
基于区块链的隐私保护去中心化联邦学习模型
2022-11-12 11:27:36胡克勇王金龙
计算机研究与发展 2022年11期
周 炜 王 超 徐 剑 胡克勇 王金龙
1(青岛理工大学信息与控制工程学院 山东青岛 266520) 2(大规模个性化定制系统与技术全国重点实验室(海尔集团公司) 山东青岛 266100) 3(东北大学软件学院 沈阳 110169)
机器学习为各行各业带来了新的发展动力,其在语音识别、图像识别和分类、药物发现、流感患病率预测等方面的应用取得了显著进步[1-4].为了获得高质量的模型,传统机器学习方案需要收集大量数据到中央服务器,这带来了过高的计算开销和隐私泄露的风险.在诸如医疗保健、物联网等领域,大量敏感数据广泛分布在不同位置,有多个数据实体联合建模的需求,但出于隐私保护的考虑,数据源之间存在难以打破的壁垒,对于数据的隐私性和安全性有着更高的要求.
随着美国《健康保险携带和责任法案》(health insurance portability and accountability act, HIPAA)[5]以及欧盟《通用数据保护条例》(general data protection regulation, GDPR)[6]的颁布实施,数据访问进一步受到限制.业界和学术界开始更加注重在应用机器学习时的隐私保护问题,私有数据不应公开上传到中央服务器.谷歌在2016年首次提出联邦学习的概念[7-9],建立了基于多个设备上数据集的分布式训练模型.训练过程包含一个中央服务器(即参数服务器)和多个设备节点,节点从服务器下载现有模型,利用本地数据进行模型训练,仅上传本地模型更新(即学习模型的权值和梯度参数).服务器则聚合所有的本地模型更新,从而形成一个全局模型更新.之后每个设备从中央服务器下载全局模型更新,进入下一轮本地训练,直至全局模型训练完成.由于这种隐私特性,联邦学习受到越来越多的研究和关注[10].
传统联邦学习依赖一个可信的中心化参数服务器,由多个参与方在保证各自数据不出本地的情况下协同训练一个全局模型.服务器负责收集局部模型更新,执行更新聚合,维护全局模型更新等集中式操作,整个训练过程易受服务器故障的影响.恶意的参数服务器甚至会毒害模型,产生不准确的全局更新,进而扭曲所有的局部更新,从而使整个协同训练过程出错.此外,部分研究已经表明,未加密的中间参数可以用来推断训练数据中的重要信息,参与方的私有数据面临着暴露的风险[11-12].因此,在模型训练过程中,对局部模型更新采取合适的加密方案以及在分布式节点上维护全局模型显得尤为重要.
区块链作为一种时间有序、去中心化、不可篡改、可追溯、高可信、多方共同维护的分布式账本,可以用于代替联邦学习中的参数服务器,存储模型训练过程中的相关信息.本文提出了一种基于区块链的去中心化、安全、公平的联邦学习模型——PPFLChain,使用区块链存储和维护模型信息,不要求参与方之间相互信任或信任任何第三方.为了保证参与方的隐私安全和模型的高性能表现,PPFLChain没有采用以牺牲训练模型性能来换取隐私保障的差分隐私技术[13],而是采用同态加密技术来保证准确性和机密性,并通过秘密共享方案为解密过程实现安全的密钥管理.同时为了保证解密过程的顺利,检测错误的秘密份额,双线性映射累加器被用来生成秘密份额的证据,提供验证手段.
为增强联邦学习过程的可靠性,PPFLChain引入信誉值作为评估参与方可靠性的指标,信誉值较高的参与方意味着为模型训练过程做出了更多积极的贡献.信誉计算利用主观逻辑模型实现,根据参与方的历史交互行为计算信誉值,并据此择优选出参与方组成联邦学习委员会,进行模型聚合和协同解密.信誉值还作为激励机制的参考,依据各参与方对训练过程的贡献大小发放不等的奖励,惩罚恶意的参与方,补偿积极的参与方,以保障协同训练的公平性.值得注意的是,委员会成员不是一成不变的,而是每隔一段时间重新选举一次,这有利于激发参与方的积极性,不断改进全局模型.
本文的贡献主要有3个方面:
1) 提出一种基于区块链的隐私保护联邦学习模型——PPFLChain,实现去中心化、安全、公平的联邦学习.
2) 利用双线性映射累加器生成秘密份额的证据,为秘密共享方案提供可验证性,并从理论上分析该累加器方案的安全性.
3) 引入信誉值作为评估参与方可靠性的指标,利用主观逻辑模型实现不信任增强的信誉计算作为联邦学习委员会的选举依据.信誉值还作为激励机制的参考,保障协同训练的公平性.
1 相关工作
Yang等人[14]进一步讨论了联邦学习的概念、体系结构和潜在的应用,根据数据集的分布特点,将联邦学习分为横向联邦学习、纵向联邦学习、联邦迁移学习3类.第1类针对不同数据集之间,特征重合较多而样本重合较少的情形;第2类针对样本重合较多而特征重合较少的情形;第3类针对特征和样本均重合较少的情形.同时指出联邦学习应当采取合适的技术手段提供有效的隐私保护.
为给联邦学习过程的中间结果提供有力的隐私保障,Aono等人[15]采用加法同态加密机制由任一终端生成密钥对并分享给其他终端.各终端在本地训练完成后,上传用公钥加密后的中间参数.中央服务器直接对收集的密文进行盲计算,返回加法同态后的结果,各终端利用私钥解密得到全局模型更新.但是这种方案由于所有终端都掌握着私钥,一旦某个终端窃取到其他终端发送的密文信息,则能够立刻解密得到明文参数.更加值得注意的是,这种密钥管理方案几乎不能容忍入侵,对于终端的安全性要求较高.Zhang等人[16]将解密工作转移到中央服务器上,由服务器聚合上传的密文参数后解密.为防止局部参数泄露,采用秘密共享技术确保至少k个用户上传参数之后,服务器才能够解密.Heikkilä等人[17]设计了由多个服务器组成的安全聚合方案.终端将本地更新参数随机分割,加密后分别发送给多个服务器,单独的服务器无法获知原始数据,仅能在收集完所有用户的参数碎片后共同聚合并解密,得到聚合结果.
但是这种依赖一个或多个服务器的隐私保护联邦学习方案仍面临三大挑战:
1) 训练场景复杂多样,联邦学习中参与方的可信度低,并且完全依赖服务器的可靠性来存储和计算模型更新,训练过程易受服务器故障和恶意攻击的影响.
2) 联邦学习具有增量特性,在训练过程中会产生大量信息,而联邦学习缺乏对相关信息进行验证的手段.
3) 联邦学习缺少对参与方贡献大小的考量,缺乏激励手段来吸引更多的训练数据和计算资源,保障公平性.
区块链作为一种去中心化的分布式账本技术,可以记录历史事务并防止篡改,是替换中心化服务器的有效解决方案.针对以上三大挑战,当前区块链也被作为改善联邦学习的平台进行研究.Dillenberger等人[18]分析了联邦学习与区块链融合的可行性问题.指出区块链为联邦学习过程提供了一种安全的交换学习模型参数的方法,其在存储模型参数的同时允许对联邦学习中迭代的模型进行审计.此外,基于区块链的联邦学习的性能几乎可以与独立的联邦学习相媲美.
Kim等人[19]提出了BlockFL,在区块链网络环境下进行设备上的联邦学习.用户设备在本地训练数据并上传模型更新,矿工负责在预定时间内收集足够多的本地模型更新并打包成块记入区块链.BlockFL根据本地训练时长来分配数据奖励给设备节点,以及分配挖矿奖励给矿工,并通过调整块生成率,即POW难度,使延迟最小化.然而由于设备节点的间歇性和可用性的问题,更加动态的网络环境间接导致了部分参与设备在预定时间内训练完本地模型并上传更新是不可靠的.
Li等人[20]提出了BFLC,为联邦学习选择可靠的参与者.系统详细定义了模型在区块链上的存储模式、训练过程和一个新的委员会共识.委员会成员不参与本次迭代的训练过程,而将本地数据集作为验证集来验证参与者的局部更新是否可靠,并给出验证得分,以达到交叉验证的效果.智能合约则在一段时间后选出性能较好的节点,组成下一轮训练的新委员会.通过这种方式,BFLC选出了可靠的联邦学习参与者,实现了在投毒攻击的情况下仍能保持良好的模型性能,同时提高了共识效率.但是由于难以在保持模型可用性的同时提供有力的隐私保护,该系统传输的是明文的中间参数,并未考虑参数的机密性.
Weng等人[21]提出了DeepChain,为深度学习提供安全的训练环境.具体做法是利用同态加密保证局部更新的机密性,结合秘密共享实现协同解密全局模型,并基于普遍可验证的CDN(UVCDN)协议来实现加密梯度和解密份额的可审计性.采用的blockwise-BA共识协议通过加密抽签选择一个工作者来创建区块,并由该区块内交易的参与者所组成的委员会验证.DeepChain还实现了一种基于区块链的激励机制,利用名为deepcoin的数字货币作为资产来奖励诚实的参与者,惩罚恶意的参与者.然而该方案假定选举的全体委员会成员都是诚实的,并且随机算法是接近完美随机的.
现有基于区块链的联邦学习方案可以有效记录节点的性能、减少恶意攻击、提高模型训练的准确性;但在隐私保护、增加验证手段、衡量参与方贡献大小及保障公平性方面还有所欠缺.同时,采取合适的方案选择诚实可靠的参与方对于联邦学习任务来说也是至关重要的.
2 预备知识
本节对系统设计中需要用到的关键技术给出一些初步的介绍,包括区块链、秘密共享、同态加密、双线性映射累加器.
2.1 区块链
区块链是一种点对点、时间有序的去中心化分布式账本技术,具有密码学保证的不可篡改、不可伪造的特点[22].事务信息存储在包含时间戳和上一个块引用的区块中,并以链的形式增长,由所有参与方共同维护,并通过共识算法来保证账本的一致性[23].根据准入规则,区块链可以分为公有链和联盟链.对于公有链,参与方可以自由加入和退出,参与方的数量不是固定的,如比特币[24];对于联盟链,只有得到授权的用户才能加入,参与方集合通常是预先定义好的[25],如IBM的Hyperledger fabric.
区块链以其透明、可追溯、健壮的特点,可在互不了解的多方间建立起可靠的信任,是在不安全的环境下替换易受攻击的中央服务器的一种有效解决方案.联盟链作为具备准入控制的区块链,适用于需要预先审核用户和具有相对稳定参与方集合的联邦学习.亟需一种合适的方法将区块链和隐私保护联邦学习结合起来,以解决中央服务器的安全问题,增强多方参与模型训练的安全性.
2.2 秘密共享
秘密共享是在多个参与方之间共享秘密的密码学技术,保证信息不会被破坏、篡改和丢失.秘密共享通过特定运算将秘密分成若干份额,分配给多个参与方,秘密恢复需要根据协议由多个参与方联合进行,单独的秘密份额没有用处.目前的秘密共享方案主要包括Shamir方案[26]、Blakley方案[27]、中国剩余定理方案[28]等.Shamir方案作为一种(k,N)门限方案,将秘密S分为N个秘密碎片并分配给N个参与方,要求至少k个参与方合作才能恢复出秘密,而少于k个参与方得不到有关秘密的任何信息.该方案基于拉格朗日插值公式实现,核心功能有2个:
1) 秘密分割.F(x)=S+a1x1+a2x2+…+ak-1xk-1modp.其中p为大于秘密S的素数,a1,a2,…,ak-1为小于p的随机数.取N个不相等的x代入可以得到N个秘密碎片s0,s1,…,sN,其中si=(xi,yi).

该方案能够在分布式系统中实现安全的密钥管理和信息保护,有效防止系统外部攻击和内部用户的背叛,达到分散风险和容忍入侵的目的.
2.3 同态加密
同态加密是一种对密文进行运算的基于数学难题和计算复杂性理论的密码学技术,允许对加密后的密文直接进行计算,且解密后的结果与基于明文的计算结果相同[29].根据支持密文运算的程度,同态加密可以分为部分同态加密和完全同态加密2类.部分同态加密只能支持有限的密文计算深度,在一些运算并不复杂的场景中得到应用,如Paillier同态加密支持密文间的加法运算,但是不支持密文间的乘法运算[30];BGN(Boneh-Goh-Nissim)方案能够支持无限次密文间的加法运算,但是只能支持一次密文间的乘法运算[31].完全同态加密对密文的计算深度没有限制,支持任意类型的密文计算,但是计算代价高、效率低下,并未得到大规模应用[32].
同态加密作为一种特殊的加密算法已被用于联邦学习中的隐私保护,参与方传递的都是加密后的参数信息,保证这些信息即使被攻击也不会泄露模型信息和用户隐私.用于解密的私钥安全性变得尤为重要.门限同态加密将私钥分割为多份,由多个参与方持有并且解密过程需要多方协同进行,是一种安全的多方计算方案.门限Paillier同态加密[33]作为这种方案的典型,包含4个过程:
1) 密钥生成.KeyGen(p,q)→(pk,sk).随机选择2个大质数p,q,使得p=2p′+1,q=2q′+1,gcd(n,φ(n))=1,其中p′,q′为不同于p,q的质数.计算n=pq,m=p′q′.随机选择β∈*n,(a,b)∈*n×*n.令g=(1+n)abnmodn2,θ=amβmodn,生成公钥pk=(n,g,θ),私钥sk=mβ.私钥sk通过Shamir秘密共享方案进行分割,第i个参与方Pi将得到秘密份额modnm,其中d0=sk,d1~dk-1为从{0,1,…,nm-1}中随机选取的值.
2) 加密.Enc(m,pk)→c.对于明文m,随机选择一个数r∈*n,加密可得到密文
c=C(m)=gmrnmodn2.
(1)
3) 解密份额生成.ShareDec(c,si)→ci.N个参与方中第i个参与方Pi利用持有的秘密份额si计算其解密份额
ci=c2N!simodn2.
(2)
4) 协同解密.CollaborativeDec(D,pk)→m.设集合D包含至少k个正确的解密份额,计算可得到明文
(3)

该方案满足加法同态性质,对于2个密文C(m1)和C(m2),计算后得到基于明文的和运算结果的密文,即
C(m1)C(m2)=gm1+m2(r1r2)nmodn2=
C(m1+m2).
(4)
扩展到多个密文的计算,这种性质能够确保联邦学习在参与方传递加密参数信息的情况下,安全地聚合局部模型,起到保护参与方隐私的效果.
2.4 双线性映射累加器
在数学中,双线性映射指的是2个循环群之间对应的线性映射关系.定义一个概率多项式时间双线性映射生成算法BMGen(1λ) →(e,g,G,H,p),其中G和H是具有相同素数阶p的循环乘法群,g为G的生成元,则存在双线性映射e:G×G→H,具备3条性质[34]:
1) 双线性.对于任意的u,v∈G和a,b∈p,均满足e(ua,vb)=e(u,v)ab.
2) 非退化性.e(g,g)≠1,其中1为群H的单位元.
3) 可计算性.对于任意的u,v∈G,e(u,v)都能够高效计算得出.
在密码学中,累加器是一个单向的隶属函数,用于识别一个元素是否为某个特定集合的成员,能够将集合中的所有元素进行累加,生成一个固定大小的值,并高效地给出任意元素的(非)成员证明,且在验证过程中不会暴露集合中的成员信息.密码学累加器主要分为静态累加器、动态累加器以及通用累加器3种类型[34].第1种针对静态集合中元素的累加;第2种允许从累加集合中动态地添加和删除元素;第3种能够同时支持成员证明和非成员证明.根据底层密码工具的不同,可分为基于RSA的密码学累加器、基于双线性映射的密码学累加器和基于Merkle哈希树的密码学累加器.该技术已在群签名、匿名凭证、外包数据验证等领域得到广泛应用.
3 系统模型
本节介绍所提出的PPFLChain,一种基于区块链的去中心化、安全、公平的联邦学习模型,并讨论整个学习过程中面临的威胁和安全目标.
3.1 系统概述
PPFLChain利用区块链取代传统联邦学习中的参数服务器,以去中心化的方式存储协作训练信息,避免服务器单点故障影响模型训练的过程,并通过结合同态加密、秘密共享以及密码学累加器技术实现可追踪、可验证和隐私保护的联邦学习,增强模型训练过程的安全性.同时,系统根据参与方的行为表现给出信誉评估,并据此选举出一个联邦学习委员会进行模型聚合和协同解密.信誉得分还将作为激励机制的参考保障联邦学习的公平性.
系统的概览如图1所示.由图1可知,系统主要由4部分组成:任务发布方、参与方、委员会和区块链.具体来说,任务发布方发布联邦学习模型训练任务,对该任务感兴趣的节点可以申请参与到模型训练当中,提交本地模型更新到区块链.委员会负责聚合区块链上记录的所有局部模型更新,并提交全局更新到区块链.最后区块链替代集中式服务器收集和存储协作训练信息.下面将对PPFL-Chain的各个组件进行详细说明.
1) 任务发布方.根据需求提出建立一个机器学习模型,同时发布联邦学习模型训练任务的要求(即存储、计算能力等的要求),并支付一笔费用作为奖池.对此感兴趣并符合要求的节点可以申请参与该联邦学习任务.然后任务发布方将随机选择参数的初始化模型上传到区块链.随着越来越多的节点加入其中并为模型训练做贡献,任务发布方将最终得到一个高性能的机器学习模型.
2) 参与方.指申请加入模型训练任务并经过任务发布方审核通过的节点,其对该机器学习模型有需求,但由于自身存储、计算能力不足或数据资源有限而无法单独完成整个训练任务.参与方在上传局部更新到区块链时,需要申明本地数据量大小,并附加相应的训练耗时,据此表明自己的数据贡献大小.
3) 委员会.系统将委员会中成员的数量设定为所有参与方数量的一半.初始委员会由任务发布方随机指定参与方组成,并依次担任委员会的领导者,负责模型聚合和发放数据贡献奖励给相应的参与方.在轮流担任领导者一圈或未担任领导者的委员会成员不在线时,系统将按照参与方的信誉值高低择优选举一半节点组成新的委员会,关于信誉计算的更多细节将在第4节中给出.
4) 区块链.由于联盟链作为区块链的一种特殊类型,具备准入控制,符合需要预先审核用户和具有相对稳定参与方集合的设定,PPFLChain使用联盟链取代传统联邦学习中的参数服务器来存储局部更新和全局更新.所有参与方共同维护区块链账本,单一节点的故障或退出并不影响其他参与方对信息的获取,这提高了数据容灾的能力.此外,由于区块链具有透明、可追溯、不可抵赖的特点,系统对每个参与方的信誉评估历史也被记录在区块链上,基于信誉的联邦学习委员会选举方案也变得更加开放、透明和可靠.

Fig. 1 System model of PPFLChain图1 PPFLChain系统模型
3.2 威胁和安全目标
系统假设参与方是诚实训练的,都是经过严格审核后加入的节点,有着获得更好模型性能的期望,不会发起投毒攻击以毒害全局模型,进而扭曲所有的局部更新,从而使整个协同训练过程出错.但是他们可能会对数据隐私感兴趣或者有意无意地做出其他错误行为.接下来将讨论PPFLChain面临的威胁,以及在应对这些威胁时能够实现的安全目标.
威胁1:本地数据和模型信息泄露.尽管在联邦学习过程当中,每个参与方利用自身数据在本地进行模型训练,只上传中间参数,但这种明文参数可能被其他参与方利用,他们可以通过发起成员推理攻击,推断出局部数据的重要信息,或基于梯度发起参数推断攻击,获取模型的敏感信息.
安全目标1:训练数据和中间参数的机密性.联邦学习参与方在不主动公开本地训练数据的情况下,不会泄露数据隐私,其他方在协同训练的过程中无法直接或间接地得到有关该方的真实数据信息.参与方利用本地数据训练完模型后,通过同态加密技术加密参数后上传,而不是传输明文信息,其他方无法根据密文更新推断出该方的中间参数信息以及本地数据信息.
威胁2:参与方行为错误.主要包含3种错误行为:1)考虑参与方可能会为了节省训练成本,谎报一个较大的数据量,而实际在本地进行模型训练的数据集较小,以期获得更多的数据贡献奖励;2)考虑委员会领导者在计算全局更新时可能会给出错误的聚合结果;3)考虑在协同解密时,委员会成员可能为了个人利益给出错误的解密份额,想要提前中止训练过程.这些错误行为都将导致诚实的参与方蒙受损失,甚至导致协同训练任务失败.
安全目标2:模型聚合与秘密份额的正确性验证.参与方上传的局部更新密文以及委员会领导者计算的全局更新密文都将以公开透明的方式被记录在区块链上,任何参与方都可以通过这些事务来验证计算结果的正确性.秘密份额的证据由双线性映射累加器产生并被记录到区块链,任何参与方都可以利用该方案验证秘密份额的正确性,监督委员会成员计算出正确的解密份额.
安全目标3:参与方的公平性保障.PPFLChain考量参与方的贡献大小,对模型训练贡献较大的一方将获得更多的奖励.贡献大小主要包含2个方面:1)参与方本地数据量大小.根据其训练花费的时间与训练样本的多少成正比关系确定.2)参与方的信誉值.参与方只有诚实积极地为模型训练过程做贡献,才能提升自己的信誉值.高信誉值的参与方意味着做出了更多的贡献,将得到更多的奖励.PPFLChain还采取惩罚措施,对有错误行为的参与方进行罚款,以补偿诚实的参与方.同时受信誉计算方案的影响,行为错误的参与方将会获得较低的信誉得分.
3.3 累加器方案
Nguyen[35]提出的双线性映射累加器,是基于q-SDH(q-Strong Diffie-Hellman)假设[36]的动态累加器,以双线性对运算为基础,能够为集合中的元素提供简短成员关系证明.设tup=(e,g,G,H,p)是双线性映射的一组参数.对于s∈*p,给定元素gs,…,gsq∈G,q-SDH假设是指对于所有多项式q和所有概率多项式时间对手Adv:
(5)
该假设表明Adv几乎无法通过破解累加器来伪造成员关系证明.式(5)是该累加器的安全基础.
为实现委员会协同解密全局模型过程中秘密份额的正确性验证,PPFLChain基于上述双线性映射累加器构造,设计出适用于本系统的累加器方案,由4种概率多项式时间算法组成:
1)KeyGen(1λ)→(sk,pk).λ为安全参数,输入1λ并选择一个随机值s∈*p;输出为私钥sk=s和公钥pk=(g,gs,gs2,…,gsq).



3.4 工作流程
为了便于表示,表1列出了描述使用的相关符号:

Table 1 Notation Description
结合图1中过程①~⑨,PPFLChain的工作流程主要包含6个阶段:初始化、联邦成立、全局更新下载、本地模型训练、局部更新上传、全局模型更新.
在初始化阶段(l=0),任务发布方发布模型学习的任务要求,并支付一笔费用作为奖池.然后将随机选择参数的初始化模型W0上传到区块链(如过程①).节点根据自身计算能力和数据资源条件向任务发布方申请加入建模过程,审批通过的节点将参与到该模型训练任务当中,并缴纳一笔费用作为押金.具体的审批方式可以是线下协商等形式,这不是本文关注的重点.
在全局更新下载阶段,参与方从区块链上最新的块下载全局模型更新Wl(如过程②),并将其作为下一次本地模型训练的输入.



在协同解密过程中,要求至少有k个委员会成员提供正确的解密份额来协作解密C(Wl)(如过程⑦).CMj利用持有的秘密份额sj通过式(2)计算得到解密份额cj并提供证据ρj证明其使用了正确的秘密份额进行计算,整个秘密份额验证过程在算法1中进行了详细描述.通过式(3)解密后生成的全局模型更新Wl被领导者上传到区块链(如过程⑧).
算法1.基于密码学累加器的秘密份额验证.
begin
证据生成(由任务发布方执行):
设S为秘密份额集合{s1,s2,…,sN};
应用Calc(·)生成累加值acc(S);
#acc(S)将作为秘密摘要记录到区块链.
对于每个秘密份额子集Si⊆S,Si={si}
应用ProveContainment(S,Si,pka)→ρi,生成证据.
#每个证据ρi将连同秘密份额si一起发送给参与方Pi.
验证对象生成(由参与方执行):
对于每个拥有秘密份额si的参与方
应用Calc(Si,pka)→acc(Si);
然后发送验证对象〈acc(Si),ρi〉给验证者.
结果验证(由验证者执行):
从区块链读取秘密摘要acc(S);
应用VerifyContainment(acc(S),acc(Si),ρi,pka);
如果si是正确的秘密份额,输出1;
否则,输出0.
end
然后不断迭代过程②~⑧直至模型收敛,模型收敛的条件是损失函数小于预先设定的值或迭代次数达到预先设定的最大迭代次数.最终任务发布方从区块链上得到一个高性能的机器学习模型(如过程⑨).
值得注意的是,由于秘密共享方案的可配置性,PPFLChain在委员会成员协同解密全局模型更新时,一般设定k 委员会在PPFLChain的模型训练过程当中扮演着重要角色,负责验证参与方数据贡献大小、聚合模型和协同解密全局模型.这都将关系到训练模型的精度和协作学习的安全及效率,甚至是训练过程的正常运作.因此,采取高效、准确的信誉计算方法来选举出可靠的委员会成员是至关重要的.本节基于主观逻辑模型设计了一种不信任增强的信誉计算方法,在评估不同实体可信度和可靠性水平的同时,引导委员会成员行为正确. (6) (7) (8) (9) 参与方的信誉值更新将在每次全局模型更新后进行. 本节根据PPFLChain面临的威胁,回顾3.2节中系统实现的安全目标,并给出相应的安全分析. 定义1.安全性[39].对于所有的安全参数λ∈,运行KeyGen(1λ)→(sk,pk),然后把公钥pk给任意的多项式时间敌手Adv,如果Adv根据2个集合A和B生成B⊆A的证据ρ的成功概率是可以忽略不计的,就说明累加器是安全的.这里Adv成功是指其应用VerifyContainment(acc(A),acc(B),ρ,pk) 输出结果为1,然而BA. 该方案所使用的累加器构造已经在文献[39]中的q-SDH假设下被证明确实满足了期望的安全性要求,定理及证明过程如下. 定理1.在3.3节中给出的累加器构造满足定义1中的安全特性. 证明.用反证法证明.假设有一个敌手Adv生成了关于集合B⊆A的有效子集包含证据ρ(实际上BA).这意味着: 而实际上因为BA,所以存在(bj+s)不能被除掉,由此可以得到其中Q(s)是关于s的多项式,C是一个非0常数.因此敌手Adv可以得到: 这与q-SDH假设相违背.由推出矛盾得知,定理1成立. 证毕. 这个属性确保了委员会成员伪造秘密份额证据的可能性是可以忽略的,是所设计的累加器方案能够实现正确性验证的保障. 本节介绍了PPFLChain的实验环境,并从训练准确率、时间成本、信誉值方面对所实现的系统性能进行了评估. 为了评估提出的PPFLChain的系统性能,实验在真实的数据集MNIST[40]上实现了系统的原型.该数据集用于手写数字识别,拥有60 000个训练样本和10 000个测试样本,每个样本是一个28×28的灰度图像,代表0到9之间的手写数字.实验将训练集随机划分为数量相等的10个子集,并分别分配给10个参与方作为本地数据集.这样,对于每个参与方,本地训练样本的数量为60 000/10=6 000.然后根据参与方人数设定的不同进行了7次实验,分别有4,5,6,7,8,9,10个参与方,实验编号分别用E-4,E-5,E-6,E-7,E-8,E-9和E-10表示.委员会成员的数量分别设定为2,2,3,3,4,4,5. 实验在1台配备了4核8线程Intel CPU i7-6700HQ和16 GB内存的笔记本电脑上使用了一个名为FISCO BCOS的区块链系统来模拟PPFLChain.使用Python编程语言利用软件开发工具包FISCO BCOS Python SDK来实现系统的业务逻辑.智能合约采用Solidity编写.学习模型使用Python 3.7.11和Pytorch1.2.0编写,并在NVIDIA Geforce GTX 970M GPU上执行. 区块链节点被视为参与方和委员会成员,参与联邦学习任务并与预定义的智能合约进行交互.生成的事务在区块链中序列化. 实验通过训练准确率、时间成本、信誉值3个指标来评价PPFLChain在多方协作学习下的有效性. 对于训练的准确率,实验设置了基线方和独立方与PPFLChain进行比较.其中基线方在本地用6 000个样本独立训练模型,不参与协作学习的过程;独立方则使用包含60 000个训练样本的完整数据集独立训练模型.图像分类模型均来源于相同的卷积神经网络(convolutional neural network, CNN),模型卷积核大小为5×5,激活函数为ReLU.同时固定一组模型超参数以保证公平性.表2中总结了一些相关的训练参数. Table 2 Training Configuration 实验分别对基线方、独立方和E-4~E-10进行了10次数据提取,并把得到的最终结果的平均值绘制成图2.其中,基线方的准确率为95.90%,独立方的准确率为96.45%,E-4~E-10的准确率分别为96.12%,96.28%,96.14%,96.44%,96.38%,96.32%,96.22%.可以看出,PPFLChain都比基线方获得了更高的准确率,这意味着协作学习得到了比单方面训练表现更好的模型.同时,随着参与方人数的增加,协作方训练准确率提高,PPFLChain的性能不断趋近于独立方的训练效果.虽然训练准确率相比拥有完整数据集的独立方略有损失,但PPFLChain能够在多方协作的环境下,以去中心化的方式训练模型,大大降低了隐私泄露的风险. Fig. 2 Comparison of training accuracy among PPFLChain, standalone party and baseline party图2 PPFLChain与独立方和基线方的训练准确率比较 接下来,记录了实验E-4~E10中参与方在协作训练模型过程中加密梯度参数耗费的平均时间,分别为44.452 s,44.261 s,43.955 s,44.222 s,44.609 s,44.645 s,44.485 s,以及委员会成员在协同解密阶段验证秘密份额耗费的平均时间,分别为8.193 ms,8.380 ms,9.701 ms,9.614 ms,11.950 ms,12.143 ms,14.856 ms.由图3可以看出,不同参与方数量下加密中间梯度所用的时间基本一致,这是由于各参与方在本地同步训练,训练集大小和模型的参数量相同,细小的差异仅取决于硬件性能. Fig. 3 Time cost of encryption图3 加密时间成本 Fig. 4 Time cost of verification图4 验证时间成本 为了评价信誉计算方案,实验记录了5个本地数据集大小互不相同的参与方分别与其他协同方的10次积极交互中的信誉值变化情况,用P1~P5表示,本地训练样本的数量分别为2 000,3 000,4 000,5 000,6 000.如图5所示,数据贡献较大的一方获得了较高的信誉值,因为在评估参与方信誉时,本地数据集大小被作为计算信誉值的影响因素之一. Fig. 5 Comparison of reputation values between participators with different amounts of local dataset图5 本地数据量互不相同的参与方之间的信誉值比较 然后在不信任影响程度α=0.8和α=0.2的2种设置下又记录了一个参与方与协同方的22次交互中的信誉值变化,该参与方在1~3次的交互中行为正确,在4~14次的交互中行为错误,在15~22次的交互中行为正确.设定不确性影响程度β=0.5,不确性影响常数c=2.如图6所示,当表现错误行为时,该参与方的信誉值开始下降,并且在最初的几次恶意交互中信誉值下降飞快,这意味着节点只要做出恶意行为,无需累积多次,就会付出较大的代价.而对于没有信誉保护的方案,信誉值仍呈增长趋势.同时在α=0.8的情况下信誉值的下降速度要比α=0.2的情况下更快,下降幅度也更大,可以看出,通过配置α的大小可以方便地控制节点作恶对信誉值的影响程度.此外,系统引入的信誉值是由多方评估计算得出并记录在区块链上,与没有区块链的信誉方案相比,这种去中心化和防篡改的特性能够抵御内部攻击,使得计算出的信誉值更加可靠和具有代表性. Fig. 6 The reputation values of an unreliable participator图6 不可靠参与方的信誉值变化 本文提出了一种基于区块链的去中心化、安全、公平的联邦学习模型——PPFLChain.模型引入信誉值作为衡量参与方可靠性的指标,并基于信誉值选举可靠的联邦学习委员会,负责聚合模型和协同解密全局更新.模型采用门限Paillier密码算法实现局部更新参数的机密性,利用Shamir阈值秘密共享方案,为解密过程实现安全的密钥管理,设计了一种基于双线性映射的累加器方案为秘密份额提供验证手段.利用主观逻辑模型实现不信任增强的信誉计算方案作为联邦学习委员会的选举依据.模型还将信誉值作为激励机制的参考,并惩罚有错误行为的参与方,以保证协作学习的公平性.最后在一个真实的数据集上实现了系统的原型,并对系统的安全性和性能表现进行了分析和评估. 作者贡献声明:周炜提供研究思路,审阅论文,提供论文修改意见;周炜和王超确定研究思路,负责论文起草、修改及最终版本修订;徐剑、胡克勇和王金龙审阅论文,提供论文修改意见.4 信誉计算方案
4.1 基于主观逻辑的信誉表征

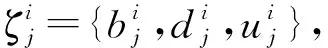


4.2 综合委员会成员的信誉意见

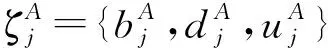
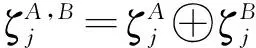
5 安全分析
5.1 机密性
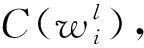
5.2 正确性验证
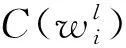

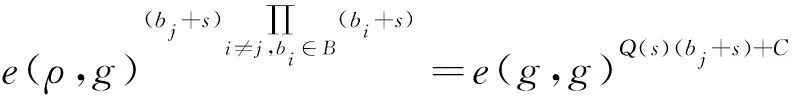
5.3 公平性保障
6 实 验
6.1 实验设置
6.2 性能评估

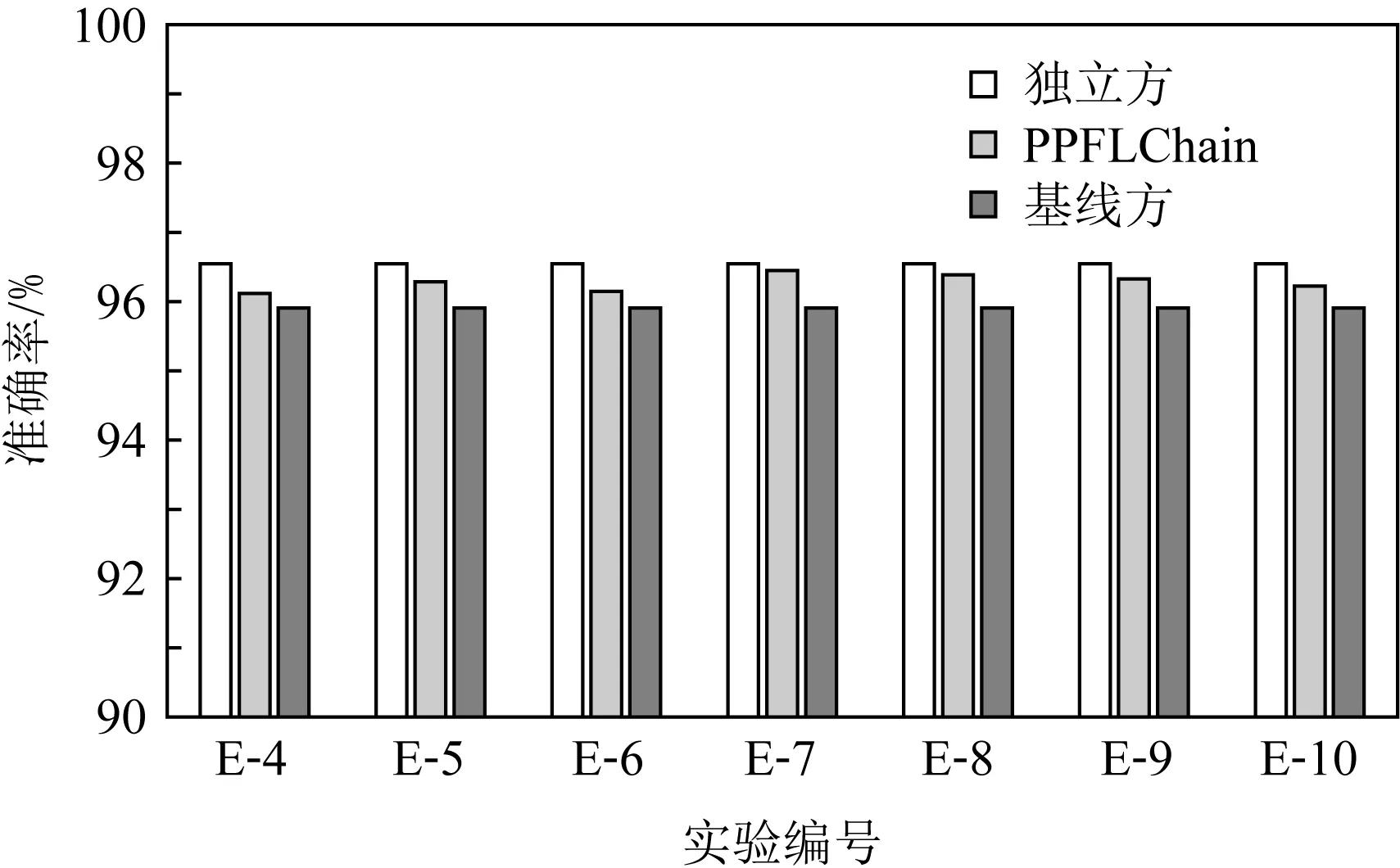


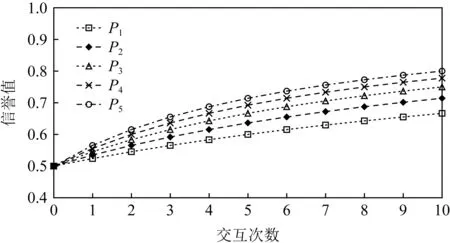
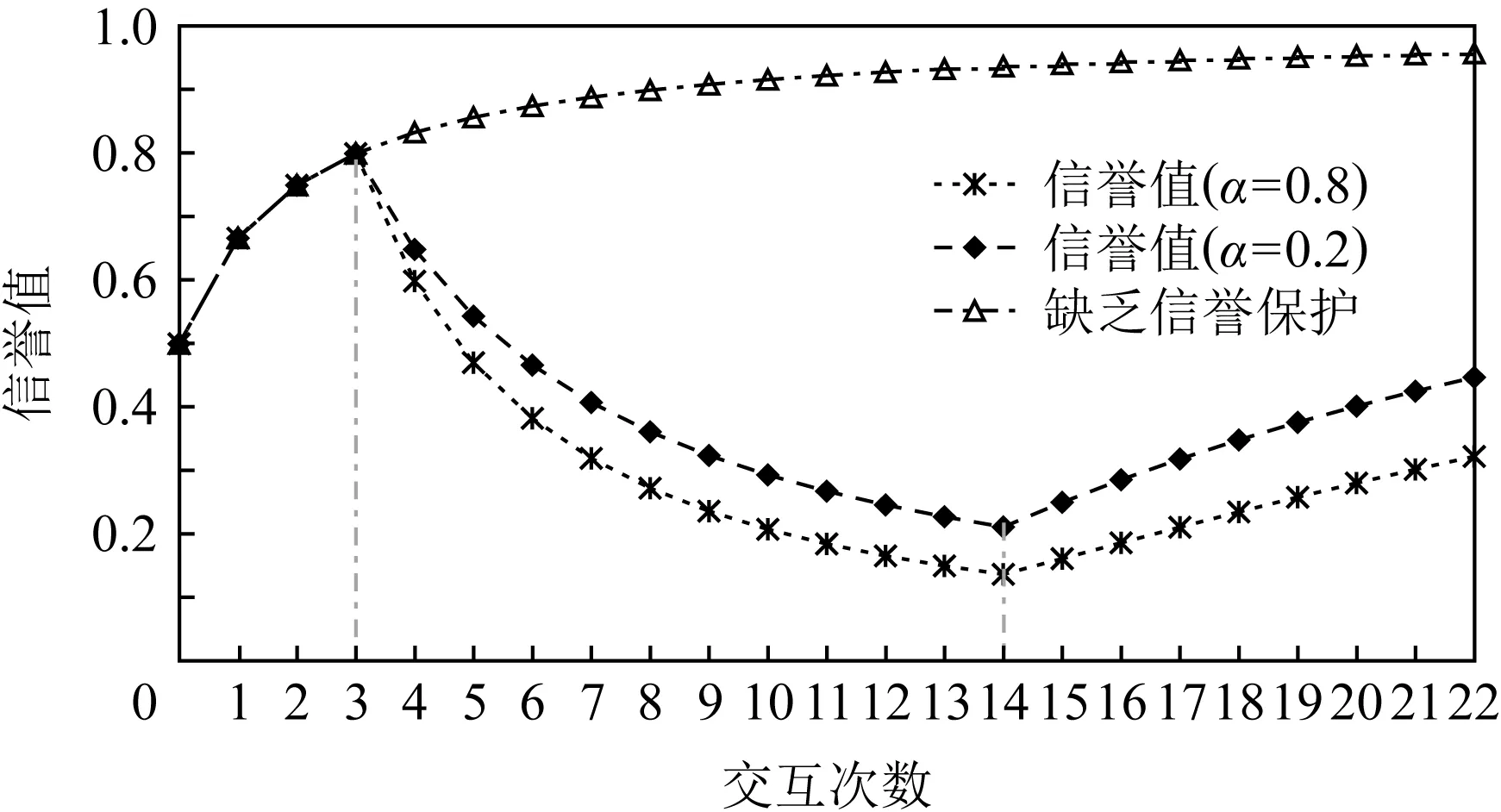
7 总 结
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:16:26
计算机研究与发展(2022年10期)2022-10-14 06:02:26
计算机应用文摘·触控(2022年8期)2022-05-25 13:27:53
西安电子科技大学学报(2022年1期)2022-04-26 06:50:12
华人时刊(2019年13期)2019-11-26 00:54:42
科学与财富(2018年33期)2018-01-02 11:55:50
物联网技术(2016年8期)2016-12-02 14:27:53
中国房地产·学术版(2016年7期)2016-10-21 15:17:01
专利代理(2016年1期)2016-05-17 06:14:03
项目管理技术(2016年10期)2016-05-17 05:39:44
