
基于深度置信网络的风功率预测研究
2022-11-25 06:17张丽红祁庆丰
东北电力技术 2022年10期
刘 姝,张丽红,祁庆丰
(1.沈阳工程学院新能源学院,辽宁 沈阳 110136;2.沈阳工程学院电力学院,辽宁 沈阳 110136;3.华能新能源股份有限公司辽宁分公司,辽宁 沈阳 110001)
受环境污染严重及相关政策影响,风电装机容量持续增加[1]。高精度风电预测已成为新能源接入电力系统高比例运行的必要技术[2-3]。预测风机的运行状态,可以有效提高运行的可靠性,及时发现异常情况,提前进行预防性维护。深度学习和各种统计方法在风电预测中得到广泛应用,风电预测的准确性不断提高。
文献[4]对气象特征和风电数据的波动过程进行了划分,建立了基于气象特征和风电波动过程相关性的组合预测模型,有效提高了预测精度。文献[5]基于天气移动背景,对NWP中风速波动过程进行了划分,建立了多步风速和风电功率预测模型。基于波动过程的数据挖掘方法可以有效提高风电预测精度,但没有考虑波动过程的划分阈值对预测精度的影响。文献[6]中设定风速、风向和桨距角作为系统输入,转子转速作为系统输出。最后利用模型输出电机的转子转速值进行故障预测。文献[7]对极限学习机的优化采用多目标灰狼优化方法,预测未来短期的风速,有效提高了风速预测的准确性和鲁棒性。
本文探讨风电机组的运行特性,对铁岭某风电场实际运行的50 MW并网风电机组SCADA系统数据进行分析,应用深度置信网络进行建模,并通过实例进行仿真分析。经统计数据验证,风速、温度、湿度和气压等参数可以直接影响机组的出力情况。因此,本文将风速、温度、湿度、气压定为系统输入,将功率作为系统输出,最终利用所建模型输出功率值进行预测。
1 影响风力发电的因素
风的产生是由于空气密度不均匀导致的空气流动,风能是空气流动产生的动能[8]。简单来说,风力发电就是将风能转化为机械能再到电能的过程,机组的输出功率为
(1)
式中:vn为额定风速;Pn为额定功率;Cp为风能利用系数;ρ为空气密度,kg/m3;A为风轮扫过的有效面积,m2;υ为实测风速,m/s。由式(1)可知,输出功率主要与风速、空气密度和被风轮扫过的有效面积有关,主要的影响因素为风速,风功率与风速的三次方成正比,即风速增大1倍,风电功率增加7倍。因此本文将风速作为主要影响因素进行研究分析[9]。
空气密度与输出功率也有直接关系,而根据气象学知识,空气密度与气压、温度、湿度密切相关,关系式为
(2)
式中:p为气压,×100 Pa;t为温度,℃;pw为水气压,×100 Pa。由式(2)可知,压强、温度和湿度会影响空气密度的大小,进而决定风功率的大小。因此,在风电功率预测研究时,应考虑压强、温度和湿度等影响因素[10]。
本次研究综合考虑所有影响因素,将风速、压强、温度和湿度作为预测模型的输入变量。
2 深度置信网络
深度置信网络(deep belief network,DBN)由若干限制的玻尔兹曼机(restricted boltzmann machine,RBM)组成[11],是一种能够随机生成观测数据的模型,该模型是生成模型和判别模型的结合。生成模型将RBM逐层叠加,使DBN模型从输入数据中逐层提取相应的特征,进而得到一些高层次且准确的表达式。判别模型用于达到分类或预测的目的,是有监督的神经网络模型[12]。
RBM是一种随机神经网络,包含2层神经元。一层是显层,也称可视层,由可见单元组成,用于训练数据的输入。另一层为隐藏层,由隐藏单元组成,用作特征检测器。RBM构架如图1所示。
这些单元除了自身调节外,还有0或1两种存在形式:当单元为状态1时,参与网络权值的训练过程;当状态为0时,不参与训练。设显层单元的状态为V,隐层单元的状态为H,则RBM的能量函数为
(3)
式中:ai为第i个显层单元偏置限定值;bj为第j个隐层单元偏置限定值;wij为第i显层单元和第j隐层单元之间的权重;vi、hj为显层和隐层单元的存在形式[13]。
能量函数的大小反映了整个结构框架的状态,训练过程要实现参数寻优的目的,使其与相应的样本数值相吻合,这样能量函数会逐渐趋于稳定,在进行优化的情况下,RBM神经元节点的随机分布规律要与样本数值相同[14]。
在给定可见单元状态时,连接其隐层单元的活化概率为
(4)
在其他条件相同时,限定隐藏层单元不变时,可见单元的活化概率为
(5)
RBM的激活公式为sigmoid函数,此函数在(-∞,+∞)函数值始终在0~1,通过计算可以得出相应节点的激活概率[16],函数图如图2所示。
在训练过程中,每次循环执行命令时,会随机为节点设置1个0~1的随机数,然后将该随机数与激活概率进行对比。只有当随机数大于激活概率时,各个单元才被激活。
在训练预测模型时,随机初始化参数使输出值在稳定值附近上下波动的次数增加,不能突出该模型的代表性特征。因此,需要确定最佳参数值来提高预测模型的性能,此时的参数虽是一个近似值,但在寻优过程中可以减少波动次数,提高模型的预测精度。寻优参数为RBM的显层和隐层节点数、迭代次数和学习效率。参数寻优过程如图3所示。由图3可知,随着迭代次数的增加,训练误差越来越小,逐渐逼近于零,当迭代次数为1000时训练误差最小,因此本次试验设置的迭代次数为1000。
3 建立风电机组功率预测模型
3.1 数据归一化
由于风电系统历史数据包含多个变量,每个变量具有不同的维度和大小,不利于数据特征的分析。为了消除不同维度在数据间的冲击,避免计算节点饱和,减少计算量,需要将不同表征的数据归一化到一定维度上,如图4、图5所示。在本研究中,使用最大和最小归一化方法将每个数据限制在[0,1]范围内。归一化公式如式(6)所示。
(6)
式中:x为待归一化的序列;xmax和xmin分别为该序列的最大值和最小值;x′为归一化结果[17]。
归一化后可更明显看出,几个变量之间的变化程度及风速、温度、湿度、压强等变量之间的相互作用机制,更有利于模型训练的建立。
3.2 建立预测模型
DBN的训练过程由2个阶段组成,一种是正向的训练阶段,将训练集作为输入对RBM进行无监督训练,另一种是反向训练阶段,将上层输出的误差作为BP神经网络的输入进行有监督微调训练,直至预测模型完成参数更新,获得较好的结构参数[18]。预测模型结构如图6所示。
该模型利用归一化后的历史数据作为输入,预测功率作为输出,将多层RBM结构和BP神经网络进行结合,通过误差微调及反馈,提高了整个模型的性能。
3.3 深度置信网络的训练流程
深度置信网络主要是将输入数据和输出数据建立对应关系来完成预测流程。该网络基于经过预处理的数值天气预报数据和风电场的历史数据建立风电场预测模型,该模型前2层由RBM组成,最后1层为BP神经网络输出层,模型的算法流程如图7所示。
具体步骤如下:
a.采集历史数据,并将数据集分为训练集和预测集[19];
b.筛选数据并进行归一化;
c.参数选择,并进行寻优处理;
d.将训练集输入到预测模型中进行训练,调整RBM的学习速率,从而改变训练过程中的权重;
e.当训练误差达到要求时,训练结束,并根据此时的DBN模型参数建立预测模型,将预测集输入到预测模型中进行预测,得出结果。
4 实例仿真分析
4.1 数据提取与预处理
本文试验研究数据来源铁岭风电场SCADA系统。实时采集系统数据库中的数据,会在传输过程中由于设备损坏、人工失误等因素导致数据丢失和冗余,从而降低功率预测的准确性。因此收集到的数据需要进行处理,以保证预测结果的普遍性。异常数据的风速-功率曲线如图8所示。
为了使预测结果在相应的误差范围内,需要对风场中提取的数据进行筛选和处理,具体处理方法如下:
a.数据的时间分辨率为15 min;
b.用相邻数据的平均值代替中间的缺测数据或异常数据;
c.采用风机的额定值代替超过阈值的功率值或小于零的值。
利用以上方法对源数据进行处理,要尽可能保留历史信息,不破坏其本身的性质。
举部分数据点为例,选取3000个风场实际运行的数据点,从图9中发现4个功率缺测点。
对发现的异常数据进行预处理后,样本的功率缺失点消失,得到图10。
经处理过的数据信息更加完善,生成相对标准的风速-功率曲线进行仿真分析,如图11所示。
4.2 预测结果分析
基于图6的算法,建立了深度置信网络的风电功率预测模型。经数据预处理,选取铁岭某风电场提供的2020年5月1日至10月31日每15 min采样1次的数值天气预报数据和风场实际运行数据进行功率预测。将数值天气预报风速、温度、湿度、气压及前一刻风电场功率作为模型的输入,风电场实际输出功率作为输出进行训练和预测。
DBN网络的训练过程首先使用训练集训练模型,其次为验证预测模型的泛化性在测试集上运行模型,测试对新样本的判断能力,风电功率预测结果如图12所示,蓝色的圆形标点代表真实值,红色的星形标点代表输出预测值,均方误差为105.9934。
为进一步说明深度置信网络模型的功率预测效果,在均使用经过筛选后的训练样本前提下,本文利用深度置信网络和BP神经网络模型作比较分析,如图13所示。
为了定量分析2种方法的预测效果,采用横向误差和纵向误差进行对比分析。纵向误差反映了风电机组长期的工作情况,横向误差则说明了预测系统的性质和效能。当分析模型的性能时,纵向误差视为平均绝对误差、均方根误差,横向误差视为相关系数[20]。各指标的公式为
(7)
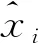

表1 误差比较分析
通过表1可知,深度置信网络(DBN)的预测模型优于BP神经网络预测模型,在采用深层次多隐含层网络结构时,BP神经网络结构的训练能力低于深度学习网络结构,深度学习模型更具优势。在训练过程中对参数寻优,大大提高了预测模型的性能,与BP神经网络相比DBN预测模型的平均绝对误差大大降低,精确度明显提高,DBN预测模型更适用于风电场功率的分析预测。
5 结语
本文结合风电机组的运行特点,将深度置信网络应用到风功率预测中。在训练过程中对RBM参数进行寻优,从而缩短训练时间,减少振荡次数,提高了预测精度。最后通过实例验证了DBN网络模型的预测效果优于BP神经网络,预测功率和实际功率之间的误差较小。在功率平稳变化阶段,预测值与实际值比较接近。因此,可以及时更新风机数据,实时调整误差,实现深度置信网络模型的优化。通过对风电机组功率的预测,可以预知下一时间段的预测值,基于历史数据对风电机组的有功、无功、电压等进行预判,从而可以提前了解并调控风力机的运行状态。
猜你喜欢
现代电力(2022年2期)2022-05-23
护理学报(2022年3期)2022-03-11
铁道建筑(2021年10期)2021-11-08
建材发展导向(2021年13期)2021-07-28
火力与指挥控制(2020年12期)2021-01-22
海峡姐妹(2020年8期)2020-08-25
现代农业科技(2018年11期)2018-08-14
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
风能(2016年11期)2016-03-04
风能(2016年12期)2016-02-25
