
一种LLE降维表示的汉字字体识别方法
2022-11-17 03:44王存睿
大连民族大学学报 2022年5期
刘 聪,王存睿,许 爽
(大连民族大学 a.信息与通信工程学院;b.计算机科学与工程学院;c.大连市汉字计算机字库设计技术创新中心, 辽宁 大连 116605)
字体识别可作为字体侵权行为检测的技术方法之一。不同的汉字字体的特征除了体现在字符形态的多个方面如部件的空间分布、疏密程度、中宫的聚集程度,还体现在笔画的粗细、曲直、光滑度、笔锋的变化、交叉点等方面,这将导致字体特征变得更加复杂,但同一字符的不同字体又具有较高的相似性,这给字体识别带来诸多挑战如图1。

图1 “乖”的不同字体
随着汉字行业的发展,字体种类的增加,对于字体识别侵权往往需要识别不同混合字体,这将必然导致系统识别错误率的上升。针对上述问题,本文提出了一种基于LLE降维表示的汉字字体识别方法提高汉字字体识别的准确性。
1 研究现状
在相关研究中,字体识别可以分为两类:第一种是字符无关字体识别,即在未知识别字体图片表示具体字符,识别其字体分类属性。第二种是已知字体图像的字符编码,进而识别其字体分类属性[1]。根据字体识别的对象是单字符还是多字符文本,字体识别又可以分为两种,一种是基于单字符字体识别,另一种是基于多字符字体识别[2]。文献[3]提出了一种基于经验模式分解的汉字字体识别方法,选取反映汉字字体基本特征的8种笔画作为模板,在汉字文档图像块中随机抽取笔画信息,形成笔画特征序列[3]。陈等人对单个汉字的字符图像进行小波分解,在变换图像上提取小波特征,用线性鉴别分析技术(linear discriminant analysis, LDA)进行特征选择,使用修改二次判别函数(modified quadratic discriminant function, MQDF)分类器分类[4]。许等人使用了一种基于Gabor函数的全局纹理分析字体纹理[5];王等人提出一种基于特征点的个体分析法来解决汉字字体识别问题,该方法适用于多语言混排情况[6]。Guang等人针对大规模视觉字体识别问题,提出了基于最近类平均分类器的可扩展方法,可以以较低的成本推广到新类和新数据[7]。Huang等人提出了一种DropRegion方法来生成大量随机变异字体样本,该技术自适应地构造具有均衡信息的一组局部区域,DropRegion可以无缝嵌入IFN,实现端对端的训练,进行字体分类[8]。Yanan Guo提出了一种新的特征选择算法,线性判别分析Cauchy估计器用于单中文字体识别[9]。从以上方法可以得出,字体特征提取的可靠性和分类器的有效性决定了字体识别的准确性。字体图像数据维数较高,含有一些复杂的空间结构问题,可对高维字体数据流形降维进而实现字体分类识别。
本研究从字体特征提取和分类这两个角度出发,提出一种LLE降维表示的汉字字体识别方法尝试解决这一问题。
2 特征提取
在原始数据的特征数量很大,原始数据处于高维空间结构中,通过变换映射将高维数据用低维空间来表示,这个过程叫特征提取[10]。特征提取广义上来说是一种变换,但是特征选择是从已有的特征中选择出一些有效的特征,达到降低维度的目的[11]。
为了突出字体的特征,在特征提取前,先要对图片预处理如图2。
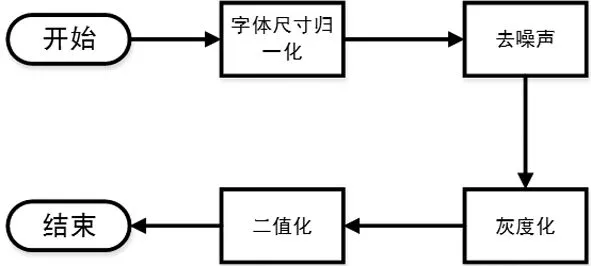
图2 字体特征提取流程图
在字体特征提取过程中首先对图像进行尺寸归一化,处理后的图像像素大小均为32×32;为了降低因处理设备等原因对图像质量的影响,采用了滤波平滑去噪处理;为了减少字体颜色等因素的影响,将图片灰度化,使其中的R=G=B;在灰度化图像的基础上对图像进行二值化处理,使得字体和背景完全为黑白两色。LLE是非线性降维方法,也是特征提取中最常见的技术之一,它与ISOMAP试图保持高维数据映射到低维空间的距离不同,LLE算法试图保持邻域内样本间的线性关系[12]。
在高维样本空间样本zi可用邻近的样本zj、zk、zl线性组合表示。
zi=wijzj+wikzk+wilzl。
(1)
为了在低维空间中局部点的相对位置关系仍然能够保持,可以按照如下步骤进行推演:
Step1:为高维数据Z中的每个样本点zi选取k个近邻点zi1,zi2,…zik;
Step2:为每个样本点计算一组权重wi,i∈[1,k]借助权重用zik重构zi;
Step3:将wi,i∈[1,k]扩充为Wi。
3 数据集
为了验证字体识别方法的有效性,本文使用的数据都是常用字体数据,用到的字体包括黑体、楷体、圆体、装饰体四种见表1。

表1 实验字体类别表
每个字体按照字典顺序取出前300个汉字,每字体随机从这300个汉字中选取200个作为训练样本,剩余的100个作为测试用例,并将字符转为32×32像素的字体图片。
4 本文方法
本文采用LLE对字体降维处理如图3。四种字体样本降维后的可视化,降维后的特征向量为Pi=(p1,p2,…,pm)。其中pm=(pm1,pm2,…,pmn),n=100。图中横纵坐标值不具备特定物理意义,对于不同特征提取方式,不同图像预处理归一化,值表示的含义不同,仅表示不同字体映射到低维空间的相对位置。
LLE关注于降维时保持样本局部的线性特征,保持原有的拓扑结构。LLE是非线性降维技术,是流形学习中最经典算法之一[13]。LLE算法将高维度字体特征映射到低维空间,且保持原有数据的特征空间。黑体HYb0gj、楷体HYh1gj、圆体HYe0gj、装饰体AliHYAiHei四种字体在低维坐标空间的聚类效果如图3。
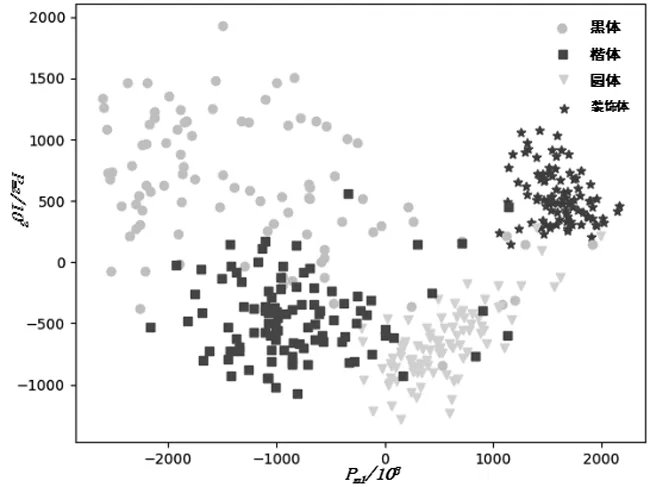
图3 四种字体降维可视化
基于LLE降维表示的汉字字体识别方法分为两部分。第一字体特征提取,首先,将字体图像数据向量化,然后使用流形降维算法LLE将高维字体数据转换成2维数据,在低维数据空间计算每个字体的聚类中心与聚类半径Rk,保留到字体特征数据集。第二邻近分类单字识别,将待识别的单字图片利用流形学习降维算法LLE同样降维到2维空间,在同一2维坐标空间中,单字图片2维点与字体特征数据集中字体聚类中心点的欧式距离作为字体的相似度判断依据。字体识别流程如图4。
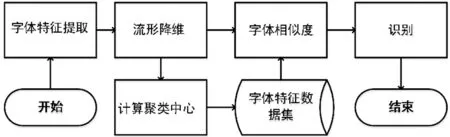
图4 字体识别流程图
先构建字体特征数据集,之后将要识别汉字单字图像降至2维,计算字体特征数据集每个字体与单字相似度,将单字归类为相似度最高字体。
构建字体特征数据集。设x为降维后字体字符向量,K为字体类目数,Rk为第k个字体聚类半径,Certerk为第k个字体聚类中心,dist(xi,xj)为两字体字符在低维坐标欧式距离,Ck为第k类族字体,t为单字测试图片,t'为降维后测试单字图片,δ(t',k)表示单字t'与第k类族字体相似度。
Step1:对聚类的每一类族随机选取1个中心点;
Step2:遍历特征数据,将每个数据划分到对应类族中心点集合;
Step3:计算每个类族中心点集合的平均值,并作为新中心点;
Step4:重复步骤2,3直到中心点不再收敛;
Step5:计算每个聚类半径Rk。
两点间欧式距离公式为
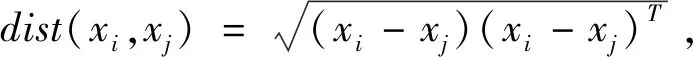
(2)
其中,x代表数据有m个属性的向量。
(3)
式中:Ck表示第k类族;|Ck|表示第k类族数据对象的个数;Certerk表示第k类族中心点,其中
Rk=max(dist(xk,Certerk)),
(4)
其中,xi∈Ck。
字体特征集为
{(Certerk,Rk)|k=1,2,…,K}。
(5)
单字识别流程为
Step1:输入单字图片t;
Step2:字体图片预处理;
Step3:使用LLE流形降维算法将字体图片降到2维t';
Step4:使用公式(5~7)遍历每个字体,获得单字与各个字体相似度;
Step5:将单字归类为相似度最高字体;
Step6:统计识别结果。
降维后单字t'与字体Ck间的相似性由单字t'与以Certerk为质心,Rk为半径的圆域欧式距离来度量,距离差越小,两字体越相似。
D(t',k)=dist(Certerk,xt')-Rk。
(6)
若D(t',k)<=0,δ(t',k)=100%;
(7)
若D(t',k)>0,
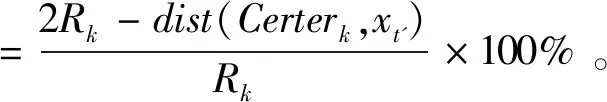
(8)
5 设计实验与实验分析
对每组字体训练数据,使用流形降维算法映射到2维空间,求出每个字体质心Certerk与圆域半径Rk如图5。图中横纵坐标值不具备特定物理意义,对于不同特征提取方式,不同图像预处理归一化,值表示的含义不同,仅表示不同字体映射到低维空间的相对位置。
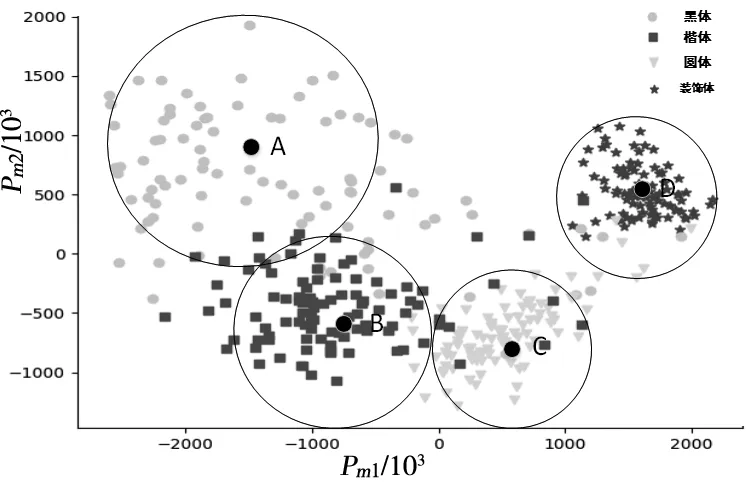
图5 字体中心点
其中,Certerk表示第K个字体中心点坐标,Rk表示第K个字体圆域半径,图中四种不同的聚类分别表示四种不同的字体,每个字体用不同颜色和形状的点标注,每个字体有一个字体中心点,其他字符到该字体中心点远近代表与该字体相似程度。
对于测试样例按照10、20、25为一个单位进行分组,每个分组最后计算平均识别率。实验结果见表2。
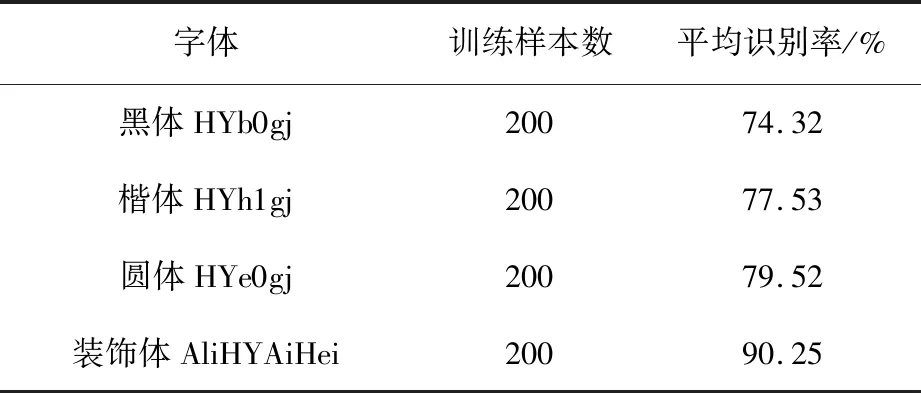
表2 四种字体平均识别率
通过对表2的实验结果分析可知,本文的方法对于不同的字体识别效果不一样。因为不同字体通过流形降维算法降维后聚类效果不一样。该实验表明,基于LLE降维表示字体分类方法整体是有效的。
6 结 语
本文在单字图片字体识别取得良好的效果,但是由于流形降维算法对某些字体降维聚类的效果并不是很好,导致实验对聚类中心点和聚类半径的计算会有偏差,所以提高流形降维算法在字体上的聚类效果,有待进一步的研究。
猜你喜欢
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
电脑报(2019年4期)2019-09-10
北方文学(2019年5期)2019-03-15
法制博览(2018年7期)2018-11-05
中华诗词(2016年11期)2016-07-21
