
基于AdaBoost改进随机森林和SVM的极化SAR地物分类*
2022-11-15 06:01张政李世强
中国科学院大学学报 2022年6期
张政,李世强
(1 中国科学院空天信息创新研究院, 北京 100190; 2 中国科学院大学电子电气与通信工程学院, 北京 100049)
合成孔径雷达(synthetic aperture radar, SAR)是一种高分辨率成像雷达,具备全天时、全天候、远距离观测目标的能力[1]。极化SAR(polarimetric SAR)是一种多通道多参数的SAR系统,与传统SAR系统相比可以获得更为丰富的目标散射特性[2],在图像分类方面具备一定优势[3]。
地物分类是遥感图像解译的关键问题之一,在环境监测、灾害评估、城市规划等方面有着广泛应用。随着大数据处理技术的发展,学者们开始尝试将机器学习等算法应用在SAR数据处理中。文献[4]用深度卷积神经网络(convolutional neural network, CNN)对极化SAR进行分类,可以得到较高的分类精度,但其依赖大量的有标记训练样本,在数据量较少时分类效果不佳,而在此情况下机器学习等传统算法表现通常优于深度卷积神经网络[5]。
一般来说,特征参数种类越丰富,所描述的地物目标信息便越全面,然而由于特征之间冗余度和相关性的存在,不加区分的特征叠加往往会导致过高的计算复杂度,而分类效果却提升有限,同时SAR图像的相干斑噪声也一直影响着分类精度。针对这些问题,文献[6]提出一种基于特征筛选的二级分类结构对建筑物进行提取,作者利用随机森林(random forest, RF)[7]对特征进行筛选,并得到初级分类结果,将筛选后的特征输入到支持向量机(support vector machine, SVM)[8]得到二级分类结果,两种结果融合后获得最终结果。该方法在建筑物提取上效果较好,但由于RF没有区分决策树的分类能力,所有决策树在分类时默认权重相同,而实际上决策树分类能力有所差异,对权重适当调整可以提升分类器的总体精度。因此陈伟民等[9]针对该问题提出一种基于自适应提升(adaptive boosting, AdaBoost)改进RF算法,并在高光谱图像分类上验证了该算法的有效性。
为提升极化SAR图像地物分类精度,减少相干斑噪声对分类的影响,本文设计了一种基于AdaBoost改进RF(adaBoost random forest, ADA_RF)和SVM的二级分类算法。该方法采用AdaBoost提升RF性能的方法[9],同时还引入了二级分类结构[6]。
该方法首先从极化SAR数据中提取特征数据集,利用分层采样法选取训练数据集和测试数据集,先得到ADA_RF分类器和特征重要性排名,再根据排名选择部分特征求出SVM的二级分类结果,通过邻域投票法融合两级结果,得出最终结果。
1 特征描述
在极化SAR图像的分析过程中常用极化散射矩阵S来描述地物的极化散射特性,S矩阵经过变换之后又可以得到极化协方差矩阵C和极化相干矩阵T。
(1)
(2)

(3)
式(2)和式(3)中:〈·〉表示集合平均,*表示共轭。在单站后向散射体制下,假定S满足互易性,即有SHV=SVH,因此通常定义极化SAR系统测量的散射总功率为
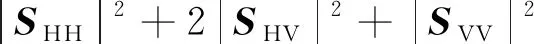
式中:Tr(·)表示求矩阵的迹,T作为上角标时表示转置。
不同的极化目标分解方法描述地物散射特性的角度不同。极化目标分解方法主要分为3种,分别是基于散射模型的分解方法、基于特征矢量或特征值分析的分解方法和相干分解方法[2]。基于散射模型的目标极化分解方法有Freeman-Durden分解、Yamaguchi分解等。基于特征矢量目标极化分解方法有Cloude-Pottier分解、 Holm分解和Van Zyl分解等。相干分解是将S矩阵分解为目标散射机制的组合,有Pauli分解和Krogager分解等方法。考虑到地物目标一般较为复杂,单一的分解方法难以适用于不同场景,故本文从3种分解方法中各选取了几个典型特征组成极化特征集合。
纹理是应用于遥感图像分类的典型特征。它通过灰度空间重复变化反映图像的灰度统计信息、空间分布信息和结构信息。纹理特征中的灰度共生矩阵和半方差矩阵是具有代表性的两个特征,前者是应用最为广泛的纹理描述方法之一,后者则能有效表示建筑区域的特征。因此本文选择灰度共生矩阵和半方差矩阵作为纹理特征集合。
综上所述,本文选取如表1所示的特征集合,分别是直接测量得到的极化数据、Yamaguchi分解特征[10]、Cloude-Pottier极化分解特征[11],还有灰度共生矩阵[12]和半方差函数[13]等纹理特征。

表1 特征集合
其中,直接测量得到的极化数据主要有极化散射总功率Span和极化相干矩阵的对角线元素T11,T22,T33。Span表示极化SAR系统的回波强度,T11代表目标对称因子,T22代表目标非对称因子,T33代表目标非规则因子。
Yamaguchi分解将地物目标散射分解成表面散射PS、二次散射PD、体散射PV和螺旋散射PH。螺旋散射信息PH的存在是Yamaguchi分解优于Freeman-Durden分解之处,该成分在具有复杂结构的目标或城区建筑中较为常见。
Cloude-Pottier分解参数包括极化熵H、散射角α与各向异性度A,它们都来自于相干矩阵T的分解,均有旋转不变性。极化熵H用来衡量散射过程的随机性,散射角α与平均物理散射机制密切相关,各向异性度A用来描述特征分解得到的第2、3个特征值的相对大小。
纹理特征选取灰度共生矩阵和半方差函数。灰度共生矩阵包含熵、对比度、同质性、均值4种特征,分别用符号ENT、CON、HOM、MEA表示。ENT描述图像信息量的随机性,CON反映图像灰度的局部差异,HOM体现图像局部均匀程度,MEA体现纹理的规则化程度。半方差函数V[14]描述像素与其邻域像素的空间相关性。将图像中的灰度值作为区域化变量,在以像素点为中心的邻域窗口内对0°、45°、90°、135°等4个方向的半方差函数取平均,最终得到中心像素的半方差纹理特征值。
2 分类方法
2.1 分类器
本文构建了由ADA_RF和SVM组成的二级分类结构。
AdaBoost是一种集成学习算法,它能根据分类器的性能赋予权重,得到分类器的加权组合,提升整体分类性能。具体来说便是根据各个分类器的分类正确率高低来分配权重,正确率高的获得高权重,低的则获得低权重。RF[7]是一种集成学习模型,决策树是它的基本分类器。它利用自助采样法随机采集样本组成子集,每个样本子集训练出一个决策树,多颗决策树组成随机森林。各个决策树通过简单投票法决定最终结果。
本文用AdaBoost算法调整随机森林中决策树的投票权重,分类能力越强权重越高,最后通过最大投票准则获得分类结果。AdaBoost算法是面向二分类的分类算法,因此本文采用“一对多”拆解法,将多类别分类问题转化为多个二分类问题。对像素分类时,每颗决策树单独给出分类结果,随机森林对投票结果加权统计,将得票最多的预测结果作为最终分类结果。
SVM是一种典型的有监督分类器[15]。它的基本思想是找到能够正确划分训练数据集并且间隔最大的超平面,该超平面要有足够间隔将离其最近的两类样本点分开,所以可将超平面的求解表示为一个凸二次优化问题
s.t.yi(wTxi+b)≥1,i=1,2,…,m.
其中:w为权重系数,b为位移项,(xi,yi)为样本集中的训练样本。SVM具有比较完备的数学理论支撑,但在大样本和高维度场景下计算效率不高。因此可以考虑利用随机森林的特征筛选功能,提前去除冗余特征,提高运行效率。
由ADA_RF和SVM得到的两级分类结果通过邻域投票法进行融合,其原理是当两级分类结果在像素点(i,j)处不同时,以该点为中心取一个宽度为d的正方形窗口,窗口中每个像素点都可以对分类结果进行投票,将中心像素的类别标记为得票最多的类别C
C=maxc(SUM(En(k,l)==c)),
c=1,2,3,…;n=1,2.

2.2 算法步骤
本文算法流程如图1所示。

图1 本文算法流程
步骤1输入极化SAR数据,进行预处理。
步骤2提取数据的极化和纹理特征,构成维度为M的原始特征参数集X。
步骤3分析极化SAR图像,查找或绘制地面真值图。利用分层采样法选取训练集和测试集。
步骤4通过输入训练数据集和标签到ADA_RF,使得随机森林的每个决策树都有各自的权重。用训练好的分类器对整幅图像进行预测,得到初级预测结果E1,同时得到各个特征的平均重要性排名V1。

步骤6利用筛选后的特征集合X训练SVM分类器,并对整幅图像进行预测,得到二级分类结果E2。
步骤7利用邻域投票法,将E1和E2进行融合,得到最终地物分类结果。
3 实验与分析
本文通过对AIRSAR采集自美国旧金山和荷兰弗莱福兰省的L波段极化数据进行分类实验,得到RF、SVM、ADA_RF和本文算法4种分类器的分类结果,通过对比来验证本文算法的有效性。
3.1 特征筛选
ADA_RF可以根据各个特征的贡献率得出重要性排名,作为特征筛选的依据。按照步骤5得到重要性排名,依次加入特征并记录精度的提升程度,得到图2所示的折线图。

图2 特征向量个数对分类精度的影响
根据图2确定两个实验的特征筛选个数N=10,即选择重要性排名前10的特征集,分别是Span,PS,PD,PV,PH,H,α,A,ENT,V。
3.2 分类对比实验
第1个对比试验利用的是美国旧金山海湾地区的数据。数据大小为900×1 024,PauliRGB图和地面真值图像如图3(a)、3(b)所示,其中地面真值图像的绘制参考了文献[16]和谷歌地图。将地物类别分为5类,分别是山地、海洋、城市、植被、有角度城市,城市对应的是普通建筑区域,有角度城市对应的是高层建筑区域。
在实验中,RF和ADA_RF的决策树各设置为200棵,SVM采用的是径向基函数核。训练和测试数据集通过分层采样法获得,二者比例为3∶7,最终分类效果如图3(c)~3(f)所示,分类精度与耗时数据如表2所示。

表2 旧金山地区数据的分类精度与耗时指标

图3 旧金山地区数据分类效果图
从分类效果和分类精度数据来看,本文算法的分类精度最高,达到92.72%。尤其是山地和城区的精度相比RF和SVM有较大提升。从分类效果看,本文算法得到的结果相比ADA_RF和SVM结果更加光滑连续,说明邻域投票法可有效抑制相干斑噪声。由图3(c)、3(d)可知,RF和SVM在区分城市建筑物高度问题上效果欠佳,而图3(e)、3(f)表明经过AdaBoost改进的随机森林可以更好地区分普通城区和高建筑物城区。在算法的耗时上,RF耗时最短,因为ADA_RF引入了决策树权重的计算,故相比于RF耗时有所增加,但本文算法的耗时小于ADA_RF和SVM耗时的直接加和,表明特征筛选在减少计算量上发挥了作用。
为进一步验证本文算法的有效性,选取Flevoland数据进行二次验证。数据大小为750×1 024,包含15类地物,图4(b)地面真值图像的绘制参考了文献[17]和谷歌地图。分类器中RF和ADA_RF的决策数仍然设为200棵,训练数据集和测试数据集通过分层采样获取,比例设置为3∶7。分类结果如图4所示,各项分类指标如表3所示。

表3 弗莱福兰地区数据的分类精度与耗时指标

图4 荷兰弗莱福兰地区数据分类图
从分类效果和分类精度上看,ADA_RF在分类精度上相比于RF和SVM有所提升,分别提升6.71和8.31个百分点。本文算法又在ADA_RF的基础上进一步提升了分类精度,达到94.68%。由此可以证明ADA_RF算法在提升分类精度上具有一定效果,经过邻域投票法之后可以有效抑制相干斑噪声,使得分类精度进一步提升。
4 结论
本文设计了一种基于ADA_RF和SVM的二级分类结构。通过对旧金山和弗莱福兰两个地区极化SAR数据的实验,结果表示本文所提算法的分类精度高于RF、SVM和ADA_RF。证明了本文算法的有效性,且ADA_RF算法能够根据RF中决策树的分类能力给决策树赋予权重,提升整体分类精度,证明特征筛选之后再训练SVM分类器能够减少计算量与时间消耗。证明通过邻域投票法将两级分类结果融合,能够在保持空间一致性的前提下抑制相干斑噪声的影响。
猜你喜欢
现代财经-天津财经大学学报(2022年5期)2022-06-01
航天电子对抗(2022年2期)2022-05-24
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
航天电子对抗(2019年4期)2019-06-02
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
