
基于改进的数据融合滚动轴承故障诊断
2022-11-08 12:26齐咏生高胜利李永亭
铁道学报 2022年10期
齐咏生,白 宇,高胜利,李永亭
(1.内蒙古工业大学 电力学院,内蒙古 呼和浩特 010080;2.内蒙古北方龙源风力发电有限责任公司,内蒙古 呼和浩特 010050)
车轮设备的滚动轴承是使用最广泛的零部件之一,也是故障高发部件之一。在旋转机械设备中,滚动轴承承担着设备的全部重量,并且长时间的旋转工作使轴承的磨损程度大幅度增加。据统计,在机械设备故障中,有30%的故障是由滚动轴承引起的。在车轮运转过程中,轴承一旦发生故障,轻则造成财产损失,重则威胁公共安全,因此实现对滚动轴承的自动故障诊断具有重大意义。
20世纪80年代,振动信号开始被应用到故障诊断中,直到现在对振动信号进行分析与处理仍是当前对滚动轴承进行故障诊断应用最多的一种技术。旋转机械振动信号往往呈现非线性、非平稳的特性,对这种非平稳信号的局部化信息提取通常采取时频分析[1-2]方法。在20世纪90年代末,文献[3] 提出经验模态分解(EMD)方法,这是目前使用较广泛的一种将非平稳信号分解为多个模态并转化为平稳信号的分析方法。在此基础上,又演变出聚合经验模态分解(EEMD)[4],变分模态分解(VMD)[5]方法。此外,还产生了诸如小波分析、峭度分析、数学形态学分析等方法。文献[6] 使用EMD分解原始信号并提取其分量信号自回归模型参数和能量参数作为信号特征,结合支持向量机(SVM)对轴承故障进行分析,并取得了一定效果。但是,EMD方法存在端点效应、模态混叠、计算量大等问题。EEMD方法是在EMD方法的基础上对分析信号加入白噪声的一种改进方法,之前的研究中也曾采用EEMD方法提取故障信号特征,结合核熵成分分析(KECA)对滚动轴承进行故障诊断,并取得了一定的效果[4]。但是EEMD方法迭代次数较多,计算量大,降低了算法的效率。VMD是近几年新兴的一种信号分析方法,该方法计算速度快,不同频率的信号分量分解准确,文献[7] 详细论证了VMD在信号处理领域的优越性。文献[8] 使用数学形态学(MM)方法在时域中处理信号,提取故障特征,从而完成轴承的故障诊断,并取得了较好的效果。然而,上述方法均为单一故障诊断算法,每种算法都有各自的优缺点,而单一算法不能实现优势互补,难免会产生受噪声干扰大、误诊率高、可靠性差等缺陷。
针对这一问题,本文提出一种基于数据融合的机械轴承复合诊断算法。该算法采用双通道并行诊断,通道1采用VMD对原始振动信号进行模态分解,提取各模态的特征组成特征向量作为SVM的输入进行故障分类,使用贝叶斯准则[9]将分类结果映射为概率形式完成类型识别;通道2采用数学形态学对原始信号进行滤波处理,将处理后的信号特征转化为频域形式,并通过相关性分析对比频谱完成故障类型的识别。最后使用改进加权证据理论将以上两通道分类结果进行数据融合,得到更为可靠的故障诊断结果。在众多数据融合方法中,证据理论是一种能够突出目标、降低干扰的融合算法。因此,以证据理论为基础并加以改进,非常适合最后的数据融合工作。融合结果也表明,该方法将VMD-SVM的分类结果准确度高的优点与MM-CA方法具有更强“泛化能力”的优点有效结合,很大程度上提升了旋转机械滚动轴承故障诊断的准确性和可靠性。
1 数据融合混合诊断算法
1.1 基于VMD-SVM的轴承故障诊断算法
图1为VMD-SVM故障诊断算法的流程。图1中左半部分表示待检测未知类型故障信号;右半部分为对m类故障信号建立分类器的操作流程。

图1 基于VMD-SVM的诊断方法流程
算法具体步骤如下:
Step1使用振动信号采集装置采集m类故障轴承的振动信号,每类故障信号包含n个样本。
Step2用小波变换对原始信号进行去噪,最大限度降低模态分解后的干扰。
Step3将去噪后的信号进行VMD分解,得到一系列模态分量IMFs。对其中各IMF求其能量E(IMF)、能量熵HEN和熵价值V[10]。对IMFs进行筛选,舍去其中熵价值较低且显著偏离其他熵价值的模态。例如,将0.177 8 mm内圈故障信号按频率成分可分解为4个IMF,使用熵价值法计算4个模态熵价值分别为-1 822.17、-1 832.41、-1 815.27、-1 940.38。显然,模态4对应的熵价值最小,且显著偏离其他熵价值较多,因此舍掉模态4。实际上,熵价值越大,IMF中包含的故障信息就越多;而且从另一个方面分析可知,由于模态4主要代表信号的高频成分,通常包含较多噪声,不利于作为特征向量,因此也需要剔除。
Step4求筛选后的IMFs重构信号的能量熵HEN,并与之前计算的各IMF的能量Ei,组合为复合特征向量T=[E1E2…EnHEN]。
Step5分别对m类故障的振动信号进行Step1~Step4得到m类型的故障特征向量。将得到的故障特征向量作为SVM分类器的输入训练数据,构建“一种类型与其他类型”的一对多分类器,构建数量与故障类型个数相同。
Step6采集待检测的振动信号,将振动信号采用Step1~Step5相同的技术处理后得到特征向量T1。
Step7将特征向量T1作为SVM分类器的检测数据输入,得到分类结果。将分类结果使用贝叶斯估计[9]映射为概率模型,给出判别结果。
这种方法本质上是在频域中提取信号特征,其优点是检测速度快、计算量小,能够较好检测出已训练过的故障类型,分类清晰且干扰性小。但是该方法存在泛化能力弱的缺点,即对于同类型不同损伤等级的故障样本如果没有参加训练,检测结果可能会失效。
1.2 基于MM-CA的轴承故障诊断算法
图2所示为MM-CA算法[11]的流程,算法包含两部分,左半部分为训练建模过程,对已知m类故障数据进行训练和建模;右半部分为算法应用过程,对待测信号进行故障识别和诊断。
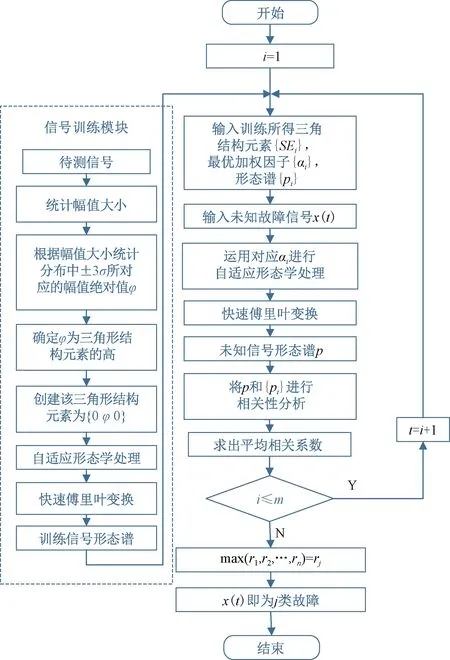
图2 基于MM-CA的诊断方法流程
该算法具体实施步骤如下:
Step1根据目前已知的轴承故障类型将训练信号分成m类,每一类包含n个训练样本信号。分别组成信号集合{xi,j}(i=1,2,…,m;j=1,2,…,n)。计算每个信号的标准差σ,根据设高为±3σ的三角形结构元素创建方法,计算出各类已知信号所对应的三角形结构元素SEi(i=1,2,…,m)。
Step2确定相对应故障信号自适应加权{αi}(i=1,2,…,m),采用自适应开闭运算和结构元素SEi对信号集合{xi}进行处理,以提取信号集合{xi}的特征信息。
Step3釆用快速傅里叶变换对处理后的信号集合{xi}(i=1,2,…,m)进行变换得到与之对应的自适应形态频谱集{pi}(i=1,2,…,m)。
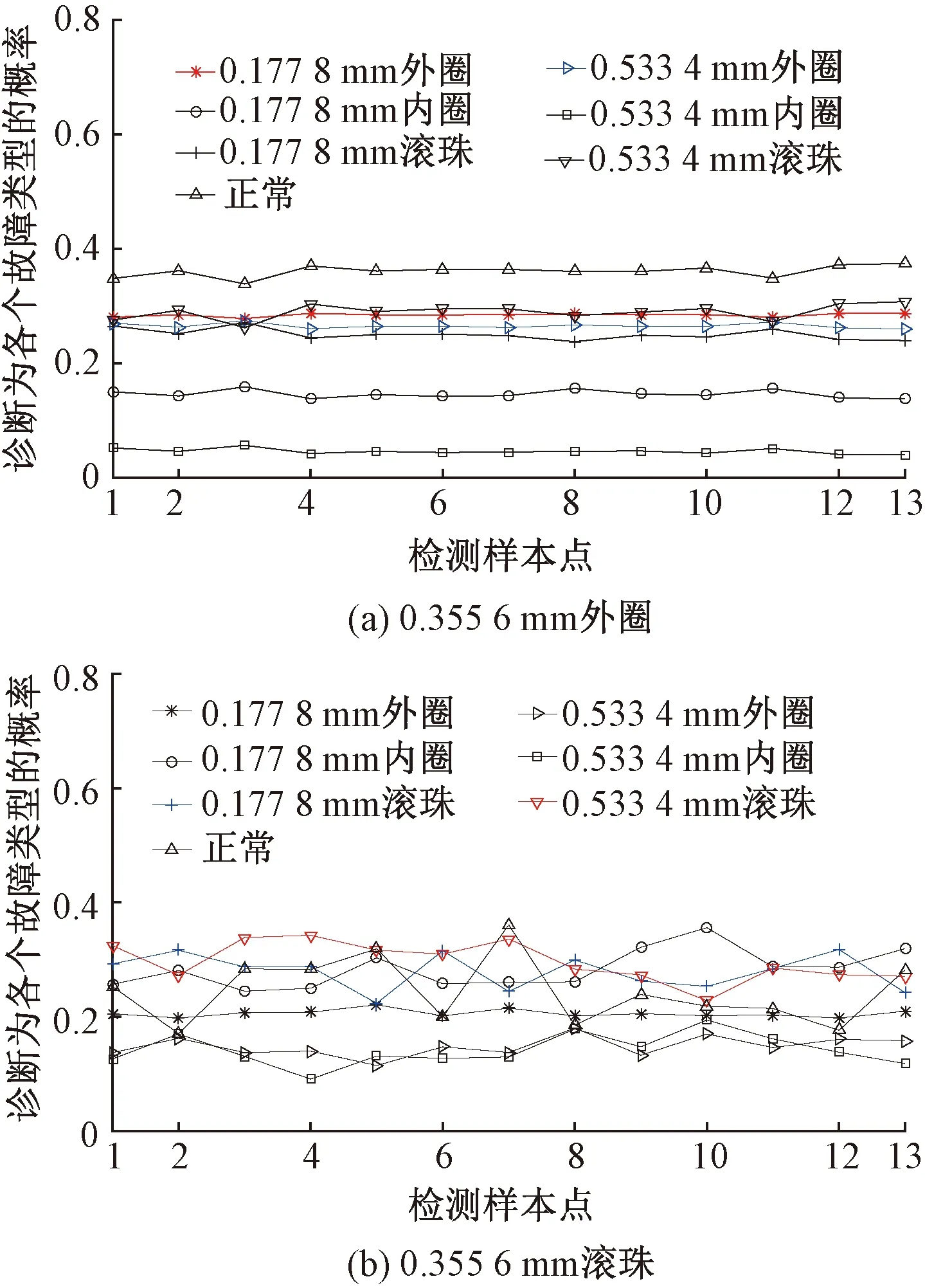
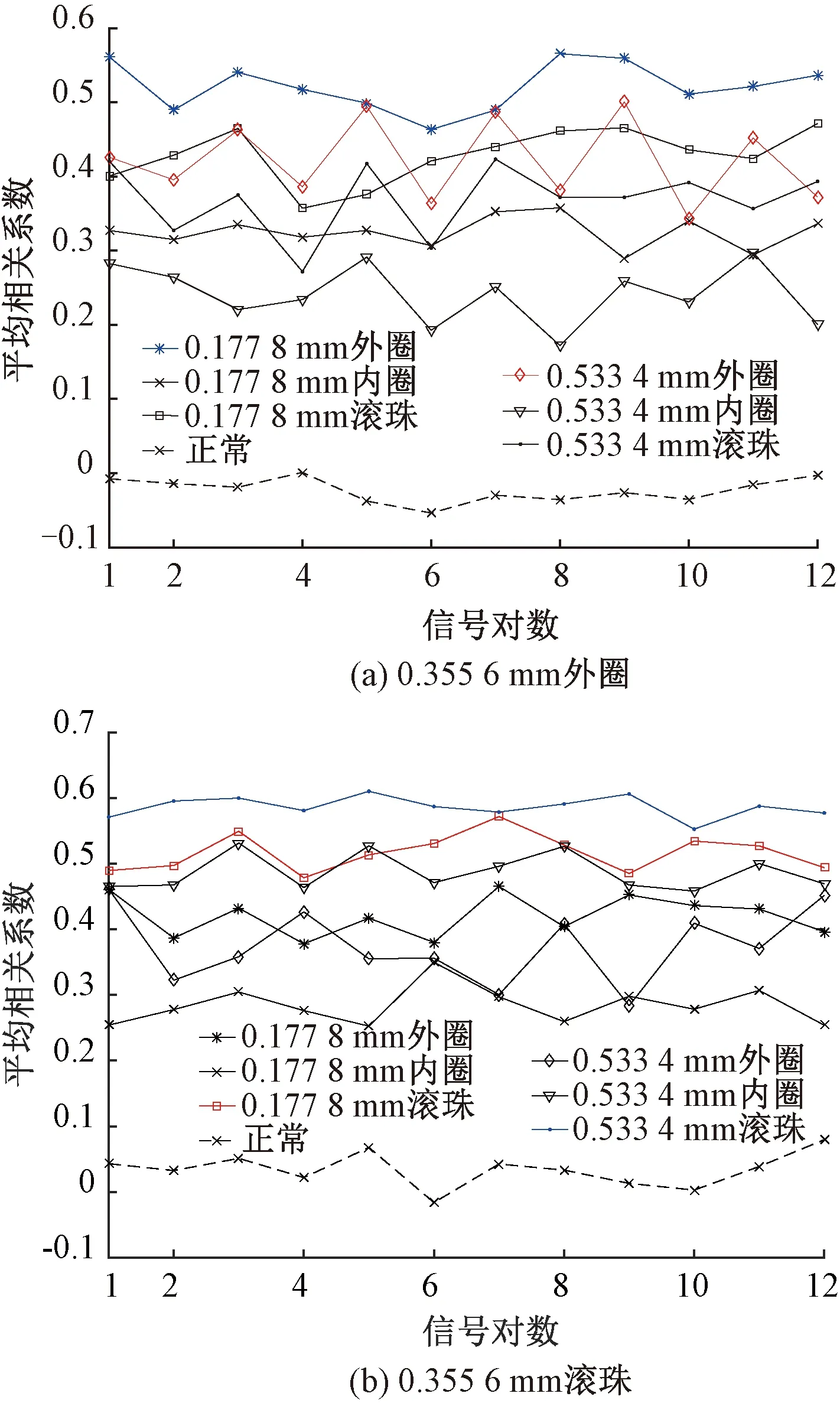
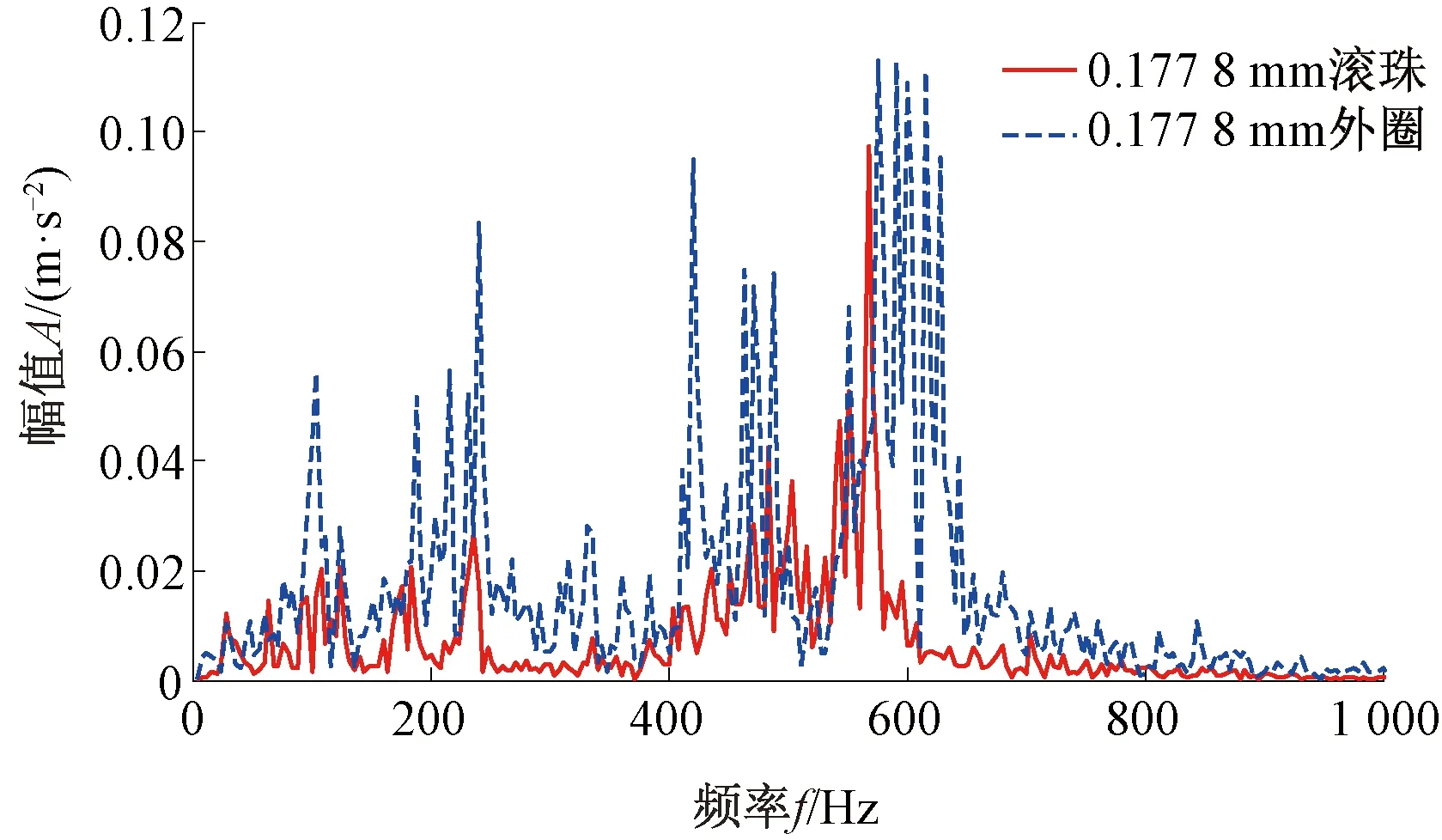
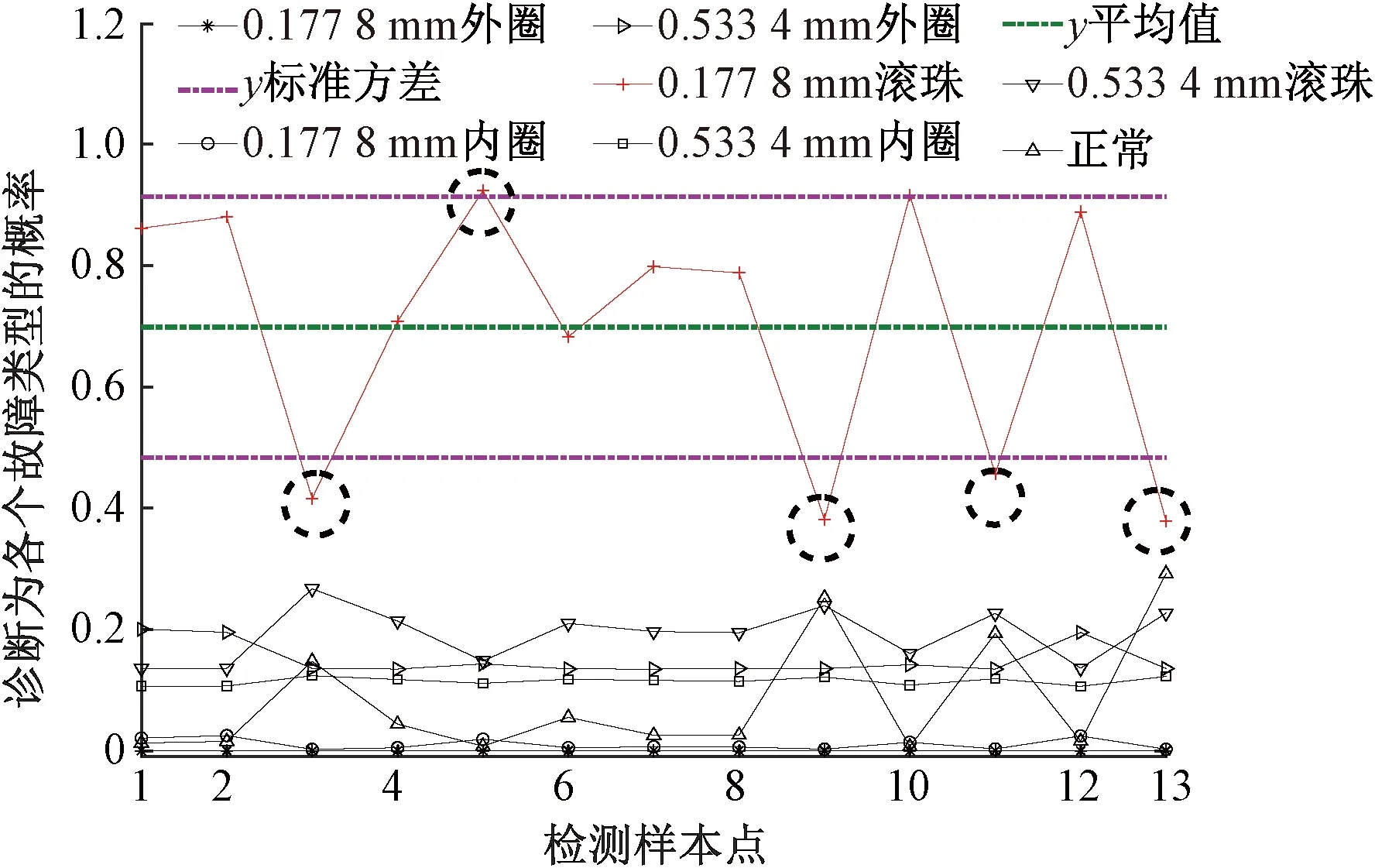
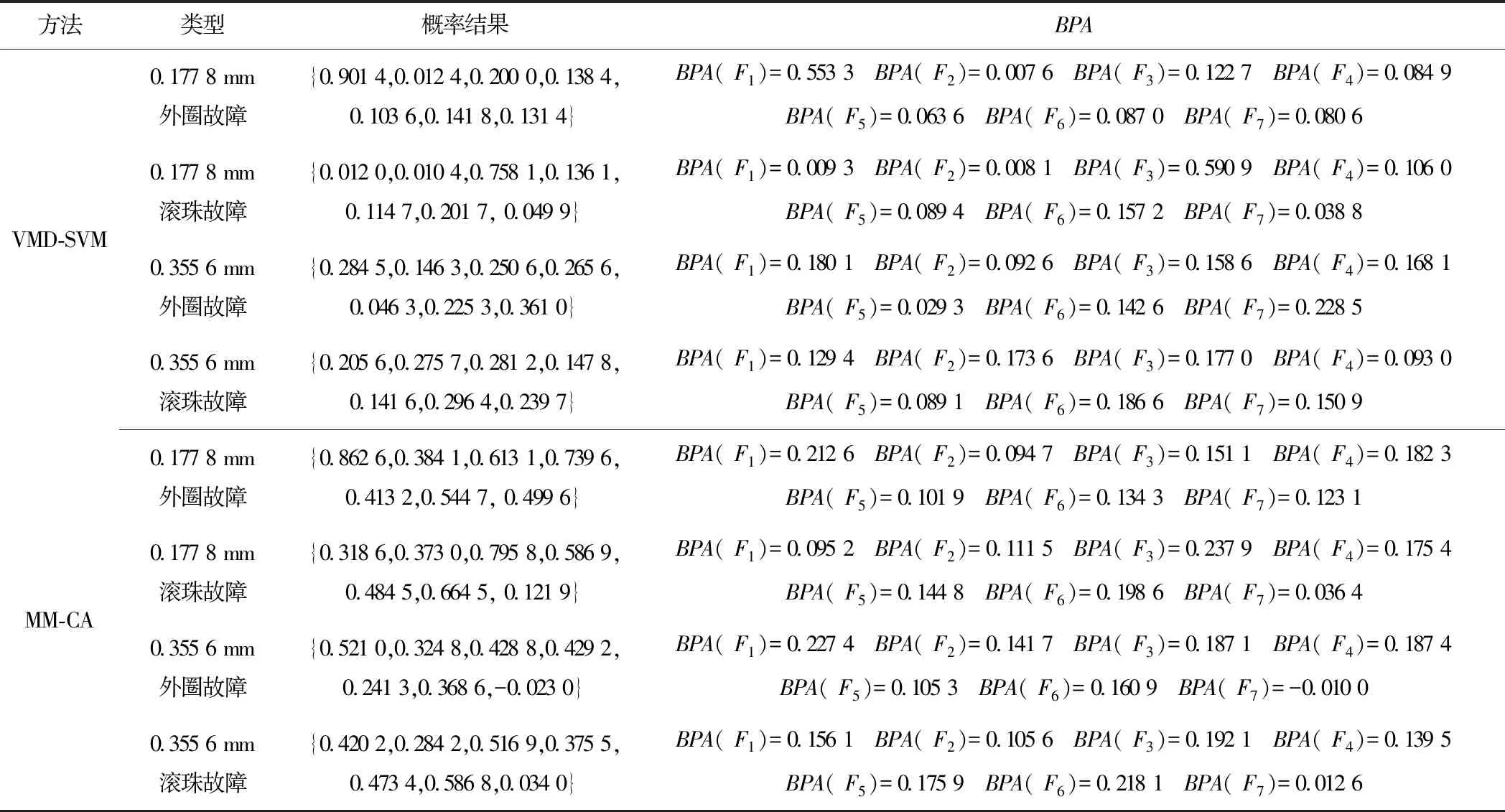
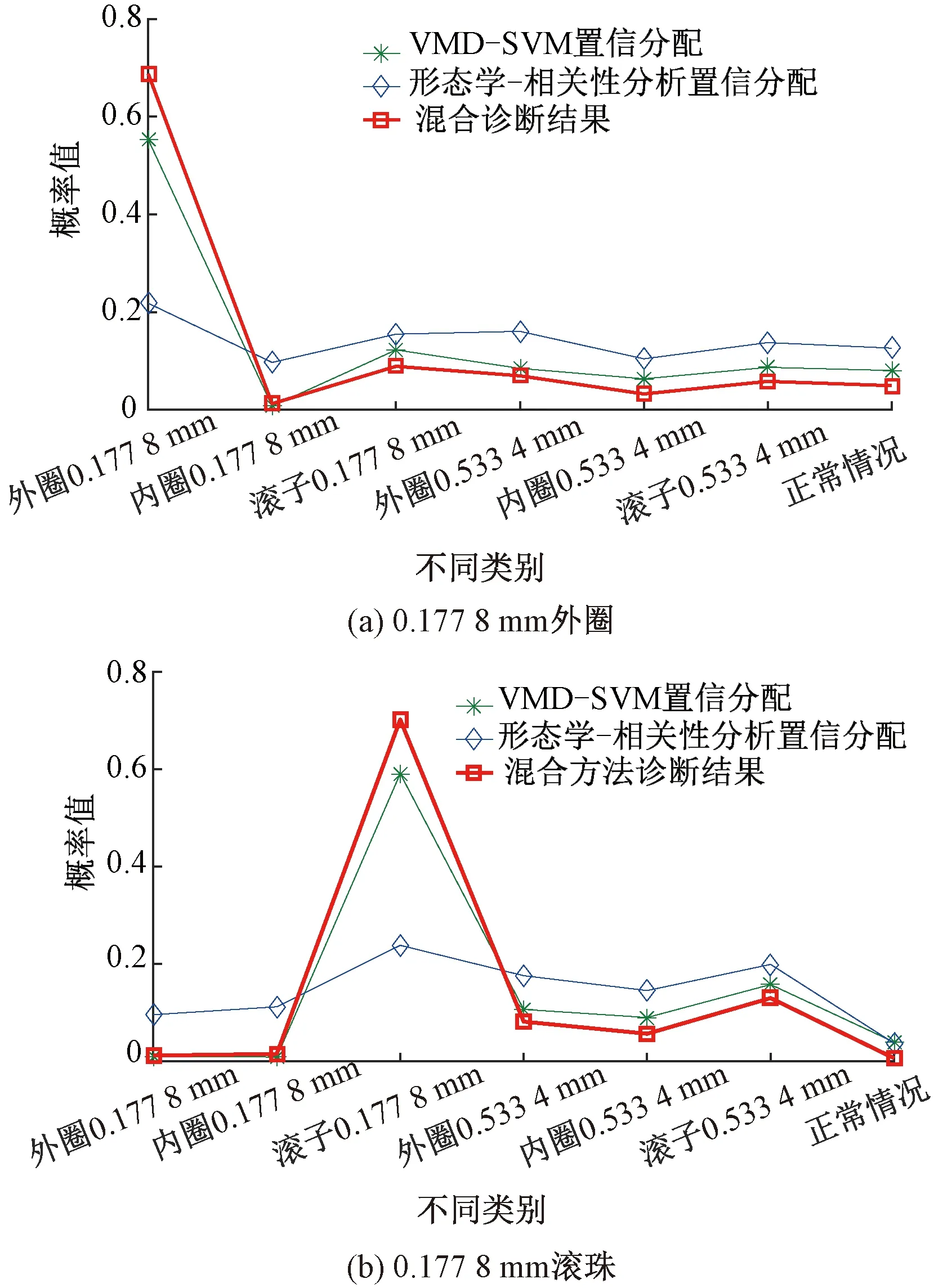
Step4对于未知故障状态的轴承信号x(t),分别采用由训练预处理得到的三角形结构元素SEi(i=1,2,…,m)和对应故障信号自适应加权系数{αi}(i=1,2,…,m),对其进行形态学处理以提取该信号的特征,通过傅里叶变换得到该信号的自适应形态频谱p。分别计算待测信号的自适应形态频谱p和训练预处理的自适应形态频谱集{pi}之间的平均相关系数ri。假设r1到rm中最大的一个为rs(0 MM-CA算法本质上是在时域中提取信号特征,在检测故障效果上该方法计算量较小,运行速度较快,检测效果较好。这种方法还具有一个明显的优点,即具有较强的泛化能力。当同种类型不同损伤等级的故障样本未参加训练时,该方法也能准确检测出其故障类型。但是其优点也是影响其检测效果的缺点,由于其泛化能力强,造成检测的精确度不够高,受噪声影响较大,检测结果中往往存在干扰项。 证据理论(DS)[12-14]作为一种信息融合的方法在各行各业已经进行了广泛的研究并得到了一定的应用,但是如果样本本身存在较大问题时,DS证据理论在处理冲突时也会出现失效的情况。当一个证据的置信分配为0时,融合的结果会发生彻底否定该证据的可能。当证据的置信分配发生微小变化时,DS证据理论的融合结果会出现较大变动。为了克服DS证据理论的这些缺点,近年来很多专家都致力于改进DS证据理论方法的研究,其中对所有证据的置信分配进行加权平均是一种效果较好又应用广泛的处理方法[15-17],这种方法可以很好的处理证据的冲突问题。在数据融合之前,为了得到更可靠的证据输入,与常规加权证据理论相比,本文在证据理论的输入端加以改进,首先用标准差法筛选证据结果,计算筛选结果的平均值作为证据输入,通过这种改进可以剔除极端证据情况的发生,得到更稳定的输入。其次,为了避免由于一个0分配置信证据导致融合结果全盘否定的现象发生,本文提出当出现0置信分配时,为该置信分配赋值0.01,同时将最大的置信分配减去0.01。 具体实施方法如下: Step1对两种算法分别选取s个检测信号进行检测,并计算两种方法检测概率结果的均值与标准差{μ1,σ1,μ2,σ2},按照约束条件μ-σ≤Or≤μ+σ,r=1,2,…,s,筛选每个检测信号的诊断结果,剔除极端值。计算满足条件值的均值Ok作为算法概率形式的故障诊断结果。 Step2将两种算法概率形式的故障诊断结果,按照式( 1 )归一化。 ( 1 ) 式中:Ok表示诊断为各类故障类型的概率输出;BPA(k)为各类故障的置信分配,k代表总数为m个故障类型中的一个。初步得到各类故障的置信分配(BPA值)。 Step3设所有故障类型集合为{A1,A2,…,Am},对于同一种故障类型两种算法的判断结果h1(Ak)和h2(Ak),相似度计算式为 ( 2 ) 式中:hp(Ak)、hq(Ak)为不同算法诊断同一故障时的BPA值;p、q为不同种方法,pq。 Step4利用相似度分别计算两种算法对应同一类故障Ep(Ak)的支持度Supp(Ak)和信任度Crep(Ak)。 ( 3 ) ( 4 ) Step5以信任度Crep(A)为权值对两种算法针对同一类故障的证据的置信分配进行加权,并应用到所有故障类型当中。归一化之后得到最终的置信分配,计算式为 ( 5 ) ( 6 ) 式( 5 )用于权值修正,式( 6 )用于归一化。将得到的新的置信分配BPAmean按照DS证据理论的规则自身融合T-1次得到最终诊断结果。本文选取T=2,即新的置信分配自身融合一次得到最终结果。原DS证据理论融合规则计算式为 ( 7 ) ( 8 ) 图3为本文提出的基于数据融合诊断算法的总体流程。该数据融合算法首先将m类故障的原始振动信号划分为等长的数据段,将同类型的所有数据段组成一个故障样本Ak,k=1,2,…,m,所有样本构成样本集{A1,A2,…,Am}。将该样本集分为两部分,训练集和检测集。使用1.1节和1.2节两种算法,并依据训练集和检测集得到各自的m类故障类型的概率形式诊断结果。最后使用加权证据理论完成数据融合,得到最终的融合诊断结果。 图3 基于数据融合的混合诊断算法流程 该融合算法依据自身特点,弱化冲突证据,增强相容证据,使互补的两种算法诊断结果相互融合,提高了轴承故障诊断结果的准确性和可靠性。 为了验证本文所提出方法的有效性,本文采用美国Case Western Reserve University(CWRU)轴承数据中心数据,该实验中心通过电火花技术在轴承上加工单点故障,轴承类型为SKF6205,用加速度传感器测量轴承振动信号,数据中包含了不同条件的多组数据,这里选择负载为3 HP(约2 200 W)、转速为1 730 r/min、采样频率为12 000 Hz的轴承驱动端振动信号进行仿真验证。所用数据对应的轴承运行状态包括正常、内圈故障、外圈故障以及滚动体故障4种类型,每种故障类型又包含3种不同损伤程度的故障,即损伤直径为0.177 8、0.355 6、0.533 4 mm。本文所选故障数据与大多数文献中所选数据基本相同。这样选择有两个目的:①易于算法比较;②这些数据相对诊断难度较大,能够更好地体现出算法的有效性。 图4 不同方法故障结果 两种单一方法均使用0.177 8 mm轴承故障数据与采用0.533 4 mm轴承故障数据作为训练数据,构建故障特征库。不同方法诊断故障结果见图4。由图4(a)、图4(c)可知,使用VMD-SVM方法对机械轴承进行故障诊断效果良好,诊断结果无交叉点,即不存在误诊断结果。由图4(b)、图4(d)可知,使用MM-CA方法对机械轴承进行故障诊断,诊断结果存在干扰项,诊断结果并不理想。通过对比图4(a)、图4(b),图4(c)、图4(d)可知,VMD-SVM方法的目标样本与其他样本的间隔较大,即干扰较小。MM-CA方法的目标样本与其他样本的间隔较小,存在干扰项。 下面采用未经过训练的样本0.355 6 mm外圈故障和0.355 6 mm滚珠故障对两种单一诊断算法进行测试。 如图5所示,VMD-SVM方法对于未参与训练的0.355 6 mm外圈故障(图5(a))和0.355 6 mm滚珠故障(图5(b))没有识别能力,均给出了错误结果。表明该方法虽然对训练过的故障类型数据抗干扰能力强、准确度高,但对未参与训练的同种故障不同损伤程度数据无法实现有效检测。 图5 VMD-SVM方法诊断故障结果 如图6所示,MM-CA方法对于未参与训练的0.355 6 mm外圈故障和0.355 6 mm滚珠故障样本虽然不能检测出具体的损伤等级,但均能正确识别出发生的故障类型。图6(a)最高和次高的检测概率曲线显示,该方法可以检测出0.355 6 mm外圈故障类型属于外圈故障,并且该损伤等级更接近0.177 8 mm。同理,图6(b)最高和次高的检测概率曲线显示,该方法可以检测出0.355 6 mm滚珠故障类型为滚珠故障,并且该损伤等级更接近0.533 4 mm。分析可知,当匹配样本中没有与测试样本同种类型同种损伤程度的样本时,算法就会匹配最相似的样本,即匹配同类型不同损伤程度的样本,实现故障类型的有效检测。上述实验表明MM-CA方法具有较强的泛化能力。 图6 MM-CA方法诊断故障结果 进一步分析原因,使用数学形态学处理0.177 8 mm滚珠故障和0.177 8 mm外圈故障后,对比其频谱,如图7所示。在相同损伤等级,不同类型故障条件下,两种故障信号的频谱几乎完全不同。图8所示为损伤等级为0.177 8 mm和0.533 4 mm的滚珠故障频谱对比。由图8可知,二者属于同种故障类型,故障特征频率理论值是相同的,因此在频谱图中大部分频率是重叠的,尤其是中频和低频段,其频谱相似性保证了MM-CA方法具有较强的泛化能力。这也是MM-CA方法能够区分不同故障与相同故障不同损伤程度的主要原因。 图7 0.177 8 mm滚珠与0.177 8 mm外圈故障频谱对比 图8 0.177 8 mm与0.533 4 mm滚珠故障频谱对比 在数据融合算法中,采用并行通道对故障进行初步诊断。对于通道1(AVMD-SVM故障诊断方法)和通道2(MM-CA故障诊断方法)的初步诊断结果,首先采用标准差法对诊断结果进行筛选。以AVMD-SVM诊断0.177 8 mm滚珠故障为例,如图9所示。首先计算最高判别线0.177 8 mm滚珠故障判别结果的标准差,在均值μ±标准差σ范围外的点为极端判别点,为了避免极端情况对概率结果产生影响,将这些点舍去,计算剩下点的平均概率值作为判别0.177 8 mm滚珠故障的最终概率结果。其他判别线均使用这种方法,得到全部概率判别结果。将两种方法的故障诊断概率结果归一化,得到初步置信分配。表1所示为VMD-SVM、MM-CA方法的概率平均值诊断结果以及置信分配。表1概率诊断结果均按照 “0.177 8 mm外圈(F1)”、“0.177 8 mm内圈(F2)”、“0.177 8 mm滚珠(F3)”、“0.533 4 mm外圈(F4)”、“0.533 4 mm内圈(F5)”、“0.533 4 mm滚珠(F6)”、“正常情况(F7)”顺序排序。 图9 标准差法筛选0.177 8 mm滚珠故障判别结果的点 表1 不同方法诊断结果及基本概率置信分配 如图10所示,将MM-CA方法的诊断结果归一化后,其存在干扰项的缺点很明显表现出来,诊断的目标类型结果并没有非常突出的高于其他类型诊断结果。结合VMD-SVM诊断结果抗干扰强的优点,经过加权证据理论融合后的诊断结果可知,目标故障的诊断概率明显上升,高于任何一种单一诊断方法的概率结果,而其他故障类型诊断概率被降低。充分体现了VMD-SVM方法能够弥补MM-CA方法准确度不够高的问题,表明了融合算法的优势。从复合诊断效果图中可以看到该方法对参与训练的样本,具有突出故障目标、降低干扰、增强故障诊断结果可靠性的优点。 图10 数据融合算法故障的诊断结果 数据融合算法故障的诊断结果如图11所示。由图11(a)可见,单一VMD-SVM方法无法判断0.355 6 mm外圈故障的正确故障类型,并且将该类型判断为正常数据的概率最高。而MM-CA方法可以正确诊断故障,其泛化能力可以弥补VMD-SVM方法的不足,数据融合方法判断0.355 6 mm外圈故障最接近于0.177 8 mm外圈故障,次接近于0.533 4 mm外圈故障。综合看融合算法的判别结果,突出了判别为0.177 8 mm外圈的概率结果,平滑了诊断为其他故障类型的概率结果。实现优势互补,完成了轴承故障类型的判别,增强了诊断可靠性。 图11 数据融合算法故障的诊断结果 由图11(b)可见,数据融合算法的判断结果表明0.355 6 mm滚珠故障更接近于0.533 4 mm滚珠故障,次接近于0.177 8 mm滚珠故障,给出了正确的故障类型判别结果。除此之外,两种滚珠故障的概率均得到了突出,其他干扰故障类型的可能性被降低和平滑。综合来看,当诊断未参与训练的不同损伤程度故障数据时,数据融合算法实现了正确诊断故障类型的目的,体现出了较强的泛化能力和突出故障目标、降低干扰的能力。 针对机械滚动轴承中的单一故障诊断方法存在干扰大、训练样本不完备而导致误诊率较高、可靠性较差等问题,提出一种基于数据融合的复合故障诊断算法。该方法使用改进加权证据理论融合两种不同特点的单一算法的诊断结果,综合了VMD-SVM方法对于已训练样本诊断准确度高、抗干扰强的优点和MM-CA方法具有较强泛化能力的优势,实现了复合算法优势互补,从而提高诊断算法可靠性的目的,具有一定的工程应用价值。1.3 加权平均证据理论以及融合诊断算法
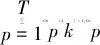

2 实验验证
2.1 单一方法诊断效果


2.2 基于数据融合的复合方法诊断效果

3 结论
猜你喜欢
汽车实用技术(2022年16期)2022-08-31
防爆电机(2022年4期)2022-08-17
一重技术(2021年5期)2022-01-18
防爆电机(2021年5期)2021-11-04
防爆电机(2021年3期)2021-07-21
农业机械学报(2021年6期)2021-06-29
东坡赤壁诗词(2020年4期)2020-09-02
电子制作(2018年10期)2018-08-04
知识就是力量(2014年3期)2014-03-06
汽车电器(2014年5期)2014-02-28
