
基于改进权重衰减的EfficientNet食用菌图像识别
2022-12-01 12:20姚芷馨张太红赵昀杰
食品与机械 2022年11期
姚芷馨 张太红 赵昀杰
(新疆农业大学计算机与信息工程学院,新疆 乌鲁木齐 830052)
中国是世界上最早进行食用菌栽植的国家之一,拥有丰富的真菌物种资源,目前现已查明的真菌种类达1 500种以上,已知的食用菌有350多种,其中多属担子菌亚门,已人工训化栽培成功的有60多种[1]。但目前食用菌种类识别通常靠人工判断,费时、费力、效率低,而且同一科属性状相似的识别出错率高。
近年来,计算机视觉技术在食用菌上的应用研究越来越多,薛雨[2]利用机器视觉技术,针对食用菌的特征实现精准、稳定的信息采集,通过不同时段的检测数据,对食用菌生产环境进行了精确调节和控制,但只实现了对具有明显形状变化或颜色改变的食用菌进行检测,此方法更适用于实验室环境,对于自然环境中拍摄的食用菌有较大误差;为快速有效地识别野生食用菌,林楠等[3]基于图像处理方法和机器视觉技术,提出了一种改进的颜色空间融合形态特征提取方法。
研究拟提出一种基于卷积神经网络的Y-Weight训练方法,通过控制有效学习率和权重范数来影响模型的泛化性能,以期为常规大型蔬菜市场和大型超市识别菌种提供帮助,减少人工识别的时间成本,提高工作效率,降低劳动强度。
1 材料与方法
1.1 数据来源及范围
通过在公共数据集Fungus[4]上以及自建数据集YMushroom上进行训练。其中,由于Fungus数据集类别多样,背景较为复杂,有各种各样的背景造成干扰,因此选用不同科属的12类具有明显特征且图片数量较多较均匀的食用菌进行测试,共计1 093张图片。其分布情况及部分示例如图1所示。
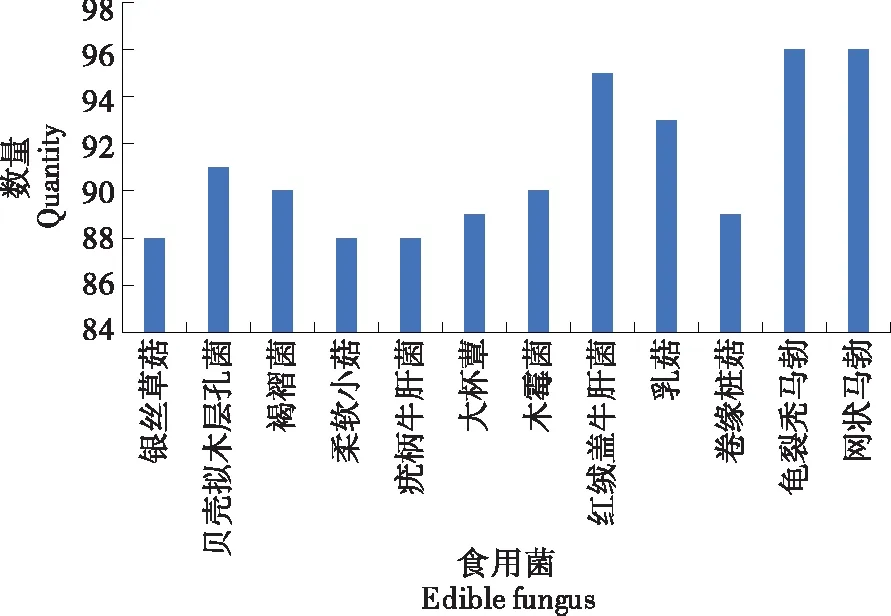
图1 Fungus(12)数据集分布Figure 1 Fungus (12) dataset distribution
自建数据集YMushroom是通过在常规蔬菜市场及大中型超市中调研,根据2020—2026年中国食用菌行业市场行情监测及发展前景展望报告[5]中提供的市场销售额、整体价格和机器手持采摘的成本等数据,挑选出最具经济价值的28种常见食用菌类(香菇、双孢蘑菇、糙皮侧耳、金针菇、黑木耳、银耳、猴头菇、毛头鬼伞、姬松茸、茶薪菇、真姬菇、灰树花、滑菇、刺芹侧耳、盖襄侧耳、毛木耳、竹荪、金顶侧耳、大杯蕈、北冬虫夏草、牛肝菌、松茸、鸡枞、羊肚菌、榛蘑、鸡油菌、红菇、青冈菌)。
由于菌类生长时间与生长环境不同,需在不同时间段进行采集。采集时间从2019年10月—2021年3月。采集设备分别采用两种不同图像处理方式的智能手机OPPO Find X2和HUAWEI荣耀Play4T,使用原相机设置为方形拍摄。参考Fungus数据集制定严格的采集标准(尺寸、图像背景、干湿比例、光照强度、不同成熟度等)。其中新鲜食用菌与干货食用菌保持1∶1的采集比例,每个种类的数据集数量基本保持均衡,并且保证了个体种类具有多样性。因为采集的样本越多,模型的训练精度就越高,所以28种常见食用菌平均每种采集了大约1 784张图片,共计49 958张图片。为提高模型运行速度,将采集后的数据集经过图像处理统一压缩为600像素×600像素大小,以此建立一个符合食用菌分类的大型数据集。将数据集按照常规训练进行划分,按照8∶1∶1的比例将其中80%的样本(约39 966幅图像)用作训练集,将10%的样本(约4 996幅图像)用作验证集,将剩余10%的样本(约4 996幅图像)用作测试集。之后为投入训练,需要将样本图像文件和对应的标签文件转换成HDF5格式文件(train.hdf5、val.hdf5、test.hdf5),保存在固定文件夹中,以便随时调用。自建数据集YMushroom分布情况及部分示例如图2所示。
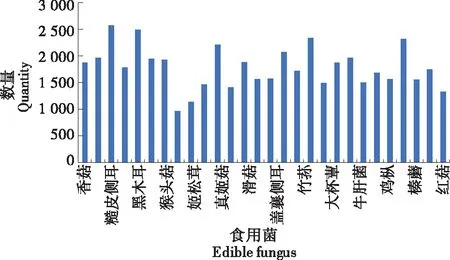
图2 YMushroom数据集分布Figure 2 YMushroom dataset distribution
1.2 研究方法
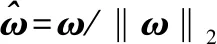
(1)
(2)
当模型缩放尺度保持不变时,权重向量的关键特征就只需要考虑其方向性。当权重随着step为t、learning rate为η的随机梯度下降进行更新时,下一次step的通道权重向量即为:
ωt+1=ωt-η∇Lt(ωt)。
(3)
权重向量在方向上的step大小按比例变化,如式(4)所示。
(4)
因此,当对所有层使用权重衰减然后进行归一化时,可以防止权重范数的无限增长,从而维持权重方向的步长保持不变,以此提高有效学习率。
1.2.2 权重范数 根据式(1)~式(4)可以看出,卷积层的权重衰减主要是通过约束权重向量范数来完成的。为了研究在训练期间权重向量范数的变化,不考虑卷积层的权重衰减,在ImageNet[6]上使用EfficientNet-B0进行训练(100轮),在卷积层中将权重范数固定为一个常数λ=0.000 1,而在权重衰减中并不使用定权范数,两者的最佳学习率选择也有所不同,通过使用网格搜索(grid search)[7]来确定学习率保证最佳性能。如图3所示,两者达到了同样的top-1精度,这些结果表明批归一化后的卷积层可以忽略权重衰减的影响。
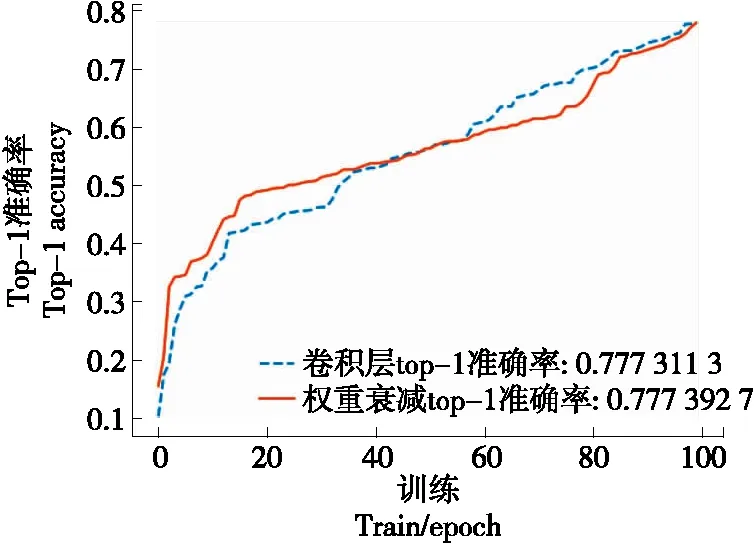
图3 Conv layers和Weight decay通过网格搜索后的top-1精度Figure 3 Top-1 accuracy of Conv layers and Weight decay after grid search
调整卷积层的权重范数是通过YWeight方法定义初始化速率为0,用V0表示。总的训练步数用t表示,初始值为0。用x表示训练样本,用y表示对应的标签,动量momentum用μ表示,τ表示交叉熵损失函数。则训练速率计算公式如式(5)所示。
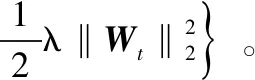
(5)
定义一个随机的初始化权重向量W0,初始学习率用c表示,则有:
Wt+1=Wt-lr×ηt×Vt+1。
(6)
下一次的卷积层权重调整公式为:
(7)
1.2.3 全连接层 为研究权重衰减在全连接层中的作用,需要对上述卷积层权重衰减方法进行改进,首先保持其具有尺度不变性,使用普通的应用权重归一化的全连接层来代替原先的全连接层,其次设置λ原先的0.000 1变为0,最后使用WConv+FC来代替原先的WConv,如式(8)所示。
(8)
原先的全连接层与替换后维持尺度不变性的全连接层进行对比,结构如式(9)、式(10)所示。
FC(x;WFC)=xΤWFC,
(9)
(10)
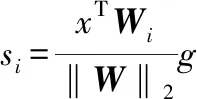
(11)
(12)
在特征空间中,权重向量W的梯度为x,Wj表示其他类别向量,Wk表示标签类向量,方向从Wj到Wk,其偏角大小由pj和g决定,并且pj也通过softmax函数依赖于g。当x是正确的分类时,g会持续增长,pj会迅速减小并且梯度减弱。x更容易偏向于Wj和Wk之间的class boundary,这种不明确的特征空间容易在训练和测试之间发生偏移,导致泛化性不好。特征空间中训练和测试的偏移如图4所示。
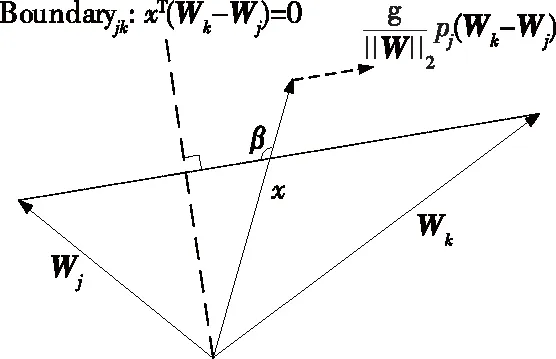
图4 特征空间中训练和测试的偏移Figure 4 Offset of training and testing in feature space
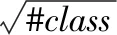
(13)
使用限制了权值大小的YFC层代替NFC层,不改变其他超参数,通过权值选择α的大小。总体来说,权重衰减通过约束全连接层的权重范数来影响cross-boundary risk,最终影响模型的泛化性能。通过使用YFC层可以恢复常规权重衰减的训练的准确率。
1.2.4 训练时learning rate和α的调整 在1.2.2和1.2.3中介绍了两种权重衰减的机制:① 讨论有效学习率对除卷积层以外的归一化之后的层的影响;② 对于全连接层FC,控制cross-boundary的影响。YFC将这两种机制结合起来,通过控制超参数lr和α直接控制其效果,使用grid search网格搜索来确定不同lr和α对top-1的影响,通过穷举[10]的方式针对每种可能的参数组合情况进行训练,并对模型进行评价,根据其评价结果将寻找到的top-1最大值时的参数取值情况进行保存,视为最优。
1.3 系统框架
1.3.1 MobileNetV2 MobileNet[11]网络结构是一种小巧而高效的CNN模型,不仅在准确率和运行速率之间做了折中,还采用了深度可分离卷积模块[12-13],并设置了两个超参数(宽度乘法器和分辨率乘法器),通过调整两个超参数来满足应用需求。在ImageNet数据集上,MobileNet与VGG16的准确率几乎一样,但参数量只有其1/32,计算量只有其1/27。MobileNetV2引入了Bottleneck结构,将其设计成纺锤型,先放大到原来的6倍,最后再缩小,形成倒残差模块(Inverted Residual Block)。网络主体结构如表1所示。
1.3.2 EfficientNet-B0 EfficientNet[14-15]的主干网络延续使用了MobileNetV2网络中的MBConv模块,使用SENet中的压缩激励模块(squeeze and excitation)优化网络结构。其中运用到模型尺度化方法,在原始模型基础上将通道数扩大,加深模型深度[16-17],之后扩大输入图像分辨率,再放大基于通道数、深度、输入图像的组合尺度。EfficientNet模型尺度化方法如图5所示。

表1 MobileNet主体结构
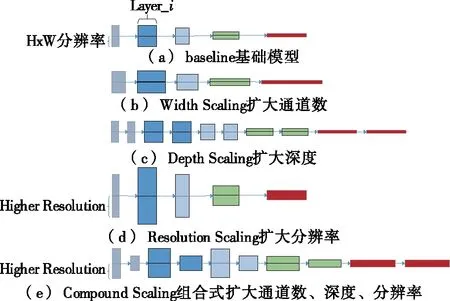
图5 EfficientNet模型尺度化方法Figure 5 Scaling method of EfficientNet model
模型尺度化方法首先执行网格搜索,然后找到在固定资源约束下基线网络(baseline)的不同缩放维度之间的关系[18]。其次找到每个维度适当的比例系数,最后应用这些系数扩大基线网络,使模型达到预期的大小或资源要求。与传统缩放方法相比,这种模型尺度化方法能够提高模型的精度和运行效率。
2 结果与分析
2.1 试验环境
硬件环境:NVIDIA Tesla P100-PCIE;显存16 GB;显存位宽4 096 bit;CUDA版本11.0。
软件环境:Windows10操作系统;Python版本为3.6.13;Tensorflow版本为2.0;Keras版本为2.3.1。
2.2 训练方法
通过使用YWeight方法,在公共数据集Fungus和自建分类数据集YMushroom上进行试验。训练时使用Stochastic Gradient Descent(SGD)随机梯度下降算法[19],保证不会陷入original-loss的奇点和minibatch-loss的奇点,decay设置为1E-006,momentum为0.9。使用一个周期的余弦退火策略(Cosine Annealing),使学习率按照周期变化。由于学习率是神经网络训练中最重要的超参数之一,刚开始训练模型初始化权重是随机的,若选择了一个较大的学习率可能会导致模型震荡,因此前4轮选用线性预热(linear warmup)来进行学习率的优化,在预热的小学习率下使模型慢慢趋于稳定。除此之外,还使用了标签平滑(label smoothing)为0.1的正则化策略,通过soft one-hot来加入噪声,防止过拟合现象,减少真实样本标签的类别在计算损失函数时的权重。
2.3 性能评估指标
评价模型的性能通常使用准确率(Accuracy,A)、精度(Precision,P)、召回率(Recall,R)和F值(F-Score,F)等指标来进行衡量,通常被用在二分类测试中。
准确率被用来统计模型正确识别的量度,是正确预测(真阳性和真阴性)的个数占样本总数的比例,也被称作“兰德精度”,其计算方法如式(14)所示。
(14)
式中:
TP——将正类预测为正类的样本数,即真阳性;
TN——将负类预测为负类的样本数,即真阴性;
FP——将负类预测为正类的样本数,即假阳性;
FN——将正类预测为负类的样本数,即假阴性。
精度用来计算与真实值的接近程度,即对正类预测的准确性。其计算方法如式(15)所示。
(15)
召回率也被称为灵敏度,为真阳性的数量占总体正类的比例。其计算方法如式(16)所示。
(16)
F值是综合精度和召回率的一个判断指标,是精度和召回率的调和平均值。其计算方法如公式(17)所示。
(17)
(18)
(19)
(20)
2.4 YWeight方法与贝叶斯优化对比分析
为证明YWeight方法的有效性,使用YWeight权重衰减和贝叶斯优化(Bayesian Optimization,BO)两种方法,在CIFAR-10数据集上使用ResNet50[20]网络和MobileNetV2网络进行对比试验,结果见表2。将ResNet50训练120轮,MobileNet训练150轮,原始模型训练的top-1 精度为92.3%和91.41%,使用贝叶斯优化进行调参后训练的top-1精度为92.37%和91.53%,使用YWeight方法训练后的top-1精度为92.41%和91.58%。

表2 YWeight与BO试验结果
2.5 数据集试验结果分析
使用MobileNetV2和EfficientNet-B0两种模型结构进行对比试验,分别在公共数据集Fungus和自建数据集YMushroom上进行训练。选取这两种网络结构进行研究,是因为在ImageNet上,MobileNet在参数量是VGG16的1/32,计算量是VGG16的1/27的情况下,与VGG16几乎达到了相同的精度。而选取EfficientNet网络是因为其延续了MobileNetV2中的MBConv模块作为模型的主干网络,同时还使用SENet中的squeeze and excitation方法对网络结构进行了优化,在8个广泛使用的数据集中都达到过比较先进的精度。
通过在Fungus数据集上对比试验,发现将MobileNet与EfficientNet两种网络结构通过YWeight方法控制学习率和权重范数后,对准确率有一定的提升。使用YWeight方法在MobileNetV2网络上进行训练的模型命名为YWeight-MobV2,在EfficientNet-B0网络上进行训练的模型命名为YWeight-EffB0。
通过表3可以看出,当lr为0.2,α为4.0E-005时,MobileNetV2的准确率为82.71%,宏F值为81.47%;当使用YWeight方法控制lr为0.4,α为8.0时,YWeight-MobV2的准确率为83.59%,宏F值为82.34%。当lr为0.35,α为4.0时,EfficientNet-B0的准确率为86.84%,宏F值为85.61%;当使用YWeight方法控制lr为0.5,α为8.0时,YWeight-EffB0的准确率为87.62%,宏F值为86.29%。由此看出,对于样本数量较少的Fungus数据集,在训练次数相同的情况下,通过YWeight方法控制不同的学习率以及权重范数,使MobileNetV2相比于原有模型识别准确率提高了0.88%,宏F值提高了0.87%,使EfficientNet-B0识别准确率提高了0.78%,宏F值提高了0.68%。可以看出,MobileNetV2网络在使用YWeight方法后,展现了更大的进步性,top-1准确率和宏F值比EfficientNet-B0得到了更大的提升。EfficientNet-B0网络相比于MobileNetV2网络来说其参数较多,模型层数更深,运行速度相对较慢,但top-1精度和宏F值相对较高。为更清晰直观地了解训练中模型拟合的速度和收敛速度,截取在验证集上损失函数值的变化图像进行对比分析,如图6所示。

表3 Fungus数据集上识别结果
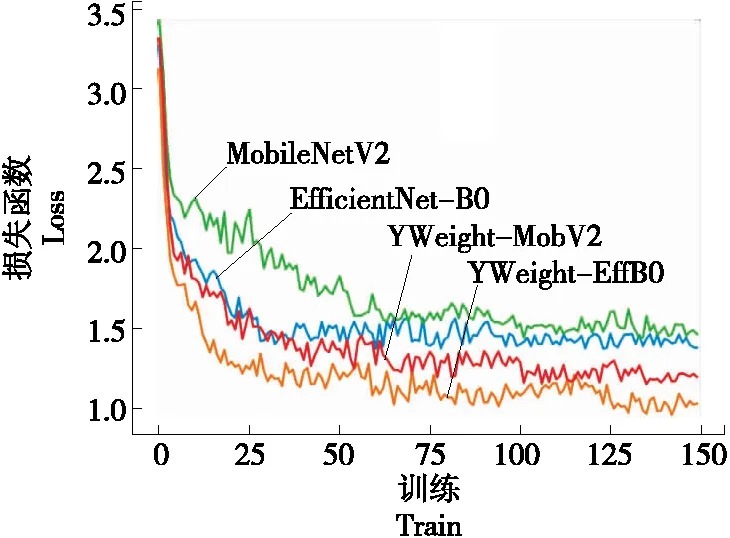
图6 Fungus验证集上各模型损失函数的变化曲线Figure 6 Variation curve of loss function of each model on Fungus verification set
在YMushroom数据集上进行对比试验,使用YWeight方法在MobileNetV2网络上进行训练的模型命名为YWeight-MobV2,在EfficientNet-B0网络上进行训练的模型命名为YWeight-EffB0。
通过表4可以看出,当lr为0.3,α为4.0时,MobileNetV2的准确率为75.48%,宏F值为74.24%;当使用YWeight方法控制lr为0.4,α为8.0时,YWeight-MobV2的准确率为76.35%,宏F值为74.61%。当lr为0.3,α为8.0时,EfficientNet-B0的准确率为78.97%,宏F值为77.74%;当使用YWeight方法控制lr为0.4,α为16.0时,YWeight-EffB0的准确率为79.82%,宏F值为78.49%。由此看出,对于比较大型的YMushroom数据集,相比于原有模型,在训练次数相同的情况下,通过YWeight方法控制不同的学习率以及权重范数,使MobileNetV2识别准确率提高了0.87%,宏F值提高了0.37%,使EfficientNet-B0识别准确率提高了0.85%,宏F值提高了0.75%。可以看出,使用YWeight方法后EfficientNet-B0在top-1准确率和宏F值的提升上更具进步性,MobileNetV2的宏F值仅提升了0.37%,而EfficientNet-B0的宏F值提升了0.75%。因此,基于试验要求更高的精度,更适合选取EfficientNet网络作为食用菌分类模型的主干网络。4个模型在YMushroom验证集上的损失函数变化图像如图7所示。

表4 YMushroom数据集上识别结果
对比表3和表4、图6和图7发现,对于小型数据集Fungus,仅需150轮就能够收敛,训练速度较快,但是对于大型数据集YMushroom则需要250轮才逐渐收敛,达到极值。证明不同的模型拥有不同的最优lr,训练模型在相同的设置下也会有不同的训练结果,需要通过YWeight方法找到最优的lr和α来提高模型性能。
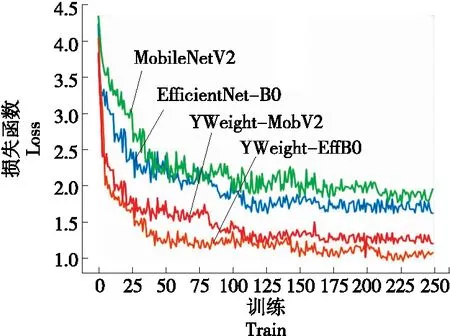
图7 YMushroom验证集上各模型损失函数的变化曲线Figure 7 Variation curve of loss function of each model on YMushroom verification set
3 讨论
(1) 目前中国较先进的菌菇研究方法大多是使用传统的机器学习方法或者是层数较少的浅层神经网络来进行图像识别,例如VGG16、AlexNet等。文中使用的MobileNet以及EfficientNet均为较深层的卷积神经网络,在模型准确率与运行速率上都有很大的提升。
(2) 目前针对食用菌图像分类的研究分类种数不超过20种,且大部分都是基于公共数据集来进行网络训练的,而试验对28种最常见的食用菌种类进行了研究,通过1年的时间,进行了不同环境、不同时间、不同拍摄设备的食用菌图像采集,构建了HDF5格式的大型食用菌数据集,共49 958张图片,能够使模型更好的训练。
(3) 大部分食用菌识别用到的网络都是通过迁移学习来完成的,通过修改模型参数来达到更高的准确率,而试验创新使用了一种权重衰减方法,在两种网络结构上试验过后发现均适用,并且比原始的模型提高了准确率和运行效率。
4 结论
采用基于卷积神经网络的EfficientNet和MobileNet两种网络结构,作为YWeight训练方法的食用菌图像分类模型,在两个数据集上进行试验,对模型识别性能进行对比分析,结果表明:
(1) 基于权重衰减策略,提出的训练方法YWeight方法,通过一种高效的、鲁棒性的方法选择超参数,通过约束全连接层的权重范数来影响cross-boundary,最终影响模型的泛化性能。试验证明通过调整超参数使模型在试验中找到了接近最优的解,在公开数据集Fungus和自建数据集YMushroom中都展现了非常高效的模型准确率,为食用菌自动识别提供了便利。
(2) 研究中发现权重衰减对最后的全连接层具有影响,发现了一种新的机制来补充权重衰减对模型泛化性能的影响,YWeight方法是简单高效的,并且在大规模数据集上证明了其性能。
(3) 从检测速度上看,基于YWeight方法的食用菌图像分类模型能够满足常规蔬菜市场以及大型超市的实时识别要求。
(4) 由于数据集非常庞大,像素比较高,EfficientNet模型实时识别计算量较大,对设备要求比较高,今后可以尝试其他更轻便高效的网络进行训练,进一步提高食用菌识别性能。
(5) 试验训练时使用的是SGD优化器,可以在每次迭代中使用一个样本来更新参数,能够提高在自建的大型数据集YMushroom上的训练速度。但是有可能达到局部最优,在目标函数为强凸函数时,SGD可能无法做到线性收敛,准确率也会下降。因此,后续将继续讨论权重衰减在Momentum优化器、Adam优化器上应用的优点以及可能存在的问题,并研究学习率、权重衰减和动量之间的联系。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2020年23期)2020-12-31
今日农业(2020年22期)2020-12-25
安阳工学院学报(2020年4期)2020-09-11
今日农业(2020年24期)2020-03-17
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国校外教育(下旬)(2017年8期)2017-10-30
东北师大学报(自然科学版)(2014年1期)2014-02-27
