
基于双流LSTM与自监督学习的在线动作检测算法*
2022-11-15 04:05朱嘉桐卿来云黄庆明
中国科学院大学学报 2022年6期
朱嘉桐,卿来云,黄庆明
(中国科学院大学计算机科学与技术学院, 北京 100049)
视频动作分析一直是计算机视觉领域下的热门研究分支,动作识别、动作检测等问题都吸引了大量的研究人员的关注。然而这些问题都是需要获取到完整视频后才能对视频中的动作信息进行分析,不能很好地被应用于例如安保、人机交互等等需要模型对人们的动作进行实时在线检测的领域中。最近在线动作检测(online action detection)这一新兴的研究方向也引起了研究者们的关注。
由于在线动作检测这一问题被提出的时间并不长,因此针对这一问题的解决方法并不是很多,其中代表性工作包括RED[1]、TRN[2]与IDN[3]等。与动作识别问题中的算法不同,这些针对在线动作检测问题的方法均使用长短时记忆网络(long short-term memory,LSTM[4])作为基本的网络结构,而不是三维卷积神经网络(3D convolutional neural networks, 3D CNN[5])这样以整段视频作为输入的网络结构。其目的也是显而易见的:通过获取LSTM的每一个时刻的隐藏状态来作为当前时刻的时序特征用于动作类别判断,从而达到实时检测当前帧的动作的目的。
与动作识别等问题不同,在线动作检测因为要实时对动作进行识别,因此使用的视频通常是包含大量背景信息的未裁剪视频。另外,在在线检测的过程中,由于模型无法得知当前时刻以后的视频信息,因此其只能根据历史信息与当前时刻的信息来判断当前时刻的动作类别,这两点都对模型的时序建模能力提出了很高的要求。本文模型引入双流网络与自监督学习的思想,通过分别给RGB与光流建模时序特征更好地挖掘出视频中的时序信息以及它们的内在关联,从而得到更好的结果。主要贡献总结如下:
1)提出分别对视频的RGB特征与光流特征用LSTM模型的双流LSTM;
2)引入自监督学习的思想,提出基于双流模型的时序相似度损失与针对光流时序特征的光流稳定性损失;
3)在THUMOS’14[6]与TVSeries[7]这2个公共数据集上进行测试,实验结果证明本文提出的模型与算法的有效性。
1 相关工作
1.1 在线动作检测的相关方法
在线动作检测问题由Geest等[7]于2016年提出,然而该作者并没有随着问题的提出提供解决方案,而是在2年后提出2S-FN模型[8]作为该问题的解决办法之一。除Geest本人外,其他各种基于LSTM的在线动作检测模型被相继提出。Gao等[1]基于编码器-解码器结构以及强化学习思想提出了RED模型,通过根据编码历史信息来预测未来几帧的动作,并根据预测时间的长短来反馈模型不同的惩罚或奖励效果。当预测时间设置为0时,该模型可以被用于在线动作检测任务。在RED之后,Xu等[2]于2019年的ICCV会议上提出了同样基于编码器-解码器模型的TRN模型。与RED不同的是,TRN模型仅根据当前帧来预测未来几帧的特征,并将预测的未来特征用于当前帧的类别判断中,由此达到较好的效果。目前性能最好的模型由Eun等[3]于2020年的CVPR会议上提出的IDN模型。该模型使用LSTM的改进版本GRU[9]作为模型的基础单元,并将其内部结构进行修改以使当前帧的特征能更好地被提取并传递用于下一时刻的隐藏状态的更新中。
1.2 自监督学习的相关方法
自监督学习(self-supervised learning)是无监督学习(unsupervised learning)的一种特殊情况,其基本思想是通过挖掘大量无标注数据中的内在联系来设计间接任务(pretext task),之后通过训练模型更好地完成这个间接任务,让模型挖掘出数据内部的更丰富的信息。当模型从无标注数据中学习到大量数据的语义信息之后,就可以将训练好的模型放在有标注的数据集中进行进一步精细调优,从而达到更好的训练结果。虽然自监督学习的思想被广泛地应用于图像、自然语言等领域,其在视频分析领域中应用的并不是很广泛。与图像领域的自监督方法类似,Lee等[10]提出基于视频序列排序(sequence sorting)的视频自监督学习方法,主要思想是通过处理并打乱视频中的原始图像再传递到模型中让模型判断出图像的正确顺序,从而训练模型挖掘出视频帧之间的内在联系。与之类似的思想包括Luo等[11]提出的完形填空(cloze)方法、Xu等[12]提出的片段排序方法(clip ordering) 与Kim等[13]提出的时空立方体拼图(space-time cubic puzzles)方法。除此之外,Jayaraman和Grauman[14]于2016年提出基于孪生网络(siamese network)的时序相关性(temporally coherent embeddings, TCE)的模型,其通过借鉴一阶导数与二阶导数的求导思想分别设计出2个间接任务。第1个间接任务训练模型去最小化相邻帧之间的特征差值,并最大化无关帧之间的特征差值;第2个间接任务训练模型去最小化相邻三元组帧对的差值的差值,即时刻t、t+1、t+2三者的时序特征应符合等式ft+1-ft≈ft+2-ft+1,由此让模型对视频的时序特征的建模更加平缓。通过这2个损失函数,TCE模型获得了较好的实验结果。本文就是受到TCE方法的启发,通过设计间接任务使RGB与光流的时序特征接近并且让光流的时序特征变得更加稳定以增强模型对视频的建模能力。
2 双流LSTM自监督算法
之前的在线动作检测算法中,大多数都是将已经提取好的RGB流与光流特征在维度上进行串联后传入到LSTM模型中作为当前时刻的输入。这样做的缺点是并没有分开考虑RGB流特征与光流特征的时间分布情况。同时我们注意到,在过去的视频动作分析领域相关的问题中,使用双流网络例如TSN(temporal segment network[15])提取的特征在很多情况下要比使用3 D CNN提取的特征效果更好,这也让我们意识到应该将RGB与光流特征分别处理,而不是简单地进行融合后传入到模型中。
实际上,我们在实验中发现,RGB流特征与光流特征沿着时间的变化大小是不同的。图1展示了THUMOS’14数据集中一个视频的相邻帧的RGB特征与光流特征的欧氏距离。

图1 THUMOS’14数据集中相邻帧之间的RGB特征与光流特征距离
从图1中可以清晰地看到,相邻帧的RGB特征距离与光流特征距离随着时间的分布是不同的,其中光流特征的距离明显更大,也就是说光流特征随着时间变化更加地剧烈。这不仅证明了使用2个LSTM模型对RGB特征与光流特征分别进行建模是有意义的,也为接下来的自监督学习算法提供了支持。
2.1 双流LSTM模型结构
如上文所说,分别对RGB流与光流构建LSTM模型用于时序特征的提取,该模型的结构图如图2所示。
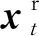
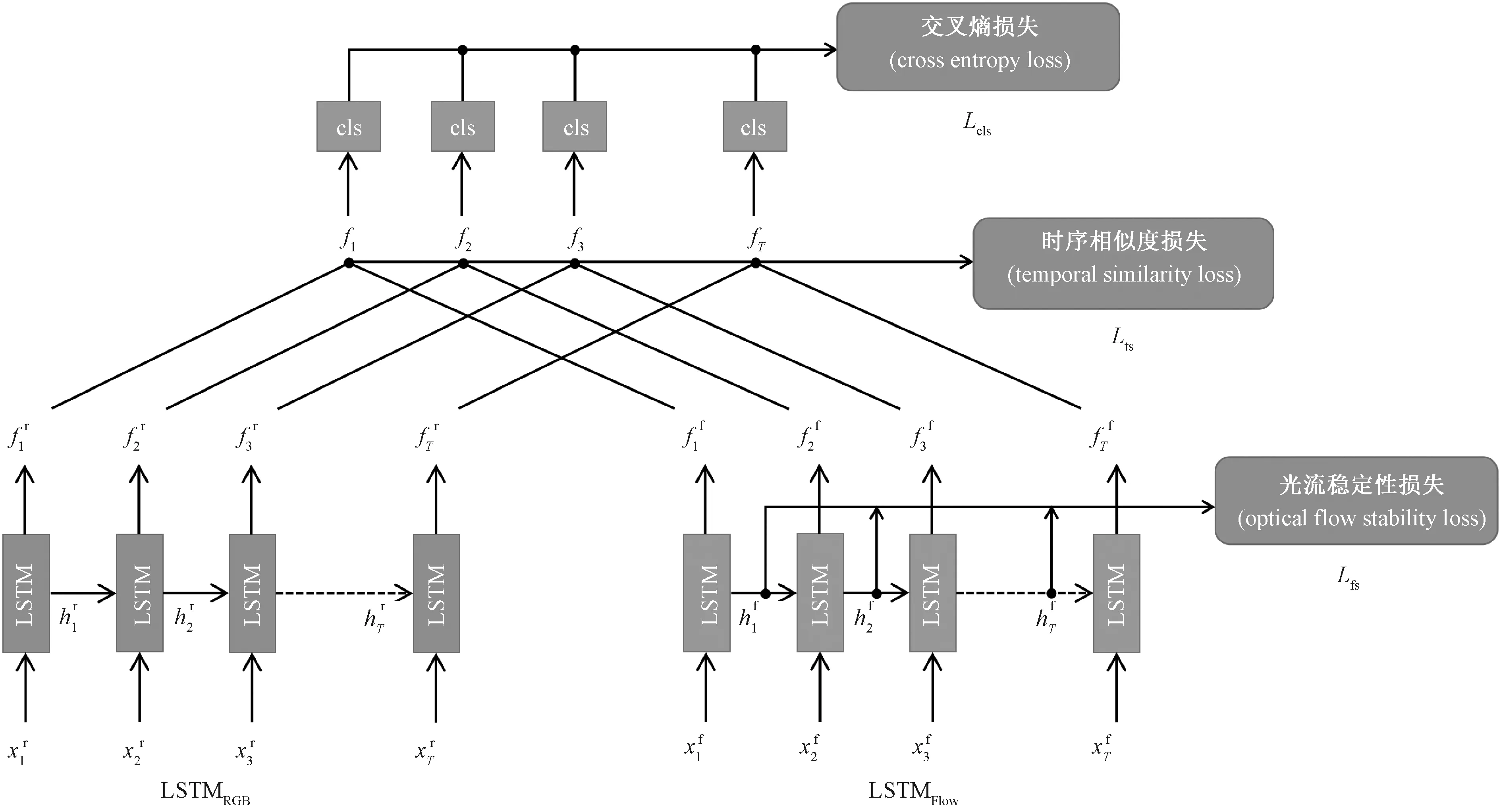
图2 2S-LSTM的结构示意图
(1)
(2)
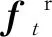
(3)
(4)
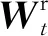
在获得时序特征之后,将2个时序特征在维度上进行串联,从而获得当前时刻的总体时序特征ft,即
(5)
其中⊕符号表示串联操作。
最后,将当前时刻的时序特征传入到分类器中进行动作分类,并获得当前时刻的动作的概率分布用于交叉熵损失函数的训练。该过程如下所示
pt=softmax(Wpft),
(6)
(7)
其中:Wp为可训练的分类器参数,pt为时刻t的动作类别的概率分布;yt,k为时刻t的真实标签,其中k为动作类别索引(包含背景类别);T与K分别为训练视频的长度以及包含背景在内的动作类别数量。
2.2 基于自监督学习的损失函数设计
本文除提出双流LSTM这一新型的模型结构外,还引入自监督学习的思想用于探究时序信息之间的内在关联。从上文中可知,由于光流的原始特征相比于RGB流的原始特征变化更加明显,随着时间的起伏更大,因此本文认为应该对通过光流特征提取出的时序特征进行一定的限制,保证其在时序上拥有一定的稳定性。除此之外,我们还认为RGB和光流是属于同一视频的不同表示模态,虽然其外在的表现方式不同,但其时序关系之间应该是近似的。出于这2点的考虑,本文提出基于自监督学习的2个损失函数,即光流稳定性损失(flow stability loss, FS)与时序相似度损失(temporal similarity loss, TS)。
2.2.1 光流稳定性损失
在图1可以看出,从光流中提取出的原始特征的相邻帧差异较大。这是因为相比RGB,光流更容易受场景变换以及人们细微的动作影响。因此,光流虽然可以提供丰富的动作信息,但也很容易造成模型对动作与背景之间的误判。出于这个原因,我们借鉴了拉普拉斯特征映射(Laplacian eigenmaps)[16]的思想,即根据原始的光流特征的差值决定提取的时序信息的差值大小,并由此设计出如下的损失函数Lfs
(8)
2.2.2 时序相似度损失
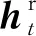
(9)
在获得3个损失函数之后,使用多任务学习的方法来获得总的损失函数L
L=αLcls+βLfs+γLts,
(10)
这里α,β,γ均为可以调节的超参数,表示不同损失所占比例。在THUMOS’14数据集中,经过实验分析,将α,β,γ的值均设定为1;而在TVSeries数据集中,将这三者分别设定为1、0.1与0.1。这是因为TVSeries数据集中的视频背景信息占比较高,因此需要调低TS与FS在损失函数中的占比从而让模型更关注动作本身的类别判断。
3 实验
本文使用THUMOS’14[6]与TVSeries[7]这2个数据集进行试验。出于控制变量的目的,为了与现有方法进行比较,按照现有的在线动作检测方法中提出的实验设置,将视频的FPS全部调整为24,之后再分别使用基于ActivityNet[17]数据集预训练的ResNet-200网络[18]与BNInception[19]网络来提取RGB特征与光流特征。在提取特征时,以6个连续帧作为一个单位,称为一个块(chunk)。其中RGB特征以6帧的中间帧作为输入,输出则为ResNet-200网络的Flatten_673层得到的输出,为一个2 048维的向量;而光流特征则以一个chunk作为输入,输出为BNInception网络的global_pool层所得到的输出,为一个1 024维的向量。之后这两者被分别传入LSTMRGB与LSTMFlow中来提取时序特征。
3.1 评价指标
在THUMOS’14数据集上,使用由Geest等提出的mean average precision(mAP)作为算法的评估指标
(11)
(12)
首先,在获得整个数据集的所有帧后,将其按照每个动作类别的概率进行降序排列。等式(11)中的TP(true positive)与FP(false positive)分别表示在第所有帧的第i个截断下的该动作类别的true positive与false positive的样本数量。基于等式(11)所计算得到的每一个截断i的精确率Prec(i),等式(12)计算了每一个动作类别k的平均精确度APk,其中Np表示该类别的所有正样本数量。当第i帧为正样本时1(i)=1,为负样本时1(i)=0。最后将所有类别的平均精确度进行平均,就得到mAP。
由于TVSeries数据集中背景帧的比例相对较高,因此TVSeries的评估指标与THUMOS’14的评估指标有所不同,为mcAP。mcAP为Geest等所提出[3],主要目标是为解决不同动作类别的正负样本比值不同所导致的AP难以比较的问题。其计算方式如下所示
(13)
(14)
其中:ω表示当前类别下所有负样本与正样本的比值,其用于平衡数据集中的正负样本比例。同样,最后将每个类别的cAPk进行平均来获得mcAP。
3.2 实验结果比较
表1中的第2列与第3列分别展示了本文的方法以及现有在线动作检测方法在THUMOS’14数据集与TVSeries数据集上的性能比较结果。除此之外,还对本文的2S-LSTM模型进行了一定的消融实验,探究每个损失函数对模型总体性能的影响。
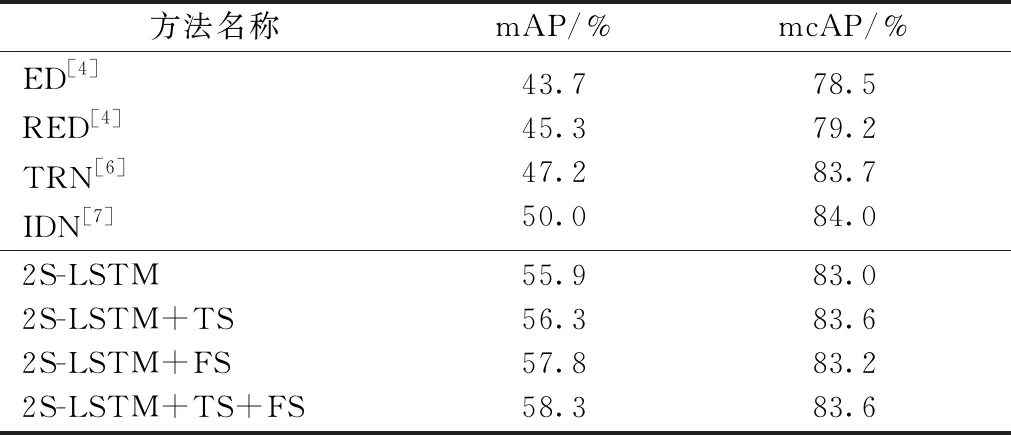
表1 THUMOS’14与TVSeries数据集下的实验结果
在THUMOS’14数据集上,本文的模型远远超出了过去最好的方法IDN的性能。即使没有增加光流稳定性以及时序相似性这2个损失函数,单纯的2S-LSTM模型也达到了54.8%的mAP性能。这充分说明本文所提出的双流LSTM模型对于提取视频的时序信息是十分有效的。而在加入FS与TS这2个损失函数之后,可以看到模型的性能都或多或少有了一定的提升。值得注意的是,当将2个损失函数同时用于模型上时,模型性能达到最佳状态,即55.9%mAP。这不仅说明我们所提出的基于自监督学习的损失函数对于性能的提升是有帮助的,更说明这2个损失函数是互补的,因此同时使用这两者会进一步提高模型的性能。
而在TVSeries数据集上,可以看出2S-LSTM的性能不尽如人意,哪怕是最好的时候也仅仅达到83.2%的mcAP,并不如之前的方法TRN与IDN的性能。我们猜测这是因为TVSeries数据集中的数据均为来自电视剧中的长视频,其包含大量的不变背景信息,从而导致模型学习了过多的有关背景的时序特征,导致模型对于动作的判别能力有所下降。为验证这一猜测,我们将2S-LSTM+TS+FS模型与IDN模型在TVSeries上每一个动作类别下的cAPk进行了比较,其结果如图3所示。
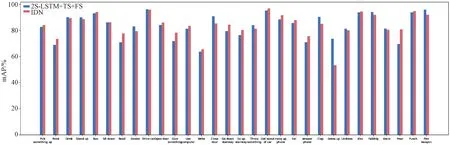
图3 2S-LSTM+TS+FS与IDN在TVSeries数据集上各个动作类别的性能比较
从图3可以看到,对于较容易判断的动作类别,例如Run(跑步)、Drive Car(开车)、Kiss(亲吻)等动作,这2个模型均取得了较好的结果,并且性能差异很小;而在Read(阅读)、Dress up(穿衣)、Pour(倾倒)这些较难判断的动作上,两者的性能出现了较大的差异,尤其是Dress up与Pour这2个动作,我们的模型在前者上的准确率要远高于IDN,模型,而IDN模型则在Pour动作类别上的准确率要远高于我们。针对这2个动作,我们对2S-LSTM+TS+FS与IDN在包含这2个动作的视频中的模型性能进行了可视化,如图4所示。
从图4(a)可以看到,在Dress up动作上,我们的模型相比IDN取得了更加理想的结果,在动作的开始部分和结束部分,2S-LSTM+TS+FS的概率曲线分别出现了明显的上升与下降,而IDN并没有很好地判断出Dress up动作,因此其概率曲线十分平缓。而在图4(b)图中,IDN模型要比我们的模型在Pour这个动作上的判别性能更好。值得注意的是,IDN模型并没有在动作的一开始就成功判断出该动作的类别,并且在动作的进行期间出现了大幅度的概率下滑的情况。结合视频的截图可以发现,在动作的开始阶段与动作的后半段,镜头中并没有出现“桶”这个明确的代表性物体,虽然动作已经开始或者正在进行,但是这会让模型误以为动作并没有开始或者已经结束。而在动作结束后的短时间内视频中又出现了“桶”这个物体,因此2个模型在Pour这一动作上的概率又出现了小幅度的上扬。从这个可视化结果中可以看到,模型对于不同类型的动作有不同的敏感度,并且模型对动作的判断性能极大地依赖于动作的复杂度以及具有代表性的物体是否出现。因此,如何保证模型在背景信息较多、动作复杂度较高且代表性物体消失的情况下更好地学习动作的时序特征并且降低对动作类别的敏感度是我们将来研究的重要方向。
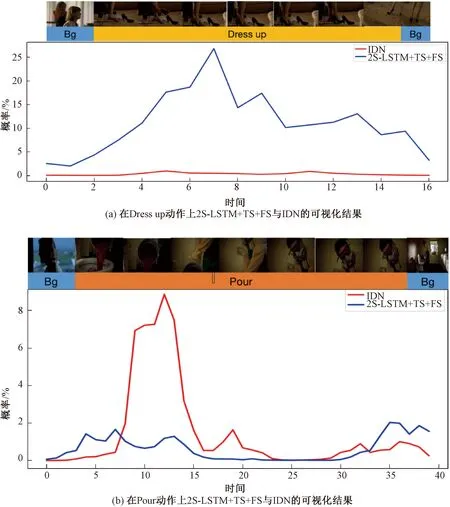
图4 2S-LSTM+TS+FS与IDN在TVSeries数据集上各个动作类别的性能比较
除与过去的方法进行比较之外,我们还对2S-LSTM本身进行了定量分析,并将其在视频上得到的动作概率进行了可视化,如图5所示。
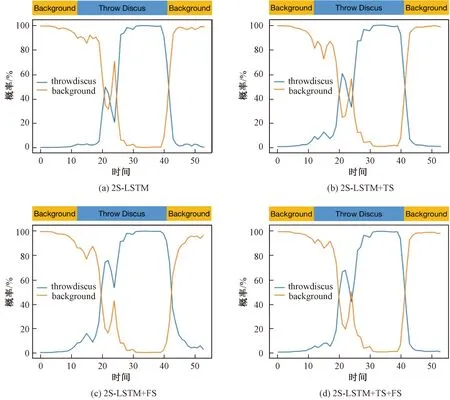
每个子图中上方的长方形条为标签,下方的图为模型计算出的动作类别的概率值
图5为2S-LSTM在THUMOS’14数据集中“Throw Discus(扔垃圾)”这个动作类别下的一段视频的检测结果。从图中可以看到,在背景与动作的交界处,单纯的2S-LSTM模型表现并不理想,其不仅没有立刻检测出动作的存在,甚至在动作的开始将背景误判为动作,造成了精确度的下降。而在分别加入时序相似度损失与光流稳定性损失后,模型可以更好地在动作的起始部分正确判断出动作类别,并且在动作的持续期间模型得出的概率曲线更加平稳。这充分说明本文所提出的自监督学习方法可以有效地提高模型对于动作的准确判断能力。值得注意的是,虽然TS与FS可以提高模型的检测能力,但是模型依旧并没有在动作的起始部分就立刻检测出“Throw Discus”这一动作。这说明在背景与动作的交界处,模型得到的时序特征并没有很好地将动作与背景区分开。因此,如何更好地通过特征的形式将背景特征与动作特征进行区分,就成为我们接下来的研究重点。
3.3 消融实验
除与之前的在线动作检测方法进行效果比较之外,我们还对2S-LSTM在THUMOS’14数据集上进行了消融实验,并将每一种模型的变种在所有动作上得到的AP进行了可视化,结果如图6所示。
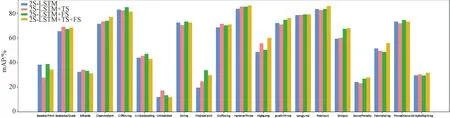
图6 2S-LSTM在THUMOS’14数据集的各个动作类别的消融实验结果
从图6可以看到,在给2S-LSTM增加了TS与FS这2个损失函数之后,模型并不是在所有类别的动作上都取得更好的效果,这也符合我们对模型性能的猜测。由于每一个动作的持续时间、复杂程度、变化剧烈程度都不尽相同并且这些动作类别下的视频呈现动作的方式也有很大的不同,从而导致模型学习这些动作的时候会出现性能上的差异。例如图中的HighJump(跳高)这一动作,可以发现TS与FS这两者对其性能增强的影响程度是不同的,其中TS对性能的提升要高于FS对性能的提升,并且当两者被同时使用时,2S-LSTM达到了更好的效果;而在BaseballPitch(投球)这一动作中,模型在加入TS损失函数后甚至相比起不加要损失很大的性能,而加入FS后有稍微的性能提升。我们认为这是因为投球这个动作相比起跳高的持续时间更短,且仅仅通过动作的表观信息难以判断动作的具体类别,其更加依赖光流来提供决定性的动作信息,因此FS相比TS在该动作类别上有更加关键的作用;而跳高这一动作持续时间相对较长,更要求模型对光流与RGB的时序特征之间的关系有更好的把控,因此TS要比FS更加关键。从这个消融实验可以得出结论,即对待不同的动作类别时,应该根据动作的大概信息来调整模型的参数,从而达到更好的性能效果。
4 结论
本文提出一种基于双流LSTM网络与自监督学习的在线动作检测算法。该算法基于LSTMRGB与LSTMFlow这2个网络分别生成RGB与光流的时序特征,从而更好地给2种模态的时序信息建模。除此之外,还将自监督学习的概念引入到在线动作检测问题中,并提出时序相似度损失与光流稳定性损失。本文在THUMOS’14与TVSeries数据集上分别进行了充分的实验,证明了所提出的模型对于解决该问题的有效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
小猕猴智力画刊(2022年3期)2022-03-28
少儿画王(3-6岁)(2020年4期)2020-09-13
导航定位与授时(2020年4期)2020-07-29
铁道建筑技术(2020年11期)2020-05-22
电子制作(2017年13期)2017-12-15
浙江大学学报(工学版)(2015年1期)2015-03-01
中北大学学报(自然科学版)(2014年3期)2014-11-22
