
基于改进遗传算法优化BP神经网络的糖尿病并发症预测模型
2022-11-23 09:09:58徐英豪朱习军
计算机与现代化 2022年11期
汪 敏,徐英豪,朱习军
(青岛科技大学信息科学技术学院,山东 青岛 266061)
0 引 言
2019年,国际糖尿病联盟(IDF)[1]发布了最新的全球糖尿病地图,地图显示我国是糖尿病人数最多的国家,且发病率不断增高。糖尿病是一种以身体内血糖含量升高为特点的慢性疾病,它的慢性并发症也是极其严重的一种疾病[2]。糖尿病并发症在早期不易被发现,所以很多人错过了最佳治疗时间[3-4]。糖尿病及其并发症已经成为严重威胁人们健康和生命的杀手,找到糖尿病最有可能引发的并发症和发病规律,对于患者及早做好预防措施,对于医生急时有针对性地给出治疗方案具有非常重要的意义。
近些年,我国对糖尿病及并发症应用于数据挖掘领域有了很大提升。陈淑良等人[5]对某医院糖尿病患者的数据进行挖掘,建立Logistic回归模型以及多层感知器神经网络模型,试验得到Logistic回归模型对糖尿病的风险预测效果较好;谭燕等人[6]选取2型糖尿病数据集作为研究对象,实验验证尿IV型胶原对糖尿病肾病的特异性诊断具有积极作用,成为预测早期DN的有价值的临床指标。苏萍等人[7]采用Cox比例风险回归构建糖尿病预测模型,以患者工作特征曲线下面积评价模型的预测效能,以十折法检验模型的稳定性,实验证明该模型在健康管理人群中具有较好的预测能力。
本文利用BP神经网络构建糖尿病并发症预测模型,采用遗传算法优化BP神经网络,通过改进遗传算法的选择方式、改进遗传算法的交叉及变异概率公式,以全局搜索的方式确定最佳的初始权值及阈值,从而在一定程度上提高了糖尿病并发症预测模型预测的准确率,最终通过仿真实验来对该模型进行评估。
1 数据预处理
1.1 原始数据分析
实际生活中,直接获取的原始数据并不能直接用于分析,因为这些数据大部分都是不完整不一致且极易受到噪声侵扰的。本文所使用的数据集为青岛市某三甲医院HIS系统中的糖尿病诊断数据,由于直接在医院获取的数据集中数据信息太多,故选取1000个样本,6个特征属性,3个标签属性,通过jupyter notebook对该样本进行数据预处理操作。选取详情见表1,选取数据集整体分布如图1所示。
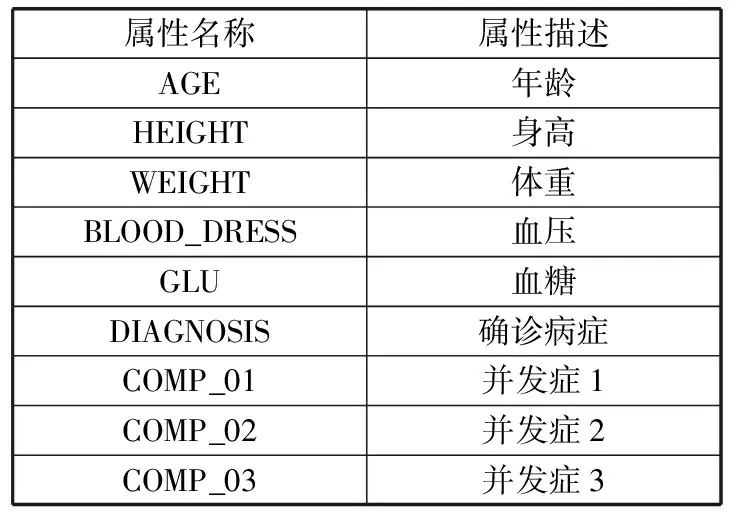
表1 选取数据集属性
图1 糖尿病数据集分布
所选属性中,特征属性分别为:年龄、身高、体重、血压、血糖、确诊病症,标签属性为并发症1、并发症2、并发症3。
关于标签属性的并发症,通过jupyter notebook工具,以分组计数的形式,统计所有并发症名称及数量,统计结果见表2。
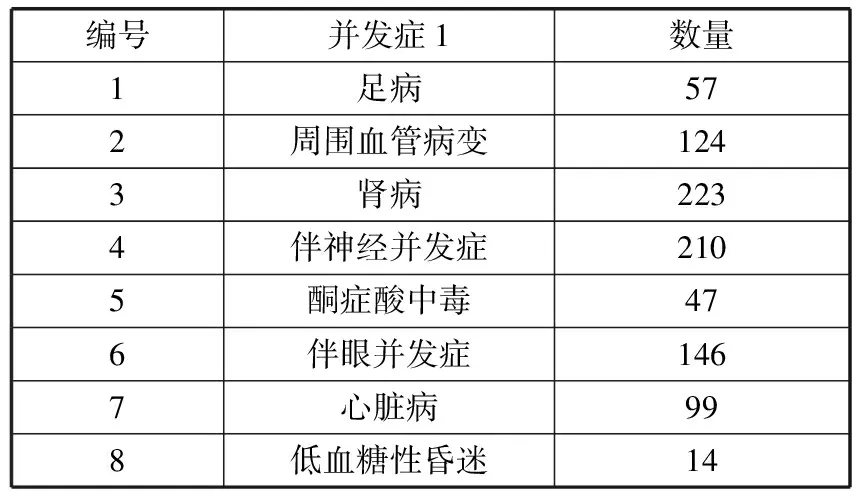
表2 各类糖尿病并发症及数量统计
1.2 异常/缺失值处理
对于数据集中的异常及缺失值,利用插补法填补[8]。图2为数据集箱线图,通过设置数据标准来反映数据面貌。通过该图对数据集进行异常分析。
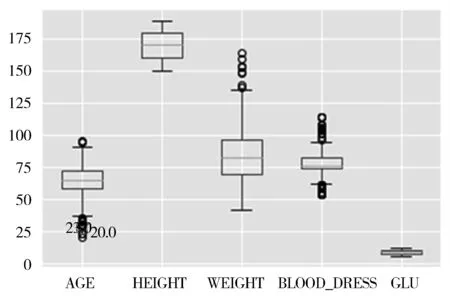
图2 数据集箱线图
最后将数据集中不合理的数据或者是存在缺失值的数据(如年龄过小、血压为空等情况),以平均值的方式进行替代。
1.3 数据标准化
数据标准化(normalization)是指将原始各指标数据按照比例缩放,去除数据单位限制,转化为无量纲的纯数值,以便于不同单位或量级的指标能够进行比较和加权[8]。对于该数据集,采用min-max标准化的方法,进行线性变化,使其落到区间[0,1]中。
对序列x1,x2,…,xn进行变换:
(1)
新序列y1,y2,…,yn∈[0,1]并且是无量纲的。(注:max{xj}为样本属性的最大值,min{xj}为样本属性的最小值)。
1.4 特征相关性分析
特征相关性分析主要分析特征两两间的关系[9]。本文数据集相关性分析使用jupyter notebook,通过corr函数,得到皮尔逊相关系数(Pearson correlation coefficient)。图3为糖尿病数据集各个特征相关关系热力图。

图3 特征关联分析热力图
由图3可知如:血糖与并发症1这2个特征间的关联程度较大;血糖与体重这2个特征间的关联程度较大等。
通过数据预处理,获得一个新的糖尿病数据集,将该数据集用于后续BP神经网络的建模工作,数据集划分为训练集与测试集,来验证构建预测模型的预测准确度。
2 改进遗传算法优化BP神经网络
BP神经网络是基于误差反向传播的多层前馈神经网络[10-11],在机器学习方面已经比较成熟。图4为BP神经网络的基本结构。它是由信息正向传播及误差反向传播2个过程组成。
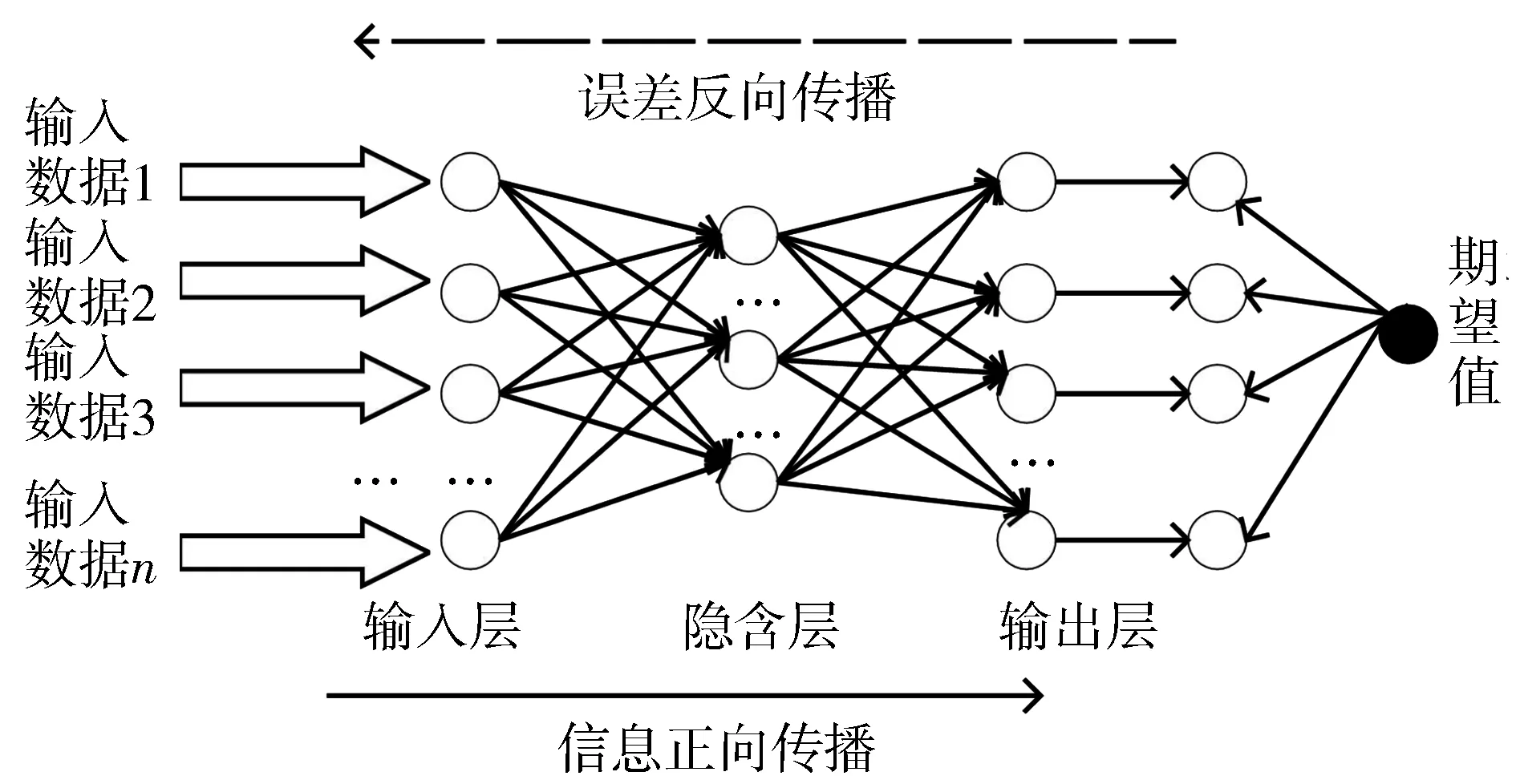
图4 BP神经网络基本结构
由于BP神经网络对于非线性数据集的预测效果较为理想,有非线性逼近以及自适应学习能力,而本文所使用到的糖尿病数据集为非线性数据集,故选用BP神经网络对糖尿病并发症进行预测。
传统BP神经网络具有极易陷入局部极小值的缺点,为了提高该模型的训练准确度,使用遗传算法的全局搜索能力确定BP神经网络最优初始权值及阈值。
2.1 改进遗传算法
1992年,Holland[12]提出模拟自然界遗传机制和生物进化论机制的遗传算法(Genetic Algorithms)。该算法具有全局搜索能力,通过遗传学中的选择、交叉、变异操作,对个体进行筛选,最终收敛到全局最优解。
前人已经对遗传算法进行了多种改进,像自适应概率、父子代竞争、保留最优父代等,这些改进在寻找最优解的问题上相对于传统的遗传算法有一些进步,但是基本都不会有很明显的下一代非常优秀于上一代的情况。主要原因便在于遗传算法与实际生物界生物进化相比,它在选择过程中并没有引导交叉变异,交叉是随机进行的交叉,变异是随机进行的变异,实际收敛速度并没有很快[13-19]。
本文对遗传算法的选择方式以及对自适应遗传算法交叉、变异概率公式进行改进,提高遗传算法寻找最优解的能力。
2.1.1 编码
一般用的比较多的编码方法有2种,分别为二进制编码和实数编码。由于BP神经网络的权值与阈值介于-1到1之间,故采用实数编码较为合适。
2.1.2 适应度
好的适应度对预测结果起积极作用,反之则起消极作用,故误差与适应度应为反比的关系,所以采用均方误差的倒数作为适应度函数。公式(2)为适应度函数公式,x表示种群个体。
(2)
2.1.3 改进选择方式
本文对于选择操作,采用通过计算每一个个体的适应度值,然后将这些个体通过适应度值的大小进行顺序排序,适应度值最大的前2个个体直接遗传至下一代,剩余个体中根据适应度值均等分为一级、二级、三级3个等级。一级的复制2份遗传至下一代,二级的复制一份遗传至下一代,三级的直接舍去不使用。该选择方法使种群整体的平均适应度得到改善,并且维持了种群的多样性。以下是对该种方法的图形化展示:
1)确定一个种群个数为14的初始种群。

5321614307294113581713191234567891011121314
2)计算种群中每一个个体的适应度值,并且依据适应度值由大到小进行顺序排序。

3532302919171614131187541025714123413911618
3)将排序后处于前2名的个体直接遗传至下一代。
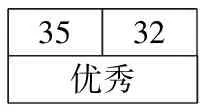
3532优秀
4)将剩余个体均分为3等份,分别定义为一级、二级与三级。

353230291917161413118754优秀一级二级三级
5)将一级的复制2份,二级的复制一份,三级的直接淘汰。

3029191730291917161413118754一级的复制2份二级的复制一份三级的直接舍去
2.1.4 改进自适应遗传算法交叉/变异概率公式
传统的遗传算法采用固定的交叉、变异概率,概率过大过小都会影响算法性能,Srinivas等人[20-22]提出了自适应遗传算法(Adaptive Genetic Algorithm, AGA),可以自适应调整交叉、变异概率。当个体适应度大于种群平均适应度时,得到一个较小的交叉、变异概率;当个体适应度小于种群平均适应度,得到一个较大的交叉概率、变异概率。较小的变异概率可以将优秀的个体保留下来,较大的变异概率可以加速变异得到新个体。具体公式如下:
1)交叉概率:
(3)
2)变异概率:
(4)
式中,fmax为种群中的最大适应度值,favg为种群中的平均适应度值,f′为交叉的较大适应度值,f为个体变异适应度值。使用交叉、变异概率函数不断自适应调整,加速遗传算法的收敛性,有效避免遗传算法陷入局部最优解,更快地找到全局最优解。
本文引入种群适应度的平均值EX及适应度值的离散程度DX来优化自适应遗传概率与变异概率公式:
(5)
(6)
(7)
其中,fi代表种群中适应度的值。随着不断进化,种群的平均适应度值不断增大,种群间的差异越来越小,所以种群的整体离散程度是不断减小的。综上,自定义系数∂是不断增大的。
最后通过自定义系数对原始的自适应遗传算法做改进,如下为改进后的公式:
(8)
(9)
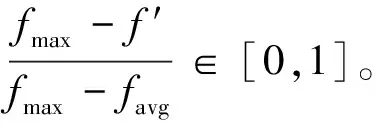
该改进有效避免了种群在初始进化时形成局部收敛,陷入局部最优解的问题,提升了该算法的寻优性能。
2.2 改进的遗传算法优化BP神经网络
使用改进后的遗传算法优化BP神经网络,确定最佳初始权值及阈值,解决传统神经网络随机给定初始权值及阈值以及极易陷入局部最小值等缺点。如图5所示为改进后的遗传算法优化BP神经网络的算法流程图。
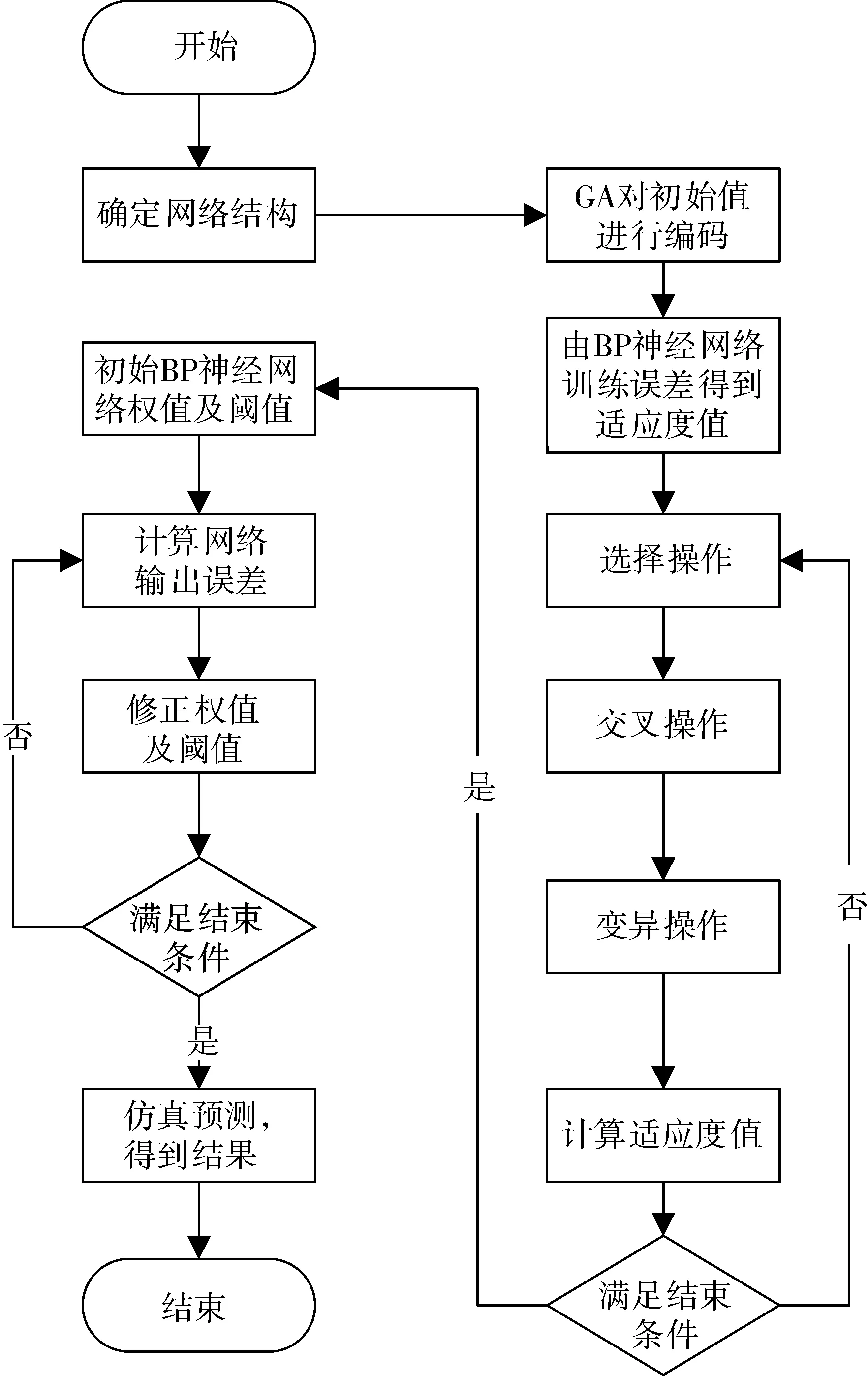
图5 改进遗传算法优化BP神经网络算法流程图
3 仿真实验
为了验证改进后的遗传算法对糖尿病并发症有良好的预测效果,因此进行了仿真实验。数据集为上述预处理后的数据集,在Matlab2016a中对BP神经网络-糖尿病并发症预测模型进行训练,实验结果表明改进后的遗传算法优化BP神经网络,训练模型的预测结果要好于未改进的。
在本文仿真实验中,预处理后的糖尿病数据集共1000个样本,前980个样本作为训练集,后20个样本作为测试集,通过年龄、身高、体重、血压、血糖来预测未来可能会患有的并发症(确诊病症已筛选全部为糖尿病,故在这里不作为预测属性出现)。所以输入层节点为5个,输出层节点为1个。关于隐含层在这里不固定,自己进行手动设置,依据经验公式[23]:
(10)
其中,m为输入层节点数,n为输出层节点数,a为1~10之间取常数。
采用传统的BP神经网络进行糖尿病并发症的预测,在Matlab中设置如下基本参数:
1)net.trainParam.epochs=100;为迭代次数。
2)net.trainParam.lr=0.1;为学习率。
3)net.trainParam.goal=0.001;为训练目标误差。
4)net.trainParam.show=200;为训练结果显示。
使用Matlab对BP神经网络进行训练,预测结果如图6所示。
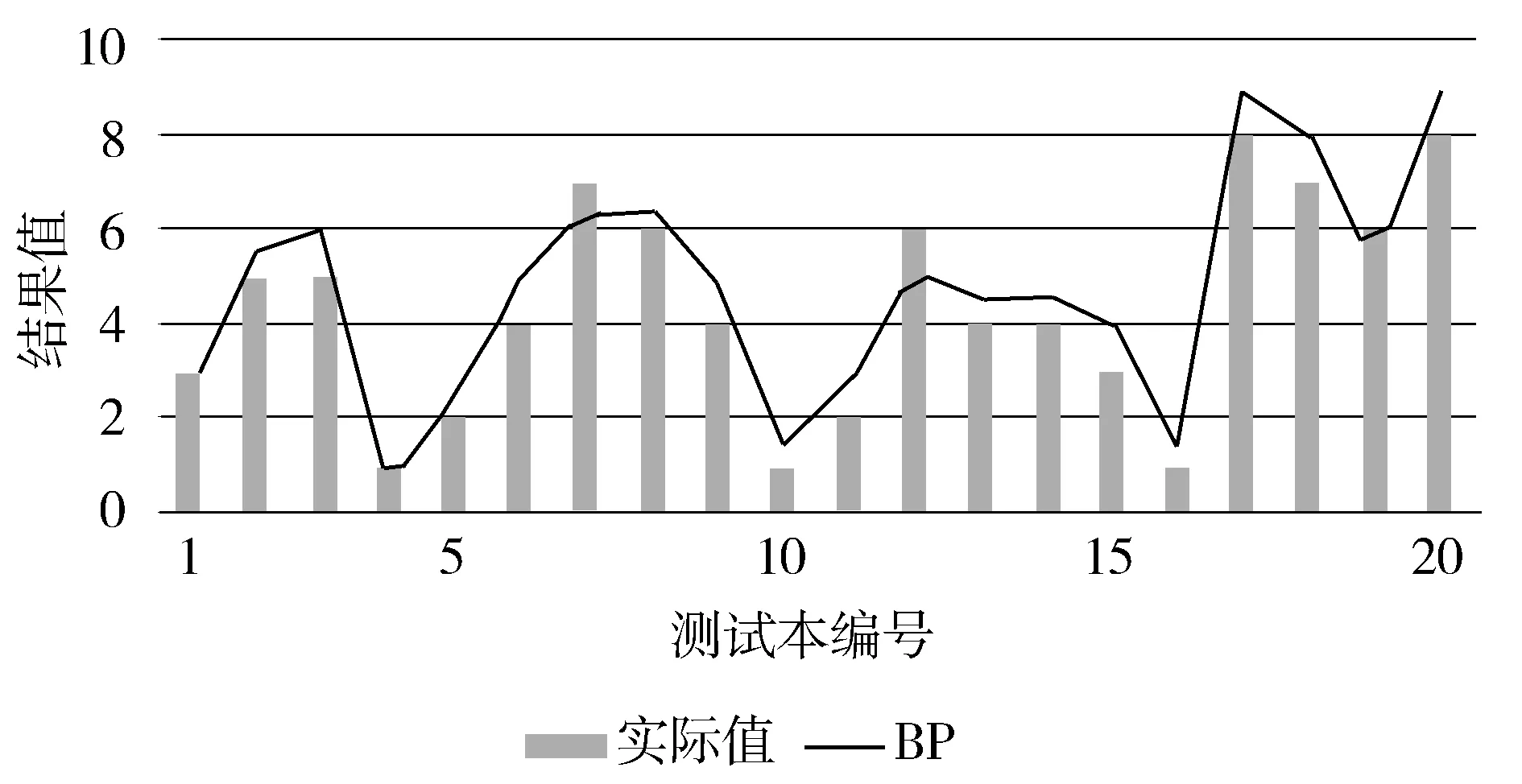
图6 BP神经网络预测值与实际值对比图
分别使用遗传算法(GA)、自适应遗传算法(AGA)、改进遗传算法(IGA)优化BP神经网络,在Matlab中对GABP、AGABP、IGABP神经网络进行训练,预测结果与实际值比较结果如图7~图9所示。
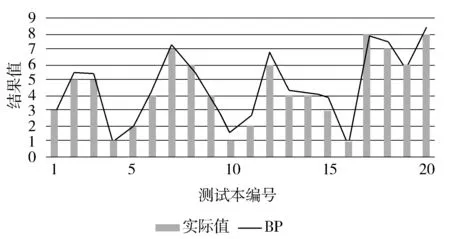
图7 GABP预测值与实际值对比图
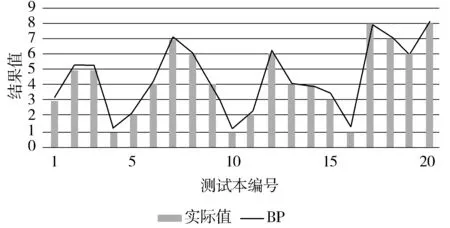
图8 AGABP预测值与实际值对比图
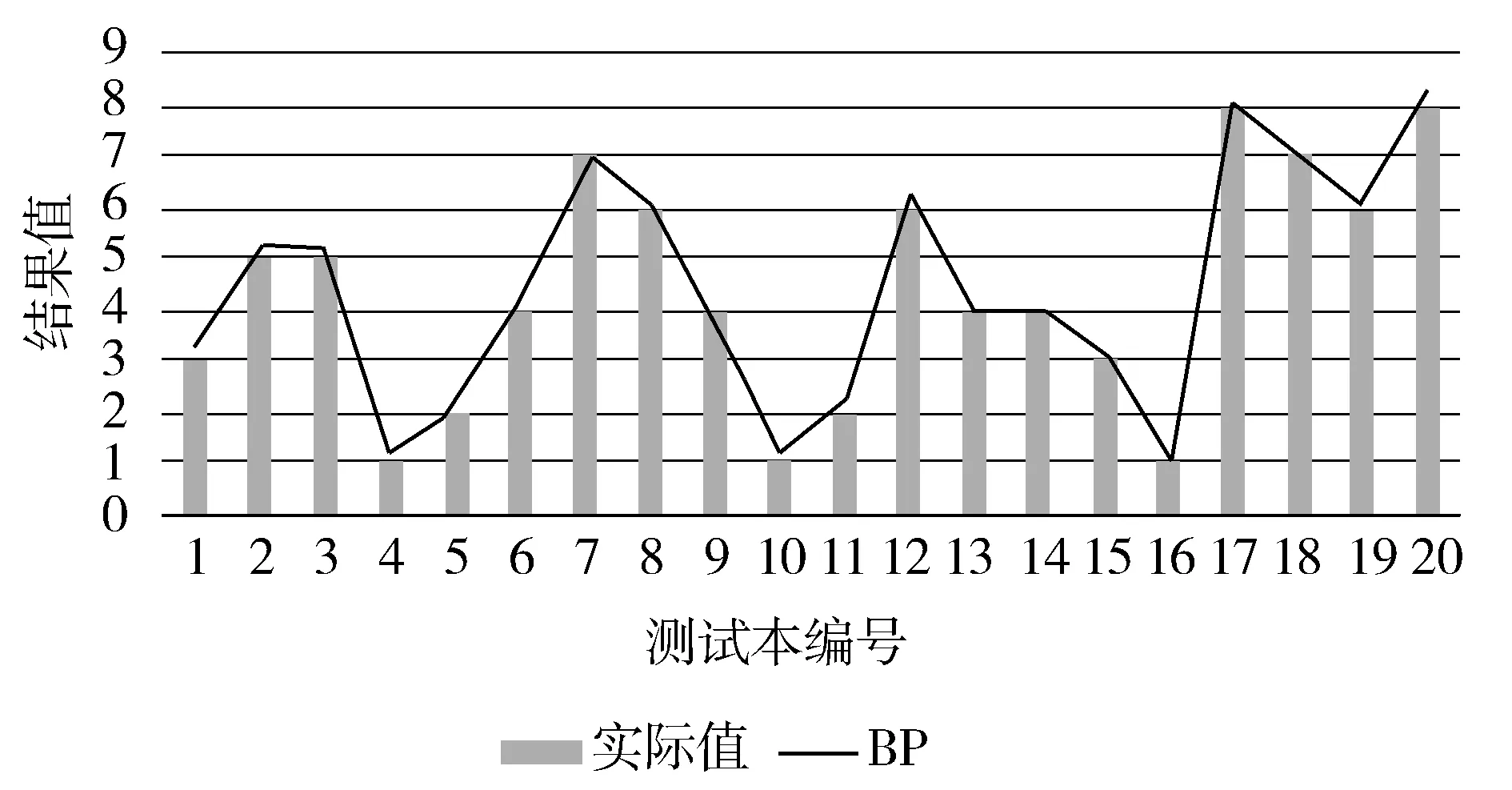
图9 IGABP预测值与实际值对比图
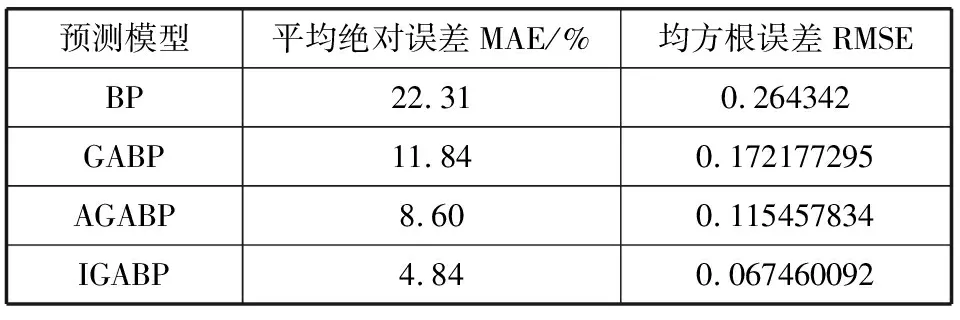
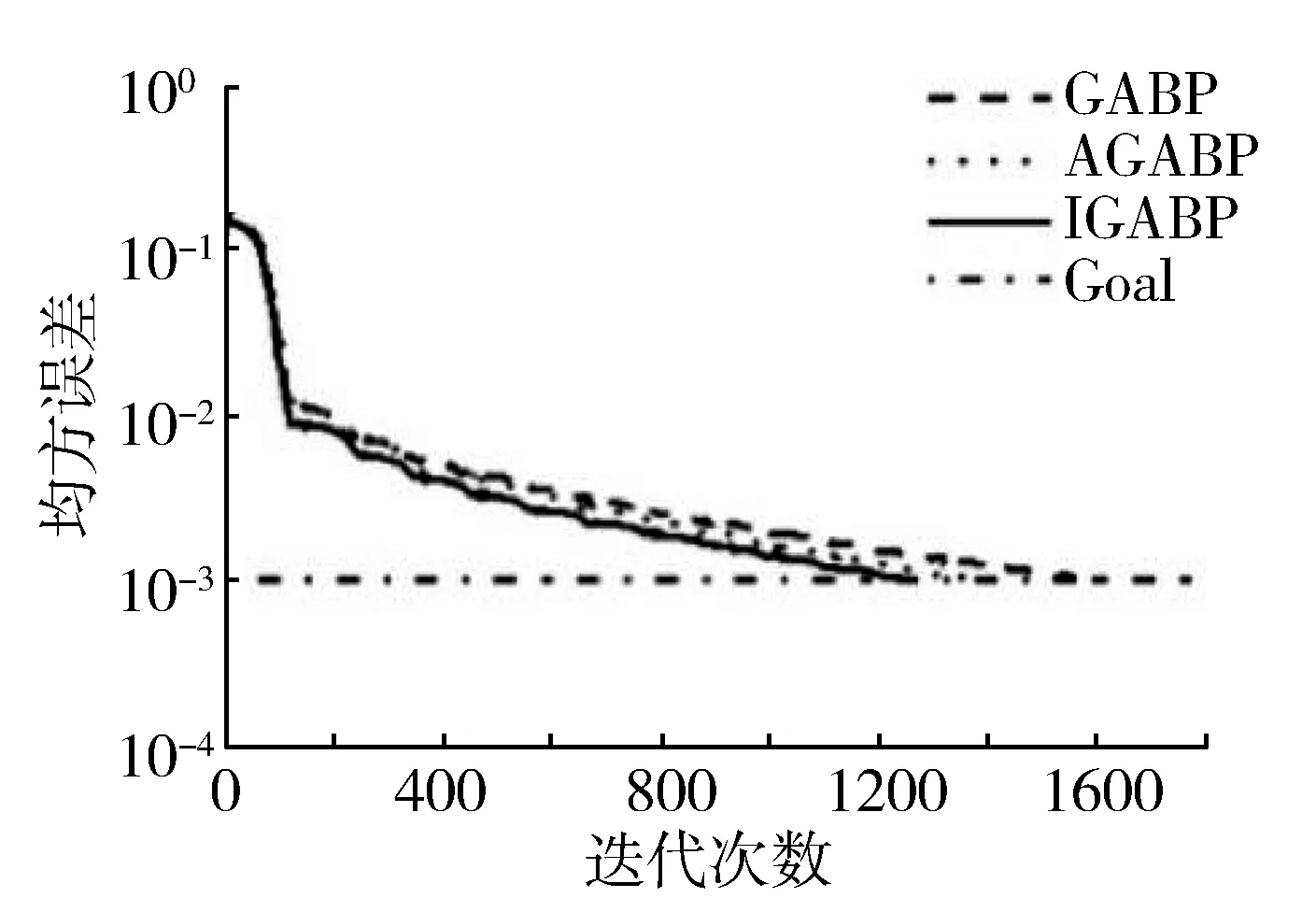
从图中可以清晰看到,这4种算法的预测结果依次逐渐接近于实际结果。即对于预测结果的好坏,BP 图10为4种算法预测输出的误差百分比折线图。由图可知,对于传统的BP神经网络,其预测误差波动范围比较大,GABP的波动范围其次,AGABP与IGABP的误差波动范围均比较接近0值,在0附近小范围波动,且IGABP比AGABP更接近于0值。 图10 4种预测误差对比图 预测结果如表3所示。 表3 预测结果对比 由表3中统计数据可知,IGABP神经网络预测模型的仿真效果最好,平均绝对误差MAE达到4.84%,均方根误差RMSE也最低;传统的BP神经网络预测结果误差最大,平均绝对误差MAE为22.31%,均方误差RMSE最高;GABP神经网络预测模型与AGABP神经网络预测模型与传统的BP神经网络预测模型相比在预测结果上有了一定的改善,但均没有达到IGABP神经网络预测模型的精度,因此IGABP在预测的精度上要优于其他3种模型。 图11 网络训练误差曲线 如图11所示,为GABP、AGABP与IGABP的网络训练误差曲线,由图中曲线可知IGABP的收敛速度要明显好于GABP与AGABP,故IGABP的收敛性更好。 本文改进遗传算法优化BP神经网络构建预测模型来提高预测准确度,使用数据预处理后的数据集对糖尿病并发症进行预测。仿真实验,结果表明改进后的算法优化BP神经网络所构建模型的预测准确率最高。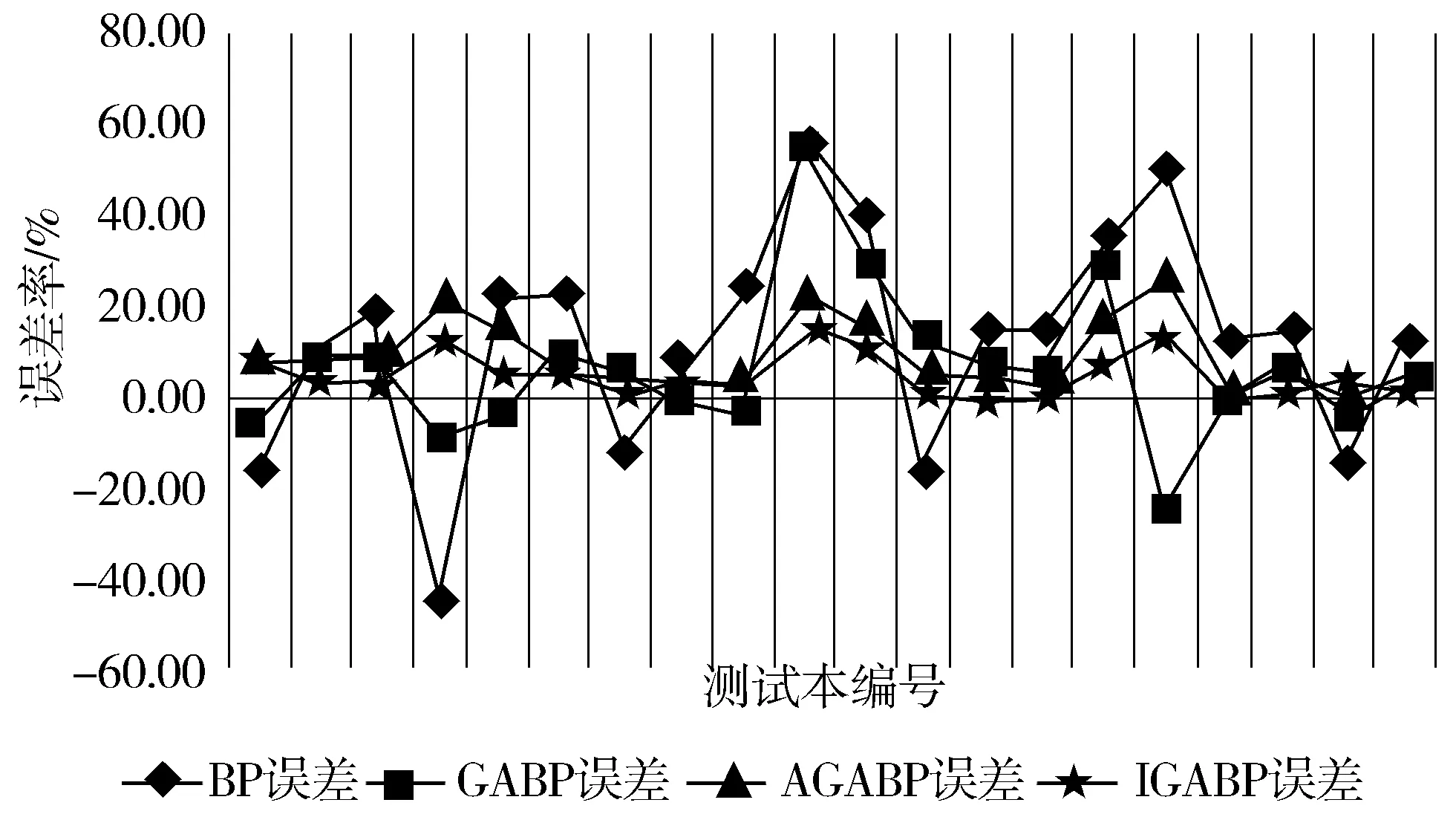
4 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
趣味(数学)(2020年4期)2020-07-27 01:44:16
支部建设(2020年15期)2020-07-08 12:34:32
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
中国塑料(2016年11期)2016-04-16 05:26:02
智能系统学报(2015年4期)2015-12-27 09:38:39
百科知识(2015年18期)2015-09-10 07:22:44
教育与职业(2014年16期)2014-01-19 01:24:36
