
高校图书个性化推荐系统设计
2022-12-01 11:02:14郭晨睿
科教导刊·电子版 2022年25期
郭晨睿
(洛阳师范学院 信息技术学院,河南 洛阳 471934)
0 引言
高校图书馆具有琳琅满目、资源丰富的藏书,为高校师生提供了自由完善的图书借阅服务。但是,用户从海量的图书中准确地找到自己想要借阅的图书资源往往花费大量的时间与精力,且随着图书数量的增多,搜寻自己感兴趣图书的难度越来越高。
因此,图书个性化推荐系统应运而生,图书个性化推荐系统是通过对大量的借阅历史等信息进行挖掘的基础上,根据用户的兴趣、偏好等特征及图书资源的特征,向用户推荐其可能感兴趣的图书资源,节省用户挑选查找图书的时间与精力,提高了图书资源的利用率。目前图书馆主要采用新书与热门图书的推荐方式为用户推荐图书,上述方式在一定程度上满足了用户对图书的需要,但缺少对图书的个性化推荐,且推荐效率较低,不能满足大部分用户的需求[1-5]。
1 高校图书个性化推荐系统
1.1 系统总体结构
根据用户对图书的需要设计了高校图书个性化推荐系统,该图书个性化推荐系统主要由显示层、推荐层和数据层三个部分组成,如图1(P105)所示。
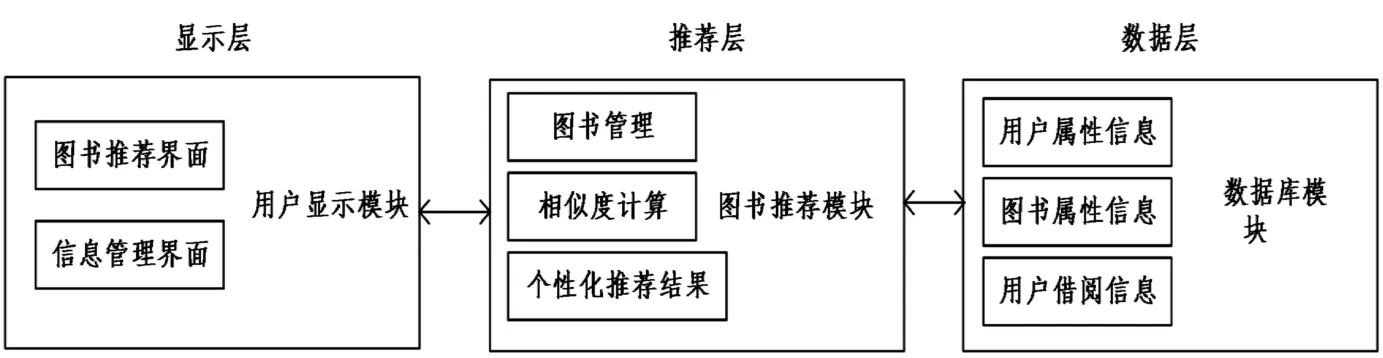
图1 系统总体结构图
位于系统最底层的是数据层,由数据模块组成,数据层负责用户属性信息、图书属性信息以及用户借阅信息的收集,收集到的相关数据通过图书推荐模块通过相似度计算获取个性化推荐结果[6]。数据层包含了大量的用户信息、图书信息以及用户对图书的借阅信息,为图书个性化推荐提供了数据支持。
推荐层是图书推荐系统的核心,由图书推荐模块组成,在接收到显示层用户的查询后,将由数据层提供的数据利用个性化推荐算法对图书进行快速处理,处理结束后将推荐结果反馈到显示层推荐给用户。管理员与用户的各项操作均需要通过推荐层进行处理。
系统的显示层由用户显示模块组成,通过系统的显示界面与用户实现人机交互。高校师生通过用户显示模块登录系统后,利用图书名称等相关信息对图书进行检索与查看,并将图书推荐模块生成的推荐图书展示给用户。
1.2 系统功能模块
根据用户个人需求的高校图书个性化推荐系统功能主要包括用户信息管理、图书信息管理以及个性化推荐三部分,如图2(P105)所示。

图2 系统功能结构图
(1)用户信息管理。该功能主要包括用户登录、个人信息管理、图书检索、图书查看、个人借阅信息、兴趣相似的用户以及图书借阅排行榜。用户登录推荐系统后通过个人信息管理部分进行个人密码、邮箱与手机号等相关信息的修改;可以进行图书的检索与查看;可以查看自己借阅图书的历史信息;可以通过兴趣相似的用户功能关注、查看与自己具有相似兴趣的用户的相关信息(用户可以设置自己的信息是否让别人查看);可以通过图书借阅排行榜查看借阅热门的图书。
(2)图书信息管理。该功能主要包括增加图书项目、修改图书信息与删除图书项目三部分。管理员登录系统后,选择利用该功能添加新进的图书,并删除已经报废的图书,还可以对图书的数量等信息进行更改。
(3)个性化推荐。该功能主要包括推荐结果展示与用户评价反馈两部分,用户通过推荐结果展示获取系统个性化推荐的结果,并通过反馈区域对该系统推荐结果提出意见与建议,为进一步优化系统做提供理论支持。
1.3 系统工作流程
图书个性化推荐系统的工作流程如图3所示。从图3中可以看出图书个性化推荐共分为9个步骤,系统数据初始化,主要是对用户的学科、性别与年龄等相关信息的权重系数的初始化;数据采集过程主要采集用户的基本信息(包括:姓名、学号、专业与性别等信息)、图书属性信息(包括:图书名称、作者、类别、ISBN等信息)以及用户的借阅信息;数据预处理阶段主要是对收集到的数据进行数据清洗,并将清洗后的数据进行分类汇总后存储到图书个性化推荐系统的数据库中;分别使用协同过滤与用户专业计算用户之间的相似度,并将二者进行线性加权求和获得最终的相似度,生成具有相似兴趣的用户并展示在“兴趣相似的用户”功能处,然后将生成的图书推荐目录显示在“推荐结果展示”功能处。

图3 图书推荐系统工作流程图
1.4 基于协同过滤的图书个性化推荐算法
1.4.1 基于协同过滤的用户相似度计算
使用协同过滤计算用户之间的相似度,需要用户对图书的评分,当前高校图书管理系统中没有用户对图书的评分或评分较少,本文根据用户借阅图书的时长来计算用户对图书的评分,将读者的借阅信息转化为相应的评分信息,量化用户对图书的喜爱程度[5]。默认用户借阅图书的时间越长表明用户对图书的评分越高,同时考虑每位用户的阅读速度等因素,采用公式1计算用户对图书的评分。


1.4.2 基于用户专业的相似度计算
由文献[2]可知:属于相同或相近专业的用户,相同或相近专业的用户在图书借阅行为上具有极大的相似性。根据这一原理,认为同一学院或不同学院相近专业的用户具有很高的相似性,根据用户的学院、专业等信息计算用户之间的相似度。依据国家标准学科分类与代码表,按照三个级别对学科进行分类[3],用户 和用户 的学科距离使用表示,如果用户u和用户v的三级学科一致则;如果用户u和用户v的二级学科一致则,如果用户u和用户v的一级学科一致则,如果用户u和用户v的不级学科一致但是一级学科相似则,如果用户u和用户v的一级学科不一致且一级学科也不相似则。用户u和用户v的学科相似度由公式3计算获得。

1.4.3 用户相似度

1.5 生成推荐目录
通过公式4计算目标用户与其他用户之间的兴趣相似度,找到目标用户兴趣最相近的位用户,并根据这位用户对图书的评分,预测目标用户对未看过的图书的评分,并依据预测评分值将的评分图书作为推荐图书推荐给目标用户,并显示在“推荐结果展示”功能处。
均值中心化的基本思路是用户对图书的标准化评分的正负情况可以直观地表现用户对该图书的喜好或厌恶程度。把用户对图书的评分减去该用户对所有图书评分的均值。因此,首先需要计算目标用户u对所有图书评分的均值,然后将目标用户u对所有图书的评分都减去均值。然后通过公式5计算用户u对图书i的评分作为目标u用户借阅图书的概率。

2 系统测试
为了检测本文研究图书个性化推荐系统的推荐性能,选取某高校图书馆作为实验对象,根据该校计算机科学与技术专业某学生登录本文的推荐系统,系统推荐结果如图4所示。从图4系统的推荐结果展示中可以看出,本文的图书推荐系统可针对该用户个人的兴趣偏好为其推荐符合用户个性化需求的《大话数据结构》《机器学习》等图书,有效验证了本文图书个性化推荐系统的推荐有效性。
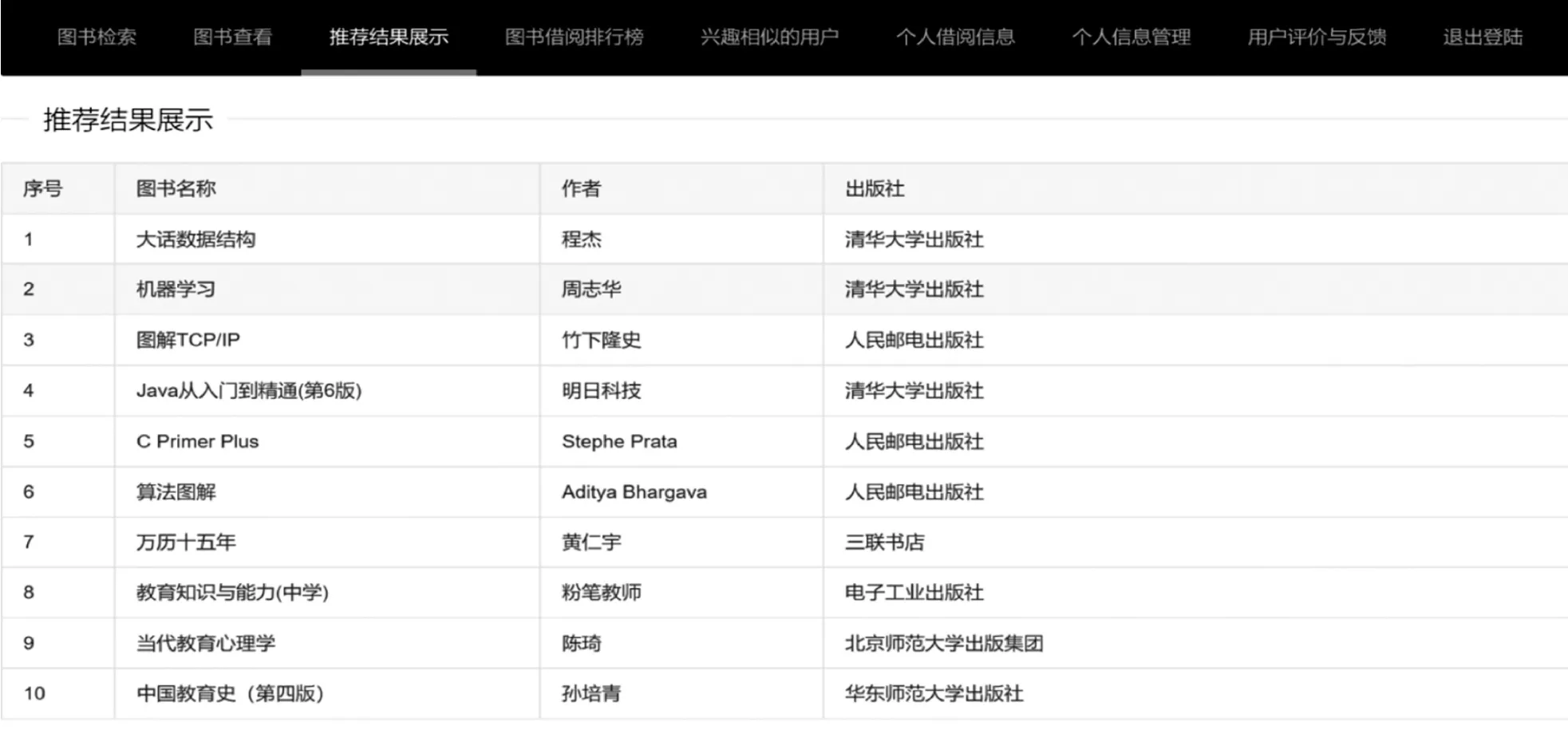
图4 图书个性化推荐系统推荐页面
3 结语
高校图书个性化推荐系统的好坏对学生阅读习惯的养成具有重要作用,高效的图书推荐系统不仅可以有效节约学生找书的时间,优化借阅体验,提高学生的阅读兴趣,扩展学生的阅读视野;同时可以把图书馆中的图书有针对性的推荐给可能会借阅的学生,提升了图书馆图书的利用率。本文首先利用用户的借阅时长计算用户对其借阅图书的评分,并结合基于用户的协同过滤算法计算用户与用户之间的相似度;然后使用用户的专业计算用户与用户之间的相似度;将协同过滤与用户专业计算获得的相似度进行线性加权求和,获得用户与用户之间最终的相似度;最后,使用均值中心化计算用户借阅图书的概率,推荐图书并生成推荐图书目录,兴趣相似的用户功能帮助许多用户找到了志同道合的朋友。
猜你喜欢
宁波大学学报(理工版)(2022年4期)2022-07-08 05:12:02
华北理工大学学报(自然科学版)(2021年3期)2021-07-03 09:06:34
南风(2020年22期)2020-09-15 07:47:08
文苑(2020年4期)2020-05-30 12:35:12
小学生优秀作文(低年级)(2019年5期)2019-04-25 13:13:40
新闻传播(2018年12期)2018-09-19 06:27:10
小学阅读指南·低年级版(2017年12期)2017-12-26 17:01:14
军事文摘·科学少年(2017年4期)2017-06-20 23:29:09
汽车与新动力(2016年6期)2017-01-04 10:50:48
中央社会主义学院学报(2016年2期)2016-05-04 04:18:29
