
基于改进FCOS网络的遥感目标检测
2022-11-15 00:23郑美俊田益民杨帅
航天返回与遥感 2022年5期
郑美俊 田益民 杨帅
基于改进FCOS网络的遥感目标检测
郑美俊 田益民*杨帅
(北京印刷学院信息工程学院,北京 102627)
找出目标的位置和类别是目标检测的主要任务。随着人工智能和深度学习的发展,目标检测可以达到人眼所达不到的精度。由于信息较少,覆盖面积小且基于锚框的检测算法易受锚框大小、比例数目的影响,对较小的目标难以精确检测。针对以上问题,改进无锚框算法全卷积单阶段目标检测(Fully Convolutional One-stage Object Detection,FCOS)实现了小目标检测的效率和精度。将FCOS算法的特征提取网络结构残差网络(Residual Network,ResNet)更换为轻量级网络结构MobileNetV3,随后在骨干网络中引入通道注意力机制和空间注意力机制对特征提取网络进行改进,最后设计T交并比(TIOU)代替原本的交并比(IOU),改善模型精度。实验结果表明,所改进的网络结构与FCOS相比,网络训练时间和模型大小为原来的一半,计算参数量由原来的32.12×106减少为11.73×106,减少到原来的三分之一,模型推理速度提升了10%,每秒传输帧数为11帧,与主流网络Faster RCNN相比,检测精度和速度更快,可以满足对小目标的实时检测。
卷积神经网络 单阶段目标检测 通道和空间注意力机制 遥感应用
0 引言
随着各行各业在计算机视觉领域取得一系列突破,在深度学习领域中占据重要地位的目标检测也得到了突破性的进展。在目前热门的自动驾驶研究中,需要从每一帧的图片中精确识别出障碍物并送入后台进行处理。在航天遥感中,需要识别出5m以下的小目标[1]。
传统的目标检测方法分为三大部分:区域选择、特征提取和分类器。由于传统的目标检测方法在时间利用率、人为设计的网络鲁棒性等方面差的原因,使得识别和检测的效果不佳。近年来,人工智能的迅速发展使得目标检测成为人工智能落地研究的重要内容,目标检测与神经网络相结合取得了巨大的成果,例如:基于锚框的检测器Faster R-CNN[2]采用预训练权重初始化区域选取网络(Region Proposal Network,RPN)的共享卷积层,然后训练RPN网络,通过生成建议框和双阶段预测取得了较高的检测精度,单发多箱预测器(Single Shot multiBox Detector,SSD)[3]对于一张图,结合多个不同的特征图预测不同大小的物体,提高了运行速度和检测的精度;You Look Only Once(YOLO)v3[4]相比于YOLOv2[5]采用了特征金字塔(Pyramid Of Features,FPN)[6]、ResNet模块和DarkNet53网络结构,提高了网络的空间和数据表征能力,增加对细粒度物体的检测力度。
针对锚框目标检测算法的缺陷,很多无锚框的算法被提出,文献[7]提出CenterNet(Keypoint Triplets for Object Detection),将边界的中心点进行建模,为了找到中心点,通过边界框左上和右下的角点坐标来找到中心点,进而回归出目标框的边界大小,且不需要进行非极大抑制(Non Maximal Inhibition,NMS)。Zhi Tian等提出的FCOS采用FPN进行分层预测,提升了对不同尺度目标的预测精度,FCOS在避免锚框复杂计算的方式上采取了去除预定义的锚框[8],且后处理只采用NMS使得FCOS更加简单[9]。
本文针对目前目标检测算法面临的检测效率慢和模型文件太大两个问题,设计出了FCOS改进版。其中,采用轻量级MobileNetV3[10]作为FCOS的骨干网络,使得网络整体参数量和最后得到的模型文件大幅度缩小。由于模型文件大幅度缩小,所以计算量也变得更小,推理变得更快,不仅拥有不差于较重模型的性能,还可以应用于更加轻量级的边缘设备,解决了深度学习的模型推理对设备配置要求高的问题。在改进骨干网络中引入注意力机制[11],改进IOU损失函数,提升了特征网络的提取性能,使得改进后的算法在模型大小大幅度缩小的前提下还能保持模型精度不变。基于以上两种方法的改进,使得本文算法能更快的检测出对应目标,且模型训练的空间和时间缩短为原先的一半,模型的推理速度提升10%,可以达到实时检测的效果[12],对于深度学习在计算机视觉领域的落地有一定的参考价值。
1 轻量级单阶段目标检测算法
1.1 轻量级单阶段目标检测算法网络模型
如图1所示,轻量级单阶段目标检测(MobileNetv3-CBAM-FCOS,MVBCA-FCOS)的网络结构,主要包括特征提取网络、特征融合网络和检测模块三个部分。

图1 MVBCA-FCOS网络结构图
该网络改进了特征提取网络和检测模块[13],对于特征提取网络,采用融合通道和空间注意力机制(Convolutional Block Attention Module,CBAM)的轻量级网络(MobileNetV3)作为骨干网络,用于提取图片中的深层语义信息。其中CBAM引导网络关注特征图中重要的区域,抑制无效特征,从而提升特征图的表征能力。骨干网络产生的3个特征图3、4、5,通过1×1的卷积(Convolution,Conv)得到256维的特征向量3、4、5,传入特征融合网络中进行特征融合。其中,6、7通过特征图5、6用步长为2的3×3卷积得到,5经过上采样与4相加的到4,4经过上采样与3相加得到3。特征图3、4、5、6、7的步长(步长表示与初始输入的特征图缩小的倍数)分别为8、16、32、64、128。将3、4、5、6、7送入网络头部(Head)进行预测,得出目标回归得分、目标分类得分和边框中心点得分。最后利用NMS算法进行后处理得到检测结果。
1.2 融合通道和空间注意力机制
常用的挤压激励(Squeexe and Excitation,SE[14])模块是为了解决在卷积池化中通道重要性不同的问题。但是SE模块忽略了空间性能对网络的影响。CBAM注意力机制分为通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spartial Attention Module,SAM)。
与SE模块相比,CAM模块多了个最大池化层,所以获得的信息更加全面。将CAM模块输出的特征图输入到SAM模块中,经过一系列的黑盒操作得到最终的权重系数。CAM和SAM分别对骨干网络中的通道特征和空间特征进行选择性提取,可以提高模型训练的精度。
通道注意力机制如图2所示,主要关注在特征图中什么样的特征是有意义的,它的输入是一个××的特征(×代表像素大小,表示通道数)。首先分别进行一个平均池化和最大池化,接着,再将得到的结果分别送入共享神经网络,经过一系列变化得到通道权重系数c。
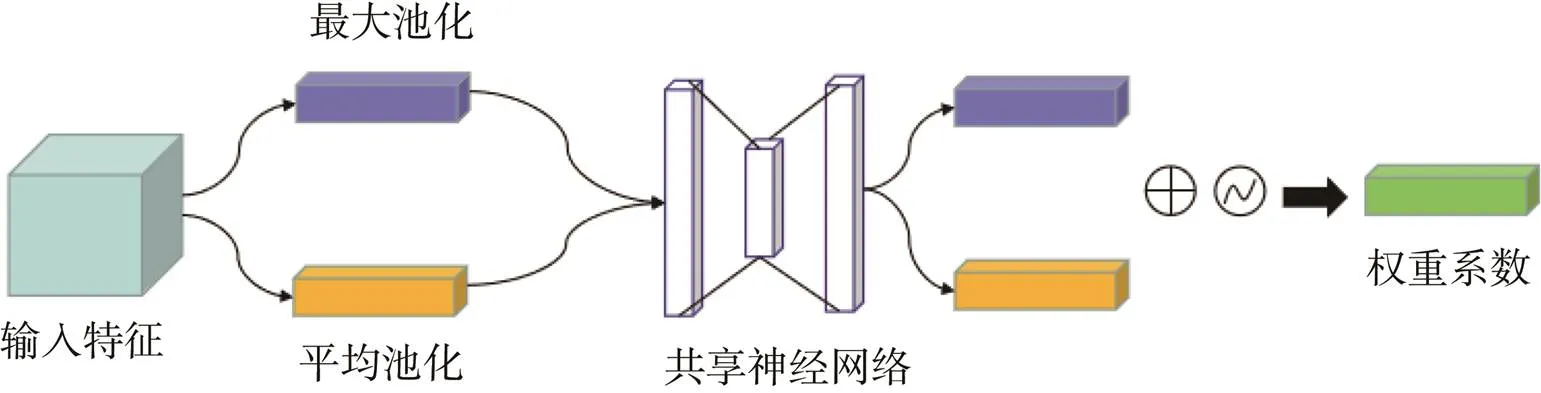
图2 通道注意力模块
空间注意力机制如图3所示,主要负责关注在特征图中哪些位置上的特征是有意义的,它的输入××的特征,先后进入最大池化层和平均池化层。然后,经过一个7×7的卷积,通过Sigmoid激活函数,得到激活权重系数s。

图3 空间注意力模块
1.3 融合通道和空间注意力机制的特征提取网络
FCOS中使用Resnet50[15]作为特征提取网络,网络参数较多,模型大小不适合在边缘设备上进行计算[16],改进后的网络结构采用轻量级网络MobileNetV3作为骨干网络进行特征提取,提出了基于CBAM的MobileNetV3特征提取网络结构,通过通道注意力机制来关注需要被“重视”的特征,“忽略”无用的特征和作用小的特征,然后通过空间注意力机制来关注需要“重视”特征区域,进而有效的提高了网络结构的精度。
在表1所示的MobileNetV3网络层中,bneck为一系列特殊的卷积,批量归一化(Batch Normalization, BN)和挤压激励模块混合作用的操作,pool为池化层,NBN代表不使用批量归一化层,conv2d为卷积操作,表示最后输出的通道数。
表1 MobileNetV3网络结构
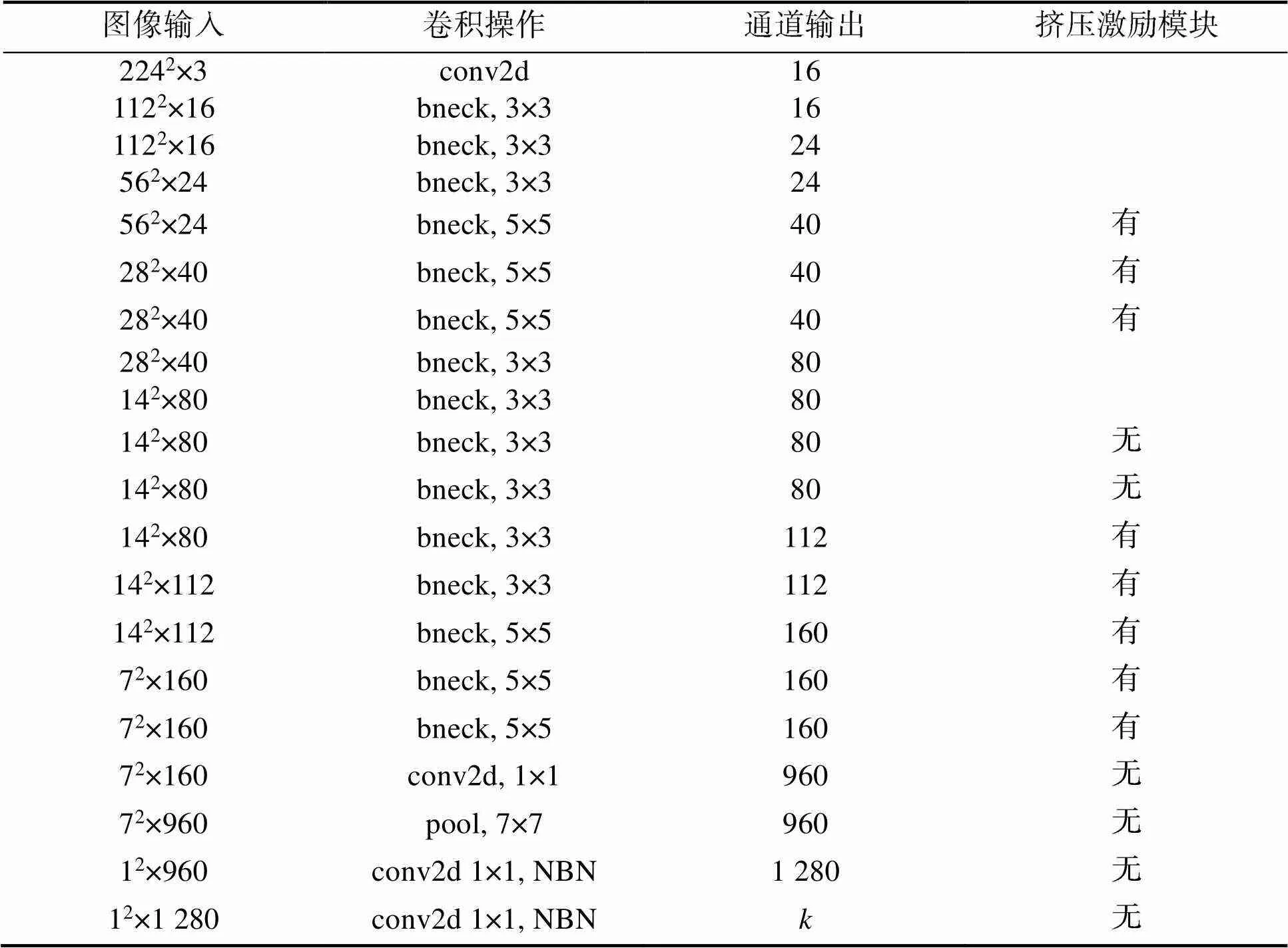
Tab.1 MobileNetV3 network structure
融合网络结构如图4所示,Block1~Block5为经过初始的一系列bneck串联组成(Block1表示第1~2个bneck,Block2表示第3~4个bneck,Block3表示第5~7个bneck,Block4表示第8~13个bneck,Block5表示第14~15个bneck),输入分别112像素×112像素、56像素×56像素、28像素×28像素、14像素×14像素和7像素×7像素。将Block1~Block5分为三部分送入FPN中进行特征融合,用不同特征层的识别不同的目标,提升模型的特征检测效果。在Block1之前和Block5[17-18]之后使用通道注意力机制和空间注意力机制。

图4 CBAM-MobileNet网络结构
骨干网络从Resnet50更换为MobileNetv3之后,网络模型的参数量大幅度下降,模型参数量从原先的32.12×106减少为11.73×106,减少到原来的三分之一,每张图片的识别速度下降了20ms,模型推理速度提升了10%。
1.4 TIOU损失函数
为了优化边界框的回归损失函数,在广义交并比()[19]损失函数中引入边界框的长宽比例系数,进而提出了一种T交并比(TIOU)作为边界框回归的损失函数。
IOU损失函数如下
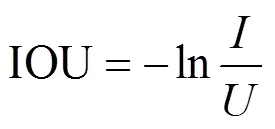
式中为图5两框的交集;为两框的并集。该损失函数的缺点是:在两个框没有交集的时候,分母为0,所以所求IOU很大,效果不佳。
GIOU是在IOU基础上的改进版本,如图6所示,绿色是真实框,红色是预测框,最外面的蓝色边框是将红绿矩形用最小矩形框起来的边界,是蓝色矩形框的面积,对应红绿矩形的并集面积。
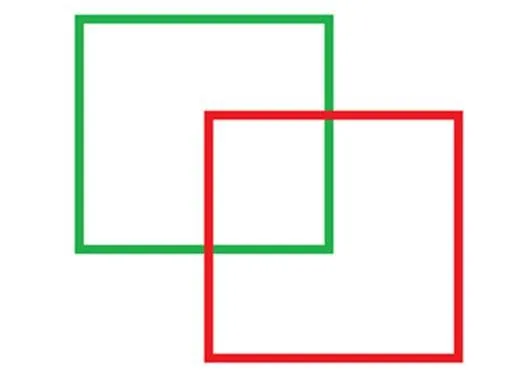
图5 IOU示意

图6 GIOU示意
GIOU解决了IOU中真实框和预测框没有交集产生的问题,在GIOU中,如果当真实框和预测框完美重合,那么IOU=1,和和预测框面积相等,GIOU=1。如果两个框距离很大,趋向于很大的数值,趋向于0,IOU趋向于0,GIOU= –1。因此GIOU取值的区间是[–1, 1]。
式(2)中GIOU计算方式如下
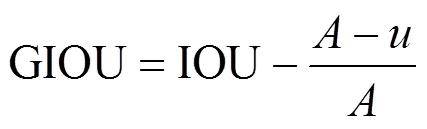
由于GIOU中没有考虑边框长宽比,所以所探测出的目标框并不是最佳长宽比,本文提出的TIOU在GIOU的基础上,额外考虑了预测框和真实框不相交和真实框与预测框之间宽高比例的问题,添加了预测框的长宽比系数,这样预测框就会与真实框更加接近。
式(3)TGIOU计算方式如下(、和gt、gt分别代表预测框的高度、宽度和真实框的高度、宽度)
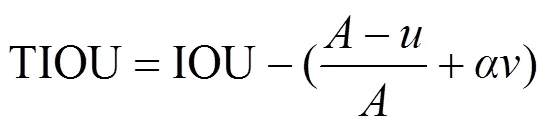
式中

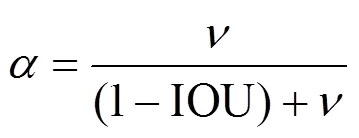
2 实验与分析
2.1 遥感数据集及评价指标
为了验证本文算法的性能,测试实验在遥感影像数据集(RSOD)上进行。RSOD为2015年武汉大学发布的一个公开的遥感图像数据集。其中有四大类别,分别为:飞机数据集,446张飞机图片中标记了4 993架飞机;操场数据集,189张操场图片中标记了191个操场;天桥数据集,176张天桥图片中标记了180座天桥;油箱数据集,165张油箱图片标记了1 586个油箱。训练时,在四个数据集中按1:8的比例随机选取图片,保证实验结果的鲁棒性。
使用平均精确率均值(Mean Average Precision,mAP)、精确率均值(Average Precision,AP)来衡量网络的性能[20]。AP衡量的是学出来的模型在每个类别上的好坏,分类器越好,AP值越高,mAP衡量的是模型在所有类别上的好坏,其范围是[0,1]。取所有类别AP的平均值就是mAP。不管是AP还是mAP,相较于精确率和召回率,都比较综合地评价了模型的性能。因此,以上两个评价指标是衡量目标检测算法性能的重要指标。准确率是预测正确的正样本数占预测为正样本总数的比例,召回率是预测正确的正样本数与正样本总数的比率。
如图7所示AP值为精确率随召回率的变化曲线,即-曲线与坐标轴围成的面积。
如图8所示,mAP用来评价模型的整体检测精度,每个类别的目标的AP值相加后取平均值得到,mAP是衡量一个模型好坏的重要指标。
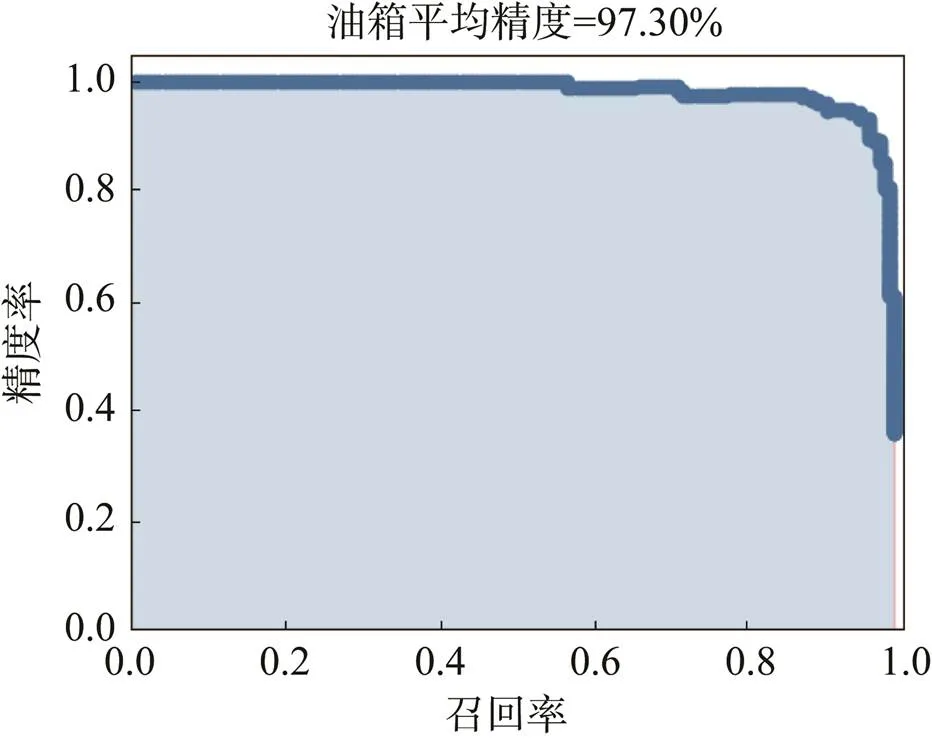
图7 油箱平均精度
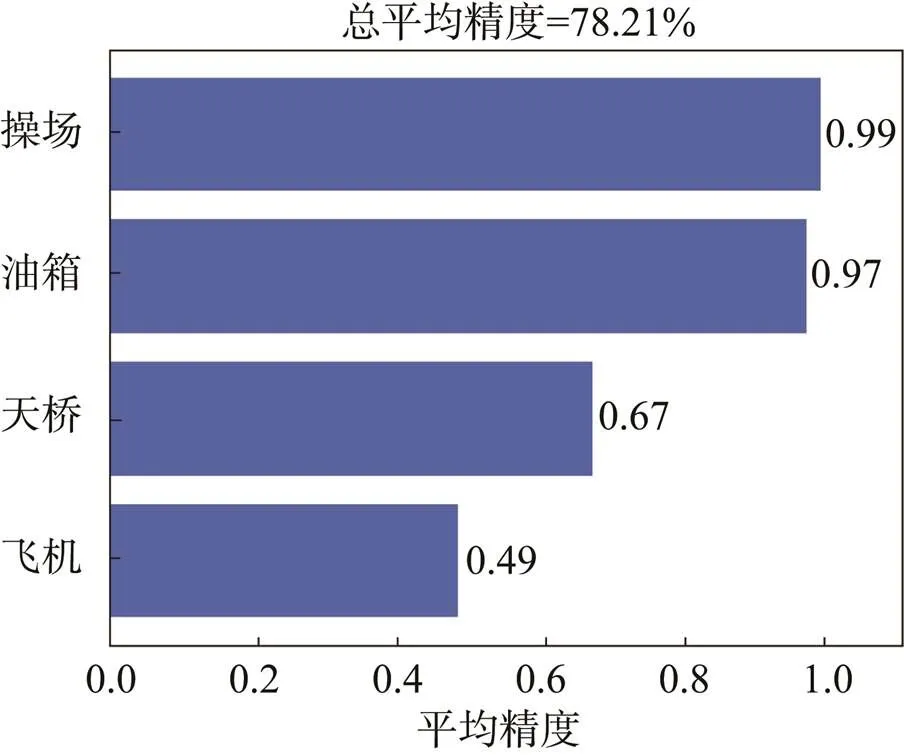
图8 数据集mAP
2.2 实验配置与模型参数设置
Windows环境下进行网络的训练和测试,CPU为Intel(R)Core(TM)i7-10750H,显卡(GPU)为GTX2060,OS为Windows10,使用Python3.7作为编程语言,Pytorch1.8作为深度学习的框架,并结合CUDA10.2和CUDNN7.6工具包进行训练和推理加速。
模型训练时网络输入的图片大小为800像素×1 333像素,采用的优化算法是SGD(Stochastic Gradient Descent),训练轮次为25,学习率为0.000 1,每隔5轮下调一次学习率,动量因子为0.9,训练配置如表2所示。
表2 实验配置

Tab.2 The Experimental Configuration
训练MVBCA-FCOS目标检测算法的损失函数计算公式如式(6)
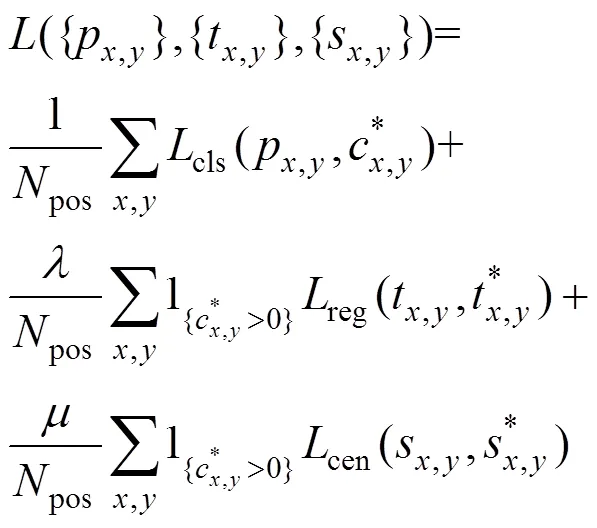
式中p,y、t,y、s,y和p,y、t,y、s,y分别为预测框和真实框的预测和真实的分类回归分数、边界回归分数和中心度回归分数,其中,为中心位置;pos为正样本的数量;cls、reg和cen分别为分类损失函数、边界框损失函数和边框中心损失函数;为reg的平衡权重因子;为cen的平衡权重因子。
2.3 消融实验分析
为了验证MVBCA-FCOS中各个模块对目标检测结果的影响,在RSOD遥感数据集上进行了消融实验[21],以MobileNetV3为检测网络为消融实验的基线,实验结果如表3所示。对于更换MoblieNetV3轻量级网络后,mAP精度下降2.6%,串联添加通道注意力机制和空间注意力机制后,精度上升2%,然后改进边框回归,引入TIOU,使得边框的真实框和预测框更加接近[22],且提升了0.6%,mAP由基本的基线中的91.5%提升到了94.1%,在精度未丢失的前提下模型大小和训练时间缩短为原来的一半,模型的参数量大大减少,模型的推理速度提升了10%。
表3 在RSOD上的消融实验对比
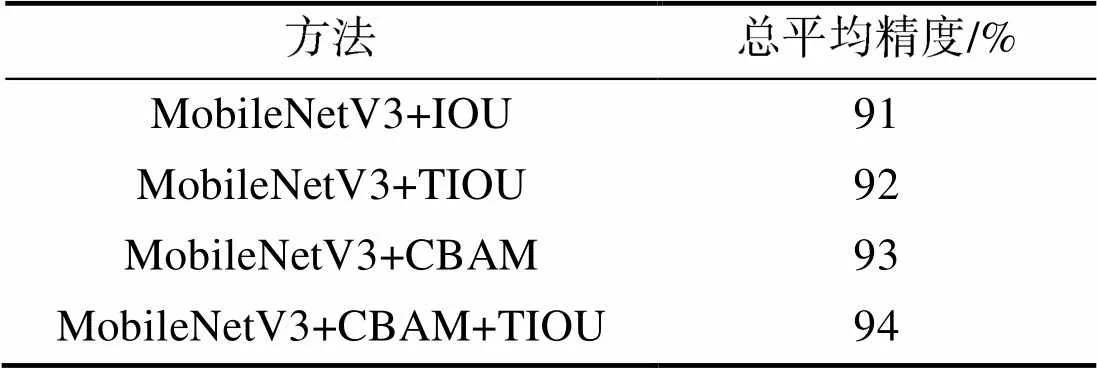
Tab.3 Comparison of ablation experiments on RSOD
2.4 对比实验分析
为了验证算法的鲁棒性和可行性,选取了主流的YOLOV3和Faster R-CNN做对比实验[23],选取的RSOD遥感数据集中,四种算法对操场的特征提取都较为良好,而油箱中有很多小目标,实验结果比较有区分度。如表4所示,本实验方法的网络精度和原始FCOS精度大致相同的情况下,缩短了模型训练和模型的大小,为原始模型的一半,推理时间提升了10%。
如图9所示,原始算法FCOS漏检了左上角的油罐,本文提出的MBVCA-FCOS算法可以较为全面的检测到油箱。
表4 不同目标检测算法在RSOD数据集上的结果对比

Tab.4 ComparisonofresultsofdifferenttargetdetectionalgorithmsonRSODdataset 单位:%

图9 算法效果对比
3 结束语
针对目标检测中,锚框设定、超参数难调整和对小目标检测效果不佳等一系列问题,本文提出了一种基于无锚框FCOS改进的检测模型MBVCA-FCOS。基于骨干网络的更换,交并比损失函数的改进,空间注意力机制和通道注意力机制的引入,在精度不丢失的前提下,提升了模型推理速度,进而提升了对小目标检测的效果,缩小了模型大小,使得该网络能够在更加便携设备上进行部署。该算法在多类目标检测中取得了较好的效果,验证了算法的有效性和鲁棒性。不过,仍然有两个问题可以改进,一是应用模型剪枝技术或者模型量化技术进一步缩小模型大小、提升模型速度,二是通过改进特征融合网络进一步提升网络的精度。
[1] 李庆忠, 徐相玉. 基于改进YOLOV3-Tiny的海面船舰目标快速检测[J]. 计算机工程, 2021, 47(10): 283-289, 297.
LI Qingzhong, XU Xiangyu. Fast Target Detection of Surface Ship Based on Improved YOLOV3-Tiny[J]. Computer Engineering, 2021, 47(10): 283-289, 297. (in Chinese)
[2] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[3] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot Multibox Detector[C]//2016 European Conference on Computer Vision(ECCV), October 8-16, 2016, Amsterdam, Netherlands. Springer, 2016: 21-37.
[4] REDMON J, FARHADI A. YOLOv3: An Incremental Improvement[EB/OL]. [2022-5-30]. http://arxiv.org/abs/1804. 02767.pdf.
[5] REDMON J, FARHADI A. YOLO9000: Better, Faster, Stronger[EB/OL]. [2022-03-30]. https://arxiv.org/pdf/1612.08242.pdf.
[6] LIN T, DOLLÁR P, GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 2117-2125.
[7] LAW H, TENG Y, RUSSAKOVSKY O, et al. CornerNet-Lite: Efficient Keypoint Based Object[EB/OL]. [2022-03-30]. https://arxiv.org/pdf/1904.08900.pdf.
[8] TIAN Z, SHEN C, CHEN H, et al. FCOS: Fully Convolutional One-stage Object Detection[EB/OL]. [2022-03-30]. https://arxiv.org/pdf/1904.01355.pdf.
[9] HU H, GU J, ZHANG Z, et al. Relation Networks for Object Detection[EB/OL]. [2022-03-30]. http://arxiv.org/abs/1711.11575.
[10] HOWARD A, SANDLER M, CHU G, et al. Searching for MobileNetV3[C]//IEEE/CVF International Conference on Computer Vision, October 27-November 2, 2019, Seoul, Korea (South). Piscataway: IEEE, 2019: 1314-1324.
[11] WOO S, PARK J, LEE J Y, et al. KWEON, CBAM: Convolutional Block Attention Module[EB/OL]. [2022-03-30]. https:/arxiv.org/pdf/1807.06521.pdf.
[12] JIANG B, LUO R, MAO J, et al. Acquisition of Localization Confidence for Accurate Object Detection[EB/OL]. [2022-03-30]. http://arxiv.org/abs/1807.11590.pdf.
[13] 孙广慧. 融合Resnet50与改进注意力机制的绝缘子状态识别研究[J]. 电子技术与软件工程, 2021(16): 247-248.
SUN Guanghui. Research on Insulator State Recognition Based on Resnet50 and Improved Attention Mechanism[J]. Electronic Technology & Software Engineering, 2021(16): 247-248. (in Chinese)
[14] YU J, JIANG Y, WANG Z, et al. UnitBox: An Advanced Object Detection Network[EB/OL]. [2022-03-30]. https://arxiv.org/pdf/1608.01471.pdf.
[15] HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 27-31, 2016, Las Vegas, NV, USA. IEEE, 2016: 770-778.
[16] TAN M, PANG R, LE Q V. EfficientDet: Scalable and Efficient Object Detection[EB/OL]. [2022-03-30]. http://arxiv.org/abs/1911.09070.pdf.
[17] HU J, SHEN L, ALBANIE S, et al. Squeeze and Excitation Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2020, 42(8): 2011-2023.
[18] HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 27-31, 2016, Las Vegas, NV, USA. IEEE, 2016: 770-778.
[19] REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression[EB/OL]. [2022-03-30]. http://arxiv.org/abs/1902.09630.pdf.
[20] 郭磊, 王邱龙, 薛伟, 等. 基于改进YOLOv5的小目标检测算法[J]. 电子科技大学学报, 2022, 51(2): 251-258.
GUO Lei, WANG Qiulong, XUE Wei, et al. Small Target Detection Algorithm Based on Improved YOLOv5[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(2): 251-258. (in Chinese)
[21] 张中华, 贾伟宽, 邵文静, 等. 优化FCOS网络复杂果园环境下绿色苹果检测模型[J]. 光谱学与光谱分析, 2022, 42(2): 647-653.
ZHANG Zhonghua, JIA Weikuan, SHAO Wenjing, et al. Optimization of FCOS Network Detection Model for Green Apple in Complex Orchard Environment[J]. Spectroscopy and Spectral Analysis, 2022, 42(2): 647-653. (in Chinese)
[22] HAN X, LEUNG T, JIA Y, et al. MatchNet: Unifying Feature and Metric Learning for Patch-based Matching[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 8-10, 2015, Boston, USA. IEEE, 2015.
[23] LOWE D G. Object Recognition from Local Scale-invariant Features[C]//1999 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 23-25, 1999, Fort Collins, CO, USA. IEEE, 1999.
Remote Sensing Target Detection Based on Improved FCOS Network
ZHENG Meijun TIAN Yimin*YANG Shuai
(School of Information Engineering, BIGC, Beijing 102627, China)
The main task of target detection is to find the location and category of the target. With the development of artificial intelligence and deep learning, target detection can achieve accuracy beyond human eyes. Due to less information and small coverage area, the detection algorithm based on anchor frame is easily affected by the size and proportion of anchor frame, and it is difficult to accurately detect small targets. Aiming at the above problems, Fully Convolutional One-stage Object Detection (Fully Convolutional One-stage Object Detection, FCOS) algorithm without anchor frame is improved to achieve the efficiency and accuracy of small target detection. FCOS feature extraction network structure ResNet (Residual Network, ResNet) is replaced with lightweight network structure MobileNetV3. Then, channel attention mechanism and spatial attention mechanism are introduced in BackBone network to improve feature extraction network. Finally, T-intersection ratio (TIOU) is designed to replace the original intersection ratio (IOU) to improve model accuracy. Experimental results show that compared with FCOS, the network training time and model size of the improved network structure are half of the original, the number of calculation parameters is reduced from 32.12×106to 11.73×106which is one third of the original, the model inference speed is increased by 10%, and the transmission frame per second (FPS) is 11. Compared with the mainstream Faster network Faster RCNN detection accuracy and speed, can meet the real-time detection of small targets.
convolutional neural network; one-stage object detection; convolutional block attention module; remote sensing application
TP79
A
1009-8518(2022)05-0133-09
10.3969/j.issn.1009-8518.2022.05.013
2022-04-25
国家自然科学基金项目(NSFC61378001,NSFC61178092)
郑美俊, 田益民, 杨帅. 基于改进FCOS网络的遥感目标检测[J]. 航天返回与遥感, 2022, 43(5): 133-141.
ZHENG Meijun, TIAN Yimin, YANG Shuai. Remote Sensing Target Detection Based on Improved FCOS Network[J]. Spacecraft Recovery & Remote Sensing, 2022, 43(5): 133-141. (in Chinese)
郑美俊,男,1997年生,2019年获华北科技学院信息工程学院自动化工学学位,现在北京印刷学院电子信息专业攻读硕士学位。研究方向为深度学习和计算机视觉。E-mail:269881724@qq.com。
田益民,男,1966年生,2003获中科院计算数学所计算数学专业理学博士学位,现为北京印刷学院电子信息专业博士生导师。主要研究方向为算法设计。E-mail:tym8@bigc.edu.cn。
(编辑:庞冰)
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
红领巾·萌芽(2019年8期)2019-08-27
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
中国与非洲(法文版)(2017年10期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
