
基于改进Seq2Seq-Attention 模型的文本摘要生成方法
2022-12-01 06:00门鼎陈亮
电子设计工程 2022年23期
门鼎,陈亮
(西安工程大学计算机科学学院,陕西 西安 710048)
随着社会进入信息时代,人们可以通过多种渠道从互联网平台获取重要信息,信息社会中人们把时间和精力花在阅读大量信息上。互联网上的信息盈余,将引导人们有效地解决信息过载的问题,而从海量的有效数据来看信息化的工作量不仅是巨大的,而且是迫切需要解决的问题。网络数据需要从大量文本信息中快速挖掘语义数据。因此,通过文本摘要生成技术可以快速获得文本主要信息。
自动摘要生成技术不仅过程完全自动化,而且生成的摘要概括能力强。互联网上的文本信息数量庞大,自动摘要生成技术可以帮助用户自动归纳文本信息的主要内容,节省了用户的阅读时间。当人工阅读文本信息总结文本主旨时,摘要质量的高低依赖于读者自身的语言概括能力和信息提取能力,容易导致捕获的语义与文本核心主旨形成较大偏差。在面对复杂且篇幅过长的文本时,人们的阅读理解能力有限,不能快速准确地获取文本主旨。自动摘要生成技术模仿人工摘要过程,学习文本的深层语义,具有高水准的概括能力。
该文利用抽取式与生成式摘要抽取模型相结合的方法应用在工业领域中,对于文本提取摘要的技术做出创新,在摘要提取的准确度、核心词以及词汇重复等方面做出一些突破,结合BERT 摘要模型进行摘要句抽取[1],分析Seq2Seq-Attention 模型,并通过Seq2Seq-Attention 模型进行文本摘要生成,在注意力机制中加入核心词,然后结合指针网络生成模型[2],该模型可以通过核心词中的重要信息,构建出摘要框架,生成信息全面精炼的文章摘要。
1 相关工作
1.1 问题描述
文本摘要问题一直是学者们研究的焦点,该文采用文本自动摘要技术,将其凝练复制成一段简单有效的段落,对于机器翻译过程中会存在关键词丢失、词汇重复以及语句不通顺等问题。调研了关于西安高压开关操动有限公司项目的质量数据管理问题,其中,质量问题主要包括质量问题的描述、质量问题的分类以及原因等。通过调研公司目前客户经常出现的质量问题,方便进行统计分析。调研质量问题,产生大量文本数据,不利于后期管理和查询统计,为了使工业生产更加信息化,通过收集工业数据集,进行广泛的实验,构建一种新的混合模型应用于工业领域,进行技术创新并解决以上问题。
1.2 系统框架
BERT 模型中集成文章的主题信息,在长语句处理时会出现问题。因为Seq2Seq 模型将产生数据截断,导致丢失信息。于是提出融合核心词注意机制,把全文本作为摘要输出。
结合现有的文本摘要模型技术,构建出一个新的混合模型,处理流程如图1 所示。

图1 文本摘要混合模型处理流程
2 文本摘要自动生成的方法
2.1 基于BERT模型的摘要句抽取
BERT 模型采用Transformer 网络结构[2],对语言模型进行预训练,通过多次语言训练得到一种通用的语言理解模型。BERT 语言模型的结构如图2所示。

图2 BERT语言模型结构
双向预训练与单项预训练有所不同,BERT 在文本摘要抽取过程中,利用了遮蔽语言机制来表示深度双向训练。在许多训练模式中,BERT 可以根据特定的任务需求改变体系结构的需求。同时,它在训练过程中显示了自己先进的性能。BERT 拥有两个变体,一个是BERTBASE,该变体拥有12 层Transformer 模块,另一个变体是BERTLarge:,该变体拥 有24 层Transformer 模块。
2.2 Seq2Seq模型
2014 年,Seq2Seq 模型[3]进入文本摘要的研究领域,学者们试图将其应用到机器学习等各个领域中,该模型的本质就是Encoder-Decoder 框架,在生成摘要的过程中,输入一段长文本,使用编码器进行编码,得到原文的向量化表示,然后用解码器进行解码得到文本摘要,输出的句子是短文本。Seq2Seq 模型结构如图3 所示。
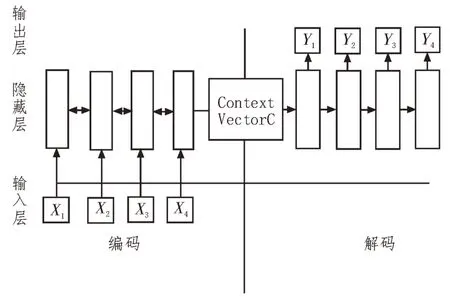
图3 Seq2Seq模型结构
2.3 Seq2Seq-Attention模型
Encoder-Decoder 框架在需要语句向量中存在较大的局限性。该模型在解码过程中需要压缩整个语句向量,这就使得压缩后的语句与原来的文本主旨存在差异,原文本中的重要信息随着压缩逐渐变少,重要信息存在遗漏,在解码阶段就不会产生重要信息,导致解码关键信息丢失。
该文提出的Attention 模型[4-6],在文本输出时,会有一个特定的范围把需要关注的重要信息标记出来,然后根据这些标记的主要信息生成输出。Seq2Seq模型中,因为向量自身长度限制,输出过长的文本导致信息丢失,在Attention 模型中,可以分为多个向量来储存信息,在编码阶段,把重要信息标注出来,在向量输出后进行调整,该模型在编码端使用双向LSTM,在解码端使用单项LSTM。模型图如图4所示。

图4 Seq2Seq-Attention模型
2.4 改进模型
在Seq2Seq-Attention 模型[7-8]中,对于长文本多次出现未登录词以及生成词汇重复率极高的情况,使得原文本中重要信息在解码阶段,由于向量长度的自身限制没有解码出来,导致得到的摘要读起来不通顺,原文主要意思无法表达出来。于是加入指针网络来解决这一问题。
2.4.1 指针网络
模型中添加指针网络[9-10],为了能够在模型抽取原文主要信息后,可以自动生成标题,而且可以根据生成词汇扩充新词汇来丰富生成的摘要信息,有效提高了原文信息的利用率,使得生成的摘要内容信息更加饱满,读者阅读也会更加通顺。相关公式如下:

式中,Pgen作为开关,可控制新词生成。
2.4.2 覆盖机制
在Seq2Seq-Attention 模型中,重复问题比较严重,由于在机制计算时,机制计算在不同时间段内相对独立,模型在采集信息位置上会出现重复现象,这就导致生成文本摘要会出现重复词汇或者会漏掉相应的重要信息。在绝大多数长文本中会重复出现一些词汇,这也说明这些词汇十分重要,针对该词汇模型注意力会更加集中,因此,模型需要对已经注意过的位置进行标记,防止下次再集中到某一位置,而导致某一词汇多次出现。因此,该文在原有模型中加入覆盖机制。相关公式如下:
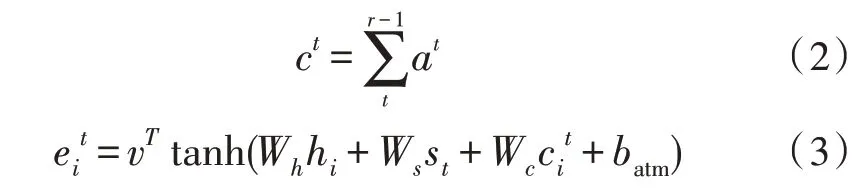
2.4.3 核心词注意力机制
神经网络进行摘要生成的过程中,原文中许多词汇没有编译出来,文章主旨表述不完整。于是在注意力机制中融入指导核心词,核心词包括原文中的主要句子和短语,核心词汇在解码时会被重要关注,生成的摘要也会概括出原文主要信息[11]。
TF-IDF 算法[12]可以提取文档中的重要词汇,然后测评出一段文本对于原文档的重要程度。TF-IDF表示某关键词在文档中出现的频率,由两部分组成:
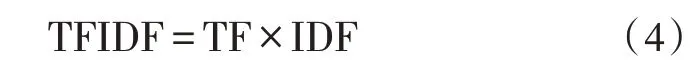
TF 为词频,表示某词汇或短语在该文档中出现的频率,频率的高低可以反映其对于文档的重要程度。
IDF 为逆文档频率,表示对于某一词语权重的衡量,若词汇在其他文档中出现频率较低,则认为该词语为少见词,若该词汇在文档中重复出现,该词汇IDF 值越大,它的权重越大,反之越低。
2.5 基于混合模型的摘要生成
基于以上模型对于文本摘要生成过程中起到了十分重要的作用,单个模型在编码以及解码中存在一些问题,该文提出混合模型的方法,然后加入注意力机制以及指针网络[13],解决了重复问题以及核心词的提取,让文本摘要语义表达更加准确,语句更加通顺。在Seq2Seq-Attention 模型中,针对无法生成OOV 词汇,并且会产生其他信息,加入了覆盖机制与指针网络,解决了词汇重复的问题。在注意力机制中,过多的关注摘要与原文的信息对比,忽略一些核心词对原文的信息表达的影响,该文将核心词提取到注意力机制中,然后通过核心词引导出较为准确的文本摘要。
3 实验分析
3.1 实验设置
1)实验选取西安高压开关操动有限公司的项目进行驻场调研,对设备进行入库、检定、维修、封存,启封、报废状态变更等过程信息的记录、查询和统计分析。收集统计文本记录,对于选取的数据集进行预处理,数据集包含训练集、验证集以及测试集,统计结果如表1 所示。

表1 数据统计结果
2)采集样本如图5 所示。

图5 采集样本
3)文本自动分词,通过分词工具,把文本内容分为两字词语,对于低频词语用符号来代替,数据集分词结果如图6 所示。

图6 数据集分词结果
4)选取抽取式摘要模型:①TextRank;②TFIDF;③BERTSUM
5)选取生成式摘要模型:①Seq2Seq;②Seq2Seq-Attention;③Pionter+Generator 4.core words
6)进行ROUGE 打分,并进行结果分析。
3.2 结果及分析
实验结果如表2 所示。实验对比模型如下:
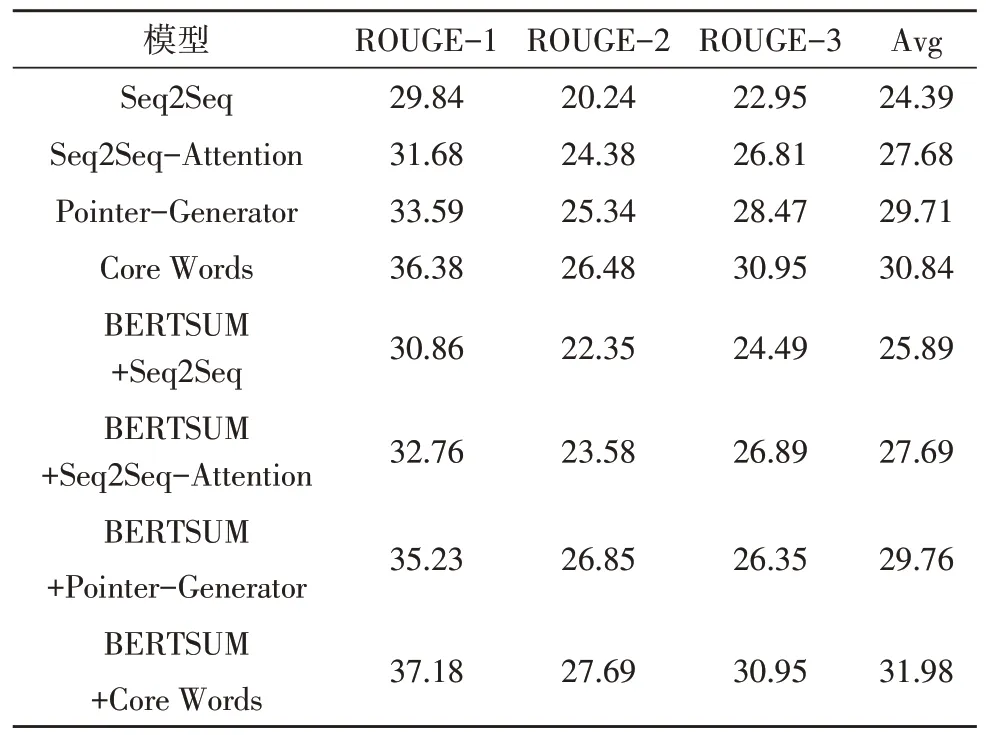
表2 生成式摘要与基于混合模型的摘要生成结果对比
1)基本Seq2Seq:属于一种encoder-decoder 结构,应用在机器翻译等领域[14]。
2)Seq2Seq-Attention:将序列到序列的模型。
3)Pointer-Generator:使用pointer 机制从原文中复制未登录词汇,保证信息的正确率[15]。
通过观察表1、表2,绘制柱状图,如图7 所示,可以得出:
1)Attention 机制的模型ROUGE 平均值较高,基础Seq2Seq 模型的ROUGE 平均值较低,Attention 机制更加适用于混合模型。
2)BERTSUM+Seq2Seq-Attention 模型[16]相比于BERTSUM+Seq2Seq 模型ROUGE 平均值提高了1.8%,混合模型相比BERTSUM+Pointer-Generator提高了2.57%。可以得出,混合模型的表现更好。
3)从图7 可以看出,混合模型比生成模型具有更好的结果,生成模型会存在信息不完整等问题。与直接输入原文相比,BERTSUM 生成的摘要更加符合原文的主旨大意,则认为它生成的摘要更为全面。

图7 柱状图
4 结论
实验证明,在工业领域中,文本摘要技术也可以得到很好的应用,让制造生产更加信息化和智能化,该文采用混合模型进行了实验。在摘要生成过程中使用了指针网络以及融合了核心词注意力机制,得到了比较精确的文本摘要,但是在文本提取过程中仍然存在很多的问题。在BERT 模型的摘要提取过程中,输出端处理工作欠缺,使得输出原文信息覆盖不全面,并且存在信息重复。在注意机制中,可以使用多种的模型方法,并且更加有效快捷地提取文章主要包含的信息,最终成为简明扼要的文本。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
电脑爱好者(2017年7期)2017-05-06
