
单目3D目标检测中注意图特征提取网络
2022-11-17 03:44杨大伟
大连民族大学学报 2022年5期
臧 倩,杨大伟,毛 琳
(大连民族大学 机电工程学院,辽宁 大连 116605)
单目3D目标检测技术多应用于自动驾驶、机器人等领域,可识别目标的物体类别,输出其在三维空间中长宽高和旋转角等参数[1]。相较于激光雷达[2-4]检测技术,单目3D目标检测领域的目标深度特征表达能力有待提升[5]。单目3D目标检测大多通过3D深度预测分支实现对深度特征的提取,如M3D-RPN[6]在进行深度估计时,提出3D区域建议网络,通过深度感知卷积[7]感知3D参数估计,使网络学习更多的空间级高阶特征[8],网络中2D分支和3D分支共享锚点[9]和分类目标,使3D分支能够有效地获取2D空间中目标的位置信息,提高深度预测准确性。
为准确提取目标特征,捕获全局信息,Wang等[10]提出非局部神经网络(Non-local Neural Networks,NLN),用于捕获图像全局的上下文信息,建立图像中两个目标之间的像素联系,使用非局部计算获取长时记忆,提高神经网络的性能。在此基础上,Zhu等[11]将非局部神经网络应用于语义分割,提出非对称非局部神经网络(Asymmetric non-local neural networks,ANN),此网络由两部分组成,基于长距离依赖关系,通过融合不同层次的特征,构成非对称融合非局部模块(Asymmetric Fusion Non-local Block,AFNB),AFNB将不同层级的特征图分别作为输入,融合高频特征图和低频特征图以获取丰富的语义信息,较大程度提高了网络的性能。将金字塔采样结构嵌入非局部神经模块,组成非对称非局部金字塔结构(Asymmetric Pyramid Non-local Block,APNB),使用金字塔平均池化可以减少计算量提高网络的性能,但在对特征进行池化操作时,低频特征被高频特征覆盖,造成细节特征丢失,不利于下游任务中对目标深度特征的提取。Cao等[12]在特征金字塔中添加注意力机制,构成上下文特征金字塔网络(Attention-guided context feature pyramid network,AC-FPN)。网络由两个模块构成:背景提取模块(Context Extraction Module,CEM)通过提取多路感受野特征获取背景信息;注意力引导模块(Attention-guided Module,AM)利用注意力机制自适应地提取显著目标周围的关键特征。金字塔中多层感受野特征图采用自上而下的路径合并,多层特征之间没有语义联系,不利于语义特征的表达。Luo等[13]提出单目3D单级目标检测网络(Monocular 3D Single Stage Object Detector,M3DSSD),使用非对称非局部注意块(Asymmetric Non-local Attention Block,ANAB)提取多尺度特征增强特征学习。对于不同分辨率的特征图,采用多种尺寸感受野提取目标特征[14],利用注意力机制提取每个分辨率特征图的关键信息。M3DSSD实现了对多层特征中显著信息的利用,使网络获取更精准的3D空间目标位置信息,但由于对多层特征使用注意力机制,网络也存在计算复杂度偏高的问题。
本文在M3DSSD算法及注意力机制[15]的启发下,针对历史特征提取不准确的问题,提出注意图特征提取网络(Attention map feature extraction network,AFENet)。AFENet使用语义卷积得到目标特征的注意图,获取历史特征中的全局信息。注意力机制从更加准确的注意图中增强当前和历史中显著的目标特征,提高深度特征提取的准确性和完整性。
1 AFENet算法
1.1 问题分析
以往解决目标深度预测不准确问题时,可在特征提取阶段采用注意力机制获取深度特征。注意图中的特征不准确会影响网络对3D空间中目标位置信息的预测。在注意图特征提取网络中忽略对历史特征中的上下文信息捕捉。本文提出采用卷积单元加强网络对历史特征的提取能力,将特征通过注意图网络,提取全局特征信息,捕获长时记忆关系。AFENet网络逻辑结构图如图1。
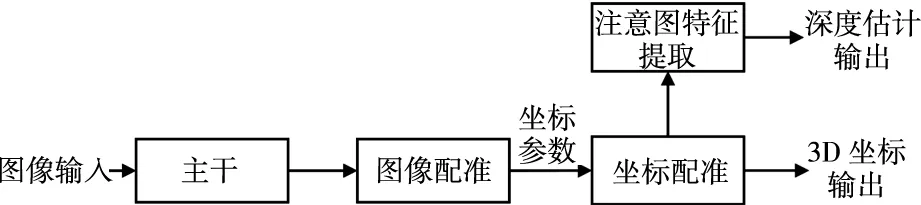
图1 AFENet网络逻辑结构图
主干模块通过卷积和上采样全连接等操作对输入图像进行处理;图像配准模块根据特征图的尺寸调整感受野的大小;坐标配准模块通过将卷积采样中心集中到目标的坐标中心,获得更精准的3D空间位置信息;注意图特征提取模块提取深度特征,生成包含准确信息的注意图,完成对目标的深度预测。
定义1:经过坐标配准处理的特征输入注意图特征提取网络,经过查询(query)矩阵和历史(key)矩阵处理,建立查询矩阵和历史矩阵关联,得到二者之间的相似矩阵。相似矩阵计算过程:
(1)
HK∈RL×C;
(2)
HQ∈RN×C。
(3)
式中:HS表示相似矩阵;HQ表示查询矩阵;HK表示历史矩阵。通过计算相似矩阵得到查询特征和历史特征之间的相似度。
定义2:相似矩阵的输出维度通过Softmax函数进行归一化,并将其与值(value)矩阵相乘。归一化计算过程:
HF=Softmax(HS)×HV;
(4)
HV∈RL×C。
(5)
式中:HV表示值(value)矩阵;HF表示注意图特征提取网络的输出矩阵。
定义3:HK为历史矩阵,通过历史语义矩阵和历史特征矩阵相乘得到,计算过程:
Hk=HC×HJ;
(6)
HC∈RC×1×1;
(7)
HJ∈RC×1×1。
(8)
式中:HC为语义矩阵;HJ表示特征矩阵。1×1表示卷积核的尺寸,通过HC矩阵提取语义特征,通过HJ提取额外的历史全局信息。
注意图特征提取网络通过采用历史矩阵计算丰富的历史特征,提高历史特征和查询特征的相似度。加强查询特征和历史特征之间的联系,解决深度特征提取不充分的问题,增强网络长时记忆能力。
1.2 注意图特征提取网络
在对原始特征进行处理时,在保持原特征完整性的基础上,通过残差结构加强网络对深度特征的提取。采用查询矩阵和历史矩阵生成特征注意图,使用历史矩阵增强对历史特征的提取能力,生成的注意图包含精确的查询特征和历史特征。
注意图特征提取网络结构图如图2。

图2 注意图特征提取网络结构图
1.3 AFENet算法
AFENet算法的基本思想是通过主干网络DLA-102[16]处理输入图像,连接层中采用的卷积均为可变形卷积(Deformable Conv,DCN)[17],通过变化感受野尺寸,增强特征的表达能力。采用注意力特征提取网络加强对深度信息的预测。
定义4:输入图像到目标检测主干网络的特征:
Y=G(X)。
(9)
式中:X表示输入特征量;G表示DLA-102主干网络中可变形卷积和下采样操作;Y表示主干网络输出的特征图。通过可变形卷积操作,可以自适应改变感受野的大小,增强特征学习能力。AFENet网络结构图如图3。
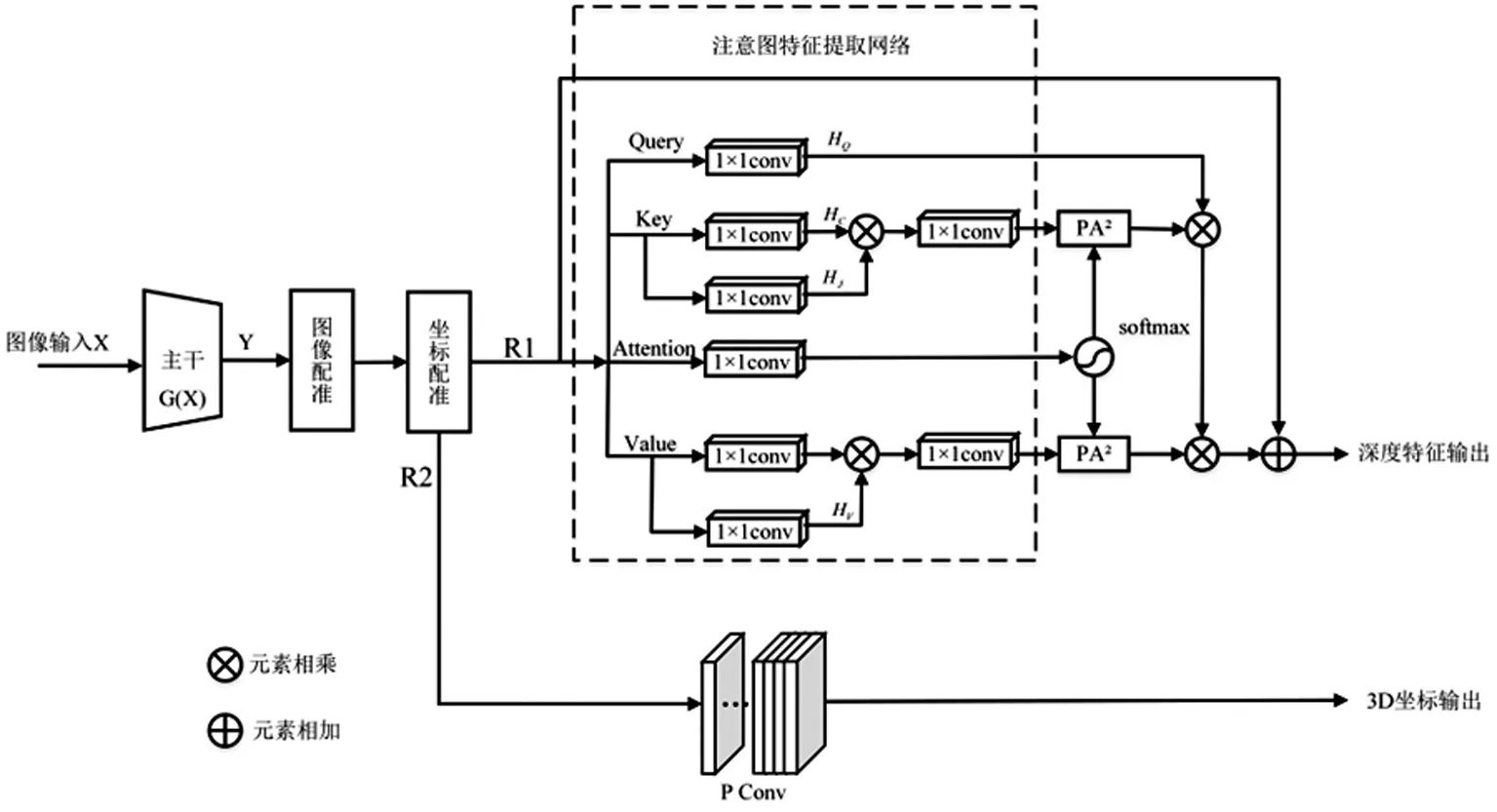
图3 AFENet网络结构图
主干DLA-102网络对输入图像处理;图像配准模块调整特征图和感受野的尺寸,实现特征尺寸对齐;P Conv卷积块由2D卷积构成,计算坐标配准后的特征R2,输出目标在三维空间中的坐标信息Xd和Yd;注意力特征提取网络从输入R1特征中提取深度特征,通过卷积单元获取历史全局信息;PA2特征金字塔结构[13]包括不同分辨率的多层特征,使用平均池化操作收集多层特征中的关键信息;Sigmoid函数调整权重,对与目标相关的关键特征信息分配更大权重。
在注意图特征提取网络中,加强历史特征的额外提取能力,实现全局信息并建立长时记忆关系。解决深度特征提取不准确的问题,提高网络在3D空间中对目标的定位能力。
2 实验结果分析
2.1 实验设计
实验运行环境硬件配置为NVIDIA-GeForce 1080Ti显卡,Ubuntu16.04软件系统,使用Pytorch0.4.1作为深度学习框架。训练使用KITTI数据集[18],其中包括7 481张带有标签的训练图像和7 518张测试图像,包含汽车、行人和骑行者等目标类别。
AFENet算法使用交并比(Intersection over Union,IoU)和平均精确度(3D mean Average Precision,3D mAP)作为评估目标检测精度的指标。实验将汽车类别的IoU阈值设为0.7,行人和骑行者的IoU阈值设为0.5,AP丨R11表示召回率设置为11,与KITTI官方标准设置相同。mAP越大,表示像素预测值和真实值的交集越大,目标检测越精准。根据图像被遮挡的程度以及目标尺寸的大小,划分简单、中等和困难三个指标下的目标检测精度。
在KITTI数据集下,将批尺寸设置为4,初始学习率为0.004,使用余弦退火(Cosine annealing)函数将学习率降为4×10-8。训练周期为70,和M3DSSD算法相比,设置相同的超参数[13]进行训练。训练阶段,将图像的尺寸调整到384×1 280,使用随机平移、水平镜像翻转和随机缩放的常规图像处理操作防止过拟合现象的产生。KITTI数据集汽车类别测试结果对比见表1。
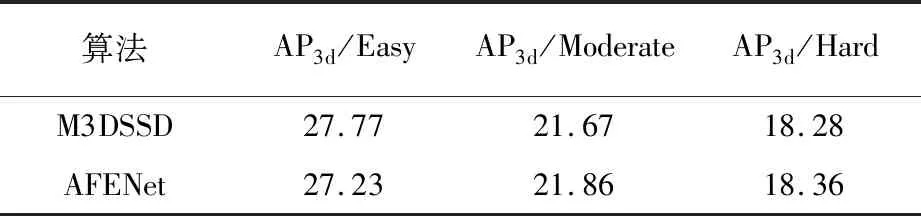
表1 KITTI数据集汽车类别测试结果对比 %
在KITTI数据集上的结果表明,AFENet算法在检测难度为中等和困难情况下,检测指标3D mAP分别高于M3DSSD算法0.8%和0.4%。AFENet算法能够有效提高检测精度,尤其在车辆类别检测效果有提高,可以应用于无人驾驶、智能机器人以及视频监控等领域。KITTI数据集行人和骑行者类别测试结果对比见表2。
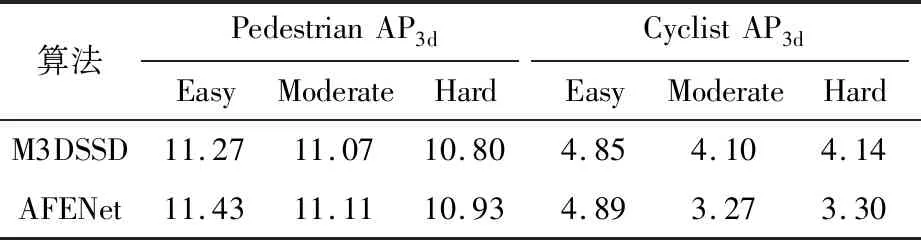
表2 KITTI数据集行人和骑行者类别测试结果对比 %
与汽车相比,行人和骑行者在检测难度上更有挑战性,因为骑行者和行人等目标尺寸较小,形状变化较大。AFENet算法在KITTI数据集上对行人和骑行者类别的检测,相较于M3DSSD算法能够输出精确度更高的目标检测。
2.2 实验结果分析
为证明历史语义卷积在特征提取上的有效性,探究语义卷积连接方式是否影响提取历史全局信息的准确度问题,测试不同卷积结构对目标检测精度的影响。实验分为三组,使用不同卷积结构,消融实验的逻辑结构图如图4。
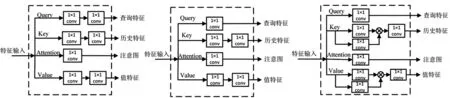
a)网络深度影响 b)查询特征相关性 c)网络宽度影响 图4 消融实验结构图
图4a为探究通过卷积复用加深网络对特征提取性能影响进行消融实验。查询(query)矩阵和历史(key)矩阵、键(value)矩阵使用相同的卷积连接结构。实验结果表明对查询特征使用两层卷积处理的方式,导致查询特征在计算过程中细节信息丢失,不能保持原特征的完整性,进而导致查询特征和历史特征的相似度下降,网络记忆能力下降。图4b为探究语义卷积对查询特征和历史特征在原始性保持上的影响。值语义卷积为历史特征进行加权,两者之间存在关联性。因此只为查询特征减少卷积层数量,探究语义卷积是否造成部分查询特征丢失。图4c为探究在网络深度适宜的基础上,增加网络宽度对历史特征提取是否有效。实验增加同一卷积层中卷积核的个数,提取额外历史全局特征,实现较好的特征提取效果,对目标的分类定位更加有效。
注意图特征提取网络中卷积核的大小不局限于1×1,可扩展应用不同大小的卷积,该原理依然有效。使用三组不同的卷积连接方式进行消融实验,发现网络的深度和宽度影响深度特征的提取能力,进而影响3D空间中目标检测能力。三组消融实验在KITTI数据集上汽车类别下的3D mAP指标见表3。
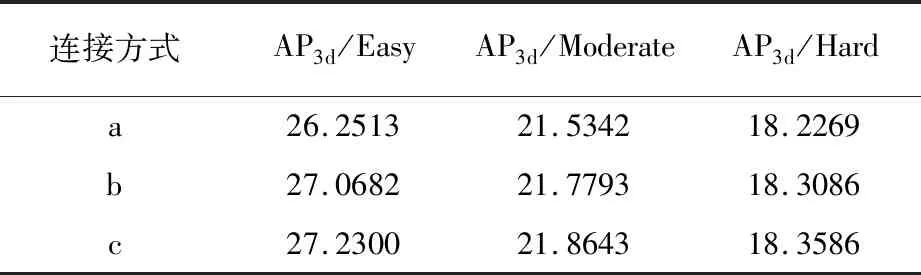
表3 不同卷积连接方式在KITTI数据集汽车类别仿真结果 %
表3中数据证明了AFENet网络中使用历史卷积对提取历史全局信息的有效性。通过使用不同卷积结构处理当前特征和历史特征,有效提高了AFENet算法对历史特征提取的准确性,增强查询特征和历史特征之间的相似性,网络记忆能力提升。
M3DSSD算法和AFENet算法在KITTI数据集上的可视化结果如图5。在街道实景中,存在多位行人,目标密集、重叠度较高。AFENet算法能够准确检测行人,在目标尺寸较小的情况下检测依然有效,并且对车辆在3D空间中的长宽高位置定位相较于M3DSSD算法更加精准。

a)M3DSSD检测结果 b)AFENet检测结果图5 KITTI数据集检测可视化结果
AFENet算法在KITTI数据集低光照度场景下的目标检测结果如图6。在前景目标和背景区域较为模糊的情况下,依然能对车辆中心位置和尺寸方向检测定位。AFENet算法增强对深度特征中历史信息的捕获,提高特征提取的准确性,对目标在3D空间中的坐标定位更加精准,实现了较好的3D目标检测效果。

图6 AFENet算法低光照场景检测结果
3 结 语
本文针对M3DSSD目标检测算法深度估计过程中存在的深度特征提取不充分问题,提出注意图特征提取网络,提取更加准确的深度特征注意图,加强对历史全局特征中上下文信息的关注。与M3DSSD算法相比,AFENet算法改善了深度特征提取不充分的问题,实现较好的目标检测效果,对3D空间目标的检测分类能力有较大提升,适应于无人驾驶以及智能机器人等应用场景。后续工作中,将进一步提高小目标和目标遮挡等复杂场景下的目标检测能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
雷达学报(2018年5期)2018-12-05
北京航空航天大学学报(2018年1期)2018-04-20
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
