
基于SVM的雷达信号样式分类与模式判断*
2022-11-09 07:27胡晓玲
舰船电子工程 2022年8期
胡晓玲
(91668部队 上海 200083)
1 引言
雷达信号样式分类与工作模式的判断识别是雷达威胁等级评估的重要依据,是后续实现威胁估计、行为意图推理、自适应雷达对抗等重要环节的基础[1~3],对干扰资源的合理分配提供支持具有重要意义。现代海空战场上只有实时准确获得敌方雷达信号特点、工作模式、模式探测性能和对抗能力,判断对方雷达尤其是机载火控雷达威胁程度,以产生和启动明确的技战术动作,最大限度提高己方生存率。
2 雷达信号样式及模式
目前,雷达信号样式的用语多来自于日常侦测实践,是对侦测到雷达脉冲描述字规律性结构体的叫法,雷达信号样式通常包含脉冲到达时间(TOA)、载波频率(RF)、脉冲宽度(PW)、脉冲重复间隔(PRI)和脉冲数(NOR)等参数及其规律性描述[1~5]。雷达短语则是将侦察截获的脉冲串按照雷达字建模过程,得到脉冲串中包含的多组雷达字,因此,可以理解为雷达信号样式接近或类同于雷达学术中的“雷达短语”,即分选后的单部雷达的一种信号工作样式,通常包含于一种工作模式的脉冲信号序列[6~7]。国内常用方法有进一步采用支持向量机(SVM)、多层次建模判定、神经网络等分类算法来识别工作模式[1,5~8],本文的雷达信号样式分类过程是对雷达短语的分类过程,首先提取雷达信号样本的特征,再根据训练样本的PDW字结构利用支持向量机分类识别器对未知的雷达信号样式(短语)进行分类,最后根据雷达信号样式与工作模式的先验知识进行模式推断[8~10]。
3 支持向量机方法
支持向量机(SVM)的基本模型是特征空间上的间隔最大的线性分类器。模型训练的目的是求解训练样本的最优分类超平面g(x)=(w·x)+b=0,若用一个优化问题来描述则可以写成如下的形式[8~10]:
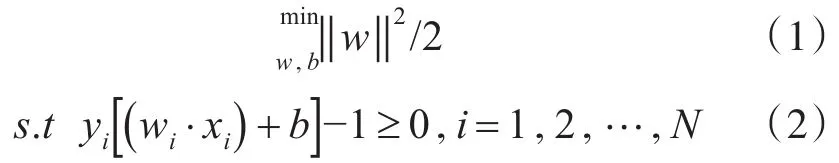
其中,N为训练样本个数,xi和yi分别是样本数据和样本类型,引入拉格朗日泛函,上述问题等价于下面的优化问题的解:
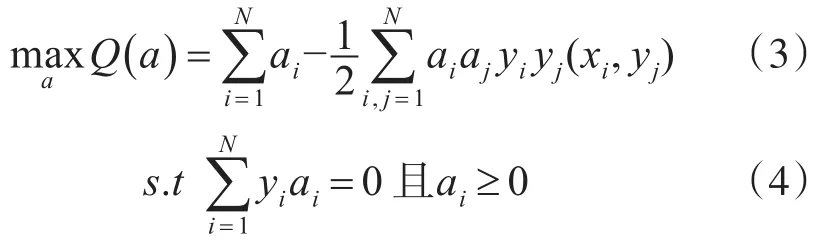
上述问题是建立在训练样本线性可分的前提下,当训练样本线性不可分,则需要引入松弛变量求解最优分类超平面问题。本文采用SVM支持向量机方法解决信号样本分类,SVM算法将实际问题通过非线性变换转换到高维(雷达短语PDW字中5~8个维度空间)的特征空间,在高维特征空间中构造线性判别函数来实现原始空间中的非线性判别函数[8~9],并采用径向基核函数保证机器有较好的推广能力,算法的复杂度与雷达信号样本维数无太大相关。
4 雷达信号样式分类与判断
实际工作中,获取的某型雷达信号样式多且未专门整理,并笼统将信号样式、工作模式混为一谈。雷达字是组成雷达信号的最基本单元,雷达短语则是由雷达字按照规则排列组成的序列,雷达句子是单部雷达包含多种工作模式的脉冲信号序列。国内外研究雷达工作模式识别[1,6~7],是对一个以上雷达短语的识别,通常将雷达信号进行分层建模,使用载频、脉宽、脉冲重复间隔、脉冲数等关键字对雷达脉冲序列采用“字-短语”的分层结构划分,利用人工智能手段、机器学习等数学方法分类相近的多个雷达信号样式,对所有分类器预测、投票,利用置信度确定分类结果。
4.1 雷达脉冲及信号样式
雷达在不同的工作模式下,产生不同调制方式和瞬时带宽的信号。雷达脉冲描述字主要有脉冲到达时间(TOA)、载波频率(RF)、脉冲宽度(PW)、脉冲重复间隔(PRI)等参数,即PDW={TOA,RF,PW,PRI,NTOR}。
4.2 信号分类与模式判断流程
信号样式分类中,考虑侦测信号噪声误差,编写雷达信号样本PDW字结构模型,进行大量样本训练、学习测试,减小雷达信号多维特征参数间交叠及模糊关系对样本分类判定准确率的影响,并采用SVM支持向量机分类识别器对特征库内信号样式进行算法自动标签计算和统计分类,实现信号样式自动分类识别、区分,减少相似度高、规律性不强的人工研判模糊性和主观性。雷达信号样式的分类判定流程如下。
第一步:雷达信号样式或短语。雷达脉冲描述字主要指标为PRIPWRFPWINTOR,并按照雷达信号特征库的结构表述,建立雷达信号短语建模(雷达信号样式)。
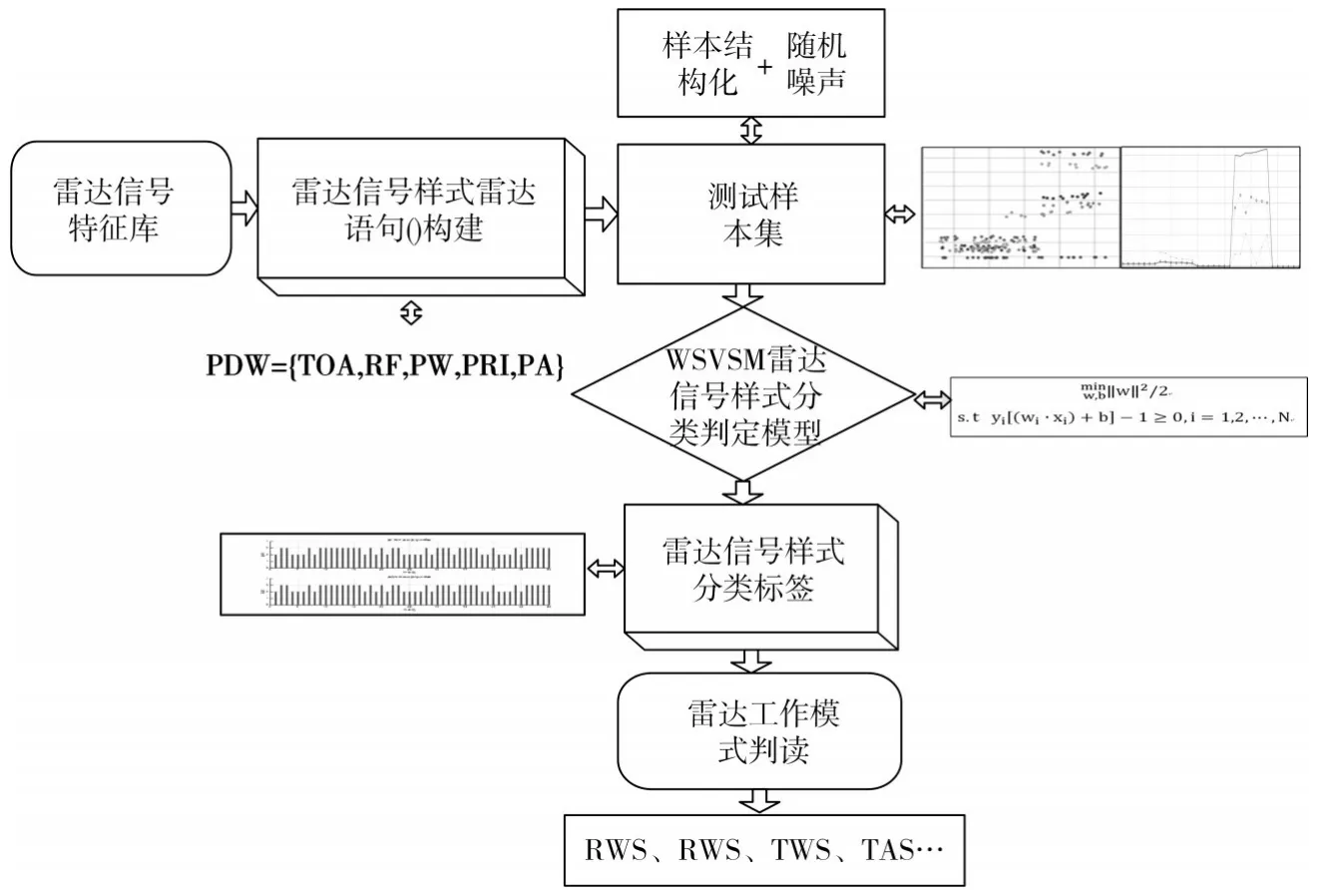
图1 雷达工作样式分类判定流程
第二步:模型训练学习。以雷达信号样式结构化描述的信号数组或结构体作为先验知识库来源,构建雷达信号样式分类学习的训练样本集。经过高斯核分类模型、参数寻优和自学习等步骤,优化信号样式分类模型。
第三步:信号样式分类。对测试样本集中的信号参数提取分层特征,按照雷达信号特征库结构化表述,运用第二步中训练好的雷达信号样式分类模型;模型中采用一对一分类方法;如果给定m个类,对m个类中的每两个类都训练一个分类器,经所有分类器预测、投票确定类属性;对于某个需要分类的雷达信号样式,以最大置信度标记并输出分类结果。
第四步:基于速度搜索、边搜索边测距、跟踪加搜索、海空搜索等典型等工作模式波形特点,以雷达PRI、脉宽、占空比、波束驻留数等特征为主要信息综合判断分类后信号样式所属工作模式[11~12]。
5 仿真计算
5.1 雷达信号样式分类
从雷达仿真数据库中提取某部雷达的一、二、三、四等4种信号样式,共计150个信号样本,叠加载频、重复间隔、脉宽、驻留时间等参数设备测量噪声;共生成1200个信号样本,其中随机选取5/6样本作为先验知识库即训练数据集,1/6作为测试数据集;选取信号指标为PW/PRI/PF/NTOR。利用VSM算法非线性分类训练学习计算雷达信号样式中的样式一、样式二和样式三。
图2为雷达信号的重复间隔与载频聚类、脉宽、脉冲数的聚类关系图。图3~图6为信号样式一、信号样式二、信号样式三的测试样本(各类样式样本100个)分类估计标签,信号样式一的分类估计标签为1的准确率为0、标签为2和3的准确率分别为0.4、0.6,信号样式二的分类估计标签为2的准确率为40%,信号样式三的分类估计标签为3的准确率为60%。样本训练和测试后,综合图6中显示的信号样式一、二、三的训练样本分类标签准确率,雷达信号样式一、样式二、样式三难以有效区分,分析为信号样式(同一类标签)。图7、图8为信号样式一、样式四的训练样本分类计算:信号样式一的分类估计标签为1的准确率为98%、信号样式四的分类估计标签为3的准确率为100%。样本训练和测试后,雷达信号样式一与信号样式四分类准确率高,区分明显,分析为不同信号样式(分类标签各为1、3)。

图2 雷达脉冲重复间隔与载频聚类、脉宽、脉冲数的聚类图
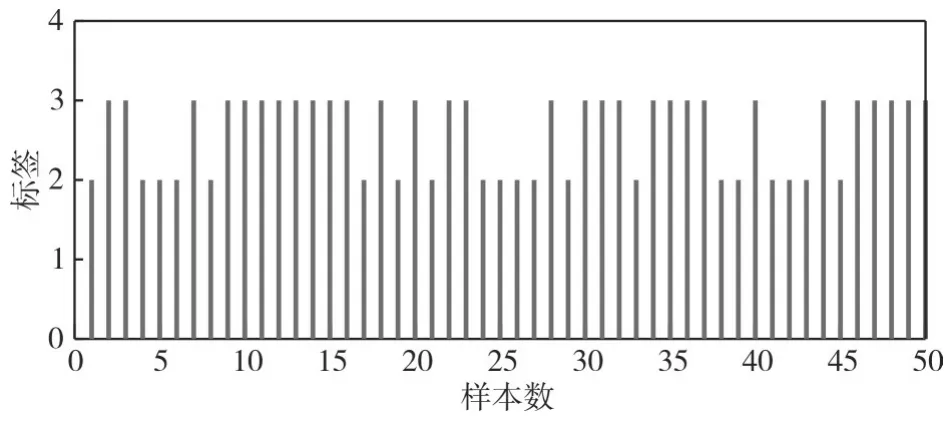
图3 信号样式一的分类估计标签(分类结果不明显)
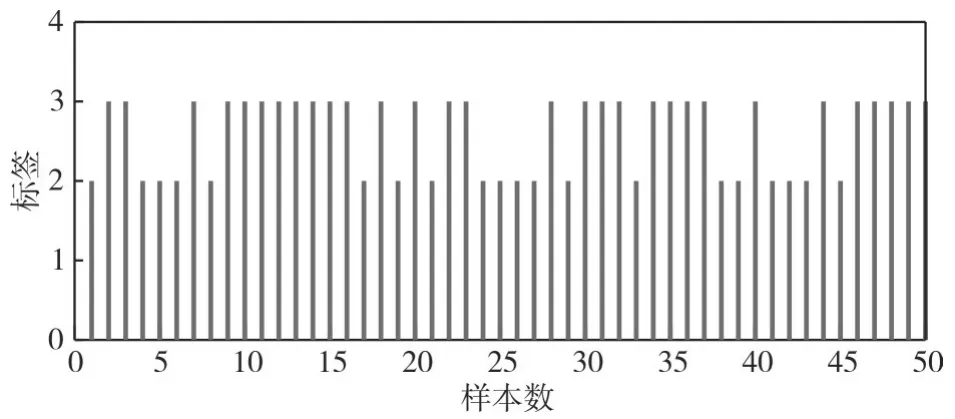
图4 信号样式二的分类估计标签(分类结果不明显)
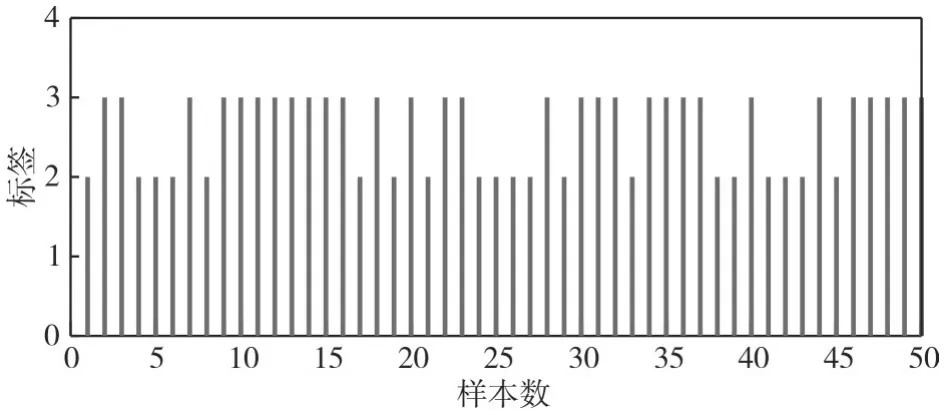
图5 信号样式三的分类估计标签(分类结果不明显)
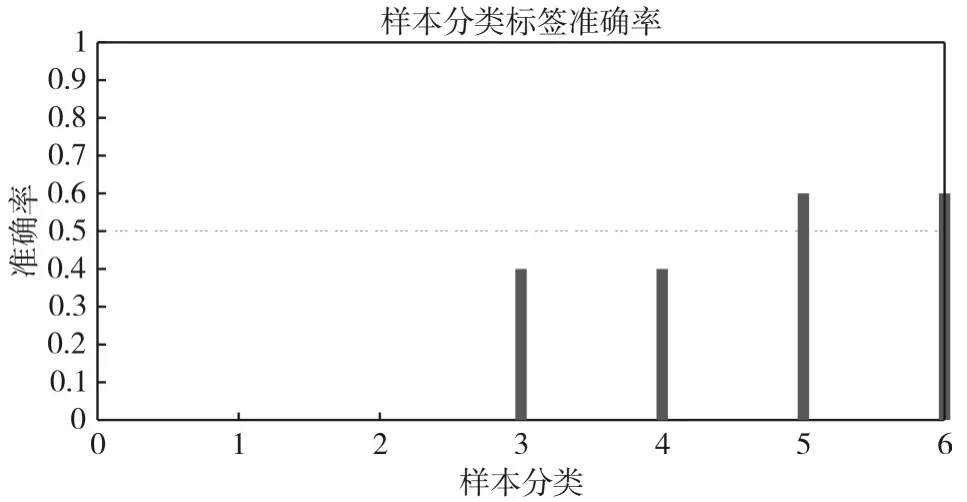
图6 信号样式一、二、七的训练样本分类标签准确率
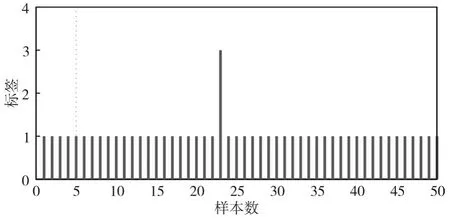
图7 信号样式一的分类估计标签(分类结果1)
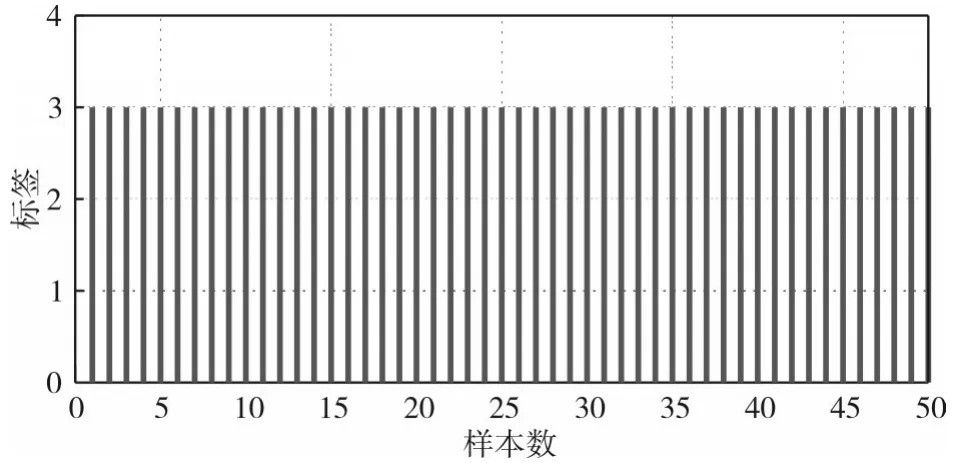
图8 信号样式一的分类估计标签(分类结果3)
5.2 雷达信号工作模式推断
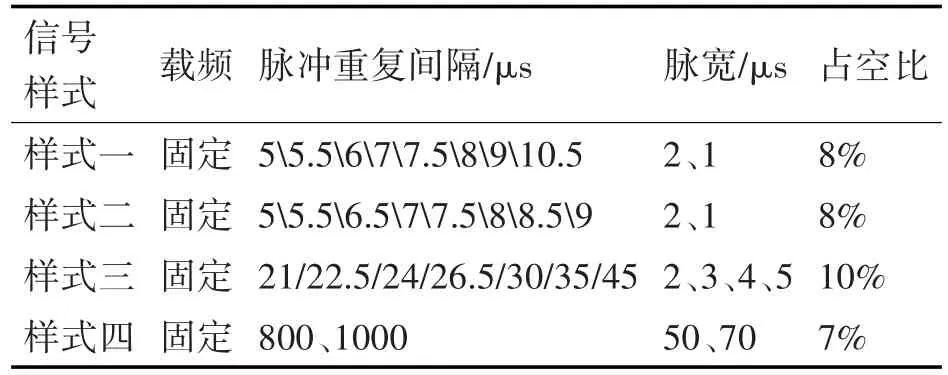
表1 雷达信号仿真参数
由于信号样式一、样式二和样式三的分类标签为2、3,分类标签估计结果相互交叠,且标签交叠率在40%~60%,分类结果为同一类信号样式;根据上述3种同一类信号样式的样本载频固定,重频组参,中高重频,中等脉宽,脉冲积累数大等特点,适用于对中远距离目标的搜索跟踪,脉冲驻留和数据率上基本相似,推断雷达信号样式一、样式二和样式三为边搜索边跟踪模式。样式四大脉宽大重复周期,推断为海面搜索工作模式。
6 结语
雷达信号样式并不严格对应于某一种雷达工作模式,本文主要目的是对雷达样式进行测试、学习和分类,并验证支持向量机方法在分类结果上的算法有效性,为后续机器学习测试提供工程基础;在算法的要素空间、搜索参数的选择上需要根据测试样本集丰富性进一步调整优化。
猜你喜欢
科学导报(2021年7期)2021-02-22
电脑爱好者(2021年2期)2021-01-22
初中生学习指导·中考版(2020年5期)2020-09-10
晚晴(2016年11期)2016-12-20
课堂内外(初中版)(2015年9期)2015-09-10
哈尔滨理工大学学报(2014年3期)2015-01-04
