
基于关联规则挖掘的图书馆信息资源整合方法研究
2022-11-10 10:12马丽
江苏科技信息 2022年30期
马 丽
(西安医学院 图书馆,陕西 西安 710021)
0 引言
图书馆信息资源整合,是指参照一定的标准与要求,使用多种技术,将多渠道、不同来源的数据、信息、资源进行集成,实现不同类型、多种格式信息之间的无缝连接[1]。经过整合后的图书馆信息库,具有集成式、一体化检索功能,可实现为终端用户提供跨平台、跨终端、跨数据库、跨内容等多种新式服务。图书馆在市场内作为承载信息、典藏资源的主要场所,不仅可以为用户提供资源检索服务,还可以为物质资源与非物质资源的存储提供安全、可靠的空间。为满足图书馆服务对象的多元化需求,管理人员需要加大对资源信息整合的投入,从杂乱无序的资源中筛选出有价值的信息,将多种具有相同指向的信息进行集成,通过此种方式,使资源建设朝着整合化、集成化的方向发展[2]。为落实此项工作,向图书馆用户提供更加优质的服务,科研单位在较早时期引进大数据技术与云端共享技术进行信息资源的集成与融合,但由于设计的融合方法与用户需求呈现背离状态,导致融合后的资源一直未能在图书馆发挥预期的效果,也未能实现给予用户更优质的推送资源。因此,本文将在现有工作的基础上,引进关联规则挖掘技术,设计一种针对图书馆信息资源的全新整合方法,通过此种方式,集成多类别信息,为图书馆用户提供更加优质的资源检索服务。
1 构建图书馆信息资源分布结构模型
为实现图书馆信息资源的有效整合,应结合图书馆信息资源的来源与获取渠道,构建图书馆信息资源分布结构模型。为确保构建的模型与资源分布具有较强的适配性,引进Small-world网络拓扑结构,参照此结构,建立图书馆信息资源存储中心与来源渠道之间的直接访问接口,实现对资源分布的精细化描述[3]。此过程如图1所示。
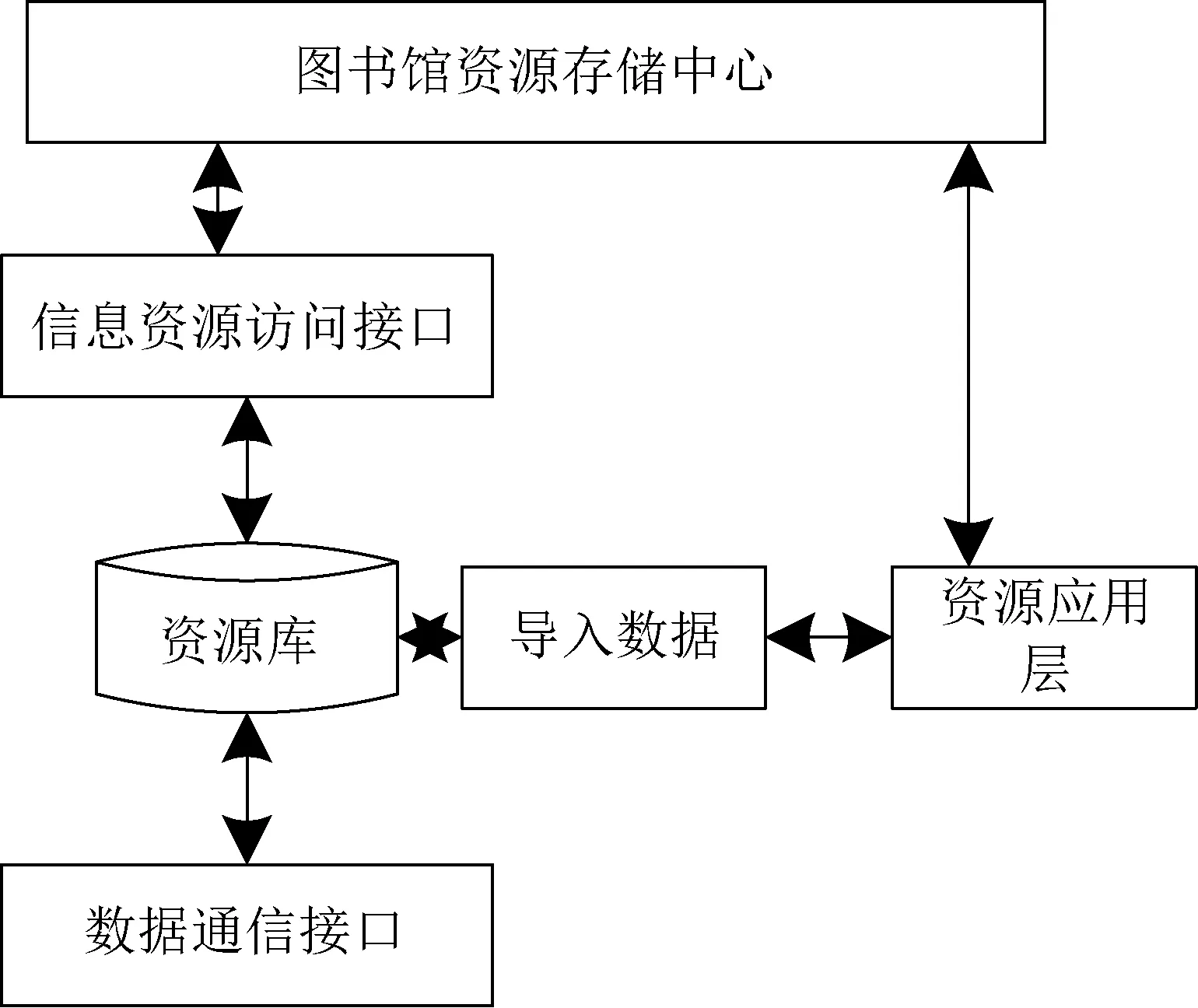
图1 图书馆信息资源分布结构模型
在掌握不同信息资源的来源渠道后,对现有信息进行属性专项配置,通过此种方式,构建在不同时态区间下,图书馆信息资源的空间状态[4]。对其状态进行描述,计算公式如下:
(1)
式中:Pn为图书馆信息资源的空间状态;P0为资源在空间中的分布密度;δ为分布节点。在此过程中,假设信息资源在空间中的动态属性表示为Y,此时Y可以作为空间中的一个因变量,假设图书馆信息资源表示为X,则X与Y之间存在某种约束性条件,对此种约束条件进行描述。计算公式如下:
(2)
式中:m为X的最大取值。在此基础上,使用相关统计法,对资源进行在线调度,根据最优线性均衡函数,进行图书馆信息资源存储空间中信息的回归表达,方程式如下:
(3)
式中:x为图书馆信息资源存储空间中信息的回归表达方程式;η为动态回归参量;r为资源在图书馆中的有效传输路径;T为资源调度时间;R为资源覆盖范围;s为信息资源流通节点;σ为资源传输路径总数;N为链路结构;z为链路长度;y为信息资源格式。通过上述方式,对图书馆信息资源的空间状态与来源渠道进行描述,将相关信息通过集成的方式导入结构模型,实现对信息资源分布状态的描述。
2 基于关联规则挖掘的信息资源特征提取
完成上述设计后,为实现图书馆信息资源的整合,需结合资源在空间中的分布特征,进行历史数据的挖掘。为此,本章引进关联规则挖掘技术,根据图书馆中现有信息资源,进行信息资源特征的提取。在此过程中,使用关联规则挖掘技术中的Apriori算法,提取数据库中的两组信息资源,将其表示为A与B,对A与B的潜在联系进行挖掘。此过程可表示如下:
(4)
式中:p为A与B的关联挖掘;γ为关联规则;b为关联条件。按照上述方式,提取A与B的关联关系,掌握两者之间的联系后,持续扩大事件的选择范围,进行信息资源的频繁选择。为避免输出冗余信息,可设置一个伪代码将其作为信息资源规律挖掘的全新规则,将此作为参照,对图书馆信息资源进行深度挖掘与关联,通过此种方式,提取图书馆信息资源特征,此过程可表示为:
(5)
式中:M为图书馆信息资源特征;n为伪代码;v为资源有效传输区间;i为资源类别数量。按照上述计算公式,进行图书馆中不同类别信息资源特征的提取,以此方式为后续信息资源聚类中心的确定提供支撑。
3 基于特征辨识的信息资源聚类融合
完成上述研究后,建立针对特征的空间映射函数,函数表达式如下:
(6)
式中:D为图书馆信息资源特征空间映射函数;L为空间映射范围。在此基础上,设计一个随机聚类节点,建立针对此节点的链路矩阵,矩阵表示为S,S可以通过N×L实现。考虑到此节点可能并非信息资源聚类最优节点,因此,可以在构建矩阵后,采用概率分布计算的方式,进行节点为最优聚类中心概率的计算,计算公式如下:
(7)
式中:β为节点为最优聚类中心的概率;Z为资源分布离散型;G为节点时隙;w为节点最大跳点;χ为空间调度矢量。通过上述方式,掌握节点与最优聚类中心之间的关系,为实现聚类节点向最优节点的靠近,结合自适应算法,根据节点数据之间的关联性,进行聚类中心节点的优化。此过程计算公式如下:
κ=E[ωk(vj)]
(8)
式中:κ为最优聚类中心节点;E为自适应调度算法;ω为嵌入式网络环境;k为模糊中心;j为可调度节点。按照上述方式,设计最优聚类中心,在此节点进行信息资源的聚类融合。此过程计算公式如下:
f(κ)=μK·ij
(9)
式中:f为图书馆信息资源的聚类融合;μ为均衡信道;K为节点差分矩阵;ij为聚类过程中的奇异值。按照上述方式,对图书馆信息资源进行聚类,以此种方式,完成基于关联规则挖掘的图书馆信息资源整合方法设计与研究。
4 实验对比
上文从3个方面完成了基于关联规则挖掘的图书馆信息资源整合方法设计,为检验此方法在实际应用中的整合效果,下文将以某地区大型公共图书馆为例,通过设计对比实验的方式,检验本文方法的整合效果。
实验前,由相关人员与图书馆管理人员进行交涉,发现此图书馆已经实现其内部的全数字化管理,并开发了完善的信息资源库,用于存储多渠道、多来源的信息资源。通过对管理终端的检索,掌握此图书馆现存资源的类别与来源。
为进一步检验本文设计的整合方法在实际应用中的性能,引进基于云处理技术的图书馆信息资源整合方法,将其作为传统方法,对所选用的信息资源进行整合。在此过程中,需要先将信息资源导入图书馆管理云端,在云端建立数据信息聚类中心,在中心区域内进行数据类别的划分,将具有相同特征的图书馆信息资源进行聚类;完成区块信息的聚类后,再将多个分项单元进行整合,通过此种方式,实现基于传统方法的图书馆信息资源整合。
将整合处理后资源的查全率作为评价整合方法有效性的指标。查全率是指在数据库中输入检索关键词,可检索得到的和关键词相关的信息量与数据库中和检索关键词相关的信息总量比值,计算公式如下:
(10)
式中:C为整合处理后图书馆信息资源的查全率;C1为可检索得到的与关键词相关的信息量;C2为数据库中与检索关键词相关的信息总量。按照上述方式,在两种方法整合后的数据库中搜索关键词,计算检索不同关键词时数据库的查全率。统计测试结果如表1所示。

表1 图书馆信息资源整合后的查全率
从表1可以看出,本文方法在实际应用中的整合效果较好,可以提高整合后图书馆内信息资源的集成度,从而为用户提供更丰富的检索信息。
5 结语
在信息化技术与图书馆发展发生融合后,图书馆早期的典藏方式与读物模式都面临着巨大的冲击,如何为用户提供更加优质的资源、提高资源的专项性与服务性成为图书馆管理工作关注的重点。为进一步落实此项工作,发挥图书馆在市场内更高的价值与效能,本文从构建图书馆信息资源分布结构模型、信息资源特征提取、基于特征辨识的信息资源聚类融合3个方面,开展了基于关联规则挖掘的图书馆信息资源整合方法设计研究。完成设计后,通过对比实验证明了相比传统方法,本文设计的融合方法聚类效果更优。因此,可在进行图书馆的服务优化设计时,将本文方法在试点单位中进行推广,通过此种方式,为用户提供更加优质的资源检索服务。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科学与财富(2019年27期)2019-10-25
当代陕西(2019年15期)2019-09-02
电子制作(2019年14期)2019-08-20
现代计算机(2018年27期)2018-10-25
学苑创造·A版(2018年11期)2018-02-01
舰船电子对抗(2017年6期)2018-01-11
科学与财富(2017年28期)2017-10-14
读者(2017年5期)2017-02-15
互联网天地(2016年1期)2016-05-04
