直方向具有高度对称性和相似性,所以双路权重分配单元采用两组不同方向的不规则卷积[17]提取重要细粒度信息,配合平均池化和具有压缩比的点卷积,实现对特征通道赋予权重的操作。通过设置压缩比,来减少信息冗余。该模块的结构如图5所示。
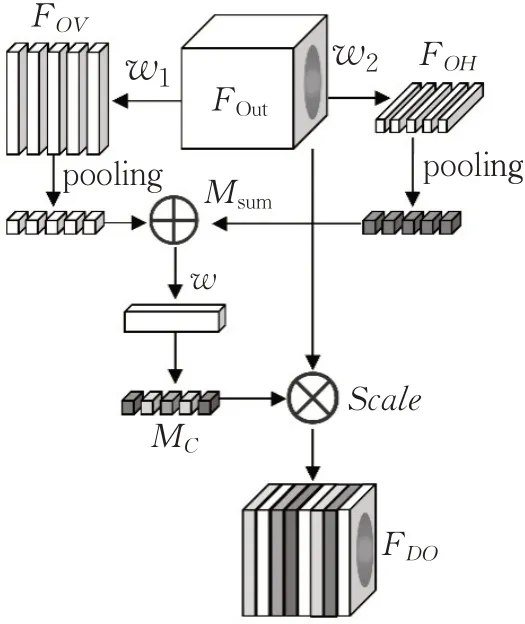
图5 双路权重分配单元Fig.5 Double-channel weight allocation module
FOut作为双路权重分配单元的输入(即特征映射模块的输出),传递给两路不规则卷积w1(w1∈RH×1×C/r)和w2(w2∈R1×W×C/r),通过设定压缩率r,实现通道压缩。然后,将卷积后得到的梯度特征FOV和FOH进行全局平均池化,对池化结果进行求和得到通道信息的表征,用Msum表示。其次,对Msum执行点卷积计算,并通过Sigmoid函数激活输出结果,获得输入特征FOut在通道维度上的权重MC。将上述计算过程用如下公式进行表达:
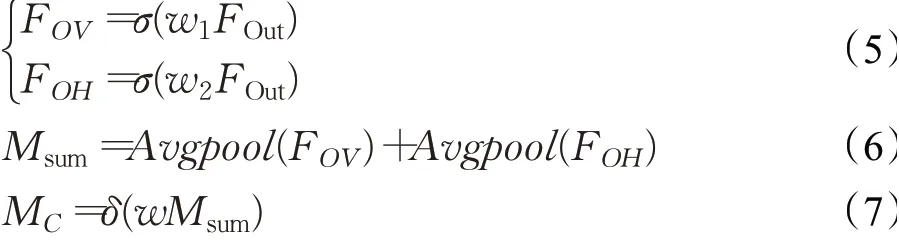
其中,δ表示Sigmoid激活函数,σ表示ReLU激活函数。
最后,将MC与输入FOut相点乘,获得了最终加权结果FDO。上述所提出的双路权重分配单元对得到映射后的特征图通道进行归一化计算,通过不规则卷积获取通道权重,有效提高信息利用率,增强了FOut中有益特征通道对输出的响应。
2 融合支路辅助学习的网络架构
支路辅助学习模块结构灵活,可以装载在现今各类主流卷积神经网络上。本文选取较有代表性的VGG16、ResNet50以及InceptionV3作为基础网络,分别添加支路辅助学习模块并在公开数据集进行测试。不同模型的内部结构和网络深度都存在差异,如表1所示。
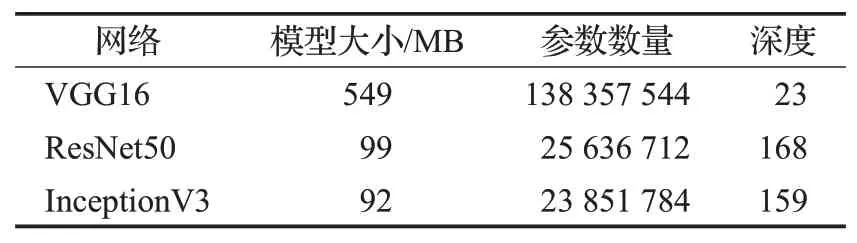
表1 本文所选基础网络及其参数Table 1 Selected base-network and parameters
对应三种基础网络,本文设置不同的计算块划分,最终根据划分方式为基础网络添加支路辅助学习模块。
VGG16+支路辅助学习:VGG16模型包括通道数递增的3×3卷积层、最大池化层、点卷积层、全连接层,以及输出层五部分,其结构具有规律性。本文将VGG16模型中每两个最大池化层中间定义为一个计算块,具体见表2所示。
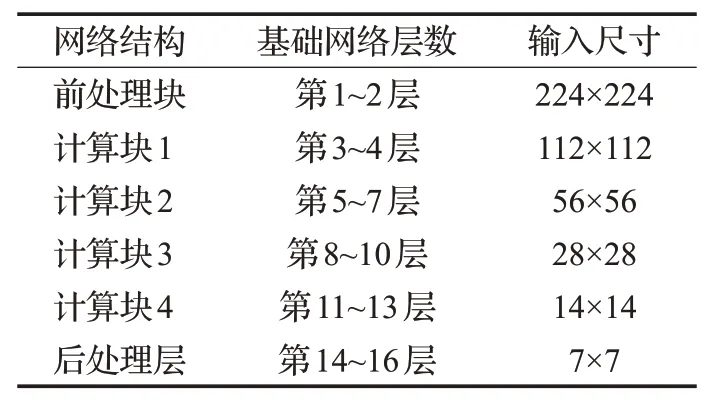
表2 VGG16的计算块划分Table 2 Block in VGG16 model
ResNet50+支路辅助学习:ResNet50网络包括7×7大小的卷积层、最大池化层、瓶颈层、批归一化层(batch normalization,BN)、残差块以及输出层六个部分,将ResNet50划分为10个计算块,见表3所示。
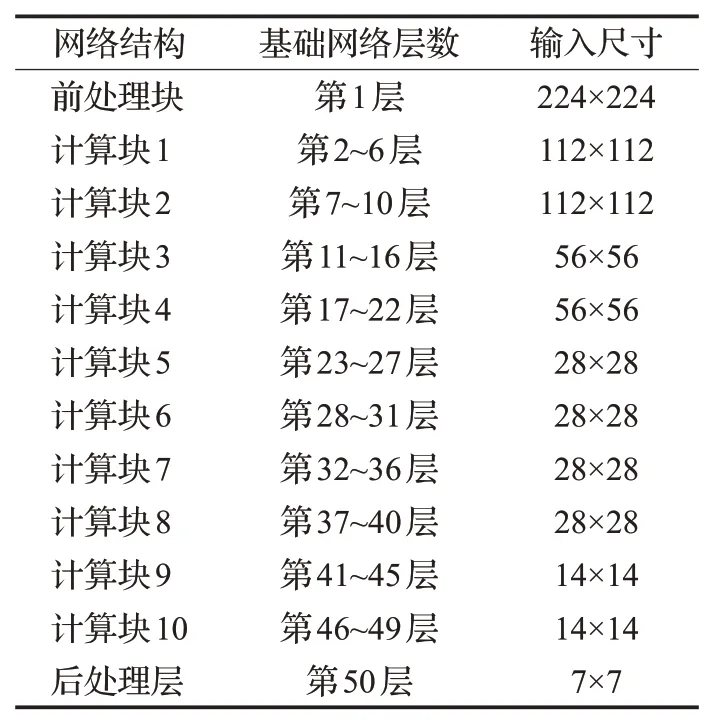
表3 ResNet50的计算块划分Table 3 Block in ResNet50 model
InceptionV3+支路辅助学习:InceptionV3网络包括3×3卷积层,池化层以及三种不同方式的Inception结构块,将该网络划分为8个计算块,见表4所示。
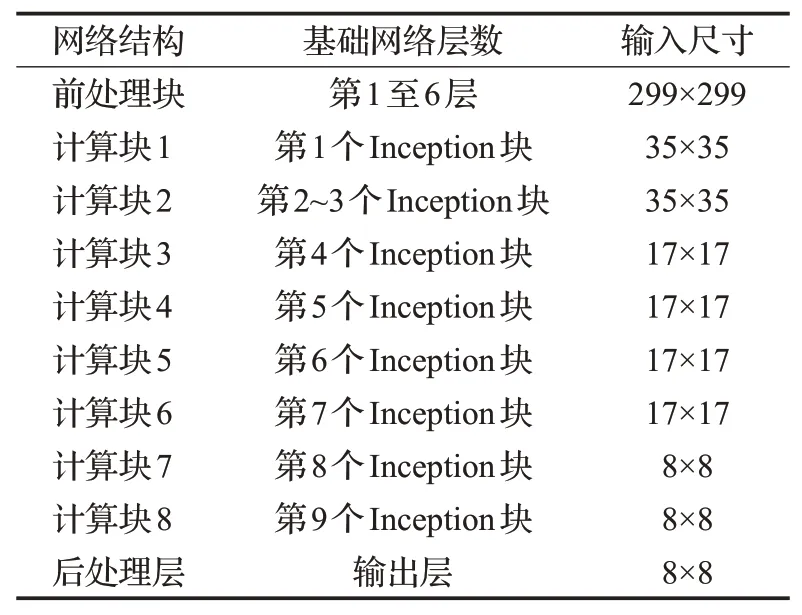
表4 InceptionV3的计算块划分Table 4 Block in InceptionV3 model
由于InceptionV3模型较为特殊,在前处理块采用了5层不填充卷积,为了更好地验证本文提出方法对于Inception块的提升,支路辅助网络将复制InceptionV3的前处理块作为前置特征提取部分。
3 实验与结果分析
3.1 实验平台
本文所有实验均在Windows平台下完成,深度学习框架为TensorFlow2.6版本,处理器为Intel E5-2660@2.00 GHz,内存为64 GB,显卡为NVIDIA GeForce GTX1080,显存为8 GB。
3.2 数据集与评价指标
为了验证本文方法的有效性,分别在CK+[18]、FER2013[19]、JAFFE以及MMEW[20]四个公开人脸表情数据库进行实验评估。其中,CK+数据集包含7类表情,共326张经过标注的人脸表情图像;JAFFE数据集也包含7种表情标签,共213张人脸表情图片;FER2013数据集较为特殊,来自Kaggle人脸表情识别挑战,数据集中有7类共35 887张包含标签的人脸表情图像,并且划分了训练集、验证集和测试集。相较于上述两个数据集,FER2013中的图像更加符合真实环境,不但角度偏移大,同时还存在部分遮挡;MMEW是现今在人脸(微)表情识别任务上最新的数据集,该数据集同时包含了微表情和宏表情样本,本文采用其中的宏表情对模型进行测试。宏表情数据共包含了30位被测者的6种不同表情样本,相较于其他三个数据集,MMEW具有更好的图像分辨率和面部分辨率。四个数据集的样例如图6所示。

图6 不同数据集面部表情示意图Fig.6 Diagrams of facial expressions in different data sets
本文将类别加权平均准确率(Acc)作为模型在数据集上的最终评价指标,如式(8)所示:
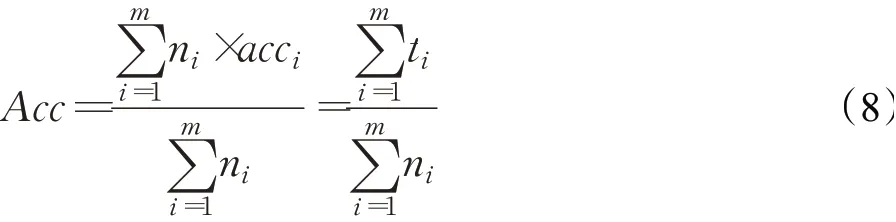
其中,m表示验证集中的类别数量,ni表示第i类的样本数,acci表示第i类的识别准确率,ti表示第i类的识别正确样本数量。
3.3 数据增强
为了克服因数据量不充足而导致网络泛化能力差的问题,需要对实验数据进行数据增强。除了线性变换方法(随机亮度、随机对比度、随机锐化、随机剪裁,水平对称,随机旋转)之外,本文还采用了一种GradMask[21]方法,即:结构化地删除图像上一组均匀分布的正方形区域,从而获取一些新的图像。
通过上述的7种数据增强方法,将最终投入模型训练的样本数量扩大为原来的15倍。数据增强示例如图7所示。
图7 数据增强示例Fig.7 Diagrams of data enhancement
3.4 训练方法与参数设置
由于CK+、JAFFE和MMEW数据集并未标定训练集与测试集,故实验中采用十折交叉验证方法。对于FER2013数据集则统一使用既定训练集训练模型,将验证集的识别率作为识别结果。
实验中,网络权重参数采用随机值初始化,将初始学习率设置为1E-3,参数更新优化器选择为Adam,损失函数使用交叉熵函数。因为VGG16模型中没有设置批归一化层,以VGG16网络为基础模型时,批处理大小设置为32;当以InceptionV3和ResNet50网络作为基础模型时,批处理大小设置为128。最后,统一将双路权重分配单元的压缩率r设置为4。
本实验采用的四个数据集中,CK+、JAFFE、MMEW数据集图像数量相对较少,为避免过早产生过拟合现象,将网络先在FER2013数据集上预训练,保存参数后再投入CK+、JAFFE和MMEW的数据进行训练。
3.5 结果分析
3.5.1 模块有效性分析
为了验证支路辅助学习模块的有效性,分别对VGG16、ResNet50、InceptionV3模型在有无添加支路辅助学习网络的条件下进行仿真实验,将支路辅助学习网络模块缩写为“BAL”,其中包含了支路辅助网络、特征映射模块和双路权重分配单元三部分。添加该模块的模型记为“基础网络名+BAL”。各个数据集的加权平均识别率结果见表5所示。
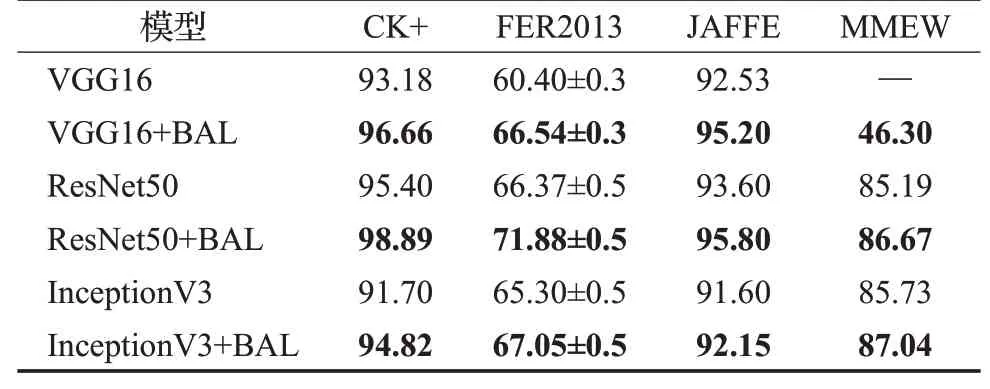
表5 不同模型结构下的人脸表情识别准确率Table 5 Accuracy of different model structures for facial expression recognition单位:%
从表5可以看出,添加BAL后的模型,在四个数据集上的识别率都得到了提升。FER2013数据集图像质量较差、角度偏移大,因此总体识别率偏低;而JAFFE和CK+中图像数量少,采集角度固定,故识别率更高。InceptionV3在添加BAL后在CK+、FER2013以及JAFFE数据集上分别提升了3.12、1.75和0.55个百分点;VGG16分别提升了3.48、6.14和2.67个百分点;ResNet50分别提升了3.49、5.51和2.20个百分点。
对于MMEW数据集而言,该数据集中不同类别表情的差异相对较小,背景信息对最终分类结果的影响较大。浅层网络VGG16在训练过程中难以收敛,在添加BAL后,最终达到46.3%的识别准确率,虽然分类结果相对较差,但是BAL有效改善了基础网络在该数据集上无法收敛的问题;而深层网络ResNet50及InceptionV3都分别得到了较好的识别结果,并且在添加BAL后,分别提升了1.48和1.31个百分点。
由于ResNet50在添加BAL后得到了最优识别结果,分别为98.89%、71.88%、95.80%和86.67%,因此将ResNet50+BAL作为本文所采取的方法,其实验结果的混淆矩阵如图8所示。
从图8可以看出:在CK+数据集上本文方法得到了较好的识别结果。并且,每类表情的识别准确率都较高。在FER2013中,“恐惧”“正常”和“悲伤”这三类之间交叉误识率较高,原因在于这三类表情面部表征区活动不明显,故难以识别正确。在JAFFE数据集上,本文方法同样取得了较好的识别率,但在“厌恶”和“愤怒”这两类数据上识别率较低,其原因可能是存在数据错误标识所导致的。对于MMEW数据集,本文方法在“厌恶”“高兴”和“惊讶”三类表情上获得了较高识别率,而其他表情类别则部分被误识为以上三类表情。原因是被误识的样本均属于消极类情绪,相似性较强,当出现这些表情时,面部特征通常只有细微改变,因此识别难度更高。
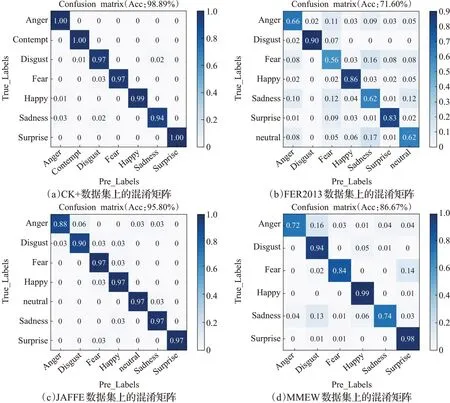
图8 ResNet50+BAL方法在四种数据集上得到的混淆矩阵Fig.8 Confusion-matrix of four data sets recognition result based on ResNet50+BAL model
为了评估BAL对具体类别识别效果的提升,在FER2013数据集上对有无添加BAL的ResNet50模型进行具体类别识别结果的对比分析,结果如图9所示。其中深色柱状图表示添加BAL后的识别率,浅色表示未添加BAL的识别率。很明显,添加BAL后,绝大多数表情的识别率都有所提升,尤其在“厌恶”类别下,识别结果提升了0.18,这说明BAL在绝大多数情况下能提升基础网络对细节特征的提取能力。
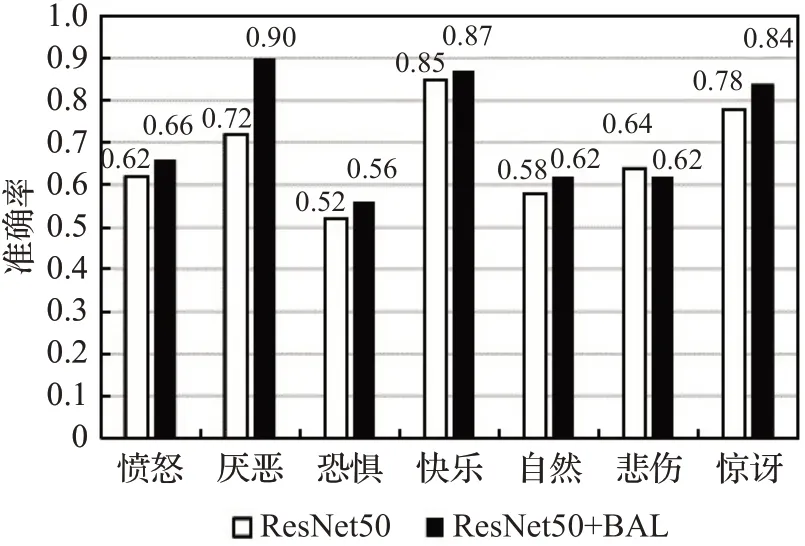
图9 具体类别识别率对比Fig.9 Comparison of recognition rate of each category
3.5.2 消融实验
为了进一步验证BAL中各个模块的有效性,以ResNet50作为基础网络,在复杂度较高的FER2013数据集和MMEW数据集上进行一项消融实验,步骤如下:(1)首先对没有添加任何模块的基础网络ResNet50进行实验,记为R50;(2)仅将双路权重分配单元添加在基础网络ResNet50上,记为R50+DCWA;(3)将深度为10的支路辅助网络作为基础网络进行实验,记为B10;(4)将支路辅助网络添加在基础网络ResNet50上,通过特征映射模块传递特征,记为R50+B10+FM;(5)将支路辅助网络添加在基础网络ResNet50上,使用传统特征融合方法融合支路与主路特征,记为R50+B10+TFF;(6)将完整支路辅助学习模块添加在基础网络ResNet50上,即本文所提方法,记为R50+BAL。为了验证算法复杂度,将各种方法的参数量展示出来。实验结果如表6所示。
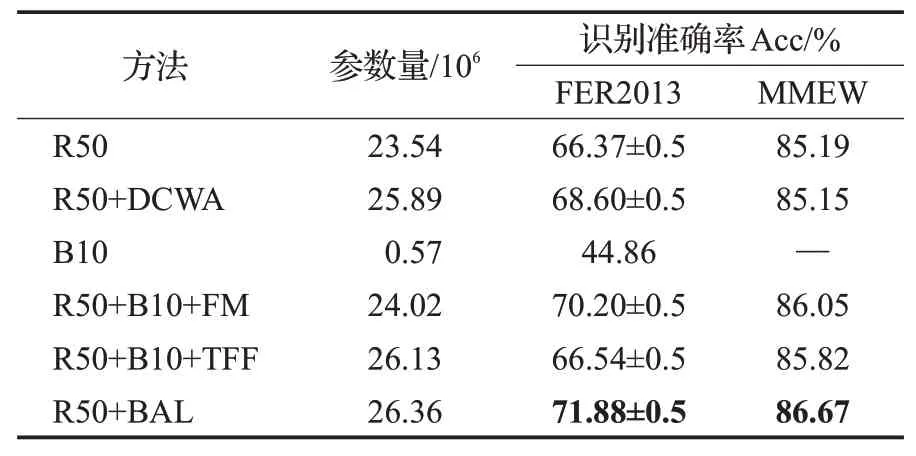
表6 消融实验对比Table 6 Comparisons of ablation experiments
由表6可知,若将单独的支路辅助学习网络直接投入训练并测试结果并不能达到较优的识别率,同时较少的参数量说明支路辅助网络是一个用于提取初级特征的轻量化网络。将支路辅助学习网络载入基础网络并添加特征映射模块后,模型在两个数据集上的识别率均有一定提升。如果使用传统特征融合方法替换特征映射模块,不但会造成更多的运算复杂度,同时测试结果相对也较差,这是因为传统特征融合方法在细粒度识别场景下往往难以有效利用初、高级特征。对比添加完整BAL模块和仅添加DCWA的模型可知:若仅添加DCWA,网络性能并不能得到较高提升,因为没有添加掩膜的网络在训练过程中通道间联系并不会受到较大的波动,直接添加DCWA不能从根本上解决背景因素对分类结果的干扰。添加完整BAL模块的模型最终在FER2013和MMEW数据集上达到了最优识别结果,验证了支路辅助网络模块对基础网络学习能力的提升。
3.5.3 可视化实验分析
为了直观地验证支路辅助学习模块的作用,本文通过Grad-CAM[22]技术将卷积过程可视化。Grad-CAM通过计算梯度来获取卷积层中像素点的重要性,通过构建热力图的方式展示网络学习到的特征,模型关注度越高的像素区域将拥有更高的亮度。有无添加BAL模块得到的实验结果如图10所示,第一行是输入图像,样本为数据集外随机选取的真实人脸图像和漫画形象,第二行是应用ResNet50模型后得到的特征热力图,第三行是应用ResNet50+BAL模型得到的特征热力图,图框为绿色表示模识别正确,红色表示识别错误。
由图10可知,添加BAL可以使特征激活结果更加聚合,降低背景对分类结果的影响,有效弱化无用特征。特别地,在第二、三列的漫画形象上,原网络出现误识,而增加BAL后,模型得到了正确输出,说明本文方法在提升网络特征提取能力的同时,有效提高了网络的泛化能力。

图10 加权梯度类激活映射热力图对比Fig.10 Comparisons of heat maps by Grad-CAM
3.5.4 多种人脸识别模型对比实验分析
为了验证本文方法的优越性,选取了近年来一些典型的基于卷积神经网络的人脸表情识别方法进行对比实验,它们是:通过自适应学习权重得到关键区域特征的模型MANet[23]、结合通道注意力和Inception块的方法[24]、使用Focal Loss替换交叉熵损失函数的方法[25]、将残差块赋予空间掩膜信息的模型[26]以及使用多尺度特征提取块替代残差单元的模型APRNET50[27],其对比结果如表7所示。
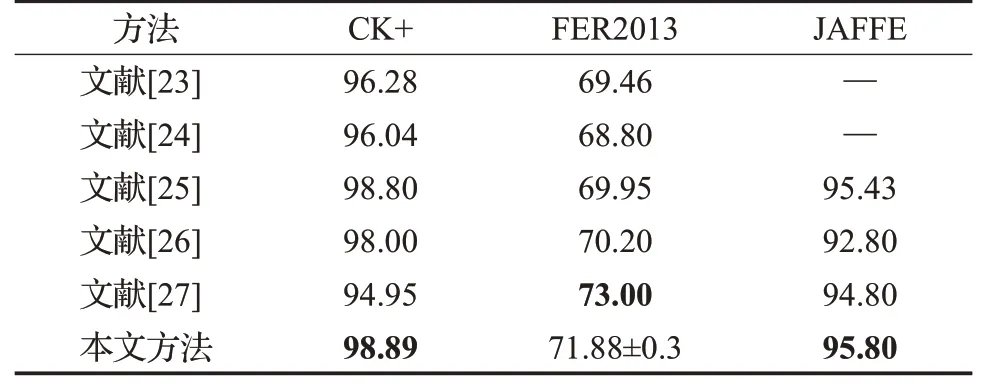
表7 多种算法在人脸表情数据集上的识别率Table 7 Recognition accuracy with different algorithms on several facial expression datasets 单位:%
从表7可以看出,在CK+和JAFFE数据集上,本文方法都得到最优识别率;在FER2013数据集上,本文方法与结合注意力机制的算法[24]和文献[26]对比,分别提升了3.08和1.68个百分点,与文献[27]结果接近,表明本文提出的模型在人脸表情识别上具有较强的竞争力。
4 结束语
本文提出了一种基于支路辅助学习网络的人脸表情识别方法,对主流网络提出优化,改善了原始模型对重要特征信息的利用率,有效提升了原网络对面部表情特征的提取能力及模型泛化能力。实验表明,该方法在多个数据集上均获得了较好的识别结果。
同时,本文所提出的模型架构经过多任务测试,发现同样适用于其他识别任务(例如:手指静脉图像识别问题、皮肤癌图像分类问题等),因此该结构在多种计算机视觉问题中均有一定适用范围。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电机与控制学报(2018年9期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
科技与创新(2017年7期)2017-05-13
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
