
数据驱动的应用自适应技术综述
2022-11-12 11:28:50涂志莹
计算机研究与发展 2022年11期
代 浩 金 铭 陈 星 李 楠 涂志莹 王 洋
1(中国科学院深圳先进技术研究院 广东深圳 518055) 2(福州大学计算机与大数据学院 福州 350108) 3(哈尔滨工业大学计算机科学与技术学院 哈尔滨 150006)
应用自适应一直是软件工程和服务计算中的一个热点问题,Laddaga[1]和Salehie等人[2]给出了自适应相对精确的定义:“自适应系统旨在通过调整各种组件或属性,以响应自身或是环境的变化.这里的自身是指软件系统,而环境则是指包含操作环境中影响系统行为和属性的一切因素.因此自适应系统是一个包含了自身和环境反馈的闭环系统.”
传统软件自适应往往讨论的是单个软件程序的自适应过程,但当今大数据时代的信息系统往往相当复杂,已经不再是一个以独立应用为主体的系统,而是以多个应用间的协同来实现一个服务的系统,所以本文中讨论的自适应应用是一个相对广义上的服务计算系统,如云服务系统、智慧家居系统、智慧交通系统、人脸识别系统等,这类系统往往具有多流程、多组件、多模态、分布式等特点,因此通过自适应可调整的功能空间非常巨大、也更加复杂.因此,传统的软件自适应系统(self-adaptive systems, SAS)主要从软件的需求、结构、行为、环境等方面考虑如何实现自适应,通过因果网络、时序逻辑、概率模型以及控制论等方法,对系统和环境进行建模和规划.这些方法大部分基于软件代码或组件层面,在软件设计和软件配置过程中实现自适应模块.本文中我们则重点关注的是大型系统的环境感知和自适应规划,侧重于从系统的流程、资源等方面实现自适应管理系统,利用这些分布式系统中的大量日志数据等实现自适应感知和规划.以一个典型的智慧家居应用为例,应用将在用户设定的闹钟前30 min自动关闭空调,并开始煮咖啡,当咖啡煮好之后,打开卧室的灯光,并播放音乐唤醒用户,接着在用户离开卧室之后自动关闭灯光,并开始播放新闻.可以看出,这样一个基础的应用是由多个不同的流程组合而成,这些流程是可以按照一定的规则重新组合的.同时,这个应用所处的环境是充满了不确定性的,如用户提前起床、家里停水等,如何针对这种非确定性的运行环境来对流程进行自适应,是本文重点探讨的目标.
自适应发生在对运行环境中发生的事件的反应中,应用可以在运行时改变自身流程,以便在不同的情况下为用户提供高效、便捷的功能.系统需要自适应的原因有很多,如用户环境的状态发生改变,需要不同的交互模式;由于服务调用失败,导致应用不再可用;由于临时的高计算负载,计算设备的资源条件发生了变化等.现代信息系统,包括物流分单系统、高频交易系统、交通调度系统、自动驾驶系统等,这些系统的特点是需要持续保持运行态,一旦服务宕机则将会造成难以估量的损失.对于物流、金融等应用场景的应用故障可能会造成直接的经济损失,而对于一些工业、交通等场景,甚至可能造成更严重的后果.而且,这些系统面对的场景是复杂多变的,比如物流系统中不规范的用户输入、交通调度中异常的行驶车辆等,更普遍的是,由于这些系统往往集成了以物联网为代表的移动计算设备以及各种各样的传感器,导致大大增加了监测设备故障和复杂网络带来的环境异常风险.这些风险在系统设计阶段往往是难以预见的,所以如何在保障系统在正常运行的前提下,通过自适应技术使得系统面对异常故障也能提供稳定鲁棒的正常服务,是现代信息系统中亟待解决的问题.
简而言之,应用的自适应旨在自动做出决策,使用户不必手动地将应用程序从一种操作模式切换到另一种操作模式.传统自适应往往需要预定义规则,而对于如今广义的复杂系统,人工预设规则意味着巨大的工作量.与此同时,预设规则式自适应需要事先嵌入静态的自适应逻辑,其只能对固定范围内的环境变化做出反应,对于超出范围的环境变化则缺乏适应性.此外,这种方法需要设计者具备一定的专业领域知识,往往只能解决特定问题,泛化能力较弱.为了解决这些问题,数据驱动的方法近年来越来越受研究人员的重视.数据驱动并不依赖于系统的数学模型或专家知识,而是用数理统计和机器学习等方法来挖掘离线和在线数据中隐含的有用信息,提升自适应系统的适用范围和在线规划能力,形成自动化的决策模型.数据驱动的应用自适应系统具有感知性、适应性、自治性和协作性四大特点,对于系统的不确定性具有更强鲁棒性.
1 自适应驱动技术
应用自适应可以分为规则驱动和数据驱动2种类型[3].规则驱动即是利用相应的专家领域知识进行数学建模,预先生成固定的规则模型来进行应用自适应;数据驱动则不再依赖于已知的数学模型,而是直接从系统在线或离线的数据中获取对应的知识,因此,其对系统的先验知识要求较少.规则驱动与数据驱动一个比较大的区别在于,规则驱动的系统模型是已知且可以预设的,而数据驱动往往将系统看作一个黑盒,算法并不关心系统内部结构,而是通过输入输出数据训练出的数学模型来拟合系统模型.
1.1 规则驱动
规则驱动方法通常有2种:一种是方法通过标准的知识工程方法获得的上下文知识,然后根据所获得的知识,使用如基于逻辑的形式方法[4-5]来表示规则模型,将系统模型用抽象逻辑表示出来,利用形式推理技术来针对环境改变进行自适应决策.由于在自适应的过程中存在着大量的不确定性,因此通过逻辑推理的优点在于可以将这种不确定性形式化为确定的逻辑表达式,从而执行对应的自适应规则.基于这个思路,Cámara等人[6]提出了一种通过推理来实现有人类参与的系统自适应技术.由于人类参与者的行为受到很多外部因素(如疲劳度、熟练度等)的影响会为系统带来很大的不确定性,Cámara等人通过显式建模的方法,将人类参与者和系统交互的影响因素通过逻辑语言形式化地表示出来,从而实现系统的自适应.进一步地,Cámara等人在另一篇文献[5]中还提出了一种形式化分析技术来量化考虑感知不确定性的潜在好处,并结合形式推理技术来改进不确定性产生的影响.这种基于逻辑表达的方法虽然有着优秀的可解释性和鲁棒性,但是对系统设计者的要求较高,并且需要结合一定的专业领域背景知识,因此难以被广泛应用.
另一种方法则是基于本体的建模方法,使用基于标记语言的本体来描述相关的上下文知识[7],应用从本体检索到的知识来分析环境更改造成的影响,从而创建一个适应计划来响应变更.从近几年的文献来看,基于本体建模方法因为具有一般性和可复用的特点,所以更受到研究者们的青睐[7-9].基于本体建模的自适应方法,需要针对特定的应用领域开发本体,来作为交互应用模块中机器可理解的知识库.运行时决策模块根据本体和收集到的信息推断出新的事实,执行对系统变化(包括外部环境变化或内部状态更改等)的反应操作,如重新配置、申请资源、流程修改等,从而实现应用的自适应.这种方法被广泛运用于各种自适应场景中,例如Chen等人[7]提出了一种基于知识驱动的智慧家居活动识别方法,该方法使用了基于描述逻辑的标记语言来构建本体,本体可以被看作是通过基于活动属性在活动和上下文信息之间建立联系的模型,该模型对传感器数据和活动进行统一的本体建模和表示,不仅方便了领域知识的重用,而且允许利用语义推理进行活动识别.同样,Evesti等人[8]也提出了一个用于安全自适应的本体建模方法,与Chen等人提出的方法不同的是,这个方法将知识从自适应架构中分离出来,同时给出了从架构到知识的映射,由于本体本身包含了自适应的知识,这种安全自适应方法不需要为分析和规划阶段做规则的硬编码.Zhou等人[9]则将基于本体的建模方法应用在工业控制领域,使用本体建模集成了一个知识驱动的自适应控制模块来监测和分析应用的变化,实现系统的自适应,开发人员通过特定领域模型来构建控制系统的逻辑和功能,然后根据知识库上的语义查询增强的Web规则语言(semantic query-enhanced Web rule language, SQWRL)查询自动推断症状和动作请求,实现了一个用于自动重新配置的工业控制系统.但是这种方法通常是预先计算和设计好了相关的领域知识,并不能随着应用的运行进行自动化学习,因此Huang等人[10]根据软件定义网络(software defined network, SDN)的设计原则和上下文认知过程,提出了一种上下文驱动的智慧家居控制机制(smart home control mechanism, SHCM),通过将机器学习(machine learning, ML)算法和本体模型集成到上下文认知过程中,提高了智慧家居控制系统的上下文感知自动化水平.该机制通过挖掘不同感知应用中固有的多属性上下文特征,建立隐含的聚类和关联规则,并利用本体模型实现自动化的集成上下文管理,智能家居设备通过上下文驱动的控制策略在数据层实现上下文反馈.
规则驱动模型语义清晰,表示方法统一,无冷启动问题,能建立可重用的模型,方便扩展到规模更大的环境中.但是,虽然规则驱动的方法具有较好的稳定性,却不能处理不确定性问题,它们使用的是基于一般知识的推理,如模糊逻辑和概率推理,而不是通过历史数据来进行统计分析,因此基于这类方法的自适应系统对于实时环境变化的敏感性较差,但是可解释性较好.
1.2 数据驱动
与规则驱动方法相比,数据驱动方法的强大之处在于其可以利用实时产生的海量数据,来获取系统的动态反馈,并据此进行建模.数据驱动方法将数据进行组织形成信息,之后对相关的信息进行整合和提炼,在数据的基础上经过训练和拟合形成自动化的决策模型,当有新的数据输入、产生新情况时系统用之前拟合形成的模型和人工智能的方式直接进行决策,因此数据驱动方法具有更好的鲁棒性和适应性[11].
目前主流的数据驱动方法主要是利用了机器学习从数据中建模,其中经典的监督学习方法有2种:一种是生成方法,它试图建立输入或数据空间的完整描述,通常使用诸如用于活动建模的Markov模型[12]和贝叶斯网络[13]等概率分析方法.使用生成模型的好处在于可以为系统环境进行建模,方便对系统环境进行深入的分析,并设计出更加高效和可解释的自适应方法,例如将系统状态的变迁拟合为一个Markov决策过程(Markov decision process, MDP),从而挖掘出不同系统状态之间的关联.这种概率表示的方法有效降低了为复杂环境交互建模的难度,但同时也存在一个缺点,即每次环境变化时都需要重新构造MDP.因此,Moreno等人[14-15]提出了一种在离线时构造MDP、在线时通过随机动态规划进行自适应决策的方法,这种方法显著地减少了在数据量级上自适应的运行时间,并保证自适应的结果一致.构造MDP是需要在对于系统状态有全面了解的前提下设计的,事实上大部分情况下设计者并不能获得所有的环境信息,因此Paucar等人[16]提出了使用部分可观测的Markov决策过程(partially observable Markov decision process, POMDP)对系统进行建模的方法,根据监测模块的数据结合贝叶斯推理来生成和更新POMDP模型,进而支撑系统自适应,这种方法摆脱了需要对运行环境整体进行建模的前提,因而更具有现实意义和实用价值.当然,这些方法都是通过调整概率模型参数的初始值来实现预测,所以主要缺点是模型在概率变量配置方面是静态和主观的.另一种则是判别方法,它只对从输入数据到输出活动标签的映射建模,判别方法包括许多分类方法,例如k近邻(k-nearest neighbor, KNN)[17]、决策树(decision tree, DT)[18]、支持向量机(support vector machine, SVM)[19]等.Li等人[20]基于数据驱动方法设计了一个对于个人健康活动进行规划和建议的自适应应用,通过聚类算法从历史数据中识别出典型的活动模式以及目标,结合历史数据的周期性预测目标是否能够实现,然后对实时数据应用线性二次型调节器(linear quadratic regulator, LQR)算法实现活动流程的自适应调整.Muccini等人[21]则提出了一种在基于机器学习的物联网架构中执行主动自适应的方法,该方法利用长短期记忆(long short-term memory, LSTM)[22]算法对长时依赖的敏感性,从传感器的日志数据中识别出物联网架构中不同组件的模式来优化系统的服务质量(quality of service, QoS).Bao等人[23]针对分布式机器学习的工作负载中不同作业的放置问题,提出一种深度学习(deep learning, DL)驱动的机器学习集群调度器,该调度器使用深度神经网络(deep neural network, DNN)对奖励值进行建模,构建了一个辅助奖励预测模型,然后实现了基于深度强化学习(deep reinforcement learning, DRL)框架的自适应调度器,实验表明这种调度器的性能优于一些典型的传统调度器.
数据驱动方法虽然具有处理时间信息和空间信息不确定性的能力,但大多需要大量训练和学习数据集来建立预测模型,因此会出现“数据不足”或“冷启动”问题.不幸的是,数据不足仍是目前广泛存在于真实世界系统中的一大问题.
1.3 小 结
规则驱动与数据驱动的对比如表1所示.虽然数据驱动比规则驱动需要更少的专家领域知识,实现上也更为简单,但却不能避免冷启动的问题;而规则驱动技术可用于预测,并遵循基于描述的方法来建模传感器数据和活动之间的关系,但它不能很好地处理不确定性问题和时间信息,所以有许多研究是结合了数据驱动与规则驱动这两者的优点来实现的.

Table 1 Comparison Between Rule-Driven and Data-Driven表1 规则驱动与数据驱动对比
例如Gayathri等人[24]提出了一种利用Markov逻辑网络(Markov logic network, MLN)将概率推理集成到领域本体中,将统计学习方法与本体论相结合,将语义转换为一阶规则,并利用数据学习规则的权值,从而提高活动识别的精度.还有一种结合方式是在初始阶段以规则驱动建模,再利用数据驱动方法来对自适应系统进行调整优化.如Sukor等人[25]提出的一种将规则驱动与数据驱动推理相结合的方法,使活动模型能够根据用户的特性自演化和自适应.该方法首先使用基于规则驱动的活动模型推理方法作为初始模型,然后使用数据驱动技术对模型进行训练,生成一个动态活动模型来学习用户的各种操作.该方法在一些公共数据集进行了评估,实验结果表明与其他模型相比,学习活动模型获得了更高的识别率.受此工作启发,Wang等人[26]将在线强化学习与历史决策库相结合,基于软件定义的方式,实现了城域网中虚拟服务的高效自适应迁移,以更低的成本和更高的QoS满足用户的服务请求.因此,一种比较合理的结合方式,在数据驱动的自适应框架中引入部分包含先验知识的规则驱动方法作为补充.
2 自适应框架
作为一种有效地处理系统复杂性、不确定性和动态性的系统,自适应系统中有很多不同的框架来实现,如观察—定向—决策—行动(observe-orient-decide-act, OODA)[27]、知识密集型数据处理系统(knowledge intensive data processing system, KIDS)[28-29]框架等.这些框架大多都包含了一些关键的模块,如评估、规划等,当然,目前最有影响力的参考控制模型是通过MAPE-K(monitor-analyze-plan-execute knowledge)来实现的[30],相对于KIDS,MAPE-K多加了一个知识库,用于存储自适应的相关知识规则.MAPE-K是一个由“监测—分析—决策—执行—知识”组成的循环序列,这些组件分别用于分析监控数据、规划响应动作、执行这些动作,这种闭环控制具有更好的适应性和鲁棒性,可以使系统在变化不确定的运行环境下自适应运行,MAPE-K的框架结构如图1所示.MAPE-K的框架目前广泛应用于各种自适应系统中,包括软件自适应[30]、智能家居自适应[31-32]、工作流自适应[33]、云计算自适应[34-35]等.

Fig. 1 MAPE-K architecture图1 MAPE-K架构
自适应是指在环境或自身发生变化时,对自身进行规划和调整.然而,一个重要而又容易被忽略的问题是,对于连续的监测结果来说,这种变化什么时候需要自适应系统做出调整(即是否存在一个监测值的临界点,导致自适应系统需要对应地做出调整).除此之外,决定启动自适应的时间点也是非常重要的,因为不同时间点做出规划的效率会随着环境的变化而变化,随之而来的是成本的变化,例如计划延迟会导致额外的资源、能源消耗等.因此Chen等人[36]设计的自适应框架DLDA(debt learning driven adaptation)中,创新性地加入了一个二分类器,用于判别什么时候执行自适应调整.DLDA的架构如图2所示,分类器(classifier)根据前一个状态和当前状态判断出是否需要自适应,需要则利用规划器(planner)进行自适应调整,不需要则系统不进行调整.
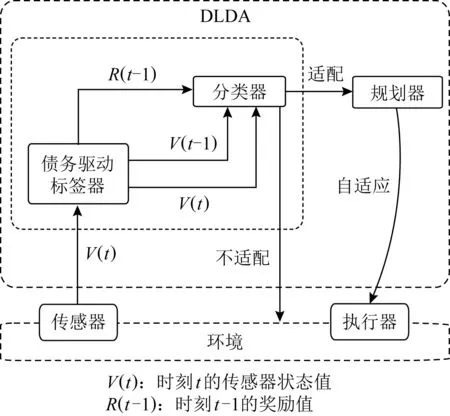
Fig. 2 DLDA architecture图2 DLDA架构
对于复杂的计算系统,我们以一个实际的应用场景来分析,在智能家居领域自适应的应用中,通过应用的Log日志识别出各类活动(或事件),这些活动通过挖掘算法和机器学习方法使其在概念逻辑、时空方位上关联,由此导出不同场景的自适应规则和事件图谱(流程).在获得规则模型和特征模型后,利用活动的上下文语义关系及目标-特征的耦合关系,建立特征对目标的量化支撑函数,最后再依照用户的需求偏好,通过目标-特征的最优匹配(全局目标最大化)绑定,完成对用户活动流程的自适应.
从图1可以看出,数据驱动的自适应已经不再是简单的“监测—分析—决策—执行”的循环,而是一个极端复杂和智能的优化过程.我们从认知计算的理性思维适应性控制(adaptive control of thought-rational, ACT-R)框架中得到了一些启发,ACT-R是卡内基梅隆大学的Anderson等人[37]建立的一个人类认知理论框架模型,其思路是在对环境进行统计分析的基础上,使得知识的获得和调用过程随环境而发生改变,实现系统的自适应性,这正符合人类针对环境的自适应认知过程.ACT-R包含了对环境的感知和对数据模式的理解,并从中做出最优的决策,而且认知计算可以从大量数据中归纳出新的知识,类似于人的认知能力.
因此,我们认为一个完整的数据驱动应用自适应系统应该包含4个功能:1)从复杂的环境中提取日志、图像等数据特征;2)从数据特征中挖掘识别出环境和应用的流程模式;3)识别出当前的流程模式,进行自适应的适配;4)当适配无法实现系统功能时,需要对现有的规则进行演化来补充支持系统的自适应.基于这4个功能,我们认为一个自适应框架应该是如图3所示的.

Fig. 3 The architecture of data-driven self-adaptive system图3 数据驱动的自适应系统架构
如图3所示,应用产生的传感器数据通过表征学习模块进行预处理和特征提取;模式识别则负责从特征中识别出应用的场景,理解用户的活动模式和意图,并对正在进行的活动进行监测反馈;决策规划模块通过结合实时的特征、应用的情景以及当前活动来对系统进行动态的自适应调整;评估器将对产生的策略和环境进行匹配,当不匹配时调用规则演化模块生成新规则以适应当前环境,匹配时则直接进行执行该策略;规则演化则是为了应对数据不足或冷启动,以及规则异常的问题,通过引入部分专家知识或是其他领域知识来演化出新的规则.因此,接下来我们将分别介绍应用自适应框架中用到的这4种主要技术:表征学习(represent learning)、模式识别(pattern recognition)、决策规划(decision plan)、规则演化(rule evolution).
3 表征学习
原始数据一般是复杂异构的,包含了如时空数据、图片、语音等,这些原始数据通常具有异构、稀疏、高秩等特点,并不能直接提供给学习系统使用.因此,原始数据需要通过相应的算法转换为低秩的特征向量,剔除原始数据中冗余或无关的信息,提高机器学习预测或分类的性能效率,同时也加强了模型的可解释性.表征学习通常包含数据清洗、特征提取、压缩感知、多源融合等技术,具有智能性、主动性、自适应性等特点.
这种转换根据是否需要人工干预,可分为特征工程和表征学习2种.传统的特征工程依赖于专家领域知识提取显式的特征,因此人工工程量较大,选择的特征质量也将影响后续的任务质量;表征学习则是自动学习数据的隐式特征,并不依赖于专家经验,而是通过与后续任务进行联合训练来提取特征,其目标不是通过学习原始数据预测某个观察结果,而是学习数据的底层结构(underlying structure, US),因此往往需要大量的数据集.对于高维且复杂的异构数据(如图片、视频、文字、语音等),使用依赖人工的特征工程来提取特征显然不太切合实际;而表征学习则借助算法使机器自动地学习数据的特征,在大量的数据集下自动的表征学习显然更有效率.
最早的表征学习算法是1901年Pearson[38]提出了主成分分析(principal component analysis, PCA)以及其衍生的一些变体,用线性投影的方法学习数据的低维度特征.这类算法被称为无监督表征学习算法,除PCA外还包含了无监督字典学习(unsuper-vised dictionary learning, UDL)[39]、独立成分分析(independent component analysis, ICA)[40]、自动编码(auto-encoders, AE)[41]和矩阵分解(matrix factorization, MF)[42]等.
与之相对的则是监督式的表征学习算法,这类是目前更为通用的学习算法,如神经网络主要是指现在流行的深度学习方法[43].近年来,深度学习的发展主要得益于3个方面巨大的进步:表征学习、大规模数据集、通用图形处理单元(general-purpose graphics processing unit, GPGPU)[44].深度学习以较好的通用性、自动化等特性,正在自然语言处理、计算机视觉、语音识别、推荐系统等领域大展身手,其除了应用于结构化数据外,也适用于非结构化数据的特征表示,表2中列举了一些典型的数据表征学习算法.深度学习模型通常是“端到端”的,即没有特定的区分表征学习和最终的学习任务,实际上我们可以将模型中隐藏层的作用看作是在进行表征学习.

Table 2 Typical Represent Learning Algorithms表2 典型的表征学习算法
如表2所示,深度学习在非结构化数据的表征学习中有着广泛的应用,这类算法可以从非结构化数据中提取出有效的结构化特征,用于支持后续如预测、分类等任务.例如在图像领域,原始的图像存在大量无意义的像素点,有效的应该是图像边缘轮廓以及局部模式等,通过卷积神经网络(convolutional neural network, CNN)等算法可以去除图像的信息冗余,实现图像分割和边缘检测,提取出对应的图像特征,实现特征的高效压缩,如Pan等人[70]使用空间卷积神经网络(spatial CNN, SCNN)来做交通场景图像的理解,Rawat等人[71]也使用CNN提取图像上下文信息来提升多标签分类的准确率.深度神经网络还可以提取深层的高级表示,这使其更适合复杂的活动识别任务,其逐层结构允许可伸缩地从简单到抽象的特征学习,并且可分离性使得其可以灵活地组合成具有一个整体优化功能的统一网络.这些优势使得深度学习目前在表征学习中占据着主导地位.
表征学习目前是一个比较活跃的领域,是机器感知和理解真实环境的重要技术,其本质是一种应对高维数据的自动化降维算法.随着人工智能的发展,面对的数据开始由原来的小规模、结构化、规范化的数据集转向大规模、非结构化、繁冗的数据集,应用场景也开始转向通用化、自动化.因此,表征学习也开始以深度学习为主,趋向于更加的普适、通用和更好的泛化能力.
4 模式识别
模式识别是一种用计算机模拟人类识别行为的技术,可以让计算机通过观察环境,学习如何从环境中识别感兴趣的模式,实现对环境模式的分类[72].模式识别的目的是从数据中挖掘出潜在的模式,数据包括地理位置、操作日志、时间序列等,我们将其分为识别上下文信息等的情景感知(context-aware)和挖掘用户行为的活动识别(activity recognition)2个模块.
4.1 情景感知
情景感知技术最初是由Schilit等人[73]提出,又被称为上下文感知,主要是指系统通过采集周围环境参数,对时间、空间元素进行分析,实现对环境的感知和理解能力,自动获取和发现用户需求,建立一种自适应调整机制,向用户提供适合当前情形的信息或服务,提高服务的准确性和可靠性.对于一个复杂动态的应用系统,情景感知可以根据从环境数据中提取的特征推理出系统运行的上下文.
表征学习从原始数据中提取有效的特征,情景感知技术则根据这些特征对复杂多变的上下文进行提取、融合、解释和识别,推理出有用的实体状态和动态信息,指导决策系统提供正确、自适应的服务.情景推理可分为确定性推理和非确定性推理2类,确定性推理一般基于预设的情景,在传统计算中取得了较好的效果;然而如今的上下文信息具有多样性、不确定性和动态性等特点,因此更需要的是非确定性推理方法[74].
典型的情景推理方法有模糊推理、本体推理和D-S(Dempster-Shafer)证据推理等,此外,由于数据的不确定性和不完备性,所以机器学习方法也被广泛应用于复杂的情景推理中,包括人工神经网络、决策树、隐Markov模型、KNN、贝叶斯网络、支持向量机等.例如,在移动计算领域,通过移动端的定位数据、附近可见蓝牙设备和WIFI接入点等数据,结合聚类算法推理移动端所处的场景,如家庭、办公室、度假等[75].Rana等人[76]则设计了一个基于上下文的噪音映射系统,通过对传感器数据应用KNN近邻算法来推理智能手机的场景,如口袋、钱包或手持.我们将分别讨论这些在情景推理中常用的算法.
1) 规则推理.通过IF-ELSE结构来匹配合适的规则,进行情景的推断.规则的来源可以是基于专家知识预定义的,也可以是结合本体建模所产生的规则.这种方式实现简单、稳定性好,但对于复杂多变的环境适应性不足.
2) 本体推理.依赖于逻辑描述,通过本体建模数据实现推理.本体推理使用语义语言,如RDF(resource description framework),RDFS(RDF schema),OWL(Web ontology language)来实现推理,本体推理的优点是可以与本体建模相结合.
3) 模糊逻辑.结合模糊集合和模糊规则进行推理,相较于传统逻辑,引入了更多处理不确定性和未知的能力.通常模糊逻辑与本体论、概率模型、规则推理结合在一起使用.
4) 概率逻辑.基于对事件概率和事实计算,运用数理逻辑与概率理论对归纳逻辑、归纳方法进行形式化、数量化的研究.通常利用D-S证据理论或隐Markov模型来进行多源数据的融合,以及对下一个不确定状态提供预测等.
5) 监督学习.通过收集标记的应用数据来进行模型训练,训练好的模型将用于情景的推理.监督学习被广泛运用于各种场景,各种模型也层出不穷,如贝叶斯网络、支持向量机、决策树以及目前炙手可热的神经网络等,这些方法被应用于模式识别、事件关联等情景推理场景中.
6) 非监督学习.由于数据的标记难以获取,所以非监督学习也常常用于无标记的数据中,从中提取出一些有意义的结果.例如使用K-Means等聚类算法可以从数据中推理出一些相关上下文,或者对环境感知中获取的数据进行噪声和离群点的检测和区分.
以本体推理、模糊逻辑等为主的情景感知方法通常需要结合一定的专家知识,以规则为导向进行推理,这类方法的优点是稳定性好,但缺点也很明显,即对于不确定的环境缺乏处理未知的能力.而使用机器学习的方法则脱离了对专家知识的依赖,模型几乎完全来源于数据的模式,其优点是模型可以处理未知的环境,从数据中挖掘出非预设的规则,而缺点则是稳定性较差,生成的规则并不一定符合真实情况.目前的研究趋势是机器学习方法与本体建模、模糊逻辑结合,实现混合推理模型.例如Roy等人[77]提出了使用结合本体预定义规则和贝叶斯网络的模型来识别高层级的上下文情景,这种方式结合了数据融合和语义分析,从而促进了情景识别的准确率.
4.2 活动识别
活动识别是泛在计算、人类行为分析和人机交互研究的一个重要领域,其旨在通过对用户行为和环境条件的观察,识别出用户的行为和目标[78],并检测出对应的活动模式.活动识别可以看作是一个典型的模式识别问题[79],通过从数据中识别出当前的活动模式,指导应用程序预测下一步的流程,进行一定的自适应调整和规划.活动识别能更好地辅助计算机理解用户目标和意图;帮助计算机应用更智能化、适应性地完成任务,因此被广泛应用于各种互联网领域,如广告推荐、个性化定制、安全防控、运动监测、医疗康复等.
传统的活动识别使用经典的数学模型和数理统计来进行建模分析,相对而言,数据挖掘和机器学习则能更有效地从数据中提取知识、发现知识和推理活动[80].活动识别的机器学习研究方法多种多样,包括朴素贝叶斯(Naive Bayes)[81]、决策树[82]、隐Markov模型(hidden Markov model, HMM)[83]、条件随机场(conditional random field, CRF)[84]、KNN[85]、支持向量机[86]、集成学习(ensemble learning)等算法.
可以看出,活动识别主要使用了分类算法,而深度学习作为机器学习的一个重要新分支,利用其对数据的高阶特征建模分析的能力来挖掘用户行为模式,也成为了活动识别的一个重要趋势.正如介绍表征学习时所提到的,神经网络可以提取出数据间隐含的关联关系.如CNN具有局部依赖性和尺度不变性,能捕获数据的空间关联[87];循环神经网络(recurrent neural network, RNN)则能结合时间层,获取数据的时间序列信息[88].对于输出层,深度学习的分类通常是用softmax回归作为输出,形式为

(1)
分类算法通常使用交叉验证技术来对模型进行评估训练,常用的评价指标的定义如表3所示,其中的一些符号定义如下:1)TP(true positive),将正类预测为正类;2)FN(false negative),将正类预测为负类;3)FP(false positive),将负类预测为正类;4)TN(true negative),将负类预测为负类.

Table 3 Most Used Metrics for Classification表3 常用于分类的评价指标
对于活动识别来说,标记数据对于模型训练是很重要的.利用标记数据来训练模型,实现的活动识别只能针对于已经被标记的活动.而实际环境中,能够获得的有标记数据十分稀少,一个重要的挑战便是从未标记的数据中进行活动识别.对于稀少的标记数据与未标记数据混合的情况,通常采用半监督学习来解决标注缺少的问题.半监督学习通过对有标注数据进行预训练,然后对未标注的数据进行分类,得到带有伪标签的数据.对伪标注数据进行评估,从中挑选出可信的样本加入训练集,提升分类精度.这类算法包括直推学习支持向量机(transductive support vector machine, TSVM)[89],半监督支持向量机(semi-supervised support vector machine, S3VM)[90],图论半监督学习等.
而对于完全未标记的数据,则需要通过无监督学习从训练集中识别出一些固有的模式,然后根据生成的模型,识别出这些固有模式.常用的无监督学习有高斯混合模型(Gaussian mixture models, GMM)、层次凝聚聚类(hierarchical agglomerative clustering, HAC)、DBScan聚类、K-Means聚类等.通过聚类算法,可以将数据划分为不同的簇,每个簇包含了一些特定的活动模型,从而区分出一些频繁重复的活动模式.例如Gupta等人[91]设计了一个自适应的活动识别框架,该框架分为离线挖掘和在线识别2部分,离线挖掘通过聚类等算法从历史数据中识别出一些频繁的活动模式;而在线识别则从离线挖掘的标签中训练出分类模型,来对在线数据进行活动的分类,从而实现实时的活动识别.表4列出了一些在活动识别中常用的公开数据集.

Table 4 Most Used Activity Recognization Datasets表4 常用的活动识别数据集
除了数据标记之外,活动识别中还有一个重要的挑战,数据具有非常强烈的个性化特征和环境特征,这意味着训练集中的数据具有某种特定的偏向性,这种偏向性会导致不可避免的泛化误差.为了解决这个问题,Jiang等人[98]提出了一个基于深度学习活动识别框架,它包含了2个识别器:领域识别器和活动识别器.领域识别器可以识别出相关的环境或是主题;而活动识别器则除了进行活动识别之外,还试图欺骗领域识别器,从而学习与环境或主题无关的表征.这种架构可以消除环境和主题中包含的特定信息特征,从而提升活动识别模型的泛化能力和鲁棒性.
4.3 小 结
模式识别是一种通过数学方法形成应用理解和认识环境的能力,我们在自适应中将其分为情景感知和活动识别2类.情景感知通过从环境中采集的参数特征,感知和理解应用所处的外部环境,辅助应用识别出应用场景,进行资源和应用的适配,提升服务质量;活动识别则是从应用的日志数据中挖掘出用户和应用活动的一些频繁模式,从而理解用户的行为意图,预判下一步的用户行为,辅助应用更好和更智能的资源规划和流程自适应.
情景感知和活动识别都是从数据中挖掘出有效信息,改善应用服务质量,因此不可避免地有一些共用的缺陷,如标注数据稀少、样本分布不均衡等.数据驱动的方法通常需要在每个场景下为每个用户都提供足够多的训练数据,但采集这样的标记样本成本是相当昂贵的,这严重阻碍了应用系统的自适应能力.近年来有不少的研究致力于解决这些问题,也提出了许多解决方案.数据增强便是一种人为扩展有标注训练数据集的技术,包括对样本集进行随机过采样,通过数学变换函数生成数据,引入噪声生成器来模糊原始数据集等.如文献[99]提出的一种用户自适应模型(user adaptive model, UAM),通过随机采样技术,使用少量的训练集(10%)即可大幅度提高活动识别的精度.生成对抗网络(genera-tive adversarial network, GAN)同样是一种用于数据增强的技术.GAN由生成网络和判别网络组成,生成网络通过随机噪声生成训练数据,判别网络则利用实际数据训练出的判别模型判别生成的数据是否可用,借助2人零和博弈的思想,在对抗与生成的交替中提升2种模型精度.例如Yang等人[100]提出了一个基于GAN的模型OpenGAN,用于解决开放集活动识别的问题,OpenGAN的生成器负责合成样本,用于构建样本集,提高活动识别的精度.
主动学习(active learning)也是一种针对数据标签稀少场景的算法,主要思想是模型通过与用户或专家进行交互,以查询的方式让专家确定数据标签.主动学习与半监督学习的区别在于主动学习中有专家的参与,通过算法筛选出一些对于模型训练有益的数据,以交互的方式让专家对这些数据进行标注.主动学习的难点在于如何筛选对于模型有益的数据,因此相比于半监督学习来说样本的使用效率更高.因此,一些研究也着力于使用主动学习来提升小样本时的识别精度[101]以及减少人工标记数据的成本[102].
5 决策规划
通过表征学习和模式识别,自适应系统具备了感知和分析环境变化的能力.在此基础上,自适应系统将根据环境变化和挖掘的相关规则进行在线规划和决策,动态调整应用的行为或流程,从而可以以最佳的性能实现应用功能,满足用户需求.从描述中可以看出,自适应的在线决策规划本质是一个优化问题,优化的目标不仅是在满足应用需求的情况下实现性能最优,同时还需要在求解该问题的时间上做权衡,在满足在线应用的条件下达到一个最优或近似最优的解决方案.
典型的决策规划方法有基于预设规则的、基于概率模型的、基于最优化算法的等,这些方法各有优势与缺点.例如,基于预设规则的方法往往需要基于一定的专家知识,预设出一部分相对简单的规则,然后通过搜索和规则匹配来实现决策,这类方法虽然简单有效且时间复杂度低,但是并不能应对复杂的环境变化;基于概率模型的方法需要对环境变化建模,将其抽象为概率图来进行推理决策,这类方法同样具有较好的时间复杂度,但决策的有效性依赖于模型与真实环境的匹配度,而事实上概率模型往往并不能有效地表示一个复杂系统;同样,基于最优化算法的方法优势在于能从约束条件中求解出一个最优的或近似最优的解决方案,但随着求解空间规模的增大,这类方法往往需要极大的时间复杂度,这对于一些具有较大状态空间的系统或对于实时性要求较高的系统来说时间成本过高.
除此之外,近年来强化学习(reinforcement learning, RL)在决策领域的应用也越来越受重视.强化学习适用于与环境动态交互的场景,在不需要先验知识的情况下,通过最大化长期回报来学习完成目标的最优策略,从而实现实时决策.强化学习是一种从环境状态映射到动作的学习算法,这类方法通常将决策问题建模为Markov决策过程(MDP),MDP被定义为一个四元组(状态S,动作A,回报R,转移概率P),根据交互数据来优化决策以取得最佳的决策结果.目前有许多的研究工作都是以强化学习作为自适应系统的决策技术,其中大部分的研究重点是结合深度强化学习(DRL)与自适应应用.传统强化学习的动作空间和样本空间有限,而深度强化学习则以深度网络作为函数逼近器,能拟合更为复杂的状态空间和连续的动作空间.除这些方法外,也有不少研究尝试将控制论的方法应用在自适应系统中[103],这类方法更多地使用了控制学理论和动力学模型,主要运用于机器人控制等领域,接下来,我们将分别介绍概率模型、最优化算法和强化学习在自适应决策中的应用.
5.1 概率模型
现代应用的环境十分复杂,充满了各种不确定性,这些不确定性可能会导致自适应系统做出错误的决策,所以许多研究着力于如何表示不确定性以及通过一定的策略来减少不确定性.概率模型正是一类使用概率来表示不确定性的算法,通过计算条件概率和联合概率,可以准确地解释变量间的因果性和相关性,从而推导出客观事实,进行合理的决策.
事实上,使用概率分析进行决策有多种方法,通常是将学习决策模型转化为求概率分布,并计算联合概率和条件概率来表征因果关联.而变量间的这些关联关系往往非常复杂,多维的变量间都存在着相互依赖,导致直接求解的复杂度相当高,因此通常会使用图结构来表示变量间的依赖关系,这种模型被称为概率图模型(probabilistic graphical model, PGM).
概率图理论分为表示、推理和学习理论,广泛运用于人工智能、机器学习和计算机视觉等领域.概率图模型的一个核心的理论基础便是贝叶斯法则:
(2)
其中P(M)表示关于事件M的先验概率,P(M|N)为已知事件N发生后事件M的条件概率,也就是事件M的后验概率,学习的过程通常是根据数据分布来调整事件M的后验概率,使之更符合事实情况.概率图模型分为贝叶斯网络(Bayesian network, BN)和Markov随机场(Markov random field, MRF)两类,这两类包括一些经典模型,如隐Markov模型、条件随机场、高斯混合模型等.
概率模型在自适应决策规划中的应用,主要体现在解决自适应系统中的不确定性决策问题.例如,Naqvi等人[104]提出了一个用于自适应计算卸载的模型MAsCOT,为了针对即使没有全部信息的情况下也能做出这种考虑不确定性的推理决策,该模型使用了基于概率图模型的动态决策网络(dynamic decision networks, DDNs)进行运行时的决策,动态决策网络以最大化效用的概率加权期望作为优化目标,该模型由3种类型的节点组成:机会节点、决策节点和效用节点,3种节点组成了一个有向无环图(directed acyclic graph, DAG),通过结合图论和概率计算来估计条件概率分布(conditional probability distributions, CPDs),接着利用经验最大化(expec-tation maximum, EM)算法来选取最大效用的策略.Shi等人[105]同样也使用了贝叶斯网络来表征决策的概率依赖,由于自适应系统中存在的非确定性,他们提出了使用模糊逻辑来进行知识表示.由于贝叶斯网络通过更新节点概率来进行自适应推理的能力优于模糊逻辑,所以他们结合了2种方法进行态势预测,作为自适应决策的基础,通过对自适应系统的环境特征建立贝叶斯网络,并将模糊逻辑态势评价方法与实际博弈相结合,最后使用强化学习来学习有效的策略.与之相同的是,Epifani等人[106]也使用了贝叶斯估计器,利用从运行的系统中收集的数据来对模型进行更新,这种动态参数估计的方法能够帮助模型在运行时提供更好的系统表示,从而使模型与实际情况保持同步,逐步优化模型性能.
同时,对一个复杂随机的交互环境而言,构建一些经典模型(如MDP)是非常困难的,需要大量的人工经验进行抽象建模.而概率模型则可以以随机环境的形式化规范作为输入,通过概率分析网络将其转换为MDP进行求解[14-15].通过将系统建模为概率系统,可以使用概率模型检验来分析不确定系统,Cámara等人[5]基于此,在面对拒绝服务(denial of service, DoS)攻击的场景下,使用概率模型检查开发了应对非确定系统的自适应决策技术,有效地降低了决策的时间.但概率模型的缺点也很明显,不仅需要一定的建模能力,能表示的环境模型也有限,现今更多的研究是将概率模型与强化学习这类更为通用的模型结合,使用概率模型来提取环境,使用强化学习来学习策略.
5.2 最优化算法
最优化问题指在一定的约束条件下构造出一个合适的目标函数,如何求解使得这个目标函数达到极值,形式化的定义为
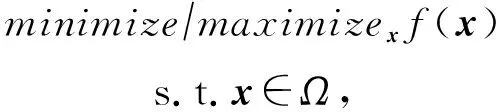
(3)
其中,f(x)是目标函数,x是决策变量,Ω是约束条件.解决最优化问题通常有2个步骤:1)对问题进行建模,构造约束条件和目标函数;2)根据一定的最优值搜索策略,在可行解中搜索最优解.常用的最优化算法分为2类:精确算法和近似算法.精确算法可以搜索出目标问题的最优解,这类方法包括线性规划、动态规划、整数规划和分支定界法等,这类算法复杂度较高,适合求解空间较小的问题;近似算法则通常只能求出问题的近似解,但面对求解空间庞大的问题,可以在多项式时间内以高概率逼近最优解,这类算法主要是包含了启发式算法,如模拟退火、禁忌搜索、蚁群算法、粒子群算法以及进化算法簇等.
在自适应系统中,目标函数通常设置为以执行过程中的效用为目标,并且是一个连续决策的问题,被管理系统和环境会随着时间的推移而进化,因而决策的时间也是一个重要的考虑因素.为了优化这个问题,Moreno等人[14]提出了一种以概率模型建模环境,但以随机动态规划替代概率模型检查来求解自适应决策,这种使用随机动态规划的方法比概率模型求解快了一个数量级.Nascimento等人[107]同样也使用了进化算法进行决策,结合多智能体系统(multi-agent system, MAS)设计了一个自适应系统,将其应用于物联网(Internet of things, IoT)领域,在一个智能交通的应用上运行进化算法来对交通灯进行决策,自适应改善城市交通流,实验评估表明他们提出的FIoT(framework for Internet of things)模型比传统的决策模型的车辆通行量高出1倍左右.Dezfuli等人[108]同样也提出了一种在自适应系统中使用在线规划算法ReteRL进行决策的动态自适应网站,与Rete-OO和强化学习算法相比,使用在线规划提高了决策的效率和可用性,这种改进大大提升了网站的定性特征,如响应时间和可用性.
在自适应系统中引入最优化算法的优势在于问题的形式化抽象较好,相对于一些传统模型来说可以考虑的变化更多,这类多目标优化的方法能从庞大的搜索空间中最大程度优化目标函数,支持连续的状态和动作空间.在如今复杂的软件系统中,面临的问题更多属于连续的空间优化问题,因此Wan等人[109]提出了一种双层MAPE的自适应控制结构,分别实现了基于最优化搜索的规划方法和基于规则的强化学习规划方法,分别用在局部和全局的多智能体代理中.文献[109]中提出的方法使用多目标进化算法,可以在目标函数的约束空间内在线搜索最优解,针对应用的变化动态地匹配自适应策略.相对于强化学习,这种搜索算法显得更灵活和快速,所以被用在局部的智能体自适应中.
最优化算法在自适应系统中通过搜索目标函数的最优解来进行决策,在目标函数相对简单的情况下能够快速灵活地求解,但对于目标函数复杂、求解空间庞大的问题,使用最优化算法往往意味着较大的计算成本.除此之外还有一些场景,定义目标函数和约束条件往往十分困难,这一点与概率模型类似,所以近年来同样有不少研究在探索将最优化算法与强化学习相结合.Goyal等人在文献[110]中,对进化算法结合强化学习的算法进行了回顾,详细介绍和对比了遗传算法(genetic algorithm, GA)、粒子群算法(particle swarm optimization, PSO)、蚁群算法(ant colony optimization, ACO)等与强化学习相结合的高性能技术.
5.3 强化学习
强化学习是一种让自主行动的应用个体在与环境之间交互的过程中逐步改进自身行为的模型.事实上,强化学习在控制领域也被称为近似动态规划(adaptive dynamic programming, ADP),这是一种用来解决长期序贯决策问题的经典算法,经过多年研究人员的努力发展,逐步形成了如今一整套的强化学习理论方法.一个经典的强化学习模型由5部分组成:智能体(agent)、观察(observation)、回报(reward)、动作(action)和环境(environment)组成,其累计回报定义为使用贝尔曼方程表示的价值函数,优化的目标即是如何选择合理策略(policy)来保证获取到最大的累计回报.传统的强化学习解决的问题通常是离散低维的,状态和动作空间较小.而现今的应用往往是高维且复杂的,所以研究人员提出了深度强化学习,通过使用神经网络来逼近状态价值函数,从而能表达更高维的环境特征以及更复杂的状态动作空间.
近年来强化学习在自适应系统中的应用通常是指深度强化学习,其按策略更新模式分为在线策略和离线策略2种,而根据动作空间则可以分为离散空间和连续空间,目前主流的强化学习通常是基于actor-critic架构,如深度确定性策略梯度方法(deep deterministic policy gradient, DDPG)和信赖域策略优化方法(trust region policy optimization, TRPO)等.强化学习是目前在自适应决策中最受关注的热门技术之一,大量的研究工作都集中在使用强化学习来优化自适应系统的决策上.例如Zhao等人[111-112]提出了一种基于强化学习的自适应规则生成与演化框架,该框架通过离线学习产生了基本的决策能力,然后结合案例推理技术根据线上动态环境的信息与案例库演化出自适应规则.这种方法改进了现有基于规则的自适应方式的灵活性和质量,案例库的引入使得算法能够记忆有效历史决策流程,当环境改变时可以依据历史决策样例进行推理,这样能够有效减少重新求解决策过程的时间,同时也能保证决策的质量.这些基于强化学习的模型与MAPE-K模型不同,MAPE-K基于一些预定义策略的手工编码逻辑,这些策略需要专家对系统设计进行详细的理解,以预测资源更改如何影响系统性能,这种方式并不适用于当今复杂的应用程序,因此有研究提出了使用强化学习来负责MAPE-K的决策过程,将强化学习作为MAPE-K的一部分组件[34],从而提升自适应系统的性能.
由于深度强化学习的易用性和泛化能力,因此被广泛运用于各种场景的自适应系统,如虚拟机容量控制[113]、航空电子系统[114]、企业级应用服务组合[115]、虚拟机放置[116]、工作流调度[117]、应用程序组件组合[34]、机器人足球比赛[105]、移动边缘计算卸载[118]、边缘缓存放置[119]等.这些场景虽然各不相同,但对于强化学习来说,只需要抽象出对应的模型就可以使用算法进行决策,所以强化学习具有比较好的易用性和通用性.
基于强化学习的自适应决策是目前研究的热点,不仅是在不同应用领域的研究,还有许多研究着力于结合其他模型,提高自适应系统的性能.比如多智能体强化学习(multi-agent reinforcement learning, MARL),通过博弈论与强化学习相结合,利用纳什均衡来改进强化学习算法在多个智能体之间协调的性能[115];Tomás等人[113]则将模糊逻辑与强化学习结合,提出了一个在线的模糊强化学习算法(fuzzy q-learning, FQL),用于解决环境存在模糊描述的自适应决策问题;Ganguly等人[120]则针对分布式应用的自适应问题,提出了去中心化的强化学习算法,动态地更新本地和全局模型,实现分布式应用的自适应;同样是针对分布式的自适应系统,Wan等人[109]则是提出了一种双层MAPE-K自适应模型,结合进化算法和强化学习,使用进化算法优化manager层,使用强化学习来优化worker层;Shi等人[105]则考虑到了系统中的不确定性,针对动态决策中的非确定性知识表示和模型的复杂度,提出了一个结合贝叶斯网络和强化学习的模型,实验表明这种方法在非确定性环境模型下可以更好地选择最优策略;而为了解决强化学习在感知力上的缺陷,Wang等人[87]则考虑结合循环神经网络与强化学习,来提升自适应系统对时序数据进行决策的性能;为了解决强化学习的性能严重受超参影响的问题,Xiong等人[118]引入了最大熵算法,有效地平衡了强化学习的exploration与exploitation,来降低强化学习对于超参的敏感性,提高自适应模型的自动化和泛化能力;Wang等人[26]则将强化学习与联邦学习结合在一起,用于联邦学习中的缓存自适应决策.
5.4 小 结
决策规划是自适应系统中最为重要的关键技术,决策问题可以看作是从所有可行策略中选择最适合、最高效的策略,同时还要尽可能地保证算法的时效性,满足在线自适应决策的需求.表5总结了一些自适应决策的文献分类,可以看出近年来主流的决策算法都集中在强化学习上,这类端到端(end-to-end)的算法仍然是未来自适应发展系统的趋势.

Table 5 References About Adaptive Planning表5 自适应决策的相关文献
自适应决策目前仍然存在很多需要解决的问题:1)决策的实时性问题,目前主流的方案是采用主动延迟感知(predictive latency-aware, PLA)的适应决策,通过限定决策时间来保证决策的实时性;2)系统的非确定性问题,环境中的不确定性意味着无法简单地对环境变化进行建模,需要结合如概率分析等技术手段来处理不确定性;3)多智能体间的不完全可知信息决策问题,在智能体间信息不对称时,如何保证算法能做出最优的决策;4)分布式系统的自适应问题,如何在去中心化的系统中实现自适应决策,保证局部系统均能获得自适应决策的收益.这些都是在自适应决策方面值得进一步研究的热点问题,同时意味着自适应决策技术未来将向着智能化、快响应、大规模的方向发展.
6 规则演化
正如在1.2节中提到的,数据驱动的自适应技术是从历史数据中学习出最优的策略,因此数据驱动应用存在一个关键的缺陷:冷启动和数据缺少的问题.由于当今应用环境的复杂多变,导致使用这类基于历史数据的方法处理一些历史中未出现的“模式”时,并不能很好地实现自适应的功能.规则演化就是应对实时环境中出现这种未知“模式”时,从已有的数据或规则中推理出相关性,将未知“模式”规约到已知的场景下,或是针对未知“模式”生成新的处理规则的方法.
一个经典的规则推理方法称为基于案例的推理(case-based reasoning, CBR)[122],这是一种懒加载解决问题的方法,它从知识库中找到类似的已解决问题来解决一个新问题,即利用旧的经验来理解和解决新问题,解决后的新问题又将成为知识库的一部分[1].CBR利用过去案例的知识来解决新案例,一共有4个步骤:1)检索,计算相似度来检索最相似的过去案例;2)重用,通过重用最相似的案例中的信息和知识,为新案例提出解决方案;3)修订,修改建议的解决方案;4)保留,保留有关新案例解决方案的信息和知识.Zhao等人[111-112]提出一个可以在线进行规则演化的自适应系统,通过结合强化学习和基于案例推理的技术,在线进行规则集演化来对环境的未知变化做出自适应的调整,为新目标激活新的案例解决方案,解决自适应系统面对新环境的适应问题.Raza等人[123]则提供了一种基于案例推理的数据库负载自适应解决方案,与单纯的机器学习方法相比,案例推理在面对未知案例时,不需要重新训练数据集来进行自适应,而是可以直接在线进行案例检索并解决,动态更新案例库.
案例推理需要借助历史案例来解决新问题,但如果新问题与案例库中的差异过大,对应的解决方案则不能很好地适应新问题,这是数据驱动的方法不可避免的缺陷,因此面对这样的问题,研究人员提出了引入一定规则驱动技术来提升自适应系统的稳定性.基于这个考虑,Mongiello等人[124]提出了一个结合知识图谱与案例推理的自适应系统,用于智能手机的应用自适应.该文作者提出的框架利用知识图谱对自适应软件及运行环境进行建模,包括应用目标、事件流程、操作要求等,利用知识图谱的分析推理功能,可以大大提升自适应系统处理新问题的能力[125].
除了案例推理与知识图谱之外,迁移学习也是一种有效帮助系统适应新环境的方法.虽然知识工程技术能够处理一部分冷启动问题,但这类方法无法处理不确定性的问题,而迁移学习则能借助概率推理来处理新问题中的不确定性.迁移学习旨在解决训练数据和实时数据在不同的特征空间、具有不同分布情况下的学习问题,即智能地应用以前的学习知识来更快或更有效地解决新问题[126].文献[11]总结了近几年迁移学习在智能家居的自适应系统中的应用,迁移学习可以用来解决当环境变化时自适应系统如何保证正常执行应用程序.
7 结束语
在本文中,我们介绍了数据驱动的自适应技术近几年的研究现状,并总结出了一个数据驱动应用的自适应系统应包含4种关键技术:表征学习、模式识别、决策规划、规则演化,接着我们分别综述和总结了这4种技术在数据驱动的自适应系统中的应用.自适应技术一直是应用开发的研究热点,利用自适应技术可以实现应用的环境适配、故障容错、负载均衡等.传统的自适应技术通常是规则模型驱动的,这类技术往往在面对复杂环境和处理不确定性上具有局限性,而数据驱动技术则是更多地结合了如今的人工智能技术,从概率和数理统计的角度来学习环境的变化,提取环境模型的特征来进行自适应系统的模式识别和决策规划,并针对数据驱动的冷启动问题,通过结合一部分知识驱动手段来实现规则的演化,增强自适应系统处理不确定性环境的变化.
随着人工智能技术的发展,数据驱动的自适应也开始转向自动化、智能化、集成化的方向发展,本文虽然将系统分为了4个模块,但许多工作开始研究端到端的自适应技术,将多阶段的处理合成为一个神经网络来建模.除此之外,随着如今大规模分布式系统以及边缘计算的兴起,自适应技术的分布式化也成为了一个研究的趋势,如分布式的MAPE-K[30]等.同时,目前的数据驱动自适应虽然摆脱了预定义规则的束缚,但如何归纳从数据中挖掘出的规则,形成可演绎进化的新规则仍然是研究的重点,也是未来智能化的自适应技术探究的方向.
作者贡献声明:代浩负责研究内容整理、论文撰写和修订;金铭负责文献调研及论文图表整理;陈星、李楠、涂志莹负责论文部分撰写和修订;陈星和涂志莹负责整体论文的检查和修订;王洋提出论文整体架构和综述路线,及最终论文的审核与修订.
猜你喜欢
汽车实用技术(2022年7期)2022-04-20 11:45:04
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
纺织科学研究(2021年9期)2021-10-14 08:52:10
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
房地产导刊(2020年11期)2020-12-28 01:32:30
铁道通信信号(2019年4期)2019-10-10 03:42:56
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
Coco薇(2017年11期)2018-01-03 20:59:57
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
通信电源技术(2016年1期)2016-04-16 04:57:31
