
改进YOLOv3算法的遥感图像道路交叉口自动识别
2022-11-15 01:57邵小美张春亢韦永昱张显云周成宇张忠豪
航天返回与遥感 2022年5期
邵小美 张春亢 韦永昱 张显云 周成宇 张忠豪
改进YOLOv3算法的遥感图像道路交叉口自动识别
邵小美1张春亢1韦永昱1张显云1周成宇2张忠豪1
(1 贵州大学矿业学院,贵阳 550025)(2 31626部队,广州 510800)
YOLOv3 道路交叉口 目标检测 空间金字塔池化 注意力机制 遥感应用
0 引言
随着遥感影像空间分辨率的不断提高,遥感影像中道路交叉口特征结构受到周围自然场景(车辆、建筑物、植被等)的影响越来越大。道路交叉口是构成道路网络的基础与核心要素,起到了连接道路和承载转向的重要作用[1]。因此,研究如何从高分辨率遥感图像中对道路交叉口进行有效、快速、智能的检测就具有非常重要意义。
近年来,国内外学者对道路交叉口的自动识别进行了大量的研究,其研究方法可分为两类:一是传统的道路交叉口识别方法,通过区域灰度、边缘、方向和几何形状等多种特征检测道路交叉口。文献[2]根据交叉口的灰度特征和几何特征,通过多角度旋转矩形模板得到角度均值图,识别出道路交叉口类型;文献[3-4]在文献[2]的方法上分别引入多尺度圆形均匀检测和三角形检测模型;文献[5]提出了一种基于模板匹配和张量投票的多阶段、多特征的道路交叉口提取方法;文献[6]采用密度峰值聚类和数学形态学处理方法提取交叉口;文献[7]利用支持向量机的方法根据交叉口路段的几何与属性特征完成交叉口的识别与化简。上述的传统识别方法多依赖于人工设计的低层次特征,未能对交叉路口的细节特征进行有效的描述,导致交叉口识别的精度不高。而且复杂的人工特征设计,增加了模型研究的成本投入。二是基于深度学习的道路交叉口识别方法,近年来基于深度学习的目标检测算法成果越来越多[8-12]。在遥感影像道路交叉口检测的过程中,通过采集大量道路交叉口样本数据,训练深度学习网络模型,实现道路交叉口识别。文献[13]利用CNN模型学习区分立交桥类型的深层次模糊性特征,实现了对复杂立交桥的识别和分类;文献[14]通过训练Faster R-CNN模型自动识别道路交叉口,但检测速度上受到了很大的限制;文献[15]提出了基于GoogLeNet神经网络的复杂交叉路口识别方法,但识别类型比较单一。由于遥感影像道路交叉口目标较小,特征不明显,而且存在较多的植被遮挡以及邻近地物颜色相近等问题,加大了道路交叉口的检测难度,导致目前已有的道路交叉口目标检测算法的精度不高且检测效率低。
目标检测模型YOLOv3在进行目标检测时具有检测速度较快且精度较高的优势,是一款非常容易操作,且对电脑配置要求相对较低的优质网络。但其在目标检测时存在对小目标检测效果不佳和漏检率较高以及难以区分重叠物体等不足。因此,本文在YOLOv3网络的基础上提出一种改进的道路交叉口目标检测算法,提高了道路交叉口检测精确度和检测效率。
1 传统YOLOv3算法
YOLOv3(You Only Look Once version 3)[16]是由Joseph Redmon和Ali Farhadi在2018年提出的YOLOv2升级版。通过采用K-Means聚类算法[17-18],根据目标尺寸聚类出9种不同尺寸的先验框进行 目标检测。YOLOv3网络主要分为主干特征提取、加强特征提取和结果预测三个部分,其网络结构如 图1所示。
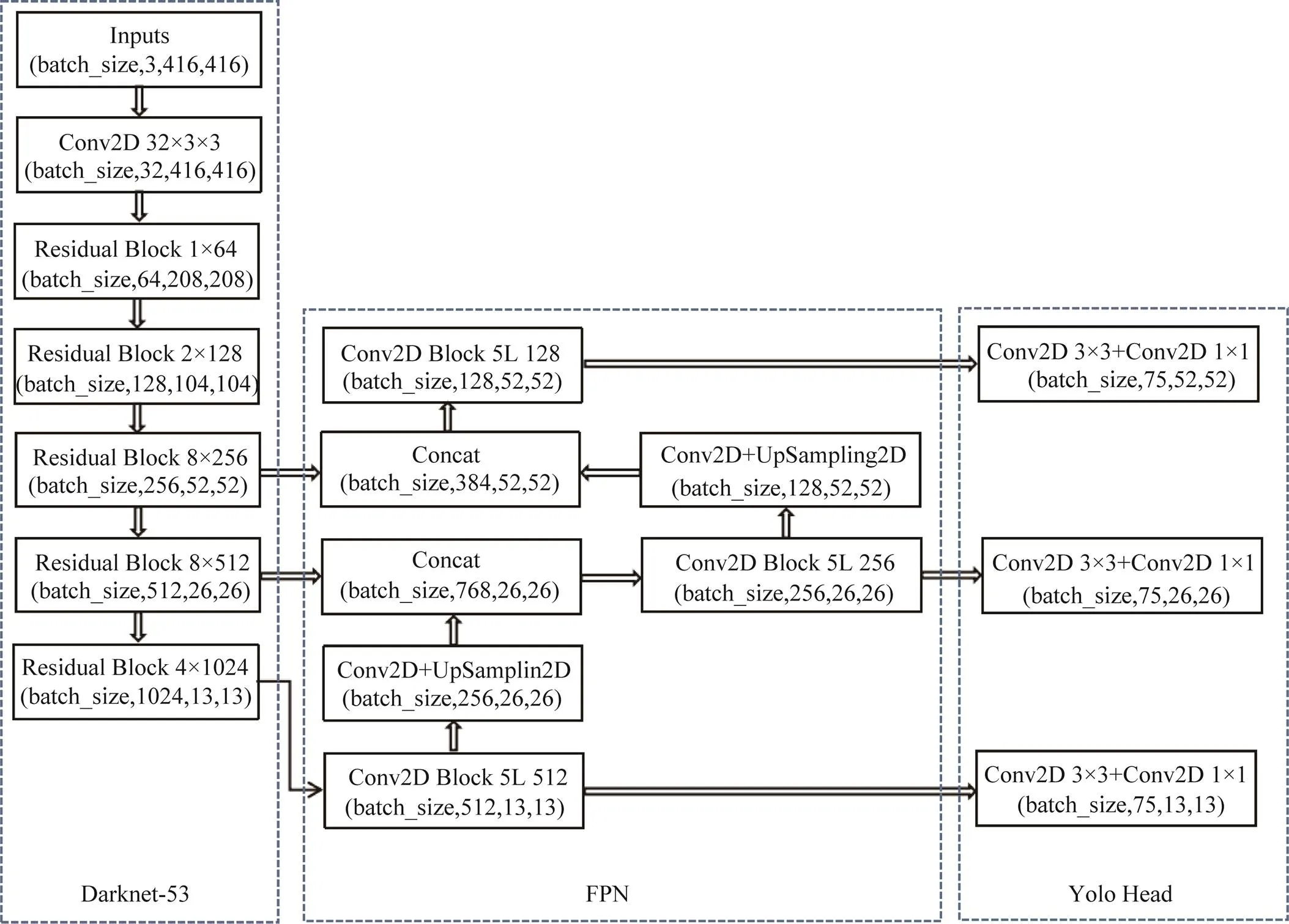
图1 YOLOv3网络结构
注:(batch_size, 3, 416, 416)中3表示通道数,416和416分别表示图片的宽和高;Residual Block 1×64表示残差块堆叠1次,通道数是64;Conv2D Block5L表示5次卷积操作;Conv2D+UpSampling2D表示卷积和上采样;Concat是指将两个特征层进行堆叠;Conv2D 3×3+Conv2D 1×1表示通过一次3×3的卷积和一次1×1的卷积进行分类预测和回归预测。
YOLOv3的主干特征提取网络是将YOLOv2的DarkNet-19替换成性能更优的Darknet-53,通过不断的1×1卷积和3×3卷积以及残差边的叠加,并在卷积层后添加批量归一化层(Batch Normalization)抑制网络出现过拟合现象,大幅度的加深了网络。通过融合残差网络(ResNet)[19]等方法,使得YOLOv3在保持速度优势的前提下,提升了检测精度。YOLOv3网络通过使用特征金字塔(Feature Pyramid Network,FPN)[20]进行加强特征提取网络的构建,利用特征金字塔将小尺度特征图进行上采样,然后与大尺度特征图进行融合,提取出三个不同尺度的特征图,并将其传入Yolo Head网络中获得预测结果。
2 CSC-YOLOv3算法
2.1 损失函数的改进
YOLOv3的损失函数由目标定位损失、目标置信度损失及目标分类损失3部分组成。定位损失包括目标预测区域中心点坐标值损失和宽高值损失,采用均方误差(MSE)作为损失函数的目标函数。分类损失和置信度损失采用二值交叉熵损失(Binary Cross Entropy)函数[21]。总的损失函数Loss公式定义如下:
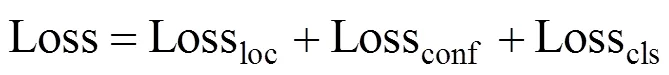
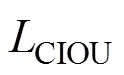
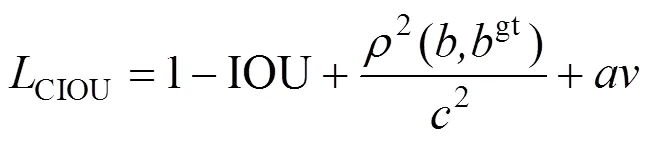
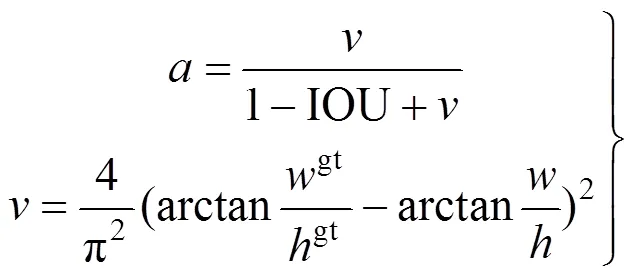
2.2 空间金字塔池化
2015年何恺明提出的空间金字塔池化(Spatial Pyramid Pooling,SPP)[24],又称之为“SPPNet”,主要解决网络输入图像尺寸不统一的问题。通过使用固定分块的池化操作,SPP模块可以在具有全连接层的网络中实现多尺度图像的输入,能够避免因尺度问题导致的图像失真问题。此外,SPP中不同大小特征的融合,有利于检测大小差异较大的目标。但由于采用空间金字塔池化会增加一定的模型复杂度,所以会影响模型运行速度。由于YOLOv3算法存在对图像重复特征提取和对多尺度目标检测性能较差等问题,本文在YOLOv3网络中借鉴了SPPNet的思想,将SPP结构引入到YOLOv3的Darknet-53和FPN结构之间,在对Darknet-53的最后一个特征层进行卷积后,利用4个池化核大小分别为13´13、9´9、5´5、1´1(表示无处理)的最大池化进行处理,使网络能够提取具有不同感受野的多尺度深层特征,大大增加网络的有效感受野,极大程度提升了本文多尺度道路交叉口目标检测的识别精度。SPP结构如图2所示。
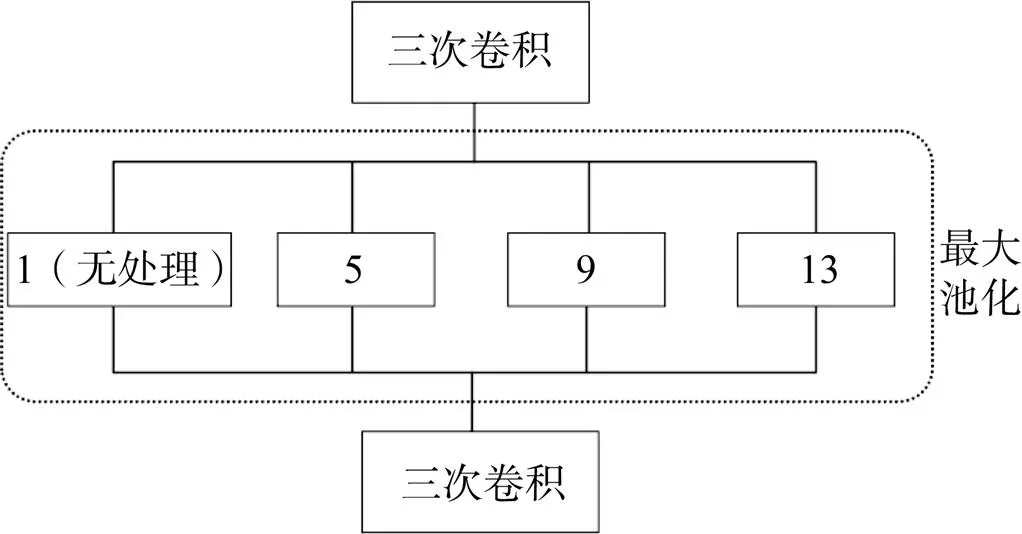
图2 SPP结构图
2.3 注意力机制模块
近年来,注意力模型(Attention Model)被广泛应用于各种深度学习任务中。在目标检测领域中,通过在网络中引入注意力机制,网络能更快速定位图像中重要特征信息的位置。注意力机制根据作用域的不同可进行二次分类,包括空间注意力机制(Spatial Attention Mechanism,SAM)、通道注意力机制(Channel Attention Mechanism,CAM)以及混合注意力机制。其中CBAM(Convolutional Block Attention Module)[25]表示卷积模块的注意力机制模块,是一种结合了SAM和CAM的混合注意力机制模块,相比于SE(Squeeze and Excitation)模块只关注CAM可以取得更好的效果。其网络结构图如图3所示:

图3 CBAM网络结构图
从图3可以看出,CBAM是依次通过CAM和SAM。通过CBAM模块能加强目标关键特征的注意力,抑制非关键特征的注意力,即使网络更多关注到目标,抑制网络对背景的关注,进而提升目标检测的精度。其中CAM模块是通过全局最大池化和全局平均池化对特征进行降维,而SAM模块则是经过全局最大池化和全局平均池化堆叠后得到两个不同的特征图,再通过卷积层对其进行连接,最后利用sigmoid函数将连接的特征向量映射到[0,1],进而得到空间注意力结果。
本文通过在YOLOv3模型的三个特征层结构以及两个上采样结构中引入CBAM模块,使网络学会关注重点信息,特征信息可以覆盖到道路交叉口的更多部位,进一步提升YOLOv3模型对特征不明显的道路交叉口的识别精度。特别是在被植被遮挡的道路交叉口和与背景相似的城市道路交叉口中能获得更准确的目标特征,减少背景其他物体特征对网络的影响,进而提升道路交叉口的检测精度。
3 实验与结果分析
3.1 数据集制作
由于目前还没有公开的遥感影像道路交叉口的数据集,本文使用贵阳市的“高分二号”卫星影像和马萨诸塞州道路数据集中的部分图像自制数据集。通过分析影像上道路交叉口的特征,使用LabelImg工具以人工方式对目标逐一进行标注,图像标注的基本目标是根据图像的视觉内容和获得的指导信息来确定对应的文本语义描述[26]。因本文检测目标为道路交叉口,所以本数据集目标标注只将遥感图像中出现的道路交叉口目标尽可能的标注出来,其他类别不做标注。
自制的道路交叉口数据包含1 137张图像,其中包含了十字、丁字、X形、Y形等多种常见的道路交叉口类型。将数据以8:1:1的比例划分为训练集、验证集和测试集用于本文的研究。该数据集中分布的小尺寸道路交叉口目标较多,这就导致目标信息量小,难以检测,并且场景中目标受到不同程度的遮挡,加大了检测的难度。
3.2 网络训练
实验所用的编程语言为Python,深度学习框架为Pytorch,采用Adam优化器。在整个训练过程采用迁移学习的方式进行冻结训练,主要是可以加快训练速度,也可以在训练初期防止权值被破坏。为了能使网络更快的收敛且防止模型训练过拟合,训练过程中采用Label Smoothing将标签进行平滑,初始学习率设置为0.001,每次传入网络的图片数量(Batch Size)为4,并使用原始YOLOv3的初始训练权重进行训练。当迭代到50次时进行解冻训练,将学习率衰减为0.0001,Batch Size改为2。随着迭代的进行使损失逐渐收敛,从而得到模型训练的网络权重。经过多次实验显示CSC-YOLOv3网络在迭代到90次左右趋于稳定,所以本实验将总的训练迭代次数设置成100。训练过程的损失函数曲线如图4所示。

图4 CSC-YOLOv3网络训练损失曲线
3.3 检测结果及分析
(1)定性分析
为了能直观的验证本文提出的改进算法的性能,对原始YOLOv3算法和改进的CSC-YOLOv3算法使用相同的实验硬件配置和实验参数进行训练,对检测结果进行对比分析。分别在存在植被遮挡、邻近地物颜色相近和小目标场景下的检测结果如图5~7所示。图中黄色检测框表示改进前后的变化情况。

图5 植被遮挡场景下道路交叉口检测结果
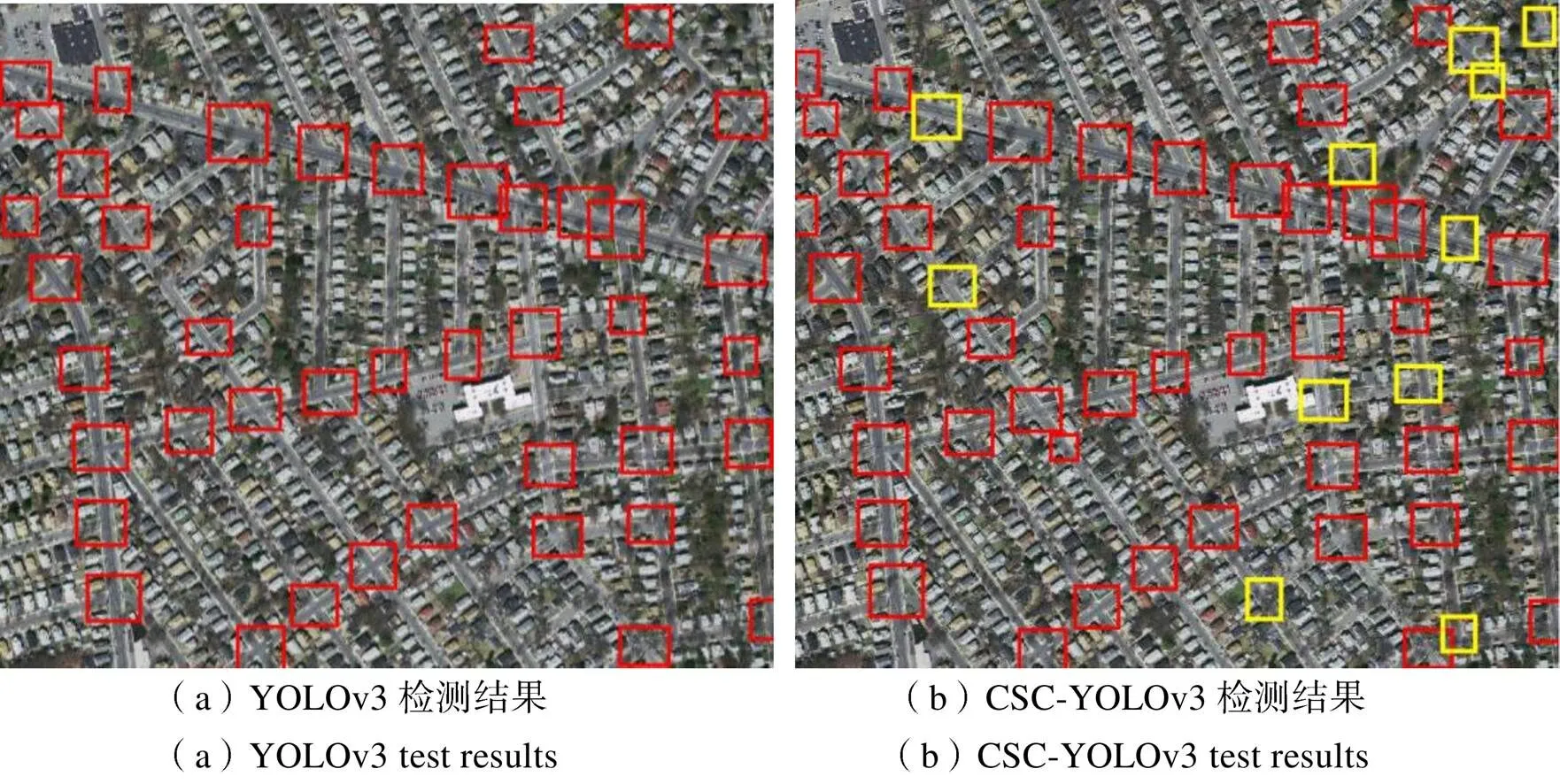
图6 邻近地物颜色相近场景下道路交叉口检测结果

图7 小目标场景下道路交叉口检测结果
从图5可以看出,由于道路交叉口被植被遮挡严重,在原始的YOLOv3网络检测中,部分道路交叉口因特征不明显,未能被检测出来;而CSC-YOLOv3网络中由于引入了注意力机制,对于遮挡严重的道路交叉口目标,能根据道路交叉口的部分特征进行识别,这使道路交叉口的检测更加细致。对于图6中的城市道路,道路和周围的房屋背景较为相似且道路网复杂交错,导致交叉口的检测难度加大。在这样的情况下,原始YOLOv3网络模型虽然能准确的检测出大部分的道路交叉口,但出现较多的漏提目标,相比之下,CSC-YOLOv3网络检测出的道路交叉口更完整。而图7中除两条主干道以外,存在较多的小尺寸交叉路口,从图中可以看出,两个模型均能检测识别出大尺寸道路交叉口目标,但针对部分小尺寸道路交叉口目标,CSC-YOLOv3网络的检测效果更优,在原始YOLOv3网络的基础上,降低了小目标漏检率。
从以上三种不同场景下的道路交叉口检测对比实验可以看出,改进后的CSC-YOLOv3网络在自制的道路交叉口数据集上表现出了较好的检测效果。相较于原始YOLOv3网络,其检测性能得到了大幅提升,对于植被遮挡场景、邻近地物颜色相近场景和小目标较多的场景,均能精确地检测出道路交叉口目标。
(2)定量分析
为了进一步验证本文提出的改进算法的性能,本文通过、、1、AP和FPS对改进的CSC-YOLOv3算法和原始YOLOv3算法进行评价。实验对比结果如表1所示。
表1 道路交叉口检测结果对比

Tab.1 Comparison of test results of road intersections
从表1可以看出,相比于原始YOLOv3算法,本文改进的CSC-YOLOv3算法对道路交叉口的检测精度提升较为显著,、、1、AP和1值分别提高了6.54、8.55、11.74和8个百分点,虽然FPS降低了3帧/秒,但是其检测性能的提升弥补了速度上的不足,证明了改进CSC-YOLOv3算法的有效性,提升了高分遥感影像道路交叉口的检测效果。
(3)消融实验结果对比分析
本文在现有YOLOv3模型的基础上,通过使用CIOU损失函数并引入SPP和CBAM模块,设计了一种新的遥感图像道路交叉口识别方法。为了明确各个模块对网络性能的影响,本文采用消融实验进行对比分析。一共设置了四组实验,如表2所示,其中“√”表示包含对应的模块,“×”表示不包含对应的模块。
表2 消融实验结果比较

Tab.2 Comparison of ablation results
从表2中可以看出,相比于原始YOLOv3算法,引入不同的模块改进的YOLOv3算法在道路交叉口数据集上的、、AP以及1值上均有所提升。S-YOLOv3网络因为引入了SPP模块增加了一定的模型复杂度,导致模型的计算量稍有增加,FPS下降1帧/秒,但、、AP以及1值均提升较多,分别提高了5.58、7.26、9.37和7个百分点。而CS-YOLOv3网络通过在S-YOLOv3网络中使用CIOU损失函数进行改进,、、AP、1以及FPS值在S-YOLOv3网络的基础上分别提高了0.45、0.87、0.56、1个百分点和1帧/秒,表明CIOU损失函数能在加快网络模型的训练速度的同时提升道路交叉口检测精度。CSC-YOLOv3模型是综合SPP模块和CIOU损失函数的特点,继续将CBAM模块引入到YOLOv3网络中。相比于CS-YOLOv3模型来说,CSC-YOLOv3网络的、、和1值进一步提升,但FPS值降低了3帧/秒,表明引入CBAM模块能使网络学会关注交叉口的重点信息,提高目标识别精确,但由于CBAM模块的增加使网络运行速度受到了一定的影响。
为了更准确地描述各个模块的性能,对原始YOLOv3、S-YOLOv3、CS-YOLOv3和CSC-YOLOv3四个模型的检测结果进行分析,局部检测结果如图8~9所示。
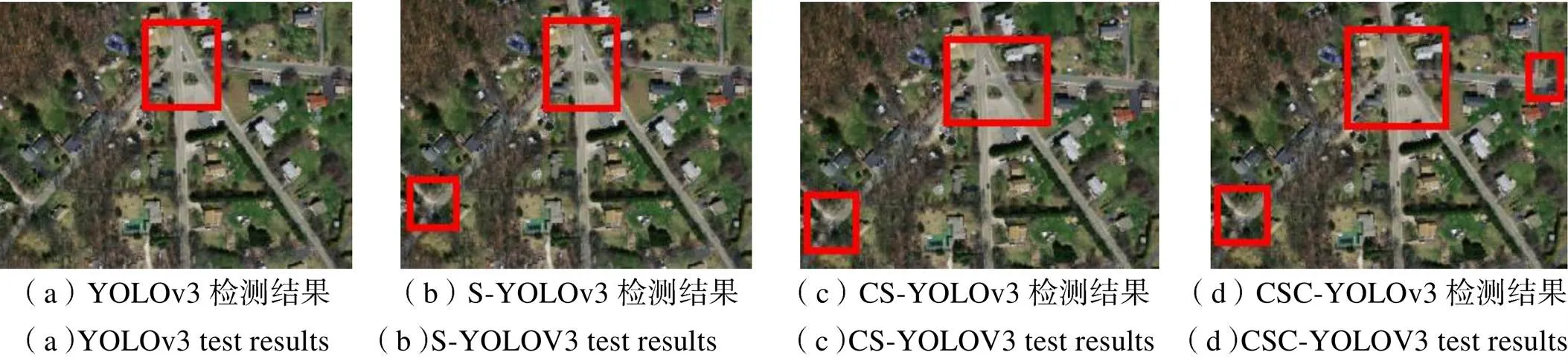
图8 郊区道路交叉口检测结果

图9 城市道路交叉口检测结果
从以上两种不同场景下的道路交叉口检测对比实验可以看出,引入不同模块改进的YOLOv3算法的检测效果具有一定差异。从图8的郊区道路交叉口检测结果可以看出:引入SPP模块可以优化多尺度目标的检测效果,提升小目标检测精度。使用CIOU损失函数后对检测结果影响不大,但目视来看,目标检测框更加准确。而引入CBAM模块则主要可以有效检测被植被遮挡的道路交叉口。从图9的城市道路交叉口检测结果可以看出:引入SPP模块后城市道路交叉口的检测精度得到了一定的提升,特别是对小目标检测效果的提升较为明显,但部分相聚较近、被植被遮挡以及与背景相似的目标存在漏检情况。在此基础上,使用CIOU损失函数,更好地反应预测框的定位精度,有效地识别出了相聚较近的目标。而引入CBAM模块则更准确地对被植被遮挡以及与背景相似的道路交叉口进行识别,有效提升了模型检测精度。
综上所述,SPP模块通过增加网络的有效感受野提升模型检测精度,有利于检测大小差异较大的目标;CIOU损失函数主要是提升运行速度和预测框的回归准确度,对相聚较近的目标有较好的效果;而CBAM模块主要用于识别特征不明显的目标,包括植被遮挡目标和与背景相似目标等。通过消融实验可知,本文改进的CSC-YOLOv3模型是综合了三个模块的特点,提升了模型的整体性能。
4 结束语
本文针对道路交叉口目标较小、存在较多的植被遮挡、邻近地物颜色相近等问题,提出了一种改进的CSC-YOLOv3网络模型。CSC-YOLOv3算法是将SPP模块和CBAM模块引入到YOLOv3模型中,并使用CIOU损失函数改进原来YOLOv3的目标定位损失函数,从而降低目标漏检率,提升目标检测精度。改进的CSC-YOLOv3算法对道路交叉口的检测效果相较于原始YOLOv3网络取得了较大的提升,对于道路交叉口遮挡严重的场景、背景复杂的城市场景以及小目标较多的郊区场景,均能精确地检测出道路交叉口目标。
[1] 李雅丽, 向隆刚, 张彩丽, 等. 车辆轨迹与遥感影像多层次融合的道路交叉口识别[J]. 测绘学报, 2021, 50(11): 1546-1557.
LI Yali, XIANG Longgang, ZHANG Caili, et al. Road Intersection Recognition Based on Multi-level Fusion of Vehicle Trajectory and Remote Sensing Image[J]. Acta Geodaeticaet Cartographica Sinica, 2021, 50(11): 1546-1557. (in Chinese)
[2] 程江华, 高贵, 库锡树, 等. 高分辨率SAR图像道路交叉口检测与识别新方法[J]. 雷达学报, 2012, 1(1): 100-108.
CHENG Jianghua, GAO Gui, KU Xishu, et al. A Novel Method for Detecting and Identifying Road Junctions from High Resolution SAR Images[J]. Journal of Radars, 2012, 1(1): 100-108. (in Chinese)
[3] 蔡红玥, 姚国清. 高分辨率遥感图像道路交叉口自动提取[J]. 国土资源遥感, 2016, 28(1): 63-71.
CAI Hongyue, YAO Guoqing. Auto-extraction of Road Intersection from High Resolution Remote Sensing Image[J]. Remote Sensing for Land & Resources, 2016, 28(1): 63-71.(in Chinese)
[4] 郭风成, 李参海, 李宗春, 等. 高分辨率SAR影像道路交叉口自动提取方法[J]. 测绘科学技术学报, 2017, 34(2): 199-203.
GUO Fengcheng, LI Canhai, LI Zongchun, et al. A New Method for Automatic Extracting Road Junctions from High Resolution SAR Images[J]. Journal of Geomatics Science and Technology, 2017, 34(2): 199-203. (in Chinese)
[5] SUN Ke, ZHANG Junping, ZHANG Yingying, et al. Roads and Intersections Extraction from High-Resolution Remote Sensing Imagery Based on Tensor Voting under Big Data Environment[J]. Wireless Communications and Mobile Computing, 2019, 2019: 1-11.
[6] 李思宇, 向隆刚, 张彩丽, 等. 基于低频出租车轨迹的城市路网交叉口提取研究[J]. 地球信息科学学报, 2019, 21(12): 1845-1854.
LI Siyu, XIANG Longgang, ZHANG Caili, et al. Extraction of Urban Road Network Intersections Based on Low-Frequency Taxi Trajectory Data[J]. Journal of Geo-Information Science, 2019, 21(12): 1845-1854. (in Chinese)
[7] 马超, 孙群, 陈换新, 等. 利用路段分类识别复杂道路交叉口[J]. 武汉大学学报(信息科学版), 2016, 41(9): 1232-1237.
MA Chao, SUN Qun, CHEN Huanxin, et al. Recognition of Road Junctions Based on Road Classification Method[J]. Geomatics and Information Science of Wuhan University, 2016, 41(9): 1232-1237. (in Chinese)
[8] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 779-788.
[9] 吴永静, 吴锦超, 林超, 等. 基于深度学习的高分辨率遥感影像光伏用地提取[J]. 测绘通报, 2021(5): 96-101.
WU Yongjing, WU Jinchao, LIN Chao,et al. Photovoltaic Land Extraction from High-resolution Remote Sensing Images Based on Deep Learning Method[J]. Bulletin of Surveying and Mapping, 2021(5): 96-101. (in Chinese)
[10] 方明, 孙晓敏, 黄然, 等. 面向高分辨率卫星遥感的电力杆塔自动检测[J]. 航天返回与遥感, 2021, 42(5): 118-126.
FANG Ming, SUN Xiaomin, HUANG Ran, et al. Research on Automatic Detection Algorithm of Power Tower Using High Resolution Remote Sensing Satellite Image[J]. Space Recovery & Remote Sensing, 2021,42(5):118-126. (in Chinese)
[11] 刘颖, 刘红燕, 范九伦, 等. 基于深度学习的小目标检测研究与应用综述[J]. 电子学报, 2020, 48(3): 590-601.
LIU Ying, LIU Hongyan, FAN Jiulun, et al. A Survey of Research and Application of Small Object Detection Based on Deep Learning[J]. Acta Electronica Sinica, 2020, 48(3): 590-601. (in Chinese)
[12] 余培东, 王鑫, 江刚武, 等. 一种改进YOLOv4的遥感影像典型目标检测算法[J]. 测绘科学技术学报, 2021, 38(3): 280-286.
YU Peidong, WANG Xin, JIANG Gangwu, et al. A Typical Target Detection Algorithm in Remote Sensing Images Based on Improved YOLOv4[J]. Journal of Geomatics Science and Technology, 2021, 38(3): 280-286. (in Chinese)
[13] 何海威, 钱海忠, 谢丽敏, 等. 立交桥识别的CNN卷积神经网络法[J]. 测绘学报, 2018, 47(3): 385-395.
HE Haiwei, QIAN Haizhong, XIE Limin, et al. Interchange Recognition Method Based on CNN[J].Acta Geodaetica et Cartographica Sinica, 2018, 47(3): 385-395. (in Chinese)
[14] 周伟伟. 基于道路交叉口的高分辨率遥感影像道路提取[D]. 武汉: 武汉大学, 2018.
ZHOU Weiwei. Road Extraction from High Resolution Remote Sensing Image Based on Road Intersections[D]. Wuhan: Wuhan University, 2018. (in Chinese)
[15] 张鸿刚, 李成名, 武鹏达, 等. GoogLeNet神经网络的复杂交叉路口识别方法[J]. 测绘科学, 2020, 45(10): 190-197.
ZHANG Honggang, LI Chengming, WU Pengda, et al. A Complex Intersection Recognition Method Based on GoogLeNet Neural Network[J]. Science of Surveying and Mapping, 2020, 45(10): 190-197. (in Chinese)
[16] REDMON J, FARHADI A. Yolov3: An Incremental Improvement[EB/OL]. [2021-12-20]. https://www.xueshufan.com/ publication/2796347433.
[17] 张素洁, 赵怀德. 最优聚类个数和初始聚类中心点选取算法研究[J]. 计算机应用研究, 2017, 34(6): 1617-1620.
ZHANG Sujie, ZHAO Huaide. Algorithm Research of Optimal Cluster Number and Initial Cluster Center[J]. Application Research of Computers, 2017, 34(6): 1617-1620. (in Chinese)
[18] 孔方方, 宋蓓蓓. 改进YOLOv3的全景交通监控目标检测[J]. 计算机工程与应用, 2020, 56(8): 20-25.
KONG Fangfang, SONG Beibei. Improved YOLOv3 Panoramic Traffic Monitoring Target Detection[J]. Computer Engineering and Applications, 2020, 56(8): 20-25. (in Chinese)
[19] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 770-778.
[20] LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 2117-2125.
[21] 张彬彬, 帕孜来·马合木提. 基于YOLOv3改进的火焰目标检测算法[J/OL]. (2021-03-12)[2022-02-22]. http://kns. cnki.net/kcms/detail/31.1690.TN.20210311.1628.047.html.
ZHANG Binbin, PAZILAI Mahemuti. Improved Flame Target Detection Algorithm Based on YOLOv3[J/OL]. (2021-03-12)[2022-02-22]. http://kns.cnki.net/kcms/detail/31.1690.TN.20210311.1628.047.html. (in Chinese)
[22] ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression[EB/OL]. [2022-02-22]. https://arxiv.org/pdf/1911.08287.pdf.
[23] 秦鹏, 唐川明, 刘云峰, 等. 基于改进YOLOv3的红外的目标检测方法[J]. 计算机工程, 2022, 48(3): 211-219.
QIN Peng, TANG Chuanming, LIU Yunfeng, et al. Infrared Target Detection Method Based on Improved YOLOv3[J]. Computer Engineering, 2022, 48(3): 211-219. (in Chinese)
[24] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[25] WOO S, PARK J, LEE J Y, et al. CBAM: Convoluational Block Attention Module[EB/OL]. [2022-02-22]. https://arxiv. org/pdf/1807.06521.pdf.
[26] 卢汉清, 刘静. 基于图学习的自动图像标注[J]. 计算机学报, 2008, 31(9): 1629-1639.
LU Hanqing, LIU Jing. Image Annotation Based on Graph Learning[J]. Chinese Journal of Computers, 2008, 31(9): 1629-1639. (in Chinese)
Improved YOLOv3 Algorithm for Remote Sensing Image Road Automatic Intersection Identification
SHAO Xiaomei1ZHANG Chunkang1WEI Yongyu1ZHANG Xianyun1ZHOU Chengyu2ZHANG Zhonghao1
(1 School of Mining, Guizhou University, Guiyang 550025, China)(2 Troops 31626, Guangzhou 510800, China)
Aiming at the problems of small intersection target, more vegetation occlusion and similar color of adjacent ground objects, an improved YOLOv3 high-resolution image intersection target detection algorithm, CSC-YOLOv3, was proposed. Firstly, CIOU loss function is used to improve the target locating loss of YOLOv3 and reduce the target missing rate. Secondly, the effective receptive field of YOLOv3 network was increased by adding spatial pyramid pooling module after the main feature extraction network of YOLOv3. Finally, the attention mechanism module was introduced into three feature layer structures and two upsampling structures of YOLOv3 network to improve the detection accuracy of the network. The results show that the accuracy rate, recall rate, average accuracy rate and F1 score of CSC-YOLOv3 algorithm reached 86.05%, 70.19%, 83.71% and 77% respectively. Compared with the original YOLOv3 algorithm, the improvement is 6.54, 8.55, 11.74 and 8 percentage points respectively. Although the FPS is reduced by 3 frames per second, the improvement of its detection performance makes up for the lack of speed and effectively improves the detection effect of high-resolution remote sensing images on road intersections.
YOLOv3; road intersections; target detection; space pyramid pooling; attentional mechanism; remote sensing application
P237
A
1009-8518(2022)05-0123-10
10.3969/j.issn.1009-8518.2022.05.012
2022-04-20
国家自然科学基金(41701464);贵州大学培育项目(贵大培育[2019]26号);贵州省省级科技计划项目(黔科合支撑[2022]一般204)
邵小美, 张春亢, 韦永昱, 等. 改进YOLOv3算法的遥感图像道路交叉口自动识别[J]. 航天返回与遥感, 2022, 43(5): 123-132.
SHAO Xiaomei, ZHANG Chunkang, WEI Yongyu, et al. Improved YOLOv3 Algorithm for Remote Sensing Image Road Automatic Intersection Identification[J]. Spacecraft Recovery & Remote Sensing, 2022, 43(5): 123-132. (in Chinese)
邵小美,女,1994生,2017年获贵州大学测绘工程学士学位,现在贵州大学测绘科学与技术专业攻读硕士学位。主要研究方向为高分遥感影像信息提取。E-mail:1598091011@qq.com。
(编辑:毛建杰)
猜你喜欢
当代陕西(2022年4期)2022-04-19
小猕猴学习画刊(2022年3期)2022-03-28
数学小灵通·3-4年级(2021年5期)2021-07-16
青年歌声(2020年12期)2020-12-23
今日农业(2019年15期)2019-01-03
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
工程建设与设计(2016年8期)2016-03-11
中国房地产业(2016年2期)2016-03-01
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读写算·高年级(2015年1期)2015-07-25
