
基于多源异构数据融合的电力工程知识图谱架构算法
2022-12-01 06:00赵军董勤伟戴威
电子设计工程 2022年23期
赵军,董勤伟,吴 俊,戴威
(国网江苏省电力有限公司,江苏 南京 210000)
随着我国经济的发展,配电网络的配置和规模受用电需求的增长而不断发生改变,如何对配电网络进行科学的管理、及时发现潜在故障的诱因、快速确定故障的类型与解决方案成为了业界关注的焦点[1-3]。为了保障供电安全,较多先进的监测设备和管理措施被应用在现代电力系统中,尤其是数据中台的建设促使电力行业数据实现了逻辑集中,使得各类电力系统所产生的数据得以有效采集、存储、处理和分析[4-8]。除了上述数据外,来自互联网等其他领域的公开数据逐渐被应用在电网安全风险评估、安全维护等应用领域[9]。
随着数据来源的增多,海量、异构数据的高效处理成为制约电力行业数字化发展的瓶颈。如何进行电力行业内部数据与外部数据的有效融合,成为相关学者的研究课题之一[10-11]。目前为止,网络本体语言、资源描述框架被提出用来进行异构数据的表示,并取得了一定的进展。2012 年,知识图谱由谷歌公司提出,因其严谨、强大的数据表示能力以及完善的各类配套工具,成为多源数据融合的重要方法之一[12-16]。
针对以上问题,该文开展了电力工程知识图谱架构算法研究。通过构建电力工程知识图谱将电力行业与外部数据进行系统性整理,同时理清相关专业概念,便于相关从业者查询;针对多源、异构数据,采用CRF 算法把非结构化文本信息通过分词以及提取词向量的手段转化为结构化信息;最终将典型相关分析(CCA)和深度神经网络相结合,通过逐层语义匹配,构建出深度语义匹配模型。
1 算法框架
电力工程知识图谱的构建目的在于对电力系统中的各项数据进行系统性地整理、分析,从而发现电力系统管理中的不足和潜在故障诱因,提高电网管理和应急保障能力。知识图谱是一种由节点和边线构成的图数据结构,每一个节点代表电力系统中一类信息来源,通过连线的方式表征来自不同信息源数据之间的逻辑关系,进而得到实体关系网络。而多源异构数据的融合,有效提升了电力数据的数据挖掘能力,进而提高预测电力故障的精度。通过基于多源异构数据融合的电力工程知识图谱架构算法,可以有效提高电力系统管理的综合能力。
基于多源异构数据融合的电力工程知识图谱架构算法主要分为两个部分,如图1 所示。第一个部分为知识图谱构建,首先整理相关领域的专业术语,并将其转化为知识图谱的节点,再以各专业概念之间的逻辑关系为各节点的连线;第二个部分为非结构化的概念和信息的结构化转换与数据融合。
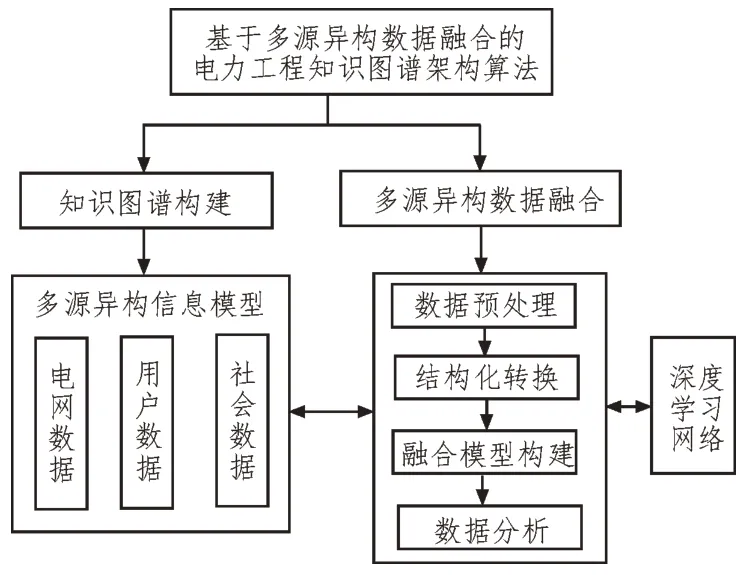
图1 电力工程知识图谱架构算法的总体框架
2 电力工程知识图谱架构算法
2.1 电力系统多源异构信息模型构建
伴随着国家电网建设规模的增大,电网数据呈现大幅增长的趋势,且数据类型繁多,具体表现为:不同的采集周期所呈现出来的数据信息略有不同;电网数据地域化特征明显,由于不同地区所开展业务的情况不同,相关数据考核指标也略有不同;配电站、输电网络等内部数据,以及来自互联网等外部数据促使电网数据来源广泛。
为了改善传统数据存储、分析技术的不足,构建了电力系统多源异构数据信息模型,将电力数据划分为三个类别:电网数据、用户数据和社会数据。电网数据覆盖了电能的产生、传输、故障检修和质量评估,涉及到电力生产系统、供电电压自动采集系统、故障抢修管理系统以及数据采集控制系统等;用户数据主要是指采集系统数据、充电桩数据、CMS 系统数据等;社会数据主要是指公共服务系统数据、气象系统数据和地理系统数据,具体如表1 所示。

表1 电力系统数据分类表
为了降低文本等非结构化数据转化成结构化数据的难度,电力系统多源异构数据信息模型在进行数据采集和输出时,应具有统一的格式。该文将电力系统多源异构数据信息模型的数据物理结构设计成三级形式:表头、索引和存储,如图2 所示。
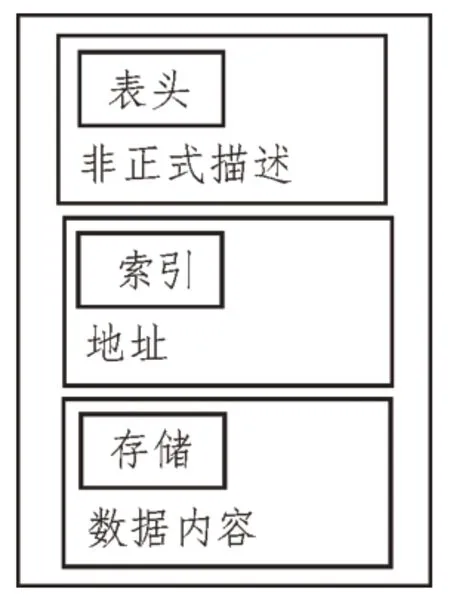
图2 多源异构数据信息模型的数据物理结构
无论是电网数据、用户数据还是社会数据,均存在大量的文本信息。文本信息与数字信息不同,属于非结构化信息,并不能直接进行特征提取;且由于文本信息通常是连续的文本序列,并掺杂着大量、无实际意义的语气词,因此需要进行中文分词。该文采用CRF 算法,利用事先标记好的样本数据进行模型训练,进而将概率最大的词作为分词结果输出。
2.2 电力系统异构数据融合
由于电力系统中某些模态的数据实例数目较少,造成了特征提取不准确的现象,该文采用迁移学习来解决数据实例较少的域的特征学习。其具体过程为:将典型相关分析(CCA)和深度神经网络相结合,通过分词后的多源异构模态数据的逐层语义匹配,构建满足域私有网络和域共有网络的深度语义匹配模型。
深度神经网络通常包含:输入层、隐藏层和输出层,这些层也包含了多种分支。该文使用深度置信网络作为多源异构数据融合算法的基本模型,其由多个受限玻尔兹曼机组成,采用逐层正向、反向进行网络参数的训练。在文中将典型相关分析融入深度置信网络中,参与源域数据和目标域数据的相关性分析。而深度置信网络可作为初始参数的预训练,以提高模型的性能和收敛速度。
典型相关分析可以将不同数据域中相关的特征,通过矩阵映射到某个特征子空间,由此可将强相关性的特征提取出来。考虑到电力行业数据和外部数据存在多个数据源,且不同数据源的体量大小不一,使用典型相关分析来提取不同数据源之间的共享特征,进而实现迁移学习。在这一过程中,不同数据源的共生数据CS、CT的隐层特征在转换矩阵的作用下被提取出来,并得到相关匹配系数矩阵。具体过程如下:
1)利用栈式自动编码机对源域以及目标域进行编码,通过编码结果将跨域共生数据提取出来,进而得到其对应的隐层特征。
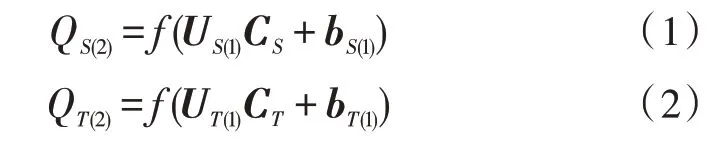
在以上两式中,US(1)、UT(1)分别表示源域和目标域的网络权重矩阵,bS(1)、bT(1)分别被用来表示源域和目标域相应的偏置向量,f()为Sigmoid 非线性激活函数;
2)将编码后的源域和目标域进行典型相关分析,根据共生数据特征可得到这两个数据域之间的最大相关系数矩阵US(2)和UT(2)。利用最大相关系数矩阵可将源和目标域的共生数据特征映射到语义共享子空间中;
3)为了增强源域与目标域之间的相关性,需要对深度置信网络模型参数进行优化。在深度置信网络模型反向传播过程中,即从目标域到源域的过程,使用矩阵US(2)和UT(2)对域网络参数(US,bS,UT,bT)进行微调。
在图3 所示的迁移学习模型中,目标函数的作用被设定为:1)最小化源域和目标域的重构误差;2)最大化跨域深度网络的相关性。因此目标函数的表达式为:
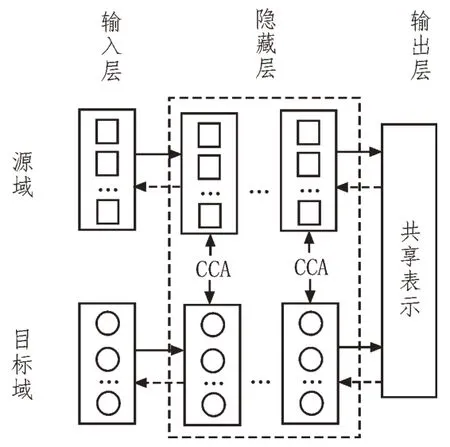
图3 基于深度学习的异构迁移学习模型框架
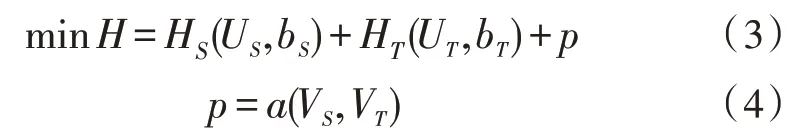
上式中,HS(US,bS)、HT(UT,bT)分别表示为源域和目标域在编码后,经过深度置信网络训练后的重构误差。p与源域、目标域的最大相关系数矩阵VT、VS的投影向量有关,其代表两者之间的相关匹配函数。利用最大相关系数矩阵的投影向量VT、VS,可进一步地将源域和目标域的共生数据最大化转换为特征相关性最大化的问题。
目标函数中共有六种参数:WS、bS、WT、bT、VT、VS。若同时优化这六种参数,则会带来极大的计算量。该文使用拉格朗日乘子与随机梯度下降法分别对(WS、bS)、(WT、bT)和(VT、VS)进行优化。由于目标函数中(VT、VS)仅存在第三部分,因此可以给定源域和目标域的(WS、bS)、(WT、bT),对(VT、VS)进行拉格朗日转换,即可求得VT和VS。而(WS、bS)、(WT、bT)的优化,则需要给定相关系数矩阵[VT,VS]。源域和目标域的优化过程相同,这里仅叙述源域的优化。在深度学习训练反向传播过程中,利用梯度下降算法对WS、bS进行调整,具体为:

以上两式中,μS表示学习率。
3 测试与验证
该文采用江苏省某地区近三年的电力系统数据作为原始数据进行方案验证,数据涉及电力行业数据和外部数据两个部分。其中,电力行业数据涉及了项目合同主数据、项目执行过程数据和用户评价数据等;外部数据涉及三年内气象数据、当地经济效益数据等。文中将这些数据随机分成四种数据集对所提出的多源异构数据融合算法进行验证。上述四种数据集中均含有1 000 个文本实例,每种实例使用不同语言描述。为了验证该文所述算法的性能,将对照组算法设定为典型相关分析和深度匹配网络两种算法。实验组和对照组均使用相同的硬件配置:英特尔酷睿i7-7500U 的处理器、2.70 GHz 的主频、32 GB 的内存配置,软件平台则是使用Matlab。
图4 展示了实验组和两种对照组算法在四种数据集作为训练数据下的结果。从图中可以看出,该文方案在四种数据集下的精度均优于典型相关分析和深度匹配网络,平均精度分别高出8.32%和11.7%。这是因为文中所述的基于多源异构数据融合算法在本质上是面向域私有网络和域共有网络的深度语义匹配模型,通过将典型相关分析和深度学习网络结合,可利用多层非线性转换来挖掘多层特征结构。迁移学习的应用可弥补跨域数据实例的语义误差,实现源域到目标域的知识迁移。
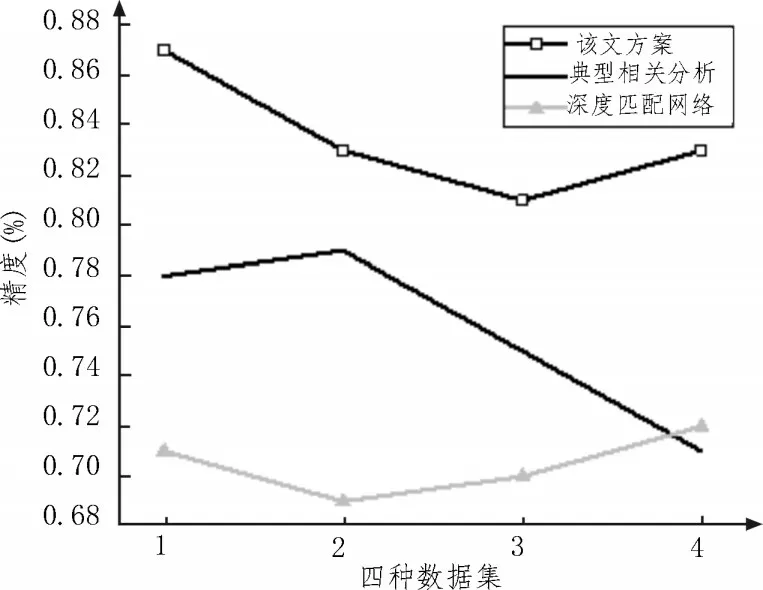
图4 实验组和对照组对比
图5 分别展示了深度学习网络中隐藏层层数和神经元个数对语义误差的影响。从图中可以看出,随着隐藏层层数和神经元个数的增加,语义误差均呈现出快速下降趋势。值得注意的是,随着隐藏层层数的增加,语义误差下降的速度更快。且当神经元个数为50 时,语义误差曲线基本趋于平稳,这表示结果已收敛。隐藏层层数和神经元个数的增加均有助于提高多层相关匹配效果,可有效弥补异构模态数据之间的语义偏差。

图5 隐藏层层数和神经元个数对语义误差的影响
4 结束语
该文采用知识图谱将电力行业以及外部数据进行系统性整理,并将相关概念进行网络化关联,然后又将典型相关分析和深度学习网络相结合,构建了一种多源异构数据的融合算法。测试和试验结果表明,该文所述方案具有一定的可行性和优越性。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
北京航空航天大学学报(2022年8期)2022-08-31
小学教学研究(2022年5期)2022-04-28
少先队活动(2020年12期)2021-01-14
计算机技术与发展(2020年11期)2020-12-04
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
青年文学家(2015年29期)2016-05-09
