
基于改进Retinex-Net的低照度图像增强算法
2022-11-11 12:45王延年杨恒升刘妍妍
西安工程大学学报 2022年5期
王延年,杨恒升,刘妍妍,杨 涛
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
图像拥有信息量丰富、传送方便等特点,但在实际应用中,成像过程易被低光照情况所干扰,取得的图像亮度与对比度普遍较低且存在噪声,给图像的进一步处理带来极大困难。为了解决这一问题,学者们不断更新各种增强算法,传统算法包括直方图均衡化[1]、伽马变换[2]、Retinex理论[3]等方法。
直方图均衡化算法的原理是将图像的灰度值进行拉伸,使其分散至灰度直方图的整个区间,通过扩散图像的灰度值分布以实现图像增强。直方图法能起到增加图像画面亮度的作用,且速度较快,但灰度级别会下降导致细节不明显。Retinex模型是由LANG等提出的一种仿视觉系统对图像进行识别的模型。依据Retinex理论可得,眼睛所感受的物体的色彩与亮度仅仅由物体固有的特性确定,与映射到眼睛中的光线没有必然联系。虽然Retinex理论的相关算法可以增强图像的亮度,但算法本身不够灵敏,边缘部分的增强效果不佳且噪声较大。
近年来,随着深度学习理论不断取得进步,其在图像去噪、图像识别等方面获得优异的成果,故研究人员们也将深度学习应用于图像增强。文献[4]提出一种多尺度融合的残差编解码器的低照度图像增强方法,但由于结构复杂难以学习训练。文献[5]提出一种通过学习收缩场改进Retinex理论的增强方法,能有效去除图像伪影,但增强后的边缘细节不清晰。而文献[6]和文献[7]在Retinex基础上发展了单尺度与多尺度方法,通过对RGB颜色通道进行滤波处理估计光照图,有效改进了颜色失真的问题。但当图像中有大片阴影区域时,会产生光圈效应。文献[8]提出一种基于深度编码器的低照度图像处理算法,该方法可直接应用于自然环境中,但在对比度提升方面有所不足。文献[9]提出一种卷积神经网络低照度图像增强算法,该算法以Retinex模型为基础,使用卷积神经网络预测光照分量,但无法有效去除噪声。文献[10]提出一种混合网络以提升图像能见度,但边缘提取方面有所不足。文献[11]通过从实际照明环境捕捉的图像来估计RGB色彩空间的增强模型,此方法具有很好的适用性,但处理后的图像会发生颜色失真现象。文献[12]提出一种生成对抗网络的方法,此方法在没有图像对的情况下也可以进行训练,但其准确度需依赖大量图像数据为基础,故处理速度较慢。文献[13]提出一种融合密集特征的增强算法,该算法通过校正色偏并在生成器部分引入密集特征融合机制对图像进行增强,但训练速度较慢。文献[14]提出一种数据驱动使网络学习相机成像原理进行图像增强的方法,将短曝光与低光图像转换至RGB通道,此方法有效避免了伪影现象,但亮度增强有所不足。文献[15]提出一种可快速去噪的神经网络,此算法只需一个网络即可完成去噪处理且速度较快,但复原性能较差。
本文以Retinex-Net为框架,为解决原始图像在分解过程中会产生大量噪声的弊端,在分解网络中嵌入残差收缩构建单元(residual shrinkage building unit,RSBU)[16]。同时,为使图像特征提取更加完整,针对不同的问题,将增强网络分为3个子网络分别进行处理。
1 本文算法理论
1.1 Retinex理论模型
根据Retinex理论,物体表面的颜色是由物体本身内在特质,即对各种光线的反射所决定的,而其特质不会因环境不同发生变化[17]。因此Retinex理论的核心观点就是忽略光线的作用,维持物体本身的性质。该模型可被表示为
S(x,y)=I(x,y)R(x,y)
(1)
式中:I(x,y)为光照分量;R(x,y)为反射分量;S(x,y)为观察者所观测到的图像。
1.2 改进网络结构
低照度图像增强由于暗区部分细节特征较少、存在噪声较多,需要对其进行处理。原始的Retinex-Net存在以下问题:①由于噪声与光照强度有关,在将图像分解时会产生噪声[18];②在增强图像时会产生失真或模糊现象[19]。故对Retinex-Net进行改进是非常有必要的。算法的整体结构如图1所示。

图 1 改进Retinex-Net结构
图1是通过依次对分解与增强2部分网络结构进行改进得到一种改进的Retinex-Net。首先,将原始图像与对应的低光图像经过改进的分解网络分解为光照分量与反射分量。其次,光照分量经过一个包含卷积与反卷积层、密集残差层与空洞卷积的多分支网络进行增强处理。最后,将增强后的光照分量再根据Retinex理论与反射分量进行融合得到处理后的图像。
1.3 分解网络部分
在分解网络部分,此网络将输入的低光图像Slow与正常图像Snormal分解为反射分量(Rlow,Rnormal)与光照分量(Ilow,Inormal)作为输出并共享网络参数。首先,用3个3×3的卷积层对输入图像(Slow,Snormal)进行特征提取。然后采用6层以ReLU激活函数为基础的卷积层得到图像的光照分量和反射分量。考虑到图像分解过程中会产生噪声,本文参考了文献[16]的思想,在分解网络中加入了恒等映射以及残差收缩构建单元作为子网络去除噪声。其本质上是残差网络的一种改进单元,在基础残差网络结构上增加了一个小型子网络,将软阈值函数嵌入残差网络中,此网络可有效改进在学习过程中噪声较大的问题。与普通残差网络、传统卷积神经网络对比,分类准确率更高。将阈值设置为超参数,可以自动选择阈值大小,同时每个输入信号有自己的阈值。其中C、W、H表示特征图的通道数、宽度和高度。子网络最后是一个Sigmoid激活函数将输出限制在0到1之间,以保证阈值为正数且不会过大。阈值计算公式为
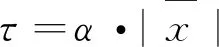
(2)
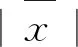
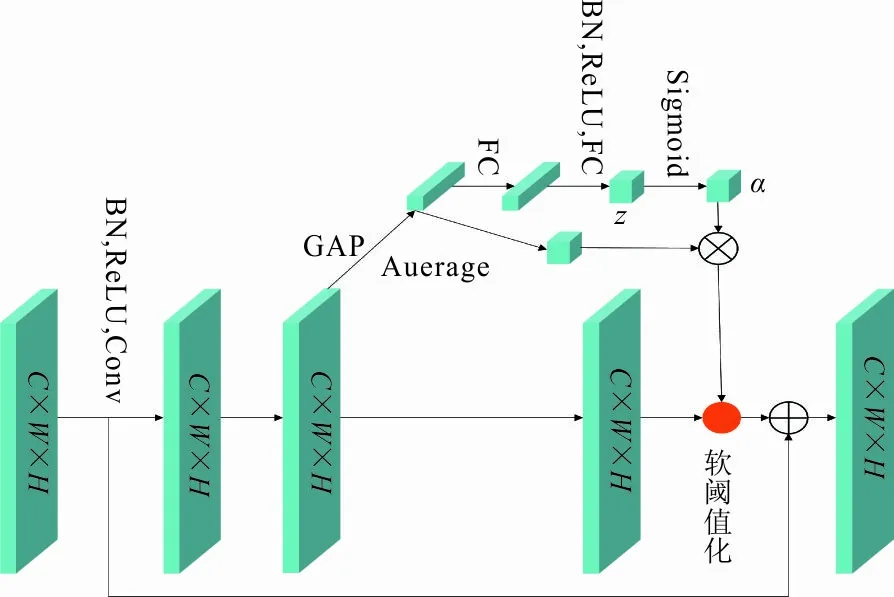
图 2 RSBU结构
在特征图经过2个带有图2所示单元的卷积层后,然后用一层3×3的卷积与Sigmoid函数进行激活分别得到其光照与反射分量的映射图,并将Ilow作为增强网络的输入,经过一个3×3卷积的多卷积层的单分支网络,其每一层的输出作为下一层子网络的输入。同时,为减少训练时间,分解网络部分进行了参数共享。
1.4 增强网络部分
增强网络部分由3个子网络构成。由于特征图在卷积过程中视野关注局部信息,故本文在之后引入了反卷积操作将视野扩展到整体以获取特征图中更大的信息[20]。其中第1个子网络由卷积与反卷积的堆叠组成,并且为了保障光照特征的传递性,在两侧对应层间通过跳跃连接相连。第2个子网络主要为一个密集残差层,其由残差密集块[21](residual dense block,RDB)组成,由于传统残差网络并不能有效利用每一个卷积层中的信息,会导致特征信息利用率和网络性能低下等问题,本文采用RDB将卷积层以密集连接的方式组合进行特征提取。同时,RDB采用的连接结构可以使之前所有卷积层的特征结合,然后再依次向后传递。这种方法不仅可以多次利用特征还促进了特征的传播,从而形成了连续记忆(contiguous memory,CM)机制。RDB的结构如图3所示。
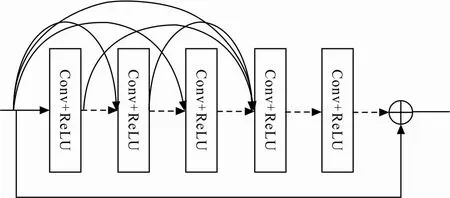
图 3 RDB结构
从图3可以看出,上一层特征提取的结果作为本次残差块的输入,经过若干个卷积和ReLU激活函数操作,然后通过一条跳跃直连边将之前的特征进行结合并作为下一层的输入。为避免网络的过拟合和梯度消失问题,其中每个残差块由4个3×3大小的卷积块与ReLU函数组成,然后将提取的特征信息利用Concat进行融合并与当前残差块的输入相加,最后将其传递到下一层的输入中,根据实验,残差块的个数为6时效果最佳。为了增加感受野和降低网络训练时间的同时保持分辨率不变,本文在增强网络中嵌入空洞卷积[22],由于空洞卷积的步长较大,故空洞卷积的卷积核覆盖区域大于普通的卷积,其中空洞卷积的输出可表示为

(3)
式中:X为空洞卷积的输入;S为卷积核的大小;k为卷积核的数量;r为空洞卷积核的空洞率。由式(3)可得,空洞卷积可以借助改变卷积核大小或调整空洞率的方式来增大感受野。第3个子网络是一个由3×3大小,空洞率为2的空洞卷积组成的空洞卷积层,其输出与输入的大小一致。最后,将3个子网络的输出融合后用一个1×1的卷积合并得到增强后的光照分量Ien,与分解网络的输出Rlow结合得到增强后的图像Sen。
1.5 损失函数
在网络的学习过程中,选取一个恰当的损失函数来估计网络权重参数以提高学习的准确性是十分必要的。由于物体自身的属性不变,其本身的反射分量也应不变,故分解网络部分的损失函数采用已有的模型进行评估[23]。该部分损失函数由4部分构成:
L=Lrec+αLrs+βLis+γLmc
(4)
式中:Lrec为反映分解准确度的损失函数;Lrs为反射率相似性损失;Lis为光照平滑度损失;Lmc为相互一致性损失;α、β与γ分别表示损失函数的权重参数。根据先前理论,不同光照下图像分解的反射率应相同,其反应相似度的损失函数如下:
Lrs=‖Rl-Rh‖1
(5)
式中:Rl为低光图像的反射率;Rh为正常图像的反射率,‖·‖1为L1范数。接下来对光照分量的低光与正常2个方向的梯度求损失,损失函数如下:
(6)
式中:∇Lh为正常图像的光照分量的光照梯度;∇Ih为正常图像的光照梯度;∇Ll为低光图像光照分量的光照梯度;∇Il为低光图像的光照梯度,低照度和正常照度的光照梯度较大或较小时表明此时的光照处于平衡的物体表面或边缘部分,只有在梯度之间存在差异且差异不大时进行惩罚。此时引入相互一致性损失,损失函数如下:
Lmc=‖M·exp(-c·M)‖1
(7)
式中:M为∇Ll与∇Lh之和;c为控制函数形状的参数。由于被分解的光照分量与反射分量需要遵循Retinex理论,即可以被还原成原来的图像,故引入分解准确度损失函数,函数公式如下:
Lrec=‖Ih-Rh·Lh‖1+‖Il-Rl·Ll‖1
(8)
2 实验与分析
本文实验均基于TensorFlow框架训练模型。详细配置如下:系统为Windows10;处理器Intel 酷睿i7-8700K;显卡为NVIDIA GTX 2080 GPU,12 GiB内存;系统内存16 GiB。
2.1 数据集及参数设置
本文使用的训练数据集采用LOL训练集和Brighting Train。测试集选用DICM数据集和LOL评估集。为了使实验结果更加准确,在学习阶段需要大量的训练数据,而目前数据集的图片数量有限,故本文将数据集的图片进行了一系列随机翻转,缩小,平移等处理进行了数据增强。权重参数设置为α=0.01,β=0.15,γ=0.2。其中分解模块部分的训练次数为1 500次,增强模块部分的训练次数为2 000次。
2.2 实验结果与讨论
为进一步证明本文方法的效果,选取了几种主流的增强算法进行比较,其中包括SRIE[24]、LIME[25]、GLADNet[26]、Retinex-Net,对比结果如图4所示。

(a) 输入图像 (b) 正常图像 (c) SRIE (d) LIME (e) GLADNet (f) Retinex-Net (g) 本文算法
从图4可以看出,SRIE方法的图像整体偏暗,SRIE方法是从图像特征区域的关联性入手,在图像光照分量中增强图像的亮度及信息,但在亮度突变较大的区域会出现伪影现象且亮度增强不足,在“碗橱”图像中,橱内碗的反光处与阴影交界处较为模糊。 LIME方法是在RGB通道中找出每个像素的最大值来估计光照度,然后再通过原始的光照图预测结果作为最终的光照映射,但由于每次都需要经过上述过程,所以速度较慢且存在过度曝光的现象,在图“公仔”中,玩具表面的反射光过亮且颜色发白。GLADNet方法将输入图像下采样到特定尺寸并送入到编码器-解码器网络中生成关于亮度的全局光照估计,基于全局光照估计与原始输入图像,采用包含卷积层的下采样块进行细节还原,可有效提升图像亮度,但由于对图像进行了缩小操作又重新缩放至原始尺寸后导致增强后的细节上有所缺失且颜色失真。Retinex-Net方法将图像分为光照与反射分量并根据Retinex理论只对反射分量进行处理,但对于分解过程中产生的噪声只采用了普通的双边滤波,故增强后的图像噪声较大。而本文算法相比于其他算法,在亮度增强方面相比其他算法有较大提升,且避免了Retinex-Net的图像细节丢失与噪声过大等问题。
在客观评价方面,本文选取了4个评价指标来判断算法的性能,其中包括峰值信噪比(PSNR)、均方误差(MSE)、结构性检验标准(SSIM)和相对亮度顺序(LOE)。PSNR是一种衡量图像增强算法的常见指标,其表示图像峰值信号与噪声信号的比值,其数值越大表示图像的增强效果越好。MSE表示增强后图像像素值与初始图像像素值之差平方和的均值,数值越小表示增强后图像清晰度越高。SSIM为结构相似性,独立于亮度与对比度,表示增强图像与输入图像的共通性,取值在0到1之间,值越大表示处理后图像相似度越高。LOE表示了图像亮度的自然性,其通过评估图像的邻域中亮度的顺序变化过程来评价图像的照度变化值,值越小表示图像的亮度越自然。不同算法评价指标结果如表1所示。
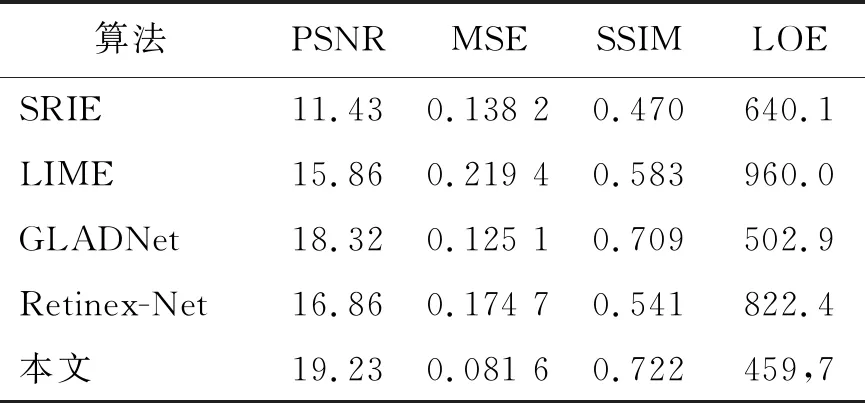
表 1 不同算法评价指标结果
2.3 算法有效性验证
为进一步验证本文算法各个模型的效果,分别对加入了各种模块得到的增强图像进行比较。其中方法1表示以Retinex-Net为基础的网络结构;方法2表示在Retinex-Net分解网络部分加入RSBU网络结构;方法3以方法2为基础在增强网络中仅加入卷积与反卷积堆栈层;方法4以方法2为基础在增强网络中仅加入空洞卷积层;方法5、6、7都表示在Retinex-Net基础上加入RSBU以及卷积与反卷积堆栈层、空洞卷积层和残差网络层,且由于增强网络中有残差网络的存在,而残差网络的层数与网络的性能有着极大关联,并且随着残差网络数量的增多,尽管可以改善网络的特征提取能力,但同时也会使网络的训练时间增加[27]。故考虑到硬件设施与耗时等问题,本实验分别选取了残差数量为6、10、12的残差网络进行对比。其中方法5的残差块数量为6,方法6的残差块数量为10,方法7的残差块数量为12。实验模型使用LOL数据集的测试集,主观实验结果如图5所示。
从图5可以看出,方法1增强后的图像噪声较大且壁画处的颜色有失真现象。方法2和方法3处理后图像噪声明显减少但天空部分颜色失真且在建筑物边缘部分有些模糊。方法4图像整体仍有噪声。对比方法6、7,方法5的色彩与细节保持良好,方法6图像整体已经开始出现模糊现象,而方法7建筑上的十字架甚至已经几乎趋于不可见。
在客观评价方面,本文利用PSNR评价噪声指标,SSIM评价处理后图像与原始图像的结构相似性。不同方法实验结果如表2所示。

表 2 不同方法实验结果
从表2可以看出,相较于Retinex-Net方法,在此基础上加入RSBU后虽然SSIM指标变化不大,仅提升了0.004,但PSNR指标提升了0.92 dB,说明通过RSBU单元起到了训练子网络的阈值过滤噪声的作用。由于卷积操作会丢失图像信息产生噪声,故利用反卷积操作可对特征图进行恢复,所以在方法3中继续引入卷积与反卷积层后, PSNR指标提升了0.52 dB,SSIM指标提升了0.053。由于引入了空洞卷积,故在方法4中加入了空洞卷积层后SSIM指标提升了0.061。而在继续增加残差网络后,PSNR与SSIM指标都大幅提升,其中,当残差块数量为6时,PSNR与SSIM比无残差块数量增加了1.18 dB和0.037,比残差块数量为10和12平均增加了0.52 dB和0.03,故本文将数量6作为残差块的最终数量。综上所述,本文引入的RSBU网络以及改进的增强网络可有效提升对低照度图像的处理能力。
3 结 语
本文通过对Retinex-Net算法进行改进,提出了一种更为有效的方法对低照度图像进行增强。基于Retinex理论,采用包括残差收缩构建单元和卷积的分解网络将图像分解为光照和反射分量2部分,有效抑制了分解过程中产生的噪声。增强网络部分通过一个由密集残差块、空洞卷积层和卷积与反卷积层构成的多分支网络对图像进行增强,保留了更多细节特征。实验表明,针对低照度条件下的图像,本文算法能够有效增强图像亮度并能抑制无关噪声,能够更好地应用于图像处理任务中。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中国机械工程(2022年8期)2022-05-09
上海金属(2021年2期)2021-04-07
儿童时代·幸福宝宝(2021年1期)2021-03-29
北京航空航天大学学报(2020年10期)2020-11-14
小资CHIC!ELEGANCE(2019年40期)2019-12-10
自动化学报(2019年6期)2019-07-23
音乐教育与创作(2019年8期)2019-05-16
故事作文·高年级(2017年2期)2017-03-01
中国惯性技术学报(2015年1期)2015-12-19
