
基于多粒度双向注意力机制的词义消歧深度学习方法
2022-12-03 01:56:46初钰凤赵丽华
计算机应用与软件 2022年11期
初钰凤 张 俊 赵丽华
(大连海事大学信息科学与技术学院 辽宁 大连 116026)
0 引 言
词义消歧(Word Sense Disambiguation,WSD)是自然语言处理中的基本任务,也是长期存在的挑战,有着广泛的应用。目前的词义消歧方法主要可以分为基于知识的方法和基于监督的方法。基于知识的方法主要依赖于知识库的结构和内容,例如,词义定义和语义网络,它们提供了两种词义之间的关系和相似性。
基于监督的方法通常根据其使用的特征可分为两类,使用周围单词嵌入、PoS标签嵌入等常规特征的基于特征的监督方法和使用Bi-LSTM等神经网络编码器来提取特征的基于神经网络的监督方法[1]。虽然已有的基于监督的词义消歧方法在大规模训练语料的情况下实现了较好的词义消歧性能,但还是存在一些问题。
首先,基于监督的方法通常对于每个单词训练专门的分类器,这使得很难将其扩展到需要消除文本中所有多义词的全词词义消歧任务,即当文本中存在N个多义词时,需要训练N个分类器[2]。最近的基于神经网络的方法通过为所有多义词构建统一模型来解决此问题[3]。其次,神经网络的方法总是仅考虑歧义词的局部上下文的作用,忽视了WordNet中包含的词义定义等词汇资源。对于词义定义资源,在Lesk算法及其变体中因起到扩充词义含义的作用而得到广泛应用[4]。
此前,基于神经网络的词义消歧方法总是对于上下文语境使用一位有效编码(One-hot encoding)获取词级向量表示或者使用循环神经网络(RNN)获取句子级向量表示,并没有考虑获取字符级的向量作用。在引入词义定义的词汇资源后,总是单独构建上下文语境和词义定义的向量表示,没有很好地构建两者之间的交互作用。在此基础上,本文提出分别整合歧义词上下文语境和词义定义的字符级和词级向量表示,构建句子级上下文向量表示,然后在双向注意力模型中链接和融合上下文语境和词义定义的句子级上下文向量信息。
本文提出采用不同粒度对歧义词上下文语境和词义定义的表示建模;提出运用双向注意力机制整合词义定义的神经网络词义消歧方法,以便更好地构建歧义词语境和词义定义之间的相互表示作用。实验验证模型在SemEval-13:task #12和SemEval-15:task #13的全词词义消歧的数据集上达到很好的消歧效果。
1 相关工作
词义消歧的定义可描述为:假设歧义词w在词典中有N个义项,则将包含w所有词义定义的集合记为S(w)={s1,s2,…,si,…,sN}。设该歧义词w所处的特定上下文语境为C(w)={c1,c2,…,cj,…,cn},其中:n为上下文特征的个数;cj表示某个上下文特征。在词义集合S(w)中有且仅有一个词义si是w在确定的上下文C(w)中表达的真实词义。词义消歧就是从歧义词w的词义集合S(w)中找到真实词义si的工作。词义消歧任务可表达为将上下文语境中的歧义词与预定义的词库中的最合适的条目相关联[5]。根据其特性,词义消歧方法主要可分为两类:基于知识的方法和基于监督的方法。
基于知识的词义消歧方法主要是利用两种多义词的知识。第一种是利用在文献[4]及其变体中的词义定义知识——注释,通过计算歧义词的上下文语境和词库中的词义定义之间的重叠或分布相似性关系。另一种是在文献[6]中广泛运用的基于图的算法,其中:节点是同义词集;边是语义关系——语义网络结构。首先创建输入文本的图表示,然后在给定表示上利用不同的基于图的算法执行词义消歧。基于知识方法的优点是不需要大规模的训练语料,但存在难以适应语言动态变化和缺乏完备性等缺点[5]。
基于监督的词义消歧方法通常将每个歧义词作为单独的分类问题,基于人工标注的特征训练分类器。尽管基于监督的方法能够在准确度上实现较好的性能,但是对于全词的词义消歧而言,在灵活性上比较差。为了解决这个问题,最近的基于神经网络的方法构建统一的分类器,该分类器在所有的多义词之间共享参数[3]。文献[7]利用双向长短时记忆网络,在所有的多义词之间共享参数,通过端到端的训练来充分利用单词顺序。文献[8]将词义消歧问题转化为神经序列标签任务,提出一系列端到端的神经网络,从双向长短时记忆模型到编码解码模型。
对于监督的方法和基于神经网络的方法,很少考虑WordNet等词汇资源。有许多任务显示出整合知识和标签数据到统一的系统中能实现比单独从大量标签数据中学习的方法获得更好的性能,如汉语分词、语言建模和LSTMs任务。文献[2]通过记忆网络将目标词的语境和词义定义整合到一个统一的框架中,分别对目标词的语境和词义定义进行编码,然后在记忆模型中对语境向量和词义定义向量之间的语义关系进行建模。除此之外,还提出利用语义关系扩展词义定义以便更好推导上下文。文献[8]研究表明,WordNet中的粗粒度语义标签可以在多任务学习框架中帮助词义消歧。文献[9]通过使用WordNet中的约束和语义关系将单词嵌入扩展到语义嵌入,当使用语义嵌入作为SVM分类器的词义消歧功能时,它们可将性能提高1%以上。以上列出的所有研究表明,将词汇资源整合到WSD的监督系统中可以显著提高性能。而且,已经有一些研究探索了使用诸如词义定义等知识资源来增强监督词义消歧的方法,并取得了很好的效果。因此,本文遵循这个方向,寻求一种更好地整合词义定义知识资源的词义消歧方法。
此外,之前的基于神经网络的方法通常分别利用One-hot或RNN构建歧义词上下文语境词级和句子级向量表示,并没有考虑利用CNN构建字符级向量表示的作用。文献[10-11]研究表明,在构建文本向量表示时,字符级的局部向量表示对于提高阅读理解能力和问题回答准确性起到重要作用。
本文关注如何构建不同粒度的上下文语境和词义定义的文本表示,通过高速网络(Highway Network[12])将不同粒度的表示级联,并运用双向长短时记忆网络模型(LSTM[13])构建上下文的向量表示。采用在问答等自然语言处理领域取得巨大进展的双向注意力机制,构建上下文语境和词义定义之间的交互作用[14-16]。在双向注意力模型上做了适当的调整,以便更好地获取上下文语境和词义定义之间的内部关系。
2 多粒度双向注意力词义消歧模型
首先定义所提的多粒度双向注意力词义消歧模型的整体概述,模型主要包括5层(如图1所示),然后分别对每一层进行描述。
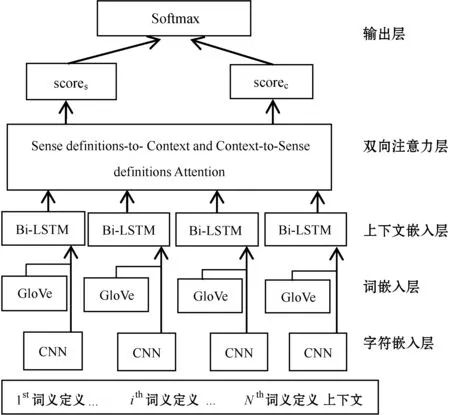
图1 多粒度双向注意力词义消歧模型
2.1 模型综述
模型由字符嵌入层、词嵌入层、上下文嵌入层、双向注意力层和输出层构成。字符嵌入层主要是通过卷积神经网络(CNN),把每个词映射到向量空间;词嵌入层通过预训练的词嵌入模型(GloVe),将每个词映射到向量空间;上下文嵌入层运用双向长短时记忆网络模型(Bi-LSTM)构建上下文向量表示。对于歧义词的上下文语境和词义定义的句子分别运用字符嵌入层、词嵌入层和上下文嵌入层获取向量表示。双向注意力机制层主要是结合歧义词的语境和词义定义,生成对于歧义词语境中每个单词的一组词义定义的向量表示和对于歧义词词义定义中每个单词的一组语境的向量表示,构建两者之间的交互关系。输出层计算歧义词所有词义的分数,并最终输出歧义词的所有词义的概率分布。
2.2 多粒度嵌入
令{c1,c2,…,cn}和{x1,x2,…,xm}分别表示歧义词上下文语境和词义定义中的单词序列,其中,n和m分别表示上下文语境和词义定义序列的最大长度。
(1) 词嵌入层:负责将每个单词映射到高维的向量空间。使用预训练的单词向量模型GloVe来获取每个单词的固定向量,表示成d1维度。对于不在预训练中的单词(Out-Of-Vocabulary,OOV),被映射为
(2) 字符嵌入层:负责将每个单词映射到高维的向量空间。GloVe通过分配一些随机向量值来处理OOV词,而随机分配最终会影响整个模型的效果。所以对于GLoVe中不存在的词,使用一维卷积神经网络(1D-CNN)获得每个单词的字符级嵌入,每个字符都表示成d2维度的可训练向量,维度表示输入通道的大小(卷积滤波器的数量)。按字符滑动扫描单词,经过卷积和最大池化操作,选择每一行的最大值,以获得每个单词的固定大小为d2维的向量表示。
(3) 对于字符嵌入向量和词嵌入向量进行级联,得到维度为d=d1+d2的级联向量表示,然后矩阵被传递到两层的高速网络中,得到两个维度相同的矩阵表示:对于歧义词的上下文语境有C′∈Rd×n,歧义词的词义定义有S′∈Rd×m。上下文嵌入层:单词级的向量表示并没有考虑上下文的含义,所以在前两层提供的级联嵌入向量表示之上,通过双向长短时记忆网络模型级联前向和后向的双向文本状态信息。从而得到歧义词上下文语境表示C∈R2d×n,歧义词的词义定义表示S∈R2d×m。
模型的前三层是从歧义词的上下文语境和词义定义中计算不同粒度级别的向量表示,类似于计算机视觉领域的卷积神经网络的多阶段特征计算。
2.3 双向注意力机制
不同于之前的注意力机制(Attention)表示,采用在自然语言处理问题中,证明能很好地构建不同文本之间的交互表示的双向注意力机制。对于在自然语言处理和计算领域广泛应用的Attention,只是将不同的文本单独构建分布式向量表示,然后计算文本之间的相似性或者相关性,不能充分利用不同文本之间的交互作用。
双向注意力机制层如图2所示。
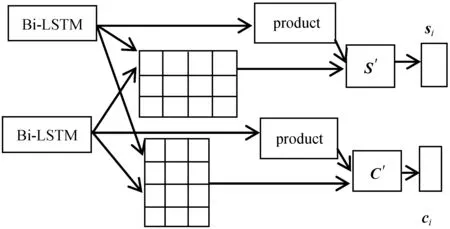
图2 双向注意力机制
输入为上下文嵌入层获得的歧义词上下文语境表示C和词义定义表示S,输出为N对(词义定义的数量)双向注意力表示的歧义词上下文语境和词义定义向量表示。双向注意力机制表示从两个方向上计算注意力,上下文语境到词义定义(Context-to-Sense definition)的注意力向量表示和词义定义到上下文语境(Sense definition-to-Context)的注意力向量表示。
首先,需要计算一个相似性矩阵A∈Rn×m,Aij表示的是上下文语境的第i个词和词义定义的第j个词之间的相似性,相似性的计算公式表示为:
Aij=α(C:i,S:j)∈R
(1)
式中:α表示的是可训练的标量函数,用于编码两个输入向量之间的相似性;C:i表示C的第i列;S:j表示S的第j列。α函数的表达式为:
α(c,s)=(W(A))T[c;s;c∘s]
(2)
式中:W(A)∈R6d,是一个可训练的权重向量;∘表示逐元素相乘(矩阵相乘);[;]表示跨行级联运算。基于相似性矩阵A来获取两个方向上的注意力矩阵,分别为上下文语境到词义定义的注意力矩阵As∈Rm×n和词义定义到上下文语境的注意力矩阵Ac∈Rn×m。
Sense definition-to-Context(S2C)注意力,表示对于歧义词的每个词义定义词而言哪个语境词最相关。由于相似性矩阵A的第j列表示每个语境词和第j个词义定义词之间的相似性,所以可利用跨A列的Softmax函数来获得每个语境词的注意力权重,其计算式为:
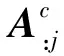
C′:C′=CAc∈R2d×m
(4)
式中:C′的第j列表示根据词义定义的第j列获得的语境表示。最终,通过计算C′列之和求得语境向量,其计算式为:
Context-to-Sense definition(C2S)注意力,表示对于歧义词的每个语境词而言哪个词义定义词最相关。由于相似性矩阵A的第i行表示第i个语境词和每个词义定义词之间的相似性,所以可利用跨A行的Softmax函数来获得每个词义定义词的注意力权重。由于矩阵存在转置特性,A的行等于AT的列,所以其计算式可以表示为:
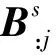
S′:S′=SAs∈R2d×n
(7)
式中:S′的第j列表示根据语境的第j列获得词义定义的表示。最终,通过计算S′列之和求得词义定义向量,其计算式为:
最后,采用余弦相似度来计算歧义词上下文语境和每个词义定义之间交互关系的相似度,其计算式为:
式中:i表示第i个词义定义;ci表示由第i个词义定义获得的词义定义到上下文语境的向量c;si表示由第i个词义定义获得的上下文语境到词义定义的向量。对于歧义词上下文语境的向量表示,采用N个词义定义到上下文语境向量的平均值,其计算式为:
2.4 输出层
输出层主要是计算歧义词w的N个词义定义的分数,并输出N个词义定义的词义概率分布。每个词义的分数是由两个值的权重和求得:scores和scorec。scores表示歧义词的上下文语境和词义定义之间的相似度分数,主要体现在词义消歧中引入词典中词义定义的作用,其计算式为:
scores=[β1,β2,…,βN]
(11)
而scorec表示歧义词的上下文语境向量分数,是通过一个线性映射层计算的,主要体现广泛应用的歧义词上下文语境标签数据的作用,其计算式为:
式中:Ww为权重参数;bw为偏置项。
最终歧义词的所有词义概率分布计算式为:
y′=softmax(λwscores+(1-λw)scorec)
(13)
式中:λw∈[0,1]是歧义词w的参数。
在训练的过程中,所有的模型参数通过最小化y′和真实标签y之间的交叉熵损失联合学习获得。损失函数表示为:
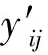
3 实验与结果分析
3.1 数据集
选择SemCor 3.0作为训练集,是通过WordNet词典手工标注的最大的词义消歧语料库。它由352篇文档的226 036个词义标注组成,包含名词、动词、形容词和副词。采用公开评测的英语全词词义消歧数据集(English all-words WSD),把SemEval-07:task #17(SE7)作为验证集,SemEval-13:task #12(SE13)和SemEval-15:task #13(SE15)作为测试集。其中:SemEval-07:task #17仅包含名词和动词,由455个词义标注构成;SemEval-13:task #12仅包含名词,由来自各个领域的13篇文档的1 644个词义标注构成;SemEval-15:task #13包括名词、动词、形容词和副词,由来自三个异构领域的1 022个词义标注构成。表1显示了训练、验证和测试数据集的统计数据。
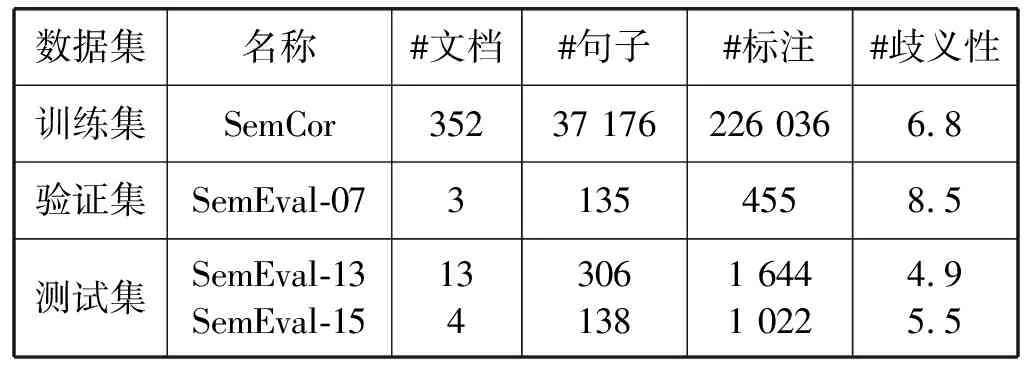
表1 WSD数据集统计
3.2 实验设置
运用验证集SE7来设置模型的最佳参数:词嵌入大小d1、字符嵌入大小d2、LSTM的隐藏层大小n、优化参数和初始化函数等。由于SE7仅存在名词和动词而没有形容词和副词,所以选择从训练数据集中随机抽取一些副词和形容词到SE7中进行验证。使用的卷积输入通道的大小为200,截断或者填充的大小为16,预训练词嵌入的维度为300,并保证这些参数在训练过程中固定大小。隐藏状态大小n是256,最小批量大小设置为32。在训练的过程中,选择Adam优化器,初始学习率为0.001。为了避免过度拟合,在LSTM的输出上使用丢弃正则化(Dropout Regularization),并将丢弃率设置为0.5。正交初始化用于在LSTM中初始化权重,而对于其他操作使用[-0.1,0.1]的随机均匀初始化。如果验证损失在最后5个周期(epochs)内没有改善,则提前停止,训练运行最多进行50个周期。
3.3 结果分析
这一部分首先给出词义消歧的实例结果分析,然后给出不同的词义消歧模型在英语全词任务中的实验结果。
对于本文的词义消歧模型,在SemEval-13:task #12(SE13)和SemEval-15:task #13(SE15)数据集中分别随机选取部分多义词进行准确度判断,统计的结果如表2、表3所示。在表3中的词义定义列中显示的符号表示为名词(n)、动词(v)、形容词(adj)和副词(adv)。
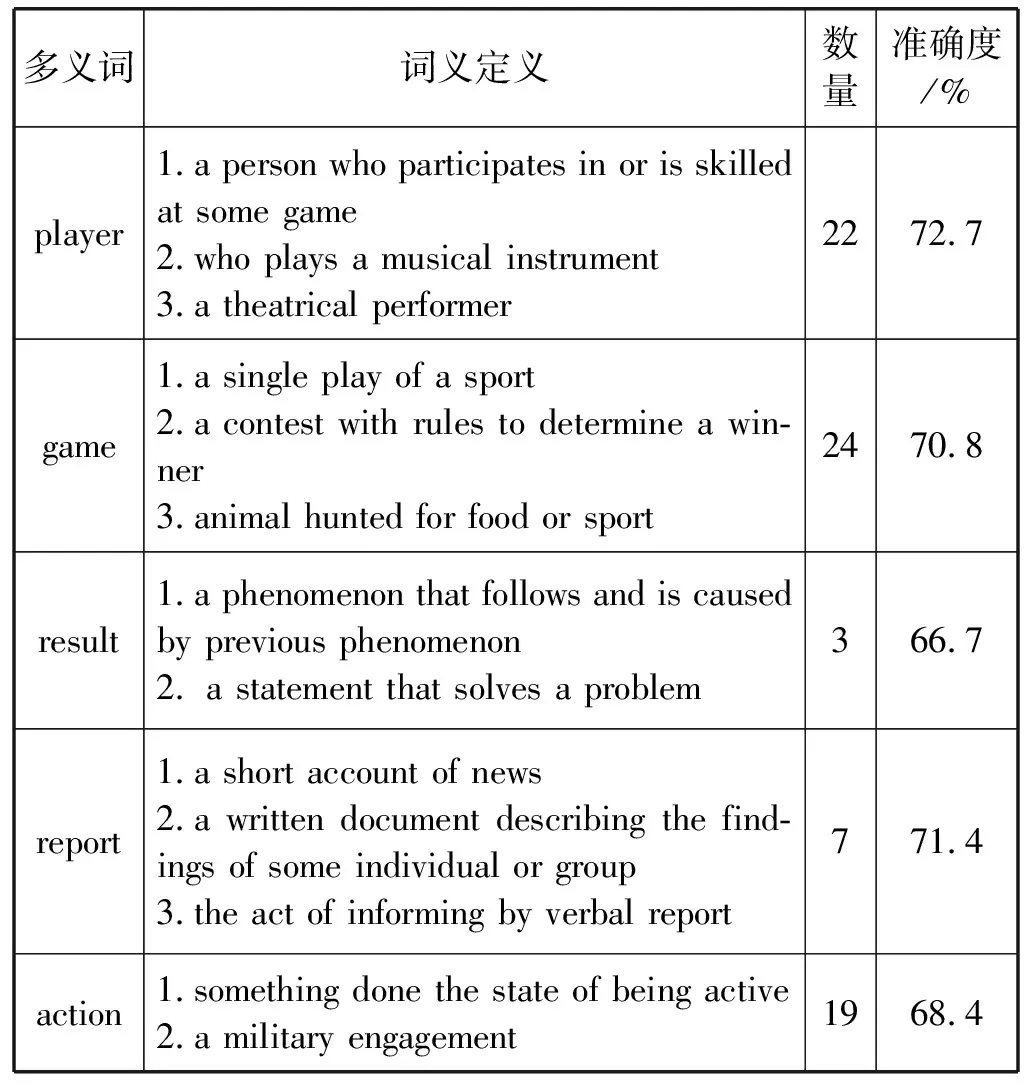
表2 SE13名词词义消歧结果
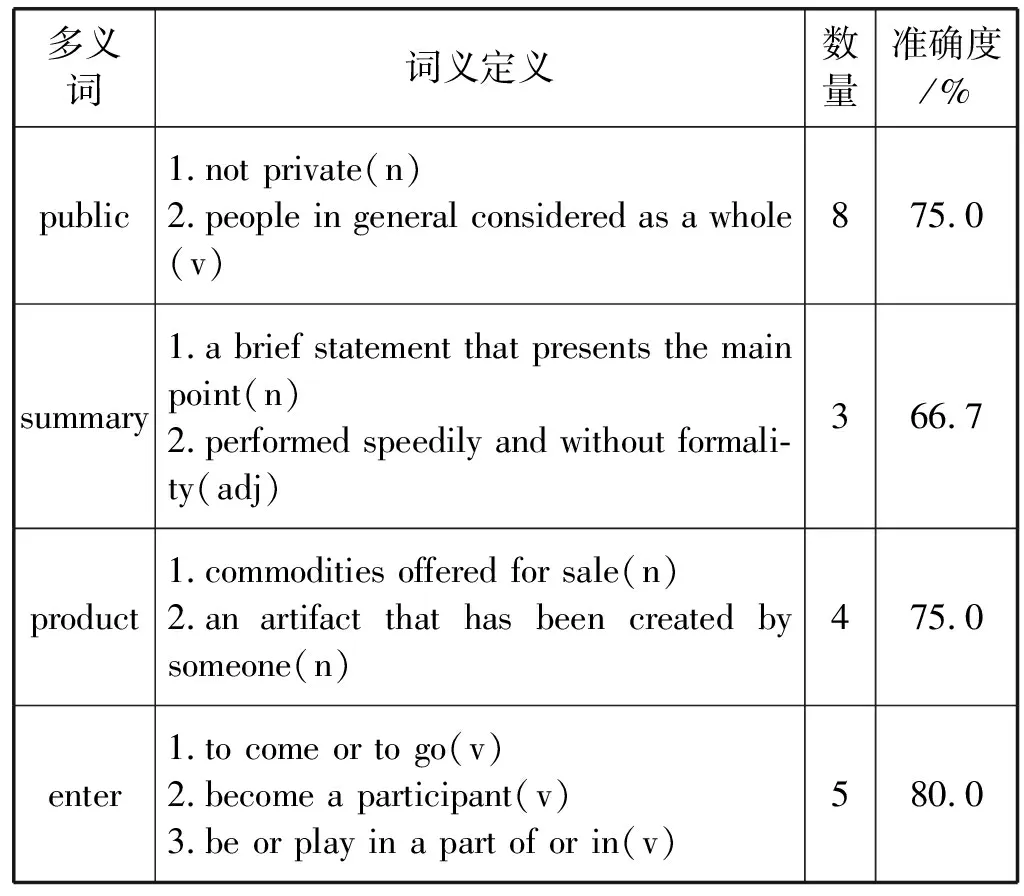
表3 SE15全词词义消歧结果
可以看出,本文所提出的词义消歧模型对于多义词的词义判断有较高的准确度。
对于英语全词词义消歧的方法,主要包括:基准方法、基于知识的方法、基于监督的方法和基于神经网络的方法及整合词义定义等词汇资源的神经网络方法,如表4所示。
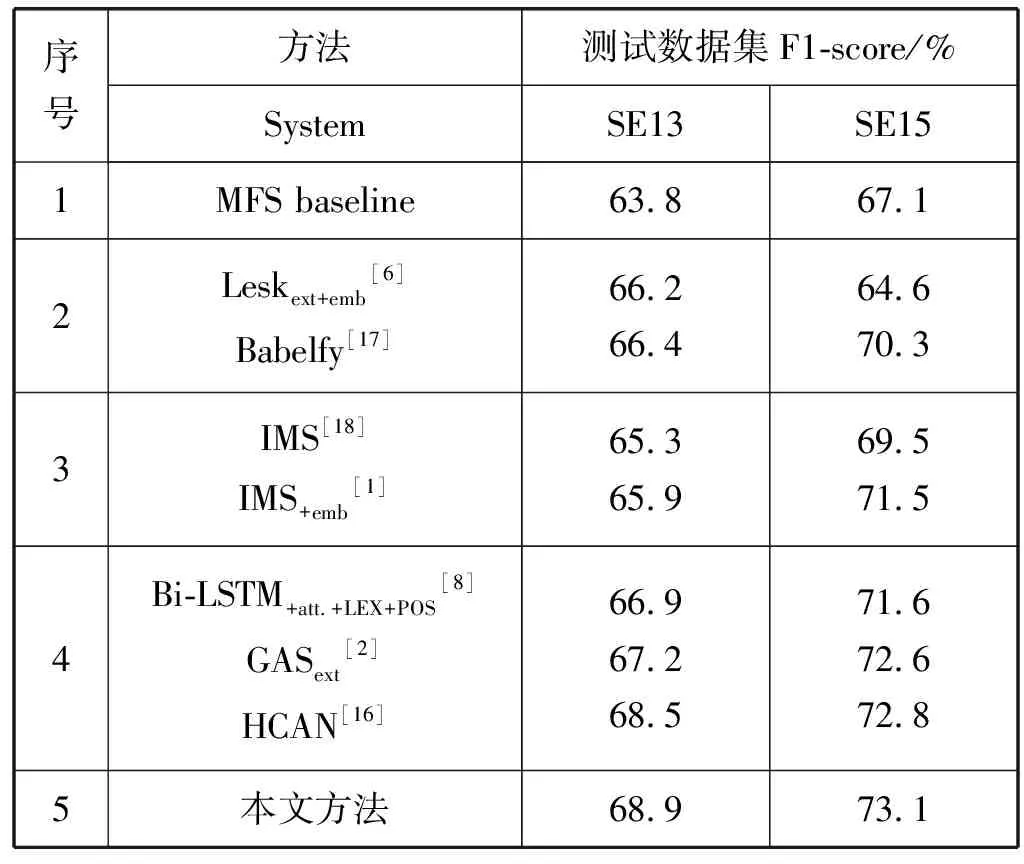
表4 英语全词词义消歧测试结果
表4中,所有的实验都是在SemCor 3.0上训练的。序号1行显示了基准MFS(Most Frequent Sense)的测试集性能,MFS是一种选择训练数据集中的最频繁词义作为歧义词词义的方法。序号2行显示的是两种基于知识的词义消歧方法:Leskext+emb是著名Lesk算法的一种变体,通过计算歧义词的上下文和词义定义之间的覆盖度来计算词义得分;Babelfy是一种基于图的词义消歧方法,利用同义词集中的随机游走来确定相互之间的联系,通过整合WordNet构建的BabelNet语义网络来消除歧义。序号3行展示了两个传统的监督系统,这些系统仅基于手工设计的特征从标记的数据中学习。IMS可以为K个多义词训练K个SVM分类器,默认设置中包含语境、词性、局部词组搭配。其变体IMS+emb将单词嵌入功能添加到IMS中。IMS和IMS+emb是通过为每个目标词构建单独的分类器,即每个目标词都有其自己的参数。因此,对于仅使用标记数据的许多神经网络来说,IMS+emb都是在词义消歧上很难被击败的系统。序号4行主要显示了三个最新的神经网络方法,除了Bi-LSTM之外,其余的方法除了运用标签数据之外,还运用了词典的词汇知识资源。Bi-LSTM+att.+LEX+POS是一种对于词义消歧、词性标注、具有上下文自注意力机制的LEX的多任务学习框架。GAS是注释增强的运用记忆网络模型进行词义消歧的神经方法。HCAN是一种整合注释知识的层级注意力机制词义消歧模型,实验结果表明句子级的信息比词级信息更重要,提升了词义消歧的准确率。
在序号5框中,是本文提出的多粒度双向注意力词义消歧模型的性能,本文模型在SemEval-13和SemEval-15两个公开评测的数据集上将结果分别提高了0.4百分点和0.3百分点。尽管没有采用HCAN模型中的层级架构,但是在多粒度级别上进行整合操作,运用字符级嵌入弥补词嵌入中OOV词向量随机初始化的缺点,以及采用不同的双向注意机制模型建模方法,在数据集中获得更好的性能。
3.4 消融实验
这一部分进一步研究模型中的各个组成部分的重要作用。通过消融某部分组成来训练模型:消融字符级嵌入(No Char)、消融词级嵌入(No Word)、消融语境到词义定义的注意力(No C2S Attention)和消融词义定义到语境的注意力(No S2C Attention)。
对于消融字符级嵌入是只把词级向量输入到双向长短时记忆网络中,通过双向注意力机制模型进行训练;对于消融词级嵌入是只把字符向量输入到双向长短时记忆网络中,通过双向注意力机制模型进行训练;对于消融语境到词义定义的注意力是移除由语境向量生成的注意力,即As的所有元素设置为1;对于消融词义定义到语境的注意力是移除由词义定义向量生成的注意力,即Ac的所有元素设置为1。
消融实验中,没有字符级嵌入和词级嵌入对于SE13分别下降了0.3百分点和1.0百分点,对于SE15分别下降了0.4百分点和0.9百分点,显示出了多粒度级别中,词级嵌入比字符嵌入更重要。没有上下文语境到词义定义的注意力和词义定义到上下文语境的注意力对于SE13分别下降了0.9百分点和0.5百分点,对于SE15分别下降了1.2百分点和0.9百分点,显示了上下文语境到词义定义注意力比词义定义到上下文语境注意力更重要,表明语境已知的词义定义向量更能直接地确定歧义词的正确词义。消融实验的结果如表5所示。
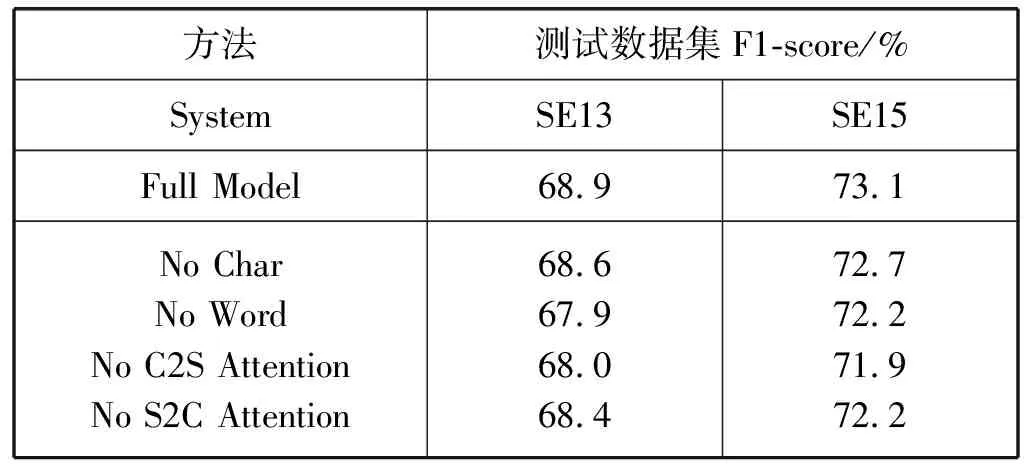
表5 模型的消融实验结果
4 结 语
本文提出一种引入词义定义的基于双向注意力机制的词义消歧方法。该方法不仅利用歧义词上下文语境标签数据的作用,而且充分发挥了词义定义词汇资源的作用。在歧义词上下文语境和词义定义上分别进行字符级、词级、句子级的多粒度向量表示,运用双向注意力机制构建上下文语境到词义定义和词义定义到上下文语境的注意力。实验结果显示,本文方法在两个全词词义消歧数据集上取得了很好的效果。下一步的工作将考虑使用词典中词义的上位词和下位词等词汇资源,以提供更准确的词义表示。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
中国外汇(2019年12期)2019-10-10 07:26:58
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
语言与翻译(2014年3期)2014-07-12 10:31:59
中文信息学报(2012年4期)2012-06-29 06:29:14
