
视频动作定位中密集特征金字塔主干网络
2022-11-17 03:44佟明蔚杨大伟
大连民族大学学报 2022年5期
佟明蔚,毛 琳,杨大伟
(大连民族大学 机电工程学院,辽宁 大连 116605)
时序动作定位算法主要为解决确定动作起止时间并赋予类别标签问题,在视频分析与总结、人机交互和视频处理等领域有着广泛应用[1]。现有时序动作定位算法中,存在动作分类偏差问题,主要由特征提取阶段细节特征缺失造成。细节特征缺失会使算法在预测阶段产生偏差,从而造成确定动作类别和起止时间结果偏差。
现有时序定位算法主要分为三类,分别是基于滑动窗口、锚点检测和无锚检测。滑动窗口动作定位使用滑动窗口检测方式进行时序动作定位,以Shou等[2]提出的分段卷积神经网络(Segment-CNN,S-CNN)最为经典,滑动窗口与检测窗口覆盖重叠度越高,找到片段越完整,但缺点是计算量大、效率低,定位时间不准确。锚点检测动作定位也称单元回归方法,受两阶段目标检测算法启发,将视频分为固定大小单元,以单元为中心锚点,向两端扩展寻找不同长度片段;Gao等[3]提出时序单位回归网络(Temporal Unit Regression Network,TURN),以视频单元为最小计算单位,避免滑动窗口重叠度太高带来冗余,还可以对时序区间进行边界修正;Xu等[4]提出的区域卷积3D网络(Region Convolutional 3D Network,R-C3D)是一种端到端网络,把定位和分类结合起来一起训练,将整个网络划分为三个部分,分别是特征提取、时序候选段子网和分类子网,这种方法可以接受任意长度视频输入,节约计算成本;Long等[5]提出高斯时间感知网络(Gaussian Temporal Awareness Networks,GTAN)修改池化过程,通过一个可学习高斯核对每个提议采用加权平均。无锚检测动作定位可以减少有锚方法产生的冗余,无锚方法将整个网络分为特征提取和边界预测两部分,强调特征提取在边界预测中的重要性,这种方式可以更好地提升效率,但边界预测准确性更加依赖特征提取的准确性;Lin等[6]提出显著性边界特征无锚框时序动作检测方法(Anchor-Free Saliency-based Detector,AFSD),采用无锚方法能够提升边界预测的准确性。但上述三种不同方法均没有考虑动作信息在特征提取阶段的缺失问题,无锚检测方法可有效减少冗余提高效率,但在特征提取阶段忽略了细节特征缺失,导致预测结果不准确。
综上所述,针对细节特征丢失导致预测结果不准确的问题,本研究基于AFSD算法,提出密集连接型特征金字塔主干网络(Dense connection feature pyramid backbone networks,DFPNet)。网络针对RGB支路的特征提取阶段进行密集连接,实现金字塔参考层特征、基础层特征与深层特征的联系,能够解决金字塔层数增加导致的时间分辨率降低,细节特征不完整问题。通过为预测阶段提供更完整的特征,提高动作类别和动作起止时间预测结果的准确性。
1 密集连接特征金字塔主干网络
1.1 问题分析
本文根据算法功能将AFSD算法分为三个阶段,分别是特征提取主干网、预测阶段和融合阶段,预测阶段特征来源于特征提取主干网。AFSD网络结构图如图1。
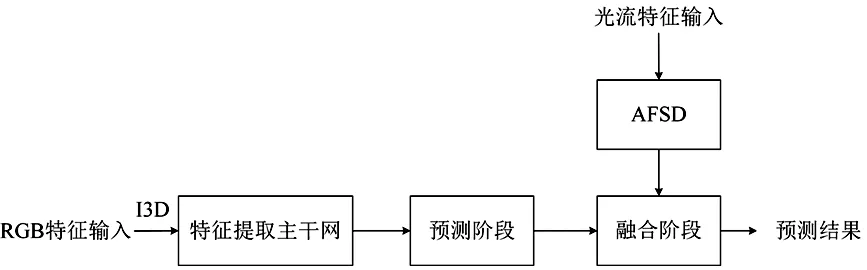
图1 AFSD网络结构图
AFSD算法在特征提取主干网中采用一维时序特征金字塔进行特征提取,对AFSD特征提取主干网特征。
(1)
式中:x1、x2为图像特征;Fi为金字塔第i层特征;Convi为金字塔第i层卷积运算;i为金字塔层数;N为金字塔总层数。
在特征金字塔层数i增加时,会导致时间分辨率降低,进而造成细节特征不完整,引发动作定位算法预测结果不准确的问题。为解决以上问题,本文提出DFPNet网络。借用Huang等[7]提出的密集连接卷积神经网络(Densely Connected Convolutional Networks,DenseNet)的密集连接思想,构造密集连接型特征提取主干网络,增强层与层之间的联系,将基础层和参考层中较为完整的细节特征提供给深层,对深层中不完整的细节特征加以补充,进而提高预测准确性。
1.2 密集连接特征金字塔
在AFSD一维时序特征金字塔,采用双输入特征金字塔:一支逐层提取金字塔特征,并将每一层特征作为层级特征提供给预测阶段;另一支取金字塔参考层与基础层融合后的结果作为帧级特征,提供给预测阶段。特征金字塔(Feature Pyramid Networks, FPN)[8]是一种常见的特征提取工具,在金字塔层数加深的同时,特征会有部分丢失。同样一维时序金字塔则在层数加深的过程中,会产生细节特征缺失现象,直接影响后续预测动作类别和动作起止时间结果的准确性。
DFPNet网络为提高预测结果的准确性,将金字塔中时间分辨率较高且细节特征保留较为完整的参考层特征、基础层特征和前序金字塔深层特征,通过下采样相加的方式,作为细节特征补充,提供给特征金字塔深层参考。构造一个特殊密集连接形式的特征金字塔,使得细节特征更加丰富完整,解决由于金字塔层数增加,导致时间分辨率降低、细节特征不完整的问题[9]。通过采用细节特征更加丰富且完整的特征提取主干网络,为预测阶段提供更丰富且完整的特征,进而提高预测阶段的准确性。DFPNet网络中密集连接型特征金字塔结构如图2。
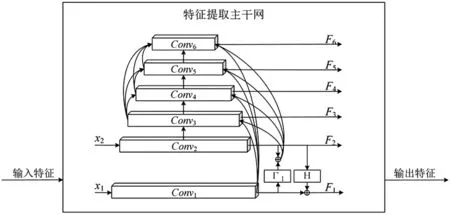
图2 密集连接特征提取金字塔图
DFPNet网络特征金字塔各层特征定义如下。
定义2:一个N层金字塔结构,其中i=1为金字塔参考层,i=2为金字塔基础层,i∈[3,N]为金字塔深层。金字塔参考层特征由输入图像特征x1通过卷积运算得出,金字塔基础层特征由输入特征x2通过卷积运算得出,金字塔融合细节特征由金字塔参考层特征与金字塔基础层特征相加得出,金字塔深层特征由金字塔第i-1层特征通过卷积运算结果、所有前序金字塔深层特征、参考层特征和金字塔融合细节特征求和得出,金字塔各层特征计算如下:
式中:x1、x2为图像特征;Fi为金字塔第i层特征;Convi为金字塔第i层卷积运算;i为金字塔层数;FR为金字塔融合细节特征;Γ为下采样计算;Η为上采样计算;N为金字塔总层数。
2015年,李克强总理在政府工作报告中首次提出制定“互联网+”行动计划,“互联网+”一跃成为社会各界追捧的热词。2015年7月,国务院印发《关于积极推进“互联网+”行动的指导意见》,其中对“互联网+”的解释是“把互联网的创新成果与经济社会各领域深度融合,推动技术进步、效率提升和组织变革,提升实体经济创新力和生产力,形成更广泛的以互联网为基础设施和创新要素的经济社会发展新形态”。
密集连接金字塔x1、x2作为输入,x1作为金字塔参考层与金字塔深层相加,x2作为金字塔的初始输入通过卷积进行逐层传递。层数增加导致时间分辨率降低,细节特征不完整,需建立基础层与深层之间的联系,因此将参考层与金字塔深层进行相加,增加参考层与深层之间的联系。同时考虑参考层与深层之间的差异较大,只进行参考层与深层之间的联系会导致效果不佳,将参考层与基础层相加作为基础层特征,进行基础层与深层的联系再次加强参考层、基础层与深层特征之间的联系,通过提供更完整的细节特征,提高动作类别与起止时间的准确性。总体上看,密集连接特征金字塔通过加强参考层、基础层与深层特征之间的联系,在一定程度上,能够保证金字塔传递时特征的完整性。
1.3 DFPNet网络结构
DFPNet网络是通过对RGB支路的特征金字塔进行密集连接,增加层间联系,对深层细节特征进行补充,光流信息作为DFPNet网络时序信息的补充与RGB信息的预测结果进行融合。DFPNet网络结构如图3。
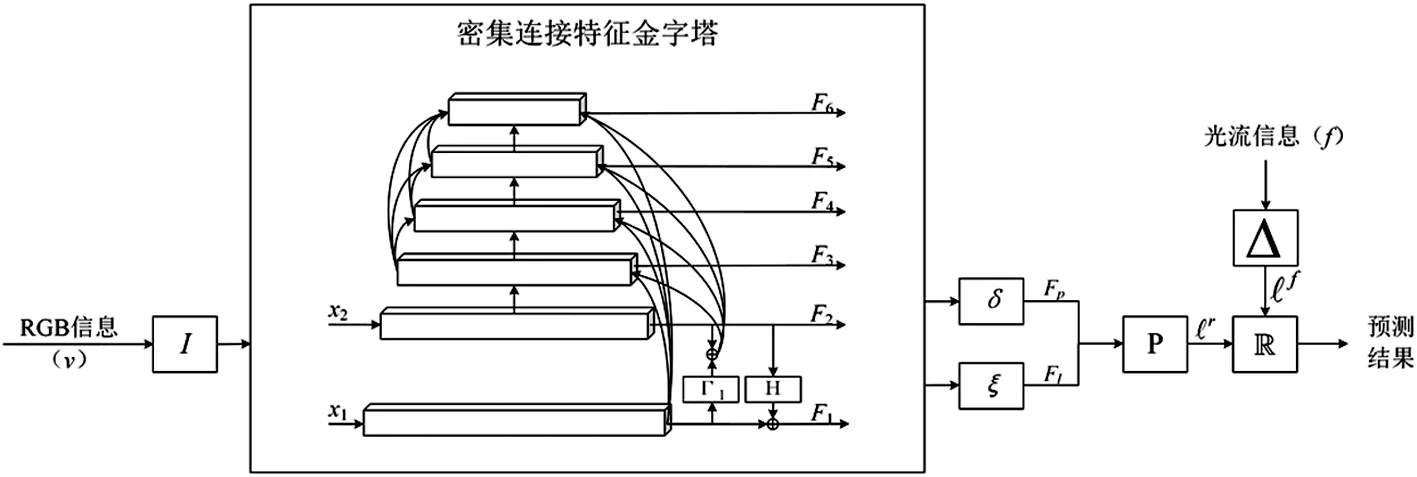
图3 DFPNet网络结构图
整体密集连接特征金字塔主干网络具体步骤如下:
(1)采用双路膨胀3D卷积[10]对RGB图像特征进行预处理,并提取x1、x2图像特征;
(2)采用密集连接特征提取金字塔主干网络,提取帧级特征Fl和逐层特征Fp;
(3)对提取出的特征进行边界预测,得到RGB支路预测结果r;
(5)将RGB和光流预测结果进行融合,得到融合后的动作类别信息和动作起止时间信息;
(6)输出动作起止时间、动作标签预测结果。
2 实验与结果
2.1 实验配置及结果分析
本文网络使用NVIDIA GeForce 1080Ti显卡,在Ubuntu16.04环境中配置Pytorch1.4.0深度学习框架,训练和测试网络模型。
THUMOS14[11]由200个验证视频和212个测试视频组成,这些视频包含20个动作类别且均标定有动作时间定位,按照原文将该数据集按2:1:1比例拆分为训练子集、验证子集和测试子集。以每秒10帧(fps)的速度对RGB和光流帧进行采样,并将视频分割成片段,每个剪辑T的长度设置为256帧。
评价指标为在阈值(tIoU)为0.3~0.7均值平均精度(Mean Average Precision,mAP),mAP越高表示预测准确度越高,mAP计算过程为
(3)
式中:K为类别;APi为平均查准率。
采用THUMOS14数据集,实验结果对比见表1。
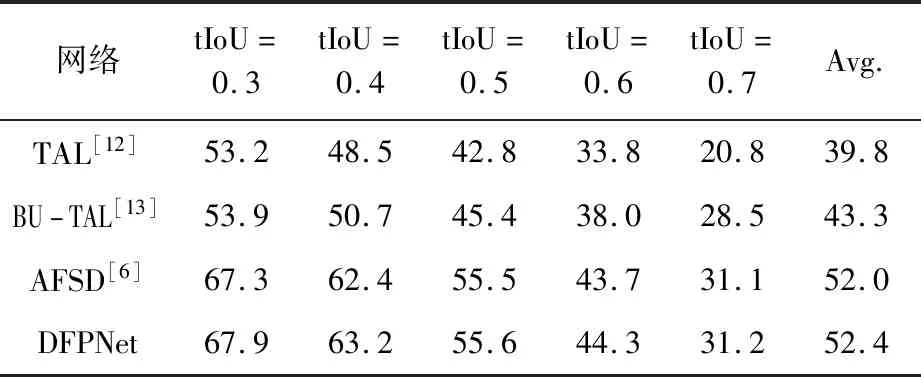
表1 实验结果对比 %
与其他动作定位算法相比,本文提出的DFPNet网络mAP为52.4%,相对于AFSD提高0.4%,在tIoU从0.3到0.7的mAP与均值mAP均高于原网络。以四段视频为例,动作类别与动作起止时间预测结果对比如图4。

d)可视化结果4(单位:s)
图4中的视频指真值时间所指视频段,而非完整视频。在类别确定的情况下,图4a中DFPNet预测动作开始时间比原网络精确0.3 s,动作结束时间比原网络精确0.3 s;图4b中DFPNet预测动作开始时间比原网络精确0.3 s;图4c中DFPNet预测动作结束时间比原网络精确0.1 s;图4d中DFPNet预测动作开始时间比原网络精确0.1 s,动作结束时间比原网络精确0.1 s。通过对比可以看出,本文提出的DFPNet网络对细节特征进行补充,对预测动作起止时间的效果进行细化,减少了由于视频动作与视频背景更贴近而造成的起止时间误判,使得预测动作结果相较于AFSD动作起止时间的预测更贴近真值。
2.2 消融实验
为验证DFPNet的有效性,尝试不同的密集连接方式,四种对特征提取金字塔进行密集连接方式如图5。图5a中DFPNet-Ⅰ型密集连接特征金字塔为完全密集连接,直接将金字塔参考层和基础层直接与深层进行相加;图5b中DFPNet-Ⅱ型密集连接特征金字塔为减少参考层与基础层之间的连接,单执行基础层与深层之间的联系,基础层之间无连接;图5c中DFPNet-Ⅲ型密集连接特征金字塔为只进行深层之间密集连接;图5d中DFPNet-Ⅳ型密集连接特征金字塔对整个特征提取阶段进行隔层相连。最终得出将参考层与基础层先融合,金字塔融合细节特征,并将参考层、金字塔融合细节特征与前序金字塔深层特征给予深层特征,细节特征补充的效果最佳。

a)Ⅰ型密集连接特征金字塔 b)Ⅱ型密集连接特征金字塔
为证明DFPNet密集连接的有效性,尝试不同密集连接方式对边界预测结果的影响,消融实验结果对比见表2。DFPNet-Ⅰ型密集连接特征金字塔与本文提出的密集连接型特征金字塔相比,减少参考层与基础层之间的融合连接,对比发现效果下降;DFPNet-Ⅱ型密集连接特征金字塔相比Ⅰ型的效果有所提升;DFPNet-Ⅲ型相比Ⅰ型效果有所提升,但相比Ⅱ型效果下降,表明只对深层进行密集连接并不是造成Ⅰ型效果明显下降的原因;DFPNet-Ⅳ型相比Ⅰ型和Ⅲ型有所提升,相比Ⅱ型有所下降,表明密集连接效果好于跨层连接,同时证明参考层与基础层对特征提取结果有影响。因此,在进行了以上四种密集连接型金字塔后,尝试将参考层与基础层特征融合后作为基础层特征加给深层特征进行参考,构造DFPNet网络中密集连接型金字塔结构。
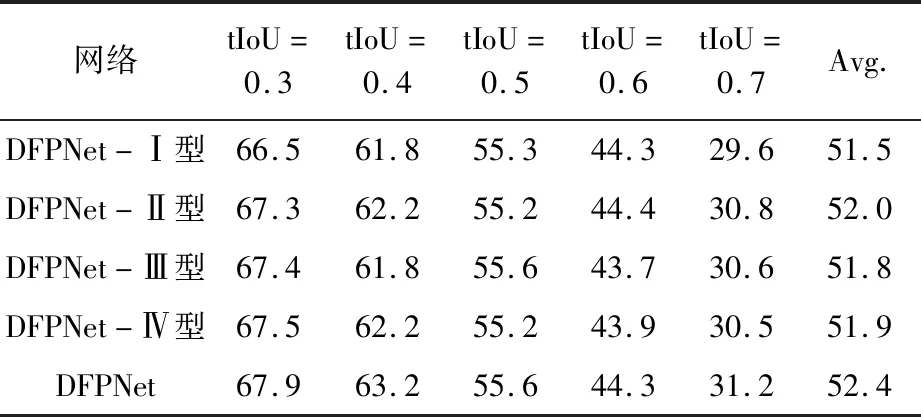
表2 消融实验结果对比 %
3 结 语
本文针对动作定位算法中预测不准确的问题提出DFPNet网络,通过提出密集连接特征金字塔,增强金字塔层间联系,改善了由金字塔层数加深导致的时间分辨率降低,从而造成的细节特征不完整问题。与AFSD相比,DFPNet网络对确定动作起止时间并赋予类别标签问题有显著提升,适用于视频动作定位、智能监控等领域。在后续工作中,将进一步提高网络的平均精度均值,提高确定动作定位和分类的准确性。
猜你喜欢
环球时报(2022-09-19)2022-09-19
煤气与热力(2022年2期)2022-03-09
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
建材发展导向(2021年7期)2021-07-16
考试与评价·七年级版(2020年4期)2020-10-23
马克思主义哲学研究(2020年2期)2020-07-21
小学教学研究·新小读者(2017年9期)2017-10-25
BOSS臻品(2015年1期)2015-09-10
太空探索(2015年5期)2015-07-12
