
基于跨尺度低秩约束的图像盲解卷积算法
2022-11-08 01:48彭天奇禹晶肖创柏
自动化学报 2022年10期
彭天奇 禹晶 肖创柏
图像复原旨在对图像降质过程进行建模,求解降质模型的逆过程,从降质图像中恢复出原始的清晰图像.模糊是一种常见的图像降质现象,通常由于相机的抖动、散焦以及物体的运动造成.单幅图像去模糊问题研究如何从一幅模糊图像中恢复出原始的清晰图像.根据模糊核是否已知,去模糊方法可分为两类: 1)若模糊核已知,则称为非盲复原方法;2)若模糊核未知,则称为盲复原方法.
对于均匀模糊图像的形成过程可以表示为如下卷积模型

其中,y表示模糊图像,x表示清晰图像,∗表示卷积运算,h为模糊核,n为噪声.在卷积模型下,图像盲复原即研究如何从模糊图像中同时估计出模糊核h和清晰图像x.由于将模糊过程建模为卷积的形式,因此盲复原问题也称为盲解卷积问题.
图像盲解卷积是一个严重的欠定逆问题,待求解的未知变量数目大于已知方程的数目,解不唯一.现有的大部分方法通过引入模糊核和图像的先验知识来约束问题的解空间.
一类为基于显著边缘的方法,此类方法充分利用图像中的显著边缘结构对模糊核进行估计.Jia等[1]首先利用图像边缘进行运动模糊核的估计,其边缘的选取是通过手工抠图完成的,这一方法非常依赖抠图的准确性.Joshi等[2]直接从模糊图像中提取出显著边缘,并根据提取的边缘估计模糊核,然而,由于很难直接从大模糊图像中提取显著性边缘,此方法仅对于小模糊图像较为有效.Cho等[3]利用冲击滤波器(Shock filter)对图像进行边缘的选择并用于模糊核估计;Xu等[4]在该方法的基础上验证了不同宽度的边缘对于模糊核估计的影响.这种方法由于增强模糊图像的边缘,在迭代求解的过程中,为了避免出现边缘过增强等现象,一般需要根据迭代次数不断调节边缘增强算法的参数,因而对参数设置较为敏感.
另一类为基于最大后验概率(Maximum a posteriori estimation,MAP)估计或其变分模型的方法[5−18].基于MAP 估计的方法在条件概率服从某一种噪声模型,结合清晰图像和模糊核的先验概率模型的假设条件下,通过最大化后验概率来估计清晰图像和模糊核,而变分模型则是在噪声概率模型服从高斯分布的条件下,通过负对数函数将最大化后验概率问题转换为最小二乘问题.早期,Chan等[5]利用全变分的方法来约束清晰图像的梯度.Levin等[6]提出了一种超拉普拉斯先验建模图像的梯度来估计模糊核.Fergus等[7]假设清晰图像的梯度服从拖尾分布(Heavy-tailed distribution),结合高斯分布模型利用变分贝叶斯方法和期望最大化求解最大后验概率问题.Levin等[8]证明直接求解最大后验概率问题偏向获得平凡解,即模糊图像本身和二维狄拉克函数,这是因为图像梯度先验在很多情况下偏向于模糊图像,而不是清晰图像.Perrone等[9]利用全变分正则化进行模糊核的估计,并且证明了投影交替最小化(Projected alternating minimization,PAM)方法可以有效避免平凡解.图像梯度表示邻域内像素之间的关系,由于自然图像包含复杂的结构,仅利用相邻像素之间的关系很难清楚地描述这种复杂的结构,基于图像块的先验可以表示更大更复杂的图像结构.Michaeli等[10]利用不同尺度图像之间图像块的相似性作为先验来估计模糊核.Zhang等[11]将图像块的稀疏表示作为先验进行模糊估计,并利用K-SVD (K-singular value decomposition)算法[19]通过其他自然图像或模糊图像本身训练字典.Ren等[12]构造了图像亮度和梯度的低秩约束先验用于模糊核的估计.Pan等[13]在模糊核的估计中引入了暗通道先验,即图像块中不同通道的最小像素值,但是这种方法不适用于缺乏暗像素以及有噪的图像,这是因为在这种情况下,无法保证暗通道的稀疏性.在Pan等[13]方法的基础上,Yan等[14]结合亮通道先验与暗通道先验作为约束项以提高算法的鲁棒性.常振春等[15]将图像块的稀疏表示和非局部(Non-local)自相似模型作为先验进行模糊核的估计.Chen等[16]利用ℓ1范数约束局部最大梯度值作为正则化项来估计模糊核.
本文将上述方法统称为基于模型的方法.近些年,基于深度学习的方法[20−23]逐渐广泛应用于图像去模糊领域.最初,此类方法主要是采用深度卷积神经网络(Convolution neural network,CNN)模型实现对清晰图像的估计或者对模糊核的估计.Su等[20]首先提出了一种基于深度卷积神经网络的视频去模糊算法,该方法通过卷积神经网络模型端到端地学习多帧模糊图像与清晰图像之间的关系并用于清晰图像的复原.Yan等[21]利用深度卷积神经网络进行模糊核分类并利用广义回归神经网络(General regression neural network,GRNN)进行模糊核参数的估计.Sun等[22]设计了一种基于马尔科夫随机场(Markov random field,MRF)的卷积神经网络用于非均匀模糊核的估计.从卷积神经网络到近期提出的生成式对抗网络(Generative adversarial network,GAN)[24],基于深度学习的方法取得了更好的去模糊效果.Kupyn等[23]利用条件生成式对抗网络(Conditional generative adversarial network,cGAN)进行去模糊,使网络直接输出清晰图像.然而,基于深度学习的方法主要有3 个方面的问题: 1) 网络很难训练,需要大量的训练数据,而且对参数的设置非常敏感;2)网络无法保证输出的结果符合数据保真项,虽然在训练过程中可以产生较好的效果,但是在不同于训练数据特征的图像上可能会失效;3) 对于估计不同类型的模糊核,需要用不同的模糊图像训练网络,且很难获取真实模糊训练数据集.综上所述,基于深度学习的方法受到了一定程度的限制.
目前大部分的盲解卷积算法对噪声较为敏感,尤其对于大模糊有噪图像,无法准确估计模糊核.本文的算法旨在构造基于图像块的先验模型,解决大模糊有噪图像的模糊核估计问题.本文提出了一种基于跨尺度低秩约束的单幅图像盲解卷积算法,利用跨尺度自相似性,在降采样图像中搜索相似的图像块,构成相似块图像组矩阵,通过对相似图像块组矩阵进行低秩约束,迫使当前图像在迭代中更加清晰,使重建图像接近清晰图像.一方面,模糊降低了图像的跨尺度自相似性,清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性,因此图像跨尺度低秩先验使解偏向清晰图像而不是模糊图像;另一方面,降采样减弱了图像的模糊程度,与模糊图像相比,其降采样图像与清晰图像具有更强的相似性,迫使模糊图像更加接近清晰图像.文献[10]在上述两点结论的基础上,通过约束相似图像块与清晰图像块之间的相似性来估计模糊核,该算法与本文的算法均利用跨尺度自相似性提供的附加信息进行模糊核估计,不同之处在于该算法将图像中的各个图像块与其每一个相似图像块进行单独比较,相似图像块之间是相互独立的,通过最小化清晰图像块与相似图像块之间的均方误差来约束清晰图像块.为了更好地利用相似图像块之间的相关性,本文的算法将降采样图像中的相似图像块构造为一个相似图像块组,并对该组进行整体的低秩约束,一是非局部相似图像块引入了附加的空间结构信息,更有利于图像块空间结构的重建,二是噪声数据在相似图像块组数据中更加稀疏,更有利于从稀疏噪声中恢复潜在的图像数据,因此,本文的算法能够解决大尺寸模糊核的盲解卷积问题,并且避免盲解卷积过程受噪声的干扰.
本文后续结构组织如下: 第1 节描述本文提出的图像跨尺度低秩先验模型;第2 节阐述本文提出的基于跨尺度低秩先验的图像盲解卷积模型以及求解过程;第3 节通过定量和定性实验验证本文算法的有效性;第4 节分析跨尺度低秩先验的有效性与局限性;第5 节为全文的总结.
1 图像跨尺度低秩先验
跨尺度自相似性普遍存在于自然图像中,本文从模糊图像的降采样图像中搜索相似图像块组成相似块组矩阵,对跨尺度相似图像块组矩阵进行低秩约束.
1.1 图像跨尺度自相似性
多尺度自相似性是指在同一场景中存在着相同尺度以及不同尺度的相似结构.这种多尺度自相似性具体表现为图像中所具有的相同尺度以及不同尺度的相似图像块[25],即从图像中提取一个图像块,可在原尺度图像及其他尺度的图像中找到相似的图像块.相机的透视投影是图像的多尺度自相似性普遍存在的主要原因.Glasner等[26]通过大量图像的实验证明了相似图像块普遍存在于同一场景的相同尺度以及不同尺度图像中,由于小尺寸的图像块只含有少量信息,通常只包含一个边缘、角点等,因此,即使人类视觉不易察觉小尺寸的相似图像块,但这些图像块普遍存在于自然图像的多尺度图像中.不同尺度的图像自相似性简称为跨尺度自相似性.
图1 展示了自然图像的多尺度自相似性.图1(a)为一幅清晰的自然图像,对于红色方框标记的一个7×7 的图像块,在该图像中搜索同尺度相似图像块,用蓝色方框标记,图1(b)为清晰图像中给定图像块及其同尺度相似图像块的细节放大图.对图1(a)进行2 倍降采样,如图1(c)所示,图中蓝色方框标记的图像块为在该图像中搜索的跨尺度相似图像块,图1(d)为清晰图像中给定图像块及其跨尺度相似图像块的细节放大图,其中,红色方框为原尺度图像中给定的图像块.跨尺度自相似性存在于不同尺度的图像中,而模糊图像的模糊核会随着图像尺度的变化而发生尺度变换,即同一幅模糊图像的不同尺度图像的模糊程度不同,从而导致模糊图像的跨尺度自相似性减弱,如图2 所示.图2(a)为图1(a)对应的模糊图像,红色方框标记了模糊图像中对应的7×7 图像块,蓝色方框标记了该图像中的同尺度相似图像块,图2(b)为模糊图像中给定图像块及其同尺度相似图像块的细节放大图.同样地,对图2(a)进行2 倍降采样,如图2(c)所示,图中蓝色方框标记了在降采样模糊图像中搜索的跨尺度相似图像块,图2(d)为模糊图像中给定图像块及其跨尺度相似图像块的细节放大图.通过观察图2(b)和图2(d)可以发现,对于模糊图像,同尺度相似图像块有着较强的相似性,而跨尺度相似图像块的相似性明显减弱.通过观察图1和图2 说明了清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性.

图1 清晰图像的多尺度自相似性Fig.1 Multi-scale self-similarity of the sharp image

图2 模糊图像的多尺度自相似性Fig.2 Multi-scale self-similarity of the blurry image
图3 说明了降采样模糊图像比模糊图像本身与清晰图像的相似性更强.对于图1(b)中红色方框标记的清晰图像块,在图3(a)所示的模糊图像和图3(c)所示降采样模糊图像中搜索其相似图像块并用蓝色方框标记,图3(b)和图3(d)分别为搜索的相似图像块的细节放大图.通过比较图3(b)和图3(d)可以看出,由于降采样模糊图像的模糊程度减弱,从降采样模糊图像中搜索的相似块相比从模糊图像本身搜索的相似块,与清晰图像块具有更强的相似性.

图3 模糊图像和降采样模糊图像分别与清晰图像的相似性比较Fig.3 Comparison of similarities between the blurry image and the down-sampled blurry image related the sharp image
跨尺度自相似性可以为图像盲复原提供必要的附加信息.图4 给出了跨尺度自相似性在图像复原应用中的解释,图中左边为清晰图像及其降采样图像,右边为模糊图像及其降采样图像.参照Michaeli等[10]通过一维信号对模糊信号的降采样信号与清晰信号相似性的证明,本文利用二维信号进行简要证明,记二维坐标为ξ和η.由于跨尺度自相似性普遍存在于自然场景中,在图中左边,假设p1(ξ,η)、p2(ξ,η)为同一场景中不同尺寸的相似结构,忽略采样问题的影响,p2(ξ,η) 的尺寸为p1(ξ,η)的a倍,可表示为的降采样版本,即

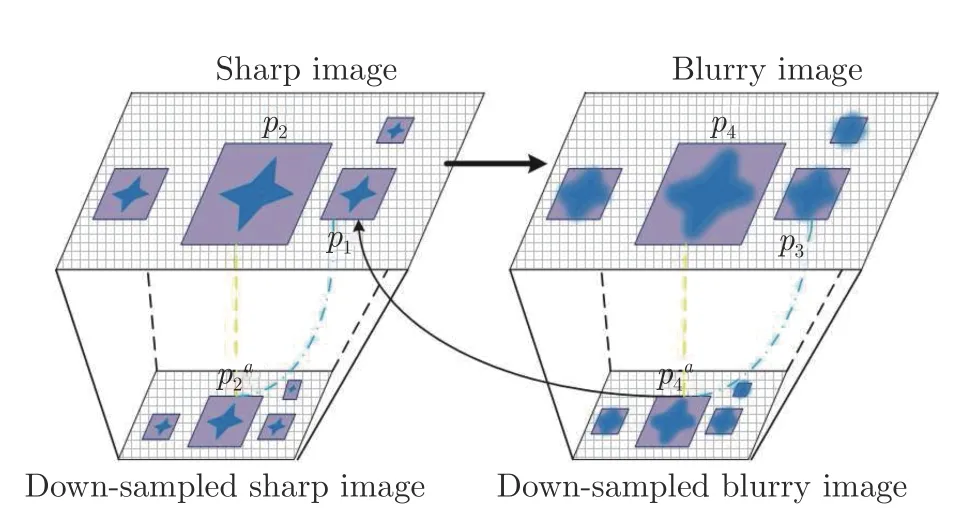
图4 跨尺度自相似性用于图像盲复原的解释Fig.4 Interpretation of cross-scale self-similarity for blind image restoration
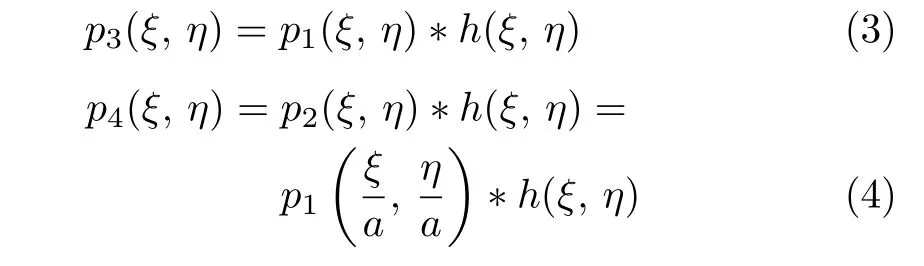
其中,h(ξ,η) 为模糊核.(ξ,η)为p4(ξ,η) 的降采样版本,由式(4)可得
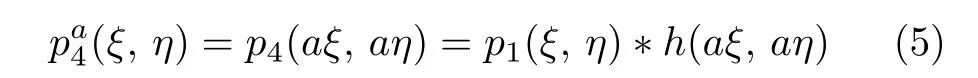
(ξ,η)与p3(ξ,η) 具有相同的尺寸.根据式(5),(ξ,η)可认为是由清晰结构p1(ξ,η)与模糊核h(aξ,aη) 卷积的结果,由于h(aξ,aη) 的尺寸是h(ξ,η)的 1 /a倍,因此,相比于h(ξ,η),h(aξ,aη) 对图像造成的模糊程度更小.

1.2 跨尺度低秩先验模型
设清晰图像x∈RN的降采样图像表示为xa∈1后面的内容涉及到范数的表示和导数计算,为了方便表达,需要将公式写为矩阵向量的形式,因此,对于空域卷积,本文近似使用列向量的形式表示.,其中 N 为清晰图像的像素数,a 为降采样因子.从清晰图像x及其降采样图像xa中抽取的图像块分别表示为Qjx和Rixa,其中Qj∈Rn×N和为抽取矩阵,分别用于从清晰图像及其降采样图像中抽取第j个和第i个图像块,抽取的图像块尺寸为n.对于图像中的任意图像块Qjx,在降采样图像xa中搜索其相似图像块Rixa.由于图像的不同尺度间广泛存在着跨尺度相似图像块,即对于Qjx,可以在降采样图像xa中寻找多个与其相似的图像块.设在xa中搜索m −1 个与Qjx最相似的图像块,并按列表示为,i=1,···,m −1,Qjx与这些在降采样图像中的相似图像块聚合构成一个跨尺度相似图像块组Pj,可表示为
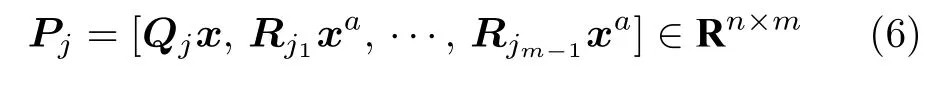
其中,n为图像块的尺寸,m为图像块的个数.
本文提出了一种基于跨尺度自相似性的低秩先验模型,利用低秩矩阵估计(Low rank matrix approximation,LRMA)对跨尺度相似图像块组矩阵进行低秩约束,该先验模型如下所示
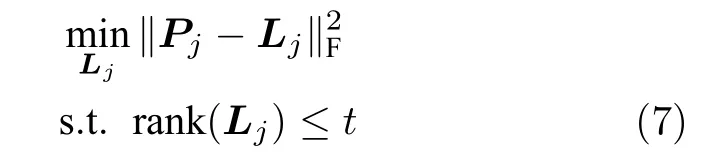
式中,Pj表示图像块Qjx与其在降采样图像中搜索的相似图像块构成的组矩阵,Lj表示观测矩阵Pj中潜在的低秩结构,∥·∥F表示矩阵Frobenius范数,r ank(·)为秩函数,t为限制矩阵秩的常数.跨尺度低秩先验模型的有效性体现在如下两点: 1)由于模糊的作用,清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性,此先验使目标函数的解偏向于清晰图像而不是模糊图像;2)由于降采样降低了图像的模糊程度,从降采样模糊图像中找到的相似块比模糊图像中找到的相似块,与清晰图像具有更强的相似性,所以利用从降采样模糊图像中搜索的相似块构成相似图像块组,通过对相似图像块组的低秩约束迫使重建图像更加接近清晰图像.此外,低秩结构更好地表示了数据的全局结构,提高了对噪声的鲁棒性.
尽管图像跨尺度自相似性广泛存在,然而,并不是所有的图像块都能为图像复原提供有效的附加信息.显著边缘的图像块对模糊核的估计起着关键的作用,而灰度平坦的图像块对模糊核估计几乎不起作用,例如若某一图像区域的像素值为常数,则该区域经过模糊后的像素值仍为同一常数,在该区域清晰图像与模糊图像完全相同,因此这一区域并不能为模糊核的估计提供有效的信息.本文将灰度值变化较小的图像块称为平坦块,灰度值变化较大的图像块称为细节块,在跨尺度低秩先验模型中,仅将细节块用于模糊核的估计.本文考虑了两种筛选图像中细节块的方案: 1)计算图像块的方差,方差较大的图像块说明图像块中灰度变化较为剧烈;2)计算像素的梯度,较大的梯度表明邻域内像素灰度变化明显,即对应显著边缘的区域.前者需要对图像中的每一个图像块计算方差,计算量大;后者可以利用模板卷积的边缘检测实现,速度快,且通常图像块的尺寸很小,图像块的灰度变化基本上等效于邻域内的灰度变化.因此,本文利用图像边缘检测确定细节块.
由于相似图像块经常出现在邻近区域,因而在降采样图像中一定尺寸的搜索窗口内通过图像块匹配搜索相似图像块.图像块相似性的判据有多种度量准则,如欧氏距离、相关系数等,本文采用欧氏距离作为图像块相似性的度量依据.对于不同程度的细节块,所搜索相似图像块的个数不同,即对于不同细节块,其相似图像块组矩阵的列数不同.本文采用一种自适应方法[26]确定图像块相似性判断的阈值,对原始图像x进行插值移位,生成具有 1 /2 亚像素位移的图像,对于每一个输入图像块Qjx,在x˜中找到对应位置的图像块Qj,阈值δd的计算式为
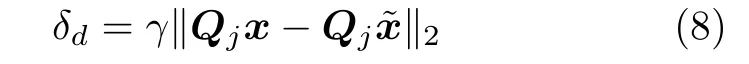
其中,γ为控制系数.选取欧氏距离小于δd的图像块作为原图像块的相似块.由式(8)可知,图像块灰度变化越剧烈,阈值δd越大;反之,图像块灰度变化越平缓,阈值δd则越小.与此同时,设置相似块搜索个数的下限 ∆l和上限 ∆h,即相似块个数满足∆l ≤m ≤∆h.如果搜索到的相似块个数小于 ∆l,则不采用此图像块;如果搜索到的相似块个数大于∆h,那么仅选取前 ∆h个相似图像块.
2 基于跨尺度低秩约束的盲解卷积算法
在上一节提出的跨尺度低秩先验模型的基础上,本节给出了本文图像盲解卷积算法的数学模型及求解过程.
2.1 图像盲解卷积算法数学模型
本文结合跨尺度自相似性与低秩矩阵估计,将式(7)中的图像跨尺度低秩先验作为正则化约束,提出的单幅图像盲解卷积算法可表示为如下约束最优化问题:
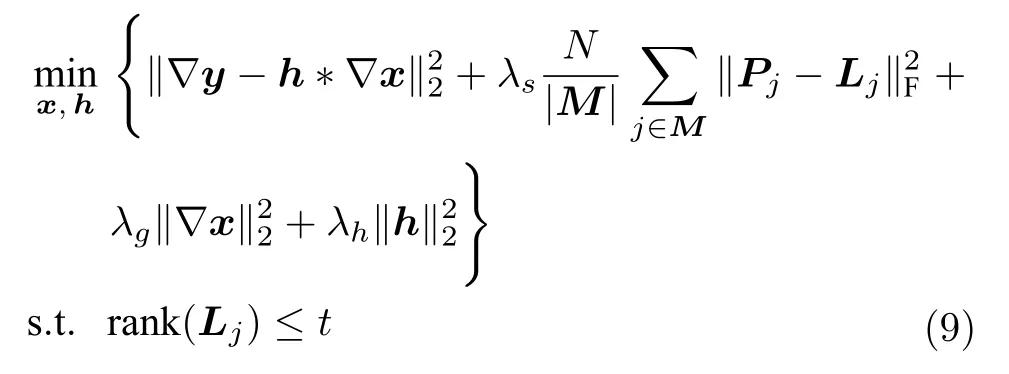
其中,y为模糊图像,x为清晰图像,h为模糊核,∇={∂x,∂y}为图像的梯度算子,∂x和∂y分别表示x方向和y方向的一阶差分算子,∗表示卷积操作,∥·∥2表示ℓ2范数,M为二值标记矩阵,用于标记细节块的位置,|M|为M中非零元素的个数,λg,λs,λh为正则化参数.式(9)中第1 项为数据保真项,保证复原结果符合图像的降质模型;第2项为跨尺度低秩约束正则项,迫使重建图像的边缘接近清晰图像的边缘,j∈M表示将跨尺度低秩先验仅限制在标记矩阵M中值为1 的细节块;第3项为梯度约束项,采用ℓ2范数对图像梯度进行约束,能够减小基于图像块先验引入的边缘 “棱角”效应,保持图像边缘的平滑性;第4 项为模糊核的正则化约束项,保证了模糊核的稀疏性.
2.2 数学模型求解
由于式(9)是非凸的,没有闭合解,本文采取交替迭代求解的方法对式(9)所示的最优化问题进行求解,即先固定对清晰图像的估计求解模糊核,再固定模糊核更新对清晰图像的估计每一次迭代,更新标记矩阵M,通过对图像块进行筛选,从而排除平坦块对模糊核估计的干扰.
1)筛选图像块
对清晰图像的当前估计结果进行边缘估计,边缘像素对应的图像块即为细节块,参与模糊核的估计.引入二值标记矩阵M,若M中对应的图像块为细节块,则该位置的元素值为1,否则该位置的元素值为0.本文利用Sun等[27]的边缘检测算法确定当前图像估计中的边缘像素,该算法对于每一个像素,利用方向算子选取8 个方向模板中的最大响应幅度作为该像素的边缘强度.
由于本文仅将跨尺度低秩正则化约束限制在图像的细节块,导致当前估计的图像中平坦块受到的约束较少,从而可能导致复原图像的平滑区域含有较多的噪声,为了减小噪声对边缘估计造成的干扰,本文首先对当前估计的图像进行高斯滤波,然后对滤波后的图像进行边缘估计.
2)估计模糊核
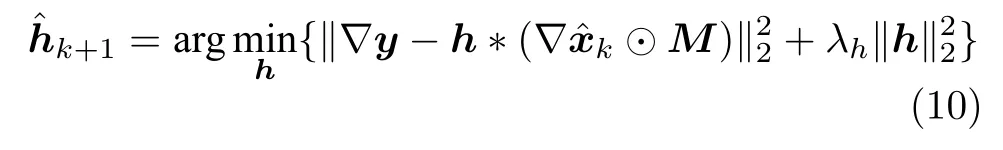
式中,⊙为哈达玛积 (Hadamard product).在估计模糊核时,仅利用图像中的细节块,避免了平坦块对模糊核估计的影响,有利于准确地估计模糊核.式(10) 为关于h的二次函数,因此存在闭合解,令式(10)对h的导数为零,可得
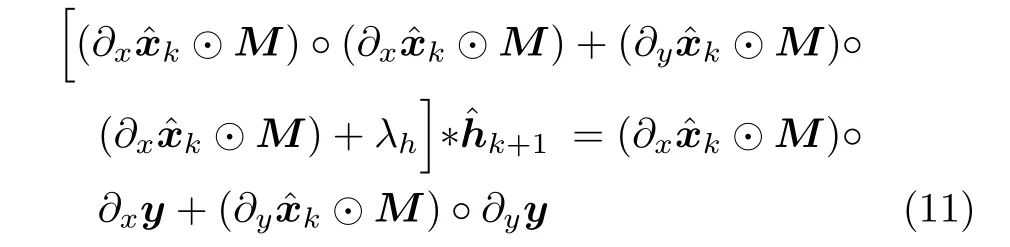
其中,◦表示相关运算.根据卷积定理可知,空域中图像的卷积等效于频域中傅里叶变换的乘积,本文将式(11)转换到频域求解:
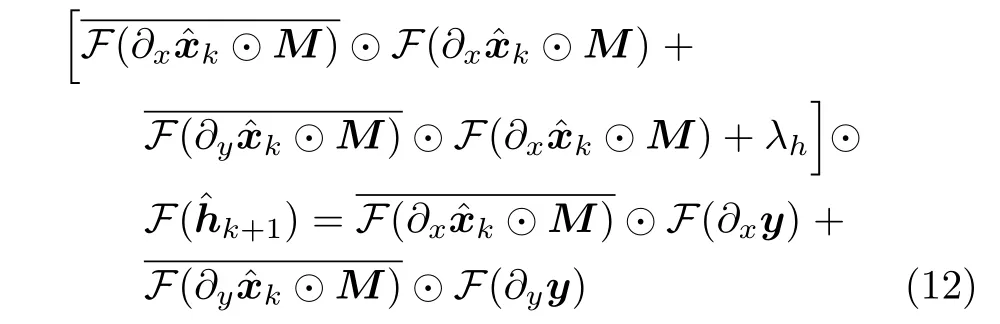
由式(12)可得h的闭合解如式(13)所示
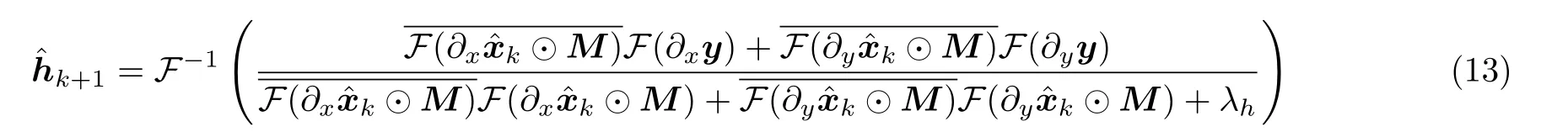

式中,表示将重建图像块Qj根据抽取的位置放回图像中对应位置,从而获得重建图像zk.一方面,清晰图像的跨尺度自相似性强于模糊图像的跨尺度自相似性,通过跨尺度自相似性组成相似图像块组,使得目标函数的解偏向清晰图像;另一方面,由于降采样模糊图像中图像块的边缘更加清晰,与清晰图像具有更强的相似性,通过约束相似图像块组的矩阵秩,迫使当前图像估计的边缘更接近清晰图像的边缘.

2.3 本文算法整体流程
本文算法的整体流程包括模糊核估计和清晰图像估计两个阶段,如图5 所示.第1 阶段中通过对式(9)的交替求解来对模糊核进行估计.首先初始化清晰图像,对当前估计的清晰图像进行细节块筛选构造标记矩阵,在标记矩阵的指导下更新模糊核,然后通过跨尺度低秩约束正则项重建图像,重建图像可视为下一次迭代更新估计清晰图像的参考图像.通过对相似图像块组进行整体的低秩约束,迫使重建图像的边缘更加清晰,用模糊程度更小的重建图像作为参考图像,可使下一次迭代得到更清晰的图像.通过式(9)交替求解出的清晰图像仅是清晰图像的中间结果,进一步利用非盲解卷积方法最终可得对清晰图像的估计.第2 阶段在第1 阶段估计的模糊核的基础上,选择合适的非盲卷积方法从模糊图像中恢复出清晰图像,例如Richardson-Lucy 算法及其变形[29−32]、EPLL (Expected patch log likelihood)算法[33]、全变分正则化方法[4,34]、稀疏非盲解卷积方法[8]和双边滤波残差消除法[13]等.
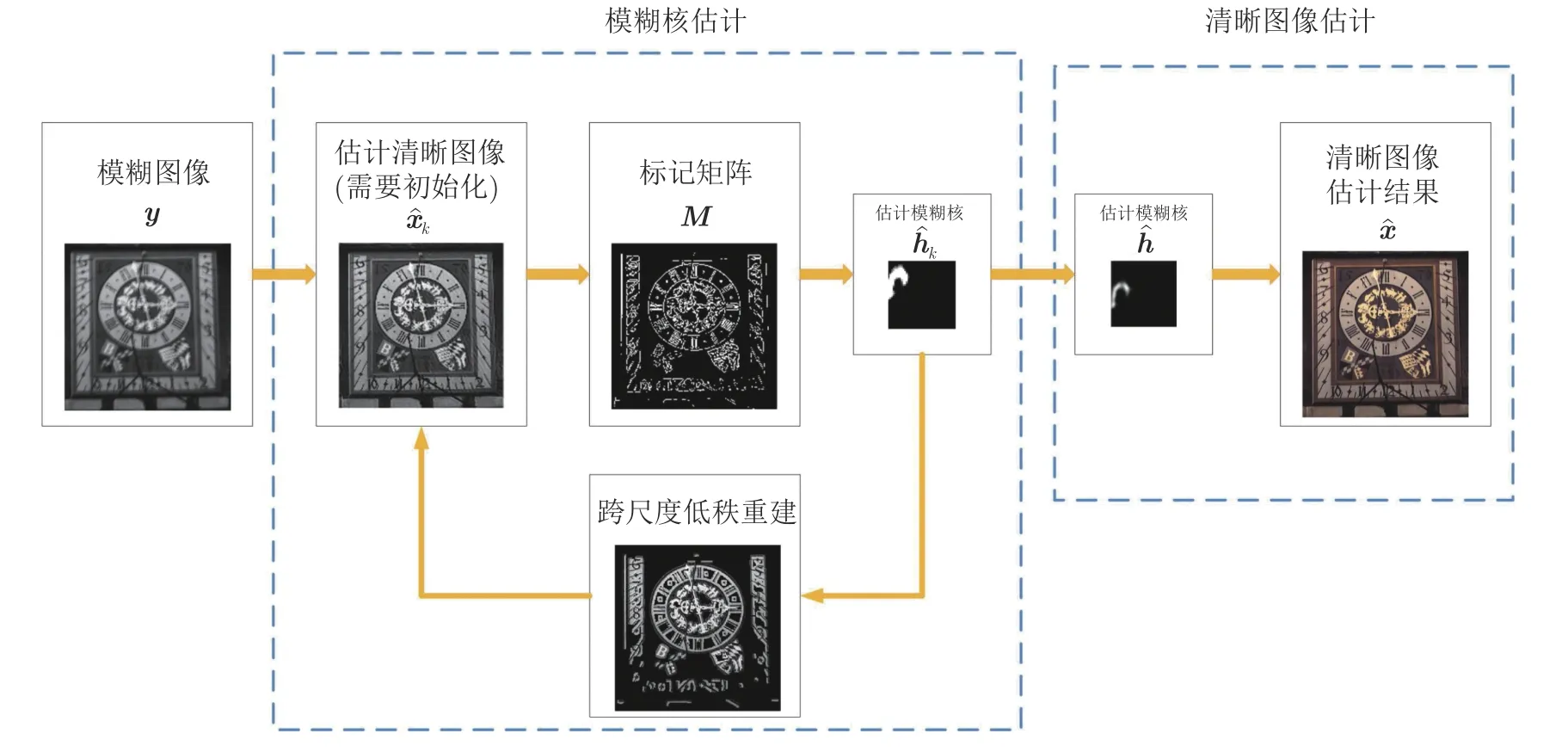
图5 本文算法流程Fig.5 The pipeline of our method
为了加速算法的收敛和处理大尺寸模糊,与目前大部分算法相同,本文通过构建图像金字塔模型由粗到细地估计模糊核.在金字塔的每一层求解式(9)所示的目标函数,在跨尺度相似图像块搜索的实际实现时,直接在上一层估计的清晰图像中搜索相似图像块构造相似图像块组.本文将当前层对清晰图像估计的插值图像作为下一层金字塔估计的初始清晰图像,则下一层金字塔中对清晰图像的初始估计更接近真实的清晰图像,从而加快了模糊核的估计过程并且提高了估计结果的准确性.
算法1 总结了基于跨尺度低秩约束的图像盲解卷积算法的伪代码,根据输入的模糊图像y,构建K层的图像金字塔,若当前层为金字塔的第1 层(l=1),则将模糊图像y作为清晰图像初始估计设置=y,否则将上一层 (l −1) 金字塔估计的清晰图像的插值结果作为当前层 (l) 清晰图像的初始估计在每一层 (l) 中,利用交替迭代求解式(9)估计出模糊核和清晰图像,这里上标表示图像金字塔的层数,下标表示在每一层金字塔上迭代的次数,直到迭代收敛或者达到预设的最大迭代次数.
算法1 的时间复杂度主要由内循环的4 个步骤决定.步骤1 中采用边缘检测筛选细节块,这种方法通过空域卷积实现,空域卷积的时间复杂度为O(Ns),其中,N为图像的尺寸,s为卷积核的尺寸.空域滤波的卷积核通常很小,因此,卷积操作的时间复杂度可近似记为 O (N).步骤2 直接在频域中计算模糊核的闭合解,其中,傅里叶变换的时间复杂度为 O (NlogN),逐元素操作的时间复杂度为O(N),因此,步骤2 的时间复杂度可以记为 O (NlogN).步骤3 中,对于所有细节块在搜索窗口内计算图像中块匹配误差的时间复杂度为 O (Ntwn);查找搜索窗口内m个最相似图像块的时间复杂度为O(Ntwlogw);完全奇异值分解的时间复杂度为O(Nt×min(mn2,m2n)),其中,Nt为标记矩阵M中对应的细节块数目1根据统计,细节块约占图像块总数的10%.,w为搜索窗口的尺寸,n为图像块的尺寸,m为选取的相似图像块数目.由于奇异值分解的运行时间远小于块匹配误差计算和排序两部分的运行时间之和,因此,步骤3 的时间复杂度可以记为O(Ntw(n+logw)).步骤4 中BICG 算法的时间复杂度为 O (ζ+N)[35],加上傅里叶变换的运行时间,总的时间复杂度可记为 O (ζ+NlogN),其中,ζ为系数矩阵的非零项个数.
算法1.基于跨尺度低秩约束的图像盲解卷积算法


从上述时间复杂度的分析可以看出,步骤1和2 的时间复杂度均不超过 O (NlogN),步骤4 中系数矩阵是稀疏的,时间复杂度可近似为线性对数阶,而步骤3 为立方阶时间复杂度.于是,本文的算法如同一般使用相似图像块搜索的算法,例如经典的BM3D 算法[36],主要耗时在相似图像块的遍历搜索上.目前快速相似图像块搜索算法的研究不多,未来快速算法的普遍研究将会为以相似图像块搜索为基础的算法提供速度上升的空间.
3 实验结果与分析
本文设置图像块尺寸为n=5×5,奇异值阈值β为0.2,相似图像块个数的上限 ∆h为19,下限∆l为5,搜索窗口的尺寸为w=25×25.由于大多数真实图像的模糊核尺寸小于 5 1×51,参照Sun等[27]和Michaeli等[10]的方式,若无特殊说明,本文设置模糊核的尺寸为s=51×51.降采样因子a越大,降采样模糊图像中的图像块越清晰,但同时不同尺度图像之间的相似图像块的个数越少[26],因此需要综合考虑设置降采样因子的取值,本文参照Michaeli等[10]将金字塔之间的缩放因子设置为 4 /3,图像金字塔不同层对应的模糊核尺寸不同,在构建金字塔模型时,若当前层对应的模糊核尺寸小于 3×3,则停止降采样的过程.
3.1 Kohler 数据集上的实验
本文在Kohler等[37]公开的数据集上验证算法的有效性,此数据集包括4 幅图像,有12种模糊核(后5 个为大尺寸模糊核),共产生48 幅模糊图像.该数据集是由相机记录的六维自由度运动轨迹合成的非均匀模糊数据集.在Kohler 数据集实验中,将本文的算法与Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]提出的算法进行比较,本文算法的正则化参数设置为λs=0.0008,λg=0.002,λh=0.0003N.该数据集中的模糊图像是由真实记录的三维空间运动轨迹而合成的,属于非均匀模糊,上述算法均利用线性卷积模型对非均匀模糊进行近似建模.为了公平比较,本文的算法也根据模糊程度的不同,将初始模糊核尺寸设置为 2 1×21 到 1 51×151 不等.Pan等[13]、Yan等[14]、常振春等[15]和Chen等[16]的结果均是由作者本人提供.通过比较每一幅图像的去模糊结果与沿着相机运动轨迹捕获的199 个未模糊图像的峰值信噪比(Peak signal-to-noise ratio,PSNR),将最大的PSNR 作为定量评估的指标.复原图像与真值图像之间的PSNR 越大,表明复原图像与真值图像越接近.
图6 比较了各个算法在Kohler 数据集上PSNR的均值及标准差.从图中可以看出,本文的算法在四幅图像上的平均PSNR 均高于常振春等[15]的去模糊结果;在后两幅图像上的平均PSNR 高于Pan等[13]的结果,在第四幅图像上的平均PSNR 高于Yan等[14]和Chen等[16]的结果.该数据集中的前3 幅图像含有足够多的暗像素,符合Pan等[13]所提出的暗通道先验,本文的算法在Kohler 数据集上达到了与Pan等[13]方法相当的结果.该方法对于缺乏暗像素的情况会失效,Yan等[14]提出了亮通道先验,并结合暗通道先验共同建模图像先验,提高了PSNR.尽管Yan等[14]和Chen等[16]方法在Kohler数据集上获得了更高的PSNR,然而他们的方法恢复细节的能力仍有限.由于该数据集是对印刷照片进行成像,图像较为平滑,并不能很好地用于评价算法对细节的恢复能力.此外,从图中的垂直误差条可见,本文算法在各幅图像上均取得最小的标准差,说明本文算法具有更好的鲁棒性.
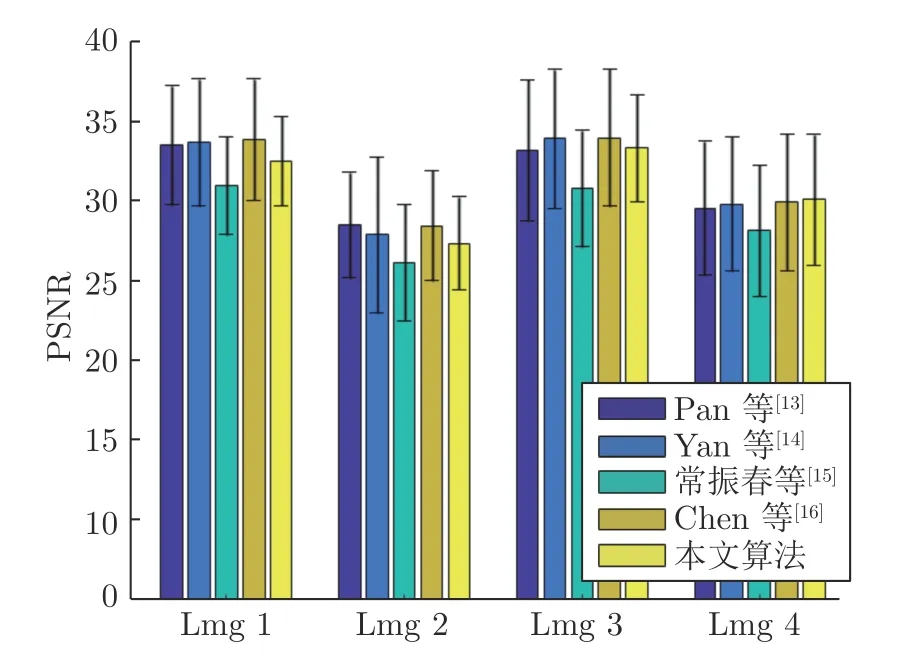
图6 Kohler 数据集PSNR 的平均值与标准差Fig.6 Mean and standard deviation of PSNR on Kohler dataset
图7和图8 给出各个算法在Kohler 数据集中两幅图像上的复原结果,图像中左上角为各算法估计出的模糊核.对于图7(a) 所示的小模糊图像,图7(b)~7(f)分别为Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]以及本文算法的去模糊结果,图像的下方为局部区域的细节放大图.图7(b)~7(f)与真值图像之间的PSNR 依次为 2 9.31 ,2 9.74 ,2 8.95,29.54和31.53.从细节放大图中可以看出,常振春等[15]的复原结果中产生了一定程度的噪声,Pan等[13]、Yan等[14]和Chen等[16]的方法在某些区域缺乏对细节的恢复,本文的算法能够更好地恢复图像的细节.大尺寸模糊核更难估计,对于图8(a)所示的大模糊图像,图8(b)~8(f)分别为Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]以及本文算法的去模糊结果,它们与真值图像的PSNR 依次为22.30,22.32,22.94,22.37和27.51.根据去模糊图像和真值图像之间的PSNR,本文算法在这两幅图像上估计出更准确的模糊核,复原图像更接近真值图像;根据视觉效果,本文算法能够恢复出更多的细节且失真更小.

图7 各个算法对Kohler 数据集中一幅小模糊图像复原结果的比较Fig.7 Comparison of the results deblurred by some state-of-the-art methods on a weakly blurred image from Kohler dataset

图8 各个算法对Kohler 数据集中一幅大模糊图像复原结果的比较Fig.8 Comparison of the results deblurred by some state-of-the-art methods on a severely blurred image from Kohler dataset
3.2 加噪Kohler 数据集上的实验
本文的算法没有对噪声进行特殊处理,利用低秩模型对跨尺度相似图像块组进行整体约束,使得算法具有一定的抗噪能力.本文在Kohler 数据集中加入了标准差为0.01 的高斯噪声模拟模糊有噪图像.在加噪Kohler 数据集实验中,将本文的算法与Pan等[13]、Yan等[14]、常振春等[15]和Chen等[16]的算法进行比较,本文的算法将正则化参数设置为λs=0.0008 ,λg=0.002,λh=0.0003N.Pan等[13]、Yan等[14]、常振春等[15]和Chen等[16]的结果均由作者提供的程序运行得到.图9 给出了各算法在加噪Kohler 数据集上PSNR 的均值及标准差,由图中可见,与Pan等[13]、Yan等[14]、常振春等[15]和Chen等[16]算法相比,本文算法在各幅图像中均取得了最高的平均PSNR 及最小的标准差,充分说明本文算法对噪声具有很好的鲁棒性.
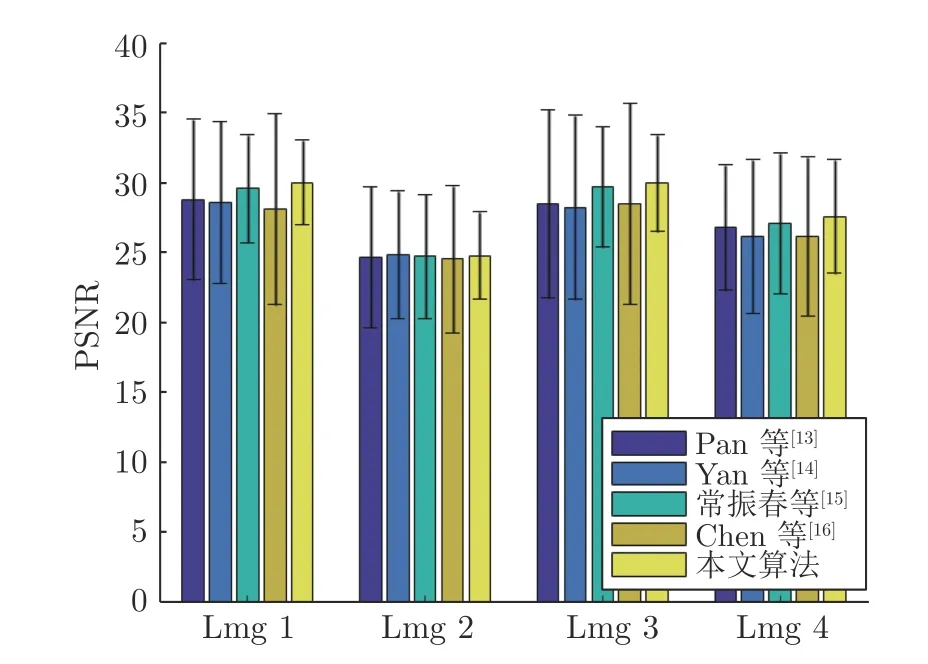
图9 加噪Kohler 数据集PSNR 的平均值与标准差Fig.9 Mean and standard deviation of PSNR on noisy Kohler dataset
图10和图11 比较了各个算法在加噪Kohler数据集中两幅图像上的复原结果.对于图(a)所示的模糊有噪图像,图(b)~(f)分别为各个算法的去模糊结果.计算去模糊图像与真值图像之间的PSNR,在图10 中Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]以及本文算法PSNR 依次为 1 9.95,17.11,2 1.60,16.38和2 6.85,在图11 中PSNR 依次为 2 4.72 ,24.80,27.51,2 4.79和2 8.23.由图10 可见,由于噪声的干扰,Pan等[13]、Yan等[14]、常振春等[15]和Chen等[16]算法都无法准确地估计出模糊核,进而无法复原出清晰的结果,本文算法能够准确地复原出图像的边缘和细节,获得清晰的复原图像.本文算法在这两幅图像上均取得了最高的PSNR 均值,表明更接近真值图像,并且展现了更好的视觉效果.

图10 各个算法对加噪Kohler 数据集中一幅图像复原结果的比较Fig.10 Comparison of the results deblurred by some state-of-the-art methods on a blurred-noisy image from noisy Kohler dataset

图11 各个算法对加噪Kohler 数据集中另一幅图像复原结果的比较Fig.11 Comparison of the results deblurred by some state-of-the-art methods on another blurred-noisy image from noisy Kohler dataset
3.3 真实模糊图像实验
在真实模糊图像实验中,将本文的算法与Michaeli等[10]、Perrone等[9]、常振春等[15]、Pan等[13]、Yan等[14]和Chen等[16]的算法进行比较,本文算法的正则化参数设置为λs=0.004,λg=0.006,λh=0.003N.Michaeli等[10]、Pan等[13]、Yan等[14]、Chen等[16]的结果均是由作者提供的程序运行得到,Perrone等[9]、常振春等[15]的复原结果由作者直接提供.真实模糊图像一般为非均匀模糊,上述算法均利用线性卷积模型对非均匀模糊进行近似建模.
图12和图13 比较了各个算法在两幅真实模糊图像上的复原结果,对于图(a)所示真实模糊图像,图(b)~(h)为各个算法的复原结果,图像左上角为估计的模糊核,图像下方为图像中局部区域的细节图.从这些细节区域以及整体复原结果可以看出本文的算法在有效减少振铃效应的同时,能够很好地恢复出图像的细节,使边缘更加清晰.

图12 各个算法对一幅真实模糊图像复原结果的比较Fig.12 Visual comparisons with some state-of-the-art methods on one real-world photo

图13 各个算法对另一幅真实模糊图像复原结果的比较Fig.13 Visual comparisons with some state-of-the-art methods on another real-world photo
3.4 真实模糊有噪图像实验
在真实模糊有噪图像实验中,将本文的算法与Michaeli等[10]、Perrone等[9]、Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]的算法进行比较,本文算法的正则化参数设置为λs=0.004,λg=0.006,λh=0.003N.Michaeli等[10]、Perrone等[9]、Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]的结果均是由作者提供的程序运行得到.
图14和图15 比较了各个算法在两幅真实模糊有噪图像上的复原结果.图(a)为在低光照环境中获取的真实图像,当光线不充足时图像容易产生噪声,图14(b)~14(h)分别为Michaeli等[10]、Perrone等[9]、Pan等[13]、Yan等[14]、常振春等[15]、Chen等[16]以及本文算法的去模糊结果,图15(b)~15(f)分别为Perrone等[9]、Pan等[13]、Yan等[14]、Chen等[16]以及本文算法的去模糊结果,在图像的左上角为各个算法估计的模糊核,在每幅图像的下方是局部区域的细节图.由图中可见,本文算法很大程度上减小了振铃效应和噪声的影响,恢复出更加清晰的结果.特别地,从图14 的细节放大图可以看出,Perrone等[9]、Pan等[13]、Yan等[14]、常振春等[15]的复原结果均放大了噪声并且存在明显的振铃效应,Michaeli等[10]、Chen等[16]减小了振铃效应,但复原结果仍存在噪声放大的情况.可见,本文算法对于噪声具有良好的鲁棒性.

图14 各个算法在一幅真实模糊有噪图像上的实验结果Fig.14 Visual comparisons with state-of-the-art some methods on a real blurred-noisy image

图15 各个算法在另一幅真实模糊有噪图像上的实验结果Fig.15 Visual comparisons with some state-of-the-art methods on another real blurred-noisy image
4 分析与讨论
本节对跨尺度低秩先验的有效性和局限性进行分析和讨论.
4.1 图像跨尺度自相似性的分析
本文通过在大量图像上对图像跨尺度自相似性的统计分析来验证跨尺度低秩先验的有效性.在本实验中,从Sun等[27]数据集提供的80 幅清晰图像中抽取尺寸为 5×5 的细节块,对于每一个细节块,在降采样图像中搜索m个相似图像块,降采样因子a分别设置为 4 /3、5 /3和2,降采样图像的尺度分别为原来的0.75、0.6和0.5 倍.采用均方误差(Mean squared difference,MSD)度量图像块之间的相似性,M SD 的数值越小,表明图像块之间的相似性越强.设清晰图像x中抽取的图像块为Qjx,在其降采样图像xa中搜索相似图像块Rixa,i= 1,···,m,则清晰图像的跨尺度自相似性用均方误差度量可表示为
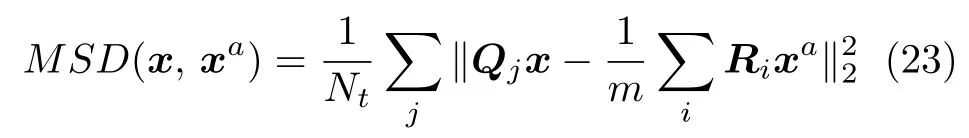
其中,Nt为图像中细节块的个数,m为相似图像块的个数.对于每一个细节块自适应地搜索m个相似图像块,然后计算m个相似图像块的均值.根据式(8)计算自适应阈值,其中,控制系数γ值越大,阈值δd越大,选取该细节块的相似图像块个数越多,这里设置相似块搜索个数的下限 ∆l=1,上限∆h=5,则m满足 1≤m ≤5.由于各幅图像中通过边缘检测确定的细节块个数不同,因此,对于每幅图像利用均方误差来度量相似性.同理,MSD(x,y)度量清晰图像与模糊图像的相似性,MSD(x,ya)度量清晰图像与降采样模糊图像的相似性,MSD(y,ya)度量模糊图像的跨尺度自相似性.对于Sun 数据集中的每幅图像各自计算均方误差,然后统计所有图像(80 幅图像)的均方误差之和.
图16 展示了降采样因子a为 4 /3、5 /3和2,控制系数γ为1、1.5、2和2.5 时80 幅图像的均方误差之和,图中,横坐标为控制系数γ,纵坐标为均方误差之和.图16(a)比较了模糊图像y及其降采样图像ya与清晰图像x的相似性,图中实线表示清晰图像与降采样模糊图像之间的相似性,虚线表示清晰图像与模糊图像之间的相似性,由图中可见,选取适合的参数可以保证MSD(x,ya) 图16 图像跨尺度自相似性的分析Fig.16 Analysis of cross-scale self-similarity of images 本文提出的跨尺度低秩先验依赖于跨尺度相似图像块的冗余性.自然图像中跨尺度相似图像块越多,它们之间的相关性能够提供更充分的附加信息,则该先验的鲁棒性越强.对于自相似性较弱的图像,由于仅能搜索少量的相似图像块,其复原能力受到了一定的限制. 图17 展示了本文的算法在Sun等[27]数据集中三幅自相似性较弱图像上的复原结果,图17(a)为模糊图像,图17(b)为真值图像,图17(c)为Cho等[3]、Xu等[4]和Levin等[6]算法的复原结果,图17(d)为本文算法的复原结果,图像左上角为估计的模糊核.通过观察模糊核以及复原结果可以看出,本文的算法并没有准确地估计出模糊核,导致无法完全去除图像中的模糊或产生halo 效应.但是,跨尺度低秩先验是一种鲁棒的先验模型,对于不同的模糊核或图像内容,本文的算法能够获得较为稳定的复原结果.当模糊核或图像内容不符合先验假设时,部分算法的复原结果会产生较大的波动,如图17(c)所示的失效图例产生明显的振铃效应,而本文的算法即使对于自相似性较弱的图像,依然能够达到一定的去模糊效果,不会产生明显的振铃效应. 图17 本文算法对Sun 数据集中三幅自相似性较弱图像的复原结果Fig.17 Visual display of proposed method on three weak self-similarity blurred images from Sun dataset 由于跨尺度自相似性普遍存在于自然图像中,本文提出了一种跨尺度低秩先验模型,在当前估计的降采样图像中搜索相似图像块构成相似图像块组,对相似图像块组构造低秩约束正则项,加入到目标函数中,使目标函数的解偏向于清晰图像.在金字塔的逐层迭代中,通过对跨尺度相似图像块组进行低秩约束,迫使当前估计的清晰图像边缘越来越清晰,细节越来越丰富.在大量模糊图像以及模糊有噪图像上的实验验证了本文算法的有效性.本文的算法没有对噪声进行特殊处理,由于低秩约束很好地表示了数据的全局结构特性,因此对噪声具有良好的鲁棒性,能够从大模糊有噪图像中有效地估计出模糊核.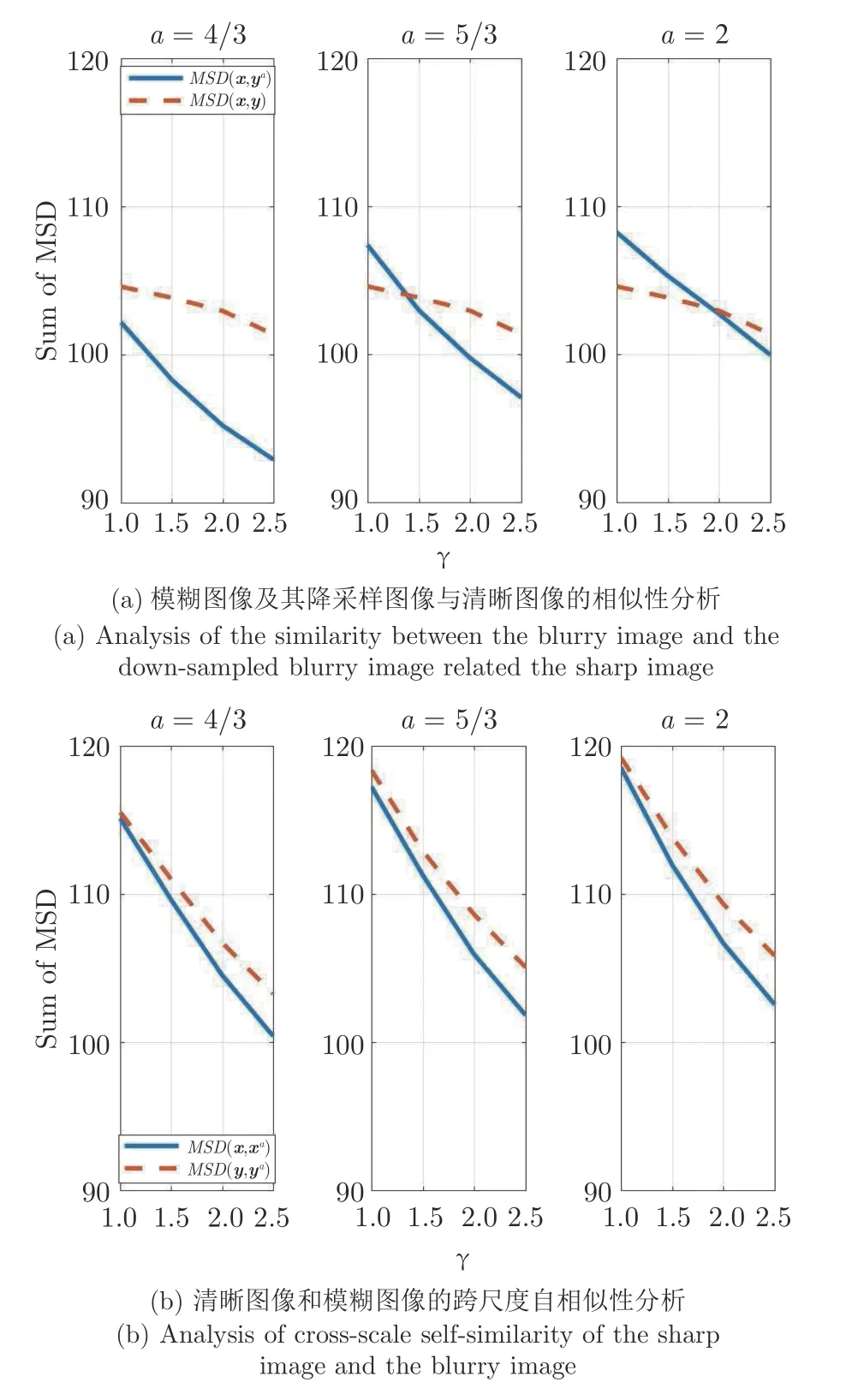
4.2 跨尺度低秩先验的局限性分析

5 结束语
猜你喜欢
疯狂英语·新悦读(2022年8期)2022-09-20
客联(2021年9期)2021-11-07
小天使·二年级语数英综合(2021年4期)2021-06-15
海外文摘·艺术(2020年22期)2020-11-18
河北画报(2020年8期)2020-10-27
紫禁城(2020年8期)2020-09-09
矿山测量(2020年2期)2020-05-17
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
岁月(2016年5期)2016-08-13
