
基于遗传模糊树的海空对抗无人机智能决策模型
2022-11-19 06:53王玉佳余应福邓博元
系统工程与电子技术 2022年12期
王玉佳, 方 伟,*, 徐 涛, 余应福, 邓博元
(1. 海军航空大学航空作战勤务学院, 山东 烟台 264001; 2. 海军航空大学岸防兵学院, 山东 烟台 264001)
0 引 言
随着高新技术在武器装备上的广泛应用,军用无人机已成为空中军事力量的重要组成部分[1]。现代无人机具有续航时间长、飞行高度高、隐身效果好等特点,可长时间执行侦察、监控任务。在未来战场中,无人机不再局限于传统的侦察探测任务,其必将担负对海攻击、拦截导弹、空中格斗等多功能作战任务[2]。
目前,无人机的自主智能化方向的发展是其在军事应用上的研究热点和难点,包括:无人机协同通信[3-5]、多无人机协同侦察任务分配[6]、无人机航迹规划[7-8]、无人机智能定位[9]、无人机感知技术[10]、多无人机武器目标分配[11]、武器使用智能决策等。其中,基于无人机察打一体化的发展趋势,无人机的武器自主决策能力成为无人机决战海战场的重要保障。
针对无人机的自主智能行为决策技术,国内外学者展开了大量的研究[12-16],目前强化学习中的遗传算法(genetic algorithm,GA)是应用于智能行为决策中最热门的技术之一[17]。文献[18]利用GA来优化无人机基本战术飞行动作的组合方式,以此得到更有利的动作决策。文献[19]利用GA来优化无人机控制量:加速度、航迹俯仰角变化率、航迹偏转角变化率,以此进行智能决策。这两篇文献充分利用了机器学习的准确性,但是忽视了决策问题的可解释性。
美国控制专家Zadeh教授于1965年提出模糊集合理论[20],在此基础上,模糊推理技术[21]应运而生。遗传模糊系统(genetic fuzzy system,GFS)[22]是使用GA对模糊推理系统(fuzzy inference system,FIS)的规则[23]和隶属度函数[24]进行编码,形成GA可进行优化的染色体,通过一系列选择、交叉、变异等进化操作,实现对模糊控制系统的自动设计和优化。GA的搜索优化能力保证决策的准确性,基于专家经验的FIS兼顾了决策的可解释性,GFS在众多领域都有所应用[25-34]。文献[24]采用GFS的思想得到进化式有规则的专家系统,用以解决无人机空战决策问题。文献[35]立足于兵棋推演,利用GA优化FIS的隶属度函数参数得到推演关键点。文献[36]利用遗传模糊树(genetic fuzzy tree, GFT)的思想对无人机编队进行训练以此解决对地打击问题,该方法对GFS进行简化,由于输入与输出的某些模糊子集无因果关系从而进行“分叉”处理,减少了FIS的规则数量,提高了决策的效率,但在进行具体实验时,数据处理的方法以及实验得到的最优染色体未能展示。
针对上述文献中算法的优点与不足,为解决未来海战场中,察打一体化无人机在执行侦察任务时,面对水面舰艇编队火力打击的武器智能决策问题,本文采用改进的GFT方法进行解决:首先梳理影响无人机武器决策诸多因素之间的因果关系,利用GFT的思想构建武器智能决策GFT框架;其次针对构造的GFT模型设计了一种新的参数编码法——三模糊子集参数编码法,用以解决GA中对隶属度函数参数的编码问题;然后针对无人机担负的任务的特点构建训练场景;在进行场景训练时,采用单场景与创新性的组合场景相结合的训练方式对最优个体进行筛选,将场景得分作为适应度函数的数值;最后将场景训练的最优个体代入任务场景中进行模型有效性的实验验证,并将实验结果与完全基于专家经验建立的模糊推理树[36](fuzzy inference tree,FIT)在任务中的表现进行对比,证明本文构建的无人机武器智能决策GFT模型的优越性和灵活性。
1 问题描述
本文针对性解决的问题是察打一体化无人机在海空对抗背景下执行侦察任务时的武器智能决策问题,所以对真实海空对抗环境进行简化设置,将三维场景简化为二维俯视图,不考虑无人机飞行高度并假设无人机可自行改变姿态达到武器发射条件。其中,海空对抗双方为水面舰艇编队和无人机单机。
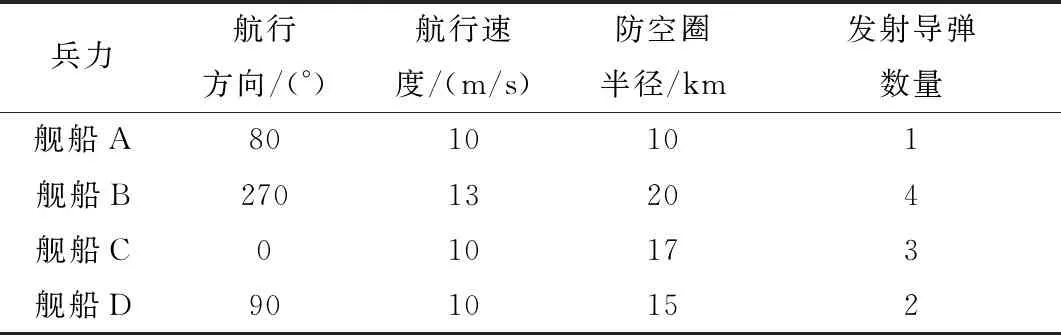
水面舰艇编队,包括驱、护舰以及搭载舰载机的航空母舰。由于无人机实施侦察时为尽可能保存自身,不会选择抵近侦察,因此编队的火力攻击武器不考虑密集阵火炮,而采用驱护舰的舰空导弹和舰载机的空空导弹。一旦无人机进入驱、护舰防空圈或者舰载机的巡逻区,水面舰艇编队立即采取空中火力打击。
无人机配备两种防御系统,一是火力防御系统,装配空空导弹;二是电子对抗防御系统,装配空射诱饵弹。无人机在执行侦察任务时,按照任务前航路规划制定的路线飞行,在面临不同空中火力威胁时,自主作出武器决策进行防御,从而保存自身,完成侦察任务。武器决策内容包括:① 依据自身武器实力,对空中威胁进行武器类型的选择;② 依据空中威胁情况,选择对敌态度(武器数量选择);③ 当武器类型确定为空射诱饵弹时,依据对抗局面的紧迫程度选择诱饵弹的发射方式。
2 武器智能决策GFT
2.1 武器智能决策FIT
将空中威胁数、威胁距离、无人机空空导弹剩余量、无人机空射诱饵弹剩余量作为输入,以此构建武器智能决策FIS。对其不存在因果关系的输入输出进行“分叉”,使之成为树形结构的FIT。其中,对敌态度决策系统是独立的FIS(简称为S1);武器选择决策系统(简称为S2)与空射诱饵弹发射方式决策系统(简称为S3)构成FIT。S1、S2与S3共同构成武器智能决策FIT,如图1所示。

图1 武器智能决策FIT
S1输入物理量为空中威胁数AN,包含模糊子集为“少、中、多”;输出物理量为对敌态度AT,包含模糊子集“勇敢、正常、懦弱”。态度勇敢表示针对一个威胁发射1枚武器,态度正常表示发射2枚武器,态度懦弱表示发射3枚武器。在无人机单机只能装载一定武器数量的前提下,发射武器数目越多,击毁来袭导弹的成功概率越高;武器消耗量越大,面对后续威胁时,可使用武器越少。
S2输入物理量为空空导弹剩余量KK、诱饵弹剩余量YE,包含模糊子集均为“少、中、多”;输出物理量为发射武器类型WT,包含发射空空导弹和发射诱饵弹。发射相同数目的空空导弹和诱饵弹对抗来袭导弹,空空导弹的成功率高于诱饵弹,但空空导弹成本高,占空间体积大,载弹量少。
当S2输出为发射诱饵弹时,决策进入S3。S3输入物理量为空中威胁数(同S1中AN)和空中威胁距离DT,包含模糊子集分别为“少、中、多”和“远、中、近”。设定当面临多个导弹威胁时,以最近一枚导弹距无人机的距离为威胁距离。输出物理量为诱饵弹发射方式Time,包含模糊子集为“低延迟、高延迟”。延迟是指从探测到敌袭导弹时至发射诱饵弹的时间间隔,高和低代表间隔时间长和短,不同的发射方式导致诱饵弹对空中威胁的干扰成功率不同。低延迟表示快速发射诱饵弹,此时来袭导弹与无人机的距离较远,其干扰概率较低,但由于延迟时间短使得干扰失败后有充足时间再次作出武器使用决策。高延迟表示在来袭导弹距无人机距离较近时发射诱饵弹,其干扰概率较高,但干扰失败后,剩余时间不足以再次做出对抗决策。
2.2 武器智能决策GFT模型
武器智能决策FIT是无人机在面临空中火力威胁,自主作出武器选择决策的控制中枢。本文将知识库中规则和隶属度函数同时进行染色体编码,利用遗传优化找寻最优的武器智能决策FIT。遗传优化过程包括规则和隶属度函数编码、选择、交叉、突变、适应度函数求解以及最优个体选择。
利用GA求得最优武器智能决策FIT的过程即武器智能决策GFT的工作过程,其工作原理如图2所示。

图2 武器智能决策GFT工作原理图
2.2.1 规则编码
本文采用匹兹堡方法[36]对规则进行编码。规则表示形式为“IfA=1 AndB=1 ThenC=2”,用数字代替字母表示模糊子集的名称,方便实现计算机进行规则编码。S1、S2和S3规则编码方式如表1~表3所示。

表1 S1规则编码表

表2 S2中WT编码表

表3 S3中Time编码表
表1表示对S1的规则进行编码,其中S1包含3条规则:“If AN=1 Then AT=m1” “If AN=2 Then AT=m2”和“If AN=3 Then AT=m3”,m1、m2、m3均可取1、2、3中任意一个编码数。其中,AN和AT取数字1、2、3分别表示空中威胁数为“少、中、多”和对敌态度为“勇敢、正常、懦弱”。对S1的规则编码实质上是对m1、m2、m3进行数字“1、2、3”的编码。
表2表示对S2的规则进行编码,其中S2包含9条规则:“If YE=1 And KK=1 Then WT=n11”,…“If YE=3 And KK=3 Then WT=n33”,n11,…,n33均可取1、2中任意一个编码数。其中,KK和YE取数字“1、2、3”分别表示空空导弹剩余量和诱饵弹剩余量为“少、中、多”,WT取数字“1、2”表示武器选择类型为“空空导弹、诱饵弹”。同理,对S2的规则编码实质上是对n11,…,n33进行数字“1、2”的编码。
S3与S2的规则表示形式相类似,表3包含S3的9条规则:“If AN=1 And DT=1 Then Time=o11”…“If AN=3 And DT=3 Then Time=o33”,o11,…,o33均可取1、2中任意一个编码数。其中,AN的数字表示意义同S1,DT取数字“1、2、3”表示空中威胁距离为“远、中、近”,Time取数字“1、2”表示诱饵弹发射方式为“低延迟、高延迟”。同理,对S3的规则编码实质上是对o11,…,o33进行数字“1、2”的编码。
因此,对S1、S2和S3这3个FIS共计21条规则的编码组成了染色体编码的前三部分,共计21位。
2.2.2 隶属度函数的参数编码
考虑到算法简便性,隶属度函数的形状设置为三角形。本文对于输入的模糊子集隶属度函数参数进行编码优化,而输出的模糊子集则直接进行设定。S1、 S2、S3系统输出物理量的模糊子集,具体形状如图3所示。

图3 输出变量的隶属度函数
S1输出一个介于1和3之间的精确数,将此数进行四舍五入得到的数字只有1、2、3,分别表示发射武器的数量为每个威胁发射1、2、3枚反击弹。同理,将S2输出的精确数进行四舍五入得到的数字为1或2,分别表示发射武器类型为空空导弹和诱饵弹。
S3输出为一个介于1和2之间的精确数,用物理量Time表示。设定此时导弹到达无人机的时间为TT,等于导弹距无人机距离除上导弹速度,而在TT时间内,前1/5时间内为诱饵弹发射准备时间,后1/5时间发射诱饵弹会造成由于干扰时间太短导致的干扰效果很差的局面,所以延迟的时间选在中间3/5的时间段里。用Delay表示诱饵弹发射延迟时间,其公式如下:
(1)
得到的Delay的取值介于TT/5和4TT/5之间。
FIT中的5个输入物理量,其模糊子集均为3个,且进行归一化后的取值范围皆为0到1。本文设计了一种三模糊子集参数编码法,以S1中AN的隶属度函数参数编码为例,隶属度函数的一般形状和参数的一般位置如图4所示。
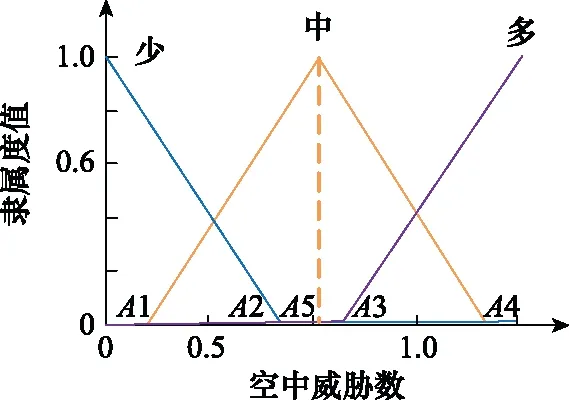
图4 输入模糊子集隶属度函数
使用五位编码对3个模糊子集的5个隶属度函数参数A1、A2、A3、A4和A5进行编码。其中,A1、A2、A3、A4为模糊子集隶属度函数与水平坐标轴交点的横坐标,A5是第二个模糊子集顶点的横坐标。由于5个参数皆为小数,为降低小数编码在后续遗传进化过程中的操纵复杂度,参数的编码方式转化为对其所在位置的左右移动进行编码表示。首先设置5个参数的取值范围和初始值,然后使用a1、a2、a3、a4和a5分别表示A1、A2、A3、A4和A5的位置移动情况。a1、a2、a3、a4和a5的取值为0到10的整数,不同取值代表不同的位置移动:5代表不移动,0代表向左移动至取值范围的最左端,10代表向右移动至最右端。
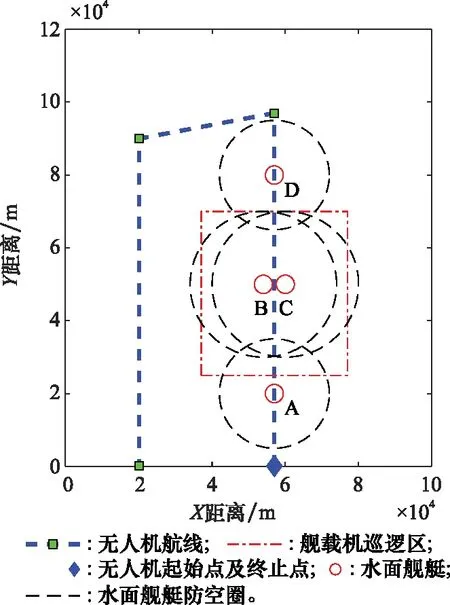
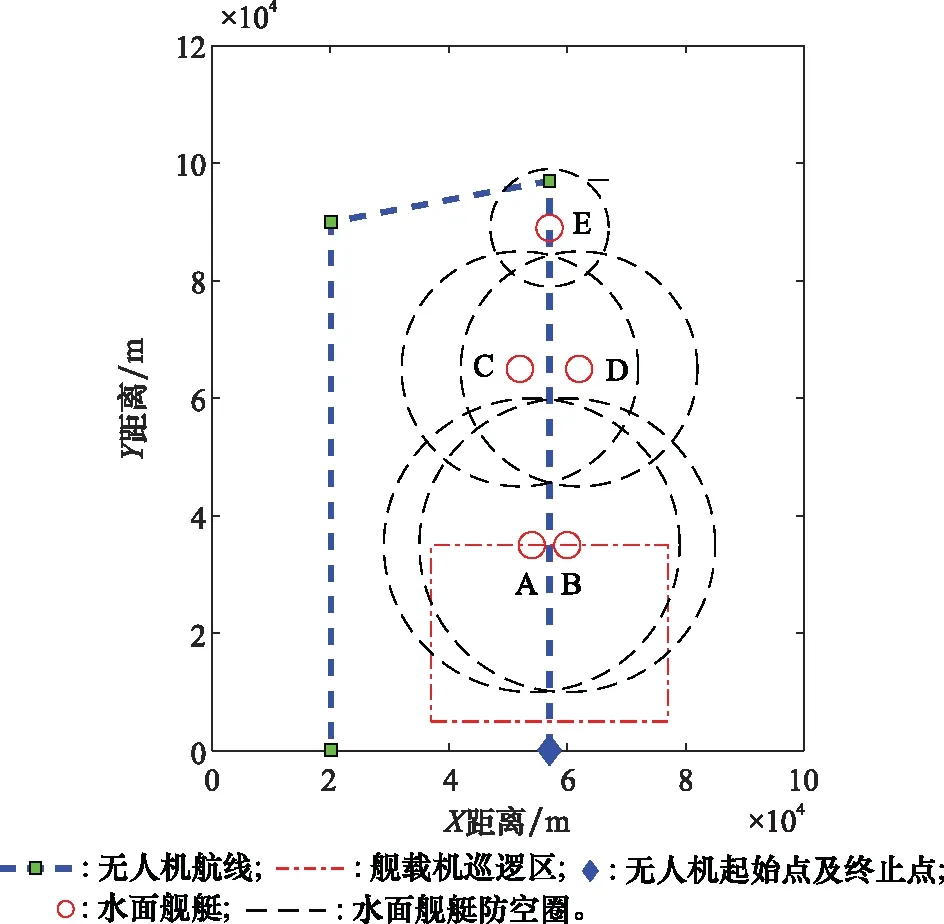
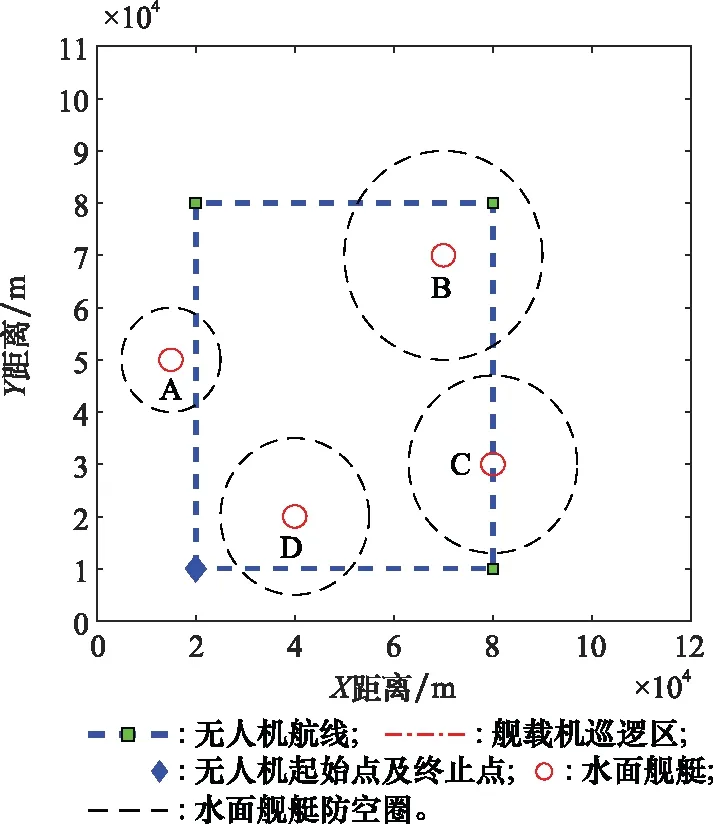
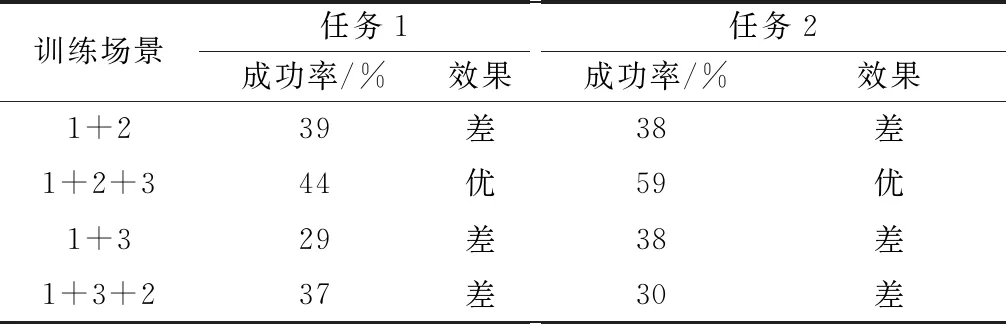
对a1、a2、a3、a4、a5进行编码时,必须考虑到A1 设定A1取值范围为0至α,A4取值范围为β至1。A1的初始值为取值范围的中点α/2,同理A4的初始值为(1+β)/2,随后对a1、a4随机进行0至10之间的编码,则 (2) (3) 由于A5表示第二个模糊子集顶点的横坐标,且第一、三个模糊子集顶点的横坐标取值为0和1,故A5无法取0或者1。为保证编码的精度,A5、A2、A3的取值范围不宜设置过大。同时,参考图4中3个模糊子集隶属度函数的一般形状和相对位置关系,设定A5取值范围为α/2至(1+β)/2,A2取值范围为α/4至(3β+1)/4,A3取值范围为3α/4至(β+3)/4。A5、A2、A3的初始值为取值范围的中点,对a5、a2、a3随机进行0至10之间的编码,则 (4) (5) (6) 特别的,当A5、A2、A3的取值超出A1至A4的范围时,将对其数值进行重新设置。以A5为例,当取值大于A4时, A5=A4-0.01 (7) 当A5的取值小于A1时, A5=A1+0.01 (8) 这种设置方法不仅可以避免无效编码导致的系统紊乱,提高后续迭代效率,并且保留了参数之间的大小关系,是一种创新的变量设置方法。 同理,可用b1、b2、b3、b4、b5和c1、c2、c3、c4、c5表示S2中KK和YE的模糊子集;d1、d2、d3、d4、d5和e1、e2、e3、e4、e5表示S3中DT和AN的模糊子集。因此,对5个输入物理量的模糊子集隶属度参数的编码组成了染色体编码后5部分,共计25位。综上所述,染色体进行编码的位数为46位。 2.2.3 种群进化方式和适应度函数 种群进化过程包括选择、交叉和突变。本文选择方式选用二元锦标赛法。交叉和突变的方法选用单点交叉和单点突变。由于染色体中包含不同含义的8个部分,所以不能仅仅对染色体中某一位进行交叉(突变),而是对染色体中8个部分同时进行交叉(突变),这样才能保证种群的有效进化。 利用GA进行武器智能决策FIT的优化,需要设置合适的适应度函数。本文采取训练场景计分的方式,其中,训练场景根据无人机任务的特点制定。 依据水面舰艇和无人机武器系统实际作战性能,同时为加强无人机面临环境的严峻性,设计各类武器的单枚命中概率和干扰概率如下。 (1) 水面舰艇舰空导弹命中率为100%(无干扰情况下)。 (2) 无人机利用空空导弹拦截舰空导弹的命中率为75%(主要考虑舰空导弹的高速运动特点)。 (3) 无人机诱饵弹对舰空导弹的干扰概率范围为25%至75%。其中,具体干扰概率值YR的影响因素主要考虑为诱饵弹发射时舰空导弹与无人机的距离,用诱饵弹发射延迟时间Delay作为衡量标准,YR与Delay呈线性相关,计算公式如下: (9) 在训练场景中,无人机根据武器智能决策FIT做出武器决策,通过作战仿真得到作战结果,作战结果不同,最终的决策得分也不同。 为达到无人机打击威胁、保存自身的目的,设定击中一个空中威胁奖励10分;一旦被任意一个威胁击中则宣布任务失败,扣除100分,未被击中则宣布任务成功,奖励100分。考虑到无人机在真实作战场景中携带的空空导弹数量远远小于诱饵弹的数量,且空空导弹的制造成本远远高于诱饵弹的现实条件,采取使用一枚空空导弹扣除2分,使用诱饵弹不扣分的计分策略,鼓励无人机在整个作战过程中尽可能多的使用诱饵弹。计分情况表如表4所示。 表4 行动计分表 在实验过程中,计算染色体在场景中得分情况时,每一个染色体均进行3次仿真实验,3次仿真实验的得分平均值作为染色体最终得分。 2.2.4 最优个体选择 种群进化的过程即无人机在训练场景进行训练的过程。在进行场景训练时,为使最优个体的筛选更具准确性,本文采取与传统GA不同的选择方式:每代种群进化后,将表现最优异的5个个体存储于数据库中,待进化完毕后,对数据库中所有个体进行仿真从而选出表现最优者。场景训练结束后,得到的数据库命名为POP库,将POP库中所有个体按顺序进行100次训练场景的实验仿真,其平均得分最高的个体即为最优个体。 训练场景的设置只针对任务的单一特点,单场景训练得到的最优个体往往不能满足复杂的任务设定。本文设计了创新性的组合场景训练方法,将单个训练场景进行排列组合,依次进行仿真实验,从而优化染色体多个特性。其具体实现方法为:对第一个训练场景建立的POP库中的染色体进行挑选,表现最优的前100个个体存储至新的数据库,定义为POPX库;将POPX库中的所有个体作为后续即将进行训练的场景的初始种群,从而实现场景间种群的遗传与进化。本文对无人机进行训练时,采取单场景与组合场景相结合的训练方法。 为验证构建模型的有效性,设计实验对无人机武器智能决策GFT的模型进行验证。首先根据水面舰艇编队的类型,构建无人机的任务场景;其次针对任务场景兵力特点构建训练场景;然后在训练场景中训练无人机的武器使用决策能力,并选出最优的武器智能决策FIT;最后将武器智能决策FIT代入任务场景中进行仿真,分析无人机的任务成功率。无人机飞行速度设置为340 m/s,空中导弹速度设置为1 000 m/s。GA中种群数量设置为100个,迭代次数为30次,交叉概率为60%,突变概率为2.5%,α为0.4,β为0.6。 根据水面舰艇编队常见的“人”形队,设置任务场景1和场景2,如图5和图6所示。 图5 任务场景1 图6 任务场景2 任务场景1中,无人机携带8枚空空导弹和16枚诱饵弹,按逆时针顺序,依次通过水面舰艇A防空圈、舰载机巡逻区、水面舰艇B和C共同防空圈以及水面舰艇D的防空圈。舰载机巡逻区的长度为45 km,宽度为40 km,无人机进入巡逻区,将受到3枚空空导弹的攻击。水面舰艇编队的行动信息如表5所示。 表5 任务场景1的水面舰艇编队行动信息表 任务场景2中,无人机携带相同数量武器按逆时针顺序飞行。舰载机巡逻区的长度为30 km,宽度为40 km,无人机进入巡逻区,将受到一枚空空导弹的攻击。水面舰艇编队的行动信息如表6所示。 表6 任务场景2的水面舰艇编队的行动信息表 针对任务场景1的特性,制定训练场景1,训练无人机在威胁数量具有连续性的情况下的决策能力。无人机携带8枚空空导弹和14枚诱饵弹,按顺时针顺序飞行。舰载机巡逻区的长度为32 km,宽度为15 km,无人机进入巡逻区,将受到4枚空空导弹的攻击。训练场景图如图7所示,水面舰艇编队的行动信息如表7所示。 图7 训练场景1 表7 训练场景1的水面舰艇编队的行动信息表 针对任务场景2的特性,制定相比较训练场景1较为复杂的训练场景2,训练无人机在威胁数量具有较大波动时的决策能力。将训练场景1中舰船B防空圈半径更改为15 km,发射导弹数量为4枚;舰船C防空圈半径更改为10 km,发射导弹数量为1枚。无人机按逆时针顺序飞行,进入巡逻区,将受到4枚空空导弹的攻击。场景2其他条件设置与场景1相同。 由于无人机携带诱饵弹的数量明显多于空空导弹,作为无人机空中使用武器的主体,诱饵弹的使用决策能力需要进行针对性的训练。所以训练场景3的设置思路为:无人机只携带诱饵弹,在不设置舰载机空中巡逻区的水面舰艇编队中进行武器智能决策的训练,无人机携带22枚诱饵弹,按顺时针顺序飞行。训练场景如图8所示,水面舰艇编队的行动信息如表8所示。 图8 训练场景3 表8 训练场景3的水面舰艇编队的行动信息表 当无人机完成训练后,得到相应训练场景的最优个体,将最优个体代入任务场景中进行仿真实验:当得分大于100分时,认定此次仿真中,无人机任务成功;当得分小于0分时,设定任务失败。由于任务场景中,设置空中威胁共计11枚导弹,其攻击率为100%,而无人机携带的武器单枚最高拦截率为75%。一个空中威胁的导弹,无人机发射两枚空空导弹进行拦截(两个导弹互不影响),拦截概率为93.75%。按照最大概率计算,每一枚空中威胁导弹,无人机均发射两枚空空导弹进行拦截,无人机拦截所有威胁均成功(任务成功率)的概率为93.75%的11次方,为49%,并且根据设定的载弹量,无人机无法携带22枚空空导弹,因此任务场景的实际成功率不足49%。为了使得算法验证过程更加合理,设置训练场景中的最优染色体在任务场景中使得无人机任务成功率高于49%的90%时,认为最优染色体在任务场景中表现是符合要求的,表现为优;否则为表现差,此时的成功率衡量标准为44%。 经过场景1~场景3训练得出最优染色体,将其分别在任务场景中进行100次仿真实验,得到任务成功率,如表9所示。 表9 单场景训练结果表 通过上述实验数据得出,只进行单场景训练无法训练出满足复杂任务场景的优秀个体,本节采取创新性的组合场景训练方法对无人机进行训练。3个训练场景中,由于训练场景1是最基础的训练场景,所以进行组合场景训练时,训练场景1为第一个训练的场景,后续进行训练的训练场景进行随机选择,最终得到最优个体及其在任务场景中的任务成功率如表10所示。 表10 组合场景训练结果表 由表10的数据可得,经过场景1+2+3组合训练后的最优染色体[2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1, 2, 1, 2, 5, 5, 0, 8, 3, 9, 9, 8, 1, 3, 7, 7, 5, 2, 1, 2, 8, 6, 1, 2, 8, 5, 3, 9]在任务场景中成功率很高,表现优异,验证了组合场景训练这种训练方式的有效性,同时证明了本文建立的无人机武器智能决策GFT是有效、可行并且正确的。 与此同时,经过场景1+3+2组合训练的最优染色体在任务场景中成功率不高,比较实验过程发现,实验中训练场景的内容相同但训练顺序不同。由此进行假设,组合场景训练中训练场景的顺序对于训练结果有影响,最佳的场景组合顺序为先简单后复杂。 为验证假设的正确与否,在训练场景2的基础上融合场景3的训练特性创建更复杂的训练场景4,既训练无人机在威胁数量具有较大波动情况下的决策能力,又训练诱饵弹的使用决策能力。其训练场景图与场景2相同。无人机携带12枚空空导弹和24枚诱饵弹,按逆时针顺序飞行,水面舰艇A、B、C发射空空导弹数目为3、6、1枚,无人机进入巡逻区,将受到6枚空空导弹的攻击,其余设置与训练场景2相同。针对训练场景4进行实验得到任务成功率,如表11所示。 表11 训练场景4相关实验结果表 由表11的数据可得,经过场景1+4组合训练后的最优染色体[2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 1, 1, 1, 2, 1, 2, 8, 5, 0, 8, 3, 8, 9, 8, 1, 3, 2, 7, 6, 2, 1, 6, 7, 5, 1, 2, 8, 1, 3, 9]在任务场景中成功率很高,表现优异,而经过场景4+1组合训练的最优染色体在任务场景中成功率较低。此结果验证了假设的正确性,说明最佳的场景训练顺序为先简单后复杂。试分析原因,前一场景的优秀个体在继承给后一场景进行训练时,两场景共同优化的特性没有发生变化,而后一场景训练的特殊特性得到进化,使得训练得到的结果适应性更好。在进行1、4组合训练时,先1后4的训练顺序使得优秀个体在继承场景一优良特性的前提下,增加了面对复杂情况下的决策能力,而在进行先4后1组合训练时,无人机面对威胁数目有剧烈波动时的决策能力被破坏,导致染色体性能下降。 本文构建的GFT对所有的规则和输入物理量的隶属度函数参数进行编码优化,这样设置的好处是GFT可以根据训练场景的特性自行调整规则和隶属度参数,而不是仅凭专家经验进行设定。为了说明GFT的优越性,现将经过场景1+4组合训练得到的最优个体与完全基于专家经验建立的FIT进行任务场景仿真,得到任务场景得分对比图,如图9和图10所示。专家根据经验建立的FIT的染色体编码为[1, 2, 3, 2, 1, 1, 2, 1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 1, 2, 2, 5, 5, 7, 5, 3, 1, 8, 8, 5, 3, 7, 7, 5, 5, 1, 6, 7, 6, 5, 2, 8, 5, 3, 5]。其在任务场景1中的成功率为7%,在任务场景2中成功率为25%,均未达到成功率的标准值44%,表现均为差。实验结果表明,GFT训练出的最优个体在任务场景中的表现远远优于完全基于专家经验的FIT,专家根据决策经验得到的FIT不适用于设置的任务场景。由此可见,GFT相比一成不变的完全基于专家系统的FIT,虽然需要经过大量训练才能得到,但是其可以根据训练场景的特性自行调整FIT中规则和隶属度参数,具有良好的灵活性。 图9 任务场景1中的得分对比情况 图10 任务场景2中的得分对比情况 本文采用GFT的思想,创建了无人机武器智能决策GFT,解决了察打一体化无人机在执行侦察任务时,面对水面舰艇编队火力打击时如何自主智能地做出武器决策的问题。本文设计的三模糊子集参数编码设置法,解决了染色体中隶属度函数参数的编码问题,不仅操作简单,避免了无效编码导致的系统紊乱,并且保留了编码特性,是一种创新的变量设置方法。文中通过组合场景的训练方式,解决了只训练单一特性的单场景的最优个体无法满足复杂任务场景要求的问题,并且创新性的组合场景实验方法实现了场景间种群的遗传与进化,并且提出最佳的场景训练顺序为先简单后复杂。将武器智能决策GFT与完全基于专家经验的FIT进行实验对比,发现武器智能决策GFT得到的最优个体在任务场景中的表现远远优于完全基于专家经验的FIT,说明武器智能决策GFT具有很好的灵活性,进一步证明了GFT这种方法的优越性。 目前,对于实验中发现的组合场景训练顺序性规律的原因尚未进行实验验证,下一步将会对此进行研究,并将其与组合场景训练这种方法结合,创造出更高效的训练方法。
3 实验与仿真
3.1 场景设置




3.2 单场景训练结果

3.3 组合场景训练
3.4 组合场景训练的顺序性验证

3.5 对比实验


4 结 论
猜你喜欢
科普童话·神秘大侦探(2022年4期)2022-05-26
作文小学高年级(2022年2期)2022-03-03
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
文萃报·周二版(2019年28期)2019-10-21
现代兵器(2017年5期)2017-06-01
现代防御技术(2016年1期)2016-06-01
都市丽人(2015年4期)2015-03-20
