
Prior-guided GAN-based interactive airplane engine damage image augmentation method
2022-11-13 07:29RuiHUANGBokunDUANYuxiangZHANGWeiFAN
CHINESE JOURNAL OF AERONAUTICS 2022年10期
Rui HUANG, Bokun DUAN, Yuxiang ZHANG, Wei FAN
School of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China
KEYWORDS Airplane engine;Damage detection;Data augmentation;GAN;Interactive
Abstract Deep learning-based methods have achieved remarkable success in object detection, but this success requires the availability of a large number of training images.Collecting sufficient training images is difficult in detecting damages of airplane engines.Directly augmenting images by rotation, flipping, and random cropping cannot further improve the generalization ability of existing deep models. We propose an interactive augmentation method for airplane engine damage images using a prior-guided GAN to augment training images. Our method can generate many types of damages on arbitrary image regions according to the strokes of users.The proposed model consists of a prior network and a GAN.The Prior network generates a shape prior vector,which is used to encode the information of user strokes. The GAN takes the shape prior vector and random noise vectors to generate candidate damages. Final damages are pasted on the given positions of background images with an improved Poisson fusion. We compare the proposed method with traditional data augmentation methods by training airplane engine damage detectors with state-ofthe-art object detectors, namely, Mask R-CNN, SSD, and YOLO v5. Experimental results show that training with images generated by our proposed data augmentation method achieves a better detection performance than that by traditional data augmentation methods.
1. Introduction
The quality and quantity of the available training data are important for modern deep learning-based methods. Given the huge number of ImageNet images, deep learning methods(e.g., VGG1and ResNet2) achieve state-of-the-art performances in image classification. However, collecting sufficient training images to train a deep damage detector is difficult in detecting damages of airplane engines.3
Various data augmentation methods have been proposed to increase the number of training images artificially for attaining satisfactory performance. One kind of data augmentation technique is based on different transformations, such as geometric transformation,4,5color transformation,6random cropping,7,8random erasure,9and neural style transfer.10,11Although this kind of methods can extend training images, it only changes appearances and positions of targets,and cannot generate novel targets. Another kind of data augmentation technique is based on synthesis,such as image mixing,12-14feature space enhancement15, and images generated by Generative Adversarial Networks (GANs).16-19This kind of methods can generate targets according to a given dataset.However,the quality of targets is poor,which makes generated images easily distinguishable from real images. Previous work20has proven that generated targets need to match image context, or they might hurt detection performance.
Fig. 1 shows examples of augmented airplane engine damage images by traditional and our proposed data augmentation methods.Fig.1(a)is a real damage image.The ellipses in Fig.1(b) are generated cracks using the proposed method. Fig. 1(c)is the label of Fig.1(b).Figs.1(d),1(e),and 1(f)are augmented images generated by traditional methods. Only one crack is present in the original image, which occupies a small ratio of the entire image pixels. Traditional data augmentation methods, such as random rotation, color dithering, and cropping,only change image appearance and viewpoint. The essential facts for the generalization ability of a deep learning-based damage detector are the diversity of damages (i.e., quality)and the number of damages (i.e., quantity).21
In this study, we aim to generate high-quality damages in health regions to increase the number of damages.We propose an interactive data augmentation method for airplane engine damage images using a prior-guided GAN. A simple stroke can be drawn, and our proposed method can generate several candidate damages that match the stroke and context of images. To achieve this goal, we firstly train a generator with random noise as input and an artificial damage image as output, which can be formulated as a generative and adversarial process. Then, we fix the generator to train a prior network for encoding a user stroke into a shape prior vector with a fixed length. We add random noises with the shape prior vector to improve the randomness of the damage. Finally, the generated damage is pasted on the background by our improved Poisson fusion to obtain natural transition at the boundary of the damage. Our method generates a damage label by adjustable labeling, which can alleviate human labeling. After completing training of the generator and the shape prior network, we build an interactive system to facilitate a user to draw a stroke and control the threshold of adjustable label generation. We verify the proposed method on airplane engine image damage detection. Compared with traditional data augmentation methods, the proposed method not only generates high-quality damages but also boosts the detection performance of Mask R-CNN,22SSD,7and YOLO v5.23The contributions are three-fold:
(1) We propose an interactive data augmentation method for airplane engine damage images, which uses simple user interaction and generates artificial damages that are close to real damages. The augmented data can improve the performance of modern object detectors in airplane engine damage detection.
(2) The proposed method can encode a user stroke into a shape prior vector, which facilitates the damage generator to generate a damage image that matches the shape of the user stroke. We also add random noises with a shape prior vector to increase the diversity of the damage.
(3) The proposed adjustable label generation can generate high-quality labels of damage images and control the final shape of the damage. Improved Poisson fusion is used to ensure natural transition at the boundaries of the damage, which makes an augmented damage image look like a real image.
2. Related work
Data augmentation is an essential step in training deep learning models, and corresponding methods can be classified into transformation and generative methods. Transformation methods use different image transformations to increase the number of images. Generative methods try to generate synthetic images.
2.1. Transformation methods
Most deep learning-based classifiers and detectors utilize transformation-based methods,such as geometric transformations,4,5to conduct flipping,cropping,translation,scaling,and rotation for achieving translation, scale, and rotation invariance. Several basic transformations can be combined, for example, cropping after translation or rotation. Apart from geometric transformations, appearance transformations change the appearances of images to mimic images captured with different lighting conditions, under the pollution of noise or blur.6Moreno-Barea et al.24tested different noise injection methods and found that adding noise to images could make Convolutional Neural Networks (CNNs) learn more robust features. Kang et al.25used filters to blur image patches and proposed a patch shuffle regularization, which decreased the classification error rate from 6.33% to 5.66% on CIFAR-10.
Transformation-based data augmentation methods are easy to implement. They have been introduced into nearly all deep learning-based classification, detection, and segmentation problems to improve the generalization ability of models.However, transformation-based methods cannot solve the problem of data unbalance and scarcity fundamentally.
2.2. Generative methods
Recent studies have focused on synthesizing images by random erasing,9Cutout,26Mixup,12Cutmix,14Augmix,13and style transfer10,11to ensure enriched data diversity for existing training data. DeVries et al.26randomly cut out image regions to simulate occlusion for increasing the robustness of models on occluded objects. Zhong et al.9erased a rectangular area to increase the difficulty of data to force a network handle partially occluded objects. However, neither cutout nor erasing keeps the balance between deleted information and retained information. Thus, a structured drop operation was proposed by Chen et al.,27and this operation deletes multiple evenlydistributed small square regions and controls data balance by density and size parameters. Different from Cutout,Mixup12merges two images by a certain ratio to generate a new image.The representative work,CutMix,14adopts a local fusion idea and fills cutout regions with pixels of another image.Hendrycks et al.13proposed Augmix that fused an original image with a transformed image according to a certain ratio. Dwibedi et al.28randomly combined foreground and background images to increase a training image set. Kisantal et al.29used different methods to copy and paste small targets for improving the performance of small-target detection.Random combinations may result in unrealistic images, which leads to unpredictable results for object detection.20
Style transfer has been studied in data augmentation areas.10,30Shen et al.11proposed a transfer network, which could transfer an image into some given styles to increase image diversity. Some researchers used a GAN to generate novel images for augmenting training images.31,32,33Motamed and Khalvati34proposed a semi-supervised augmentation of chest X-rays by a novel GAN with inception and residual blocks. Gurumurthy et al.35trained a GAN by reparameterizing a latent generative space as parameters of mixture and learning a mixture model with limited data. Georgakis et al.36augmented some hand-labeled training data with synthetic examples carefully composed onto scenes. Automatic data enhancement technologies37,38automatically learned optimization strategies from data and searched for appropriate augmentation strategies.
The most related work to our method was proposed by Lahiri et al.,39which used a prior network to build a relation between noise and a masked image. Then, a GAN took the generated noise to produce an inpainted image. Four differences have been observed: (A) our method is an interactive data augmentation method, while a prior-guided GAN39aims at inpainting; (B) we use a prior network to encode user strokes and random noise to increase damage diversity, while a prior-guided GAN39utilizes a prior network to encode contents of a masked image; (C) we use l2distance of convolutional features to train a prior network, while a prior-guided GAN39adopts l2distance of image pixels; (D) our method adopts improved Poisson fusion to fuse generated damages with background images,while a prior-guided GAN39directly complements the contents of a masked region.
3. Proposed method
We aim to generate a novel damage on an existing airplane engine image with a user stroke and a damage type.Two questions need to be answered.The first question is the way to generate a damage with a given damage type, and the second question is how to encode a user stroke. We encode a user stroke into a shape prior vector with a prior network (i.e., P)and generate a damage with a generative network (i.e., G) in this work. Fig. 2 shows the framework of our proposed interactive data augmentation method.
3.1. Damage generation
3.1.1. Generative network
We assume that a generator G(z) could produce damages that are similar to real damages by taking a random noise z. The training process of G is the same as that proposed in a GAN,40that is,alternatively training a generator G and a discriminator D. G is a counterfeiter, which produces a fake image to fool D.Meanwhile, D is a judge, which distinguishes the fake image from the real image.The generator and the discriminator play a two-player min-max game with the following objective function:
3.1.2. Prior network
Although G can learn the distributions of damages, it cannot generate damages with user-wanted shapes. We propose to learn a prior network P to generate a shape prior vector p with a user stroke Ishapeby Eq.(2)for enabling G to generate a damage with a specified shape.
where θPdenotes the parameters of the prior network. The shape prior vector p encodes the shape information of the user stroke.
A pre-trained generator G can generate a damage having a similar shape to a user stroke base on p. Let x′denote a generated damage by G(p) and y a real damage. Ishapecan be extracted from y.The distance between x′and y should be sufficiently small to ensure that x′is like y. Thus, it forces the prior network P to encode the shape information of Ishapeand generate a shape prior vector p. We extract features of the fourth convolutional layers of AlexNet,41Fx′and Fyfrom x′and y,respectively.l2distance between Fx′and Fyis used to evaluate the similarity between x′and y. The optimization of the prior network P can be obtained by
where N is the number of training image pairs.
3.1.3. Training policy The proposed model has a generative network G and a shape prior network P.Directly training the whole model is difficult.Thus, we adopt three stages to train the proposed model. We train G in the first stage. Then we train P after G has converged.Fig.3 shows the training process of the first and second stages. We firstly train G to generate a damage by inputting random noise in the first stage. Then we train P by fixing G to force P to encode user stroke information into a shape prior vector in the second stage. Finally, we joint-tune P and G to optimize the whole model in an end-to-end manner.
(1) Training G. Directly training all types of damage in a single generator produces a confused damage image.We train each type of damage alone to obtain a highquality damage. DCGAN42is used to train the damage generator G. The training setup is the same as that proposed in DCGAN.42
(2) Training P. After G is trained, we fix G to train P. The training image pairs are the stroke and its corresponding image patch. We replace the user stroke with the binary label of the damage because we do not have a user stroke for a real damage. The network architecture of P is similar to the discriminator of DCGAN.42We replace the final output of the discriminator with a 100D vector to ensure the suitability of the network for generating a shape prior vector.
(3) Joint-tuning P and G. Fixing G to train P only forces P to generate vectors being suitable for G.The parameters of G cannot update when training P. We joint-tune P and G to obtain an optimal model. Joint-tuning aims to minimize the loss of Eq. (3). After joint-tuning, G can generate a damage with a given stroke stabler and then separator training.
3.1.4. Inference
When the training process is completed, we can generate a damage x′from a given user stroke Ishapeby
3.2. Adjustable label generation
The generated damage x′contains not only a damage but also a normal background. Thus, we cannot directly treat the whole region of x′as a label.In addition,the shape of the damage does not strictly agree with the user stroke. Thus, we cannot use the user stroke as a label as well. We propose an adjustable label generation method to generate suitable labels for damages.
As shown in Fig. 4, adjustable label generation consists of Canny edge detection,43morphological dilation operation, morphological close operation, and finding the largest connectivity area.We adjust the minimal threshold Tminfor Canny edge detection. The maximal threshold Tmaxis set to 3 × Tmin. A 5 × 5 square is used as a structural element in morphological dilation operation to generate a dilated image. Thereafter, we adopt a morphological close operation on the dilated image.A final label can be generated by finding the maximal connectivity area.
3.3. Improved Poisson fusion
Directly pasting the damage image on the background image makes the fused image unnatural.We propose to fuse the damage image with the background image by Poisson fusion44in this work. Original Poisson fusion changes the pixel values of the entire foreground image, whereas crack is unnecessary to change the content inside the crack.
Fig. 5 demonstrates our improved Poisson fusion. Let g denote the generated damage and f* the background image.g′is inside the region of g, which is generated by resizing the area of g with a ratio of 0.8. The region between g and g′is a transitional region,which is represented as Ω.Our improved Poisson fusion merely changes the appearance of Ω by
where f is the fused image,v is the gradient of g,∇is the gradient operator,and ∂Ω1and ∂Ω2are the boundaries of g and g′,respectively. Eq. (5)makes the transitional region having the same texture as that of the generated damage.The two constraints enable the fused image f to have identical pixel values with f* and g at∂Ω1and ∂Ω2, respectively. Notably, g is related to the damage label, and it can be obtained by adjustable label generation. The improved Poisson fusion can not only retain the original pixels of the fusion area but also smooth the fusion boundary.
3.4. Interactive damage augmentation
Given a type and a user stroke of the damage, our proposed model can generate some candidate damages. We can fuse a generated damage at the user-given position by improved Poisson fusion.A corresponding label of the damage can be generated by adjustable label generation. The whole process of our interactive damage generation is depicted in Algorithm 1.
4. Experiment
4.1. User interface
The type and shape of a damage are closely related to the position of an airplane engine. In order to make generated damages real enough, we design a user interface to facilitate user interaction. Fig. 6 shows our user interface. Users can select a damage type and draw the shape of a damage on an image.The damage shape is the user stroke that records the movement of a mouse.With the user stroke,our method can generate a realistic damage with a given shape at a specified position. The final fusion effect can be changed by setting different values of threshold Tmin.
4.2. Setup
4.2.1. Dataset We build an airplane engine damage image dataset, namely,AEDID, to validate the proposed method. This dataset consists of 363 crack images, 316 burn images, 41 worn images,and 508 missing-tbc images. Each image has been labeled to generate a pixel-level label.
We extract sub-images and their corresponding labels that contain damages, which are resized to 64 × 64, to train the proposed network. Finally, we obtain 550 crack, 902 burn,206 worn, and 1712 missing-tbc image pairs.
4.2.2. Implementation detail
The proposed method is conducted on a laptop with RTX3000 GPU. We implemented our code with Pytorch 1.5.1,CUDA10.2, and CUDNN 7.6. The parameters of networks are updated by Adam optimizer. The base learning rate is set to 0.0002, the batch size is set to 128, and the momentum is set to 0.999.
4.3. Result analysis
4.3.1. Results of the proposed method and traditional data augmentation methods
We show some examples of traditional data augmentation methods,such as random rotation and cropping,and our proposed interactive data augmentation method in Fig. 7. Traditional data augmentation methods only simulate different viewpoints, but cannot generate novel damages. Our method can generate diverse damages of a certain type at user-given positions.Fig.7 shows that our proposed interactive data augmentation method can generate diverse damages and increase the pixel number of damages in images,which is the essence of solving an unbalanced data problem. In addition, our generated images can further be augmented by traditional data augmentation methods.
4.3.2. Results of the proposed method and image-to-image translation methods To demonstrate the effectiveness of the proposed method, we conduct crack generation by using three image-to-image translation methods, such as pix2pix,45iSketchNFill,46and SPADE.47pix2pix45learns mapping from a source domain to a target domain by introducing inverse mapping and a cycle consistency loss,which can be used for several tasks,including style transferring, object transfiguration, season transfer,photo enhancement, etc. Directly training pix2pix by image patches with a background cannot generate wanted cracks.Thus, we train pix2pix by image patches without a background.
iSketchNFill46is an interactive GAN-based sketch-toimage translation method, which allows users to generate distinct classes from a single generator network. Similar to training pix2pix,we train iSketchNFill by image patches without a background.
SPADE47is a semantic image synthesis method with spatially adaptive normalization to propagate semantic information throughout the network. The training images of SPADE are needed to be labeled into different semantic categories.We train SPADE with crack images and their corresponding semantic labels.
All compared methods are trained by the same training dataset as that of the proposed method for crack generation.Fig. 8 shows the generated crack images of different methods with given user strokes.Although the generated cracks of pix2-pix, iSketchNFill, and SPADE meet the shapes of the user strokes, they do not have the features of real cracks. Besides,SPADE fails to generate the background contents of crack images. On the contrary, our method can generate realistic cracks.
4.3.3. Performances of different detectors with our data augmentation method We conduct object detection with state-of-the-art object detectors, namely, Mask R-CNN,22YOLO v5,23and SSD,7to quantitatively analyze the merits of the proposed interactive data augmentation method.
All detectors are trained to detect crack damages because crack is one of the most concerned damages. Crack images are partitioned into 144 training images, 31 validation images,and 32 test images.For comparison,we adopt traditional data augmentation methods, namely, flipping, rotation, random cropping, Gaussian blur, and Gaussian noise, to augment training images by 10 times. We also augment training images by 10 times with our proposed data augmentation method.
We show some detection results of Mask R-CNN, SSD,and YOLO v5 with images augmented by different data augmentation methods in Fig. 9. Fig. 9(a) is the result of Mask R-CNN. Fig. 9(b) is the result of SSD. Fig. 9(c) is the result of YOLO v5. Mask R-CNN trained with different training data can detect all cracks in the last three images except the first one.Unlike Mask R-CNN,SSD and YOLO v5 only output bounding box predictions. SSD fails to detect the small crack on the left boundary of the first image with or without data augmentation. SSD trained with original data and augmented by the traditional data augmentation methods cannot detect the cracks in the third image. Without data augmentation,YOLO v5 obtains poor detection results in the first three images. On the contrary, YOLO v5 trained with the proposed data augmentation method can detect all the cracks in all four images. Fig. 9 demonstrates that (A) data augmentation is helpful for crack detection; (B) generating damages is more effective than conducting global transformation on images for damage detection.
Table 1 reports the detection performances of different detectors trained with different data augmentation methods.We can find that (A) state-of-the-art object detectors cannot obtain promising performances without data augmentation on crack detection;(B)traditional data augmentation methods can improve detection performances of all detectors by enlarging the training image number; (C) our method can further improve the performances of object detectors compared with those of traditional data augmentation methods. Specifically,training Mask R-CNN, SSD, and YOLO v5 with images generated by the proposed method achieves 49.86%,21.98%,and 116.74% relative mean Average Precision (mAP) improvements over training with original images, respectively. Training Mask R-CNN, SSD, and YOLO v5 with images generated by the proposed data augmentation method achieves 7.26%, 6.17%, and 13.11% relative mAP improvements over training with images generated by traditional data augmentation methods, respectively.
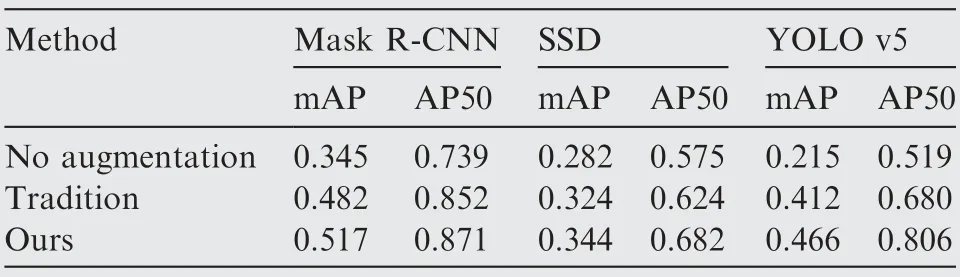
Table 1 Comparison of the performances of different detectors on training images with different data augmentation methods.
Apart from performance improvements, the proposed data augmentation method can accelerate the convergence speed of models. Mask R-CNN can be converged at 45000 iterations with images generated by our data augmentation method,while it converges at 50000 iterations with training images augmented by traditional data augmentation methods. SSD takes 100000 and 120000 iterations with training images generated by our and traditional data augmentation methods,respectively.
4.4. Ablation study
4.4.1. Replacing AlexNet with VGG-19
We replace AlexNet with VGG-19 for the generator to find the effect of using different backbone networks. As shown in Fig. 10, the difference between the generated damage images of AlexNet and VGG-19 is very small.However,AlexNet costs less computation than that of VGG-19. Although many choices can be used as the backbone for the generator, Alex-Net can generate damage images.
4.4.2. Results of generator G with a random noise vector Fig. 11 shows data augmentation results of G with random noise vector n on four types of damages. After being trained with each type of damage image, G can capture the distribution of the corresponding damage type.
Generated worn damages are similar in texture but different in color. Other types of generated damages have different shapes and textures. Obviously, G cannot control the shape of a damage with random noise vector n. However, damages are tightly related to occurred positions, which needs strict
shape control. We will conduct various experiments on crack images in the following sections to demonstrate the shape control ability of our proposed method.
4.4.3. Results of generator G with prior network P
We demonstrate some generated results of G with shape prior network P on crack images in Fig.12.x is the original damage image.Ishapeis the shape of a damage.x′is the generated damage image with Ishapeby our proposed method. The shapes input into P are generated from labels by extracting the skeletons of the corresponding labels of damage images.Generated damage images are similar to their shapes, which verifies that the shape prior network encodes shape information into the shape prior vector. We draw strokes in images as shown in Fig. 13 to generate cracks capturing the shapes of the strokes.Small random noises are added to the shape prior vector to increase the diversity of generated cracks. Images in the first column in Fig.13 are user strokes.x1′,x2′,...,x4′are generated damage images with four random noises.We can find that generated cracks follow the shapes of the strokes and show diversity with the same stroke.
Table 2 Comparison of the performances of training YOLO v5 on the images generated by using n and p+n.

Table 2 Comparison of the performances of training YOLO v5 on the images generated by using n and p+n.
Method mAP AP50 n 0.444 0.707 p+0.1n 0.466 0.806
4.4.4. Effects of the segmentation threshold
We show generated labels and their corresponding augmented results at Tmin=0,45,140,225 to study the effects of threshold Tminon adjustable label generation. As shown in Fig. 14,we can find that (A) all pixels in the patch are labeled as a crack when Tmin=0;(B)increasing threshold Tminwill reduce normal regions,and when Tmin=140,we obtain the best segmentation label for this example; (C) surging Tminwill reduce more normal pixels and even reduce the pixels inside the crack;(D) using a high value, such as Tmin= 22, results in a black label (all pixels are labeled as a background). The threshold Tmincan be adjusted according to the generated damage image to generate a suitable augmented image.
4.4.5. Failure cases
We show four failure cases of generated crack damages in Fig.15.The damages shown in the first row can capture shapes of strokes but have large translations in horizontal and vertical directions. The shapes of damages shown in the second rows are different from their corresponding strokes because random noise n disturbs the distribution of shape prior vector p.With a disturbed vector n, generator G cannot always produce promising cracks. However, failure cases rarely occur in real usage.
5. Conclusions
In this study, we propose an interactive data augmentation method with a prior-guided GAN. The proposed model has two networks:a generator G and a prior network P.We firstly train G to generate images with random noise. Then, we train P by fixing G.The training process can enable P to encode user stroke information and force P to produce a prior vector that makes G generate wanted damages.Random noise is added to the shape prior vector to obtain various generated damages.We propose an adjustable label generation method to adjust segmented regions. We use an improved Poisson fusion method based on a generated label to paste a damage image on a background image.We conduct various experiments to analyze the proposed method. Compared with traditional data augmentation methods, our method can generate novel damages on existing training images. Thus, it can effectively increase the number and diversity of training images. Experimental results on object detection demonstrate that using the proposed data augmentation method can improve detection performance with a large margin. Our data augmentation method can be applied to other computer vision-based detection problems such as deterioration detection on roads to increase the number of training images and solve the unbalanced data problem.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgement
This work was supported by the Natural Science Foundation of Tianjin, China (No. 20JCQNJC00720).
 CHINESE JOURNAL OF AERONAUTICS2022年10期
CHINESE JOURNAL OF AERONAUTICS2022年10期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Full mode flight dynamics modelling and control of stopped-rotor UAV
- Effect of baffle injectors on the first-order tangential acoustic mode in a cylindrical combustor
- Experimental study of hysteresis and catastrophe in a cavity-based scramjet combustor
- Flow control of double bypass variable cycle engine in modal transition
- Effects of chemical energy accommodation on nonequilibrium flow and heat transfer to a catalytic wall
- A reduced order model for coupled mode cascade flutter analysis