
改进的YOLOv5蛋类缺陷自动检测模型
2022-12-01 12:20姚学峰
食品与机械 2022年11期
姚学峰 李 超
(1. 沈阳职业技术学院,辽宁 沈阳 110045;2. 辽宁科技大学,辽宁 鞍山 114051)
目前,中国蛋类缺陷检测仍以人工为主,成本高、效率低。随着计算机视觉的不断发展,图像检测技术在食品缺陷检测中发展迅速[1]。对利用计算机视觉的核心技术,对蛋类缺陷图像的自动检测方法进行研究具有重要的现实意义[2]。
目前,国内外有关食品缺陷图像检测方法的研究主要集中在支持向量机和卷积神经网络等方面[3-4]。肖旺等[5]提出了一种改进的GoogLeNet用于食品表面缺陷检测,相比传统的缺陷检测方法,该方法具有更高的精度、更好的泛化能力和鲁棒性。杨志锐等[6]提出了一种改进的卷积神经网络用于食品缺陷检测,与传统检测方法相比,该方法具有更好的分类精度(95%以上)。王云鹏等[7]提出了一种通过卷积神经网络AlexNet模型融合可见光和红外图像来检测食品表面缺陷的方法,比传统检测方法检测精度更高,能够满足在线食品分类的需要,检测准确率在95%以上。薛勇等[8]提出了一种用于食品缺陷检测的GoogLeNet深度迁移模型,与传统的检测方法相比,该方法具有更好的泛化能力和鲁棒性,检测精度在92%以上。研究拟将改进的YOLOv5模型应用于蛋类缺陷图像的自动检测中,将轻量级网络MobileNetv3添加到YOLOv5模型中,以降低模型的复杂性,去除颈部网络和输出端小目标检测,从而为图像识别技术的发展提供依据。
1 系统结构
图像缺陷检测是对相机采集的图像进行特征提取,判断目标状态[9]。视觉技术与图像处理技术结合,形成了相对简单、强大的抗干扰能力,适合大规模检测。蛋类缺陷检测系统结构(图1)主要由上位机和图像采集系统两部分组成。

1. 相机 2. 灯箱 3. 样品台 4. 光源 5. 样本 6. 计算机图1 系统结构Figure 1 System structure
2 蛋类缺陷检测模型
2.1 YOLOv5模型
YOLOv5模型是在YOLOv3模型的基础上进行改进的[10],主要包括YOLOv5s、YOLOv5m、YOLOv51和YOLOv5x 4种[11]。YOLOv5模型主要由输入端、骨干网、颈部网络和输出端组成(见图2)。

图2 YOLOv5结构Figure 2 YOLOv5 structure
YOLOv5在输入端使用图像缩放和Mosaic数据增强,在主干网络使用Focus和CSP结构,在输出端使用GIOU_Loss损失函数计算方法。
(1) Focus模块[11]:Focus是YOLOv5中的一个新模块,其结构如图3所示,主要功能是并行分割输入图像,切片通过增加特征图中的通道数来减小图像大小。以一张3通道图像为例,经过切片,可以得到4×3通道的小尺寸特征图,最后叠加成12通道的特征图。与卷积相比,切片的优点是保留了所有原始信息。
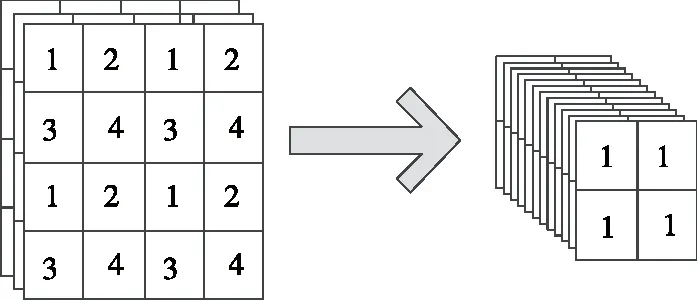
图3 Focus结构Figure 3 Focus structure
(2) CBL模块[12]:该模块由卷积神经网络的卷积层(Conv)、批量标准化层(BN)和激活层(Leaky-Relu)组成(见图4)。
(3) CSP模块[13]:CSP模块由CSP1_x控制和CSP2_x

图4 CBL模块结构
两部分组成(见图5)。CAPNet设计的初衷是减少网络计算量,获得更丰富的梯度组合。在YOLOv4中,CSP应用于骨干网络,而在YOLOv5中,CSP模块仍然保留,扩大了应用范围。YOLOv5除骨干网络外,还在颈部网络中加入了CSP模块。
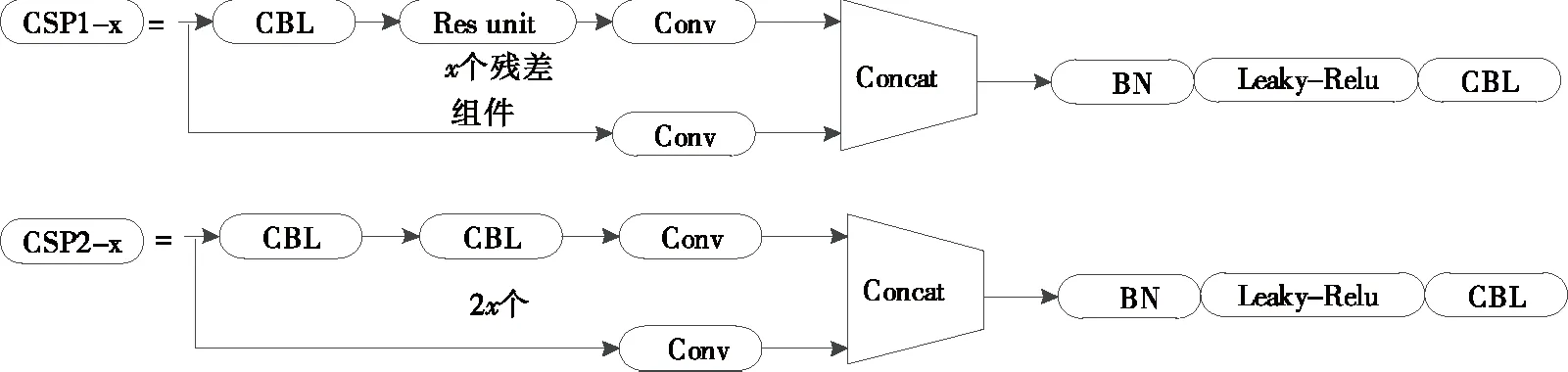
图5 CSP模块结构Figure 5 CSP module structure
(4) SPP模块[14]:SPP位于主干网络的最后一层,可以输出任何大小的特征图。SPP的内部在开始和结束时由两个CBL模块及在中间的3个最大池化通道组成(见图6)。3通道池化层的池化内核大小为5×5,9×9,13×13。

图6 SPP模块结构Figure 6 SPP module structure
2.2 改进的YOLOv5模型
在实际检测环境中,计算资源非常有限,因此为了降低模型的复杂性,需要对网络进行轻量级设计[15]。MobileNet系列是典型的轻量级作品之一[16]。MoblieNet系列网络是由GoogLe提出的一种轻量级卷积神经网络,已发展到MoblieNetv3版本。模型将轻量级网络MobileNetv3引入到YOLOv5结构中,以取代YOLOv 5的骨干网络,并对YOLOv5模型进行优化,实现轻量级设计。为了确保改进后的网络平稳运行,调整了原始网络的输入大小,使MobileNetv3的输出与YOLOv5的输入相匹配。
MobileNetV3综合了3种模型的思想:MobileNetV1的深度可分离卷积、MobileNetV2的具有线性瓶颈的逆残差结构和MnasNet基于SE结构的轻量级注意力模型。将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
深度可分离卷积在模型轻量化中被广泛应用,以输入为a×b×3的图像为例,使用常规卷积运算,其参数量计算为:
N=4×3×3×3×a×b=108ab。
(1)
使用深度可分离卷积运算,其参数量计算为:
N=3×3×3×a×b+1×1×3×4×a×b=39ab。
(2)
MoblieNetv3采用一种新的激活函数:
(3)
为了进一步降低MobileNetV3网络的计算量,对模型进行优化,去掉中间的两层卷积层,同时将最大池化层提到1×1卷积层之前,先对特征图尺寸进行池化降低,再进行升维。
YOLO模型结构设计有3个输出,每个输出都有不同的输出张量大小,分别检测大、中、小尺寸的目标[17]。文中采集的蛋类图像在图像预处理中经过目标提取后设置为640像素×640像素,因为图像已被去除且蛋类面积占图像面积的90%以上。因此,除了使用轻量级MobileNetv3网络替换YOLOv5的骨干网络以进一步压缩模型大小外,还改进了YOLOv 5网络的Neck和Prediction部分,删除了YOLOv5中用于小目标检测的输出层[18],改进后的网络结构如图7所示,其中bneckm_n表示n个m×mbneck模块。
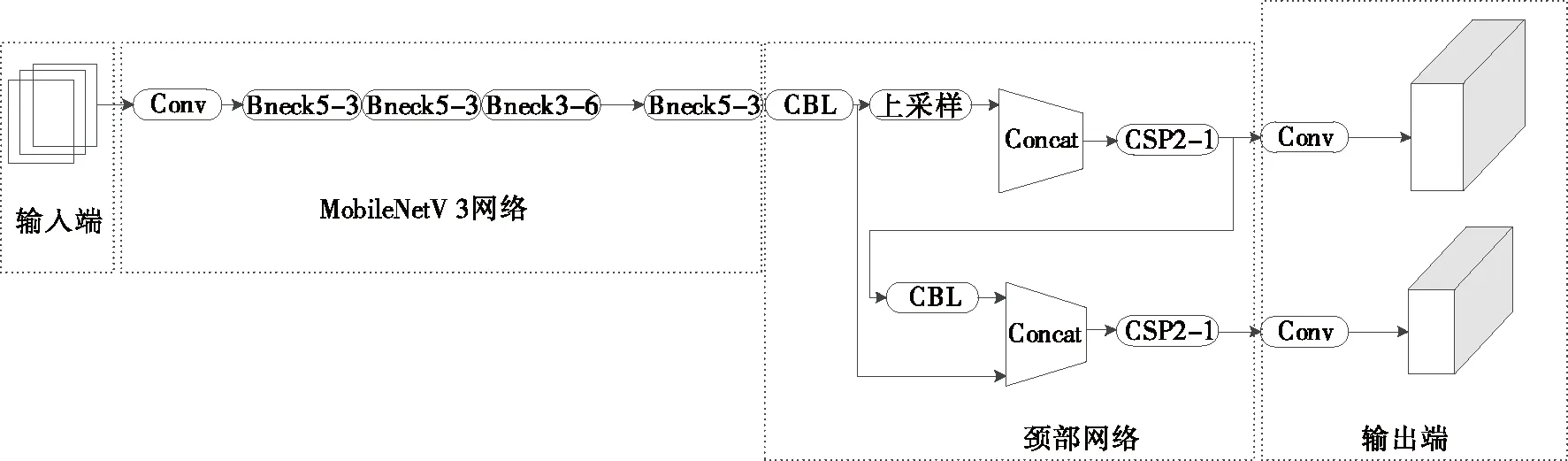
图7 改进的YOLOv5结构Figure 7 Improved YOLOv5 structure
3 试验与结果分析
3.1 试验参数
为了验证所提控制方法的有效性,以蛋类食品为例,针对各种缺陷进行了对比试验。该试验基于Python环境中的Python-深度学习框架[19]。表1为系统参数,表2为试验参数。

表1 系统参数
将原始的1万个图像数据集经图像预处理后合并为640像素×640像素×3像素的图像,并使用LabelImg工具对蛋类食品图像进行标记[20]。训练集和测试集比例为4∶1。其中正常、孔洞、裂纹及脏污蛋各2 500个。
目标检测网络的主要功能是对检测到的目标进行发现和分类。除了用于图像识别的模型精度指标外,模型速度指标也是用于评估目标检测网络性能的一个重要指标类别。文中选择准确率、召回率和平均准确率均值进行评价。

表2 试验参数
(1) 准确率:预测结果中实际包含的阳性样本数,按式(4)计算准确率。
(4)
式中:
P——预测准确率,%;
TP——正确预测数;
FP——错误预测数。
(2) 召回率:按式(5)计算召回率。
(5)
式中:
R——预测召回率,%;
TP——正确预测数;
FN——未预测数。
(3) 平均准确率均值:按式(6)计算平均精度均值。
(6)
式中:
mAP——平均精度均值;
Pi(r)——第i类的平均精度;
N——类别数。
由于模型的速度指标不仅与模型自身的结构和复杂性有关,还与硬件性能有关,因此模型的速度指数与硬件相结合。文中,每秒检测到的图像帧数用于评估模型的速度。
3.2 试验结果
为了验证文中模型的效果,将试验方法与YOLOv5l、YOLOv5m、YOLOv5s和文献[21]进行对比分析。
由表3可知,与YOLOv5系列中最小的模型YOLOv5s相比,试验方法的网络模型参数量降低了2.5 Mb,比文献[21]中的网络模型参数量降低了119.8 Mb。试验方法每秒检测的图像数为70.2,单个图像处理时间为14.24 ms。就检测速度而言,试验方法优于YOLOv5系列中最快的模型YOLOv5s,每秒检测到的图像数量增加了4.3,比文献[21]中每秒检测到的图像多17.2,表明试验模型在缺陷检测速度上具有一定的优势。
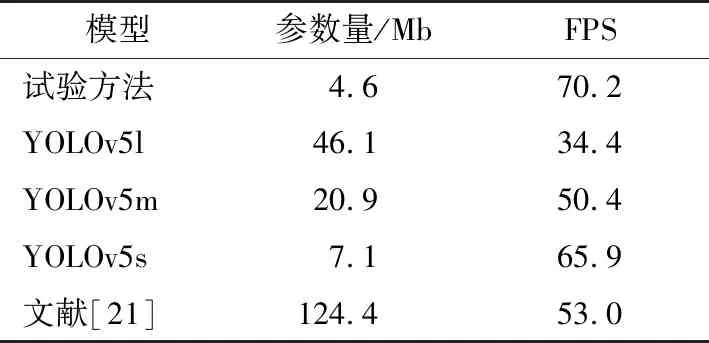
表3 不同模型参数量和检测图像数
由表4可知,试验模型的准确率最高为98.4%,为所有模型中检测精度最高的。在召回率和平均准确率两个评价指标中,YOLOv5s模型表现最好,其次是试验模型和文献[21]。YOLOv5l和YOLOv5m模型的3个评价指标最低,这类模型都是大型检测网络,具有更深的网络层次和相对复杂的结构。试验方法的检测精度较低,可能是由于数据集类型不足和数据集数量有限,导致网络的最终检测效果不佳。文献[21]的方法具有较高的精度,但检测速度最慢。试验模型为了追求轻量化设计而改变了网络结构,并引入了一个轻量化检测网络,使其在检测精度上有一定的损失,与原型网络YOLOv5s相比,网络大小压缩了35%,每秒检测的图像数增加了4.3,且检测精度和检测速度均衡,更符合实际生产线蛋类缺陷检测的硬件要求。
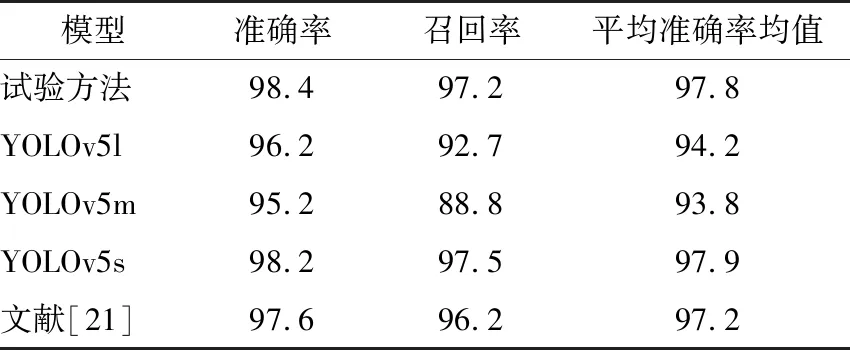
表4 检测结果
由表5可知,在各种蛋类图像缺陷检测中,试验方法的检测精度由高到低依次为孔洞、脏污、正常、裂纹,检测准确率均在97.8%以上。孔洞和正常蛋类的召回率可达100.0%,总召回率为97.2%。综合考虑各类评价指标,试验方法是孔洞特征检测的最佳方法。虽然类别的检测结果存在差异,但总体差异较小,表明试验方法的检测精度较高,综合检测性能稳定,能够适应蛋类缺陷的图像检测。此外,裂纹检测的准确率和召回率较低,可能是因为采集的蛋类图像未被清理,并且覆盖了一些蛋类表面特征,进一步说明了模型的优越性。
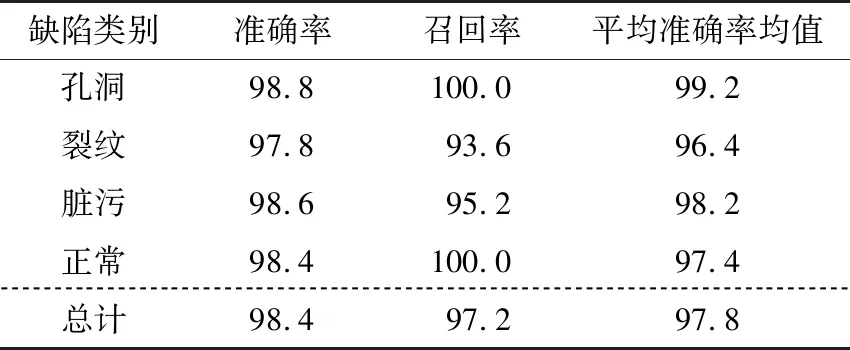
表5 试验方法检测结果
4 结论
研究提出了一种基于改进的YOLOv5模型用于蛋类缺陷图像自动检测,增加了MobileNetv3网络以降低模型的复杂性,并删除了颈部网络和输出端对小目标检测的部分。结果表明,相比于传统方法,试验所提网络模型对蛋类缺陷图像的检测准确率为98.4%,单幅图像检测时间为14.24 ms,在准确率和速度方面优势明显,满足了食品缺陷检测的需要。后续应进一步增加食品的种类并不断完善整个系统。
猜你喜欢
金秋(2022年10期)2022-08-11
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
家禽科学(2020年3期)2020-05-13
电子制作(2019年13期)2020-01-14
现代家长(2019年6期)2019-07-15
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
