
基于图像着色的无限制攻击
2022-11-23 09:06李世宝王杰伟崔学荣刘建航黄庭培
计算机与现代化 2022年11期
李世宝,王杰伟,崔学荣,刘建航,黄庭培
(1.中国石油大学(华东)海洋与空间信息学院,山东 青岛 266580; 2.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580)
0 引 言
深度神经网络(DNNs)目前被广泛应用于各种人工智能系统中,并在图像分类[1]、目标检测[2]、自然语言处理[3]和人脸识别[4]等应用中取得了巨大成功。然而,DNNs易被精心制作的对抗样本欺骗,这些对抗样本是通过在干净样本中加入一些人类难以察觉的扰动制作的[5-6],因此,在部署基于DNN的系统时,许多关键领域都出现了严重的安全和隐私问题[7-9]。对此,对抗攻击和对抗防御成为深度学习和网络安全领域的重要研究内容。近年来,在探索DNN模型的漏洞和建立可用于关键应用的可靠DNN模型方面取得了许多进展。
如图1所示,通过向一张大熊猫的图片添加一个不易被察觉的扰动,可以使分类器将大熊猫错误的分类为长臂猿。这是Goodfellow等人[5]提出的快速梯度符号法(FGSM),是一种经典的对抗攻击方法。

图1 快速梯度符号法(FGSM)
除了FGSM,还有许多对抗攻击方法。一般情况下,根据攻击者对于目标模型的结构、参数等知识的了解程度差异,对抗攻击可分为2大类:黑盒攻击(black-box adversarial attack)和白盒攻击(white-box adversarial attack)。白盒攻击是指攻击者对于目标模型的体系结构等知识完全了解,但是这种情况并不实际,大多数情况目标模型对于攻击者并不可见。黑盒攻击相对于白盒攻击更贴近于现实,即攻击者仅了解目标模型的输入和输出,对模型的结构、参数等知识并不了解。黑盒攻击的主要方法是基于转移的攻击[10-12]和基于分数的攻击[13]。基于转移的攻击是通过训练一个替代模型,利用对抗样本的迁移性实现攻击。基于分数的攻击是通过查询目标模型获得输入的结果,然后通过基于梯度的方法[14-17]或无梯度的方法[18]生成对抗样本。
对抗攻击根据扰动干净样本的强度值不同又可以分为数字对抗攻击和物理世界攻击[19]。对抗攻击所产生的扰动强度值可以是受限的也可以是无限制的[20]。数字攻击产生的扰动大部分是受限的,也有一部分无限制的。通过控制Lp范数产生的受限扰动可以控制每个像素的最大变化(L∞)[21]、扰动像素的最大数量(L0)[22-23]或最大能量变化(L2)[24]。而无限制的扰动通常能造成更大的破坏,通常是通过着色过程任意干扰强度值或操纵图像属性构造[25-28]。物理世界攻击所产生的扰动是无限制的,并且深度神经网络仅接受来自摄像机的输入。
目前大多数对抗攻击方法都是为数字世界所开发,例如C&W攻击[11]、JSMA[22]和AdvGAN[29]等。对于数字世界,受限扰动基本就可以实现对干净样本的扰动从而影响目标模型的分类结果,但是对物理世界而言,深度神经网络仅接受来自摄像机的输入,摄像机难以捕捉到受限扰动,因为受限扰动太小了。因此,物理世界的攻击需要较大的扰动。目前,已经存在一些能产生无限制扰动的攻击方法,例如RP2[30]和AdvPatch[31]等。但是由于无限制攻击是对图像属性的操作,可能会导致一些不自然的变化。
本文设计一种新的灰度图着色方法,通过一个参考图像库结合像素语义标签指导灰度图进行上色工作,并基于该方法提出一种新的攻击方法——图像着色攻击(Colorization Adversarial Attack),将输入的干净样本转为灰度图,利用上述的灰度图着色方法对灰度图进行上色,然后利用经过上色的图像攻击分类器,能够让分类器以较高置信度输出错误的分类结果。
本文工作的主要贡献如下:
1)设计了一种新的灰度图着色方法,并通过了人类观察者的异常测试。
2)基于提出的灰度图上色方法提出了一种新的攻击方法,实验结果表明,图像着色攻击在数据集102 Category Flower Dataset[32]上取得了较好的表现,在干净图片上产生了较大的扰动同时没有出现不自然的变化,并且达到了攻击的目的。
1 相关工作
1.1 对抗攻击
设x是一个高为h,宽为w,通道c为3的干净RGB图片样本,设D(·)为判断样本x分类为y的深度神经网络分类器,即y=D(x)。对干净样本x施加扰动得到对抗样本x′,使D(x)≠D(x′),即y≠D(x′)。这就是对抗攻击的过程。
对抗攻击根据最终目的不同可分为非目标攻击和目标攻击。非目标攻击是攻击者使深度神经网络对于样本最终分类错误即可,目标攻击是攻击者通过一些方法使深度神经网络将样本分类为攻击者期望的类[33]。
对抗攻击根据扰动干净图像的强度值不同又可以分为数字对抗攻击和物理世界攻击,接下来将分别介绍这2类攻击。
1.1.1 数字对抗攻击
数字对抗攻击产生的扰动大部分是受限的,并且可由攻击者直接将样本发送到深度神经网络。数字对抗攻击可以是目标攻击也可以是非目标攻击,它们的扰动由一个范数球‖·‖≤ε决定,有L0、L2和L∞这3种,其中L2和L∞是最常见的。比如经典的快速梯度符号法(FGSM)、基本迭代法(BIM)[28]、投影梯度下降法(PGD)[34]以及用于可转移攻击的跳跃梯度法(SGD)[35]。
在数字对抗攻击中,还存在着一部分扰动是无限制扰动的攻击方法,这些攻击方法一般是对于样本图片的属性进行修改和替换,比如功能性对抗攻击[36]打破传统的Lp约束攻击,将图像进行全局一致变化,通过颜色的变化实现对抗攻击。并且与Lp范数攻击结合,实现更强大的攻击。ColorFool[20]利用语义分割确定人眼敏感区域和不敏感区域,对人眼敏感区域施加有限的颜色改变,对不敏感区域施加较大的颜色改变。tadv[26]使用VGG19网络[37]来提取纹理特征,通过向干净图像中添加提取的纹理特征实现对抗攻击,具有极强的隐蔽性[25]。利用差分进化算法[38],操纵图像亮度、对比度等属性实现攻击。这些攻击方法不同于Lp约束攻击,所产生的的扰动也远大于Lp约束攻击所产生的扰动。但是这些攻击大多会产生对人眼来说不自然的变化,因此,不适合用于较为复杂的场景。
还有一部分数字对抗攻击利用了生成对抗式网络(GAN)生成对抗样本[39],但是通过GAN很难实现目标攻击,因为生成对抗样本的过程一般很难控制。
1.1.2 物理世界攻击
一项研究表明,通过打印和使用手机相机捕捉数字对抗攻击的对抗样本仍然是有效的[40]。但是,大部分数字对抗攻击其产生的扰动较小,对于现实世界的摄像头不起作用,而且对于物理世界攻击来说,深度神经网络仅接受来自摄像机的输入,攻击者无法决定对抗样本的出现与否。对于以上的情况,扰动的形式必须是无限制的扰动,并且深度神经网络所接受的来自摄像机的图像是无需攻击者攻击生成的对抗样本。针对以上情况,AdvPatch[31]和RP2[30]具备以上所提到的特点,是实现物理世界攻击的选择。
还存在一些其他的攻击,例如使用眼镜镜架[40]、T恤[41]等,它们可以欺骗人脸识别系统或一些检测器。但是这些物理世界攻击都会产生非常大的扰动来增加攻击的成功率,这将导致巨大且不现实的扭曲,大大地降低了生成的对抗样本的隐蔽性。
攻击需要合适的扰动大小来实现攻击的隐蔽性。对于物理世界来说,很难确定一个适当的扰动大小使视觉上尽可能隐蔽和对抗强度适中。对于无限制扰动,一个强大且隐蔽性强的伪装机制仍然是一个需要思考的问题。针对这种情况,AdvCam[19]利用风格转换技术实现物理世界的无限制攻击,从卷积神经网络(CNN)学习的特征将图像的风格信息分离出来,然后将这些信息重组到图像中生成对抗样本以实现对抗攻击。
1.2 灰度图着色
灰度图仅有一个通道,而着色是为目标灰度图像的每一个像素分配一种颜色,使其最终恢复为3通道的图像。考虑着色在多种应用中的重要性,比如黑白照片、视频的上色[42],协助漫画家对黑色漫画进行上色[43]等,灰度图着色迅速成为计算机视觉的一个研究热点。
早期灰度图着色过于依赖手动标注,若是为黑白视频着色,完全手动为每一帧着色是一项非常繁琐且消耗极大的工作,因此文献[44]提出了一种半自动着色方法,手动为关键帧着色,基于运动的颜色传播进行整部视频的着色。随着技术的发展,越来越多的着色方法减少了对手动的依赖,文献[45]提出了第一个基于深度学习框架的全自动着色模型,后续的研究工作也更多是结合深度学习框架研究全自动着色方法[46-49]。
2 图像着色攻击
在本章中,首先概述提出的灰度图着色方法,包括参考图像库的设计和着色方法介绍,然后介绍结合上述着色方法提出的无限制攻击方法。
2.1 着色方法
2.1.1 参考图像库设计
本节主要阐述参考图像库的设计,由于需要利用最终着色的图像实现无限制攻击,因此参考图像库的图像选择对最终着色的结果有着重要的指导作用。
实验中,将102 Category Flower Dataset在保持原有标签的同时对数据集的每一个类别标注一个的错误的标签,或加入其他数据集的图像并标注,将这个错误的标签称为假标签,以此利用这个错误的标签指导拥有该标签类别的灰度图进行上色。为了使数据集中每一类都有一个对应的参考图像库,因此选定了102张参考图像和102张备选参考图像。
如图2所示,左图为设计的参考图像库中图像,正确标签为yellow iris,但是在重新标注标签的工作中,左图被标注为canterbury bells。右图为数据集中的样本,正确标签为canterbury bells,目的是在实验中利用左图指导右图的灰度图进行上色,利用得到的着色后的图像攻击分类器实现成功的无限制攻击。

图2 参考图像和干净样本
在标注过程中,为了尽可能让被指导上色的图像最终既能成功欺骗分类器也能符合人眼观察的习惯,不会被人类观察者感觉到异常,对于参考图像库的设计遵循以下规则:
1)参考图像应确保被指导上色的图像的颜色是符合人眼习惯的,也就是说,通过参考图像给灰度图上色后,输出的图像整体颜色应该是正常的,不会被人眼观察者感觉到异常。
2)如果选择其他数据集的图像加入参考图像库,应确保这个图像在分类器分类任务中是单分类任务而不是多分类任务。
最终,在以上规则指导下,设计了一种用于指导灰度图着色的参考图像库,这个图像库有2种标签,一种是图像原本的标签,另一种是为了指导某一类图像上色而进行的标注。第二种标签的标注工作量较大,在以后的工作中将会探究如何利用深度神经网络自动进行标注。
2.1.2 着色方法介绍2.1.2.1 概述
给定一组样本E={G,R},其中,G代表输入的灰度图像,R代表其假标签和该灰度图标签相同的参考图像。设一个从灰度到颜色的映射函数F(θ,Gp),其中θ是要从E中学习到的F的参数,Gp是在灰度图像中每个像素处提取到的像素语义标签(将在后面介绍)。这个函数的作用是将G中每个像素处提取到的特征映射到R中相应的色度值,目的是实现最终的灰度图着色工作。
在实际工作中,深度神经网络输入的是在每个像素处提取到的像素语义标签的维度。因为本文使用的是YUV颜色空间,YUV颜色空间可以使3个坐标轴之间的关联性最小,因此最终深度神经网络输出的是对应像素的色度值,也就是U和V这2个颜色通道,该色度值和亮度结合最终会获得颜色。
在前面的描述中,设定了映射函数为F(θ,Gp),设参考图像相应像素的色度值为Rp,据此新定义一个灰度到颜色的映射函数为Rp=F(θ,Gp)。通过解决以下最小二乘法问题来学习参数θ:
(1)
其中,n是从E中得到的训练像素总数,γ为F(θ,Gp)的函数空间。
深度神经网络通常由一个输入层、多个隐藏层和一个输出层组成,一般第一层是输入层,最后一层是输出层,而中间的层都是隐藏层,层与层之间是全连接的。输出层神经元可以不止一个,可以有多个输出,这样模型可以灵活应用于分类、回归、降维和聚类等。在本文模型中,深度神经网络的输入层神经元数量等于提取到的像素语义标签的维数,输出层神经元数量是2个,分别为U和V颜色通道。中间的隐藏层可以增强模型的表达能力,相邻层之间都有一个权重ϖ和一个偏置项b相关联。实验中,训练后的神经网络中的一对神经元之间连接的权重ϖ为前面提到的待学习的参数θ。图3是本次实验的网络结构和大致流程图。
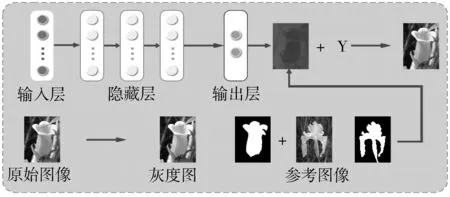
图3 本次实验的网络结构和大致流程图
实验中,训练时记录灰度图每个像素的像素语义标签和对应参考图像像素的色度值,验证时,输入每个像素的像素语义标签完成上色。
2.1.2.2 像素语义标签
卷积神经网络(Convolutional Neural Networks, CNN)在图像分类和图像检测等领域取得了广泛应用。CNN提取的特征对图像分类、图像中所包含的物体以及物体的大致位置的确定很有效[50]。因为采用了感受野(receptive field),所以对图像特征的提取更多的是以“一小块临域”为单位的,因此很难做到对图像进行像素级的分割,不能很精确地划定物体具体的轮廓边界[51]。
针对CNN很难做到对图像进行像素级分割的问题,Long等人[52]提出了全卷积神经网络(Fully Convolutional Networks, FCN)。其模型结构非常简单,使用VGG网络等对图像特征进行提取,移除最后的全连接层,使用上采样的转置卷积层将多次下采样的特征图恢复到和原图一样的大小,然后对每个像素生成一个分类的标签。
实验中由于使用的是单分类任务数据集,因此采用FCN对每个像素的标注工作变得较为简单。方法是在图像每个像素的位置分别计算一个N维的概率向量,其中N是可能的类别的数量,计算当前像素属于相应类别的概率并进行标注。在本文实验中仅有2个类,因此N为2,分别为图像的真实标签的类和其他。
实验中,首先对要着色的图像和对应标签的参考图像分别提取像素语义标签,这里对参考图像提取像素语义标签使用的是参考图像自身真实的标签,而非为了指导上色重新标注的标签。另外,灰度图自身可能会影响分类器的决策,这是因为灰度图会失去一些帮助分类器进行判断的特征,所以得到的像素语义标签可能存在不精确的现象,这也是未来工作要解决的问题之一。
在对输入图像得到像素语义标签后,由于在类别边界区域存在着不精确的问题,因此实验中引入了边缘保持滤波器[53]对边界进行平滑处理。
如图4所示,经过平滑处理确定了类别边界,同时输出的还有像素语义标签,并将其作为深度神经网络的输入进行接下来的工作。

图4 实验中通过输入图像进行分割确定边界
最终,输入的像素语义标签在经过隐藏层后输出对应像素的色度值,也就是U、V分量,将U、V分量与Y通道结合后转为RGB颜色模型,就会得到上色后的图像,下一节将介绍如何利用上色后的图像对深度神经网络进行攻击。
2.2 攻击方法
前面介绍了一种利用参考图像库指导灰度图进行上色的方法,接下来本节将介绍如何利用完成上色的图像进行攻击。
在得到上色后的图像后,对于接下来的攻击实验相当于制作了一组对抗样本。从对抗样本的类型来说,图像着色攻击可以应用于数字对抗攻击,可以实现非常强大的攻击。
同样的,图像着色攻击也可以应用于物理世界的攻击,上文曾介绍过传统的Lp约束攻击产生的扰动非常小,摄像机等图像接收设备难以捕捉扰动,因此不适合针对物理世界的攻击。而图像着色攻击所产生的的扰动远大于传统的Lp约束攻击产生的扰动,属于无限制扰动,可以被摄像机等捕捉到。

图5 因为突变产生的外表颜色变异的生物
由于物理世界攻击的分类器所接受的样本都是来自摄像机或其他接收图像的设备,因此假定本文提出的图像着色攻击是因物理世界中因为突变产生的外表颜色变异的生物(见图5)、因为彩色灯光照射而导致人类视觉颜色改变的交通指示牌和特殊环境下图像接收设备接收到的图像(如沙尘暴、空气污染)等许多特殊图像导致的分类器错误输出。
在得到对抗样本后,将对抗样本送入深度神经网络进行分类任务,最终实现黑盒、非目标、无限制攻击。
3 实验评估
在本章中,介绍了实验的设置,包括所用的数据集、网络模型、评估指标等,然后介绍了实验结果以及展示了图像着色攻击生成的对抗样本,最后是人类感知研究实验。
3.1 实验设置
3.1.1 数据集
本文实验使用102 Category Flower Dataset数据集,数据集拥有102种花卉类型,均为英国常见的花。每个类由40~258张图像组成。图像具有大尺度、姿态变化和光线变化。除此之外,还有类别内差异很大的类型和几个很接近的类型。本文使用的数据集在加载后均通过预处理以符合实验要求。
3.1.2 分类器
本文实验使用的网络模型为ResNet-18、ResNet-50[1]、AlexNet[54]和SqueezeNet v1.1[55]。本文使用Resnet-18和ResNet-50作为被攻击的深度神经网络对比CAA在同构结构下的效果。使用AlexNet和SqueezeNet v1.1检验了图像着色攻击在异构结构下的迁移性。以上几种网络为了实验要求均在实验前进行了微调。
3.1.3 评估指标
本文使用2种评估指标,即攻击成功率(SRA)和人类感知研究(HPSR)。SRA表示欺骗分类器的对抗样本数量与图像总数之间的比值,HPSR表示研究人类观察者对于对抗样本是否异常的感知结果。
攻击成功率的计算方式为:
SRA=1-SR
(2)
其中,SR表示分类正确率,即被分类器正确识别的干净样本的数量占总样本数量的比值。也就是说,对于分类器未正确识别的样本数量占总样本的比值,即为攻击成功率。
3.2 实验结果
本节介绍图像着色攻击送入深度神经网络进行分类任务的一系列实验结果,包括对不同网络模型的攻击结果以及图像着色攻击的迁移性,并且展示了使用实验生成的对抗样本。
3.2.1 实验结果对比
表1表示在102 Category Flower Dataset数据集上得到的图像着色攻击对ResNet-18、ResNet-50、AlexNet和SqueezeNet v1.1的攻击成功率以及干净样本在2种网络模型下的分类成功率。SR表示上文提到的分类正确率。未标注SR的数字均为SRA,即上文提到的攻击成功率,CAA表示图像着色攻击。可以看出,图像着色攻击在ResNet-18网络模型和网络模型上取得了较好的攻击效果,达到了较高的攻击成功率,并且所产生的的对抗样本没有产生异常的、不符合人眼观察习惯的情况。
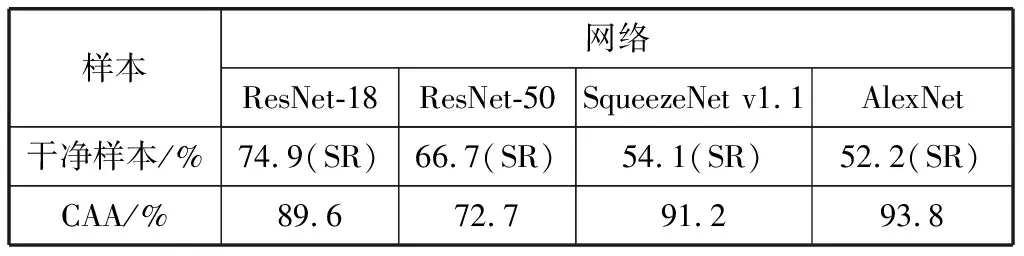
表1 CAA和干净样本在不同分类器中的实验数据
对比ResNet-18和ResNet-50网络,可以看到攻击成功率在同构结构下,层数更多的ResNet-50下图像着色攻击得到的攻击成功率有一定的降低,但是仍然保持着较高的数值。
另外,使用SqueezeNet v1.1和AlexNet作为被图像着色攻击施加攻击的网络模型时,图像着色攻击都取得了不错的效果,攻击成功率均在90%以上。从不同网络得到的攻击成功率来看,图像着色攻击具有不错的迁移性,即便在不知道目标网络模型参数、结构等知识的情况下,也能进行较好的攻击。
3.2.2 对抗样本展示

图6 原始图像、灰度图和对抗样本
如图6所示,Ground truth表示原始图像,Grayscale表示原始图像的灰度图,CAA examples表示图像着色攻击生成的对抗样本。对输入图像转灰度图后重新上色得到的图像上色攻击的对抗样本,可以看到虽然对抗样本与干净样本相比,分类器重要决策区域的颜色发生了较大变化,但仍然符合人眼的观察习惯,整体没有出现较大的扭曲,没有出现可能导致人眼观察出异常的颜色,具有较好的隐蔽性。
图7表示的是同一图像在不同参考图像下的着色情况。第一排第一张图片为原始图像,第二、三张分别为图像着色攻击为根据原始图像生成的对抗样本,第二排第一张图像为原始图像的灰度图,第二、三张分别为第一排的第二、三张图像的参考图像。可以看出,参考图像不同,最终生成的对抗样本也不相同。

图7 同一样本不同参考图像下的着色情况
如图8所示,图8(a)为数据集ImageNet[58]中某一类的图像,图8(b)为ColorFool根据图8(a)生成的对抗样本,图8(c)为CAA根据图8(a)生成的对抗样本,其中图8(c)右下角为CAA的参考图像。可以看出,CAA生成的对抗样本由于选择了合适的参考图像,对于人眼较为敏感的区域(比如人的皮肤)的颜色变化并不明显,并不影响观察者的观感。

图8 CAA与ColorFool生成的对抗样本对比
除了数字世界,在物理世界中,存在着非常多因为特殊情况而导致的颜色异常的物体,往往这些样本的获取都不容易,因此在缺乏相应训练的情况下,这些异常物体很可能会欺骗分类器导致分类器输出错误的结果。因此,这些例子不仅展示了图像着色攻击的隐蔽性,而且也表明了对深度学习系统的威胁是无处不在的。在许多情况下,不仅深度神经网络,这些对抗样本对人类观察者来说都很难被察觉。
3.3 人类感知研究
除上述实验外,本文还进行了人类感知研究(HPSR),邀请了96名人类观察者,将根据干净图像利用图像着色攻击生成的对抗样本呈现给人类观察者,要求他们在观察图像后在3个选择中做出单项选择,这3个选择分别为:没有异常、有轻微异常和有较大异常。最终,通过96名人类观察者观察后,有82人选择了没有异常,占总人数的85.4%,14人选择了有轻微异常,占总人数的14.6%,0人选择了有较大异常,占总人数的0%。选择了有较小异常的14人中,有5人直接指出了对抗样本颜色的异常,5人不能指出具体异常。这也证明了图像着色攻击生成的对抗样本不仅可以欺骗深度神经网络,同样对于人类观察者也很难察觉。
4 结束语
本文提出了一种新的灰度图着色方法和一种新的对抗攻击方法,即基于参考图像库根据像素语义标签指导灰度图上色,使用着色后的灰度图送入深度神经网络实现攻击。本文提出的攻击方法通过实验证明了攻击的有效性,并且证明了图像着色攻击具有较好的迁移性,同时使用图像着色攻击生成的对抗样本也具有较好的隐蔽性。此外,如何针对图像着色攻击进行防御,使深度神经网络对颜色变化更加敏感以及文中提到的一系列问题是接下来需要研究的内容。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
今日农业(2021年9期)2021-11-26
北京航空航天大学学报(2021年7期)2021-08-13
今日农业(2020年16期)2020-12-14
数学物理学报(2019年4期)2019-10-10
数学杂志(2019年1期)2019-02-18
电影(2018年10期)2018-10-26
计算机应用(2017年4期)2017-06-27
贵州师范学院学报(2016年3期)2016-12-01
光学精密工程(2016年4期)2016-11-07
