
加强重识别的行人多目标跟踪算法
2022-11-16 02:24王黎明陈祺东
计算机工程与应用 2022年21期
王黎明,孙 俊,陈祺东
江南大学 人工智能与计算机学院,江苏 无锡 214122
多目标跟踪(multi-object tracking,MOT)是计算机视觉领域中的重要任务之一[1]。其目的是同时识别与跟踪视频中的多个目标,并为每个目标分配唯一且长时间有效的ID 编号,以获得目标的运动轨迹。根据使用视频序列的方式,可将多目标跟踪分为在线多目标跟踪和离线多目标跟踪两类。离线跟踪能综合视频全局信息获得较好的跟踪效果,但在线跟踪更符合现实应用场景,也是目前多目标跟踪的热门研究方向。然而,由于在线跟踪无法利用视频后续图像信息,因此跟踪效果更依赖于当前图像的目标检测精度。在尺度变换和频繁遮挡等复杂场景下,检测精度降低会导致跟踪效果变差。如何在兼顾实时性的同时提高跟踪鲁棒性,仍存在一些挑战。
随着深度学习在图像领域的快速发展,目标检测算法的精度不断提高[2-6],很多学者选择基于检测的跟踪策略(tracking by detection,TBD)[1]。TBD 方法将高精度检测器与Re-ID[7]算法结合,获得了较好的跟踪性能。其中Re-ID 算法常利用深度学习模型提取目标表观特征,再通过欧式距离、余弦距离等度量函数进行特征间的相似性分析,从而引入目标间的区分度,减少跟踪目标的误匹配。根据Re-ID特征提取方法的不同,多目标跟踪又分为SDE(separate detection and embedding)和JDE(joint detection and embedding)两类[8]。SDE 方法的Re-ID特征提取独立于检测模型,使用单独的特征提取网络获取目标图像的表观特征。虽然这种two-step方法可以获得较好的表观特征,但比较耗时,很难达到实时效果。JDE将目标检测和embedding提取模块集成到单一网络中,能并行输出图像的检测信息和Re-ID特征图,再利用检测信息获取目标对应的特征向量,避免了特征重复提取的冗余计算。但one-shot 方法需要在单一网络中提取检测和表观两种不同的特征,很难使两个任务同时达到最好的效果,且通过检测信息定位特征向量容易产生偏差,导致Re-ID 特征模糊问题,因此其跟踪精度往往低于two-step 方法。FairMOT[9]通过融合深层和浅层特征来缓解检测与表观特征之间的矛盾,并使用基于无锚检测的CenterNet[5]作为检测器,来减小Re-ID特征的模糊性,进一步提升了跟踪精度,并达到实时要求。
但CenterNet 是基于中心点的检测算法,用于跟踪训练时,仅将Re-ID特征图中目标中心点处的特征向量送入分类器进行分类学习。因此每个目标仅包含一个可学习特征向量,在Re-ID 特征图上的范围较小,特征质量不高。同时,由于CenterNet存在检测偏差,若未命中目标中心点,则无法准确定位特征图上的可学习特征位置,导致Re-ID 任务过分依赖于检测精度。因此,即使Re-ID特征图有高质量的表观特征,也无法通过定位信息准确获取,从而影响Re-ID 效果,降低跟踪精度。为加强Re-ID特征提取的鲁棒性,本文从检测和特征范围两方面进行改进:首先,通过设计中心点检测偏差损失,抑制预测热力图中非真值位置的响应值大小,使高响应值向目标真值位置逼近,提升检测效果和Re-ID 可学习特征位置的命中率,减小检测偏差对特征提取的影响。其次,提出Re-ID 可学习特征动态扩充策略,根据目标尺度对其在Re-ID特征图上的可学习特征范围做自适应扩充,通过扩大可学习特征范围来提高Re-ID 任务对检测偏差的容忍度。这样即使存在定位偏差也能保证Re-ID 特征质量,减小Re-ID 对检测精度的依赖。
1 相关工作
1.1 多目标跟踪
目前在线多目标跟踪方法主要分为two-step 和one-shot 两种类型。其中two-step 为两步式,首先使用高性能目标检测器检测目标位置,再根据检测框裁剪出目标图像,并输入ID嵌入网络提取Re-ID特征用于轨迹关联。例如DeepSort[10]算法使用YOLOv3[4]作为检测器,在Sort[11]的基础上引入Re-ID外观模型和运动模型,并提出级联匹配策略,提高了跟踪鲁棒性。POI[12]使用Faster R-CNN[2]作为检测器,并结合多尺度特征提高跟踪精度。由于two-step 方法可以对检测算法和ID 嵌入网络单独训练,两个任务可以分别得到最优模型,使算法有较高的跟踪精度。但跟踪过程需要两个模型依次处理,难以达到实时效果。
JDE方法的提出使one-shot多目标跟踪受到广泛关注,其目的是在一个单一网络中并行输出目标的检测结果和Re-ID特征,以端到端的方式提取视频序列中的跟踪信息,提高跟踪效率。一个实现one-shot MOT 的简单有效方法是将Re-ID 特征提取网络嵌入现有检测器中,如在检测器顶端添加与检测头并行的Re-ID 模块,使其与检测器共享特征提取网络。目前one-shot 算法大多采用上述方法,例如Track-RCNN[13]在Mask R-CNN[3]检测器顶端添加全连接层,可以同时为每个提议回归检测框和Re-ID特征,但Mask R-CNN是两阶段目标检测器,仍达不到实时效果。JDE在单阶段检测器YOLOv3上添加Re-ID 模块,不仅达到领先two-step 方法的跟踪精度,而且有接近实时的跟踪效果。FairMOT指出JDE方法在单一网络中提取检测和Re-ID 特征存在不公平等问题,并采用基于anchor-free 的CenterNet,超越了two-step方法的跟踪精度,并实现了实时跟踪。
1.2 重识别
行人重识别是利用计算机视觉技术检索图像或视频序列中是否存在特定行人的技术[14]。在多目标跟踪任务中,常利用重识别算法引入目标间的区分度,来提高跟踪算法的匹配精度,减少误匹配。同时重识别的特定目标再识别能力可以帮助丢失目标的轨迹重新匹配再次出现的目标,提高跟踪鲁棒性。重识别任务主要包含表观特征提取和相似性度量两个部分。传统方法采用手工提取图像特征,但手工特征描述能力有限,很难适应复杂场景,而基于深度学习的方法可以自动学习目标的复杂特征,且使用简单的度量函数进行相似性度量就可以取得很好的性能[15]。因此很多学者关注于特征质量的提升,如文献[16]采用多分支网络提取目标特征,通过多分支协作来加强网络对行人特征的学习。文献[17-18]通过增强特征融合来提高表观特征的鲁棒性,文献[19]通过迁移衣服特征来消除行人衣服特征的差异。同时因全局特征易受环境因素干扰,识别精度较低等问题,基于局部特征的方法也迅速发展[20-21]。相似性度量常使用距离度量函数如欧氏距离、余弦距离等来判断特征的相似度,同时也有对度量算法的研究,如文献[22]使用组合度量策略来提高模型泛化能力。此外,还有使用GAN网络通过数据增强来解决行人重识别难点的方法[23-24]。
2 模型
本文同样采用上述one-shot方法,使用CenterNet作为检测器,添加与检测头并行的Re-ID模块,使其与检测器共享特征提取网络,如图1 所示。其中Strengthened Re-ID通过扩大Re-ID可学习特征范围来提高特征向量质量,从而加强Re-ID 效果。同时模型对预测heatmap响应值进行约束,以提高中心点检测精度,从而更准确的命中可学习特征位置,保证Re-ID 特征质量,加强重识别效果。
2.1 骨干网络
为满足检测与重识别对特征提取的不同需求,本文编码器-解码器网络采用DLA34[9]网络,如图2所示。该网络包含很多低维特征与高维特征的跳跃连接,能更好地融合深层和浅层特征,提取目标定位与表观信息。其中Stage 为树状连接[25],Sum Node 为加和操作,数字代表下采样倍数,输入图像大小统一为1 088×608,输出大小为64×272×152的特征图。
2.2 检测模块
检测模块由Heatmap head、Offset head和Box head三个预测头组成,分别对目标中心点、中心点偏移补偿和中心点到box 边框的距离进行预测,得到检测结果。本文通过构造中心点检测偏差损失,使预测位置向GT位置逼近,从而提高检测效果。
2.2.1 Heatmap检测偏差
Heatmap head输出大小为272×152的热力图,用于预测目标中心点位置。但通过heatmap预测目标中心点容易出现预测位置偏移,无法准确命中目标GT 位置的情况。如图3为一目标的预测热力图与GT热力图的对比,其中数字为响应值,坐标轴标注为热力图中的坐标位置。三角标记为目标GT位置(GT响应值为1),菱形标记为预测目标的最高响应值位置,即预测目标位置,可以看出预测位置与GT位置存在一个单位的偏差。虽然这种微小偏差对检测精度的影响较小,但由于Re-ID特征图仅在GT 位置设置可学习特征向量,因此细微的偏差也会导致无法准确定位可学习特征位置,影响Re-ID效果。
为解决该问题,本文将预测位置到对应GT 位置的距离定义为距离偏差,并以高响应值的平均距离偏差构建检测偏差损失,来抑制非GT位置的预测响应值大小,使预测位置更接近GT,进一步提高检测精度,如图1中Improved heatmap所示。如此,以目标GT位置为中心,响应值较高的预测位置距GT越远,带来的损失越大,对其响应值的抑制效果越强,相反,越靠近GT 位置,对高响应值的抑制效果越小,从而使预测高响应值向GT 位置靠拢,实现对检测偏差的修正。例如图3预测热力图中GT位置的预测响应值为0.92,而周围非GT处存在相近以及更高的预测响应值,如预测位置为0.94。构建偏差损失后,GT 处检测偏差为零,没有抑制效果,但对其余位置的高响应值均有不同程度的抑制,从而保证GT处有最高响应值,将预测位置修正到GT。
2.2.2 Heatmap损失计算
Heatmap 损失包括响应值预测损失和检测偏差损失,预测损失定义为预测响应值与GT响应值的误差,由于中心点检测存在正负样本和难易样本比例失衡的问题,为减小样本不均匀的影响,损失函数沿用CenterNet中的focal loss[26],计算定义如下:
其中,N为目标个数,α=2 用于控制易分类样本权重,β=4 用于减少负样本权重占比,R^xy为heatmap在(x,y)处的预测响应值,Rxy为GT响应值,计算如下:
从上式可以看出当Lp较大时,系数e-Lp较小,因此Ld对Lhm几乎无影响。但随着Lp不断减小,检测偏差损失会逐渐增加约束力度,使约束过程更加平滑,获得更好的效果。
2.2.3 Offset和Box损失
2.3 Re-ID可学习特征扩充
Re-ID head输出大小为128×272×152的特征图,每个特征点包含一个128 维的特征向量。如图1 中Strengthened Re-ID所示,本文通过扩大Re-ID可学习特征范围来提高ID embedding 特征向量质量,进而加强重识别效果。
2.3.1 扩充策略
Re-ID可学习特征的原始分布仅使用目标GT处的特征向量进行训练,这会增大Re-ID 对检测精度的依赖,若未命中可学习特征将直接影响跟踪效果。图4为不同尺度目标的Re-ID可学习特征设置过程,先由目标GT热力图确定位置,再对应到Re-ID feature map,确定可学习特征向量,坐标轴标注为热力图和特征图的坐标位置。其中图4(a)为原始分布,所有目标的Re-ID可学习特征都在GT 位置。然而中心点检测存在检测偏差,如图3 中菱形标记的最高响应并未命中GT 位置,这种定位信息的微小偏差也会降低Re-ID特征质量,影响ID重识别效果。
显然,扩大目标Re-ID可学习特征范围可以缓解上述问题,提高命中机率。考虑到检测偏差仅在GT 位置附近,范围较小,且可学习特征增加需对多尺度目标自适应,因此本文提出一种Re-ID 可学习特征基于GT 热力图的自适应扩充方法。具体如下,以目标热力图GT位置为中心设置大小为3×3的可扩充范围,如图4(b)中GT heatmap 所示,绿色标记为可扩充范围。取扩充阈值θ=0.5,将可扩充范围内响应值大于阈值的位置设为可学习特征位置,并对应到Re-ID 特征图,如图4(b)中Re-ID feature map所示,红色标记为Re-ID可学习特征向量。经过可学习特征扩充,可以提高Re-ID对检测偏差的容忍度,保证Re-ID 特征质量,使重识别更具鲁棒性。且由于可学习特征扩充是在输出的Re-ID 特征图上扩充学习范围,未增加网络的正向推理计算,扩充过程也仅在训练阶段,因此对在线跟踪的实时性无影响。
可学习特征的扩充范围应根据数据集的目标大小设置,MOT17训练集有76.5%的目标Re-ID特征扩充范围(GT热力图响应值大于阈值的范围)在3×3以内。因此将该范围设置为3×3可以满足大部分目标,若继续增大范围,则容易产生相近目标的ID歧义,即特征向量对不同目标的归属问题。同时为避免ID 歧义,本文不对热力图上间距小于3的目标进行特征扩充。
2.3.2 Re-ID损失
为在连续视频图像中准确识别同一目标,Re-ID 模块通过Re-ID head提取特征图F∈R128×272×152,并以目标中心处特征向量Fx,y∈R128的相似度来区分目标。因此将Re-ID作为分类任务进行训练,数据集中ID相同的目标视为同一类。损失计算仅使用ID真值处的分类结果,将真值处目标特征向量Fx,y经过一个线性分类层,得到其对每个ID分类的概率值P={p(k),k∈[1,K]},其中K为类别个数,即ID总数。Re-ID损失计算如下:
其中,Yi(k)表示第i个目标的真实ID概率分布。
2.4 多任务训练
为同时训练检测任务和Re-ID任务,使用不确定性损失[27]动态平衡两个任务,计算如下:
其中,ω1和ω2为可学习参数,用于平衡任务,初始值分别为-1.85和-1.05。
2.5 在线关联
本文采用标准在线跟踪算法进行关联[9],过程如图5所示。首先,通过网络提取输入图像的目标检测框和Re-ID 特征向量,然后根据Re-ID 特征的余弦距离计算代价矩阵。同时融合运动信息,利用卡尔曼滤波器[28]和马氏距离排除相距较远的匹配,再利用匈牙利算法[29]完成第一次匹配。对未匹配的轨迹,根据其与未匹配目标的检测框计算IoU代价矩阵,再利用匈牙利算法完成第二次匹配。最后更新轨迹信息,对未匹配的目标创建新轨迹,对未匹配的轨迹做记录,当现有轨迹未连接新目标的次数超过一定阈值,则视该轨迹结束,不再对其更新。
3 实验
3.1 数据集和评估指标
3.1.1 数据集
实验使用MOT17训练集进行训练,使用MOT16训练集验证算法有效性,并在MOT16和MOT17测试集[30]评估算法性能。MOT17 训练集包含7 个视频序列,5 316张图片,112 297个边界框标注和548个ID标注。
3.1.2 评估指标
使用MOT Challenge Benchmark[30]的评价算法进行评估,所采用的评价指标如下:
多目标跟踪准确度(multiple object tracking accuracy,MOTA):同时参考误检、漏检和ID切换等指标,能够直观地衡量算法检测并保持目标轨迹的性能。
识别F1 值(identification F1 score,IDF1):用于衡量ID 识别准确率与召回率之间的平衡性,评估跟踪器的ID识别性能。
命中轨迹比(mostly tracked targets,MT):定义为跟踪轨迹占真实轨迹80%以上的轨迹数与轨迹总数之比。
丢失轨迹比(mostly lost targets,ML):定义为跟踪轨迹占真实轨迹20%以下的轨迹数与轨迹总数之比。
ID 切换(identity switches,IDs):目标ID 发生改变的总数。
FPS:帧率。
3.2 实验环境及训练细节
实验硬件环境为搭载Intel Xeon CPU E5-2650 v4、2.2 GHz处理器和Tesla K80显卡(4张)的深度学习服务器。在单个NVIDIA RTX 2080Ti GPU上测试运行帧率。软件环境为64 位Centos7 操作系统下的Pytorch深度学习框架。
实验使用CenterNet 在COCO[31]数据集上的目标检测模型参数[5]初始化算法模型。采用Adam 优化器,在MOT17数据集训练35个epoch,batch size设置为12,初始学习率设为e-4,在第25个epoch衰减为e-5。输入图像大小统一为1 088×608,并使用旋转、缩放和颜色抖动等标准数据增强技术进行预处理。
3.3 实验结果
首先对检测偏差损失的响应阈值λ和Re-ID阈值θ的选取进行探讨,并通过实验分析选取不同阈值对跟踪效果的影响。阈值λ用于对非GT位置的高响应值进行约束,若选取过高,则对检测偏差的约束力度较小,检测效果提升不明显。相反,若阈值λ较低,则会过早对中心点偏差进行约束,影响检测任务的初期训练,且对低响应位置约束的意义不大。阈值θ用于判断Re-ID 可学习特征的扩充范围,过高则会使特征扩充偏向于大目标,无法提升小目标的重识别效果。而目标经过4倍下采样后的特征图可能小于9 个特征点,若θ较小,扩充范围过大则会给Re-ID特征带来噪声,影响ID重识别效果。为研究不同阈值对跟踪效果的影响,选择0.5 作为阈值,上下波动0.1进行对比,结果如表1和表2所示,其中阈值1为原始效果。
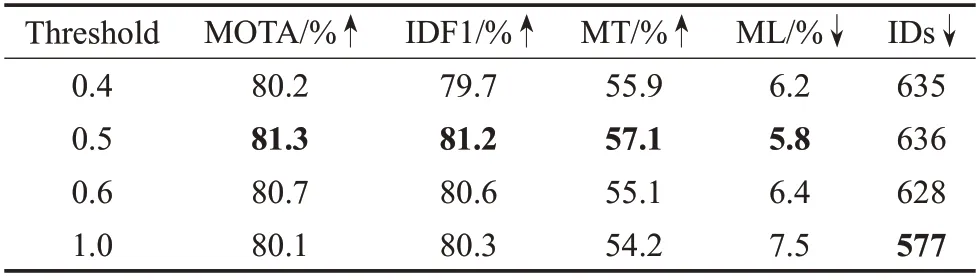
表1 热力图响应阈值对比Table 1 Comparison of heatmap response thresholds
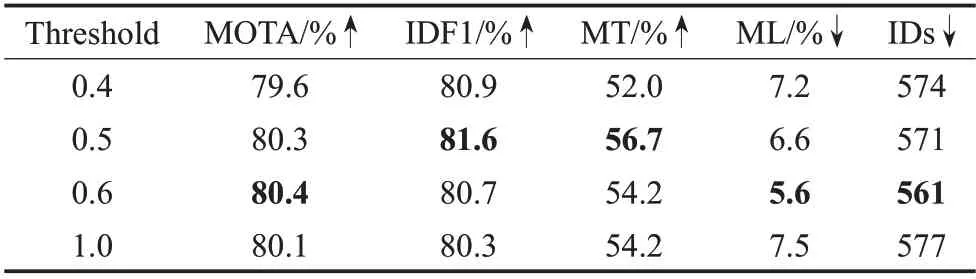
表2 Re-ID阈值对比Table 2 Comparison of Re-ID thresholds
由表1 可知,热力图响应阈值选择0.5 时有最好的跟踪效果。检测能力的提升提高了目标中心Re-ID 可学习特征的命中概率,从而有更好的跟踪效果。响应阈值减小会使整体跟踪效果下降,因为小阈值不仅会影响初期检测训练,而且增大了约束范围。这使模型将重心放在对中小响应值的约束上,缺少对高响应值的关注,没有实现高响应值向GT 位置靠拢。因此阈值选择0.4时MOTA 没有明显提升,反而识别效果受到影响,导致IDF1 下降。阈值选择0.6 时与检测相关的MOTA 有一些提升,IDF1也随之升高,但提升效果不如阈值0.5。因为增大阈值会对高响应值有更好的约束,但小目标的预测响应值较小,高阈值容易忽略对小目标的约束,使跟踪效果变差。因此热力图响应阈值选择0.5。
由表2可知,Re-ID阈值选择0.5时有最高的身份识别F1值和轨迹命中率,同时也有较高的跟踪准确度,综合跟踪效果最好。减小阈值会增大Re-ID 可学习特征扩充幅度,不仅给小目标的Re-ID特征带来周围环境噪声,降低身份识别精度,而且会影响检测特征质量,使检测效果变差。因此阈值选择0.4 时,虽然Re-ID 效果有提升,但MOTA 降低。相反,增大阈值容易忽略小目标的可学习特征扩充,ID重识别能力提升不够全面,所以阈值0.6的ID重识别效果提升不如阈值0.5。
同时,由于视频序列中经常存在目标由远及近或由近及远的尺度变换和频繁遮挡等场景,若算法ID 重识别能力不强,容易发生目标跟丢的情况,导致轨迹命中率较低。如表2 中阈值0.5 和0.6 的对比,阈值取0.6 时对大目标有更好的跟踪效果,因此预测轨迹小于20%的情况较少,轨迹丢失率ML较低。但当发生上述尺度变换或遮挡时,小目标ID无法长久保持,使预测轨迹大于80%的轨迹数变少,轨迹命中率不高。因此综合考虑,Re-ID可学习特征阈值同样选择0.5。
因主流算法测试所用数据集不同,为充分验证本文算法性能,分别在MOT16和MOT17测试集上与相应算法对比,如表3和表4所示。其中星号标记为one-shot方法,其余为two-step方法,FPS测试同时考虑检测和关联时间。表中引用数据均直接引自相应文献,所有测试结果均来自MOT Challenge官方评估网站(https://motchallenge.net/)。
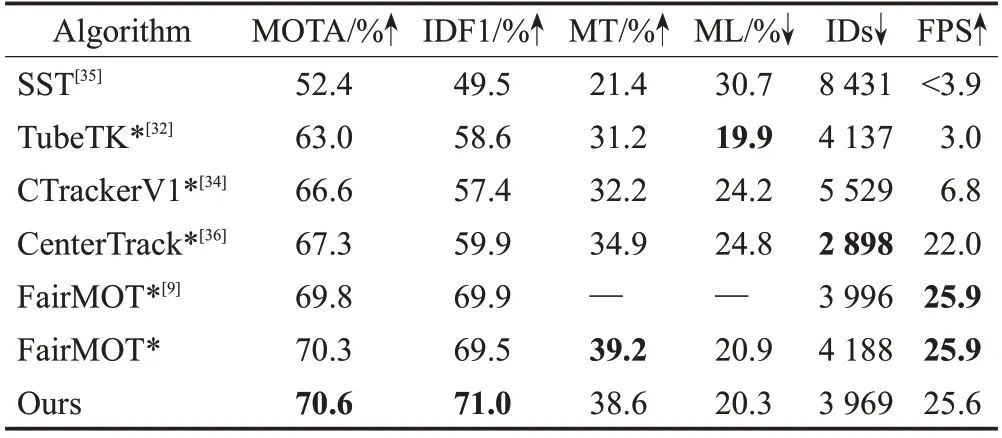
表4 不同算法在MOT17测试集上的对比Table 4 Comparison of different algorithms on MOT17 test set
可以看出,two-step方法不仅有较高的跟踪精度,且得益于Re-ID 模块的单独训练,有更少的ID 切换,但FPS 很低,达不到实时跟踪。与two-step 相比,one-shot方法的跟踪速度有明显提高,同时有领先two-step方法的跟踪效果。本文算法与不同two-step和one-shot算法对比,都有较高的跟踪精度(MOTA)和ID 识别效果(IDF1)。虽然ID 切换次数较多,但有较高的轨迹命中率MT 和更低的轨迹丢失率ML。其中CenterTrack 和FairMOT都是基于中心点检测的多目标跟踪算法,本文针对中心点检测在MOT中存在的检测偏差和Re-ID可学习特征不充足等问题进行改进后,获得了更好的跟踪效果。由于FairMOT未提供使用MOT17训练的完整测试结果,缺少MT和ML,为充分对比测试效果,在表4中增加复现结果。复现数据相比引用数据有一些浮动,但整体效果相似,结果表明本文算法依然有更好的跟踪效果。同时因提出算法仅针对训练过程进行优化,未增加在线跟踪过程的计算成本,所以有较高的跟踪速度,兼顾了实时性与准确性。
为对比不同模块对算法性能的提升,在MOT16 训练集上做相应消融实验,如表5 所示。结果表明,对热力图响应值进行约束后,MOTA和IDF1均有提升,但会增加IDs。Re-ID可学习特征扩充能有效提升模型ID识别性能,IDF1 提高1.3%,并且能少量降低ID 切换数。同时,两种方法均能提高轨迹命中率MT,并降低轨迹丢失率ML。且改进方法仅针对训练过程,未增加在线跟踪过程的计算成本,最终在不影响推理速度的情况下,本文算法MOTA提高了1.7%,IDF1提高了2.3%,MT和ML也均有改善。
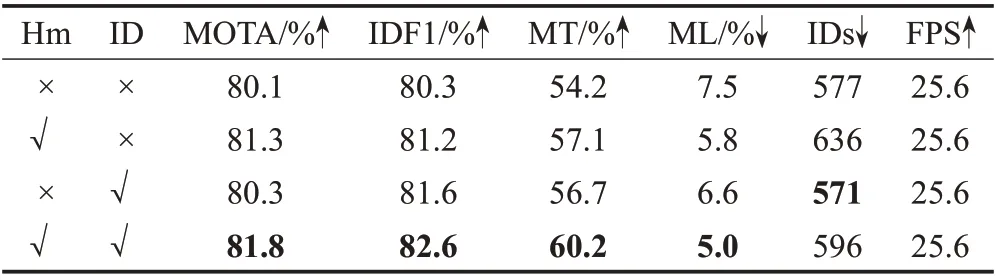
表5 消融实验Table 5 Ablation experiment
为验证算法的有效性,在MOT16 数据集上做改进前后的可视化对比分析。首先对热力图响应值约束效果进行分析,图6 为截取不同情况下的目标热力图对比,分别为GT 热力图和改进前后的预测热力图。其中三角标注为目标GT 位置,菱形标注为热力图的最高响应值位置,即预测目标位置,坐标轴标注为热力图中的坐标位置。可以看出,经过响应值约束后,图6(a)和图6(b)的预测目标位置均修正到GT位置,图6(c)的预测位置也向GT 位置逼近,说明了热力图响应值约束的有效性。
图7为改进前后的跟踪效果对比,对比目标的轨迹位于目标中心且与检测框颜色相同,其余目标轨迹位于检测框底部,图中仅保留当前目标的前20 帧轨迹。可以看出改进前,图7(a)在由近及远的尺度变化和人群遮挡后,图7(b)在经过遮挡,图7(c)在经过由远及近的尺度变化和人群遮挡后,ID均发生改变,目标轨迹无法长久保持,导致跟踪效果下降。重识别加强后,每组目标均能继续保持ID,证明提出算法有效提高了跟踪鲁棒性。
4 结束语
本文对基于中心点检测的多目标跟踪算法存在Re-ID 表观特征模糊的问题进行研究,发现Re-ID 特征图的可学习特征范围较小,在跟踪时,特征向量的选择易受检测精度的影响,使ID特征的表观信息模糊,不足以区分目标,影响ID 重识别效果。本文通过对预测热力图响应值增加平滑约束,来缓解检测中心点偏移情况,并对可学习特征做自适应扩充,提高特征质量,同时减轻Re-ID 对检测性能的依赖。实验结果和可视化分析表明,提出算法能有效解决上述问题,提高Re-ID 性能,不仅有更好地跟踪效果,且能达到实时性要求。未来的工作针对如何提高模型在昏暗和强光等复杂环境下的跟踪效果进行探索研究。
猜你喜欢
云南化工(2022年9期)2022-10-12
商界评论(2022年1期)2022-04-13
模式识别与人工智能(2022年3期)2022-04-06
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
临床骨科杂志(2020年1期)2020-12-12
智能计算机与应用(2020年4期)2020-08-31
学生天地(2020年6期)2020-08-25
现代农业科技(2020年15期)2020-08-16
数学大王·趣味逻辑(2019年10期)2019-11-06
