
基于TasNet的单通道语音分离技术的研究综述
2022-11-23 09:10朱定局
计算机与现代化 2022年11期
陆 炜,朱定局
(华南师范大学计算机学院,广东 广州 510631)
0 引 言
在现实世界中,语音交流通常发生在复杂的多人环境中。在此条件下运行的语音处理系统需能够分离不同说话者的语音,而这项任务难以在机器中建模。近年来,与传统的语音分离方法相比,利用深度学习的语音分离方法显著改善了此问题的现状[1-6]。传统的神经网络语音分离算法在过程一开始会通过短时傅里叶变换(Short-Time Fourier Transform, STFT)来创建混合语音信号的时-频域(Time-Frequency Domain)表征,然后利用对应于时频表征的掩膜将声源的单元盒进行分离,最后通过逆短时傅里叶变换(Inverse Short-Time Fourier Transform, ISTFT)来恢复分离后的语音信号。在这个框架中存在以下几个问题:
1)无法确定傅里叶变换是最优的语音分离变换方法。
2)由于短时傅里叶变换将语音信号转换至复数域,分离算法需同时处理语音信号的幅度和相位信息,而相位信息的修改难度较大,所以大多数方法仅通过计算每个语音信号源的时频掩膜来修改短时傅里叶变换的幅度,并使用经掩膜操作后的幅度谱图与语音混合信号的原始相位信息进行合成,这使得语音分离的性能存在上限。尽管存在若干系统[7-8]是利用相位信息来设计掩膜的,但由于分离过程存在不准确性,因此语音分离的性能上限仍然存在。
3)短时傅里叶变换域中的语音分离需要高频分辨率,但这将导致时间窗口长度变大,例如,时间窗口长度在语音研究领域中一般超过32 ms[3-4],在音乐分离领域中一般超过90 ms[9]。由于语音分离系统的最小延迟时间受制于短时傅里叶变换的时间窗口长度,因此这个框架会限制需要低延迟要求的系统或设备的使用与发展。解决这些问题的一种方法是在时域中对语音信号进行建模。
近年来,在时域中对语音信号进行建模的方法已成功应用于语音识别、合成和增强等任务[10-14],但尚未利用深度学习的方法进行波形级的语音分离。Luo等人[15]在2018年提出了时域音频分离网络(Time-domain audio separation Network, TasNet),这种神经网络使用编码器-解码器的框架直接对混合语音信号进行建模并对编码器的输出执行分离操作。在这个框架中,混合波形由N个基信号的非负加权和表示,其中,权重是编码器的输出,基信号是解码器的滤波器。分离操作是通过从混合信号的权重中估计对应于每个信号源的权重来完成的。因为权重值是非负的,源权重的估计值可以通过公式化操作找到表征每个信号源相对于混合语音信号权重贡献度的掩膜,这个掩膜类似于STFT系统中所使用的T-F掩膜。然后利用经学习得出的解码器重建声源波形。由于TasNet框架可以对小至5 ms的波形段进行操作,因此该系统可以以极低的延迟进行实时的语音分离操作。除了具有较低的延迟外,TasNet较基于短时傅里叶变换的系统有着更优的性能,其在不需要实时处理语音信号的应用中,也可以利用非因果的分离模块,结合来自整个声音信号的信息,从而进一步提高性能。本文接下来将从横、纵2个方向的对比来研究基于TasNet框架的单通道语音分离研究进展,并阐述目前基于TasNet的单通道语音分离模型的局限性,最后从模型、数据集、说话人数量以及如何解决复杂场景下的语音分离等层面对未来的研究方向进行讨论。
1 TasNet与基于深度学习的其他传统方法的比较研究
“语音分离”这一概念源自经典的鸡尾酒会问题,其目标是在复杂的多人说话环境中,将每个目标说话人的对应语音信号分离出来。深度学习的语音分离算法在单通道语音分离领域已经超越了传统信号处理算法,故本文将不探讨非深度学习的语音分离方法。
语音信号在时域有很强的时变性,在一段时间内会呈现出周期信号的特点,而在另一段时间内呈现出随机信号的特点,或者呈现出两者混合的特性。若将语音信号转换到频域或者其他变换域,则语音信号在时域中表现不明显的信号特征在变换域上将表现得明显,这样就可以对表现出的信号特征进行分析。
由于语音信号的时变性,研究者常用短时傅里叶变换方法进行语音信号的处理。具体做法是首先选取适当的窗函数将语音信号进行分帧处理,然后将各帧语音信号分别进行傅里叶变换。语音信号分帧后,因每帧时间较短,则可将每帧的信号看作是平稳的,这样便可观察语音信号的频谱图了,频谱图可较好地反映出语音随时间、频率的变化特性。同时经短时傅里叶变换后,语音信号为二维信号,可以将其看作一个二维矩阵,以便于后续的语音信号处理。目前,比较典型的基于深度学习的语音分离方法有深度聚类(Deep Clustering, DPCL)、置换不变训练(Permutation Invariant Train, PIT)以及本文将重点介绍的时域语音分离网络(TasNet)。表1展示了深度聚类、置换不变性训练及时域分离网络的主要特点。
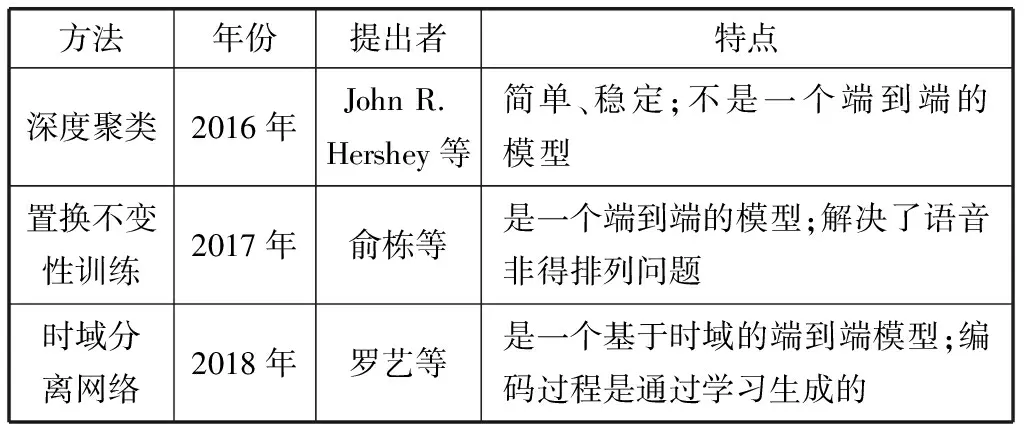
表1 深度聚类、置换不变性训练及时域分离网络的比较
深度聚类方法是MERL实验室Hershey等人[16]于2016年提出的语音分离方法。这一方法的基本思路是将混合语音信号转化为频谱图,将频谱图上每个时-频块(TF)通过一个深度神经网络映射到一个特征空间,使得在该特征空间中各个TF块的相邻矩阵与依实际标注得到的相邻矩阵尽可能相似。基于这一特征空间,对混合语音的TF块进行聚类,再将同一类的TF块选出来作为一个声源的频谱,即可实现语音分离。深度聚类的性能和泛化性较好,但缺点是它不是一个端到端的方法。
置换不变训练是Yu等人[17]于2017年提出的一种端到端的语音分离方法。PIT模型的设计思想是当模型给定时,就可以给出一个确定的分离后的语音排列,并选择可以使得损失函数最小化的排列方式,反之,当排列给定时则可以训练模型,因此可在实验最初随机初始化一个分离模型,在得到一个排列后,更新模型,反复迭代至收敛。该方法有效地解决了基于深度学习的语音分离技术中长期存在的标签排列问题。
时域分离网络是由Luo等人[15]在2018年提出的一种基于时域的端到端的语音分离方法,即直接输入混合语音信号,不经过短时傅立叶变换(STFT)从而得到声音特征。传统的基于时-频域的语音分离方法因STFT而存在相位不匹配的问题,TasNet则既可以利用幅度信息也可以利用相位信息。TasNet的结构由编码器、分离网络和解码器组成,与基于时-频域的语音分离方法相比,编码过程不是固定的而是通过网络学习生成的,信号通过分离网络得到相应目标者个数的掩膜,再经学习得到的掩膜矩阵与编码器输出矩阵进行点乘后,最后经过解码器输出分离后的语音信号。
2 基于TasNet的语音分离方法的现状与发展
2.1 基于时域的全卷积模型(Conv-TasNet)
基于时-频域的语音分离方法存在相位不匹配的问题,即在语音分离的最后阶段中,增强的幅值谱和原始混合的相位谱进行逆短时傅里叶变换后会对语音分离的性能产生一定的影响,Wang等人在2018年和2019年提出了WA-MISI[18]和Sign prediction net[19]等方法,以解决语音分离中相位补偿的问题,Liu等人[20]在2019年提出了Deep CASA的方法,以解决在复数谱中进行语音分离的问题。解决相位不匹配问题的另一种解决办法就是在时域上进行语音分离,基于时域的分离系统与将音频的时频表示作为输入的系统有所不同,时域音频分离网络通过学习产生自适应的前端,用时域卷积的非负自动编码器替代时频域表征,即利用时域的波形点作为特征输入,并同样在时域上输出波形点,因为时域上包含了语音的所有特征,所以这种端到端的训练模型可以避免相位不匹配的问题,从而突破语音分离问题中的一大瓶颈。
Luo等人2018年提出的TasNet是一种直接对混合声音波形进行操作的深度学习语音分离系统(模型示意图如图1所示),它包含3个部分:用于估计混合权重的编码器、分离模块和用于重建源波形的解码器。编码器和解码器模块的组合为混合波形构建了一个非负的自动编码器,其中非负权重值是由编码器经过计算得出的,并且基础信号是解码器中的一维滤波器,分离模块中使用了深度长短期记忆(Long Short-Term Memory, LSTM)网络,最终通过在混合权重矩阵中对应的信号源掩膜来解决在时域上的语音分离问题。该研究成果相较于基于短时傅里叶变换的系统而言,其分离速度提高了6倍,具有更好的语音分离性能。同年,Luo等人[21]开展了TasNet在语音去噪问题上的工作,他们通过将去混响问题类比为语音分离问题,进而表述成直接路径与混响分离的去噪问题,最终证明,TasNet在频谱图输入方面优于深度LSTM基线,并且通过在卷积自动编码器中调整步幅的大小进一步提高了语音分离和去混响任务的性能。图1是TasNet模型示意图。
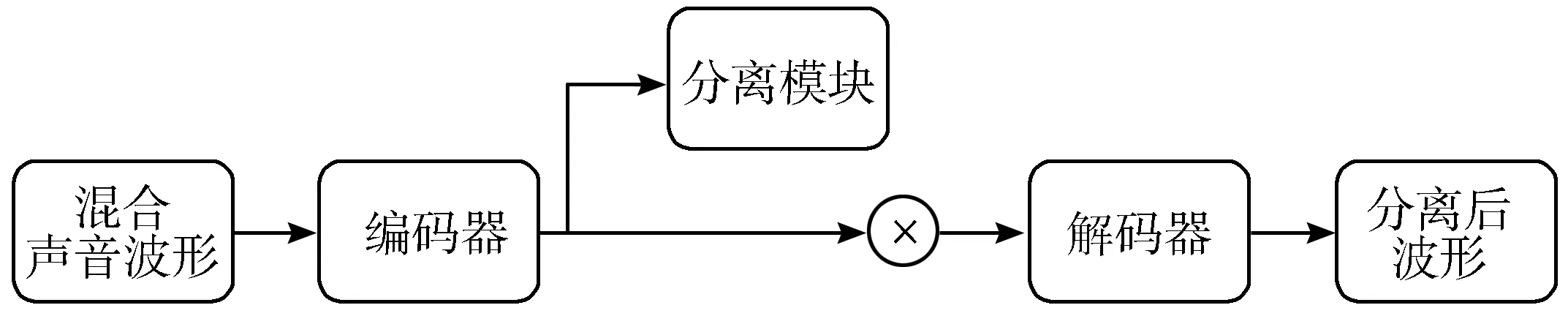
图1 TasNet模型示意图
尽管TasNet在因果和非因果实现方面都优于基于时-频域的语音分离方法,但在分离模块中使用深度长短期记忆网络会限制原始的TasNet框架。原因如下:1)在编码器中选择较短的波形段作为输入会增加编码器输出的长度,这使得基于LSTM网络的训练难以被管理;2)深度LSTM网络中所使用的大量参数会增加其计算的成本,从而限制了原始TasNet框架在诸如嵌入式系统、可穿戴听力设备等低资源、低功耗平台的适用性;3)LSTM网络具有对长期时间的依赖性,这通常会影响语音的分离精度。为了缓解原始TasNet框架的局限性,Luo等人[22]在原有基础上于2019年进一步提出了全卷积的TasNet(Conv-TasNet)模型,即在语音处理的所有阶段仅使用卷积层。受时间卷积网络(Temporal Convolutional Network, TCN)模型[23-25]的启发,Conv-TasNet中使用TCN架构来代替深度LSTM网络进行分离步骤,为了进一步减少参数的数量和计算的成本,Luo和Mesgarani等人用深度可分离卷积[26-27]代替了原始卷积。最终证明,Conv-TasNet在因果和非因果实现中显着提高了基于LSTM神经网络的TasNet的分离精度。此外,Conv-TasNet的分离精度超过了在信号失真比(Signal Distortion Ratio, SDR)和平均意见得分(Mean Opinion Score, MOS)测量评判标准下的理想时-频域幅度掩膜如理想二值掩膜[28](Ideal Binary Mask, IBM)、理想比率掩膜[29-30](Ideal Ratio Mask, IRM)和维纳滤波器掩膜[7](Wiener Filtering Mask, WFM)等的性能。
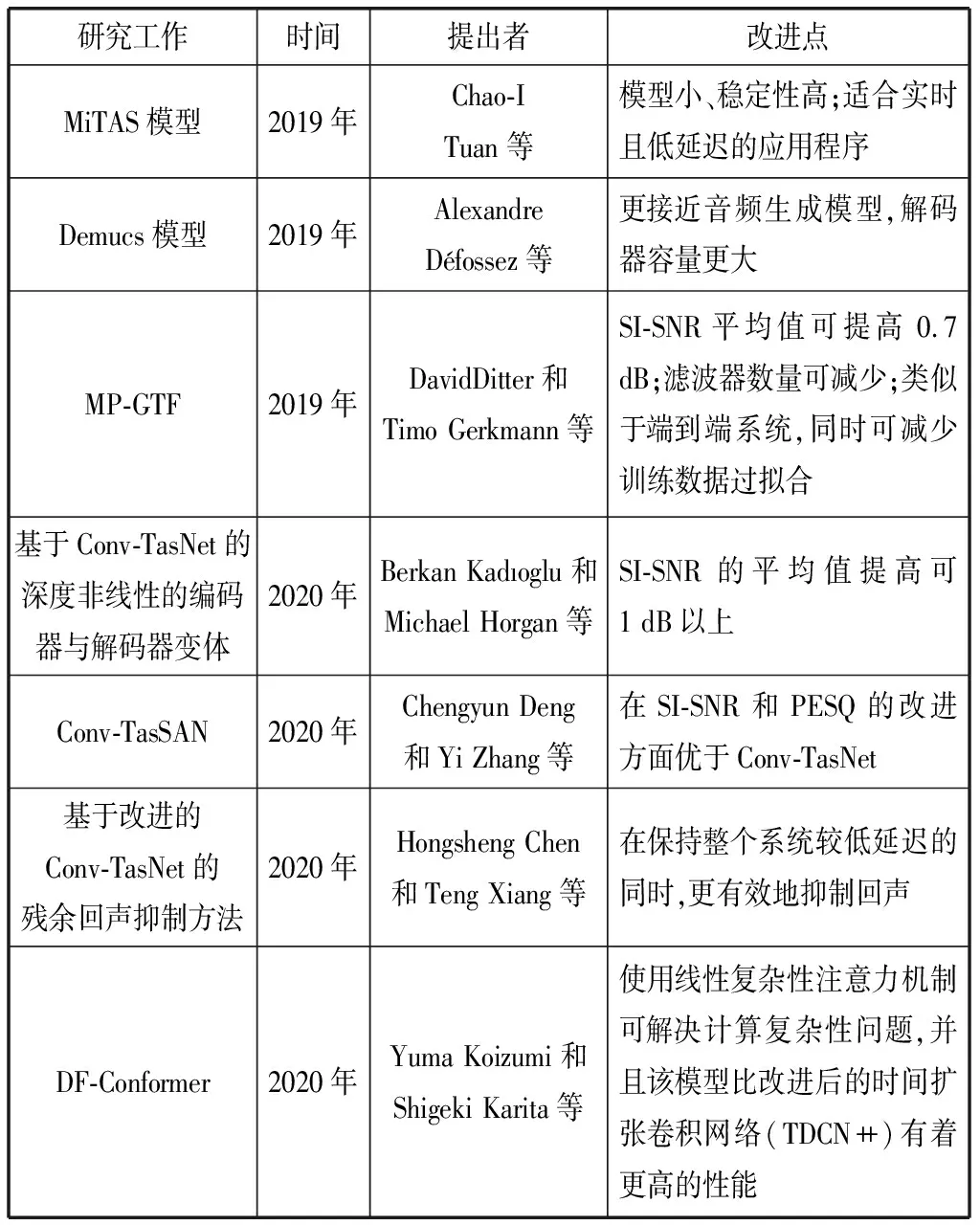
表2 针对Conv-TasNet的一些改进工作
针对Conv-TasNet,有诸多学者展开了相关的改进工作(如表2所示)。Tuan等人[31]于2019年提出了Mini-TasNet(MiTAS)模型,MiTAS模型对混合音频中背景噪音和起始点的干扰具有鲁棒性。与TasNet和Conv-TasNet相比,MiTAS能够减少4倍的模型大小,同时有着更高的语音分离稳定性,其模型更适合实时、低延迟的应用程序;Conv-TasNet被证实存在人工的操作,FaceBook人工智能实验室的Défossez等人[32]于2019年提出了一种基于掩膜方法的波形到波形的替代模型Demucs,其架构更接近于音频生成模型,解码器容量更大。Défossez等人推测,当信息在混合仪器中丢失且不能简单地通过掩膜恢复时,该方法将发挥用处;由于Conv-TasNet的训练编码器与听觉滤波器组存在相似性,Ditter等人[33]采用确定性GammaTone滤波器组,于2020年提出了确定性多相伽马色调滤波器组(MP-GTF),以替换Conv-TasNet中的学习编码器,研究表明,当Conv-TasNet中的学习编码器被MP-GTF取代时,整体系统性能不会降低,相反,该模型可以让SI-SNR的平均值提高0.7 dB。此外,在不会影响整体性能的情况下,MP-GTF滤波器的数量可以从512个减少到128个。该模型整体性能类似于端到端系统,同时可减少训练数据的过度拟合;Conv-TasNet模型主要关注分离器,其编码器和解码器为浅层线性算子,Kadioglu等人[34]于2020年提出了基于Conv-TasNet的深度非线性的编码器与解码器变体。研究表明,编码器与解码器的变体可以将SI-SNR的平均值提高1 dB以上;受生成对抗网络(Generative Adversarial Networks, GAN)在语音增强任务上的成功应用的启发[35-36],Deng等人[37]于2020年提出了一种名为Conv-TasSAN的新型分离对抗网络,其中分离器是采用Conv-TasNet架构实现的。鉴别器目标使用客观语音质量评估(Perceptual Evaluation of Speech Quality, PESQ)或可短时客观可懂(Short-time Objective Intelligibility, STOI)语音质量评价方法,以提高由分离器建模的源分布的准确性。研究证明,通过在WSJ0-2mix数据集上的实验表明,Conv-TasSAN在SI-SNR和PESQ方面优于Conv-TasNet;由于回声和远端信号之间的非线性关系,线性自适应滤波器不能完全去除声学回声,因此通常需要一个后处理模块来进一步抑制回声,Chen等人[38]于2020年提出了一种基于改进的Conv-TasNet的残余回声抑制方法,该方法采用线性声学回声消除系统的残余信号和自适应滤波器的输出,为Conv-TasNet形成多个流,在保持整个系统具有较低延迟性的同时,有效地抑制了回声。研究证明,仿真结果验证了所提出的方法在单方通话和双方通话情况下的有效性;Conv-TasNet的去噪性能和计算效率主要受掩膜预测网络结构的影响,Koizumi等人[39]于2021年提出了一种基于Conformer的时域语音增强网络DF-Conformer,研究者旨在通过将Conformer集成到新的掩码预测网络中来提高Conv-TasNet模型的顺序建模能力。为了提高计算复杂度和局部顺序建模,研究者使用线性复杂度注意力机制和一维扩张可分离卷积扩展了Conformer。研究证明,使用线性复杂性注意力机制可解决计算复杂性问题,并且DF-Conformer模型比改进后的时间扩张卷积网络(TDCN++)有着更高的性能。
2.2 基于时域的双路径循环神经网络模型(DPRNN-TasNet)
由于Conv-TasNet使用固定的时间上下文长度,即Conv-TasNet没有办法整合整句话的信息,它只能关注到所切割的固定语音长度范围内的信息,因此在需要长期跟踪某个目标说话者语音信息的场景中,尤其是在混合音频中存在长时间停顿的情况下,该方法可能会失效。为了解决这个问题,Luo等人[40]在2020年提出了一种双路径循环神经网络(Dual-Path RNN, DPRNN)的语音分离方法(模型示意图如图2所示)。
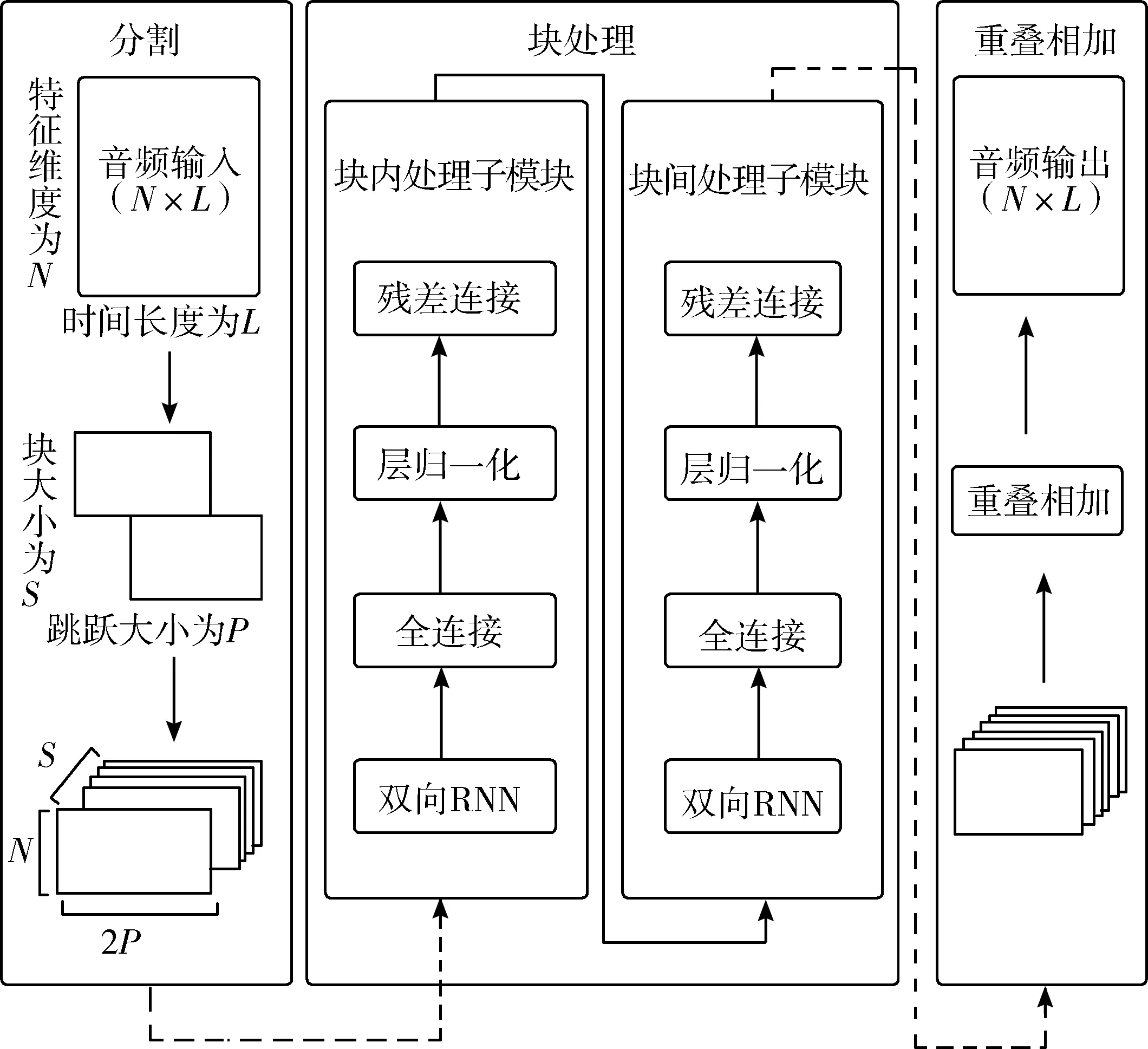
图2 DPRNN模型示意图
DPRNN不仅会考虑所切割语音的长度信息,同时也会整合目标说话者整句的信息,使得语音分离网络可以关注到更长时间的语音信息。传统的循环神经网络(RNN)无法有效地对由大量时间步长组成的输入序列进行建模,而一维卷积神经网络(1-D CNN)在其感受野小于序列长度时无法进行话语级别的序列建模。DPRNN可在深层结构中组织RNN层以对长时间序列进行建模。DPRNN将长时间序列的输入拆分成块并不断迭代块内和块间操作,其块处理过程为:将通过分割处理后得到的三维向量送入连续堆叠的DPRNN中,每个DPRNN的输入及输出维度保持一致,每个DPRNN中,输入的三维向量首先经过块内RNN,再将每个块分别作为输入送进双向RNN中,以进行局部的建模,紧接着将上述输出作为输入经过全连接层、层归一化和残差连接之后送入块间RNN,块间RNN与块内RNN类似,只是RNN的输入是每个时间步的所有块,而不是一个块的所有时间步,以此来进行全局建模,前一个DPRNN的输出结果将会是下一个DPRNN的输入,以此进行迭代处理。这种神经网络的设计允许每个RNN输入的长度与原始输入长度的平方根成正比,从而实现次线性的处理并减轻优化过程中面临的挑战。
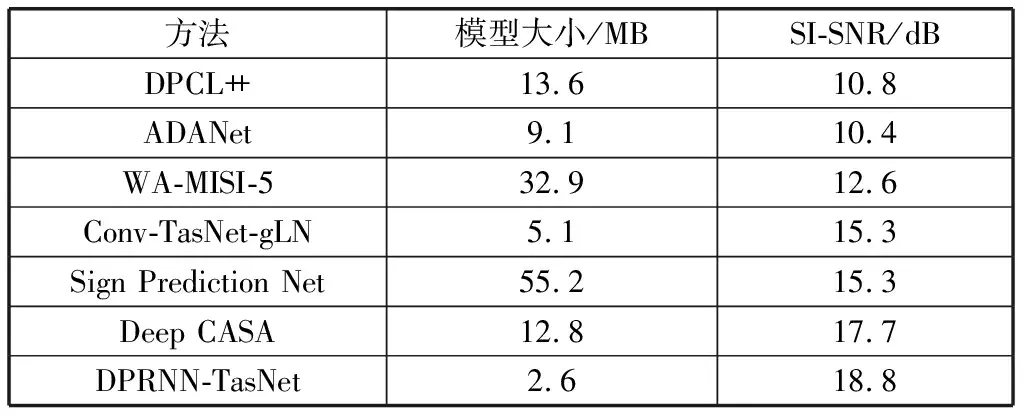
表3 基于WSJ0-2mix的各模型性能对比
Luo等人在TasNet框架中通过使用深度DPRNN替换一维CNN模块来执行样本级分离的方法,使得该方法在WSJ0-2mix数据集上获得了较之于先前语音分离方法[3-4, 6, 18-20, 22, 41-43]更优的性能,表3展示了部分方法的性能对比。
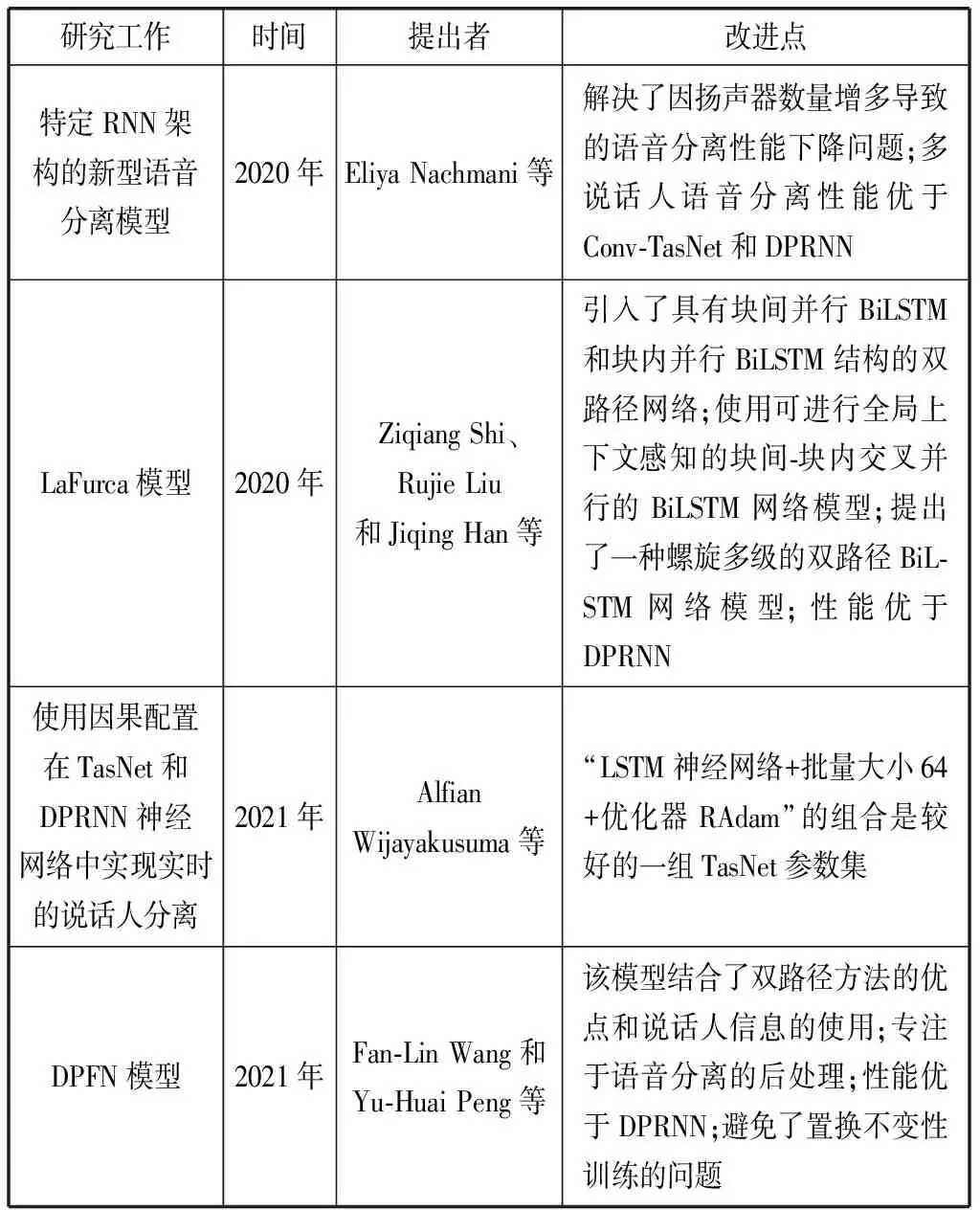
表4 针对DPRNN的一些改进工作
针对DPRNN-TasNet,有诸多学者展开了相关的改进工作(如表4所示)。2020年,Facebook团队的Nachmani等人[44]改进了DPRNN模型,采用了一种特定RNN架构的新型语音分离模型。由于语音信号包含无声部分,因此仅凭连续性无法分离实例,Nachmani等人在工作中添加了基于识别的恒定损失组件并使用它来检测混合信号中的实例数量。另外,为了解决因扬声器数量增多导致的语音分离性能下降问题,Nachmani等人在工作中通过引入了一个新的循环块,该块结合了2个双向RNN和一个跳过连接,并使用了多尺度损失以及语音恒定项。最后证明该模型在多说话人语音分离的性能方面优于Conv-TasNet以及DPRNN;2020年,Shi等人[45]针对端到端的单声道语音分离方法提出了LaFurca模型,该模型是对基于双路径BiLSTM的网络模型的改进。首先,该研究引入了具有块间并行BiLSTM和块内并行BiLSTM结构的双路径网络,以减少不同分支之间的性能差异。接下来,该研究在先前研究的基础上使用可进行全局上下文感知的块间-块内交叉并行的BiLSTM网络模型来进一步感知全局上下文信息。最后,该研究提出了一种螺旋多级的双路径BiLSTM网络模型,通过迭代从而细化前几级的分离结果,即混合语音先经过一个DPRNN模型得到2个分离语音,再将分离后的语音与混合语音一起送入第二个DPRNN模型,分离出2个语音,并不断迭代。所有这些网络都是将2个说话者的混合语音映射到2个单独的语音中,其中每个语音块只包含一个说话者的声音。最终证明LaFurca模型在WSJ0-2mix数据集上的性能超过了DPRNN网络框架。2021年,Wijayakusuma等人[46]尝试使用因果配置在TasNet和DPRNN神经网络中实现实时的说话人分离。该研究中主要使用3种实验变量类型:RNN(LSTM和GRU)、优化器(Adam和RAdam)和批量大小(128和64),以期发现较好的参数集。最终得出结论,“LSTM神经网络+批量大小64+优化器RAdam”的组合是较好的一组TasNet参数集。2021年,Wang等人[47]提出了一种称为双路径滤波器网络(Dual-Path Filter Network, DPFN)的方法。它是一个基于过滤器的模型,这意味着它将充当语音过滤器来传递混合中的目标源波形。该模型结合了双路径方法的优点和说话人信息的使用。在DPFN模型中,扬声器模块是全新设计的,灵感来自分离模型。它可以为语音分离产生更多有用的说话人嵌入,而且DPFN模型专注于语音分离的后处理,所以该模型可以连接到任何的分离模型以提高各模型的分离性能。研究最终证明,基于DPRNN模型构建的DPFN不仅优于DPRNN模型,而且避免了置换不变性训练(PIT)的问题。
3 TasNet的未来展望
尽管基于时域的语音分离方法的性能超过了基于时-频域的语音分离方法,但处理真实世界的音频仍具有挑战性。目前基于TasNet的语音分离方法还存在以下问题:
1)在模型层面,TasNet在帧跳数较大的情况下表现不佳,导致这种性能下降的主要原因可能是因为2个相邻窗口之间错开的采样数较大而引起的混叠现象[48]。
2)在实验数据集层面,基于TasNet的语音分离虽在模拟数据集上运行良好,但由于模拟训练集中的语音和阅读语音中的说话风格不匹配,在现实会话场景下语音分离效果会存在不稳定性[49],即泛化性还有待加强。
3)在说话人数量层面,大多数TasNet语音分离模型只能处理固定数量说话者的语音信息。为了解决这个限制,研究人员受语音提取的启发[50-52],开始使用说话人信息来更好地支持语音分离,即每一次的操作只需根据说话人信息提取单个目标说话人,则分离模型就不会受固定说话人数量的限制。有很多方法可以将说话者身份通过扬声器合并到分离模块中。例如,联合TasNet和说话人提取网络的SpEx[53]和SpEx+[54]模型每次只输出一个说话人的掩膜从而实现多说话人声源提取的工作,说话人向量在WaveSplit[55-56]架构的分离模块中进行仿射变换,与说话人条件链模型(Speaker-Conditional Chain Model,SCCM)[57]中混合的逐帧特征向量连接,以及仅用于计算TasTas[58]中的说话人分类损失,或者基于DPRNN-TasNet的DPFN模型[47]。
4)在复杂场景下,为了贴合真实说话人场景,TasNet模型侧重中低频语音信号的分离,但是在更广音频分布的场景中将会受限。要解决复杂听觉场景下语音分离问题,需要将计算模型和听觉研究中的一些相关机制深度结合起来[59]。为了使其泛化性更高,研究者可以尝试挖掘人耳的听觉心理学知识以及更多地关注和挖掘语音的固有特性等[60]。未来语音分离会朝着更低延迟、更低功耗、更长时间序列的方向发展,以期实现广义语音分离[61]。
综上所述,本文提出TasNet语音分离技术可以从TasNet本身的模型优化层面、实验数据集的泛化性层面、说话人数量层面以及如何解决复杂场景下的语音分离的层面进行更加深入地探索和研究。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
网络安全与数据管理(2022年1期)2022-08-29
人工晶体学报(2021年3期)2021-04-17
测控技术(2018年11期)2018-12-07
成都信息工程大学学报(2018年3期)2018-08-29
中国港湾建设(2017年11期)2017-12-19
制造技术与机床(2017年10期)2017-11-28
西安工程大学学报(2016年6期)2017-01-15
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
