
非结构化数字图书资源分布式储存方法设计
2022-12-01 06:00张娟王璇邢倩倩
电子设计工程 2022年23期
张娟,王璇,邢倩倩
(1.北京国电通网络技术有限公司,北京 100070;2.国网信息通信产业集团有限公司,北京 102200)
非结构化数据是一种数据结构不完整也没有主观定义形式的数据模型,在实际应用过程中,可用数据库二维逻辑表单来表示。作为计算机信息化系统中的重要数据传输形式,非结构化数据具有格式多样、标准多样等几类应用优势,且在译码与转码的过程中,也并不拘泥于一种单独的传输与理解形式[1-2]。一般来说,非结构化数据可作为信息采集的执行与处理基础,在开源数据库体系的支持下,每一类传输数据都与一种非结构化文档保持独立对应关系。针对不同类型的传输信息,非结构化数据在运行过程中所采取的处理原则也有所不同。
对于数字图书资源来说,随着无序与零散信息传输量的增大,数据信息的实际存储环境则很难长时间保持系统化的存在状态。为解决上述问题,传统云存储方式借助云状网络体系,同时定义数字图书资源的存储深度与存储广度条件,并根据HDFS访问副本的开放形式,确定单位时间内能存储的最大数据信息资源量。但该方法在资源信息组织与整合方面的应用能力有限,并不能实现对系统化资源信息存储环境的有效维护。基于此,提出并设计了一种新型的非结构化数字图书资源分布式储存方法,在定义元数据含义的基础上,完善非结构化资源信息的查询与编码原则,再借助Hadoop 存储架构,读取关键的数字资源文件,从而实现对分布式浏览系数值的准确计算。
1 非结构化数字图书资源的存储能力分析
非结构化数字图书资源的存储能力分析包含元数据定义、非结构化查询标准完善、编码原则建立三个处理环节,具体研究步骤如下。
1.1 元数据定义
元数据是与非结构化数字图书资源存储相关的明确定义,在实际应用过程当中,始终以描述信息的形式存在。根据数字图书资源分布式存储行为的不同,元数据可分为描述量、残差量等几种应用类型,且根据资源信息所属定义形式的不同,元数据参量所占据的存储空间也有所不同[3-4]。若将非结构化环境看作是一种独立的数据信息存储空间,则可认为元数据存在形式会随着资源信息传输量的改变而出现不断变化的情况,即任何一种固定不变的资源存储格式,都不能完全满足非结构化元数据信息的实际定义需求。设εmin代表最小的资源信息分布系数,εmax代表最大的资源信息分布系数,代表单位时间内的数字图书资源信息查询均值,联立上述物理量,可将元数据定义结果表示为:
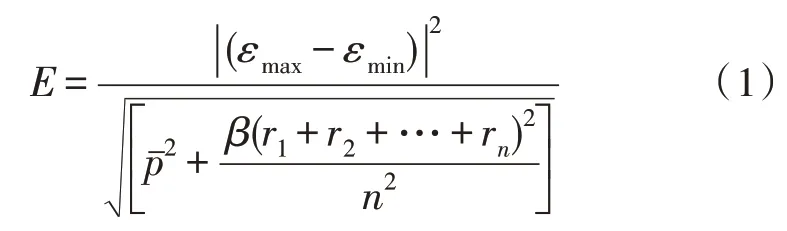
其中,β代表数字图书资源信息的非结构化特征值,r1,r2,…,rn代表n个不同的待存储图书资源信息。
1.2 非结构化查询标准完善
数字图书资源的非结构化查询标准由记录头标区、存储地址目次区、信息字段区、分隔符四部分共同组成。其中,记录头标区能够容纳所有的数字图书资源信息,能够按照元数据标准,对数据信息进行按需存储,总的来说,该区域中资源信息的最大存储量只能达到24 字符,所有小于该存储标准的信息参量,都能在头标区空间内自由传输[5-6]。存储地址目次区中包含n个目次项指标,但是每个指标的最大存储量只能达到12 字符,始终低于头标区环境。资源信息字段区起到一定的稳定存储与数据过滤作用,可对已满足非结构化传输标准的数字图书资源信息进行暂时存储,并可将满足应用标准的传输数据,过滤回存储地址目次区中。非结构化分隔符包含n个不固定字段,可对信息字段区已存储的资源信息进行二次分辨。数字图书资源的非结构化查询标准如图1 所示。
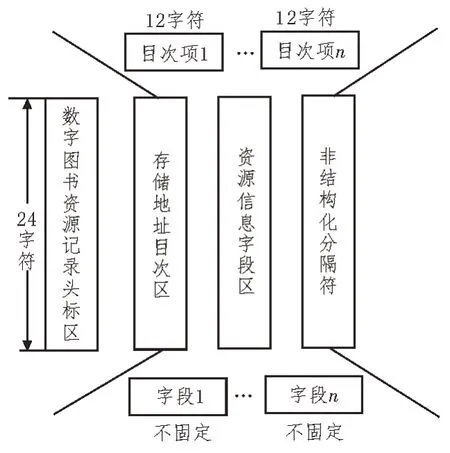
图1 数字图书资源的非结构化查询标准
1.3 编码原则建立
非结构化数字图书资源的编码原则主要以原数据参量作为参考标准。若已知具体的数据信息查询标准,则可认为待编码的资源信息量越大,分布式储存主机所面临的执行压力也就越大。在非结构化传输环境中,分布式编码原则由头结点查询、中间成分查询、尾节点查询三部分共同组成。头结点确定了数字图书资源的起始传输位置,尾节点确定了数字图书资源的终止传输位置,一般情况下,二者之间的实值距离越大,分布式空间所具备的实时存储能力也就越强[7-8]。中间成分决定了与非结构化数字图书资源相关的信息过渡条件,受到头结点定义条件、尾节点定义条件两项物理量的直接影响。设T0代表头结点定义系数,Tn代表尾节点定义系数,代表中间查询成分的信息量均值,联立式(1),可将非结构化编码原则表示为:
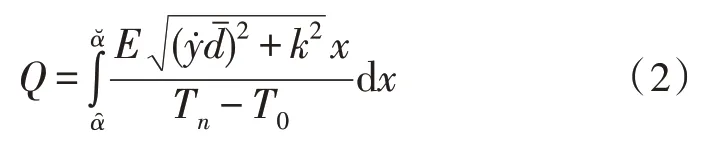
2 图书资源分布式储存方法
通常在非结构化存储能力分析原则的支持下,按照Hadoop 存储架构搭建、资源文件读取、分布式浏览系数计算的处理原则,完成新型数字图书资源分布式储存方法的设计与应用。
2.1 Hadoop存储架构搭建
Hadoop 架构负责执行所有与非结构化数字图书资源相关的存储指令,整个框架体系以HDFS 模块、数据传输地图、检索导航三个结构作为主要应用成分,可在整合数字图书资源信息的同时,制定后续运行所需的分布式存储文件[9-10]。HDFS 模块作为Hadoop 架构的核心应用单元,可按照非结构化数字图书资源的实际存储需求,构建分布式传输框架,从而使信息数据的传输积极性得到充分调度[11-12]。数据传输地图作为检索导航建立的基层组织结构,可在已知数字图书资源传输量标准的前提下,确定数据信息最远所能到达的传输距离,从而实现对资源数据的最大化整合与处理。Hadoop 存储架构示意图如图2 所示。

图2 Hadoop存储架构示意图
2.2 资源文件读取
资源文件读取是数字图书资源分布式储存过程中的必要处理环节,可借助Hadoop 架构,将各级信息参量集合到统一的数据库主机中,一方面可减少无序与零散组织在网络环境中的存在数量,另一方面也能够实现对资源信息数据的最大化聚合,从而使得整个数字图书资源存储环境不断向着系统化方向趋近。假设非结构化数字图书资源在分布式存储环境中只能保持单向传输的连接状态,且信息参量的最大存储条件不会受到任何外在条件的影响[13-14]。在此情况下,数据库主机所能读取的资源文件量越大,最终计算求得的分布式浏览系数值也就越大。设χ1、χ2代表两个不同的数字图书资源信息排列系数,联立式(2),可将资源文件读取结果表示为:

其中,ΔT代表数字图书资源信息的单位提取时长,代表分布式传输条件下的信息数据特征值,g代表资源文件在网络环境中的单次读取次数。
2.3 分布式浏览系数计算
分布式浏览系数决定了非结构化数字图书资源的最大存储条件,在网络环境中,该项系数值的物理水平越高,待存储的资源信息量也就越大。在不考虑其他干扰条件的情况下,分布式浏览系数计算结果受到资源数据存储边界、信息标度值两项物理指标的直接影响[15-16]。资源数据存储边界由最大值cmax、最小值cmin两部分组成,一般来说,二者之间的差值水平越大,数据库主机所具备的资源信息存储能力也就越强。信息标度值可表示为μ,在已知资源文件读取条件的情况下,该项物理量的数值水平越大,分布式浏览系数的计算值结果也就越小。在上述物理量的支持下,联立式(3),可将分布式浏览系数计算结果表示为:
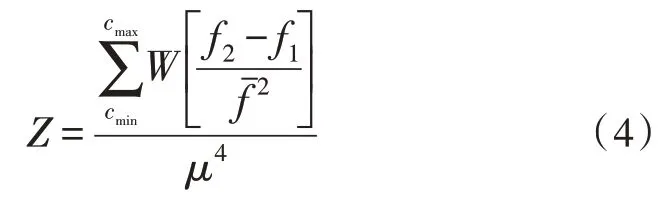
式中,f1、f2分别代表两个不同的非结构化差异系数指标,代表f1与f2的物理均值。至此,完成相关系数值的计算与处理,在确保不出现其他干扰条件的情况下,实现非结构化数字图书资源分布式储存方法的顺利应用。
3 实例分析
通过人工布线的方式,建立完整的数字图书资源存储网络,分别采用分布式储存方法、传统云存储方式对网络环境中的数据信息传输行为进行干预,将前者作为实验组,后者作为对照组。
对于数字图书资源来说,评论存储能力强弱包含零散信息组织有效性、整合有效性两部分。零散信息组织有效性是指网络主机在单位时间内所能组织处理的最大数字图书资源信息量,一般来说,该项物理指标的数值水平越大,网络主机所具备的零散信息组织有效性也就越强。
表1 记录了实验组、对照组资源信息组织量的数值变化情况。
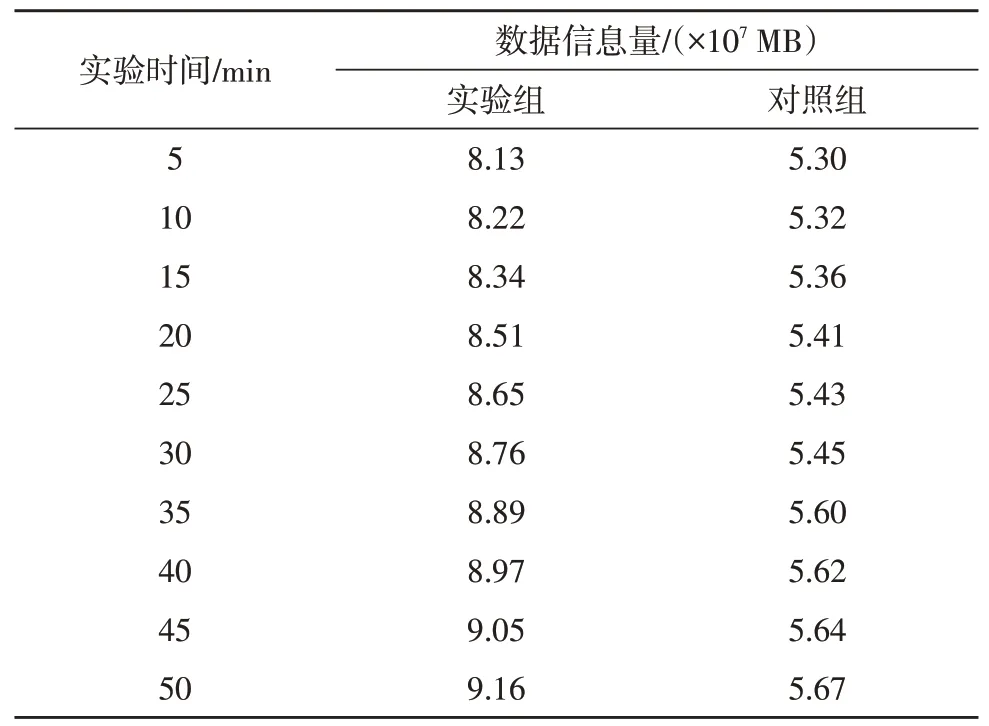
表1 资源信息组织量
分析表1 可知,实验组、对照组资源信息组织量在单位时间内均呈现不断增大的数值变化趋势,但实验组上升量级均值明显更大,整个实验过程中,实验组最大值9.16×107MB 与对照组最大值5.67×107MB相比,上升了3.49×107MB。
零散信息整合有效性是指与网络主机匹配的资源信息处理速率,一般来说,处理速率越快,零散信息的整合有效性越高。图3 记录了实验组、对照组资源信息处理速率的具体数值情况。

图3 资源信息处理速率
分析图3 可知,实验组、对照组资源信息处理速率曲线均呈现上升与下降相互交替的数值变化趋势,在整个实验过程中,实验组曲线始终存在于对照组上方。从极限值角度来看,实验组最大值8.54 MB/mm与对照组最大值3.62 MB/mm相比,上升了4.92 MB/mm,且实验组的两级差值水平也远高于对照组。
综上所述,文中实验的结论如下:
1)分布式储存方法在单位时间内所能组织的数字图书资源信息量较大,符合增强零散信息组织有效性的实际应用需求,对提升数据信息存储能力起到一定的促进作用。
2)与分布式储存方法匹配的资源信息处理速率更快,有利于零散信息的有效整合,满足最大化存储数字图书资源的实际处理目的。
4 结束语
与传统云存储方式相比,分布式储存方法在已知元数据定义条件的基础上,根据非结构化查询标准,建立完善的数据信息编码原则。再联合Hadoop框架,通过读取已存储资源文件的方式,得到分布式浏览系数的具体数值计算结果。从实用性角度来看,资源信息组织量增大与资源信息处理速率加快两类变化的同时出现,不但可增强网络主机对于零散数字图书资源的组织有效性及整合有效性,而且满足通过有效组织无序与零散资源的方式,维持数字图书资源存储环境系统化的实际应用需求。
猜你喜欢
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
文苑(2019年2期)2019-11-20
中学生百科·小文艺(2018年4期)2018-06-19
制导与引信(2017年3期)2017-11-02
燕山大学学报(2015年4期)2015-12-25
小资CHIC!ELEGANCE(2015年14期)2015-09-23
小资CHIC!ELEGANCE(2015年15期)2015-09-01
