
基于多专家和MDNet的视觉目标跟踪方法*
2022-11-15 04:05张知明李国荣黄庆明
中国科学院大学学报 2022年6期
张知明,李国荣,黄庆明
(中国科学院大学计算机科学与技术学院, 北京 100049)
视觉目标跟踪一直是国内外计算机视觉领域的研究热点,广泛应用于视频监控、视频分析、人机交互等领域。表观建模是目标跟踪的关键问题之一,吸引了许多研究人员。有效的表观模型可以帮助跟踪器准确识别目标。然而,在大多数视频中,目标和背景通常会因为光照变化而不断变化,遮挡、剧烈运动等经常发生,导致目标或背景发生较大的变化,给目标表观的建模带来极大的挑战。
早期的工作,如Isard和Blake[1]及Comaniciu等[2]用固定的特征如颜色、方向梯度直方图来描述目标。从给定的初始化框内采集有标签的样本,然后利用判别式或生成式方法构建表观模型。显然,当目标的外观发生变化时,这类跟踪器会失败。为适应目标和背景的变化,研究人员把注意力集中在了特征的在线选择和模型的在线更新上。增量子空间学习[3]、稀疏重建[4-6]、在线判别分类[7]等方法被用于处理跟踪过程中目标及背景的变化,取得了不错的效果。但是当视频内容发生较大变化时,这类方法往往不能准确地跟踪到目标。
与此同时,为提高跟踪器的速度,很多基于相关滤波(correlation filter)的目标跟踪算法[8-10]涌现了出来。这类方法主要通过设计学习有效的滤波模板,然后利用该模板与目标候选区域进行相关运算,选择响应最大的候选作为跟踪目标。在这种表示下,分类模型的训练和测试可以转换到傅里叶空间进行加速运算,使得跟踪器的处理速度极快,但仍难以处理视频的突变。
近年来,随着深度卷积神经网络(deep convolutional neural networks,DCNN)技术在目标检测领域的成功[11],目标跟踪领域也陆续将DCNN引入[12-14]。例如Wang和Yeung[12]提出利用堆叠去噪自编码器的网络[15]从大图像数据集学习通用图像特征作为辅助数据,然后将学到的特征用于在线跟踪。在大型视觉目标跟踪公共数据集上的实验结果证明,基于DCNN的跟踪方法取得了优于使用传统特征的跟踪结果。但是大部分算法只是使用在大量图像分类数据集上训练好的网络作为特征提取器,而分类和跟踪之间存在着明显的差异。利用分类任务上学习到的特征来跟踪并不是一个最好的选择。为此,Wang等[13]分析各个层的特征对跟踪的影响,提出一个同时利用卷积神经网络捕捉语义信息的深层特征和捕捉个体细节的低层特征的二分支网络结构。Nam和Han[14]提出MDNet(multi-domain network),该网络通过利用目标跟踪数据集对在图像分类数据集ImageNet上预训练好的模型进行微调,以达到适应目标跟踪数据集的目的。具体来说,由于同一个物体在某些视频中是目标而在另外一些视频中是背景,这对分类器造成很大的困扰。
为解决上述问题,如图1所示,MDNet设计了多分类器分支的网络结构,为每个训练视频使用不同的分类器,从而能将该视频中的跟踪目标分为前景。具体来说,MDNet将每个序列作为单独的域,在网络的后端设计一个域特定层进行二分类;而网络的其他层则是共享层,供每段视频共同使用,从而挖掘所有序列中的信息进行学习。在测试阶段,对目标的长期和短期变化进行建模,在线微调共享层中的全连接层和新的分类层,以适应目标的动态变化。
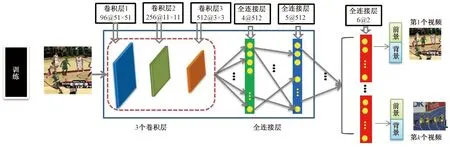
图1 MDNet的结构图
在跟踪过程中,MDNet会对全连接层进行更新,并用于跟踪后续帧中的目标。这样,跟踪器虽然可以适应视频变化,但是后续帧中的目标可能与近期观察到的目标不同,更新后的跟踪器反而不适用于处理后续的帧,进而导致跟踪失败。为解决这一问题,Nam等[16]提出基于图模型的跟踪方法。该方法利用所处理的帧构建一个高阶马尔可夫链,然后依据场景及跟踪目标的特征从已处理的帧中选择与当前帧相关的帧,用于概率的传播。受此方法启发,本文提出一种新颖的多专家跟踪方法,图2显示了所提方法的框架。在跟踪过程中,利用不同时间段的样本构造多个专家跟踪器,融合多个专家的跟踪结果得到准确的跟踪结果。本文的主要贡献总结如下:
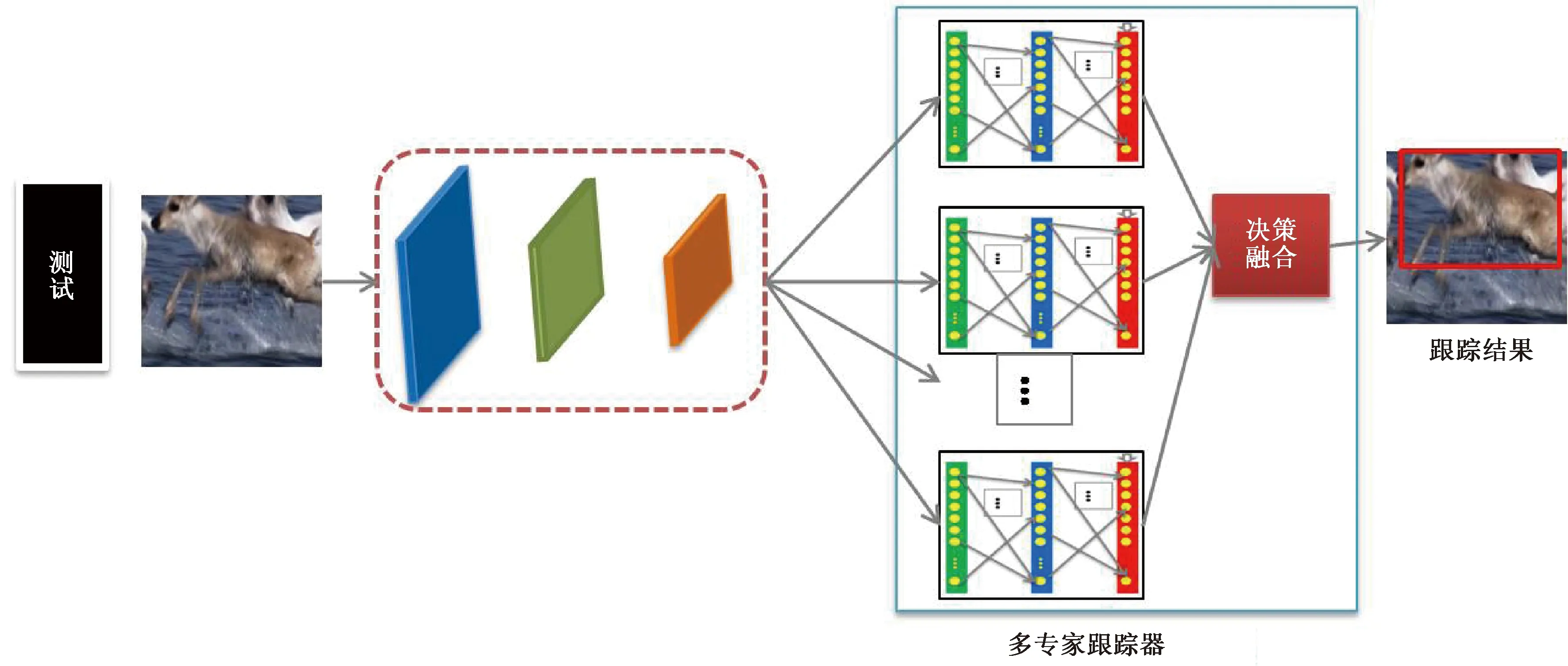
图2 所提方法的框架图
1)针对视频中存在突变如光照、尺度、运动模糊等挑战,提出多专家跟踪器的跟踪策略;
2)提出有效的多决策融合策略,融合多专家跟踪器得到更准确的结果;
3)从公共数据集OTB50上选取有突变的25段视频,在突变视频及OTB50上的实验结果证明所提方法的有效性。
1 MDNet简介
MDNet[10]将每个视频看作一个域,设计了一个轻量级的、多域的、小型网络来学习卷积特征,用于表示目标。网络结构如图1训练部分的图所示,它的输入是107×107大小的RGB图像,并具有5个隐藏层,包括3个卷积层和2个全连接层。另外,网络最后对应的全连接层具有K个分支。卷积层与VGG-M网络[12]的相应部分相同,其中特征图尺寸和输入尺寸作了调整。接下来的2个全连接层具有512维输出,并且与线性整流函数(rectified linear unit, ReLU)和剔除(dropout)结合。每个K分支包含一个具有softmax交叉熵损失的二分类层,它负责区分每个域即每一个训练视频中的目标和背景。通常将这K个分支称为域特定层,而前面的所有层称为共享层。共享层用来学习所有视频中目标的特征表达,而域特定层则用于学习特定视频序列的softmax分类器。
在离线训练时,针对每个视频序列构建一个新的检测分支,即在网络的第6层构建一个新的全连接层进行训练。而特征提取网络则是共享的,因此,特征提取网络可以学习到通用性更强的且与域无关的特征。
2 多专家跟踪系统
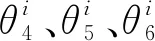
2.1 生成多专家跟踪器
但是在跟踪过程中,视频变化复杂, 此时更新得到的参数未必适用于下一帧的跟踪,而之前得到的全连接层的参数或许能够在下一帧中取得好的跟踪结果。图3展示了有运动模糊的图像。红色、绿色和黄色框分别表示我们方法、MDNet和人工标注的结果。可以看出第35帧和第36帧差异较大,第35帧得到的跟踪器的跟踪效果不如第29帧得到的跟踪器的效果好。为此,在更新参数时,我们没有舍弃原来的参数。而是用更新后的参数去初始化一个新的专家Tm(ϑm,·),m=2,3,…,M,这样能够保存更丰富的专家跟踪器。M为专家数目的最大值。当专家的总数超过M个时,舍弃最早构建的专家。

图3 所提方法与MDNet在有运动模糊的视频上的定性对比
2.2 多专家融合策略
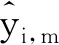
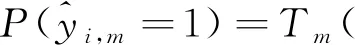
(1)
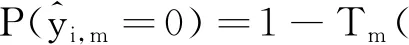
(2)
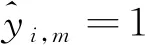
为了衡量评估每个专家跟踪器的性能,定义了两项评价准则:信息熵和最大似然。其中信息熵反映该专家对这256个候选做出判断的不确定性。而最大似然则反映该专家选出的最优跟踪结果的置信度。第m个专家跟踪器在第i个候选上的信息熵Lm(xi)的定义如下
(3)
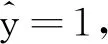
(4)
对于一个专家跟踪器,我们希望信息熵越小越好,似然函数取值越大越好。因此,一个专家跟踪器的评价损失函数由下式来定义:
(5)
这里γ是加权系数。最终选取评价损失最小的专家,用于处理当前帧,得到跟踪结果。算法1给出了所提算法的具体流程。

算法1:多专家跟踪器(MMDNet)Algorithm 1: Multiple experts tracker输入:帧序列{It}T0, 初始化目标框b0;专家跟踪器的最大数目M输出:预测的每一帧中的目标位置即跟踪结果 {bt}T1利用第1帧来初始化第6层的全连接层f6c(θ6);使用第4、5、6层全连接层的参数初始化一个专家T1(ϑ1,·);E={T1(ϑ1,·)};For t=1:T do 从It中采集256个候选X={x1,x2,…,x256}; 根据式(5)计算专家的评价损失函数; 选择最优的专家跟踪器,idx=argminLm(X); 利用Tidx(ϑidx,·)来得到跟踪结果; 根据MDNet的策略搜集正负样本; If 更新模型 用搜集到的样本微调3个全连接层的参数; 利用新得到的参数来构建一个新的专家跟踪器tempT; If E中专家的数目小于ME={tempT}∪E; Else 用tempT替换E中最早构建的专家跟踪器; EndIf EndIfEndFor
3 实验
公共数据集OTB50[17]包含50段测试视频。通常情况下,若视频中存在快速运动(fast motion)、光照变化(illumination variation)、目标尺度变化(scale variation)或运动模糊(motion blur)时,相邻帧间容易存在突变。为验证所提算法在具有突变的视频上跟踪效果,从OTB50中选择了具有以上4种属性的25段视频进行测试。
此外,我们还在公共数据集OTB50上进行实验,专门对比了MDNet和所提的多专家跟踪器MMDNet。实验中,依据经验将γ设置为0.9。
3.1 评价指标
算法估计的目标位置(bounding box)的中心点与人工标注(ground-truth)的目标的中心点,这两者的距离称为位置误差。若某一帧中位置误差小于给定阈值,则这帧被称为跟踪成功的帧。准确率则是被跟踪成功的帧占所有帧的比例。这样在给定数据集上,可以绘制出一条误差阈值-准确率(location error threshold-precision)的曲线。所有算法按照中心点误差不大于20个像素时的准确率进行排序,该数值越大表明跟踪结果越准确。
另一种评价指标为重合率得分(overlap score,SO),即跟踪算法得到的跟踪结果(记为a)与人工标注的结果(记为b)的重合率。其具体定义如下:
SO=|a∩b|/|a∪b|,
其中:|·|表示区域的像素数目。当某一帧的重合率得分大于设定的阈值时,则该帧被视为跟踪成功的帧。在给定重合率得分阈值下,某个视频上的成功率就是在该视频上成功的帧数除以该视频总帧数;在整个数据集上的成功率是所有视频成功率的均值。这样在给定数据集上,可以绘制出一条重合率阈值-成功率(overlap threshold-success rate)的曲线,所有算法根据成功率曲线下面积的大小进行排序,面积越大表明算法越好。
3.2 专家跟踪器数目的选择
由于专家跟踪器的数目会对跟踪结果有一定的影响,为设置合适的专家数目,在测试视频上,对不同的专家跟踪器数目{2,4,6,8,10,12,14}进行了测试。表1展示使用不同数目的专家跟踪器在“car4”序列上得到的跟踪结果,用粗体标出了最佳的跟踪结果。
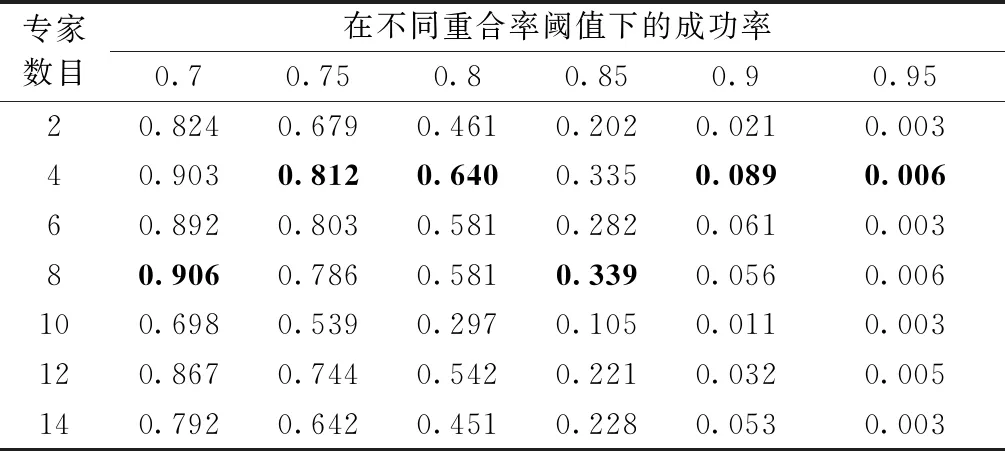
表1 不同的专家跟踪器数目对应的跟踪结果
可以看出,在不同的阈值下,最优跟踪器对应的专家数目不同。总体上来看,当专家跟踪器的数目增多时,跟踪性能先提升再下降。比如当重合率阈值是0.85时,专家的数目从2增加到8,跟踪器的性能有所提升。但是,当专家的数目超过8时,继续增加专家的数目,反而会使跟踪性能下降。我们认为专家数目过多时,专家差异大,导致最终的跟踪结果不准确。
此外,过多的专家也会需要较大的存储空间。从表1可以看出,专家数目为4时,在各个阈值下的成功率比较高。综合考虑跟踪效果与存储复杂度,在后续的实验中,将专家数设置为4。
3.3 实验结果比较
实验中,我们用一遍评估(one-pass evaluation,OPE),即用第1帧中人工标注的目标位置初始化跟踪器,然后运行跟踪算法得到平均精度和成功率。与主流跟踪方法MDNet[13]、SCM[18]、Struck[19]、TLD[20]、VTD[21]、VTS[22]、MTT[5]、ASLA[6]和CSK[8]等跟踪器进行了比较,图4展示在有突变的25段视频上的跟踪结果。可以看出与其他主流跟踪方法相比,MDNet能够取得较好的跟踪结果。而与MDNet相比,MMDNet在位置误差阈值-准确率、重合率阈值-成功率曲线面积上分别提升4.9%和2.6%。这表明不论以跟踪误差来衡量还是以重合率来衡量,所提的MMDNet都取得了优于MDNet的跟踪结果,这说明通过融合多专家跟踪器的决策,能够提升跟踪结果的准确性。
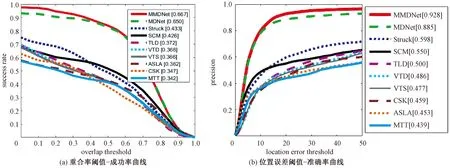
图4 在突变视频上跟踪结果的定量比较
为了进行更细致的结果分析,在快速运动、光照变化、运动模糊和目标尺度变化4种属性上分别对比了跟踪方法。图5分别给出在各类视频上的跟踪结果的重合率阈值-成功率和位置误差阈值-准确率曲线,可以看出在各类突变视频上,MMDNet的跟踪结果都优于MDNet。图6展示了一些代表性的跟踪结果,红色、绿色和黄色框分别表示MMDNet、MDNet和人工标注的结果。在第1行的第125帧中,由于跟踪目标运动较快,MDNet跟踪失败,而所提方法能够采用合适的专家跟踪器,取得准确的跟踪结果。在第364帧,由于光照变化大,MDNet再次失败,而MMDNet依然取得了较好的跟踪结果。在第3行所示的图像中,由于运动模糊的存在,第16帧和第15帧中的目标表观差异大,所以MDNet的跟踪结果很不准确,而MMDNet综合多个专家跟踪器的结果,取得了较为准确的跟踪结果。
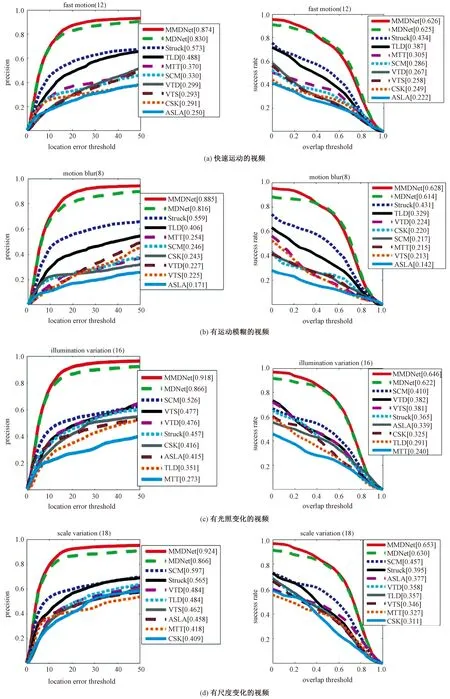
图5 在各类视频上的跟踪结果比较

图6 在测试视频上的代表性跟踪结果
为了对比MMDNet与MDNet,在OTB50的所有序列上测试了这两种方法。图7为它们的定量比较结果。可以看出MMDNet在OTB50的所有序列上的性能也是优于MDNet的,这更进一步地说明了多专家跟踪器策略的有效性。
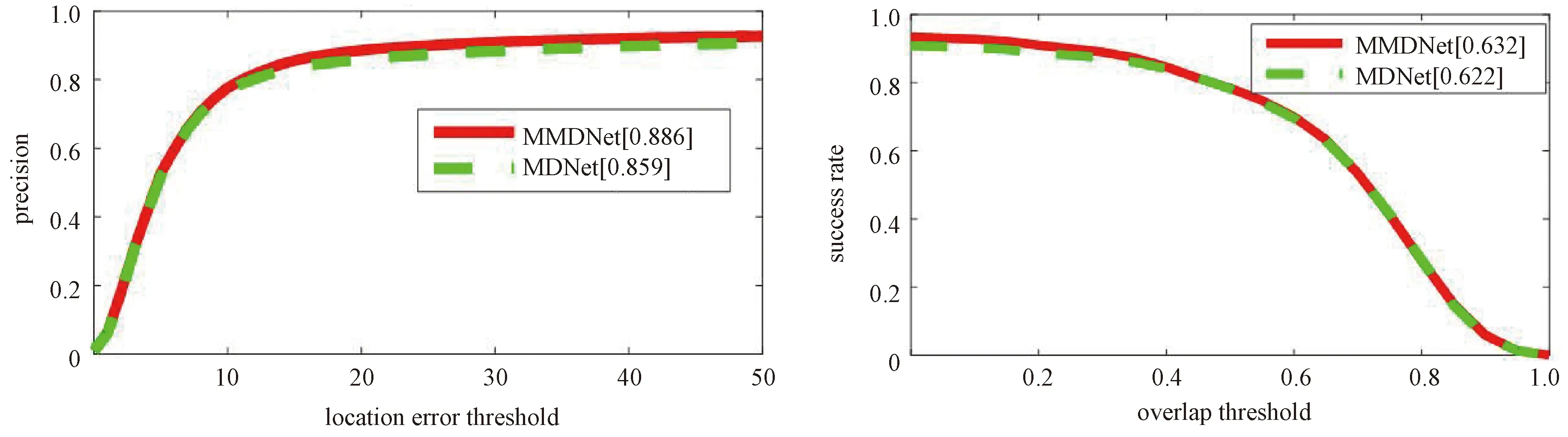
图7 在公共数据集OTB50上的定量实验结果比较
4 结论
本文提出一种基于多个专家跟踪器的视觉目标跟踪新方法。该方法在MDNet基础上,构建多个专家跟踪器,利用有效的多决策融合策略得到更鲁棒、准确的跟踪结果。MDNet利用深度卷积网络能够学到有效的视觉特征表达,而多个专家跟踪器则可以集思广益,应对视频中的各种变化尤其是突变。在公共数据集中存在突然变化的25段视频及公共数据集上的跟踪结果表明,本文提出的算法MMDNet综合MDNet及多专家系统的优势,有效缓解了由于视频突变而导致的跟踪器失败的问题。
猜你喜欢
网络安全与数据管理(2022年7期)2022-08-23
检察风云(2022年8期)2022-05-13
太阳能(2022年3期)2022-03-29
河南财经政法大学学报(2021年1期)2021-11-26
小猕猴智力画刊(2021年6期)2021-08-05
太阳能(2020年3期)2020-04-08
河南牧业经济学院学报(2020年3期)2020-01-16
当代工人·精品C(2019年2期)2019-05-10
计算机应用与软件(2017年7期)2017-08-12
作文大王·低年级(2016年3期)2016-03-11
