
Pre-locate net for object detection in high-resolution images
2022-11-13 07:29YunhaoZHANGTingbingXUZhenzhongWEI
CHINESE JOURNAL OF AERONAUTICS 2022年10期
Yunhao ZHANG, Tingbing XU, Zhenzhong WEI
Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, and the School of Instrumentation and Optoelectronic Engineering, Beihang University, Beijing 100083, China
KEYWORDS Aircraft and landing gear detection;Candidate region;Convolutional neural network;High resolution images;Small object
Abstract Small-object detection has long been a challenge. High-megapixel cameras are used to solve this problem in industries. However, current detectors are inefficient for high-resolution images. In this work, we propose a new module called Pre-Locate Net, which is a plug-and-play structure that can be combined with most popular detectors. We inspire the use of classification ideas to obtain candidate regions in images, greatly reducing the amount of calculation, and thus achieving rapid detection in high-resolution images.Pre-Locate Net mainly includes two parts,candidate region classification and behavior classification. Candidate region classification is used to obtain a candidate region,and behavior classification is used to estimate the scale of an object.Different follow-up processing is adopted according to different scales to balance the variance of the network input. Different from the popular candidate region generation method, we abandon the idea of regression of a bounding box and adopt the concept of classification, so as to realize the prediction of a candidate region in the shallow network.We build a high-resolution dataset of aircraft and landing gears covering complex scenes to verify the effectiveness of our method. Compared to state-of-the-art detectors (e.g., Guided Anchoring, Libra-RCNN, and FASF), our method achieves the best mAP of 94.5 on 1920 × 1080 images at 16.7 FPS.
1. Introduction
In recent years, computer vision technology has improved dramatically,1-10especially in regard to object detection.However, it is still difficult to detect small objects accurately.Moreover, in industrial applications, objects to be detected are often small.
Take an aircraft automatic tracking photography and measurement system as an example. The purposes of this system include object tracking, position and attitude measurement,and flight safety assurance. We obtain an aircraft’s images using turntables and cameras deployed on the ground and control a turntable to follow the aircraft through object detection and tracking technology. Simultaneously, we detect the landing gear status and calculate the aircraft attitude, which can guarantee the reliability of the landing gear and attitude stability of the aircraft during take-off and landing. Object detection, as a key part of this system, can provide an initial tracking region, provide the landing gear status, and reduce the amount of calculations needed for position and attitude measurements.Therefore,it is necessary to start detection even if the aircraft is far away and small in an image. To improve the accuracy of detection, we can use more detailed images with the use of higher-resolution cameras. However, higherresolution images increase the computational cost, which greatly increases the inference time (see Fig. 1).
Although all current mainstream object detectors have different detection strategies, such as one-stage11-18vs. twostage19-25and anchor-based14,15,26,27vs. anchor-free,16,28-33they all follow a holistic architecture,which includes inputting the entire image, calculating feature maps through the backbone network, and performing regression and classification on the feature maps. Different detectors may use different backbone networks,try new classification heads,or add image pyramids.However,there are two limitations with this design:
1) The input of the backbone network is the entire image,which takes up a large amount of computing resources.
2) A wide-scale change of the instance is negative for neural network learning.
Specifically,the first problem refers to the fact that the main computing architecture of the network deals with the entire image. Therefore, when detecting high-resolution images, the inference time will increase dramatically.The image resolution of the current dataset is low.The image size of the MS-COCO dataset is only approximately 640 × 500, and that of the VOC12 dataset is approximately 500×400.Taking RetinaNet as an example, we list Floating Point operations (FLOPs)when detecting images with different resolutions (see Fig. 1).When facing 1080P or larger images, the currently used detectors are already too ineffective to be used in practical projects.
The second problem means that when the instance scale in the dataset changes greatly, it is not conducive to network learning. This is because the features of large- and smallscale objects are different. Large-scale objects may contain more detailed information than that of small-scale objects,such as texture, but small-scale objects mostly contain edge information, so the optimization direction of the network is also different.In SNIP,34Singh and Davis proved that a model trained with large-scale instances gives poor results on smallscale validation sets. Therefore, regarding this point, limiting the scale of instances in a trainset is conducive to improving the detection accuracy of small objects.
To overcome the first problem,the usual solution is to find the region of interest in a high-resolution image. Different from the popular candidate region generation method, we abandon the idea of regression of a bounding box and adopt the concept of classification, so as to realize the prediction of a candidate region in the shallow network.We propose a novel Pre-Locate Net (PLN). As is known, features in deep layers have stronger semantic information than those in shallow layers, while features in shallow layers contain more information about edges and contours, which helps object localization.Therefore, we design a new architecture that uses several convolutional layers and fully connected layers to determine the approximate region of the instance;we then connect this image block to the subsequent convolutional network. We will show the details of this process in Section 3. Through this design, a large amount of calculation can be effectively reduced, as shown in Fig. 1.
To overcome the second problem,we also use classification ideas to estimate the scales of objects, and then balance the scales of the input objects of the network. Considering that the detection accuracy of large-scale objects is already very high and that the detection accuracy of small-scale objects is the main factor limiting the performance of a detector, we can downsample large-scale objects before training and inference. Additionally, because the judgment of object scales can depend on shallow feature maps, it is possible to predict the scales of objects while determining the approximate region.We will show the details of this process in Section 3.
We evaluate our Pre-Locate Net on a self-built airplane and landing gear dataset.The resolution of the images in this dataset is approximately 1920×1080.Compared with state-of-theart detectors,our method achieves competitive speed and accuracy results. Pre-Locate Net+RetinaNet achieves 94.5 Average Precision (AP) at a 50% overlap on 1920 × 1080 images in 60 ms on a 2080Ti GPU.
2. Related work
For the field of discriminative feature learning, the improvement of the network discriminative ability1-9,35-37is mainly focused on an increase in the number of convolutional layers of the network and a change of the network structure, as well as some improvement of the loss function. These works make it possible to use discriminative features to extract network regions of interest through classifiers.
In the field of object detection, some researchers12,33,38-47have discussed the differences in information contained in shallow to deep features. SSD12and MS-CNN43predict objects at multiple convolutional layers without combining features. HyperNet39and ParseNet40fuse features before predicting bounding boxes and scores. However, using shallow features alone is not enough.Lin et al.38proposed that features in deep layers have stronger semantic information than those in shallow layers,while features in shallow layers contain more information about edges and contours than those in deep layers. FPN38rebuilds a new feature map by upsampling and combining features from deep to shallow layers. TridentNet48notes the influences of different receptive fields on the detection of multiscale objects and proposes to add three branches with different receptive fields to detect large, medium, and small objects.
In addition, some special detection methods exist for small objects. VSSA-Net49proposes a vertical spatial sequence attention module that can obtain more contextual information than that of other methods, thereby improving the detection accuracy of small objects, especially traffic signs.Kisantal et al.50proposed a method of data augmentation by randomly copying and pasting instances on an image,thereby increasing the proportion of small instances in the image, to achieve a balanced detector for the detection of small and large objects. Li et al,51proposed using a GAN to improve the resolution of small instances to obtain detailed information and then detect new images. Li et al.52proposed a feature-intertwiner model to establish connections between different images and to use large objects to guide the learning of small objects.
The detection of high-resolution images is also a major challenge in the field of target detection. A usual solution is to find the region of interest in a high-resolution image to reduce the amount of calculation.For example,Zhang et al.53tried to detect airports in large-scale images firstly to reduce the overall aircraft detection time. In R2CNN, Pang et al.54proposed to use Tiny-Net to filter cut images, so as to retain the region of interest. However, the entire detector is divided into several pieces, the structure is complicated, and Tiny-Net needs to process each cut image, which has redundant calculations.
Current object detectors are mainly divided into two strategies: one-stage and two-stage. The former detectors11-18,28-30directly input an entire image to obtain final bounding boxes and scores. Although the speed of one-stage methods has advantages, when the resolutions of input images increase,the overall calculation amount will increase dramatically, so it is impossible to detect high-resolution images in real-time.The latter detectors19-25obtain region proposals and then regress the bounding boxes of the proposals. Usually, the improvement associated with using a two-stage method is based on increasing the accuracy of the proposal network of the region.21,26,45,55,56This strategy is likely to reduce the amount of calculations for high-resolution images; however,very accurate proposals require deeper layer support. Thus,this strategy cannot detect high-resolution images in real-time.sample large-scale instances,and how to apply PLN to current detectors.
3.1. Overall methodology
Our PLN is a plug-and-play module that can be combined with most popular detectors to improve the detection speed of high-resolution images. PLN mainly includes two parts,Candidate Region Classification(CRC)and Behavior Classification (BC). The former mainly uses the idea of classification to obtain the approximate candidate region of an instance,and the latter obtains the size of an instance in order to take different measures according to different sizes. For large objects, we downsample the original image features. For medium-sized objects, we crop the corresponding candidate regions on the original feature map. For small-scale objects,we perform PLN again in the candidate regions to further refine the subsequent regions. In this way, the amount of calculations required for the subsequent detection network is reduced,cutting of large objects is eliminated,and the variance of the input of the network is balanced.
3.2. Candidate region classification
To improve the detection speed, we use shallow features to roughly estimate the positions of instances. However, the anchor-based method will generate many candidate regions without the assistance of semantic information in deepfeature maps, and shallow features are not enough to support coordinate regression. Therefore, we introduce the concept of classification and divide an input image into nw·nhblocks.This problem is relative to the nw·nhclassification of the input image. If an instance is in the ith region, then the category of the instance is i.Before the image enters detectors,several convolutional layers and fully connected layers are used to determine the category of the instance(that is,to select a candidate region),and the candidate region is cropped and connected to the subsequent detection network. This step is called Candidate Region Classification (CRC).
If the resolution of the image is particularly high and the scale of the instance is very small, then to further improve the detection speed, we use the classification network again after isolating the candidate region. Therefore, another classification(recorded as c1)is performed to determine whether the candidate region classification needs to be performed again.If so,then the feature map corresponding to the candidate region
3. Pre-Locate Net
In order to solve the detection problem of small objects in a high-resolution image,we inspire the use of classification ideas to obtain candidate regions in the image. We design Pre-Locate Net using two new ideas: (A) we roughly locate instances using the concept of classification, select candidate regions, and then perform object detection; (B) we downsample large-scale instances before engaging the object detection network. Pre-Locate Net can be applied to most popular detectors, enabling fast object detection on high-resolution images. We apply Pre-Locate Net to RetinaNet14(see Fig. 2). In this section, we will describe how to improve the detection speed, how to reduce false negatives, how to downis adjusted to a fixed size according to the Region of Interest(ROI)and then passes through the candidate region classification network.Generally,candidate region classification is used no more than twice. Through this operation, the size of the high-resolution image fed into the detection network can actually be greatly reduced, a large number of subsequent calculations can be saved, and there is no loss of detection accuracy.
To further reduce the number of calculations,we design the first n layers of the candidate region classification network to be the same as the first n layers of the detection network.After CRC,the feature map corresponding to the candidate region is cropped and connected to the (n+1)th layer of the detection network.
To prove the effectiveness of our method in reducing the amount of computations,we design a comparative experiment.We use RetinaNet with ResNet 504as the backbone network.As shown in Fig.1,after the addition of Pre-Located Net,over half of the computations are obviated.
It is obvious that simply dividing the image will cause the instances cut off by the candidate region to be missed.To solve this problem, we divide the image into nw·nhblocks as candidate regions with an overlap rate of ξ.In this case,we can calculate the size of a candidate region(recorded as rwand rh)and the maximum size of an instance that will not be cut off(recorded as mwand mh, respectively) as follows:
rw·nw=W+ξ·rw(nw-1) (1)
where W and H reflect the size of the original image.
If there are multiple objects in an image, then we may obtain multiple candidate regions. We connect the feature maps of the candidate regions to the subsequent detection network in turn, combine all the detection results, and perform non-maximum suppression (nms) processing to obtain final results.
In fact, in R2CNN,54a crop method similar to CRC has been proposed. R2CNN actually cuts the image into blocks and then performs a two-class classification on each block to determine whether it contains an instance. Furthermore, the classification is a network independent of a detector. Our method does not need to initially perform real segmentation of the image, and the CRC module and the detector share the initial layer of the backbone network.
Next, we analyze the impacts of the values of nw, nh, and ξ on Pre-Locate Net.It can be seen from the formula that nw(or nh)and rw(or rh)are negatively correlated.Increasing rw(or rh)results in rougher candidate regions but increases the classification accuracy.Increasing ξ increases mw(or mh),but the detection accuracy decreases. Therefore, the design of these hyperparameters needs to be based on the sizes of the instances. In general, we can use nw(or nh) to control the size of the candidate region and use ξ to control the maximum size of the instance that will not be cut off.However,such a structure still cannot fully detect large objects,and we will solve this problem in Section 3.3.
3.3. Behavior classification
In Section 1, we have discussed that when the number of instances in a dataset changes greatly, it is not conducive to training a network. Therefore, we can naturally improve the detection accuracy of small objects by downsampling largescale instances.At the same time,it can also solve the problem of the inability to completely detect large objects, as discussed in Section 3.2.
Specifically, while classifying candidate regions, we can use a third classifier(labelled as c2)to determine whether an object in an image is a large-scale instance.If so,then the corresponding feature map is downsampled with a scale of (λdx,λdy) and then connected to the subsequent detection network. In fact,the operation of downsampling large-scale instances during training can be judged by the ground truth, but this module is added to the network largely for the following two reasons:
(1)The detector is not fed with large-scale instances during training, so during inference, downsampling should also be conducted on large-scale instances to prevent them from being missed.
(2)Large-scale instances may be cut off by candidate region classification during inference.
For convenience,we can replace c1 and c2 with a new classifier,called Behavior Classification(BC),with three categories describing three approaches:(A)crop the candidate region and preform CRC again, (B) crop the candidate region and connect it to the subsequent detection network,and(C)downsample the feature map and connect it to the subsequent detection network.These three categories are mutually exclusive.In fact,unless the object is very small and the image resolution is very high,we can only use the latter two operations to perform realtime detection.
In Fig.3,we show the final structure of Pre-Locate Net.We connect two sets of convolutional layers and pooling layers after the nth layer of the detector. The former convolutional layer uses a 1 ×1 kernel with 64 filters to fuse depth information. The latter uses a 7 × 7 kernel with 64 filters. We use ReLU to activate the feature maps. Then, we connect an ROI pooling layer to adjust the feature maps to a fixed size.Finally,we connect a fully connected layer with an output size of nw·nh+3,where nw·nhis used for candidate region classification, and the rest are used for behavior classification. In Fig. 3, We provide different operations when detecting three different-scale objects. Red arrows represent the operation when detecting a large-scale object after Pre-Locate Net; PNis downsampled. Blue arrows represent the operation when detecting a medium-scale object. After Pre-Locate Net, we crop PNaccording to the predicted value of CRC. Green arrows represent the operation when detecting a small-scale object. After Pre-Locate Net, we crop PNand connect it to Pre-Locate Net again.
3.4. Ground truth and loss
It should be noted that for an image, if there are multiple objects, then there may be multiple kc. At this time, candidate region classification is similar to a multilabel classification problem. However, the value of bcis only one; that is, only the largest instance in the image is considered.
Because the feature maps are cropped,the bounding box of each instance must also be aligned.We give the coordinate formulae of the new bounding box as
3.5. How to apply PLN to current detectors
In theory, Pre-Locate Net can be applied to most contemporary detectors. We take RetinaNet as an example to explain how to use Pre-Locate Net.
The network architecture is shown in Fig. 3. We connect Pre-Locate Net after the nth layer of RetinaNet. The feature map of the nth layer is recorded as PN. In Pre-Locate Net,we perform different operations on PNbased on the CRC and BC results, including cropping the candidate region and CRC again, cropping the candidate region on PN, or downsampling the feature map PN. After doing so, we obtain the corresponding feature map P′N and then connect it to the n+1th layer of RetinaNet. The remaining architecture is the same as RetinaNet.
4. Experiments
In this section, we present the details of training Pre-Locate Net and experimental results. Compared to the baseline and state-of-the-art methods, our method Pre-Locate Net+RetinaNet achieves competitive performance in terms of accuracy and speed. Unless otherwise specified, all experiments are performed on an airplane and landing gear detection dataset(recorded as ALD).
4.1. Airplane and landing gear detection dataset
To evaluate our method, we build a high-resolution Aircraft and Landing gear Detection dataset(ALD).The dataset comes from our aircraft automatic tracking photography and measurement system, which samples cached video to obtain aircraft images. Considering the feature distribution of the dataset, appropriate images should be selected when the dataset is produced. When aircraft are far away, the instances are small, but the shapes of aircraft are mostly the same. Such a data distribution is not conducive to model learning.Similarly,large amounts of blue-sky backgrounds are not conducive to model training. Therefore, we must consider the complexity of the aircraft scale, shape, model, and background. Several ALD images are shown in Fig.5,which including different aircraft and landing gear sizes and different weather conditions.For a more intuitive display, aircraft are marked with a red frame.
Specifically, the ALD includes a total of 3775 images and more than 12000 instances. These images are split into three subsets: a train set, a validation set, and a test set, which contain 3000, 200, and 575 images, respectively. The sizes of the instances range from 5 pixels to 1527 pixels. The resolution of the images in the ALD is approximately 1920×1080 pixels.Aircraft appear in the images with different shapes,at different positions, and with different sizes, while landing gears can be stowed or lowered.
We compare our ALD to other famous object detection datasets.
VOC: VOC is one well-known dataset for use in object detection tasks. PASCAL VOC Challenges were held once a year from 2005 to 2012,and the most commonly used datasets at present are VOC07 and VOC12. Both datasets have 20 object categories.The former contains more than 5000 images and 12,000 instances,and the latter contains more than 11,000 images and 27,000 target instances.The resolutions of most of the images in VOC are lower than 600×600,and the proportion of small-scale instances is small.
COCO: COCO is used for object detection, segmentation,and captioning, and it is currently a well-known dataset for comparing the performances of general detectors with stateof-the-art methods. COCO has 80 object categories and more than 140000 images,which are usually split into a trainval set,a minival set, and a test set. The trainval set has more than 115000 images, the minival set has 5000 images, and the test set has 20000 images.The resolutions of most images in COCO are lower than 700 × 700.
DFGTSD: The DFG Traffic Sign Dataset is provided by DFG Consulting d.o.o. A total of 6758 images with a resolution of 1920×1080 and 199 images with a resolution of 720 × 576 are included. These images are split into two subsets: a train set and a test set, which contain 5254 and 1703 images, respectively. DFGTSD contains more than 17000 instances, of which 4359 instances are smaller than 30 pixels.The dataset includes 200 different traffic sign categories, and each category includes at least 20 instances.
We show the object scale distribution of the ALD and several commonly used datasets in Fig. 6. In this figure, CDF means cumulative distribution function of the object scale,which reflects the proportion of objects in the dataset,and Relative scale means the ratio of an instance’s scale to the image size.
We can see that the scale of the instances in the ALD is smaller than those in COCO, VOC, and ImageNet.
4.2. Training details
Because the former N layers of RetinaNet and Pre-Locate Net share parameters, similar to a two-stage detector, we cannot train Pre-Locate Net and RetinaNet separately. Here, we describe two training strategies.
(1) Firstly, the first N layers of RetinaNet are combined with Pre-Locate Net and are trained with the loss function of Pre-Locate Net. Then, these parameters are frozen, and the subsequent detection network is connected. Finally, training is performed with the loss function of RetinaNet.
(2) The second strategy starts by training RetinaNet separately; then, its first N layers are combined with Pre-Locate Net. The parameters of RetinaNet are frozen, and Pre-Locate Net is trained. Finally, a complete detector is built and used to fine-tune the loss of RetinaNet.
In this paper, we adopt the second strategy. Unless otherwise specified, we use ResNet-50 as our backbone network,and the hyperparameters are the same as those for RetinaNet.Our backbone networks are initialized with the weights pretrained on ImageNet, and the rest of the parameters of Pre-Locate Net are initialized as described in Ref.57.When training RetinaNet, the input image is resized to 960×540. The model is trained for 12 epochs with SGD,with an initial learning rate of 0.01 and a 10-fold reduction at the 7th epoch. A weight decay of 0.0001 and a momentum of 0.9 are used. To improve the detection accuracy,we use the k-means algorithm to obtain five preset anchors before training. When training Pre-Locate Net, we connect it after the first 11 layers of RetinaNet.This time,we keep the original image resolution,which is approximately 1920×1080. Pre-Locate Net is trained for 30 epochs.The optimizer uses Adam,with an initial learning rate of 0.001 and a 10-fold reduction at the 12th and 20th epochs.Finally, during fine-tuning, we connect the rest of RetinaNet after Pre-Locate Net and use the loss of RetinaNet for training with the original resolution image.
It should be noted that in the final fine-tuning, the bounding box of each instance should be aligned according to Eqs. (7), (8), (9), and (10). The CRC and BC values in the kband kcequations should be taken as the labels, not the predicted values of Pre-Locate Net. This is mainly to prevent a generation of erroneous candidate regions based on erroneous prediction values of Pre-Locate Net, where they might adversely affect the detection network.
4.3. Testing details
Our method can run end-to-end inference well. When testing,our method produces a predicted box of the object in the candidate region by the detection network.Then,according to the predicted values for ykband ykcof Pre-Locate Net,it deduces a predicted box of the object in the original high-resolution image.
4.4. Ablation study
To verify the effectiveness of our method,we give the details of the analysis in two respects: (A) necessity of candidate region classification and (B) necessity of behavior classification.
4.4.1. Necessity of candidate region classification
As we mentioned in Section 1, current detectors fail to detect high-resolution images in real-time because of the number of calculations required for an entire image.Through experimentation, we have found that this problem is well solved by candidate region classification. Our method completes detection on 1920×1080 resolution images with a 94.5 AP score at 16.7 FPS.
The biggest concern raised by our method is the accuracy of candidate region classification because using the wrong candidate region will lead to missing instances in the new feature mapand cannot generate correct prediction boxes. Therefore,we perform experiments to find the most suitable network architecture.
The CRC module contains a total of 4 parameters: nw, nh,ξ,and N,of which the first three are used to control the size of the candidate region,and N is the position of the CRC module inserted into the backbone network.To compare the influences of different parameters on the accuracy and speed of the CRC module and verify its effectiveness,we choose RetinaNet without Pre-Locate Net as the baseline.
nw,nh,and ξ have the same effects on controlling the size of the candidate region.However,to ensure that mwand mh(i.e.,the size of the instance that can be completely detected) are large enough,we set ξ to 0.5 and control the size of the candidate region through nwand nh. As shown in Table 1, when nw×nhhas values of 3×3, 4×4, 5×5, and 6×6, the classi-fication accuracies of the CRC module are 97.5%, 95.6%,93.4%, and 92.7%, respectively, and the average inference times are 4 ms, 4 ms, 5 ms, and 6 ms, respectively. Note that an incorrect prediction of the CRC module does not necessarily generate a wrong candidate region. As shown in Fig. 7,both 3 and 6 can produce correct candidate regions that completely contain the instance. Although the ground truth of CRC is 3, a value of 6 can also produce the correct candidate region. In general, a larger

Table 1 Performance of our CRC module under different numbers of candidate regions.
nw×nhwill produce smaller candidate regions, thereby reducing the amount of calculations, but will also decrease the classification accuracy of the CRC module. Therefore,for images with different resolutions,a different nw×nhshould be selected. For our ALD, we take nw×nhas 3×3.
We compare the effect of inserting the CRC module at different positions of ResNet50 on the detection accuracy and speed, as shown in Table 2. For a faster detection speed, we take N as 11, which means inserting the CRC module after stage one of ResNet50.
As shown in Table 3, we compare these models on the ALD. The AP of small objects (recorded as APS) of our baseline is 69.9;after inserting the CRC module,the APSincreases to 92.5.If the baseline detects original-resolution images, then the detection speed will be 113 ms,but after inserting the CRC module,we can detect original-resolution images at a speed of 60 ms. These experiments have proven the validity and necessity of our CRC module.
4.4.2. Necessity of behavior classification
Behavior classification performs two functions: (A) downsampling large-scale instances and(B)classifying candidate regions again for small-scale instances.The former aims to restrict the input of large-scale instances to improve the detection AP of small objects, and the latter reduces the area of the candidate region to reduce the inference time.
We use RetinaNet as our baseline and compare the effects of two BC modules:(A)BC3retains S,M,and L as the three categories and (B) BC2abandons the classifying candidate region for a small instance (i.e., label S is equivalent to label M). As shown in Table 4, the classification accuracy of BC3is 0.943 and that of BC2is 0.972. Considering the resolution of our ALD is approximately 1920×1080, it is not necessary to reduce the area of the candidate region, so we choose BC2as the final BC module.
After inserting the BC module, the detector has a small increase of APS,as shown in Table 5,while the detection effectiveness of large objects is significantly improved. APLincreases from 74.0 to 95.2. These experiments have proven the effectiveness of our BC module in improving the detection accuracy.
4.5. Comparison to state-of-the-art detectors
We evaluate our method on the ALD as well as the DFGTSD and compare its performance with those of state-of-the-art detectors.
We select four one-stage methods and three two-stage methods:(A)one-stage:RetinaNet,FCOS,Guided anchoring,and YOLOv3;(B)two-stage:Faster-RCNN,Cascade-RCNN,and Libra-faster-RCNN. Among them, RetinaNet is also the baseline of our method. Guided anchoring uses RetinaNet as the basic network. All the methods use ResNet50 as the backbone network and use fpn to merge feature maps of different layers. Our final detector is Pre-Locate Net combined with RetinaNet. We also use ResNet50 as the backbone network and use the same hyper-parameters as those of RetinaNet.For Pre-Locate Net, the hyper-parameters for setting the CRC module are as follows: nw=3, nh=3, ξ=0.5, and λBC=1. The BC module uses BC2. To more intuitively show the advantages of our method in terms of accuracy and speed,we train two models with different image resolutions for each SOTA method.
As shown in Table 6,our method achieves the best mAP at 94.5, mainly due to the improvement of APS. However, our method does not achieve the best APL, which may be caused by the few classification errors in the BC module. If we consider a speed and accuracy trade-off, then our method can detect an image with a resolution of 1920×1080 at a speed of 60 ms. Both the speed and accuracy of our method are better than those of Cascade-RCNN and GA+RetinaNet at a 960×540 input image resolution. If these SOTA methods use test images with a resolution of 608×342, then their detection speed has advantages over our method,but the detection accuracy will be much lower than that of our method.Fig.8 shows the P-R curves of our method for the aircraft and landing gear categories and compares these results to those of SOTA methods. Fig. 8(a) is precision-recall curve of the aircraft category.SOTA methods use 608×342 as the test image resolution.Fig.8(b)is precision-recall curve of the landing gear category.SOTA methods use 608×342 as the test image resolution.Fig. 8(c) is precision-recall curve of the aircraft category.SOTA methods use 960×540 as the test image resolution.Fig.8(d)is precision-recall curve of the landing gear category.SOTA methods use 960×540 as the test image resolution.

Table 2 Performance of our CRC module under different insertion positions N . All experiments are performed on ALD.

Table 3 Performance of our CRC module compared with baseline on ALD. In order to reflect the speed advantage of our method under the same accuracy, we give the baseline performance when inputting images with different resolutions.

Table 4 Performance of our CRC module under different BC modules. BC module is connected after the C2 layer of ResNet50. All experiments are performed on ALD.
To intuitively explain the reason why our Pre-Locate Net shows these improvements, we give APSand APLfor each method, as listed in Table 6. Our method shows a great improvement on APScompared to those of the other methods;in particular, it has improved from 69.9 to 92.7 relative to the baseline. These results are also in line with our original design intention. For an instance with a small scale in a highresolution image, detailed information will be lost due to downsampling, which causes failure in detection. However,our Pre-Locate Net avoids the loss of information caused by downsampling by cropping the feature map.
Fig.9 shows some qualitative detection results of six different detectors.Green boxes denote true positives.Yellow boxes denote false positives. Red boxes denote false negatives. We can see that when the scale of an object is large, all the detectors achieve similar results. However, when detecting small objects, there are some false negatives in the results of Cascade-RCNN, Libra-faster-RCNN, FCOS, and GA+RetinaNet as well as some false positives in the results of Libra-RCNN and RetinaNet. Only our method can correctly detect small objects as well as large objects.
To further verify the effectiveness of our method combined with other SOTA detectors,we present the detection results of Pre-Locate Net + FCOS and Pre-Locate Net + GA + Reti naNet on the ALD in Table 7. It can be seen that each experiment has obtained excellent experimental results, especially compared to the baseline in Table 6.
To prove the detection ability of our method for multiobject images,we choose the DFGTSD for testing,which also contains high-resolution images,and each image contains multiple randomly distributed traffic-sign objects. We still selectthe six SOTA detectors used in the previous section for comparative experiments, and we show the detection results for small and large objects.

Table 5 Effectiveness experiments for our CRC module. All experiments are performed on ALD. All methods use ResNet50 as backbone network.
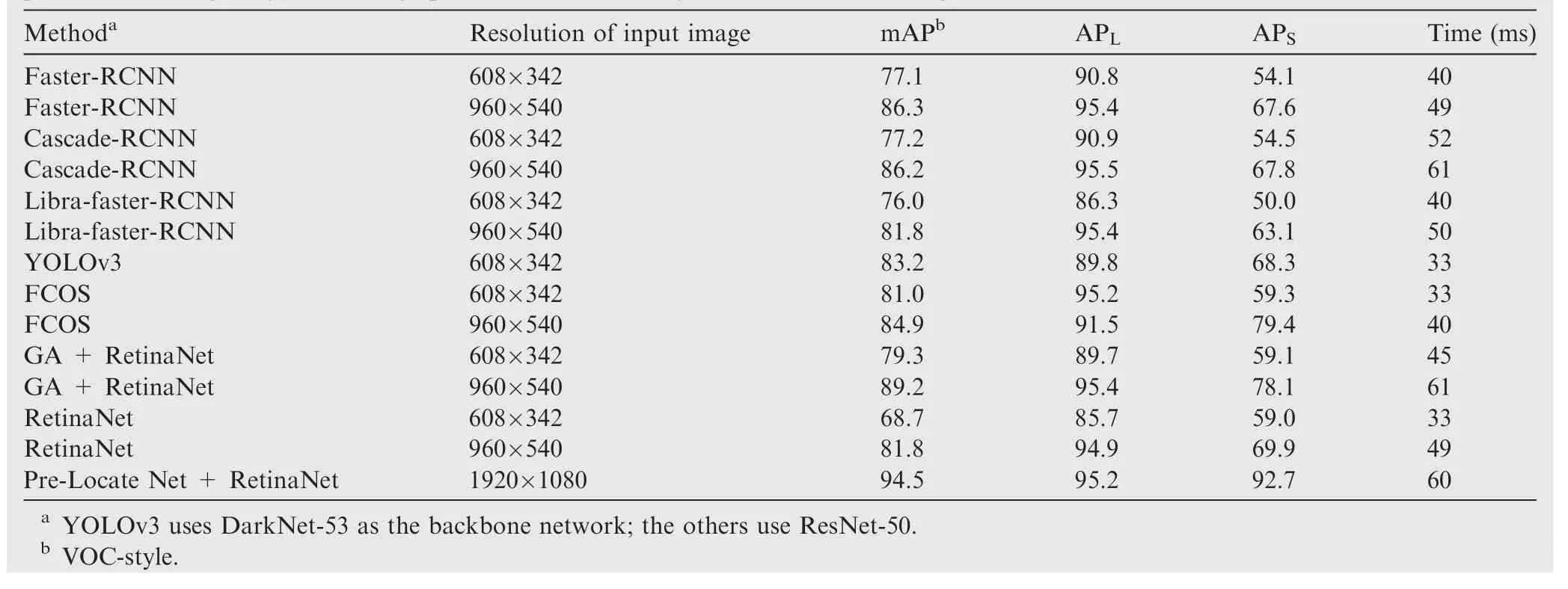
Table 6 Comparison with some state-of-the-art methods.All experiments are performed on ALD.Mean average precisions,average precisions of large objects, average precisions of small objects, and runtime are given.
It can be seen from Table 8 that our method shows a great improvement in the accuracy of small object detection compared to those of other methods, especially compared to that of the baseline. However, the detection accuracy of large objects is slightly reduced; this is due to the incorrect classification of candidate regions, which leads to the loss of some instances. Overall, our method has made good progress in the detection of sparse small objects in high-resolution images.

Table 7 mAP of PLN + SOTA detectors. All experiments are performed on ALD. Mean average precisions, average precisions of large objects, average precisions of small objects, and runtime are given.

Table 8 Comparison with some state-of-the-art methods. All experiments are performed on DFGTSD. Mean average precisions,average precisions of large objects, and average precisions of small objects are given.
5. Conclusions
In this paper,we inspire the use of classification ideas to obtain candidate regions in images, reducing the amount of calculation, and thus achieving rapid detection of objects in highresolution images. Our method mainly includes two ideas:(A) for small objects, we obtain a rough candidate region through a shallow network, thereby saving a large amount of computation time,and(B)for large objects,we downsample to prevent false negatives,and improve the detection accuracy for small objects. In order to allow the network to implement automatic decision-making on these two operations, we use two classification modules, i.e., CRC and BC. CRC is used to obtain the ID of the candidate region, and BC is used to obtain the sizes of the objects in the image.In order to further reduce the amount of calculation, we share the parameters in the first layers of the candidate region classification network with the first layers of the detection network. Our Pre-Locate Net can be combined with most popular detectors to achieve fast detection in high-resolution images. Compared to the baseline and other state-of-the-art detectors, our method achieves a competitive accuracy and an improved speed on high-resolution images. In future work, we intend to extend our method to detect dense objects in high-resolution images.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This article was funded by the National Science Fund for Distinguished Young Scholars of China (No. 51625501) and the Aeronautical Science Foundation of China (No.201946051002).
 CHINESE JOURNAL OF AERONAUTICS2022年10期
CHINESE JOURNAL OF AERONAUTICS2022年10期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Full mode flight dynamics modelling and control of stopped-rotor UAV
- Effect of baffle injectors on the first-order tangential acoustic mode in a cylindrical combustor
- Experimental study of hysteresis and catastrophe in a cavity-based scramjet combustor
- Flow control of double bypass variable cycle engine in modal transition
- Effects of chemical energy accommodation on nonequilibrium flow and heat transfer to a catalytic wall
- A reduced order model for coupled mode cascade flutter analysis